スケーラブルなRDB環境が実現できる夢のようなNewSQLの分散データベースTiDB。
世界での普及が進み、更にDBaaSマネージドサービスとしての普及が加速しています。
このスライドでは、マネージドサービスであるTiDB Cloudのメリット・使われ方・アーキテクチャなど、事例やデモを交えて紹介します。ぜひTiDB Cloudをお試しください。
TiDB Cloudクイックスタート:https://docs.pingcap.com/ja/tidbcloud/tidb-cloud-quickstart
アーカイブ動画:https://youtu.be/Tf9kNT4ZApI
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
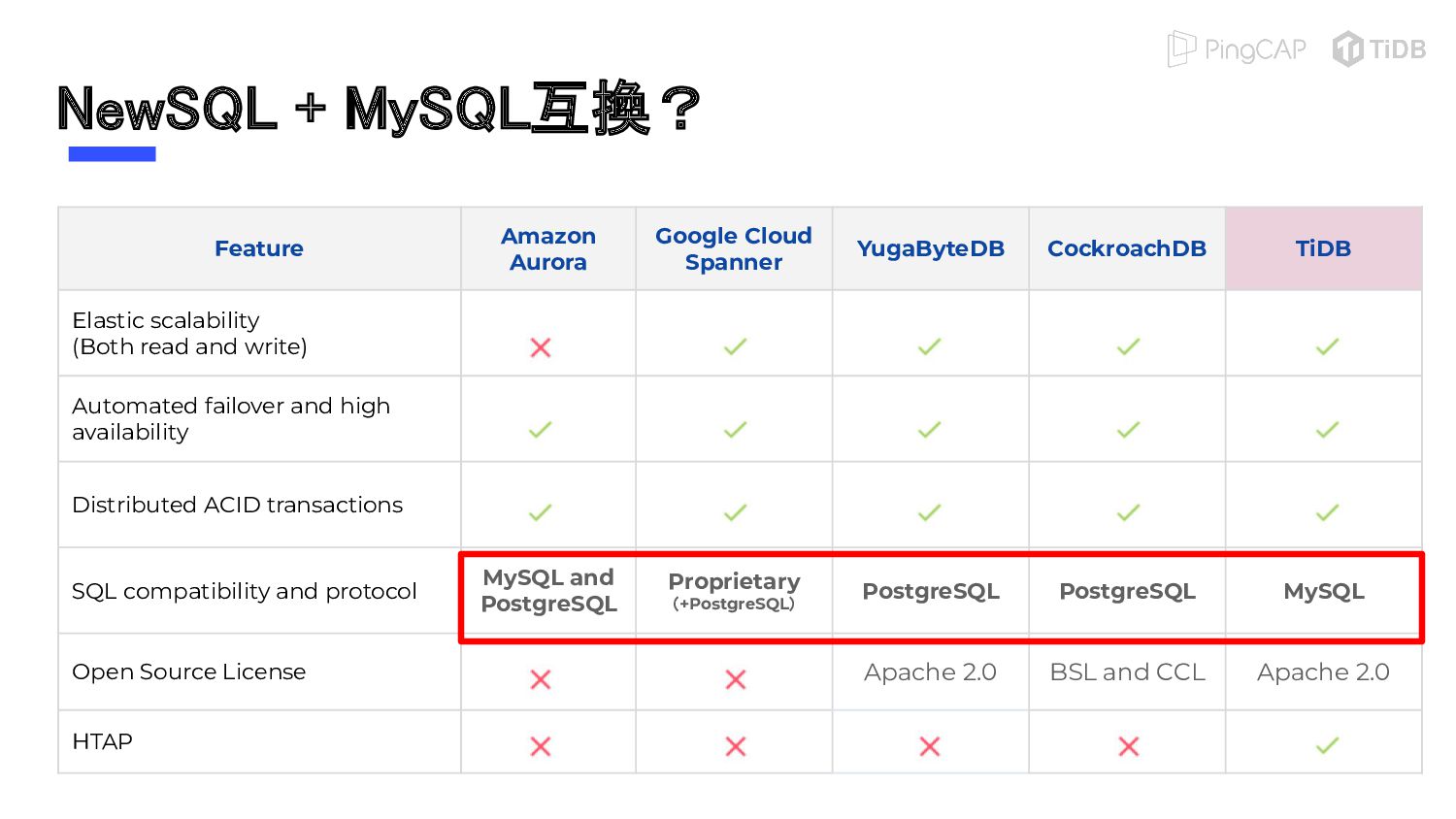{kind=link}
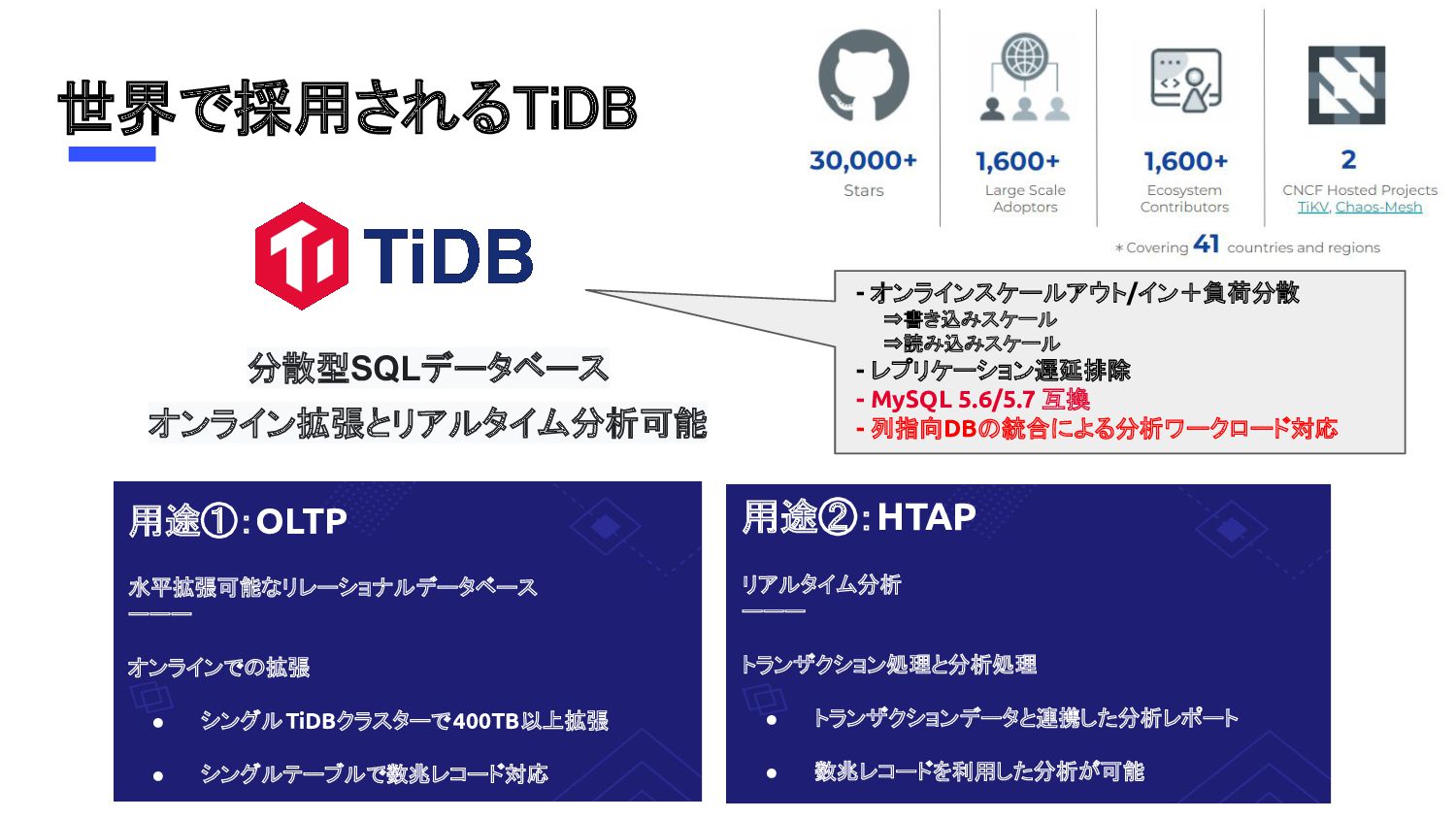{kind=link}
{kind=link}
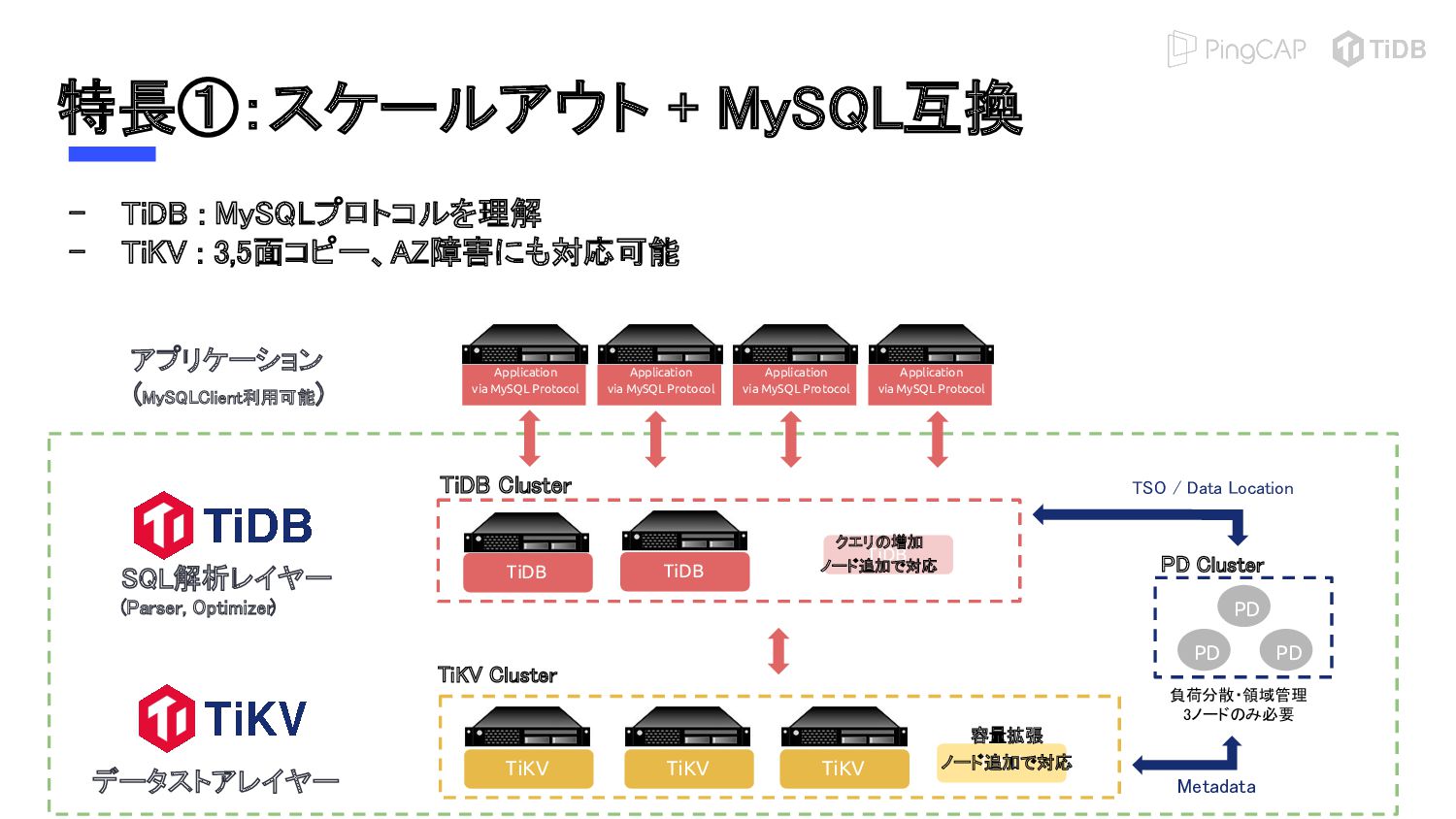{kind=link}
