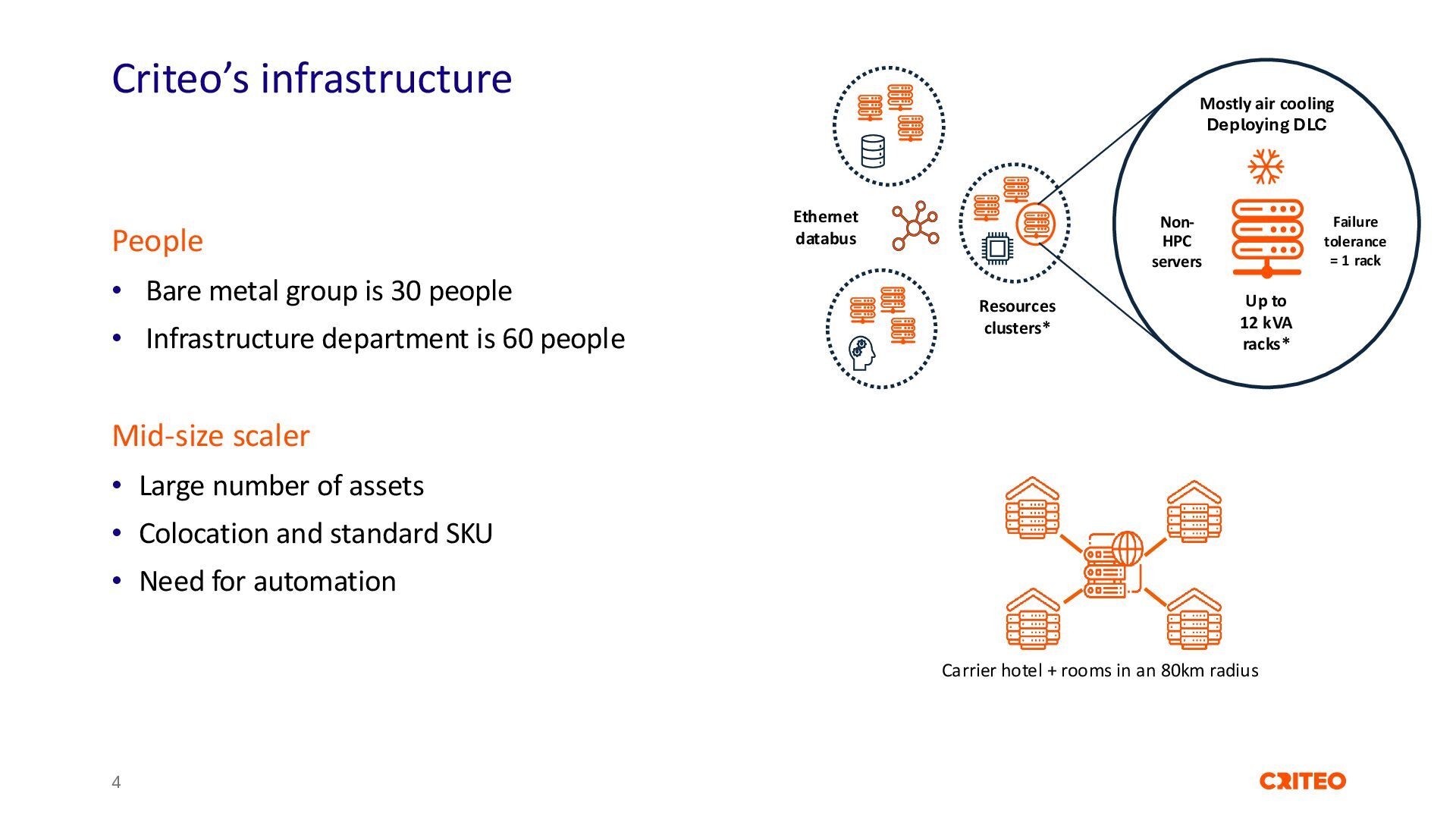
• Infrastructure department is 60 people Mid-size scaler • Large number of assets • Colocation and standard SKU • Need for automation 4 Carrier hotel + rooms in an 80km radius Up to 12 kVA racks* Non- HPC servers Mostly air cooling Deploying DLC Ethernet databus Resources clusters* Failure tolerance = 1 rack
reasons • Biggest CPU and GPU are reaching 500-1000+W • Biggest CPU are reaching 200c • Air cooling is showing its limits Cloud and hyperscalers • Half the server market • Influence vendor roadmap towards large SKU Where to go? • Large SKU are often more efficient (economies of scale) • But we need to shift to very dense liquid cooling servers • Are we ready? 7
a DLC rack Challenges • Mainstream for HPC, less so for CSP in colocation • Colocation are only starting to build mainstream DLC room • Vendor dependent, no standardization • Everyone is defensive, legal/SLA discussions takes time What we do • One rack of 40x servers (2x 160c, 2.3TB RAM, 2x 100Gbps). In total 12k cores, 92TB of RAM. • Gain confidence we can run DLC in production Conclusion • Win on all efficiency metrics • PUE reduction at the DC level (but difficult to benefit from it at the time) See BNP’s talk
very dense • Rack level (moved from 12KVA to 50-60 KVA) • Server level (moved from 64c to 320c) Challenges • Blast radius • Noisy neighbors and new bottlenecks What we do • Network: Moving back to dual TOR with bigger uplinks • Datacenter: Search for DLC ready datacenter • Software stack: Improve isolation • Redefine SLA with end-user Conclusion • Upfront testing is important for such a change See Booking’s talk
as CPU • Time spent selecting GPU is increasing New CPU architectures • ARM for servers is a reality now • RISC-V in the next 5 years? New objects • CXL memory expansion? • Accelerators? Challenges • Need to understand more things/subjects • Too many architecture/workloads to benchmark • Operational load increase • Too much diversity to fully optimize See Cloudflare’s talk
place compatible • We want to be in a position to switch if we want to Challenges • Work isn’t limited to the infrastructure group; it’s R&D wide What we do • Linux distribution have done the heavy lifting • Iterate. No need to migrate everything (80/20 rule) • Involved end-user via hackathon, 10%, etc. Conclusion • A fair amount of work, but also easier than expected
down, but it is still there • More cores, but also more features • CPU, GPU, NIC are getting more complex Complexity explosion • Modern silicon have a ton of tunable knobs • Power management, security, QOS, observability, etc. Challenges • Size of the team doesn’t increase as fast as silicon scales • Often, too little documentation • Upstream support lagging behind hardware release Conclusion • Need to work to get the best of our hardware See Cloudflare’s talk
• Cause by physical layout of devices (large die and chiplets) • Cores have varying affinity to memory, to PCIe device, etc. Challenges • Situation is more complex than 1 NUMA domain = 1 package • Default configuration → Jitter • Deterministic performance is important for end-users What we do • Careful scheduling of applications/threads to CPU cores • Large performance gains → +20% Conclusion • Need to deeply understand the underlying arch See Booking’s talk
handling should match application placement • Each core should have a dedicated network queue Challenges • NIC may not expose enough hardware queues • Default heuristic do not account well for modern CPU non-uniformity • Default configuration → Jitter What we do • Force modern NIC to expose all hardware queues • Use modern NIC hardware dispatch capabilities (RFS) • Large performance gains → tail latencies flattened Conclusion • Need to deeply understand network devices
95% is automated, the last 5% are difficult • Often, it needs a manual diagnostic and aggregated data sources Challenges • Moving towards longer life time • More complex devices with new failure mode • Dense devices are fewer and so are more precious • False positive/negative becoming more costly • No real standard solution New tools • Self healing capabilities • In-field scanning • Open firmware? See Scaleway’s talk
