we’d like to say congratulations to Rainer Weiss, Barry C. Barish, Kip S. Thorne and the rest of the LIGO and VIRGO teams for the Nobel Prize in Physics 2017. Since 2015, the LIGO and VIRGO Collaborations have observed multiple instances of gravitational waves due to colliding black holes (and more recently neutron stars). These observations represent decades of work and confirm what Einstein had theorized a hundred years ago. ... To communicate to the broader community, the LIGO/VIRGO Collaboration has created tutorials with Jupyter Notebooks that describe how to use LIGO/ VIRGO data and reproduce analyses related to their academic publications.
Jupyter has been awarded the 2017 ACM Software System Award, a significant honor for the project. We are humbled to join an illustrious list of projects that contains major highlights of computing history, including Unix, TeX, S (R’s predecessor), the Web, Mosaic, Java, INGRES (modern databases) and more.
than using traditional programming tools... ...this is a big surprise, since I have coded nearly every day for over 30 years, and in that time have tried dozens of tools, libraries, and systems for building programs." Source: https://www.fast.ai/2019/12/02/nbdev/
than using traditional programming tools... ...this is a big surprise, since I have coded nearly every day for over 30 years, and in that time have tried dozens of tools, libraries, and systems for building programs." Source: https://www.fast.ai/2019/12/02/nbdev/ — Jeremy Howard, fast.ai
How will we collaborate effectively? How can we share and reuse this code? How do we apply our code quality standards? How do we test this code? Will this work with our continuous integration system?
