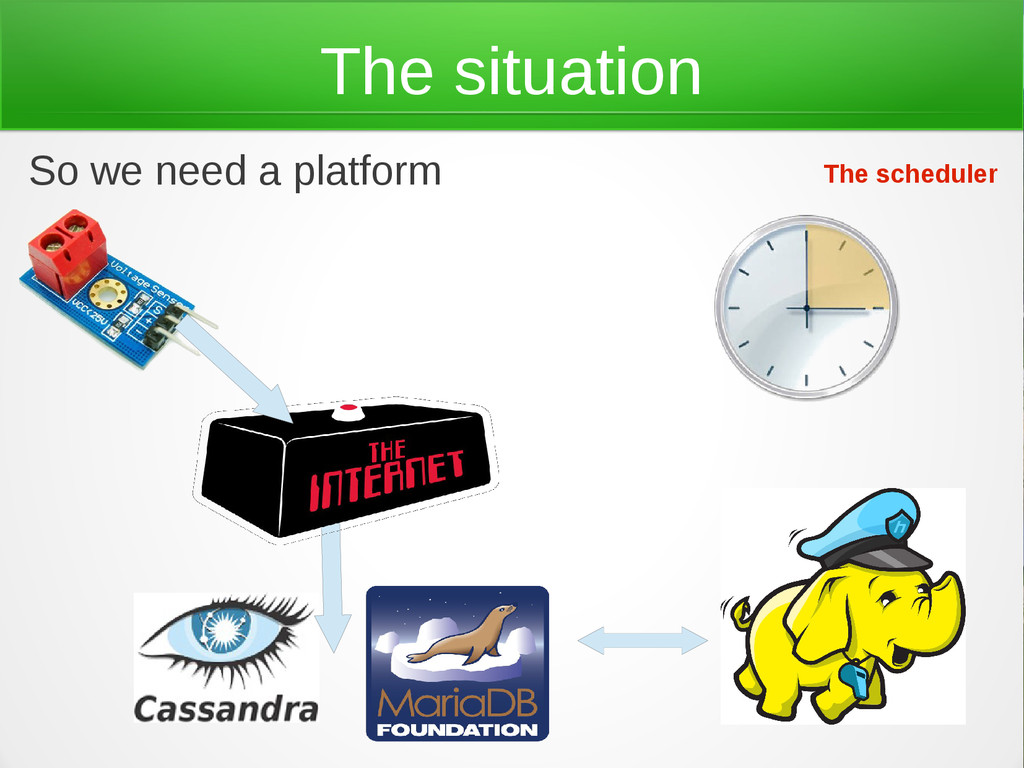
example in Templin, the north of Berlin, DE. - 214 hectares - 1.500.000 photovoltaic modules - 128.48 MW - 205 millions Euro - • We need to get inside knowledge about the installation, cause we want to know: - If everything is working properly - better ways to produce the energy The situation
Hadoop jobs, PIG scripts and/or shell scripts. • Have a REST API. • Support workflow, but also cron alike jobs. • Be able to run jobs on demand. • Be able to track running jobs. • Provide live statistics about the running jobs.