hardware vendor is hard • Getting it fixed is harder Challenges • Hard to access vendor engineering • Lack of easy-to-use tooling to extract useful information • Documentation under NDA • Bug already fixed by undistributed firmware update What we do • Written report tend to help • Ask vendors to contribute to open-source tools (dmidecode, nvme-cli, etc.) • Prem’day user group Conclusion • Call to vendors to find a model better suited to mid-size scalers See Jean Delvare’s talk
has self-healing diagnostic / procedure • We want to use it Challenges • Vendors do not always expose these features or hide them (eg PPR) • These feature are often not even documented What we do • Ask vendors to enable self-healing features • Ask vendors to contribute to open-source diagnostic tool (MCE decoding) • Automate their use Conclusion • Call to vendors to not hide these features
money • Sending people in datacenter to repair hardware cost money Challenges • Supply chain optimization problem • Vendors are lacking an API mindset • Densification may impact our throughput/latency balance What we do • Automate repair interventions scheduling • Batch repairs in bundles • Pay people to copy-paste data in GUI Conclusion • Would Prem’day members be interested in working with vendors on an OpenRMA API? See Criteo’s lightning
development practices (CI/CD) • No automated distribution pipeline (API) • No changelog, etc. Operational burden • What do I need to update? Is a new version available? • Proprietary update procedure • Difficult to automate tooling Open-source • Better open-source alternative exist (LVFS/fwupd) • Why not use them? Conclusion • Vendors really need to step-up See Richard Hughes talk
be part of an end-to-end SRE pipeline from vendors to clients Challenges • Vendors are not moving into this direction What we would like to see 1. Vendor commit a fix/feature to a firmware 2. This triggers their CI/CD 3. Vendor release a firmware. The CD makes it available to clients 4. Automated system on clients side picks the new update 5. Internal systems on clients trigger CI/CD for the new update 6. CI checks the new update on a test system 7. CD progressively rollout the new update on affected system Conclusion • Hardware vendors should move in this direction
data of interest • Large infrastructure is a tempting target Adtech specific market trends • Regulation is evolving • Google Privacy Sandbox (TEE) Challenges • Security is hard and needs continuous investment • Security is often the third wheel Conclusion • We need to collectively step-up
and audit main firmware • Specific mention for network attached devices (BMC) Challenges • Vendors are slow to embrace the subject • We want to own the root of trust (transfer of ownership) What we do • Run Sonic on our Network switches • Testing OpenBMC • Engage with vendors on the subject Conclusion • Call to vendors to move forward on this See OSF’s talk See Criteo’s lightning
working only with companies that offer and support open-source software We want to improve things for everyone If ideas and processes can help similar actors, we are happy to share mostly everything. We want privileged access to engineering Support starts at L3+ We want everything to be automation-ready Infra-as-code approach, usually via API We question spec sheets and put promises to the test NDA level data sheets >> marketing presentations We want to see what the future holds Knowledge is key when planning months/years ahead. Best would be to contribute to designs & roadmaps. We want to use our assets for as long as possible 5-year strict minimum. 7 to 9-year is our target We consider all costs TCO is key (power consumption, performance, cost, long-term support,…). We truly care about our environmental footprint Given similar products, environmental impact would be a strong tie-breaker. Openness Expertise Efficiency orientation https://github.com/criteo/hardware-manifesto
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}