How will we collaborate effectively? How can we share and reuse this code? How do we apply our code quality standards? How do we test this code? Will this work with our continuous integration system? How do we schedule and trigger automatic execution?
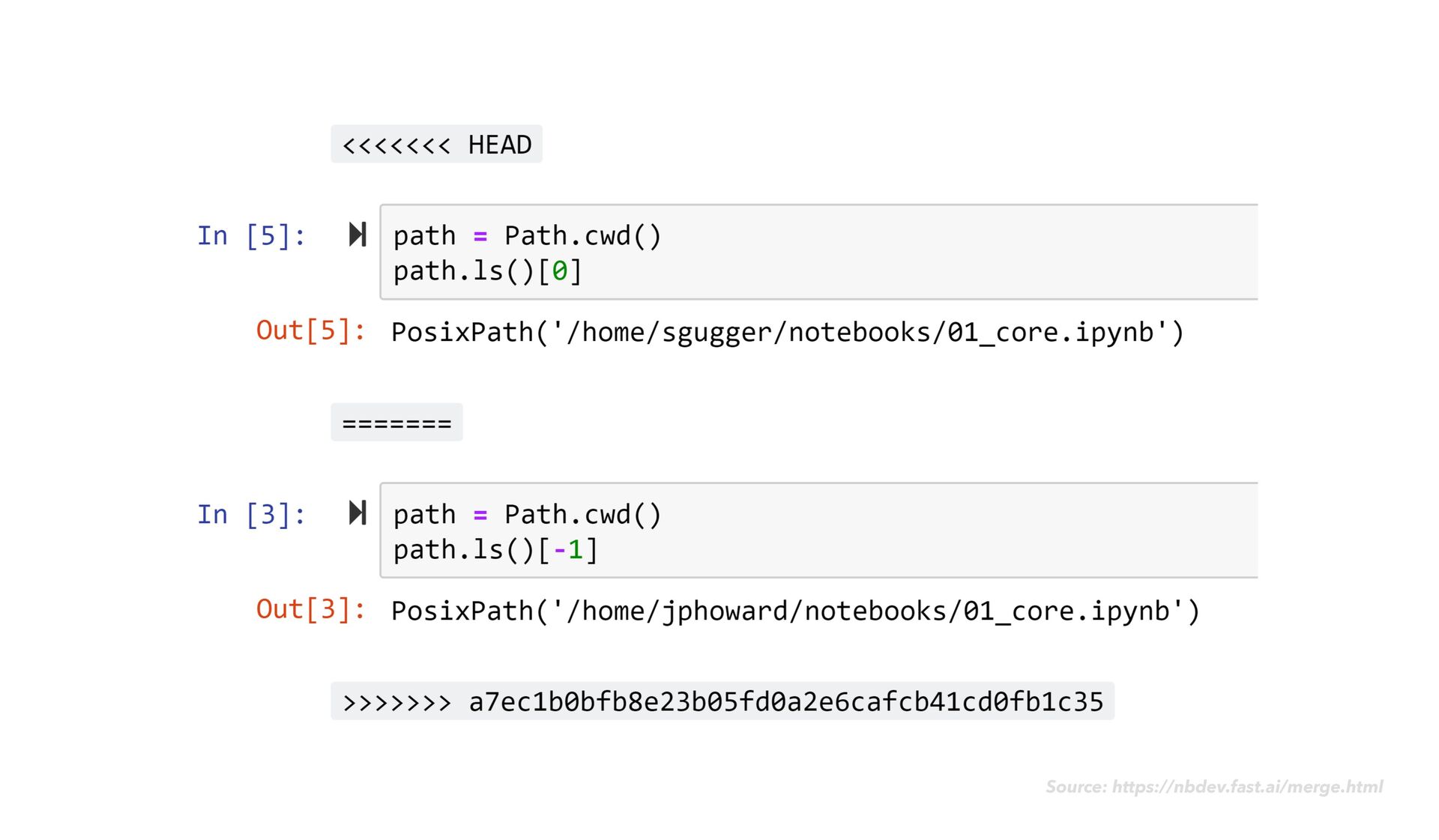
How will we collaborate effectively? How can we share and reuse this code? How do we apply our code quality standards? How do we test this code? Will this work with our continuous integration system? How do we schedule and trigger automatic execution? Out-of-order cell execution!
How will we collaborate effectively? How can we share and reuse this code? How do we apply our code quality standards? How do we test this code? Will this work with our continuous integration system? How do we schedule and trigger automatic execution? Out-of-order cell execution! ...
to reimplement this code as proper software libraries, ... subject to our company-wide software engineering standards, How should we get this work into production?
to reimplement this code as proper software libraries, ... subject to our company-wide software engineering standards, ... with reimplemented tests using our company's preferred testing framework, How should we get this work into production?
to reimplement this code as proper software libraries, ... subject to our company-wide software engineering standards, ... with reimplemented tests using our company's preferred testing framework, ... using our preferred enterprise continuous integration system, How should we get this work into production?
to reimplement this code as proper software libraries, ... subject to our company-wide software engineering standards, ... with reimplemented tests using our company's preferred testing framework, ... using our preferred enterprise continuous integration system, ... and deploy to our preferred enterprise artifact repository. How should we get this work into production?
