2. A major structural trend in financial data — ESG 3. Creating an ESG dataset from scratch with spaCy, BERT, and active learning 4. Why S&P Global is a great place for NLP practitioners
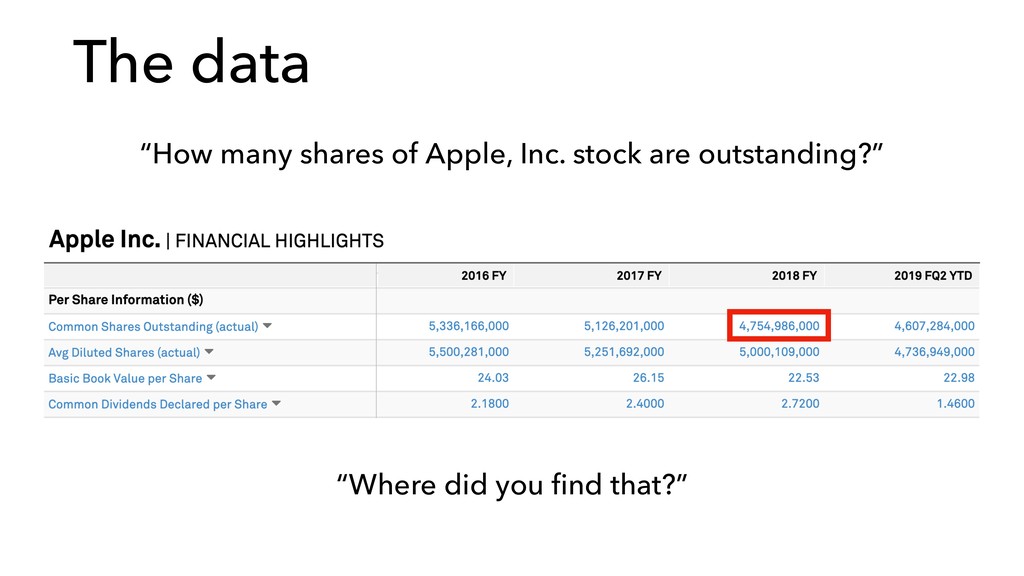
“100% precision, 100% recall rule” • If there is a fact in the public domain and it falls within the scope of S&P’s information coverage, typically we guarantee: • That fact will be in our datasets, and • the data will be correct • If you find an example where data is missing or incorrect, we will send you $50
commitment to reduce or eliminate deforestation from its business operations? • Does the company disclose the investments it is making, if any, to promote sustainable water use in its business operations? • Does the company have standards in place to prohibit child labor practices in its business operations? In its supply chain? • Has this company made a public commitment regarding animal welfare practices? • Is the CEO’s compensation linked to company performance on sustainability metrics? • Does the company have targets in place for diversity and inclusion in its workforce? • … (hundreds more) • This data is really hard to get today!
