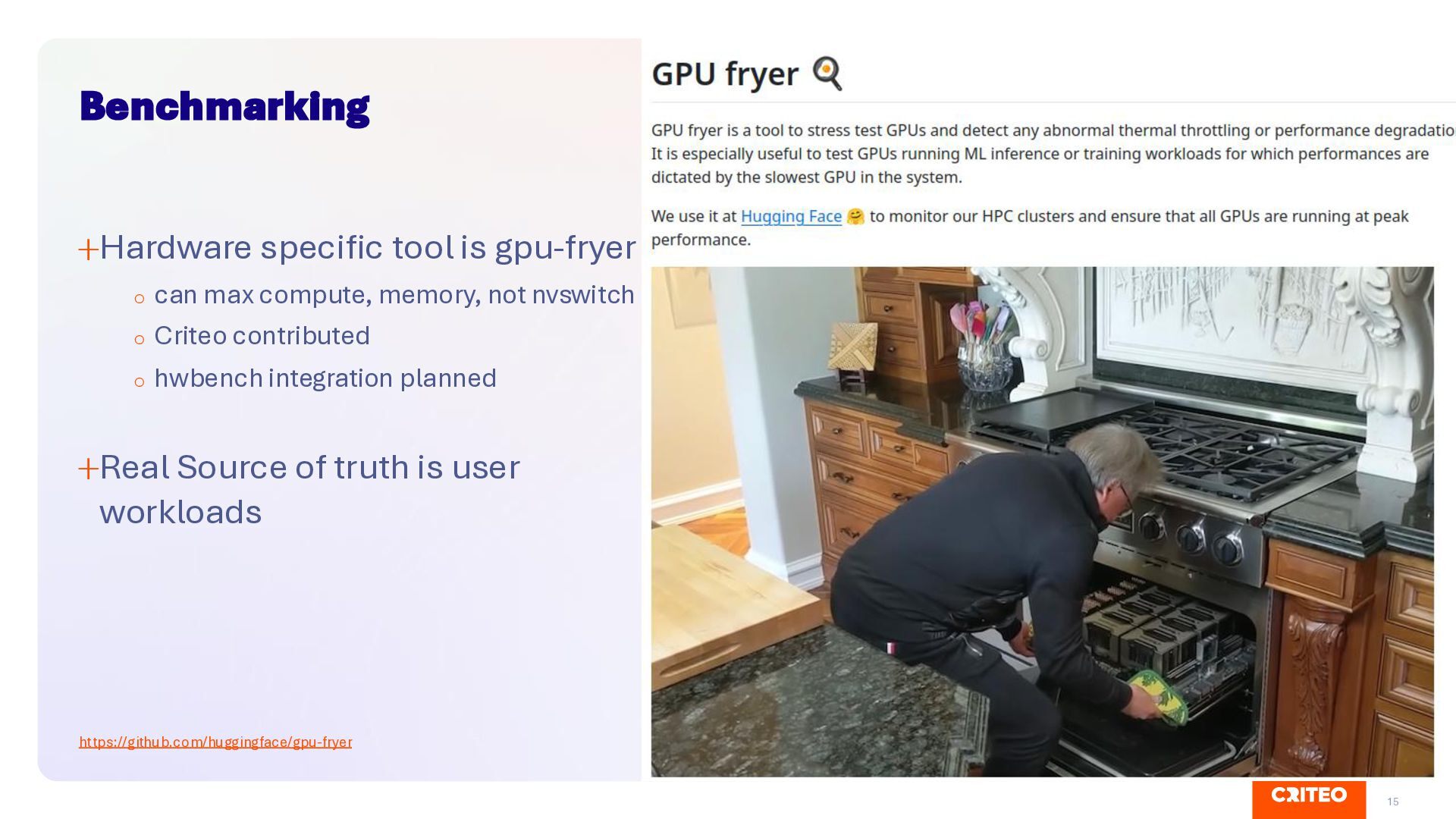
compute, memory, not nvswitch o Criteo contributed o hwbench integration planned Real Source of truth is user workloads https://github.com/huggingface/gpu-fryer
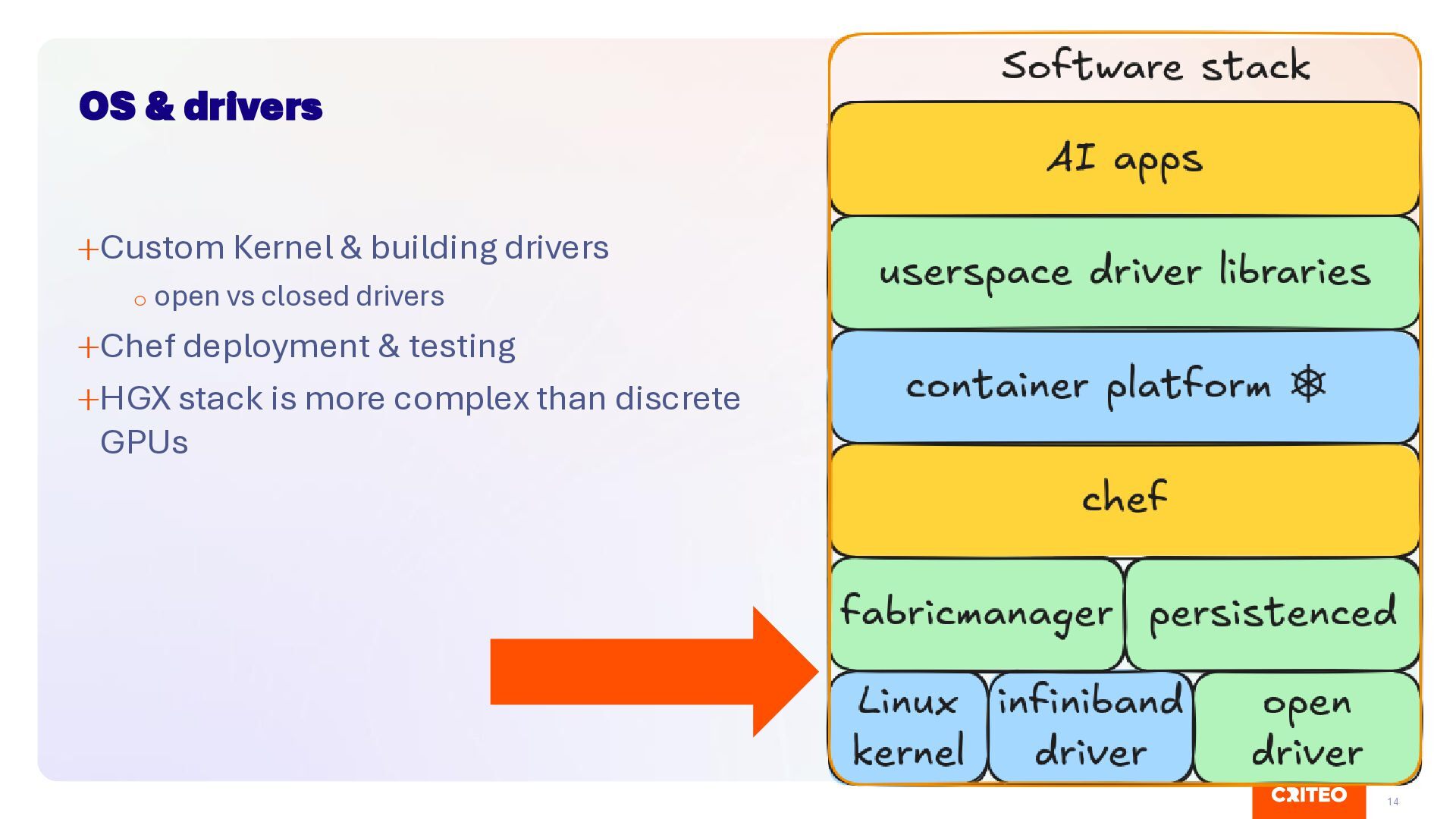
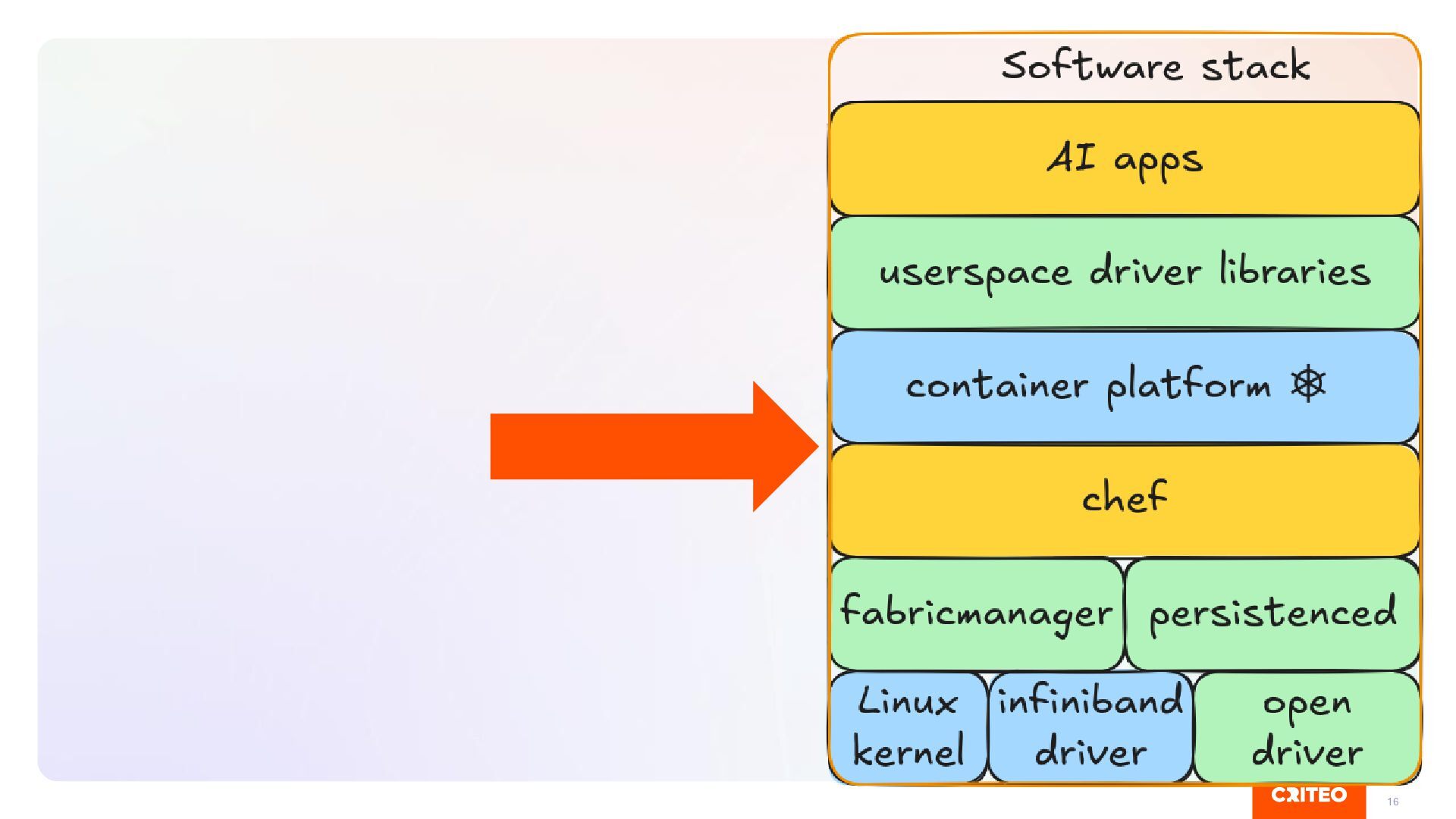
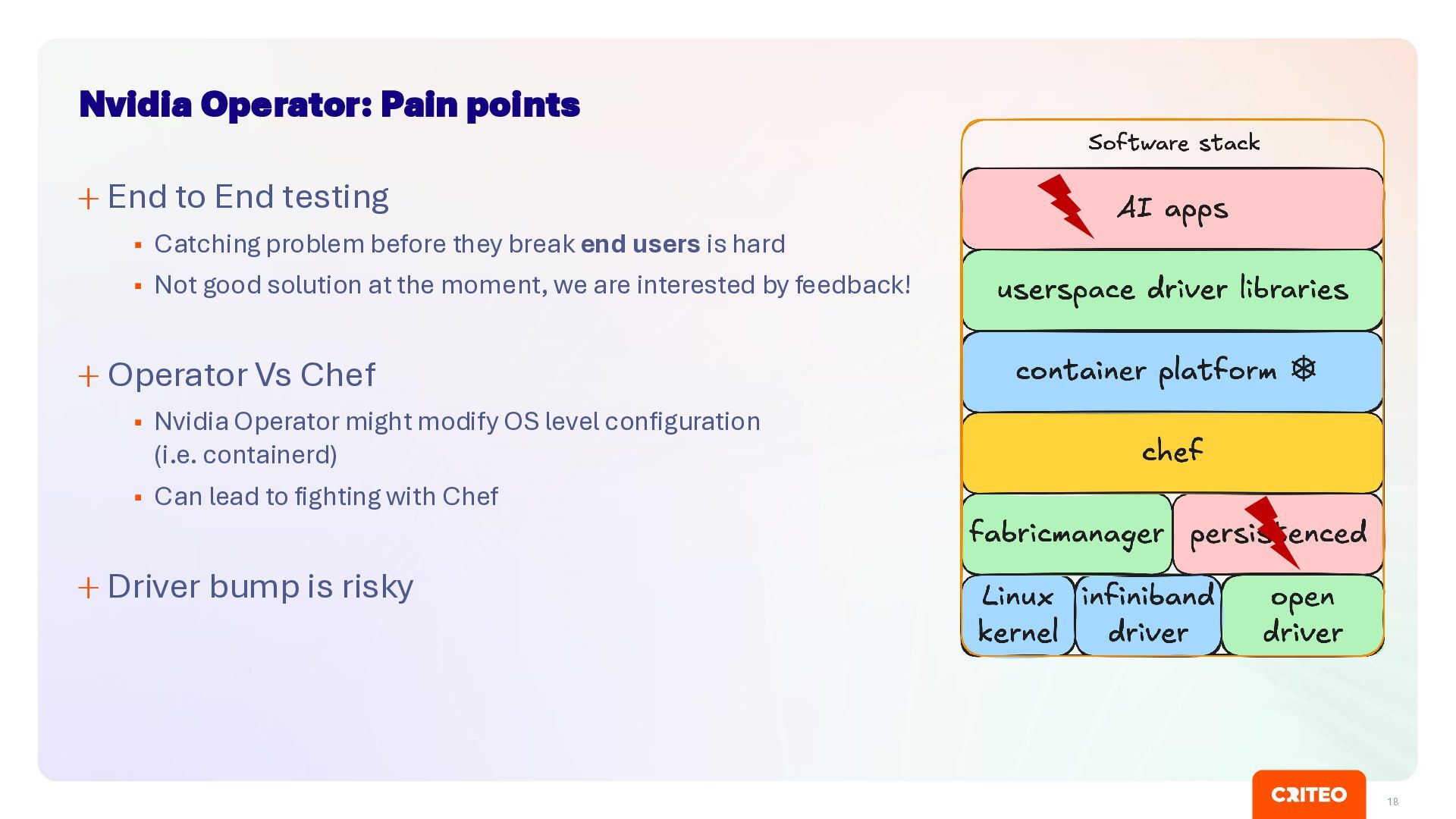
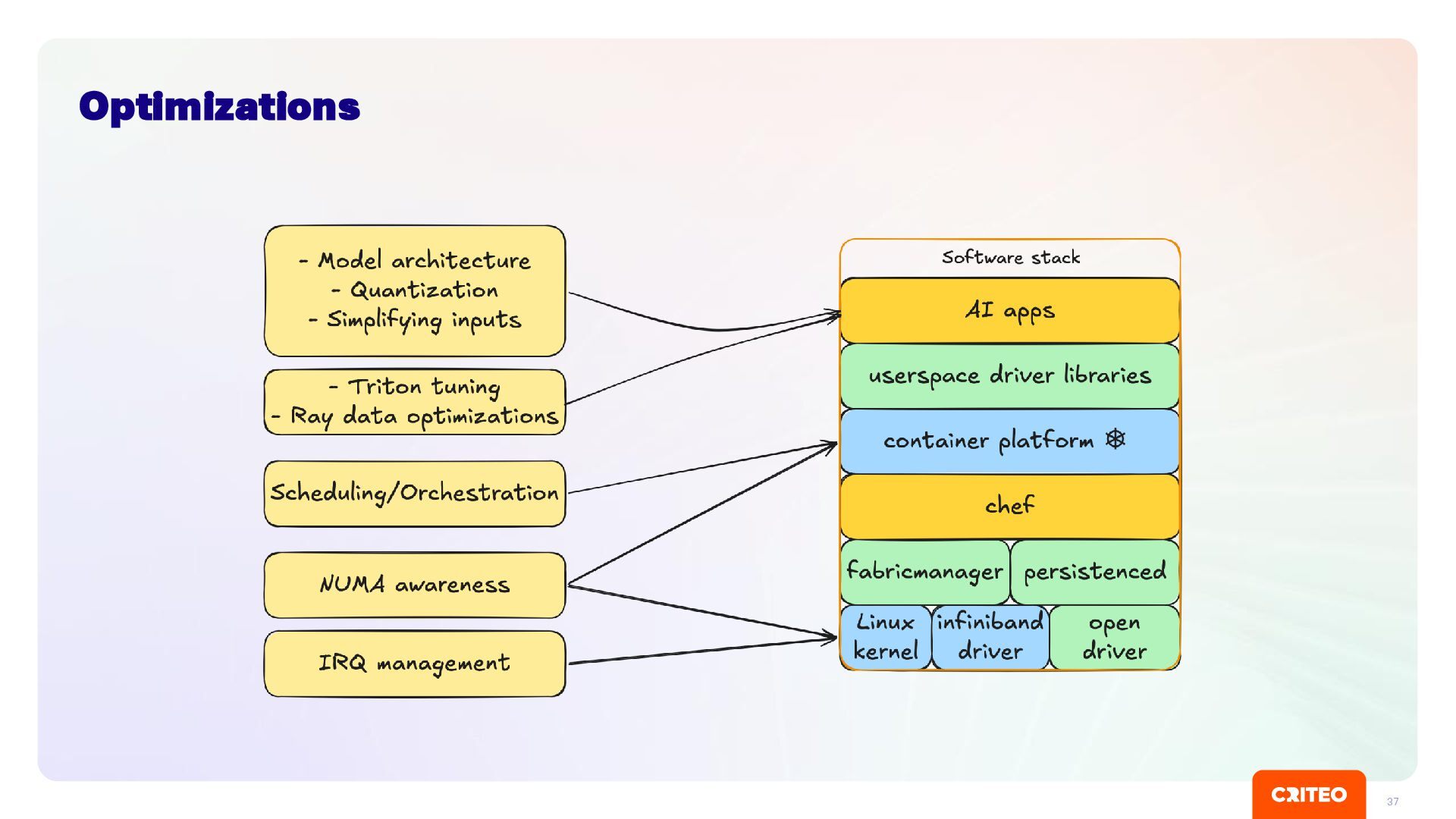
Catching problem before they break end users is hard ▪ Not good solution at the moment, we are interested by feedback! Operator