to need to reimplement this logic as data pipelines in our preferred enterprise data pipeline framework, ... which has its own engineering practices and conventions, How should we get this work into production?
to need to reimplement this logic as data pipelines in our preferred enterprise data pipeline framework, ... which has its own engineering practices and conventions, ... and may not even use the same programming language. How should we get this work into production?
reimplement the model as a web service, ... wrap it in a Docker container, ... store it in our preferred enterprise container registry, How should we get this work into production?
reimplement the model as a web service, ... wrap it in a Docker container, ... store it in our preferred enterprise container registry, ... and deploy it to our preferred enterprise container orchestration platform. How should we get this work into production?
to need to reimplement these reports in our preferred enterprise business intelligence platform, ... which has its own engineering practices and conventions, How should we get this work into production?
to need to reimplement these reports in our preferred enterprise business intelligence platform, ... which has its own engineering practices and conventions, ... and may not even use the same programming language. How should we get this work into production?
our work in production, either: 1. Our data science teams have to be stacked with unicorns, or 2. We have to loop in a bunch of other teams and create dependencies between them
side effects including increased complexity, elongated timelines, unhappy stakeholders, frustrated data scientists, increased risk of project cancelation, and loss of data science team credibility.
fastai • Initialize your git repository as an nbdev project: nbdev_new (Or, copy the of fi cial nbdev template repo on GitHub) • Install the nbdev git hooks: nbdev_install_git_hooks nbdev
fastai • Initialize your git repository as an nbdev project: nbdev_new (Or, copy the of fi cial nbdev template repo on GitHub) • Install the nbdev git hooks: nbdev_install_git_hooks • Enter some basic project information in settings.ini nbdev
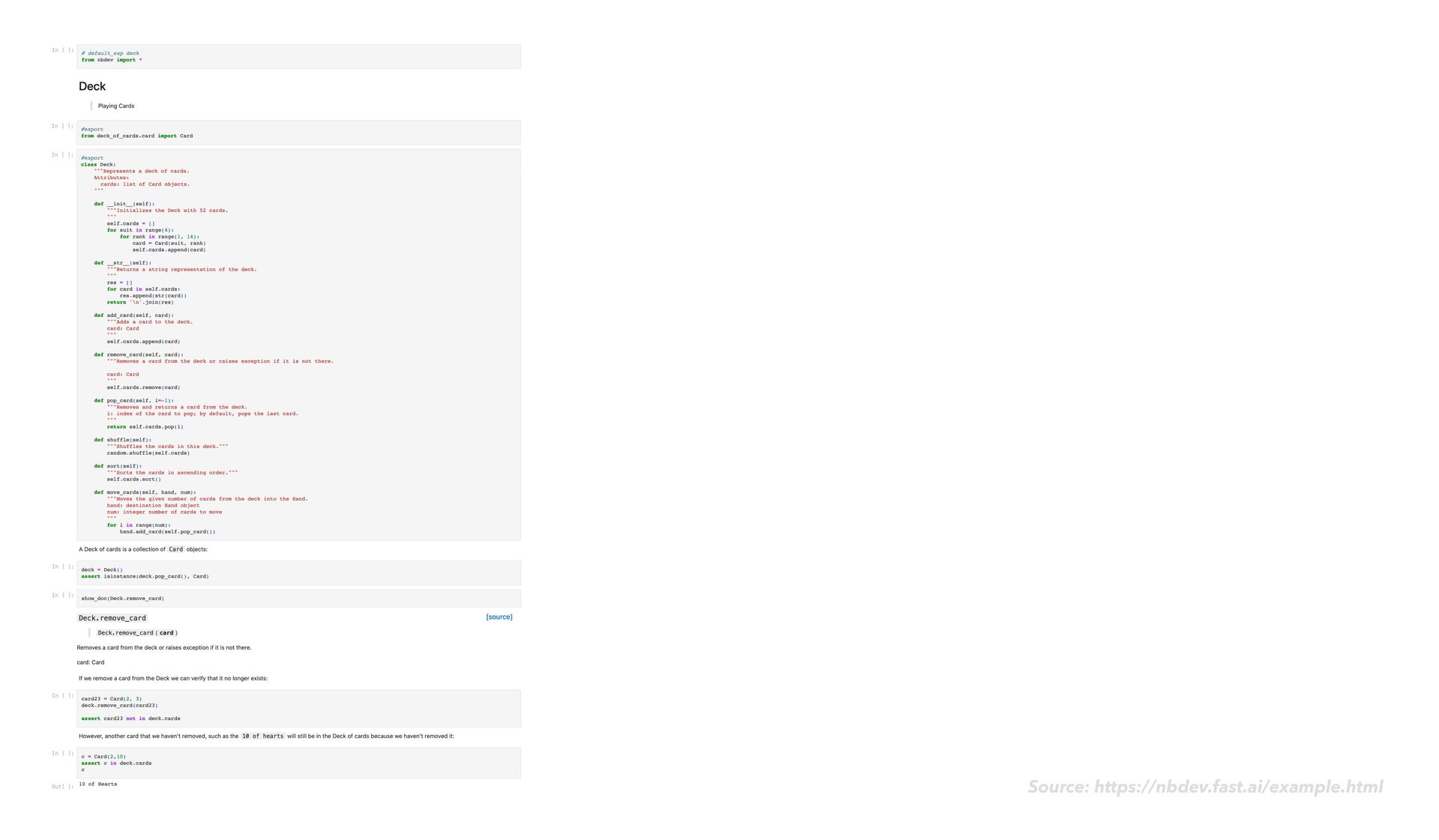
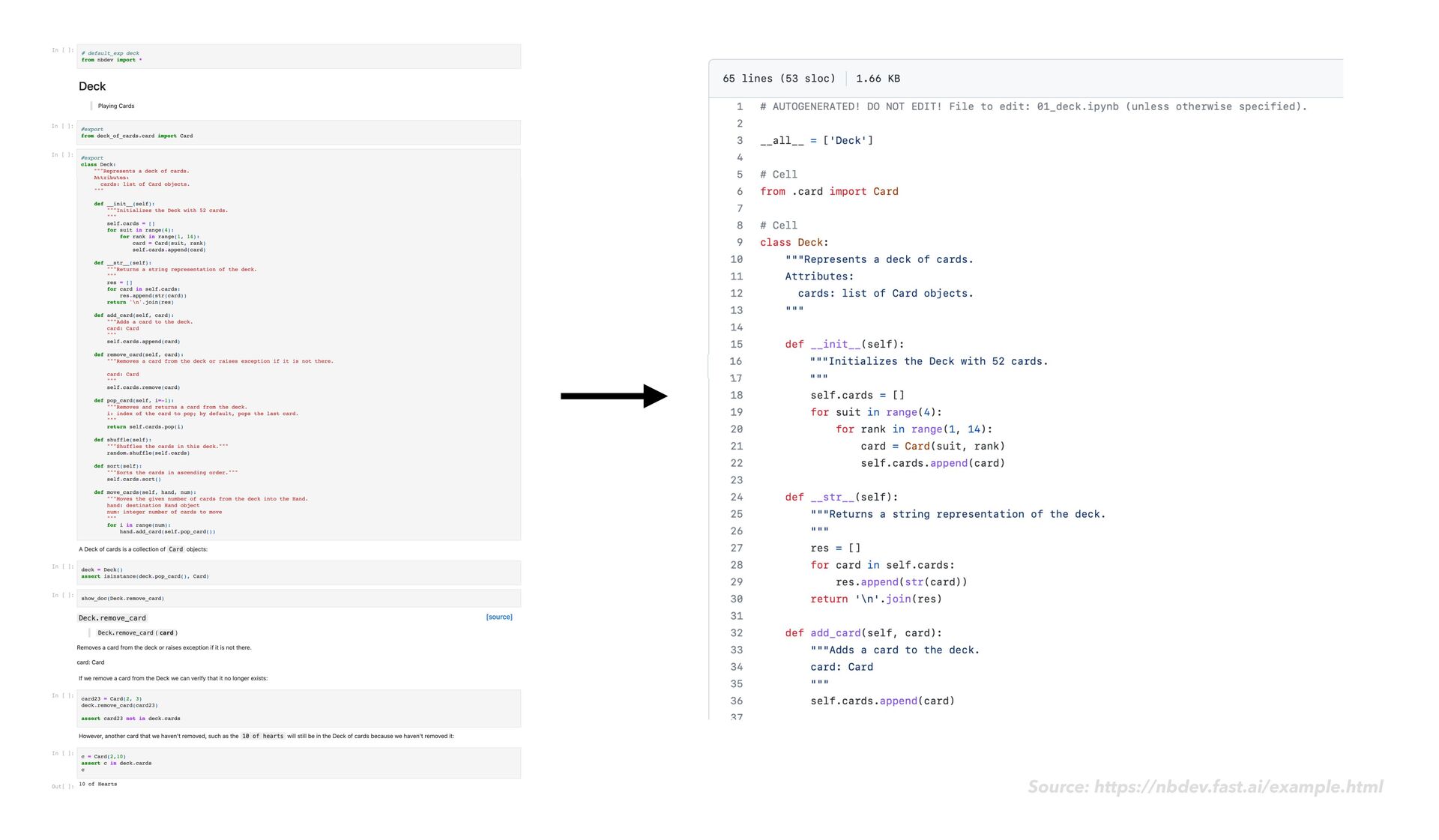
as usual • As you go, notice when it would make sense to reuse or share bits of the code you write • Reshape this code into functions and classes in a notebook nbdev
as usual • As you go, notice when it would make sense to reuse or share bits of the code you write • Reshape this code into functions and classes in a notebook • Add the #export fl ag (code comment) at the start of your main code cells nbdev
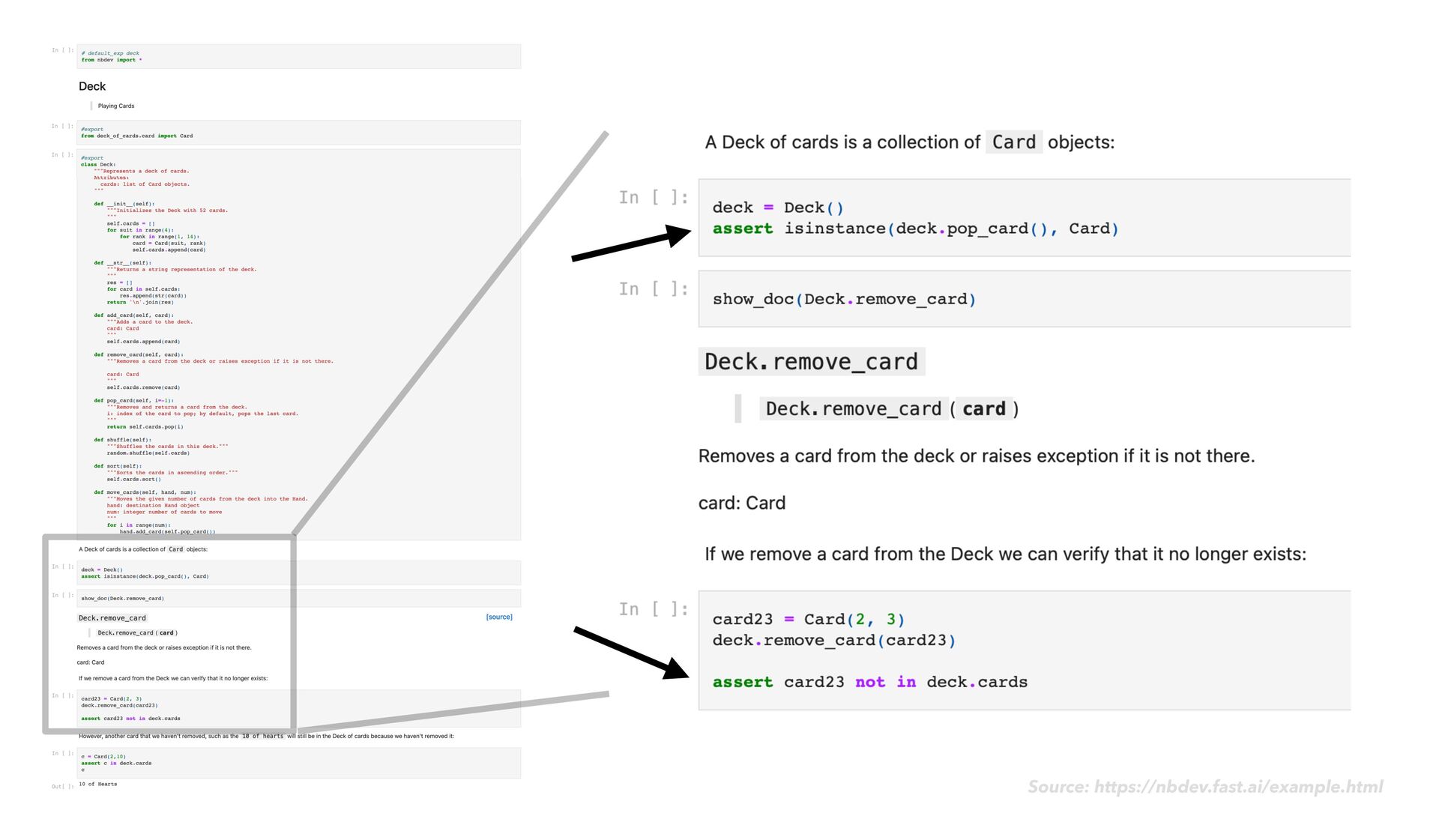
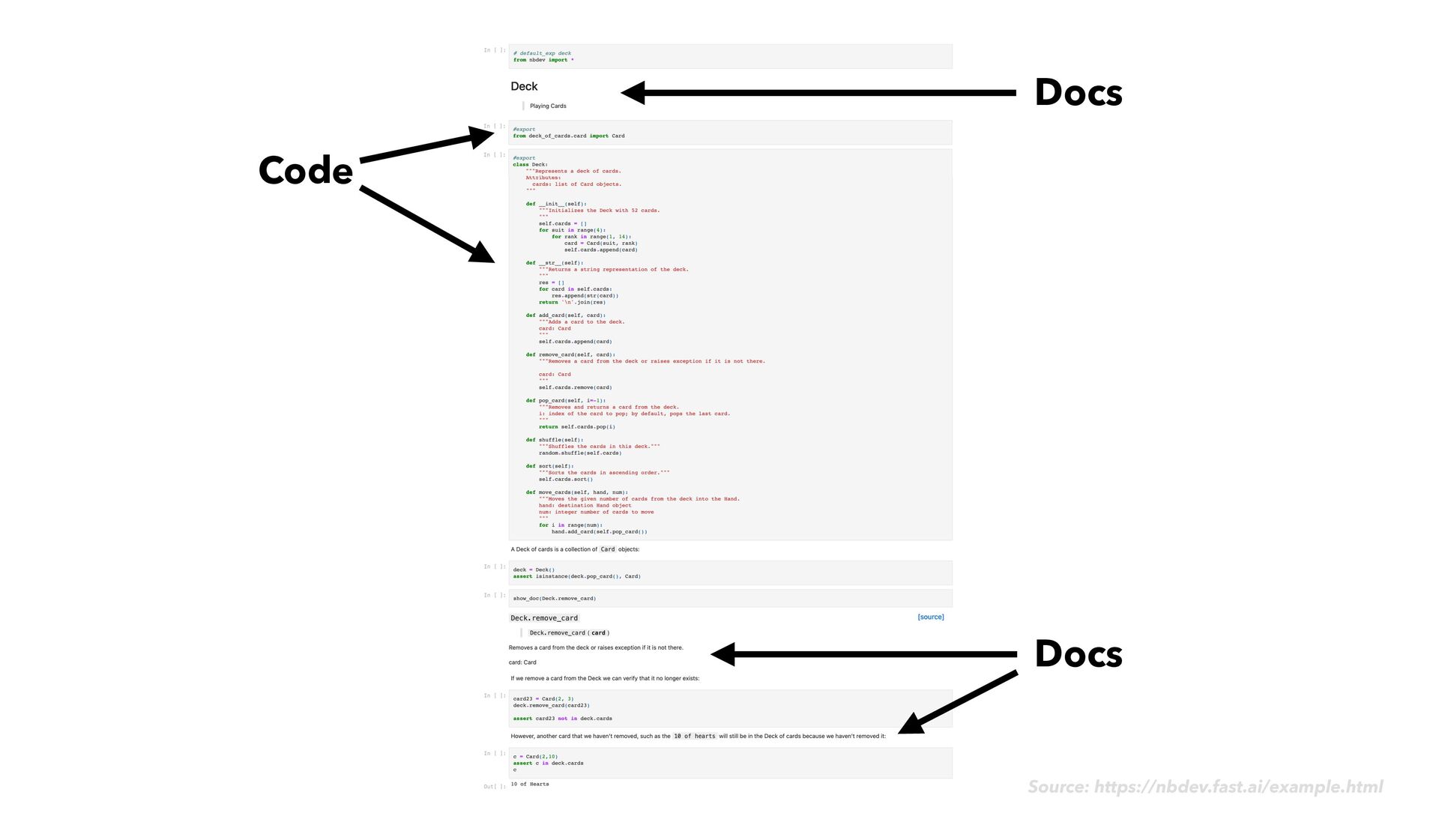
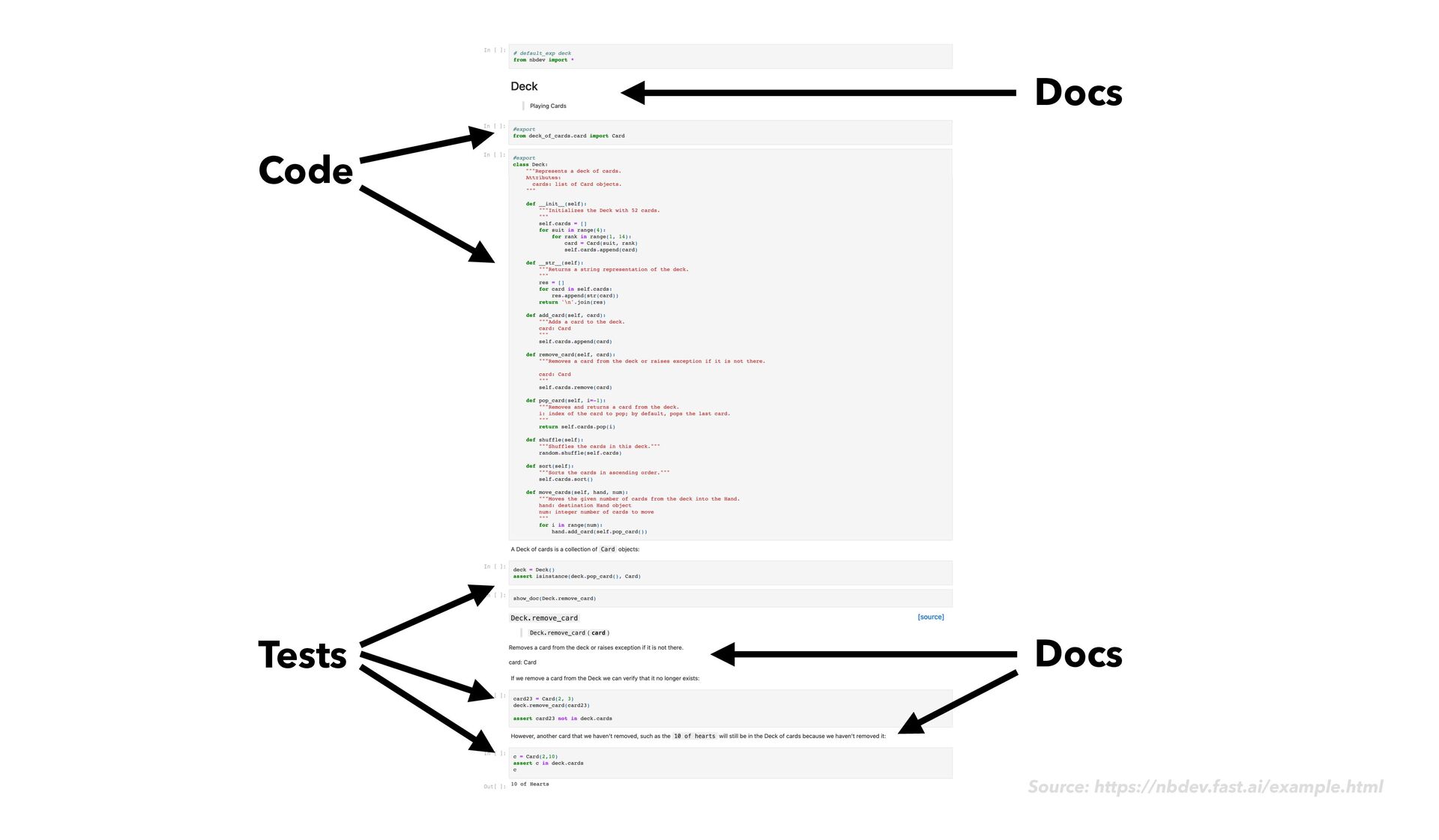
as usual • As you go, notice when it would make sense to reuse or share bits of the code you write • Reshape this code into functions and classes in a notebook • Add the #export fl ag (code comment) at the start of your main code cells • Next to your main code cells, add rich explanatory text, images, code usage examples, sample output, and assert statements nbdev