Typically regulated Typically unregulated (for now) Disclosure is mandatory Disclosure is voluntary, non-disclosure is common Companies report similar metrics Companies report a variety of metrics, or no metrics Reported in standard formats Companies report data in various formats and channels Reported at predictable times Companies may report whenever they like
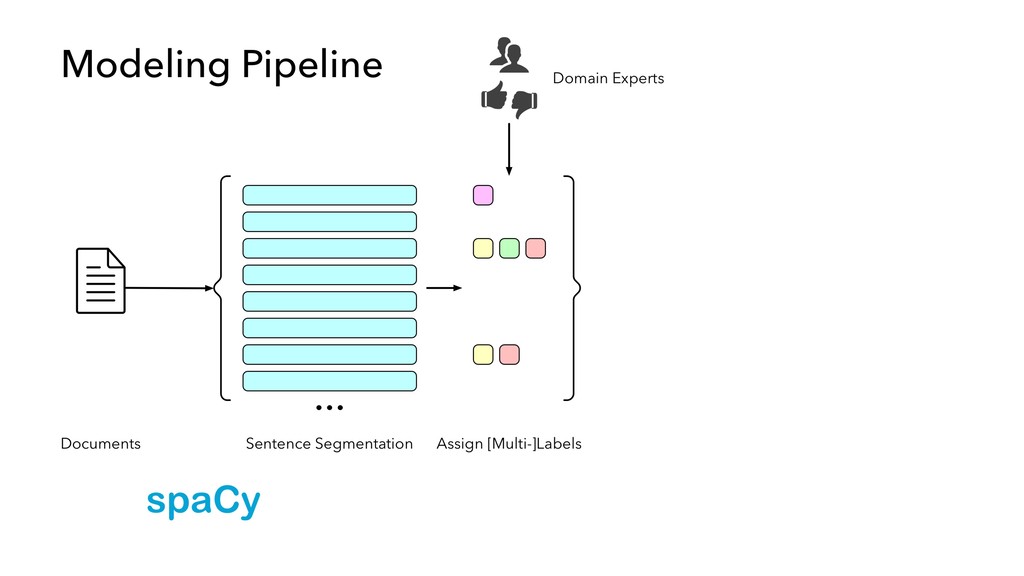
text that contain relevant evidence for a company’s ESG attributes… • …which may or may not be disclosed anywhere • …for hundreds of ESG attributes • …from a variety of document or web sources • …across thousands of companies • …and system accuracy has to be 100%.
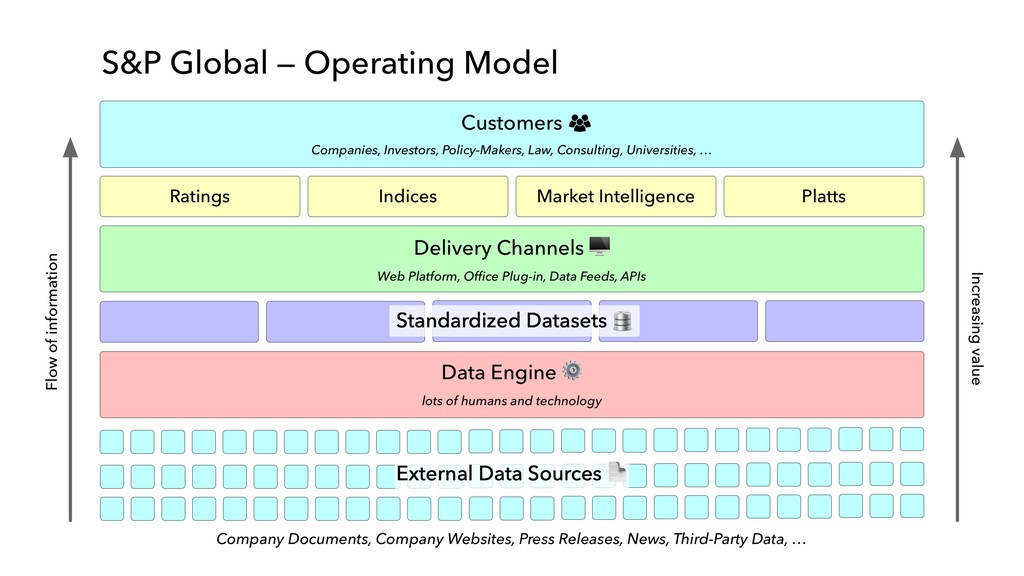