{kind=link}
![既存のツールを利用可能 下記は検証済みのものになります。その他のツール利用が必要な場合はリクエストお願いいたします。 https://docs.pingcap.com/appdev/dev/app-dev-overview Connector - [Go] MySQL connector - [Java]](https://files.speakerdeck.com/presentations/ce543b74c9884c04a2a3b4ffb17a5481/slide_13.jpg){kind=link}
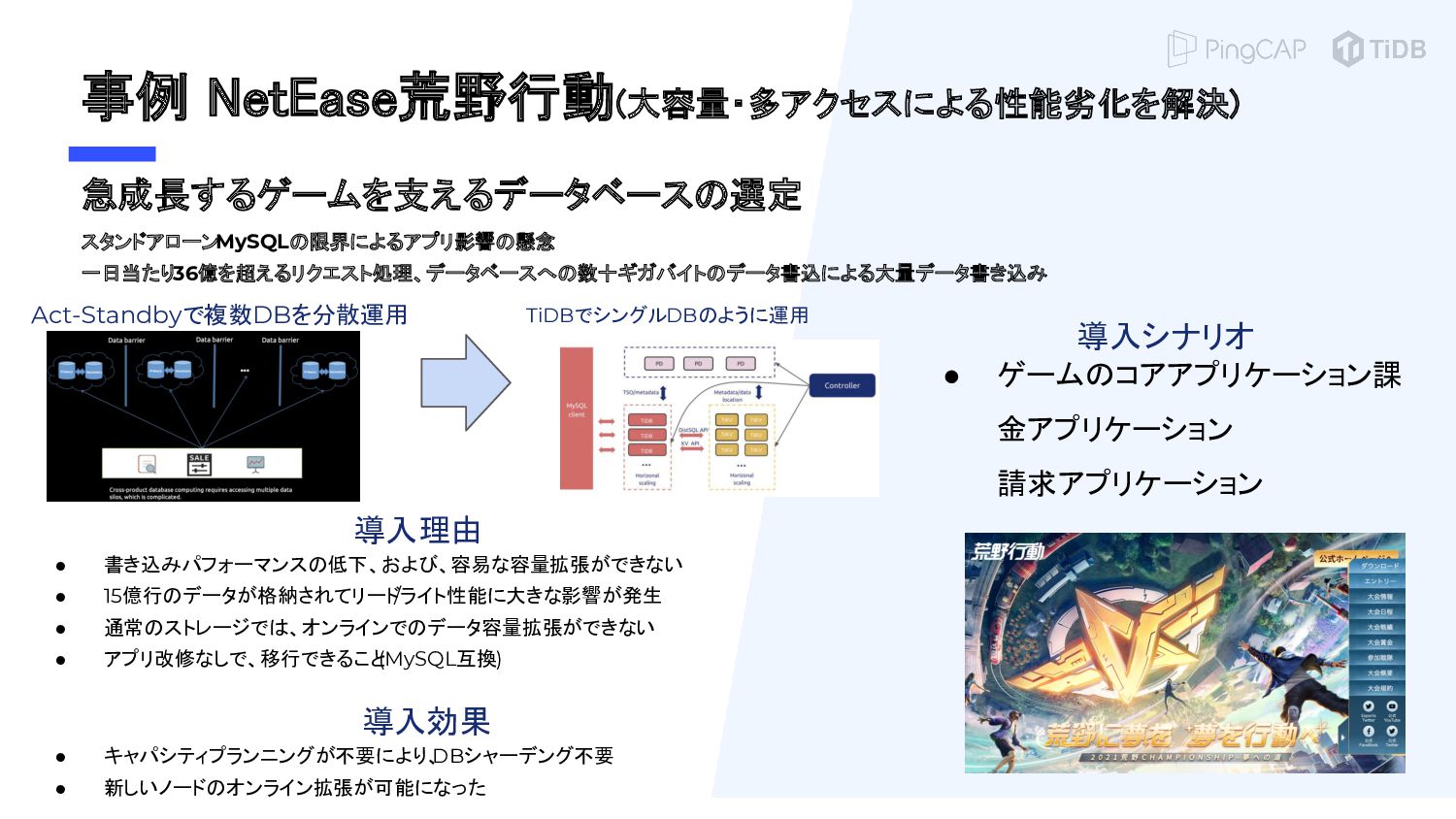{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
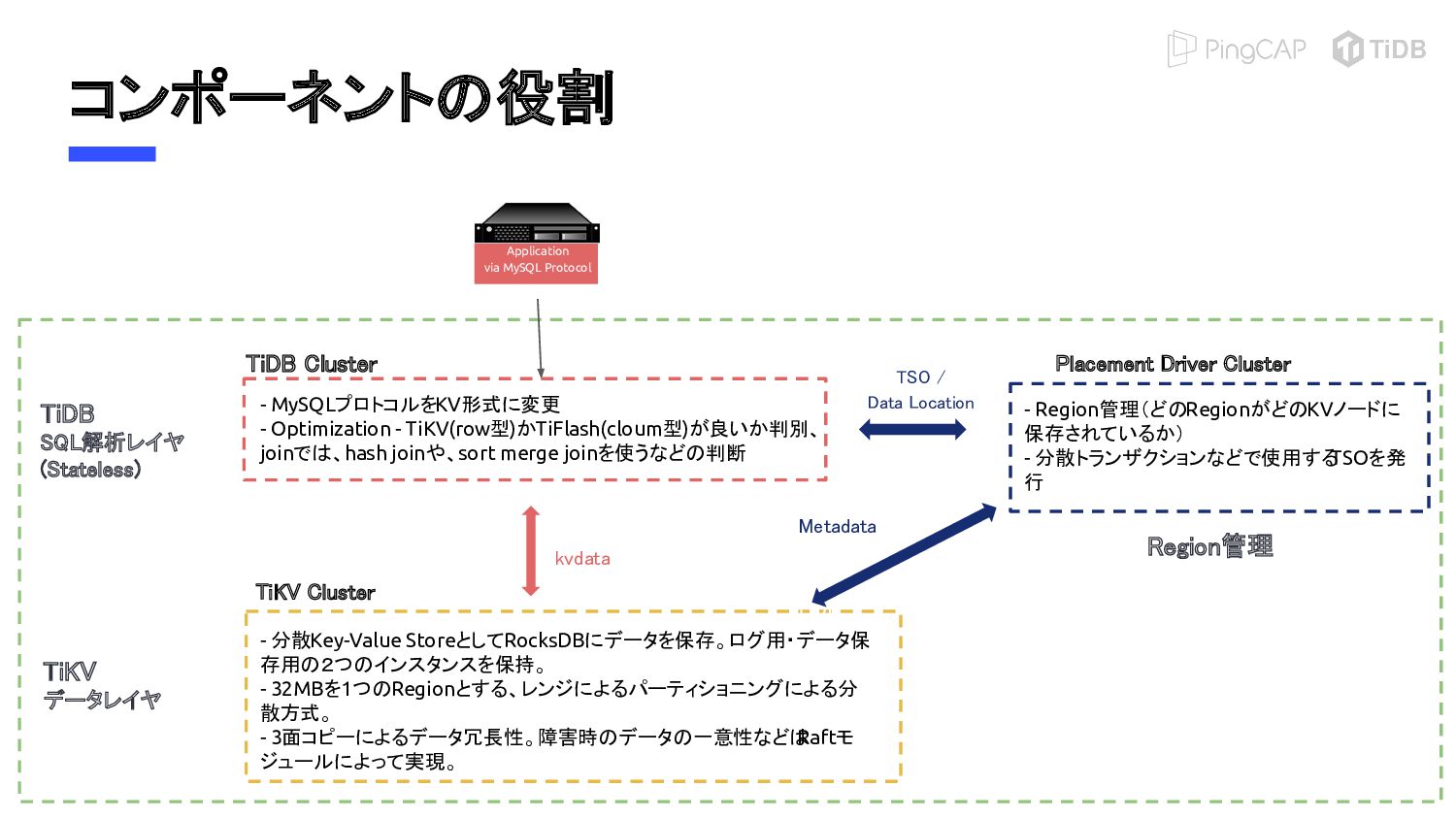{kind=link}
{kind=link}
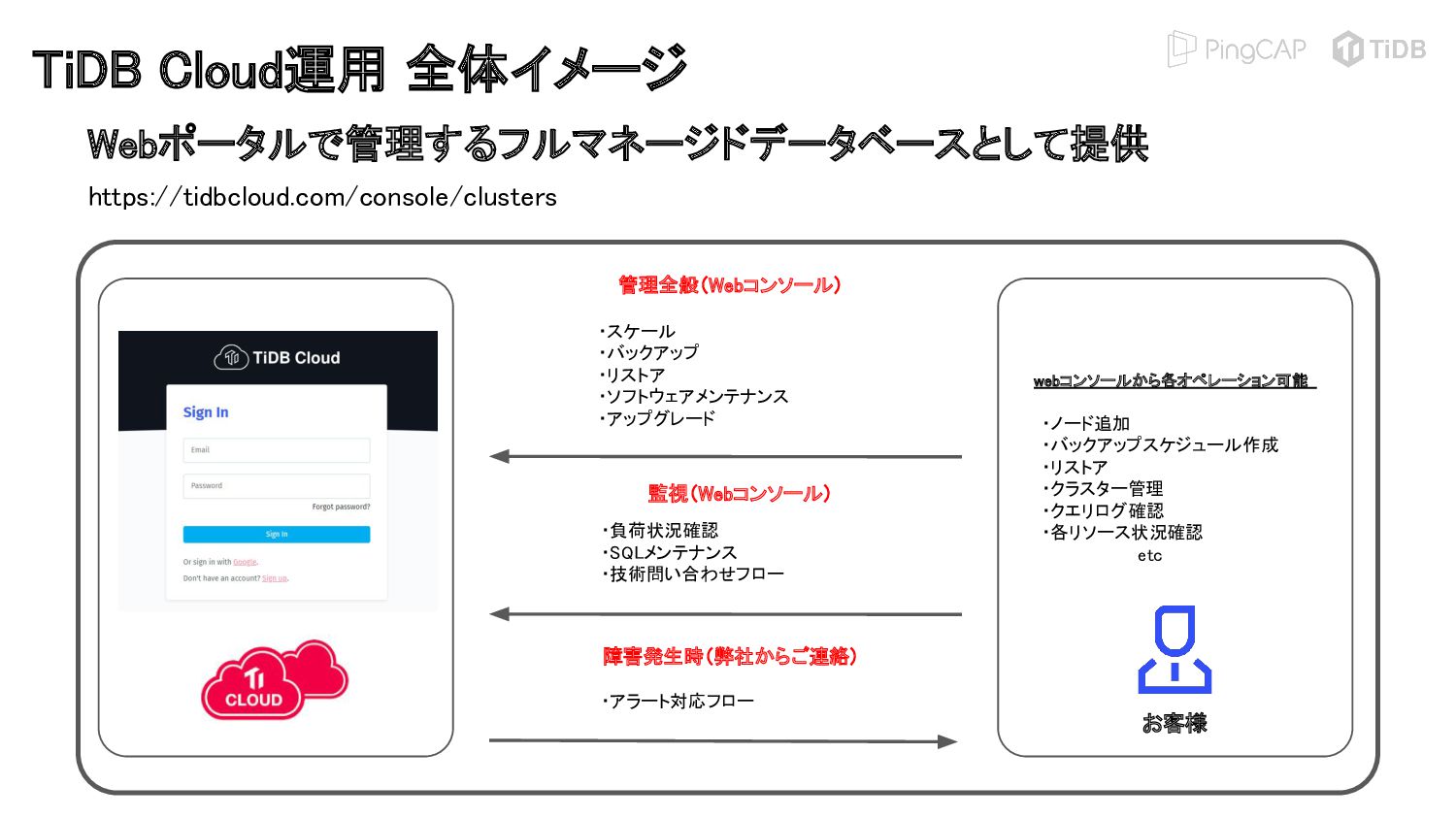{kind=link}