programming that much; you add a #export or #hide tag to your notebook cells once in a while, and you run nbdev_build_lib and nbdev_build_docs when you fi nish up your code. Source: https://www.overstory.com/blog/how-nbdev-helps-us-structure-our-data-science-work fl ow-in-jupyter-notebooks nbdev
programming that much; you add a #export or #hide tag to your notebook cells once in a while, and you run nbdev_build_lib and nbdev_build_docs when you fi nish up your code. That’s it! There’s nothing new to learn, nothing to unlearn. It’s just notebooks." Source: https://www.overstory.com/blog/how-nbdev-helps-us-structure-our-data-science-work fl ow-in-jupyter-notebooks nbdev
version control and document and test our codebase continuously... [while] preserving the bene fi ts of having interactive Jupyter notebooks in which it is easy to experiment." Source: https://www.overstory.com/blog/how-nbdev-helps-us-structure-our-data-science-work fl ow-in-jupyter-notebooks nbdev
version control and document and test our codebase continuously... [while] preserving the bene fi ts of having interactive Jupyter notebooks in which it is easy to experiment." Source: https://www.overstory.com/blog/how-nbdev-helps-us-structure-our-data-science-work fl ow-in-jupyter-notebooks nbdev — Overstory
the scheduled jobs running on the Net fl ix Data Platform to use notebook-based execution… Source: https://net fl ixtechblog.com/scheduling-notebooks-348e6c14cfd6
the scheduled jobs running on the Net fl ix Data Platform to use notebook-based execution… When we’re done, more than 150,000 [pipeline executions] will be running through notebooks on our platform every single day.” Source: https://net fl ixtechblog.com/scheduling-notebooks-348e6c14cfd6