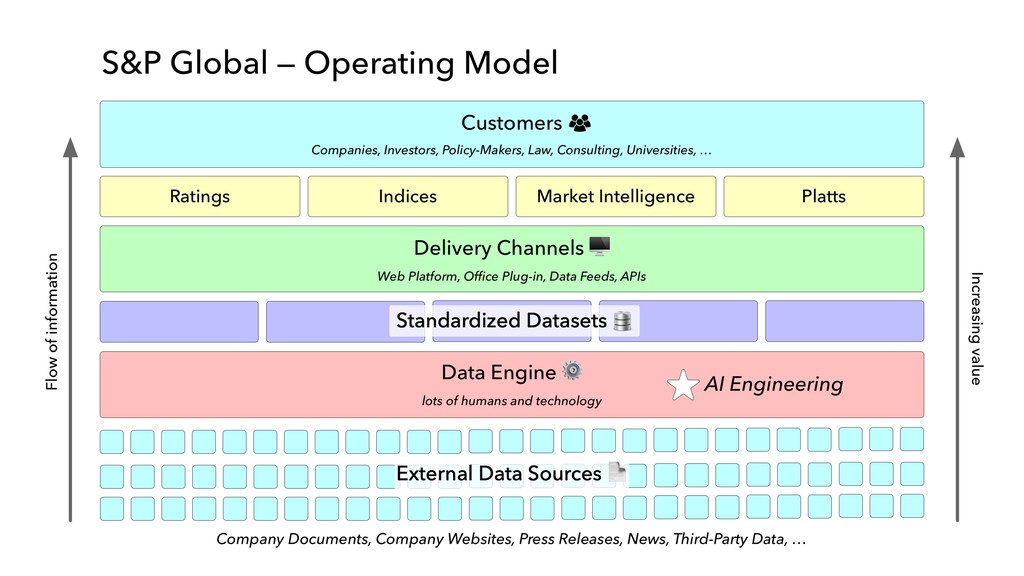
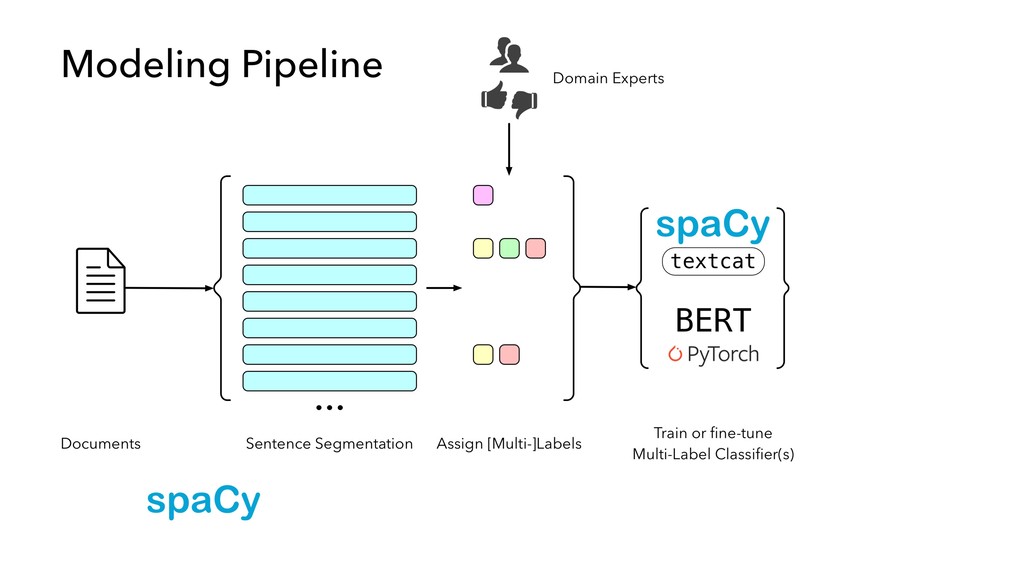
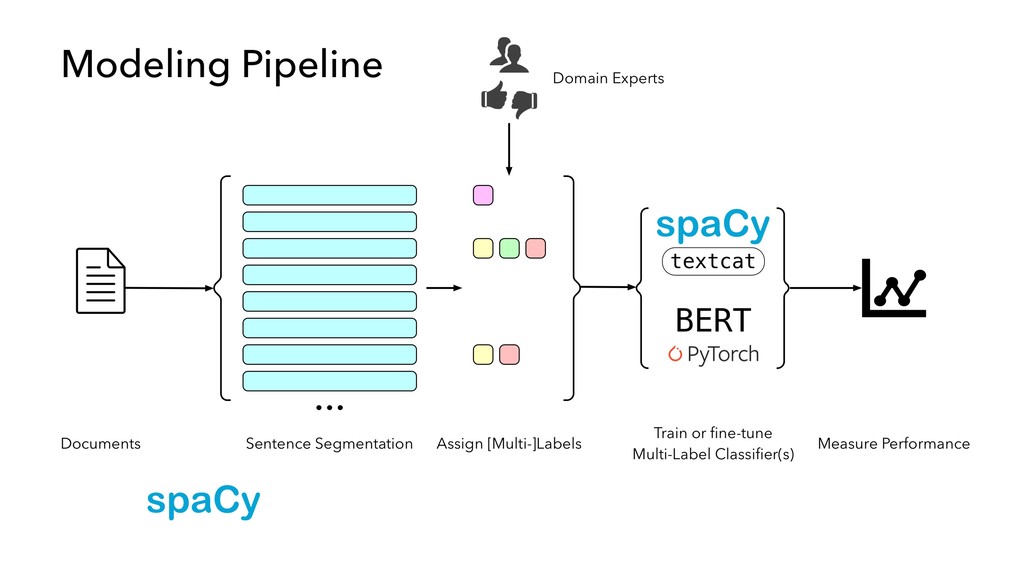
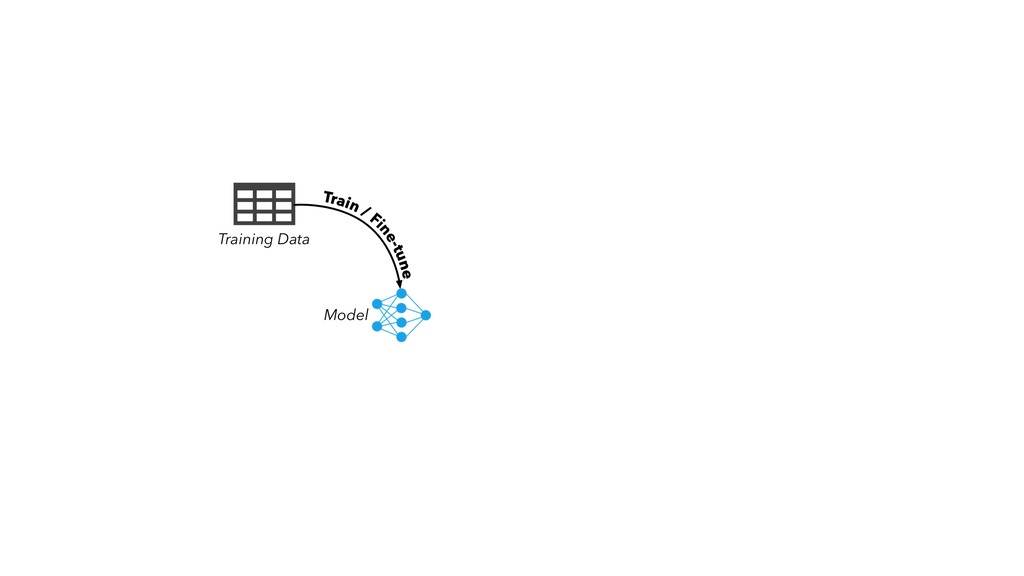
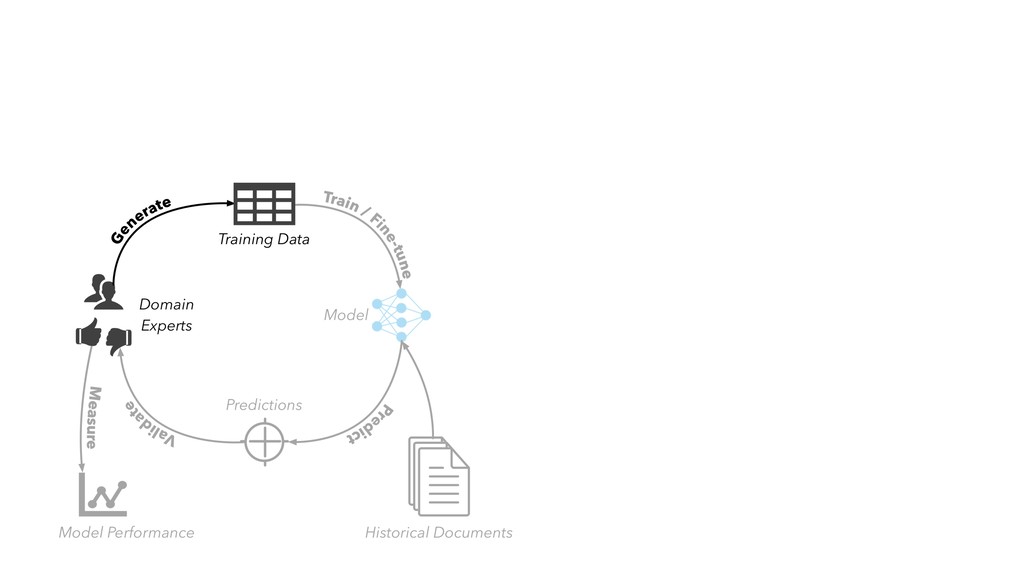
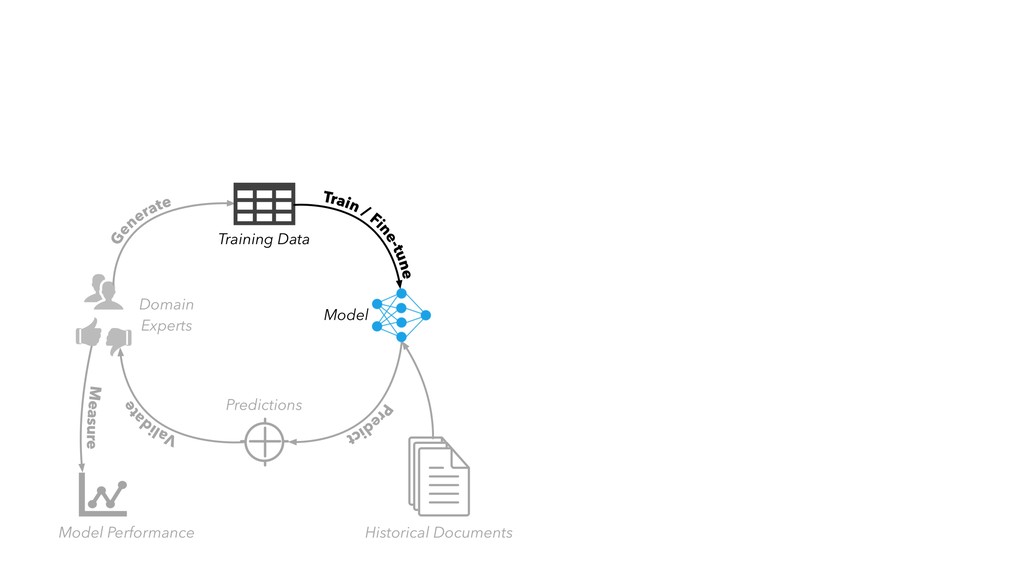
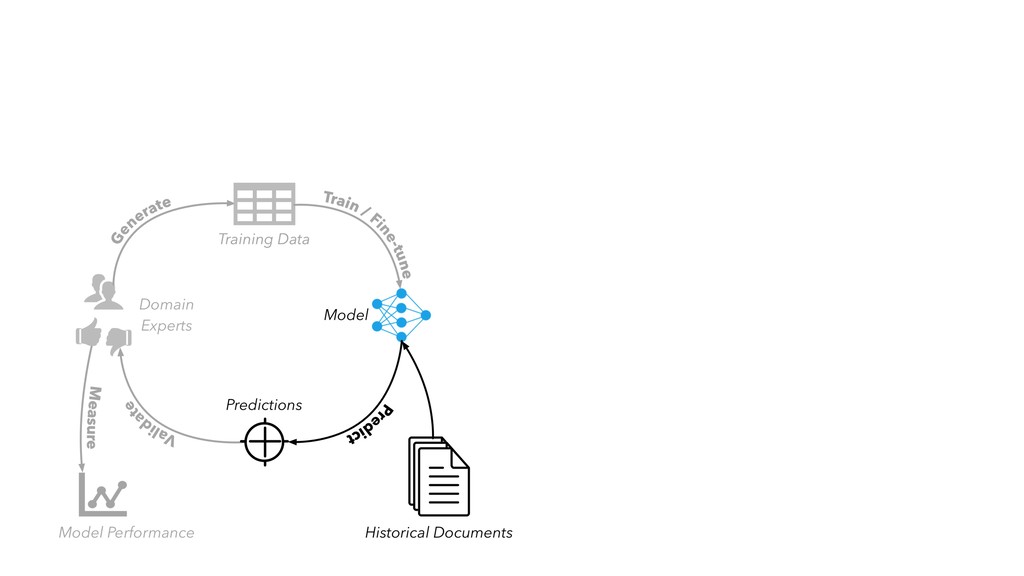
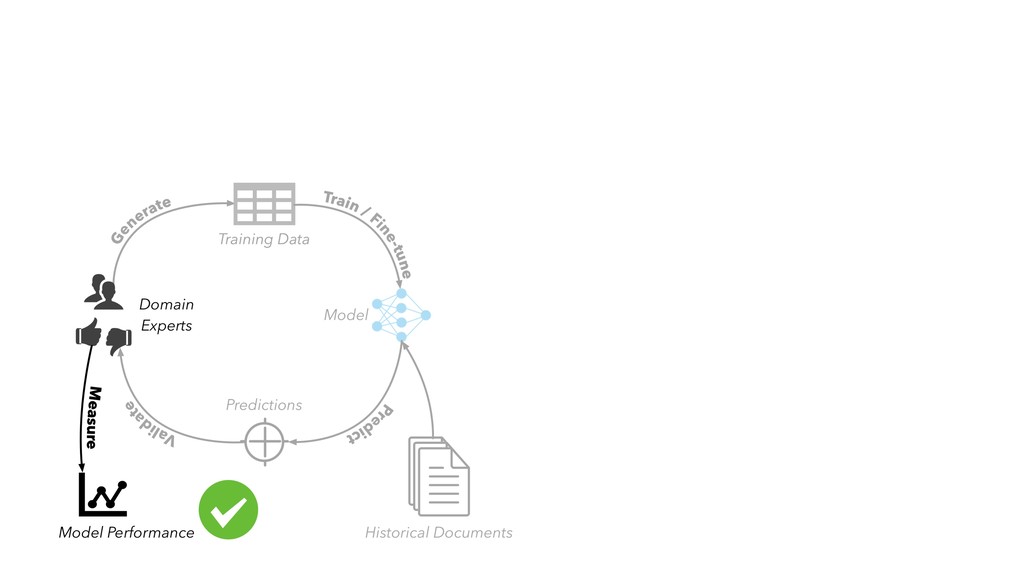
