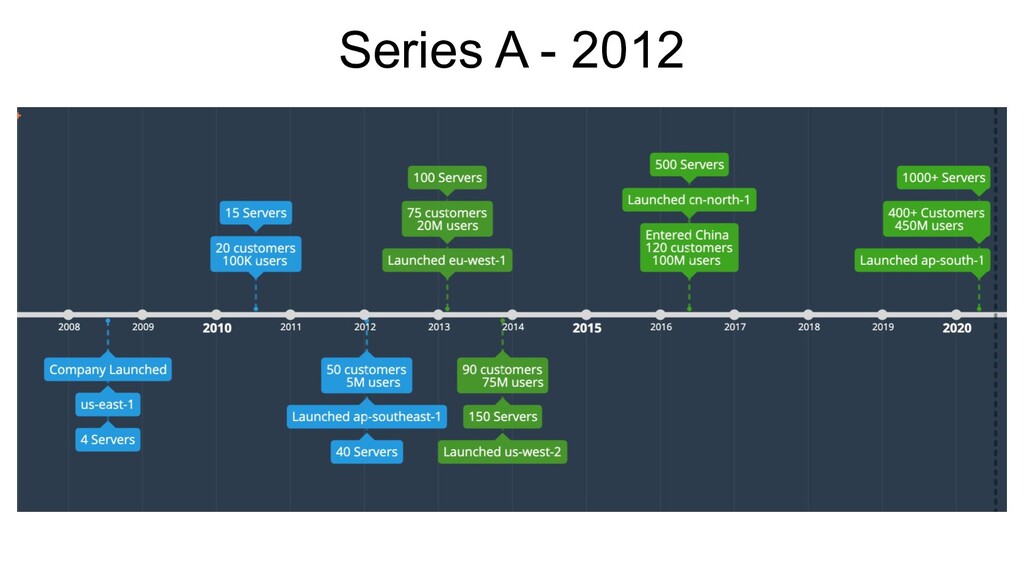
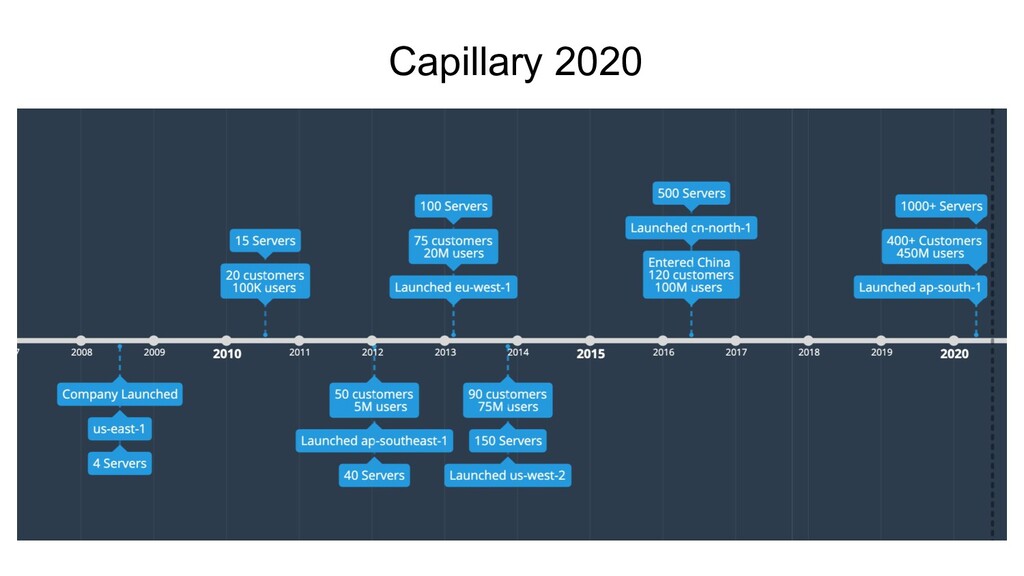
(3 app, 1 db) • PHP Monolith + 2 Java Apps • Code on prod vs Code on local box • Manual syncs and SVN Pull’s • Manual Verification and QA • Life was simple!
PHP Monolith + 4 Java Services • Service Oriented Architecture. ◦ Static Discovery • Git with SVN flavour. • Git Pulls + RSyncs still rule! ◦ Tag based deployments ◦ Should have automated!