the scheduled jobs running on the Net fl ix Data Platform to use notebook-based execution… When we’re done, more than 150,000 [pipeline executions] will be running through notebooks on our platform every single day.” Source: https://net fl ixtechblog.com/scheduling-notebooks-348e6c14cfd6 — Net fl ix (2018)
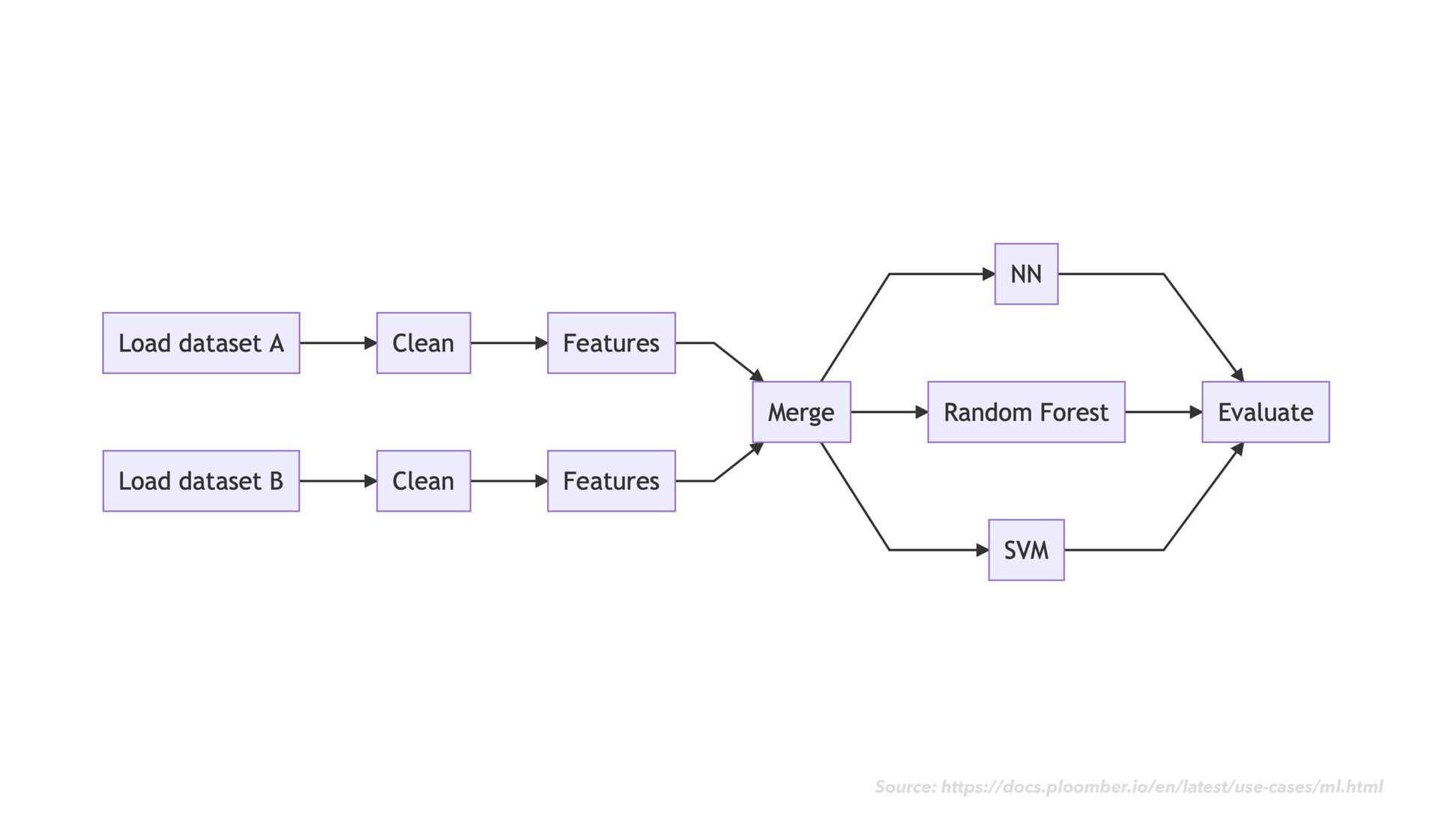
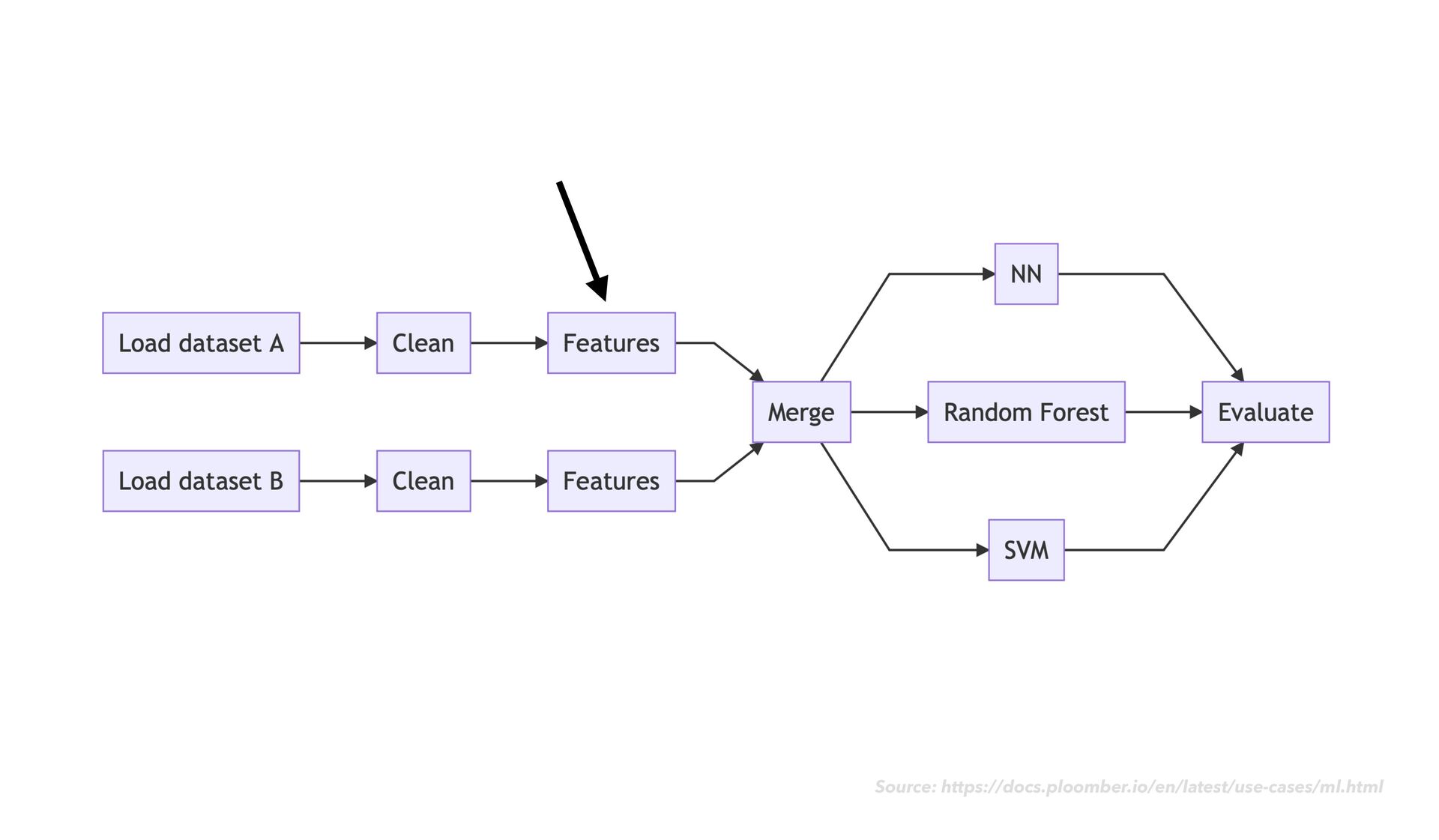
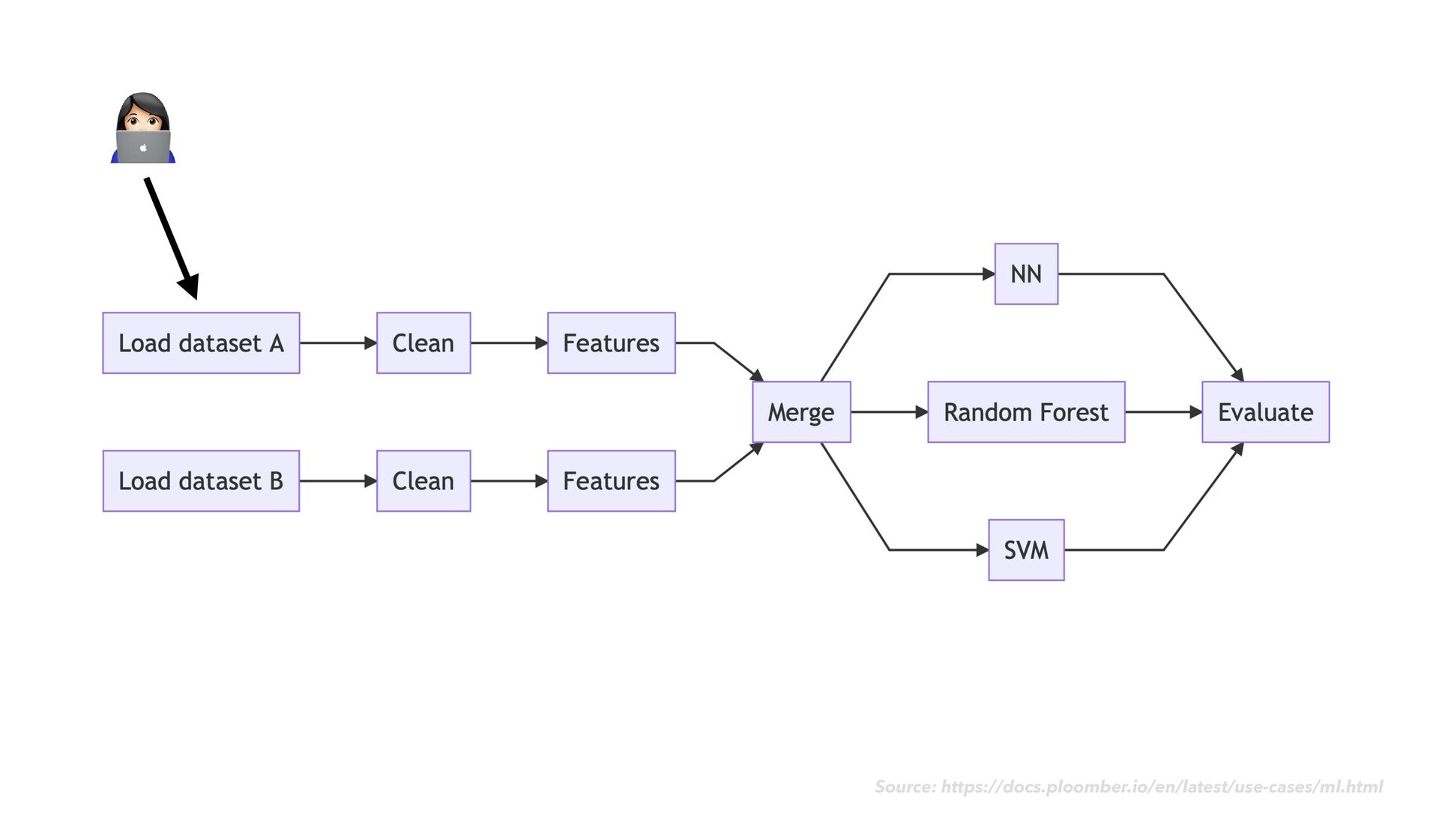
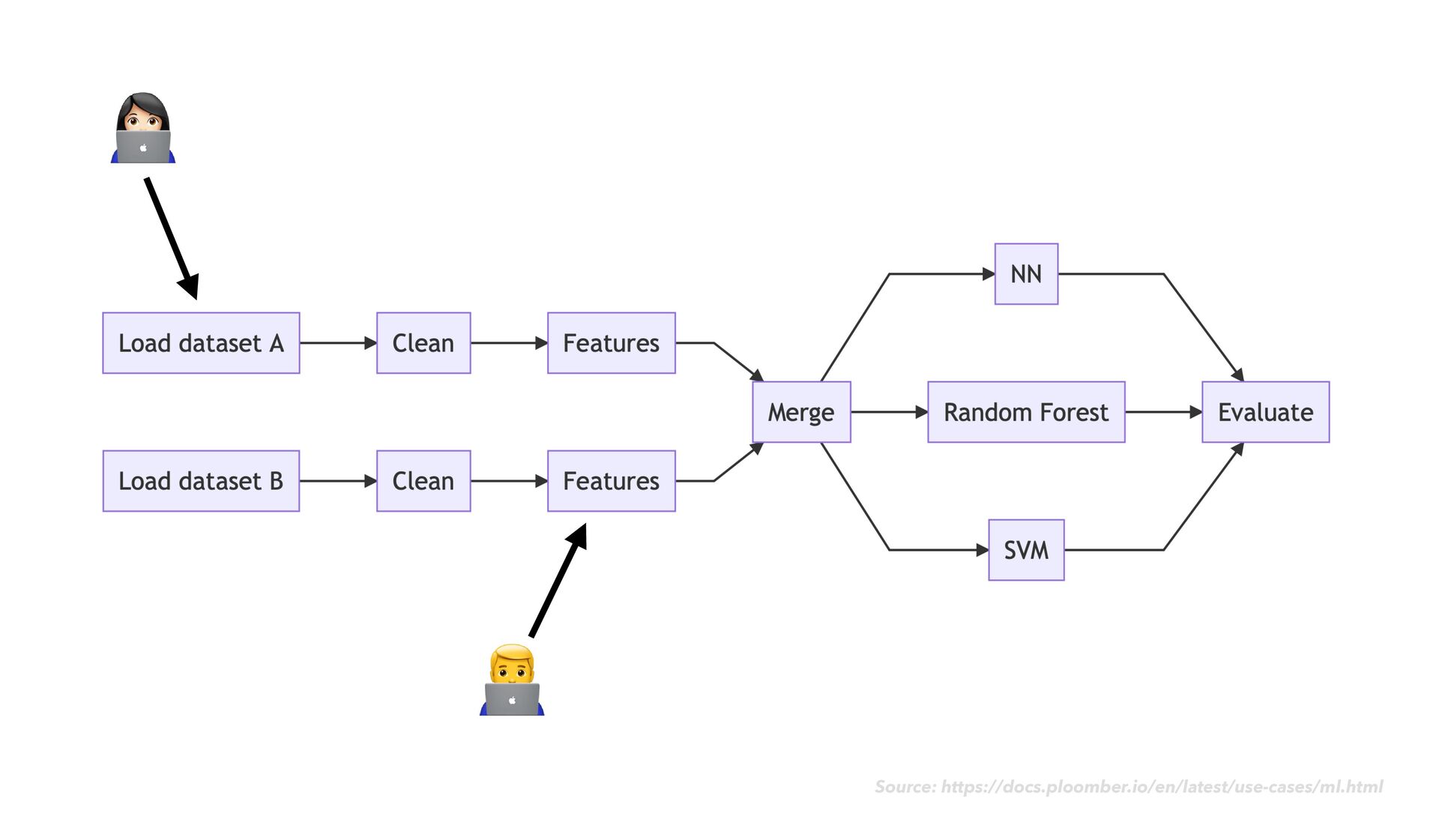
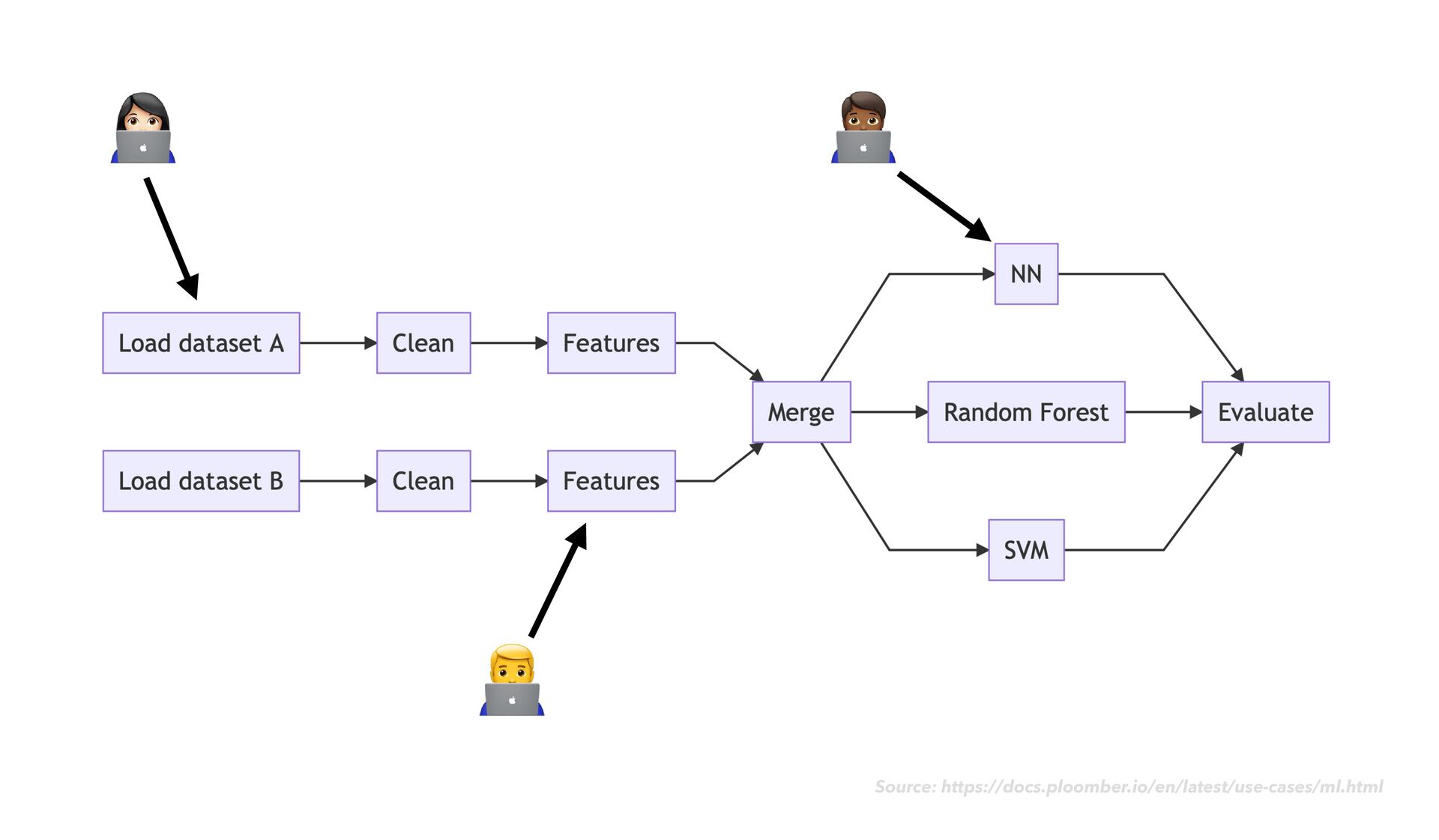
-c conda-forge • Initialize your git repository as a ploomber project: • ploomber scaffold --empty • Add information about your pipeline to pipeline.yaml as you go ploomber
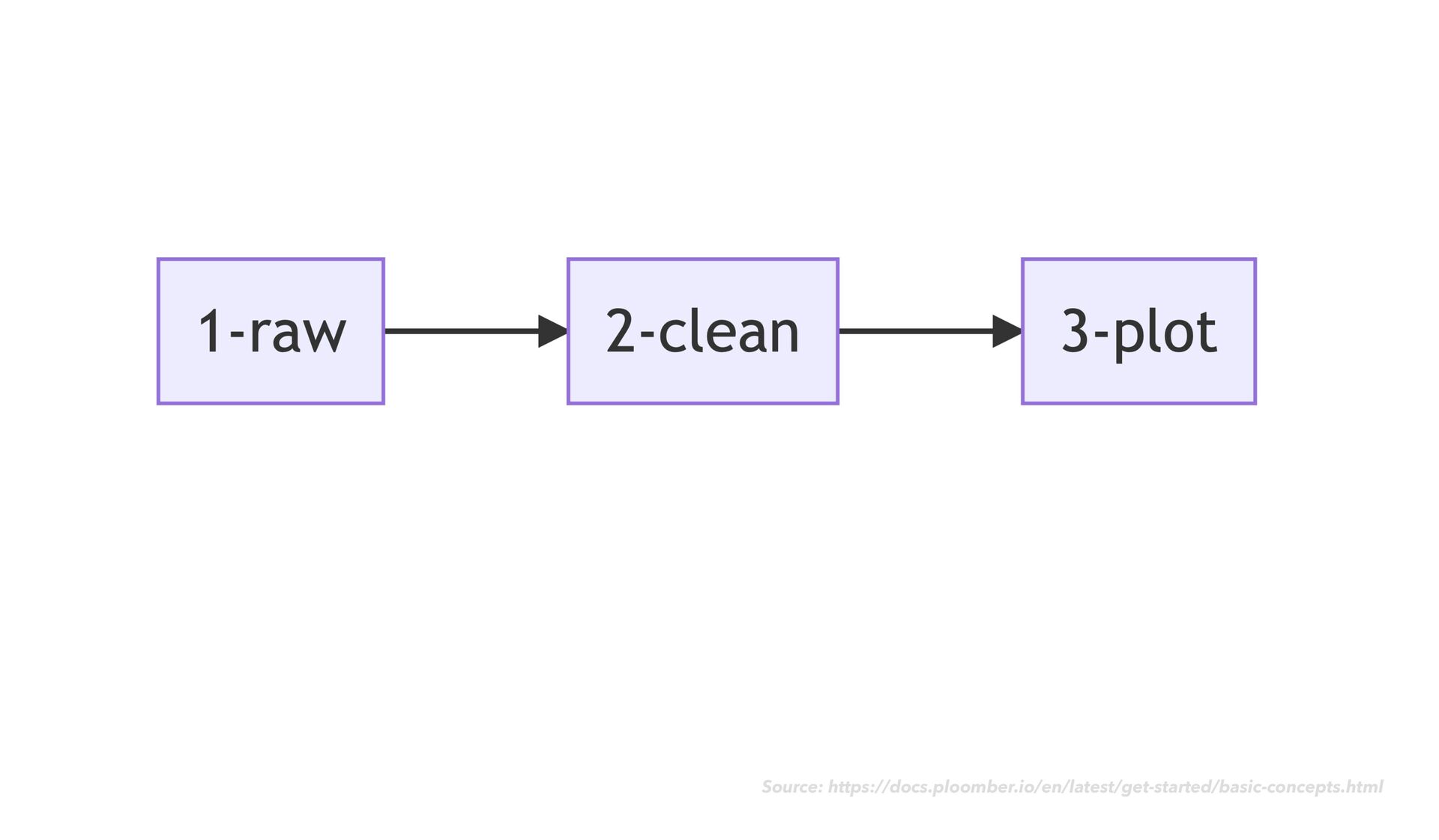
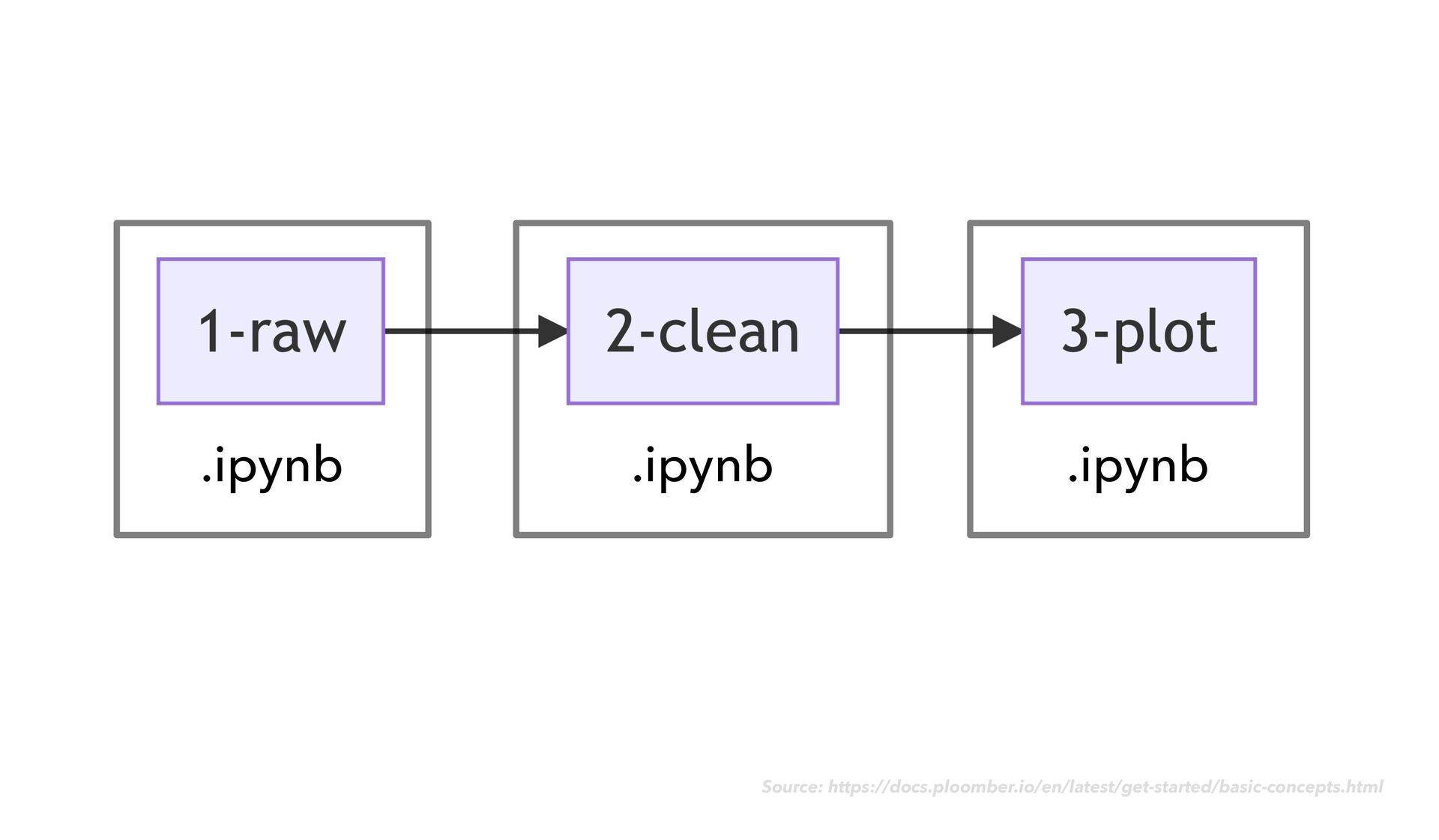
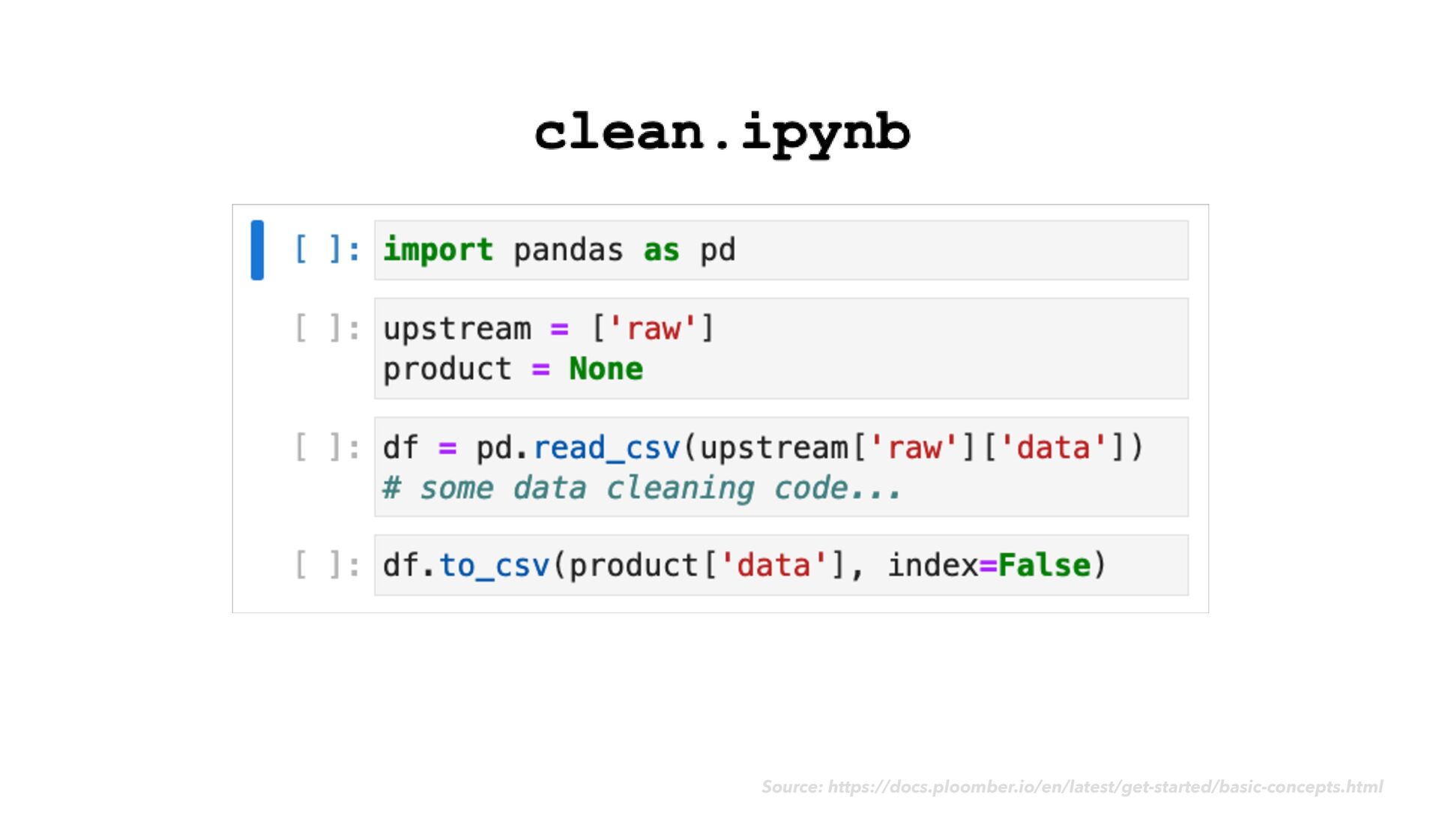
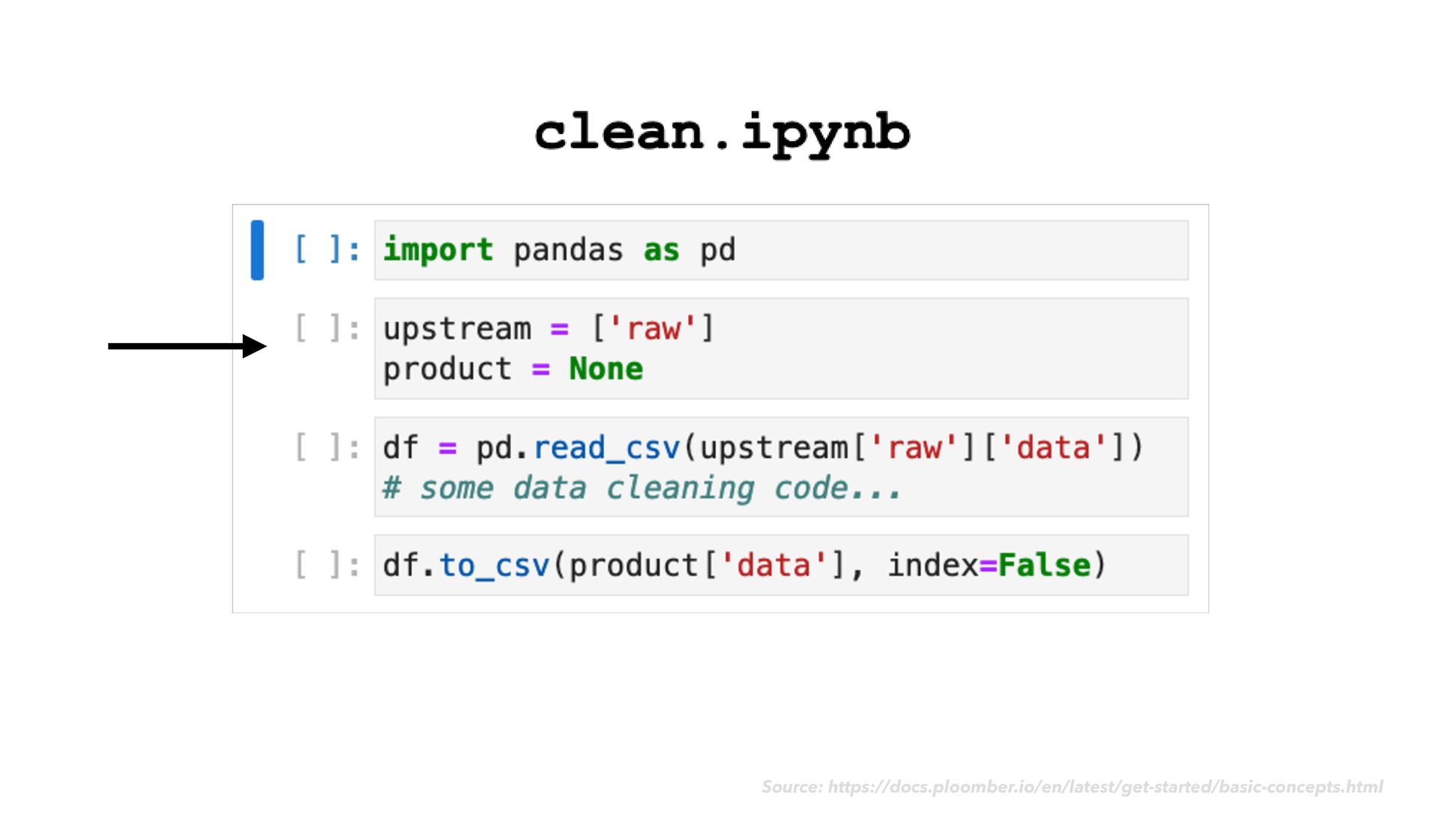
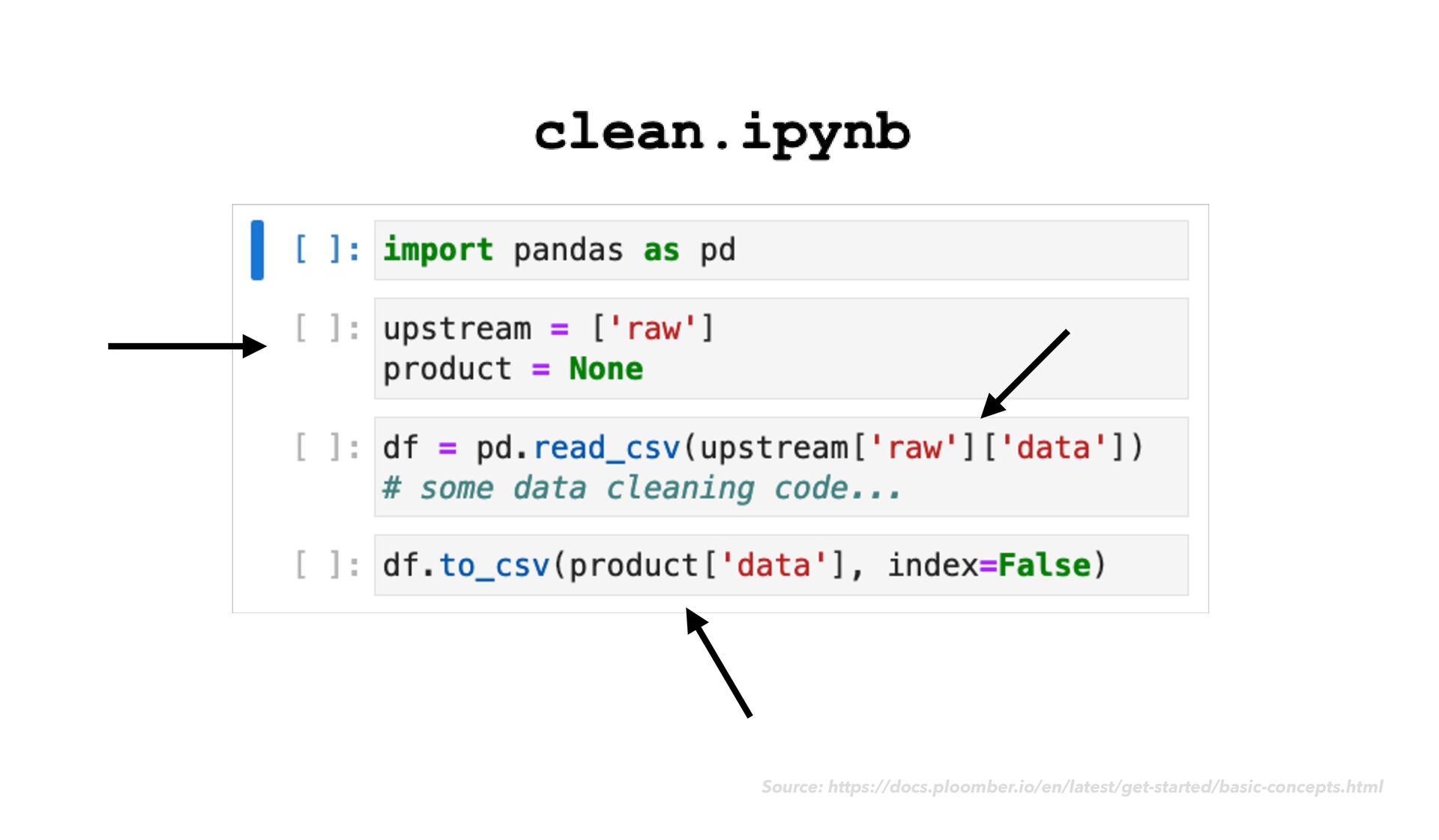
as usual • As you go, notice when chunks of your code would make sense as modular "tasks" in a data transformation work fl ow • Move the code for each task into its own dedicated notebook ploomber
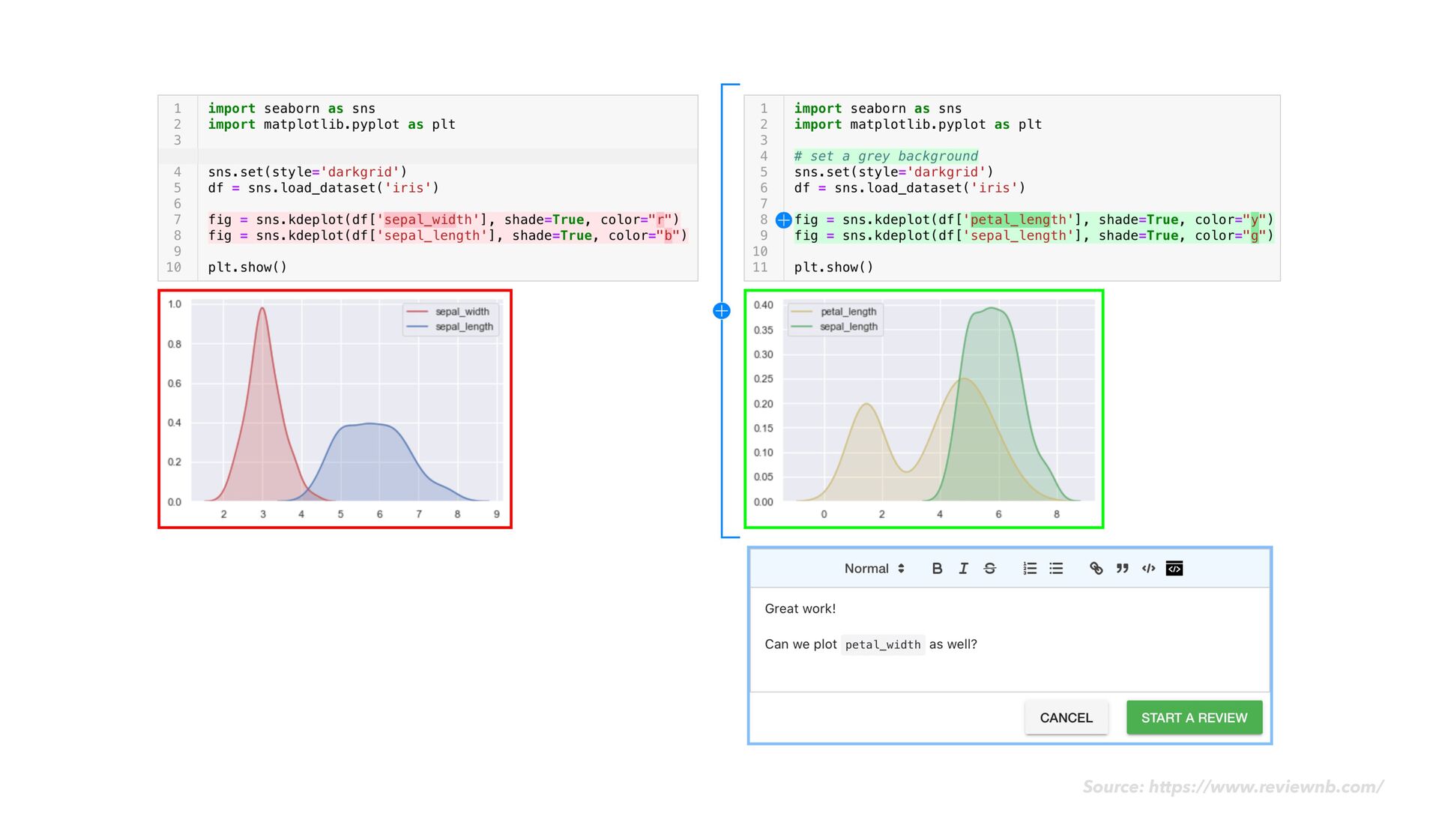
as usual • As you go, notice when chunks of your code would make sense as modular "tasks" in a data transformation work fl ow • Move the code for each task into its own dedicated notebook • Next to your code cells, add rich explanatory text, images, example expected output, and data quality checks ploomber
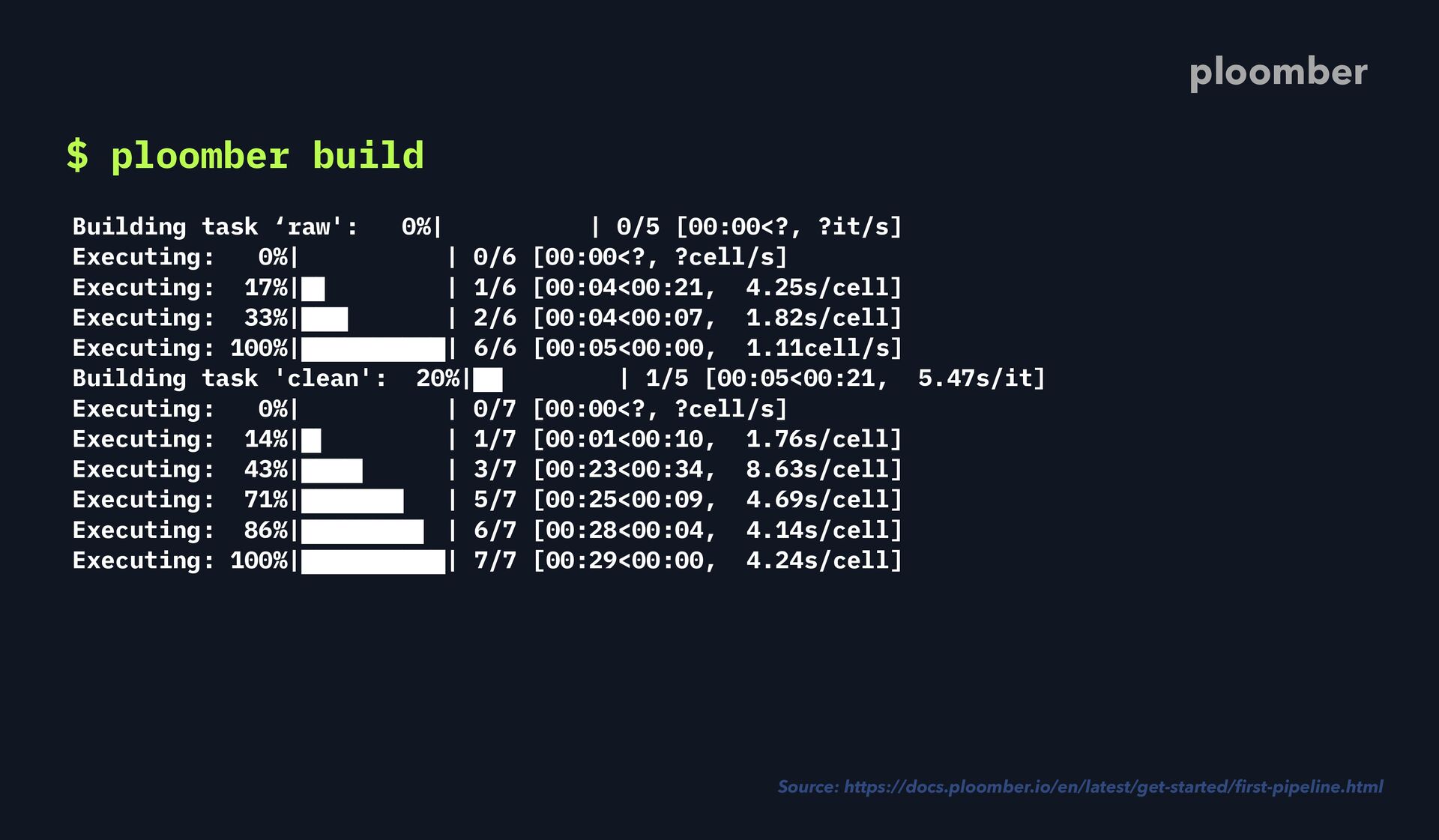
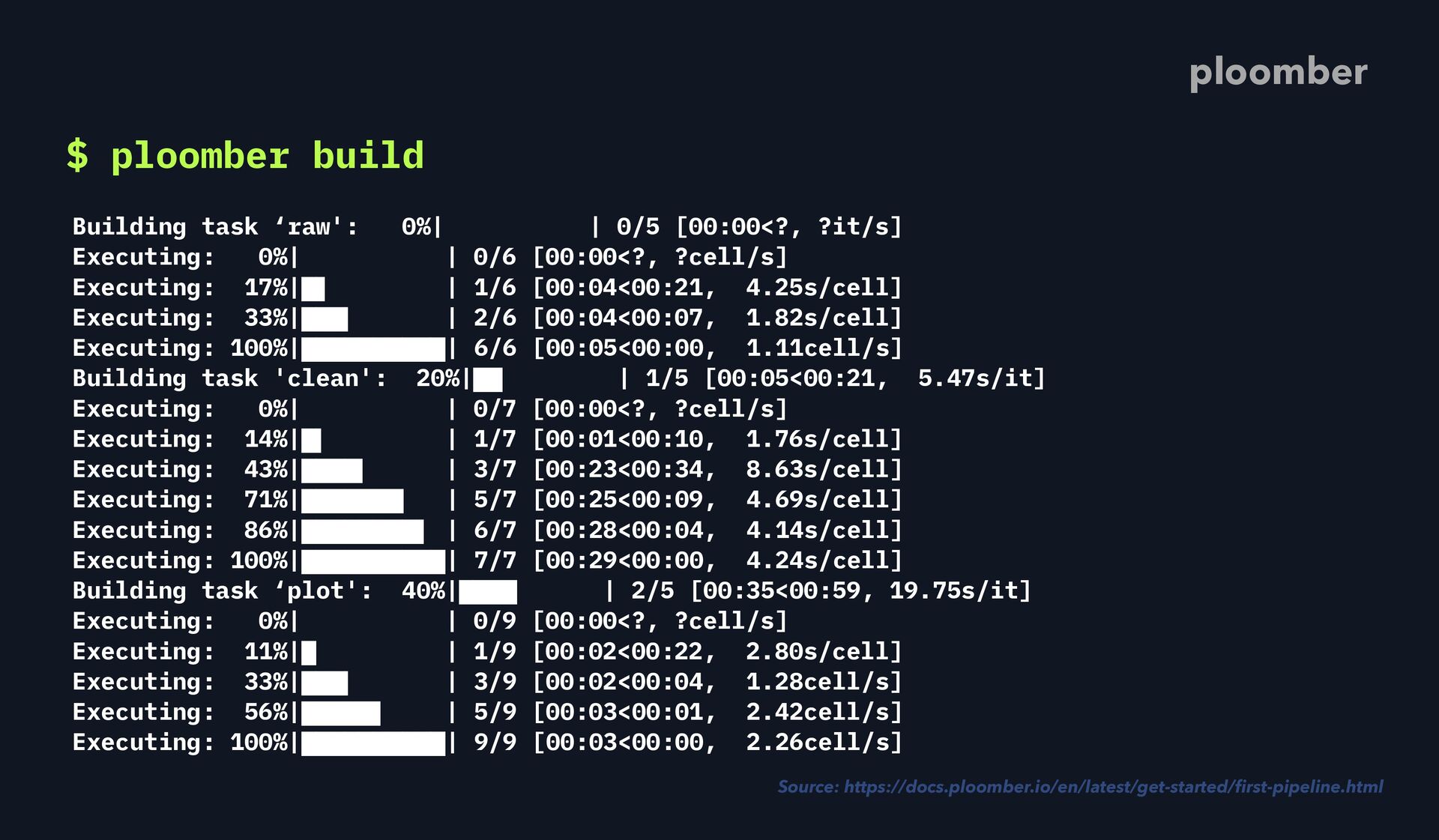
execute - source: raw.ipynb # products are task's outputs product: # tasks generate executed notebooks as outputs nb: output/raw.ipynb # you can define as many outputs as you want data: output/raw_data.csv ploomber Source: https://docs.ploomber.io/en/latest/get-started/ fi rst-pipeline.html