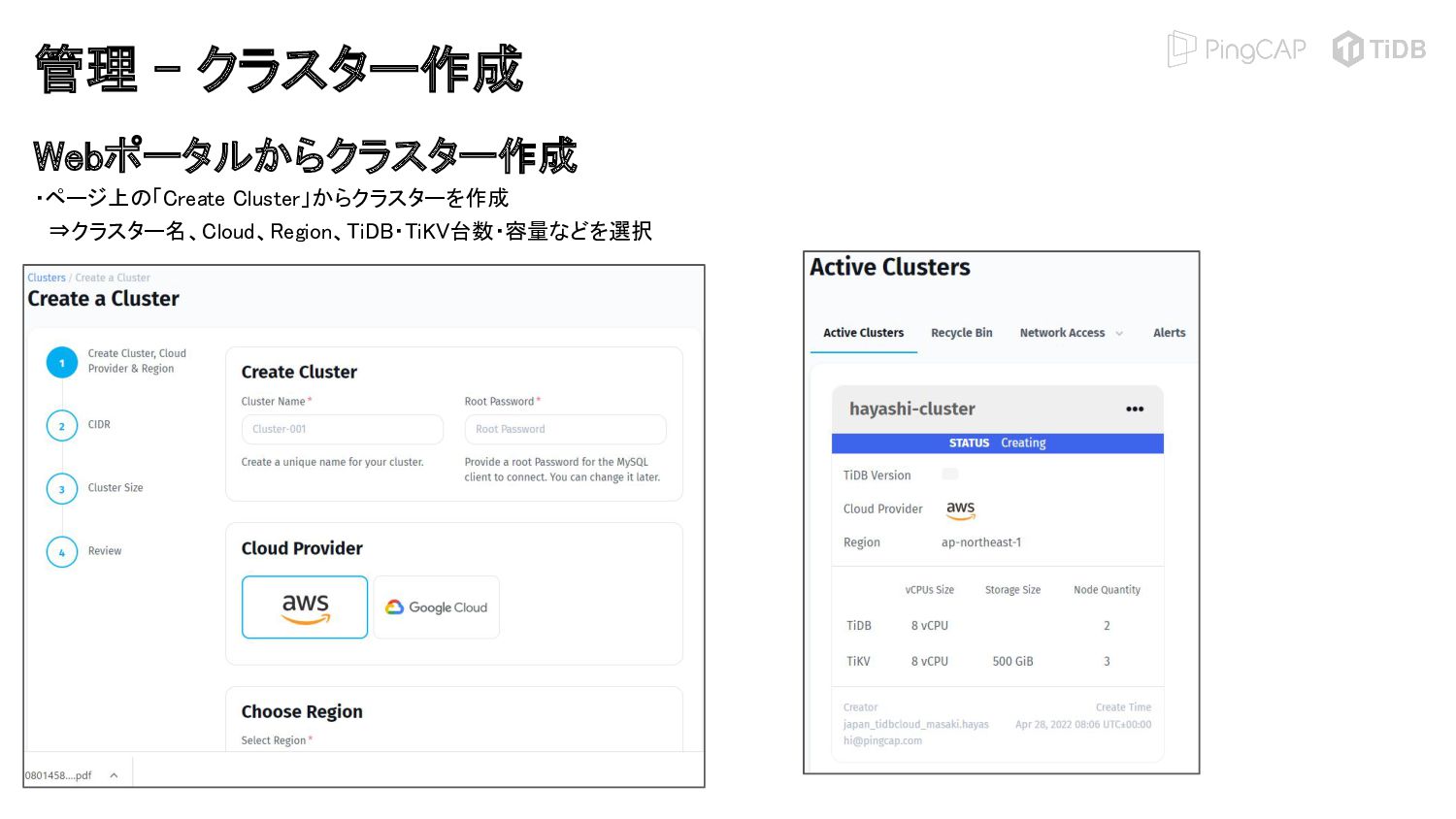{kind=link}
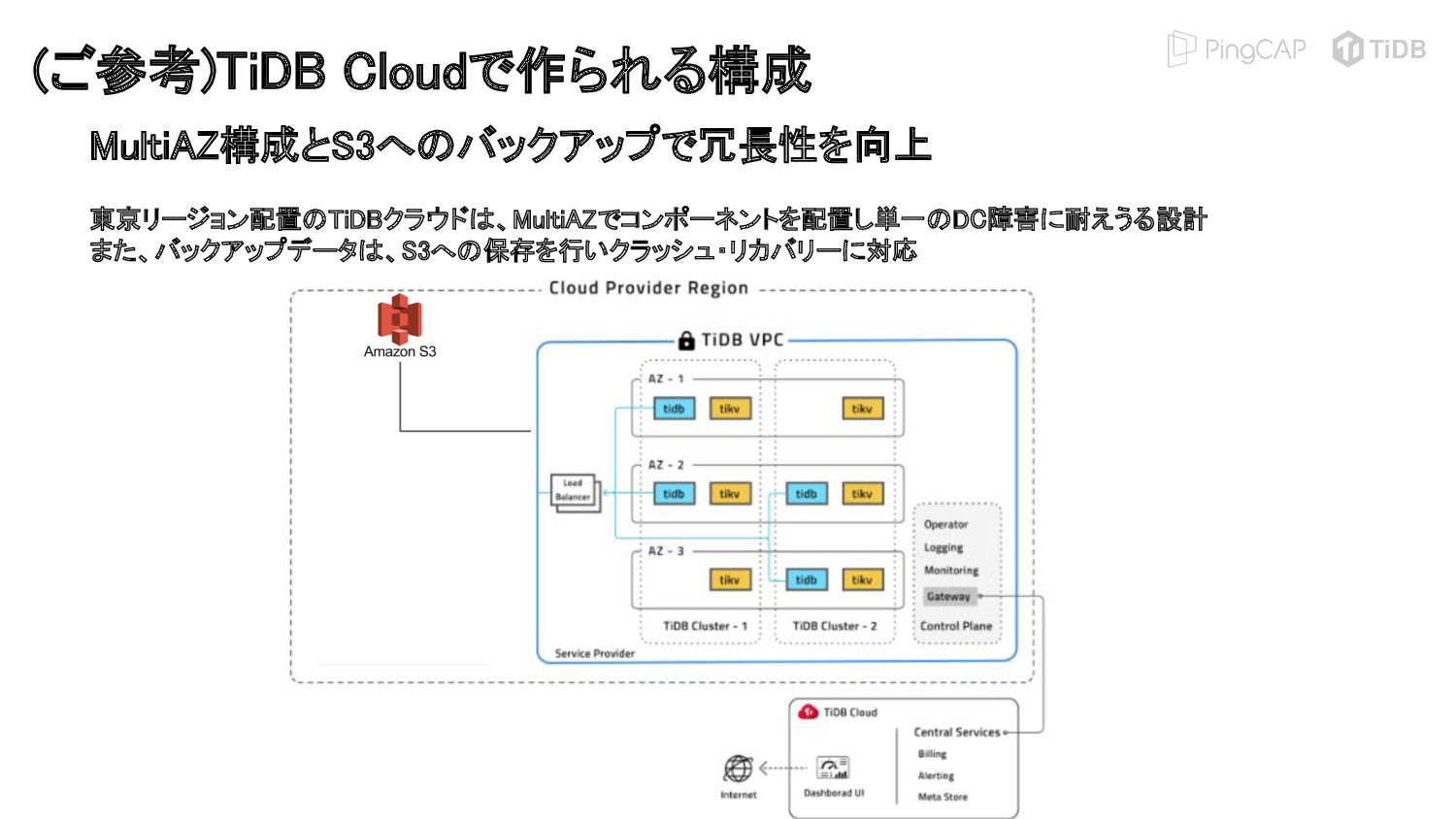{kind=link}
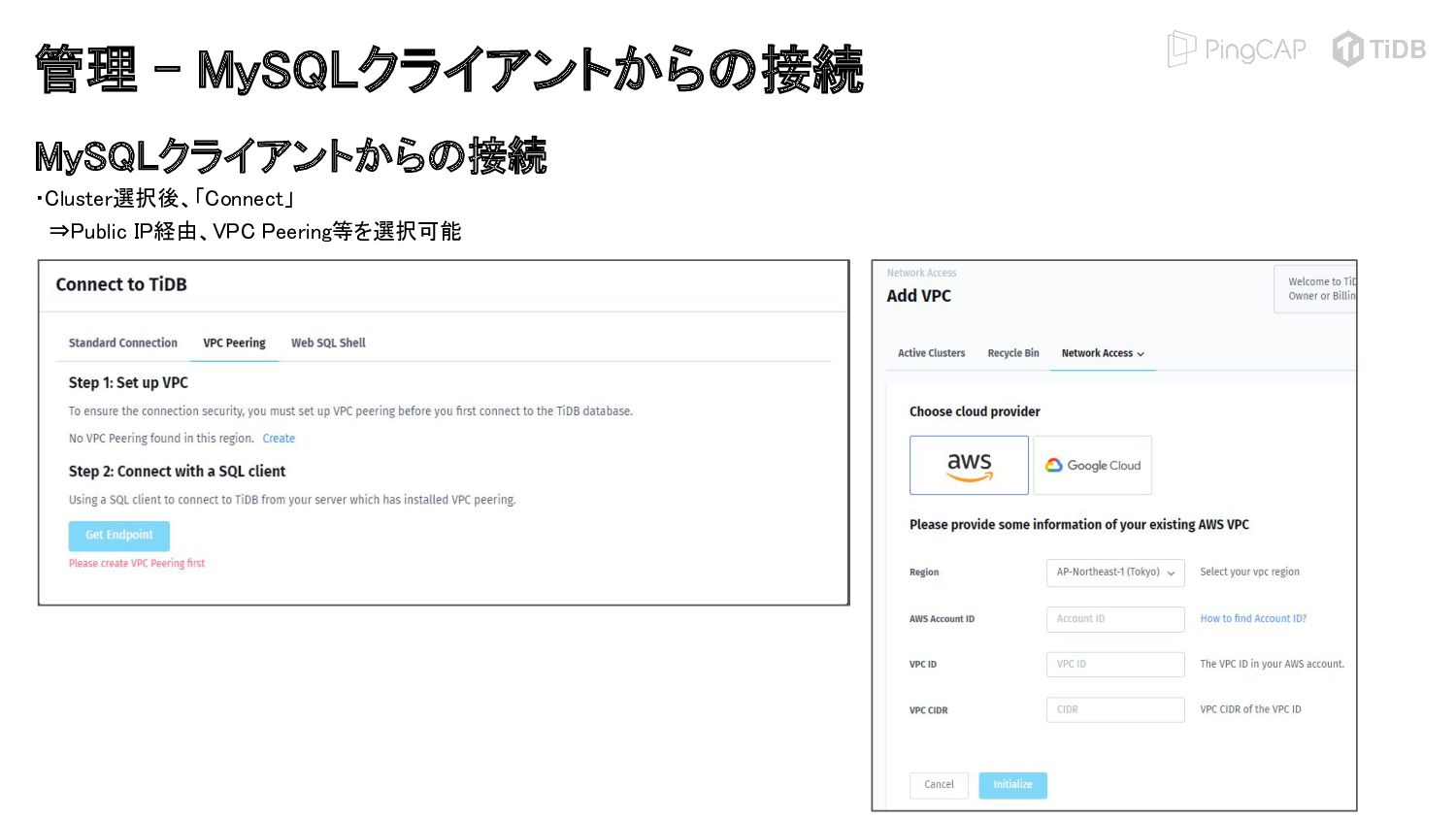{kind=link}
{kind=link}
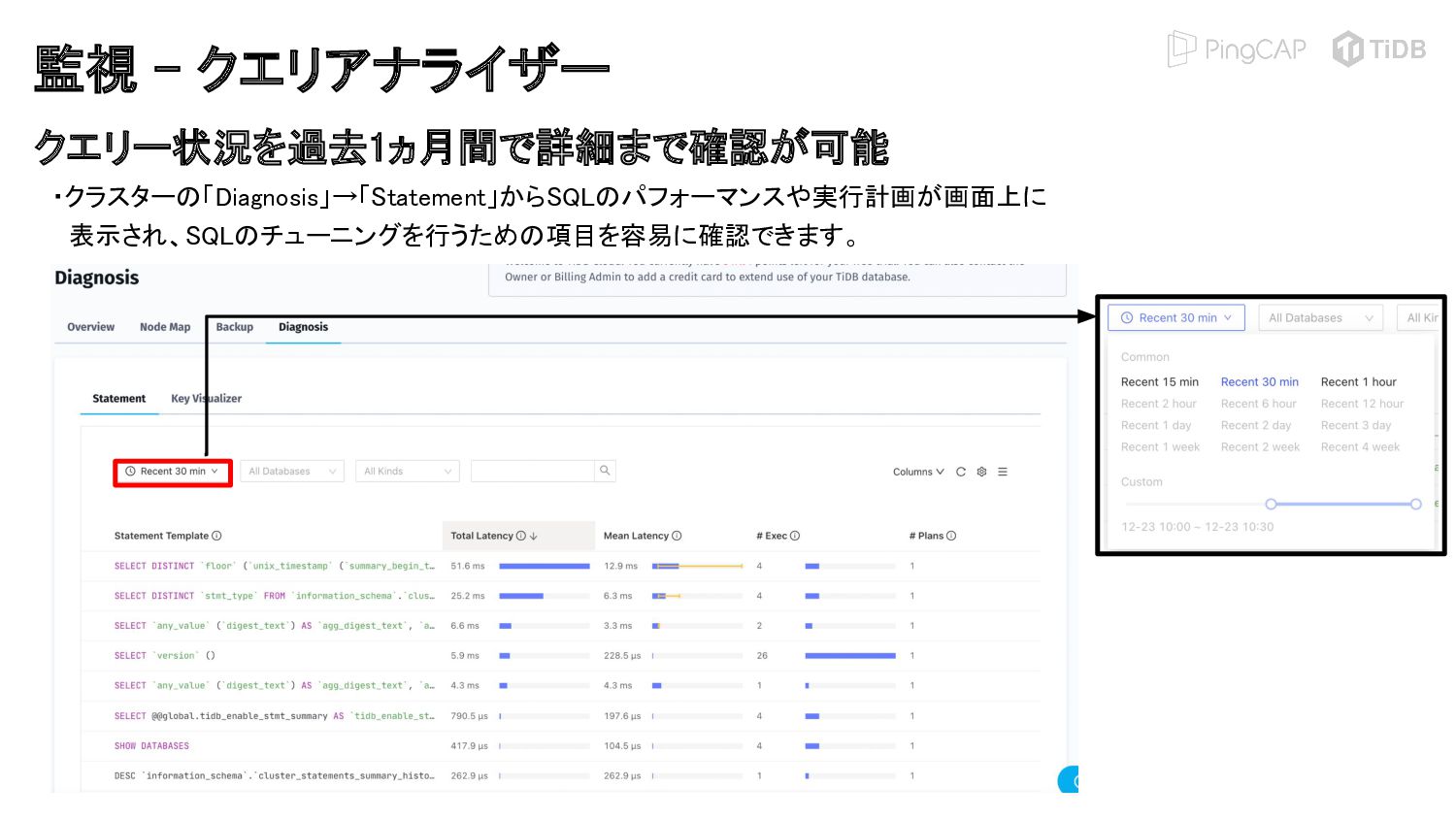{kind=link}
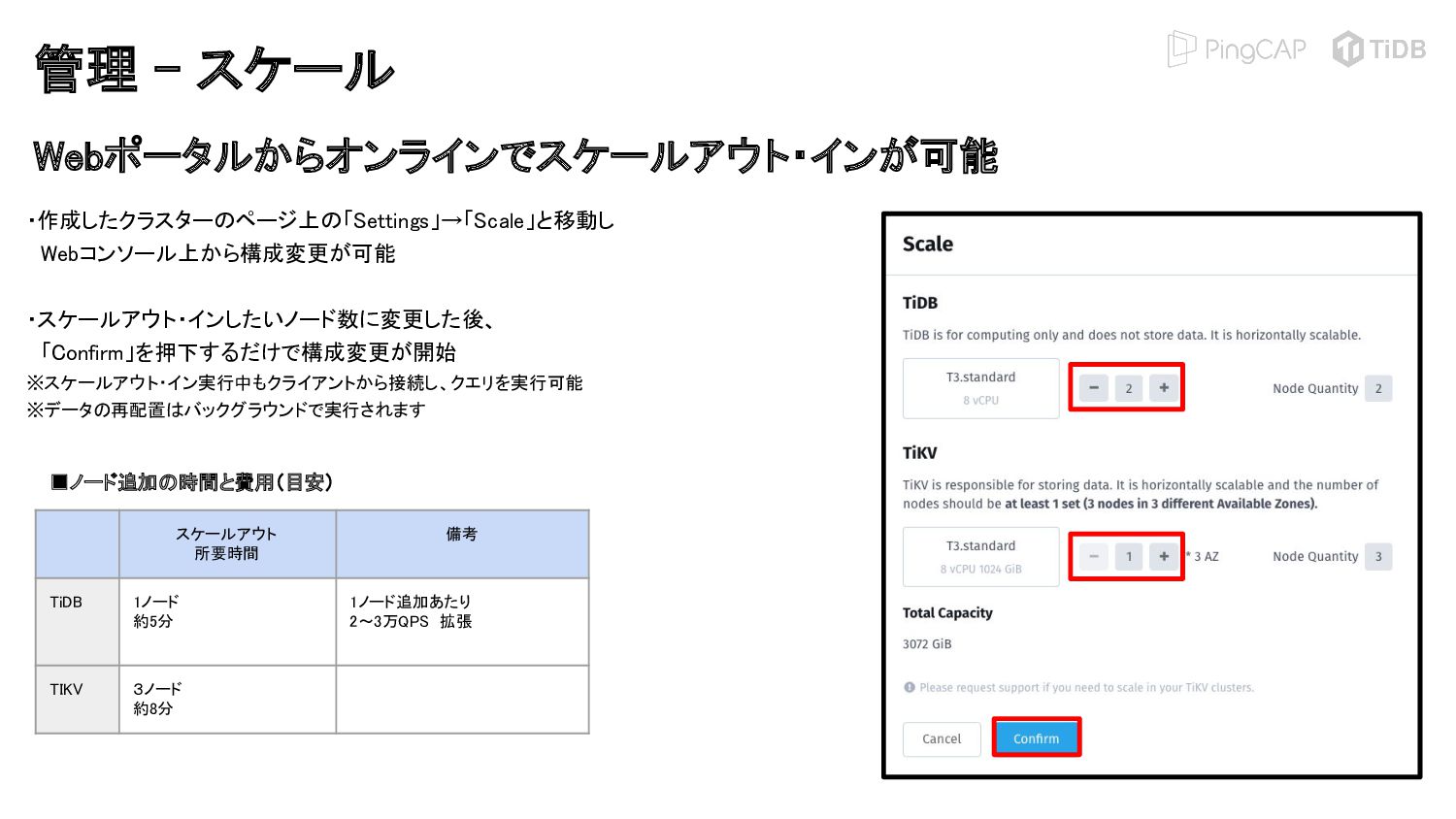{kind=link}