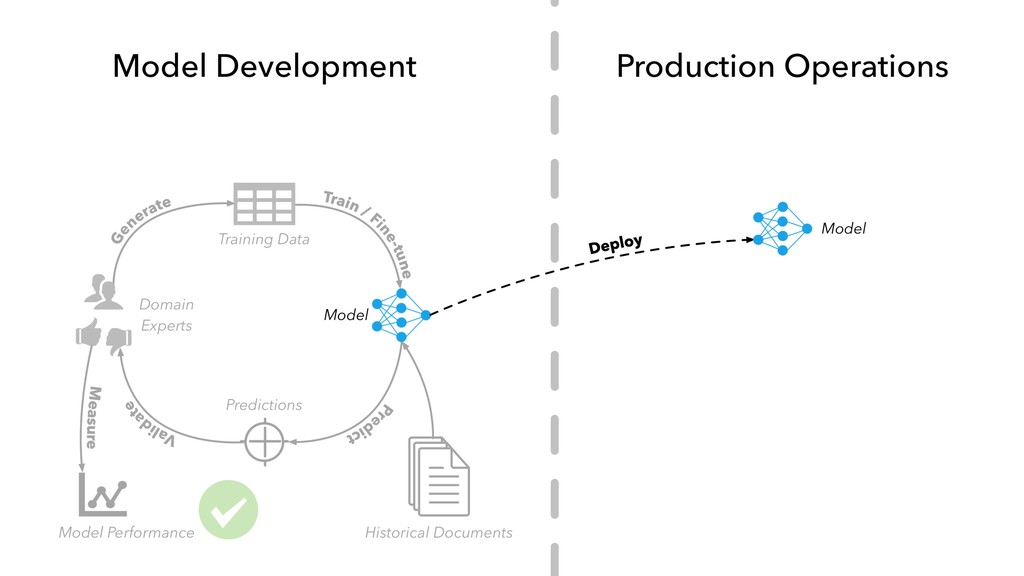
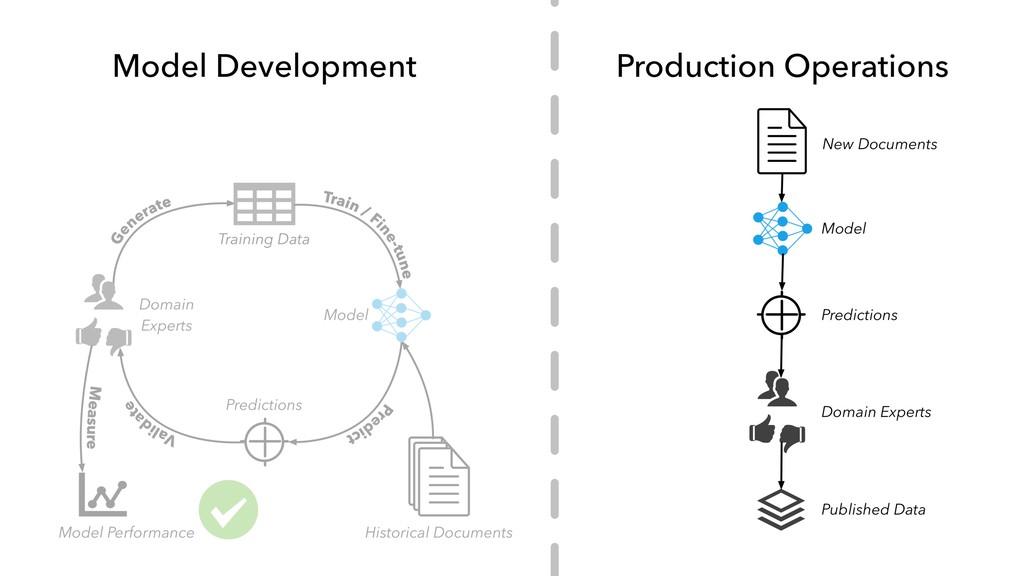
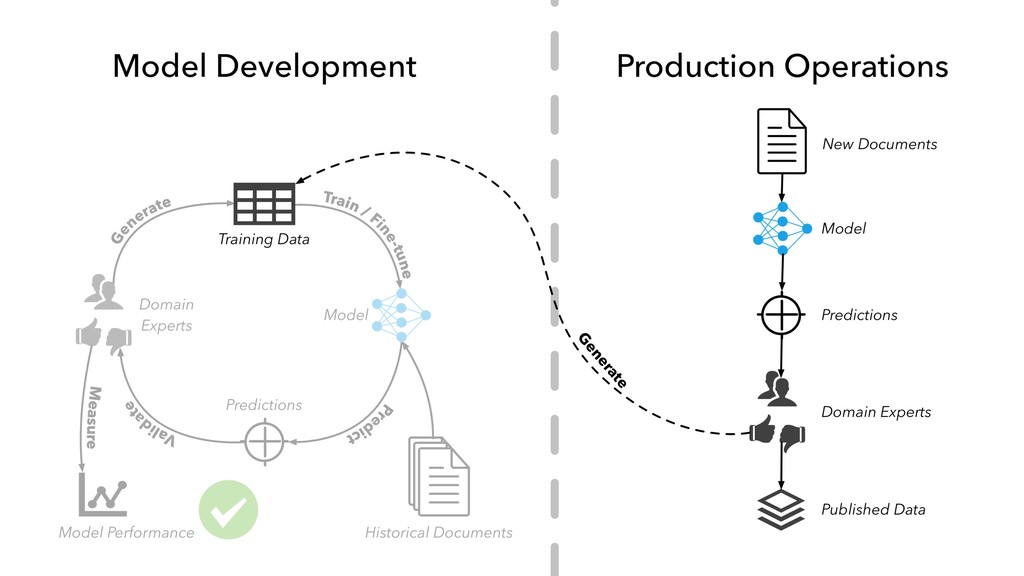
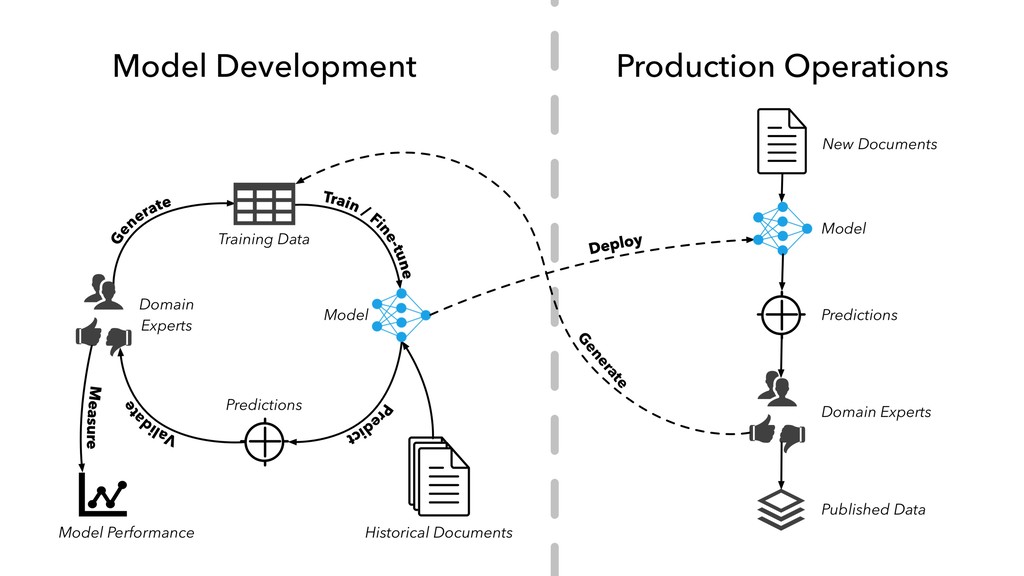
in “internal production” as S&P Global builds out its ESG dataset across thousands of companies • Members of our AI Engineering group build and maintain models, workflow tools, and infrastructure that make the active learning model development lifecycle and production workflow possible
work with hundreds of millions of professionally-produced documents • Enough text data to do some really interesting things, like creating customized word embedding and pre-trained language models for the financial services domain
subject-matter experts on staff who can assist with annotating data — no crowd-sourcing required • The data-first mindset — as a data company, we have a lot of people who have been thinking hard about the storage, management, and quality of data for a long time
operations of our business • The business opportunity for NLP is large and direct • Lots of internal and external customers really care about the results of your work
wins • It’s the end-to-end system that provides value in a specific business context, potentially including human-machine collaboration • We are hiring • A big thank you to the folks at Explosion and the rest of the Python data science ecosystem! [email protected]
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}