Vs Chef ▪ Nvidia Operator might modify OS level configuration (i.e. containerd) ▪ Can lead to fighting with Chef Driver bump is risky
second per datacenter Focused on prediction and recommendation (deep tabular) Small models = less compute = more scale and better latency Moving from traditional on-CPU ML to Deep Learning/AI LLMs have a minor footprint (at the moment)
are written in Python • Executed on a Ray cluster • Great integration with • Highly flexible core with dedicated libs: • Training • LLM fine tuning • Data/Batch Inference • Hyperparameter Tuning • Model serving (not used at Criteo) https://github.com/ray-project/ray
GPUs vs 4 workers with 1 GPU ▪ GPUs on a single nodes are more efficient ▪ More GPUs per workers = harder to schedule ▪ Scheduler can be configured for density/bin-packing
Can be called from different languages • And on different hardware • Some ways to package models: • Pure python package • ONNX • Executorch • LLM: Safetensors/GGUF
associated weights/parameters • Portable: • Easy to run from any language/stack • Can use different hardware: • Either as direct providers • Or ”transpilation” to another format • JIT optimizations of the graph • Multiple compute providers within a single execution • e.g CPU/Cuda/TensorRT
architecture and business performance SE/SRE Engineers more focused on low level performance and serving Testing new hardware (and new vendor) in days instead of weeks/months
of backends including Python, ONNX, TensorRT • Provide a server side batching scheduler • We also batch on client side • Triton tends to be the bottleneck https://github.com/triton-inference-server/server
• It is becoming harder to saturate the GPU with a single models • Mixing models with different owners and different usage is not easy (isolation, lifecycle, etc) • With Nvidia: Multi-Instance GPU (MIG) • Allow splitting a GPU in slices (RTX6000 up to 4 quarters, B200 up to 7)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}