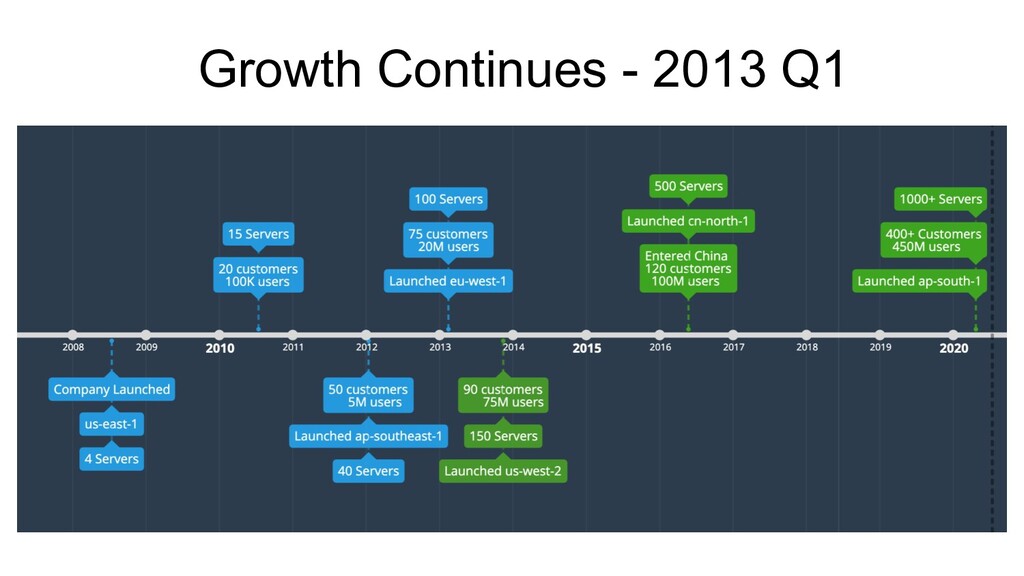
Africa & Australia in Q1! • Launched another cluster in eu-west-1 • 100+ servers (~80 apps, 20 dbs) • Service Discovery ◦ ZooKeeper - Exhibitor ◦ Apache Curator! ◦ Deployment Order and Dependencies made easy!
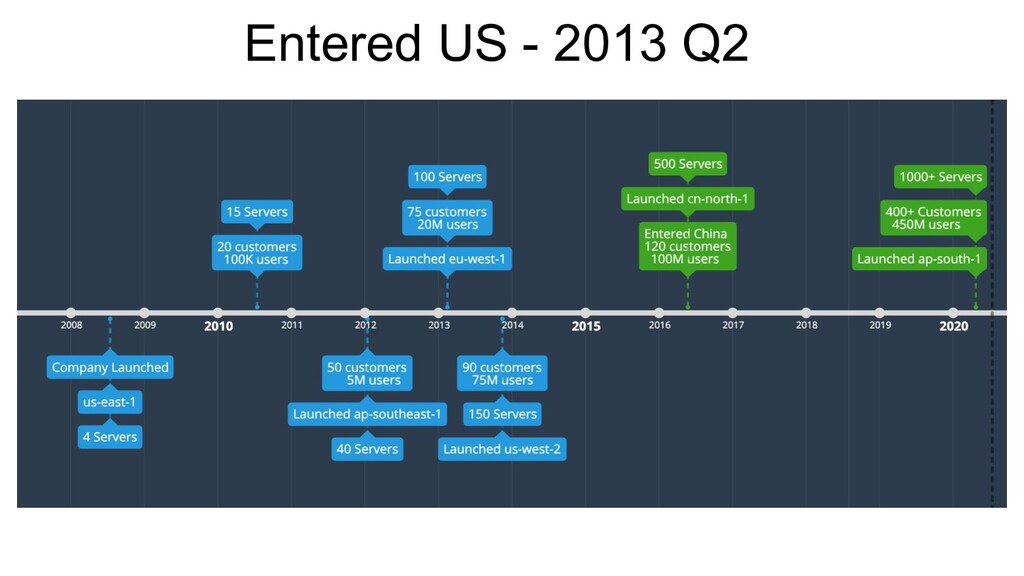
a problem. • Observability wasn’t cool, yet! ◦ Logs - 400GB per day ▪ Elasticsearch -- Too heavy to operate for a 2-member devops team. ▪ Log Streaming (Apache Flume) + Alerting Framework (Rule Engine) + MongoDb (Storage) ▪ Hive jobs for log processing and metric aggregation ▪ Splunk did exist! ◦ Metrics ▪ Custom implementation of a Time-Series store on MySQL ▪ Google Charts for visualisation. ▪ Graphite did exist! • Re-invented the wheel, unnecessarily!
◦ Took Inspiration from Yahoo! Days - YPM / Igor for the win! ▪ Move to self-contained bundles - Debian packages. ▪ Automated Release Distributions via Jenkins- Testing, Staging, Production ▪ Templatize Server States. ▪ Easy to deploy & rollback (upto 3 versions). ▪ Pre-install and Post-install steps allow seamless deployments & restarts. ◦ Deployment times reduced by 75%. ◦ Did someone say Containers? ▪ Meh.. Too early for us!