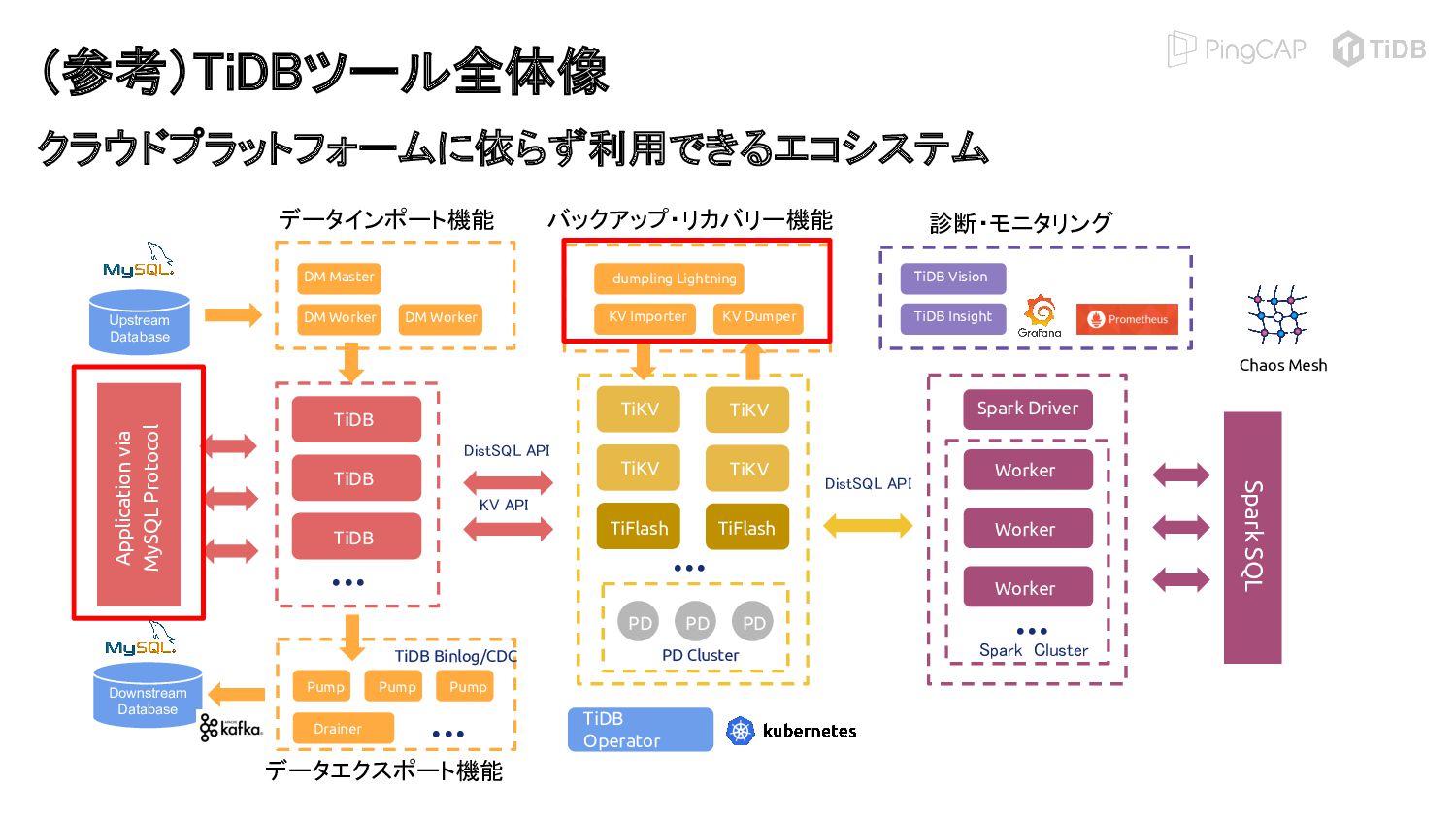{kind=link}
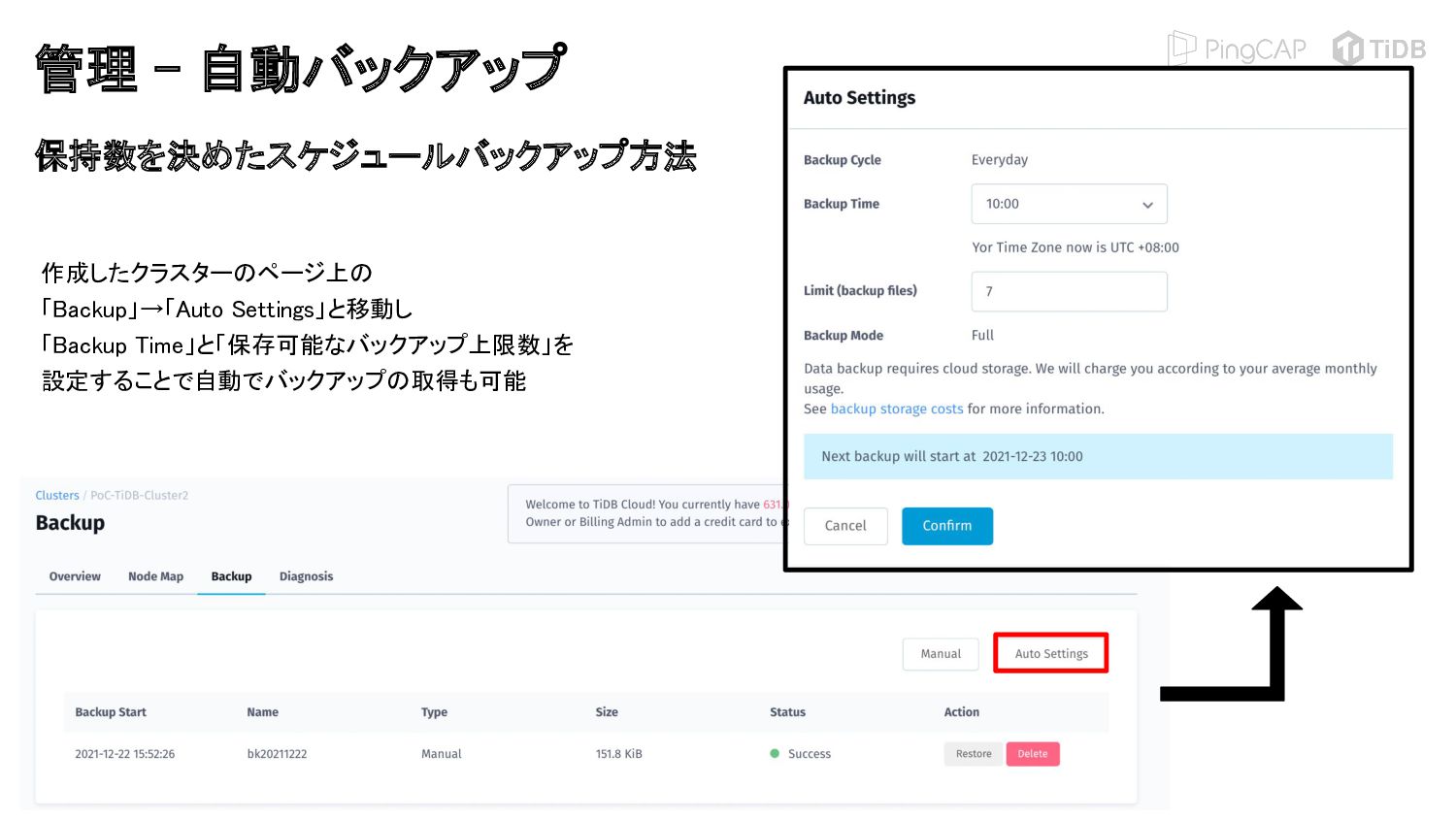{kind=link}
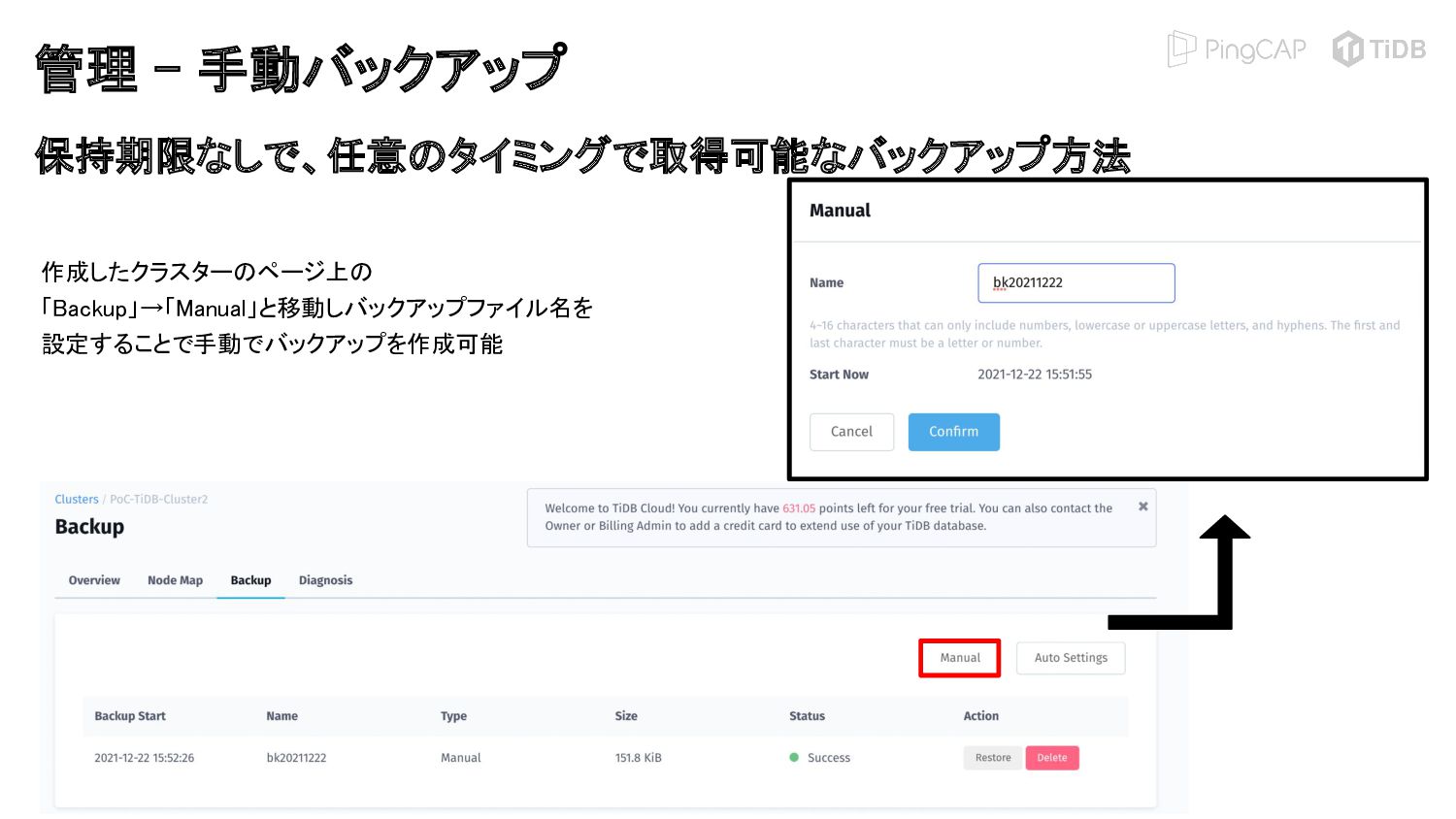{kind=link}
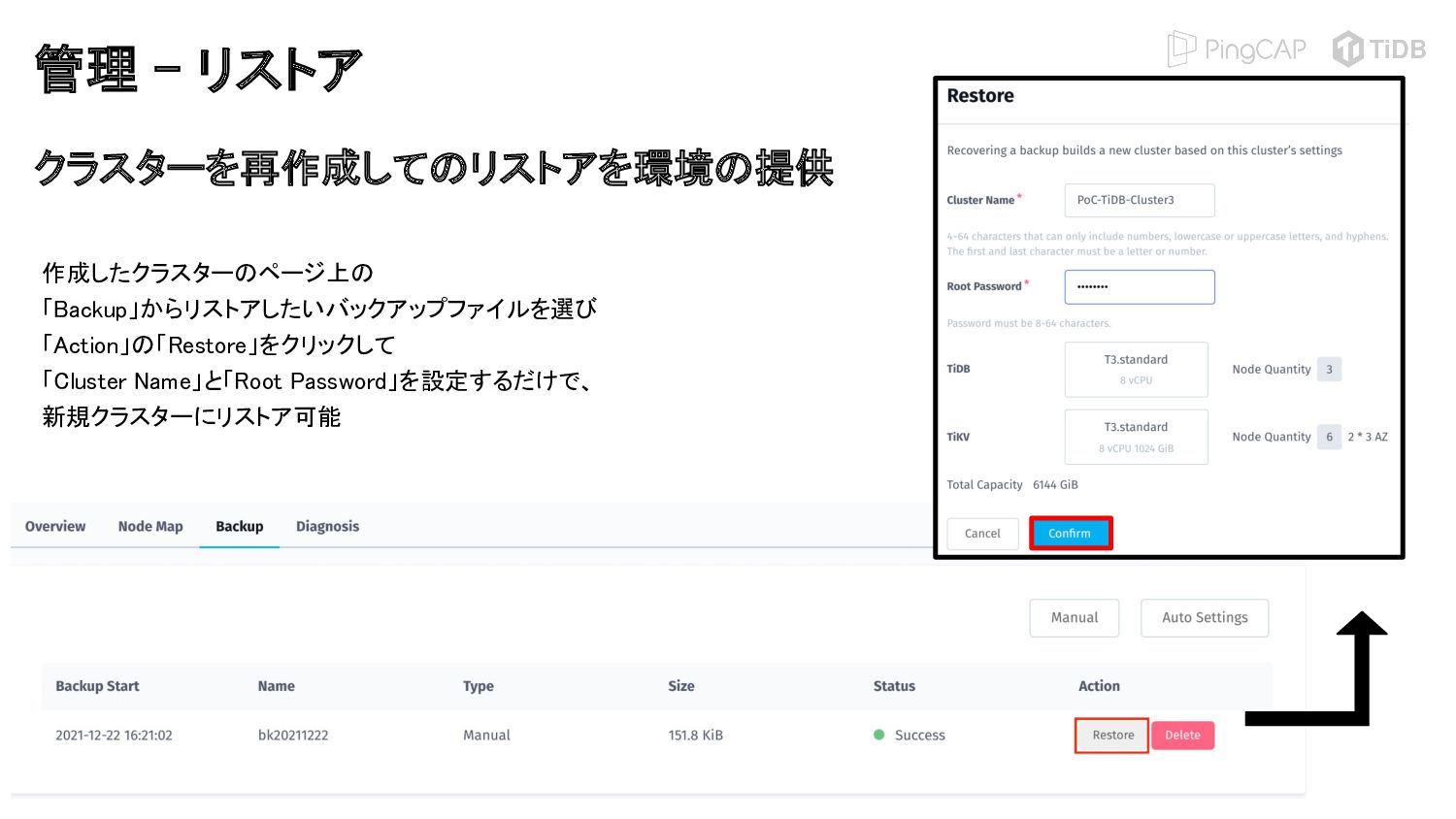{kind=link}
{kind=link}
{kind=link}
{kind=link}