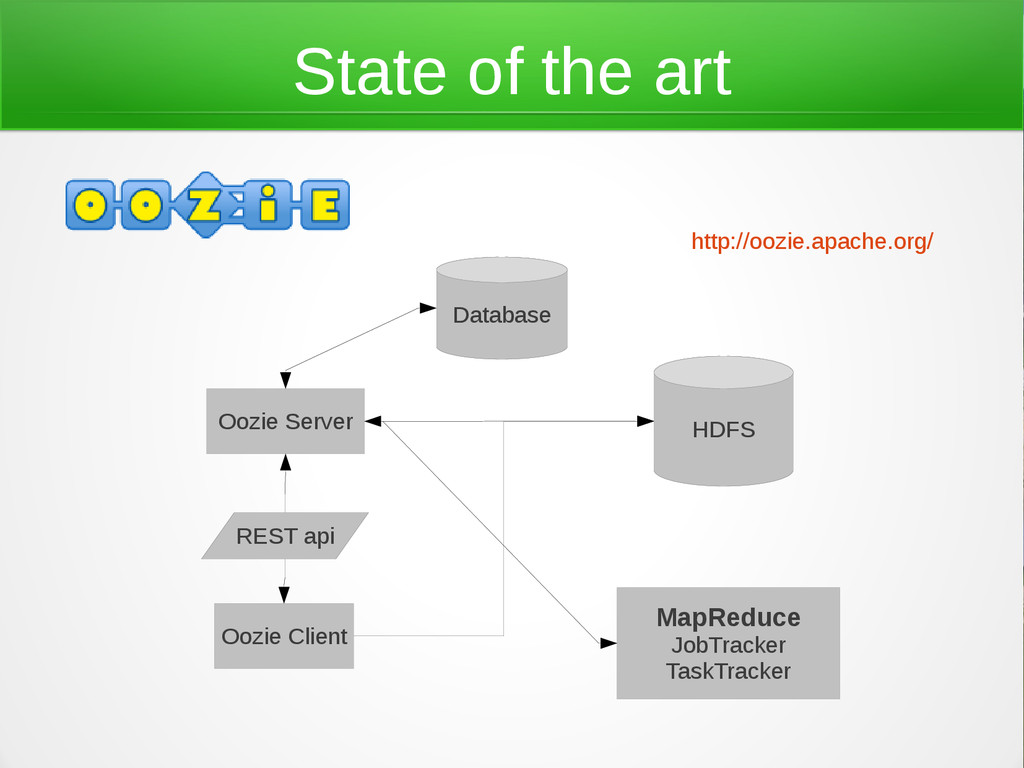
use Oozie, because: - Has a great community and features. - Integrated with the common Hadoop tooling - Has a good documentation. but - XML based configuration. - Scheduling based on map tasks. - Complicated setup. - Confusing object model. - Lack of Java experience.
configuration and deployment methods ii.Easy to interact with throw a REST interface iii.Deal with workflow and cron alike jobs iv.Have a centralized logging infrastructure v.Use not just Hadoop tooling, but also “scripts” vi.Easy to extends, maintain and adapt to our needs and wishes