Deployments - duh!! ◦ Need version control for DDL’s. ◦ Enter - DBDeploy ◦ Customized Wrapper on top. ▪ Reduced inconsistencies significantly. ▪ Devops & DBA’s were happy! • Only devs to blame now. • Monitoring & Logs ◦ Home grown tools still holding strong! • No more problems - yay!!
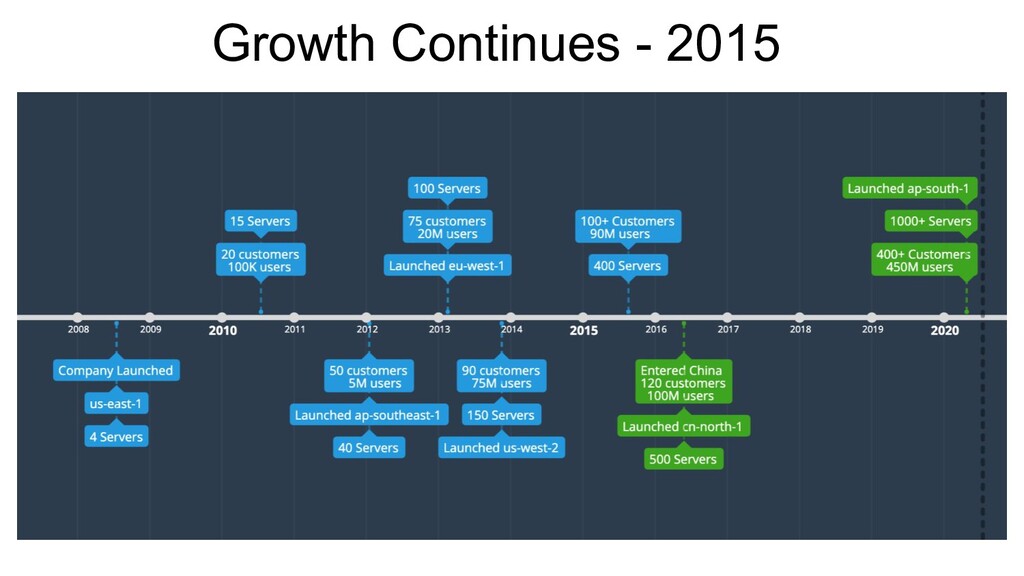
Data explosion • Keys Tables go beyond 500M records each. • Core Entities are transactional by nature - MySQL is the king! • Sharded the DB and the Services Layers • Home grown implementation. • Vitess wasn’t widely popular, yet! • Multiple copies of the schema in the same cluster • DBDeploy is still going strong - Maintains state on the db instance.
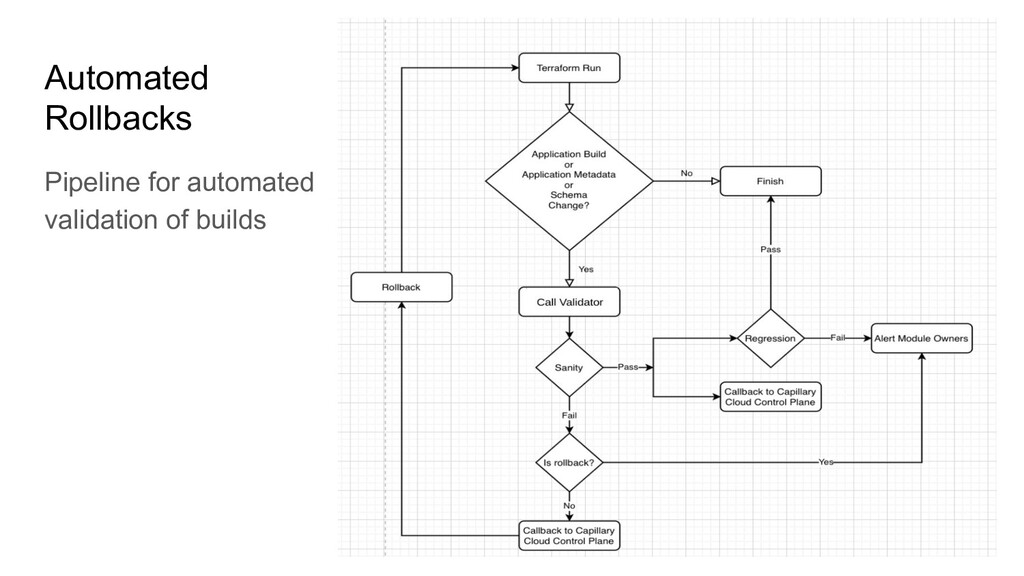
of company stage • Homegrown tools can lead to Confirmation Bias! • Deployment troubles grow exponentially as you add more clusters, and microservices. • Schema Management should be a part of Deployment Workflows!