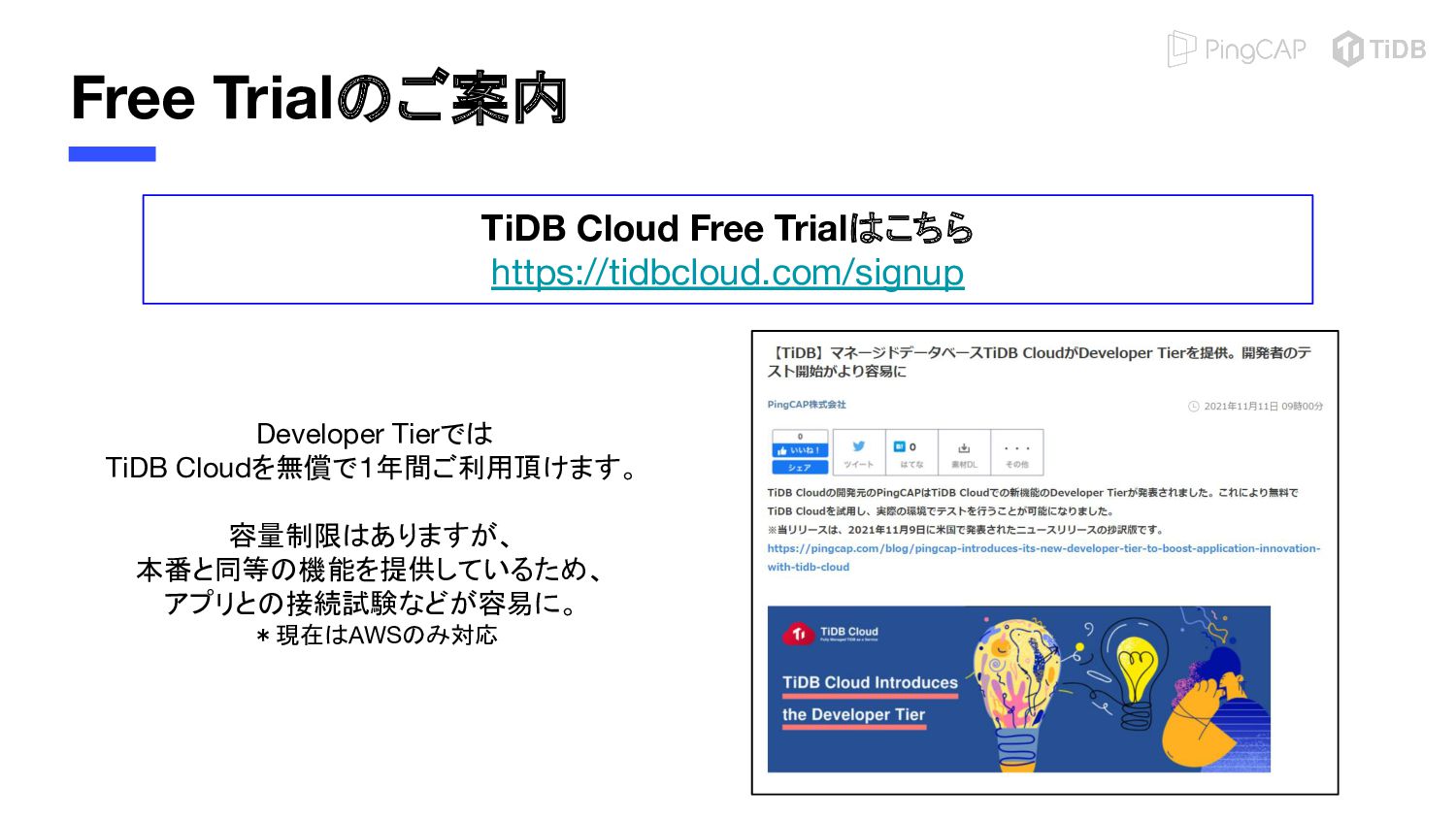{kind=link}
![お問い合わせ先 お問い合わせ先 [email protected] 製品に関する問い合わせ以外にも ハンズオンや製品デモはじめ、 勉強会などの実施も可能です。 気兼ねなくご相談、ご連絡ください。 *右の画像はCyberAgent様向けに実施したハンズオンの様子 https://developers.cyberagent.co.jp/blog/archives/33416/](https://files.speakerdeck.com/presentations/ce543b74c9884c04a2a3b4ffb17a5481/slide_51.jpg){kind=link}
![Thank You! https://www.pingcap.com/ [email protected]](https://files.speakerdeck.com/presentations/ce543b74c9884c04a2a3b4ffb17a5481/slide_52.jpg){kind=link}