execute - source: raw.ipynb # products are task's outputs product: # tasks generate executed notebooks as outputs nb: output/raw.ipynb # you can define as many outputs as you want data: output/raw_data.csv - source: clean.ipynb ploomber Source: https://docs.ploomber.io/en/latest/get-started/ fi rst-pipeline.html
execute - source: raw.ipynb # products are task's outputs product: # tasks generate executed notebooks as outputs nb: output/raw.ipynb # you can define as many outputs as you want data: output/raw_data.csv - source: clean.ipynb product: ploomber Source: https://docs.ploomber.io/en/latest/get-started/ fi rst-pipeline.html
execute - source: raw.ipynb # products are task's outputs product: # tasks generate executed notebooks as outputs nb: output/raw.ipynb # you can define as many outputs as you want data: output/raw_data.csv - source: clean.ipynb product: nb: output/clean.ipynb ploomber Source: https://docs.ploomber.io/en/latest/get-started/ fi rst-pipeline.html
execute - source: raw.ipynb # products are task's outputs product: # tasks generate executed notebooks as outputs nb: output/raw.ipynb # you can define as many outputs as you want data: output/raw_data.csv - source: clean.ipynb product: nb: output/clean.ipynb data: output/clean_data.parquet ploomber Source: https://docs.ploomber.io/en/latest/get-started/ fi rst-pipeline.html
our input and outputs are complete documents, wholly executable and shareable in the same interface.” Source: https://net fl ixtechblog.com/scheduling-notebooks-348e6c14cfd6 — Net fl ix (2018)
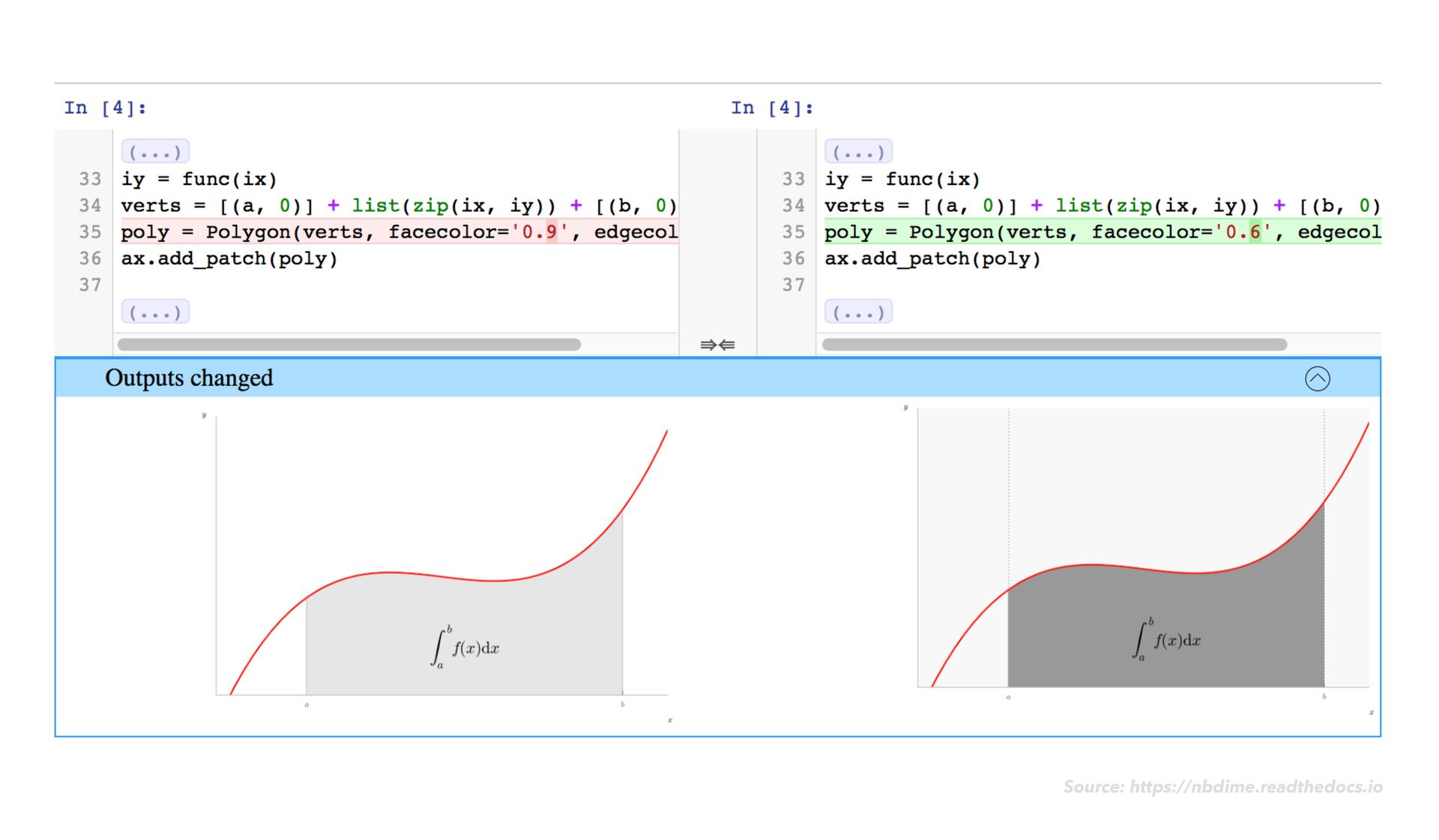
x the issue? The fi rst place we’d want to look is the notebook output. It will have a stack trace, and ultimately any output information related to an error… Source: https://net fl ixtechblog.com/scheduling-notebooks-348e6c14cfd6 — Net fl ix (2018)