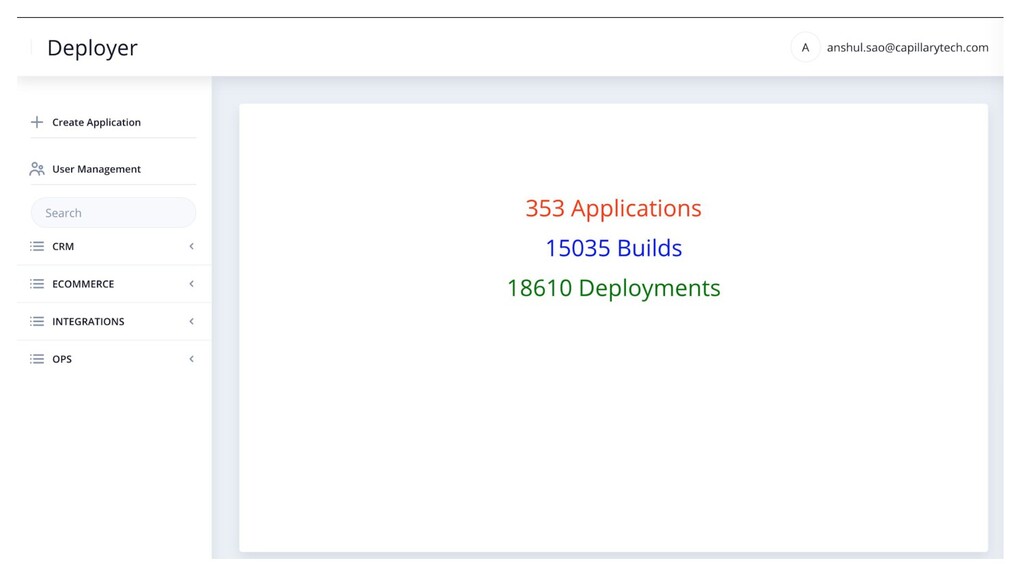
• 325 apps + 75 db’s • 100 devs + 30 QA’s • PHP Monolith + 25 Java Services in each cluster. • Package Based Deployments • Home Grown Tools for post-deployment monitoring & alerts. • 15 master data shards across clusters. • DbDeploy for Schema management. • PHP Servers were not scaling, Unpredictable loads, underutilization of infra resources. DevOps ticket based scale up and down.
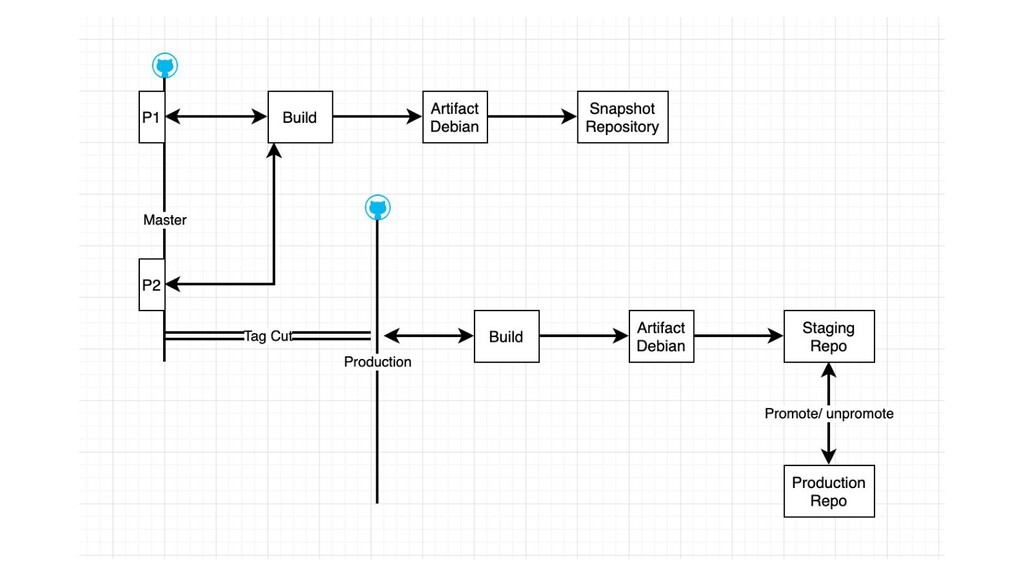
• Branching!! Too many branches to manage codes to be merged • No of microservices exploded • Which commits to be merged? Cherry picking and manual merges • Stay back to release, keep it safe! • Gitflow branching model adopted. • Jenkins to build and push artifacts in debian repos. Promotion of packages for full QA control. • Rundeck and rolling releases! Takes care of taking server offline, release and move!
multiple clusters, serving different geographies • Server estimation upscaling, downscaling was a manual task with Devs and Devops fulfilling the requests by Tickets. • Lot of wastage, as non peak hours also the cluster size was constant. • Increased downtimes in case of performance bugs. • Debian to Docker • Gitflow along with docker images (Same image is still not promoted from environment to environment. Limitation!!) • ECR for repository. • Migrated all config files to env variables. • Created Capillary custom CI.