Little team, highly distributed. - Diverse knowledge base, mostly C# and Microsoft technologies but a few with Java and Ruby skills. - Lots of ops but just a few devs. - Experience with data and databases. - In a not really technically wise ecosystem. - Highly changing environment.
'cause it also helps with concurrency, memory management, might be speed, Java integration, etc. From Neo4j we borrow the graph features, so we can deal with a workflow (DAG graph) in a more easy way. Sinatra is our man for the REST api. But we need also to track out service evolution, for this we use Redis.
use scheduler that: - Run Hadoop Jobs, PIG and shell scripts. - Track the job evolution and most of the errors. - Support workflow and cron alike jobs. - Provide a simple interface for clients. - Deploy new jobs.
![Ein einfacher scheduler for hadoop Pere UrbonBayes [email protected] http://www.purbon.com](https://files.speakerdeck.com/presentations/6f7377407175013163183abcd19aa7e9/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
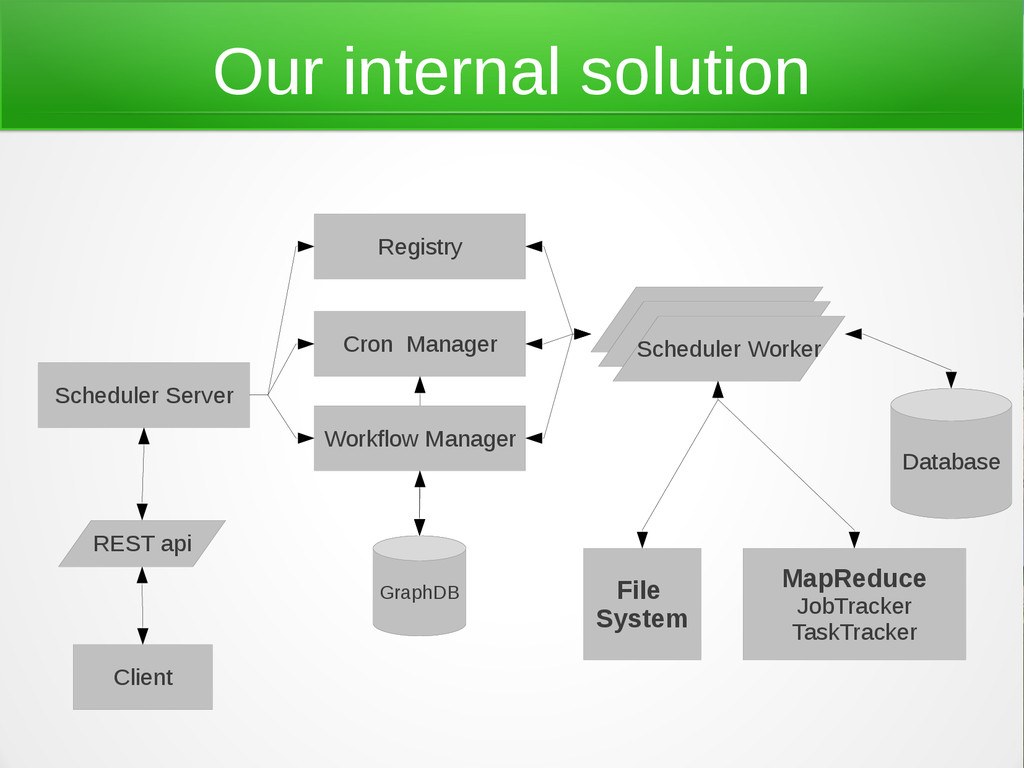{kind=link}
{kind=link}
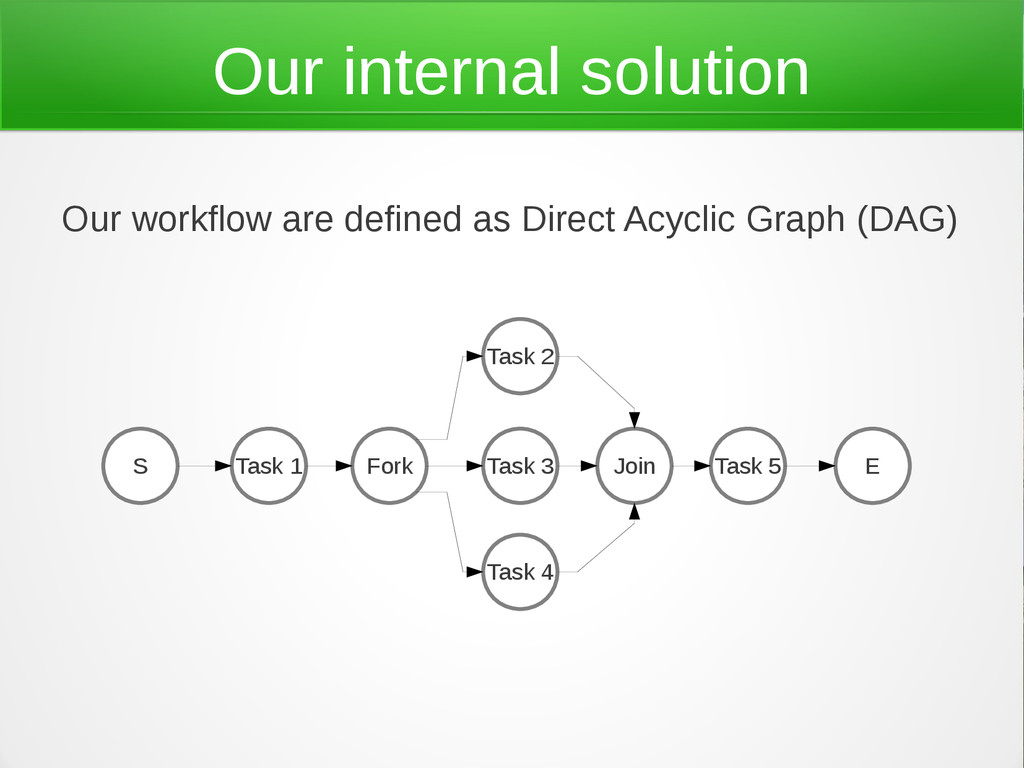{kind=link}
{kind=link}
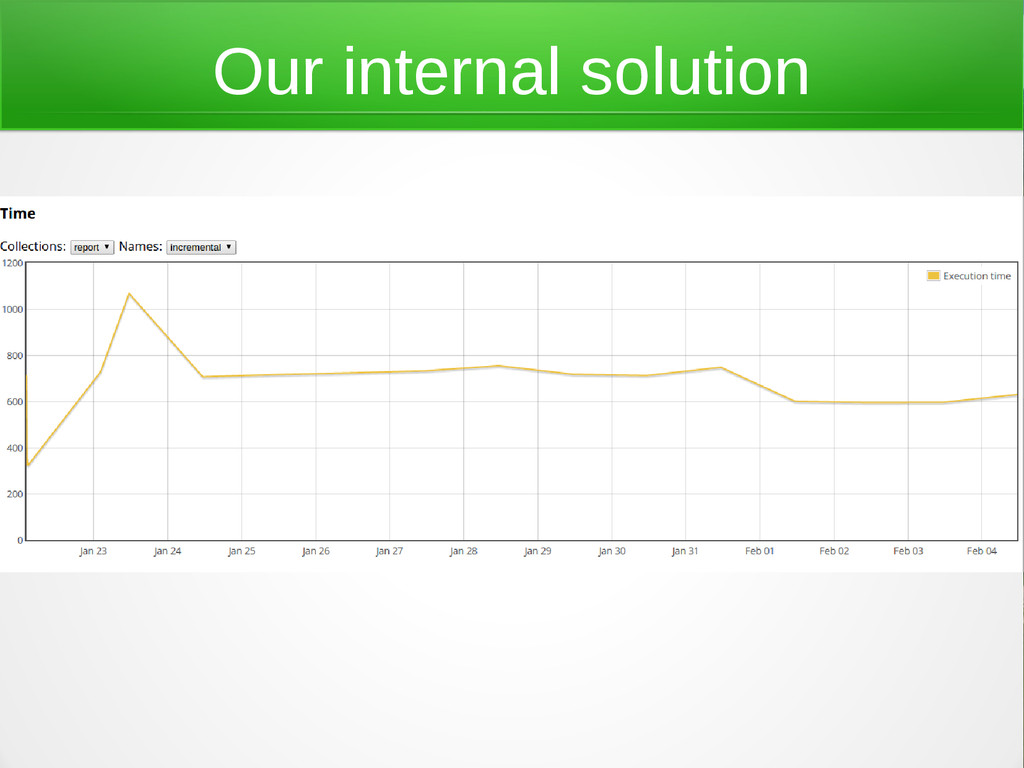{kind=link}
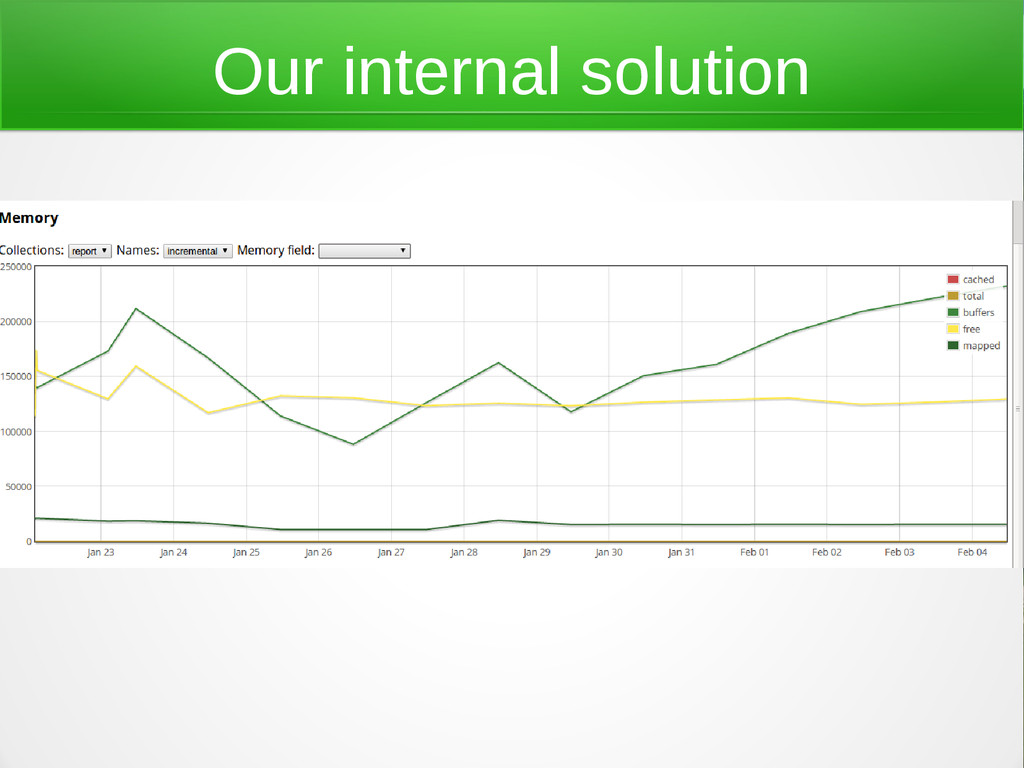{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}