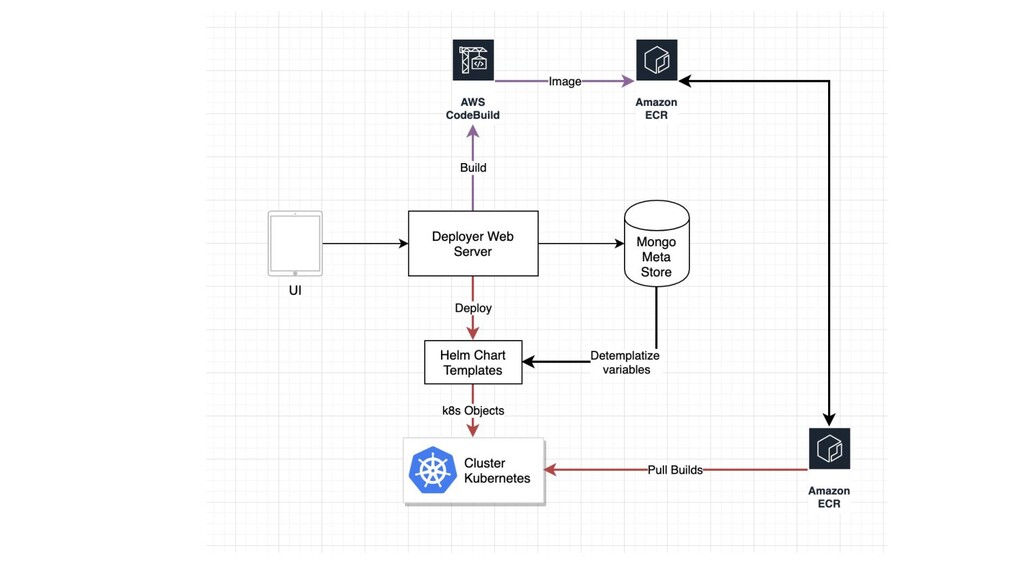
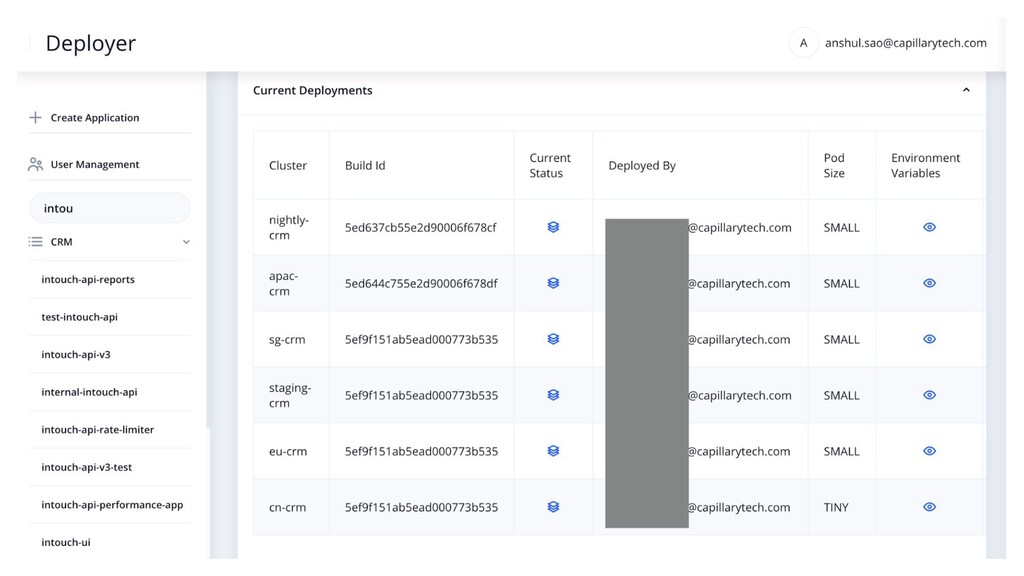
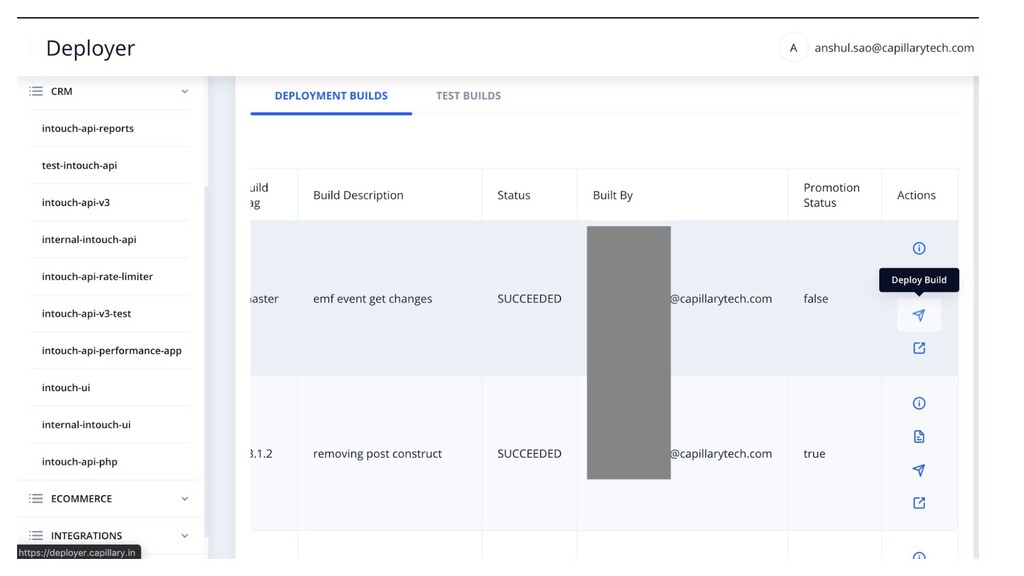
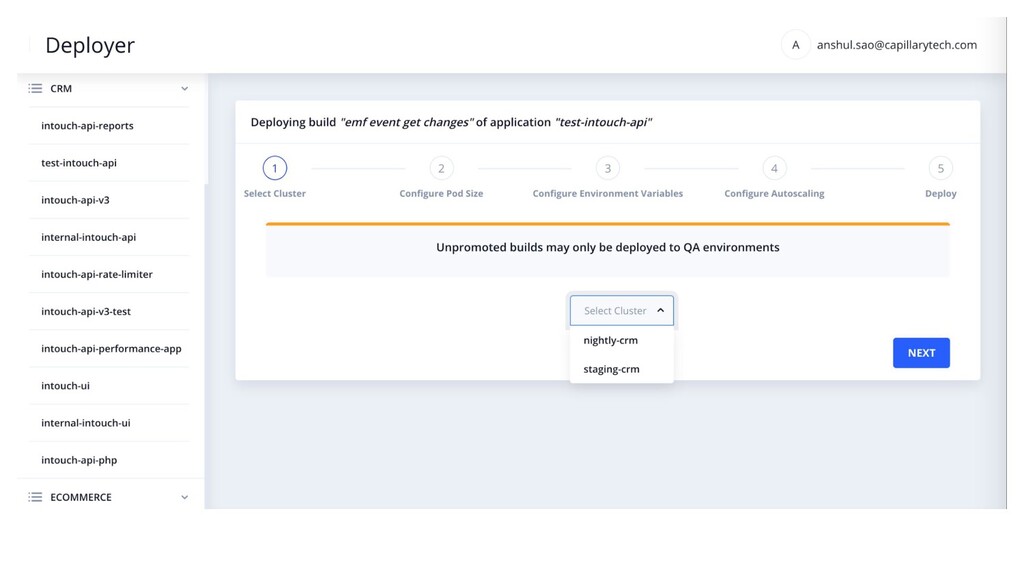
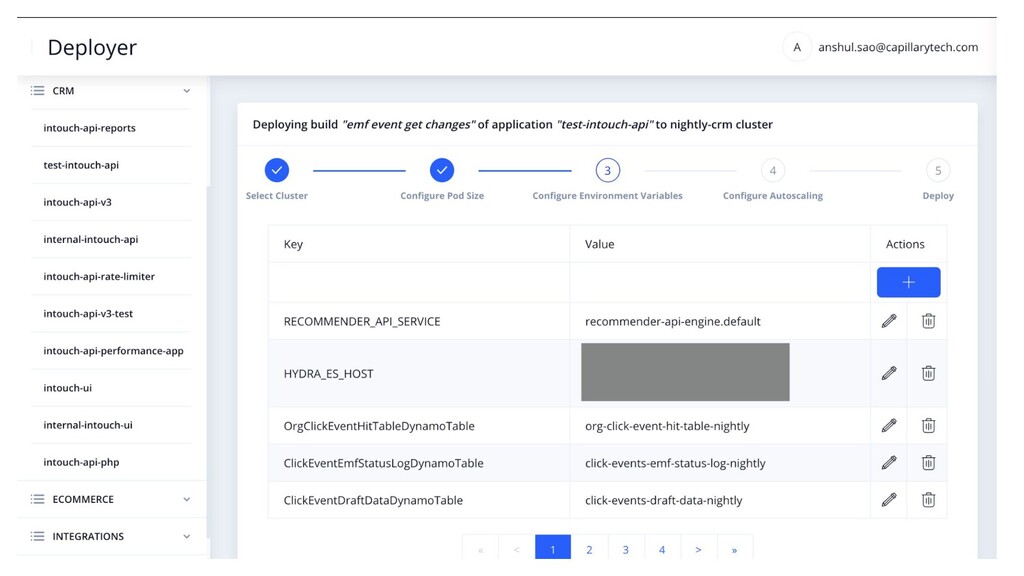
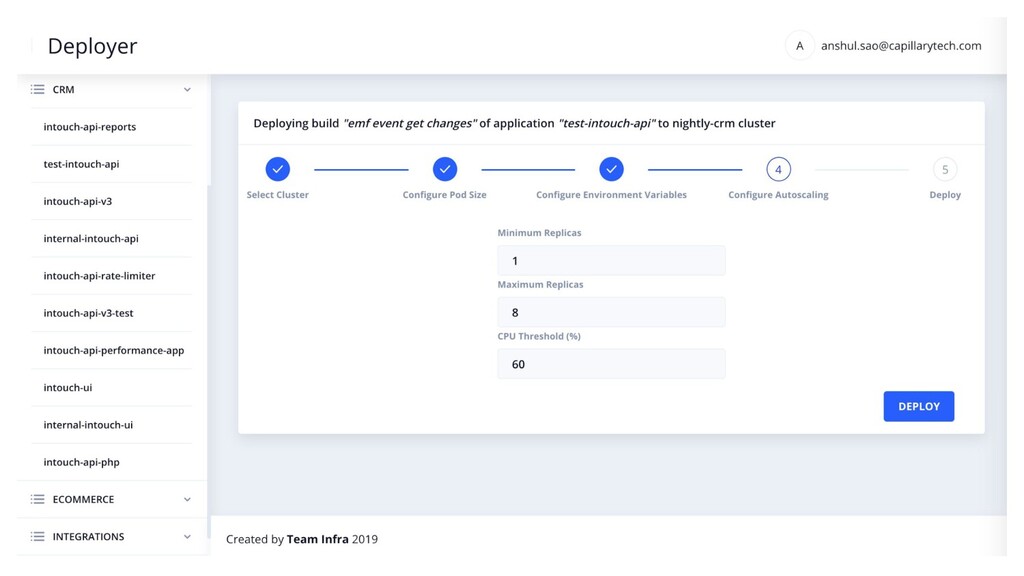
manage Kubernetes deployments? • Should developers have kubectl access? • Every deployment meant different env vars. Make files are so old school and unmanageable • Build selection and updating in yaml is a pain. • Created a Helm based build & deployment system • Build selection is UI driven and with SSO and access control • HPA configs can be easily defined with CPU thresholds in UI. • Deployment specific environment variables management in UI
status in each cluster can vary. • Developer can write a bad query or a bad undo query wrecking havoc. • Versions can grow really fast and it can be overwhelming to comprehend the final state. • How to avoid alters on big tables? • Track Final version rather than mutations • Limit permissible operations, no drops. • Schema diff to find transformation to get to final state. More predictable! • Types of data ◦ schema ◦ database_view ◦ seed_data
current db migrate To be used in Capillary Cloud Each change is version States are versioned CREATE TABLE tbl1( col1 int PRIMARY KEY ); CREATE TABLE tbl1( col1 int PRIMARY KEY); ALTER TABLE tbl1 ADD COLUMN col2 int; CREATE TABLE tbl1( col1 int PRIMARY KEY, col2 int );
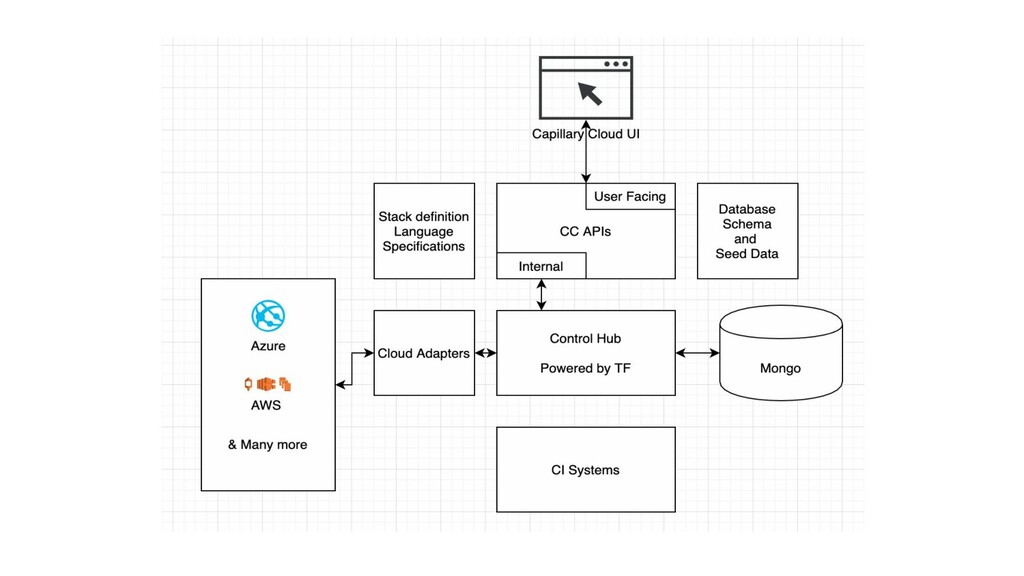
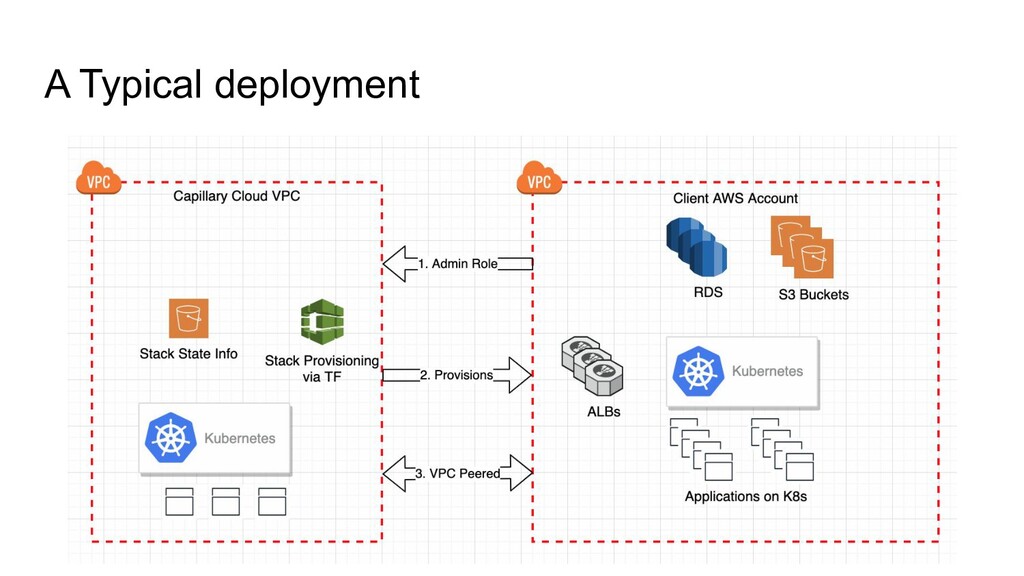
can be easily launched and managed Opinionated JSON Files to define everything in stack. Applications Service discovery is redundant Kubernetes Namespaces Manage Application access to DB TF providers to fulfill application requests with access control. How to avoid messy nginx configurations and Domain SSL management Application Definitions to contain ingress rules. TF Providers to manage domains. How to reference dynamic cloud objects without hardcoding or maintaining region specific configs DSL to refer any entity in stack. Monitoring, APM and Alerts Reusable hardened TF Modules to achieve high observability. Prometheus! What about Schema Management A new kind of Schema sync which compares end states and does schema diff to get mutations
and priority constraints. ◦ Make room for deployment debts along with business growth and priorities • We tried Deis for deployments which had limited community and support, wasted months of effort. ◦ Always choose external dependencies with good community support. • Trying to make everything Generic consumes a lot of time with limited immediate benefits ◦ It’s ok to be opinionated, to move fast and to align with internal company development processes. • Manual Interventions/ steps will cause problems in long run ◦ Automate everything
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![• Anshul Sao ([email protected]) • Piyush Goel ([email protected], @pigol1) Co-ordinates](https://files.speakerdeck.com/presentations/be9cca05eebe4e8fbb1692d42bad6b33/slide_48.jpg){kind=link}