x the issue? The fi rst place we’d want to look is the notebook output. It will have a stack trace, and ultimately any output information related to an error… [W]e simply take the output notebook with our exact failed runtime parameterizations and load it into a notebook server… With a few iterations… we can quickly fi nd a fi x for the failure. Source: https://net fl ixtechblog.com/scheduling-notebooks-348e6c14cfd6 — Net fl ix (2018)
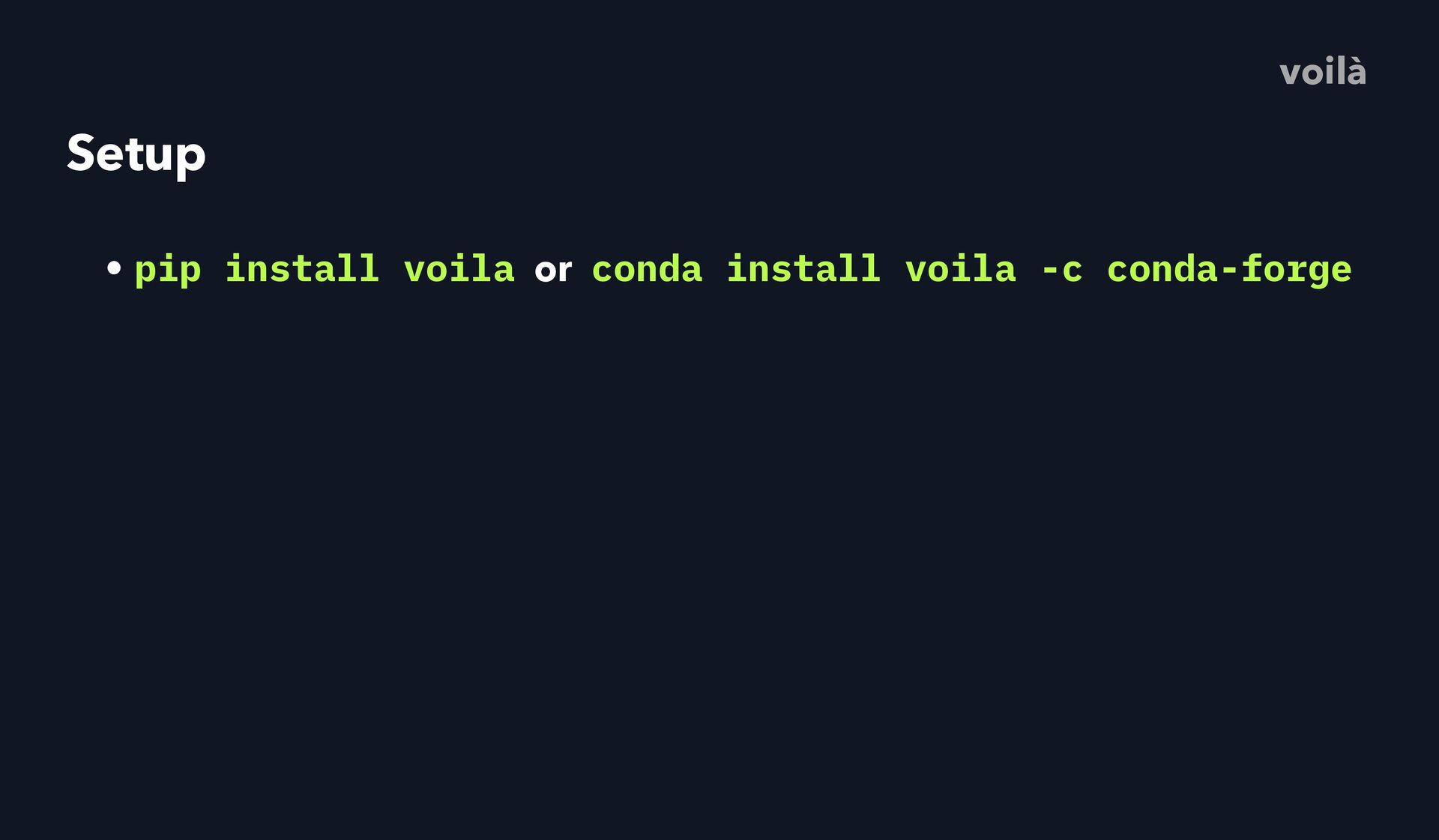
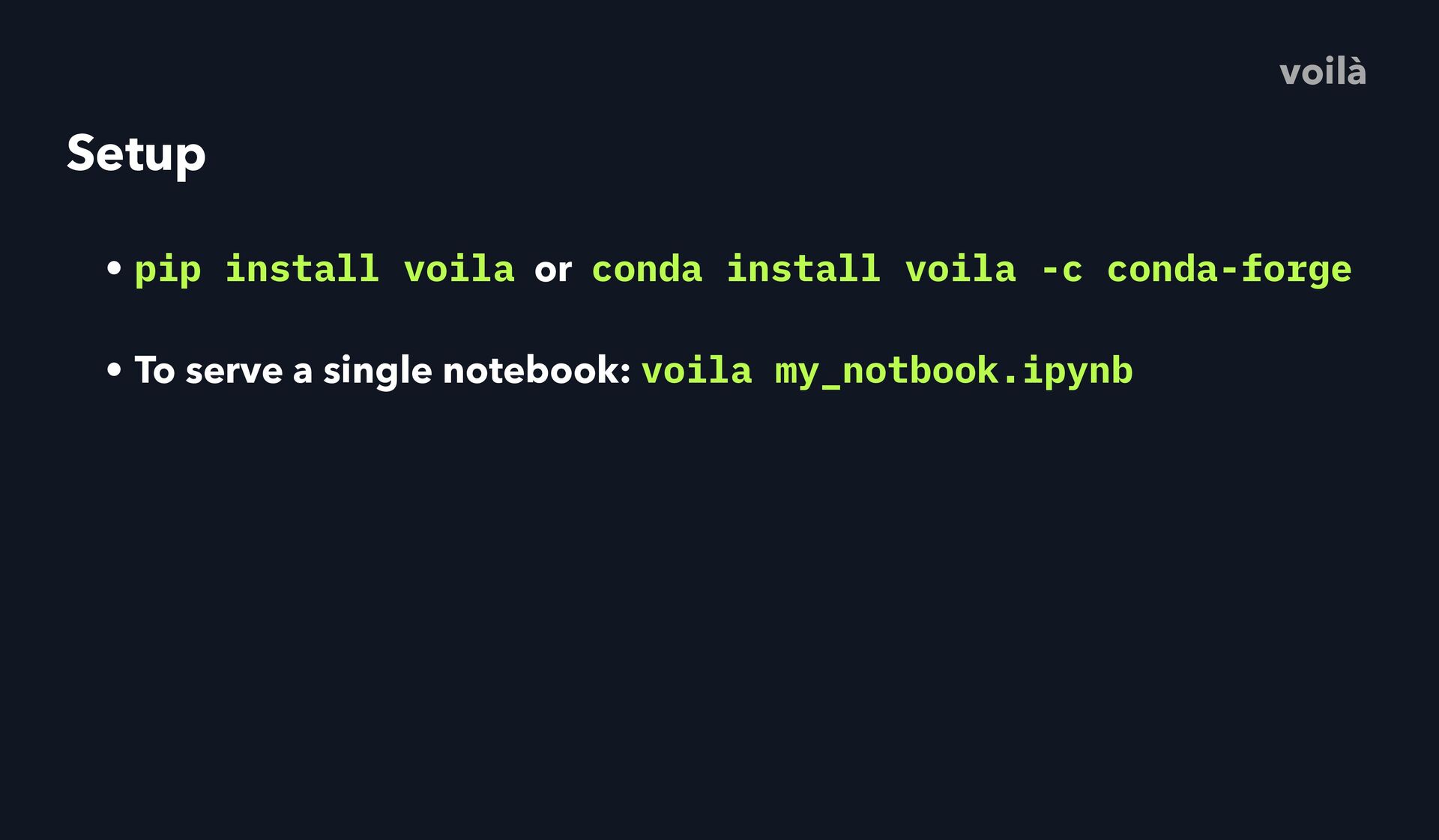
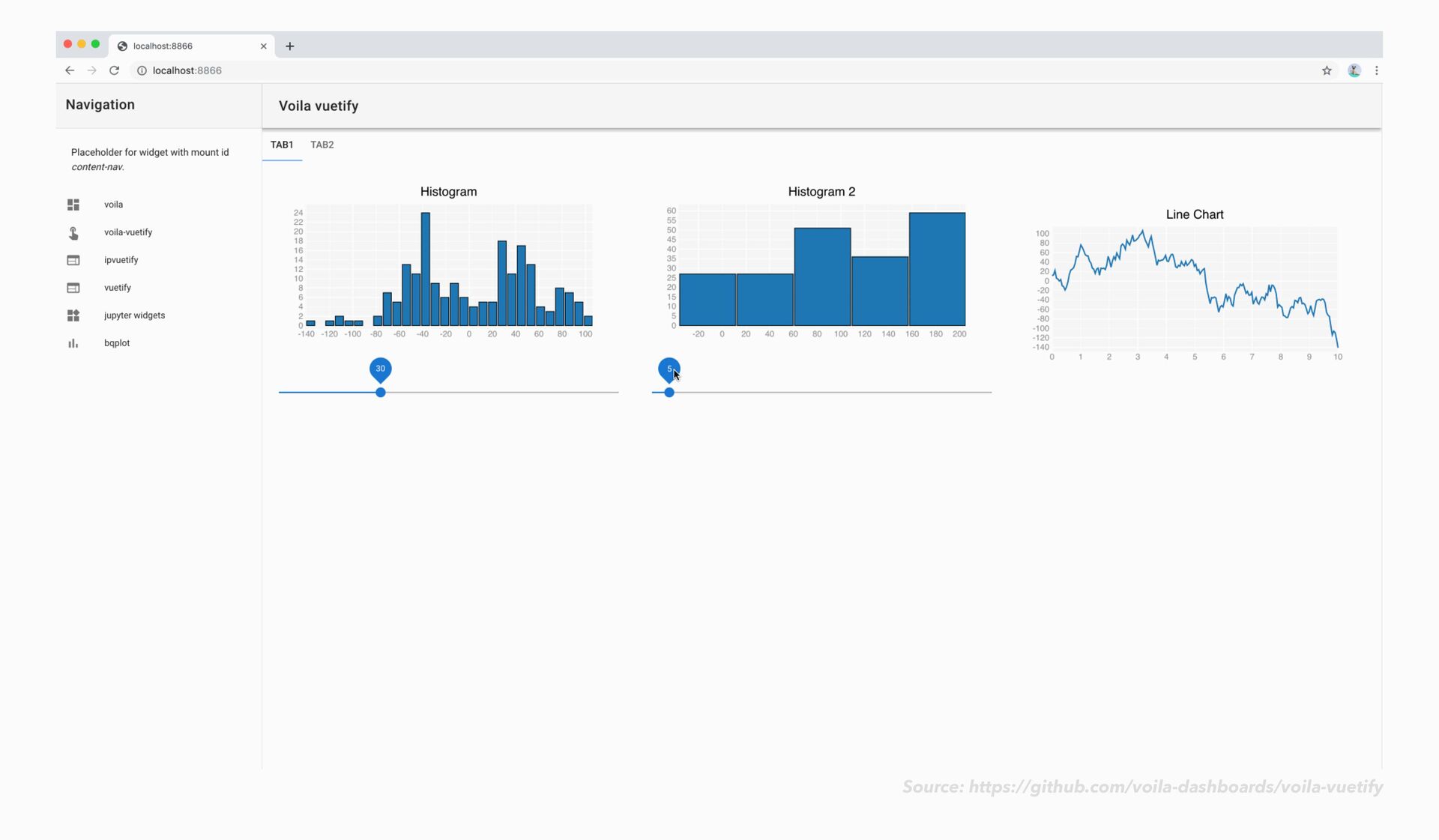
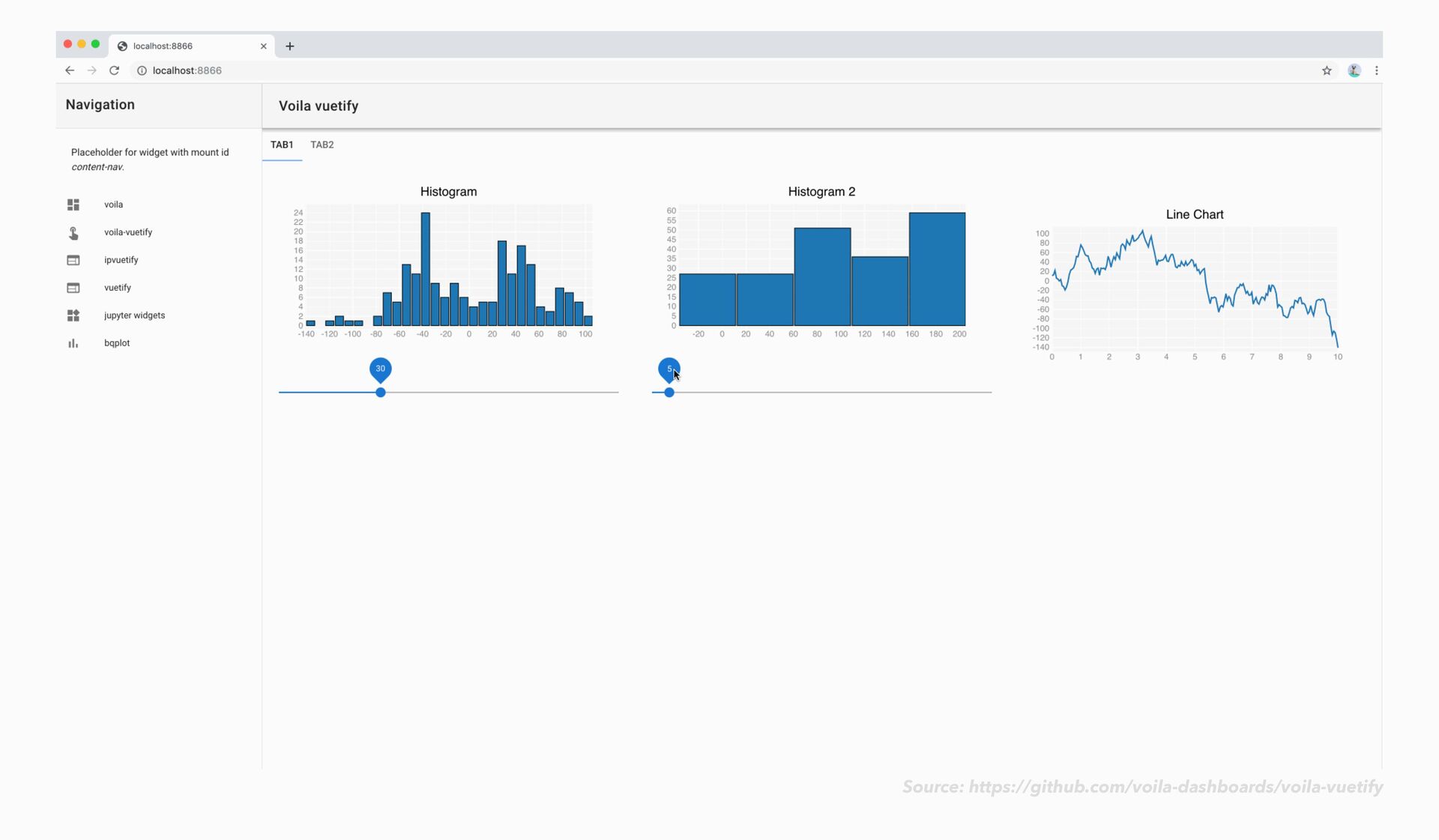
conda-forge • To serve a single notebook: voila my_notbook.ipynb • To serve a whole directory of notebooks: voila • Optionally specify a custom template: voilà
conda-forge • To serve a single notebook: voila my_notbook.ipynb • To serve a whole directory of notebooks: voila • Optionally specify a custom template: • voila my_notebook.ipynb --template=gridstack voilà
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
!["We’ve found that we’re 2x-3x more productive using [notebook-based development]](https://files.speakerdeck.com/presentations/b61640e56cf84958a65d58769cf1424a/slide_25.jpg){kind=link}
!["We’ve found that we’re 2x-3x more productive using [notebook-based development]](https://files.speakerdeck.com/presentations/b61640e56cf84958a65d58769cf1424a/slide_26.jpg){kind=link}
!["We’ve found that we’re 2x-3x more productive using [notebook-based development]](https://files.speakerdeck.com/presentations/b61640e56cf84958a65d58769cf1424a/slide_27.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
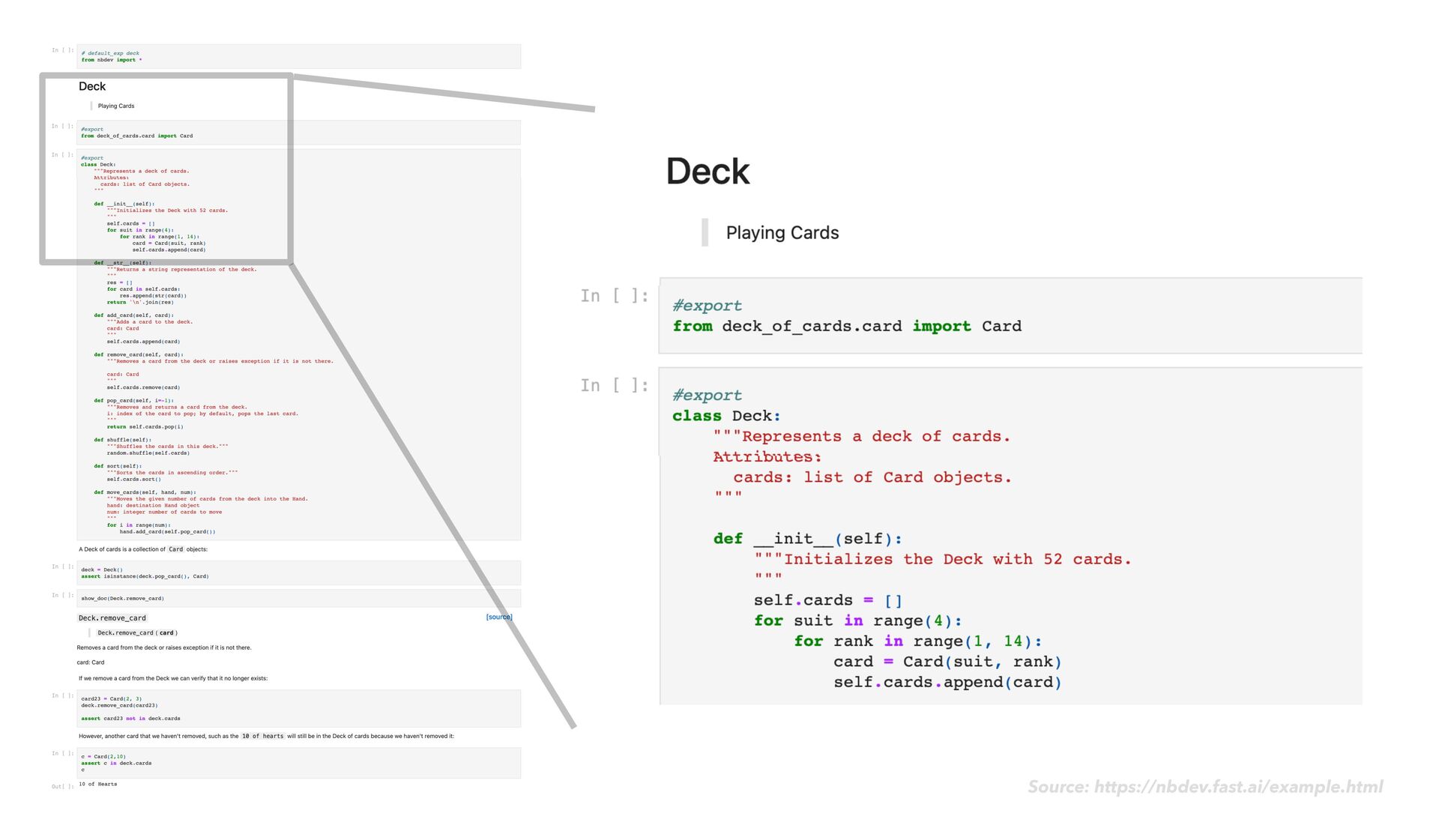{kind=link}
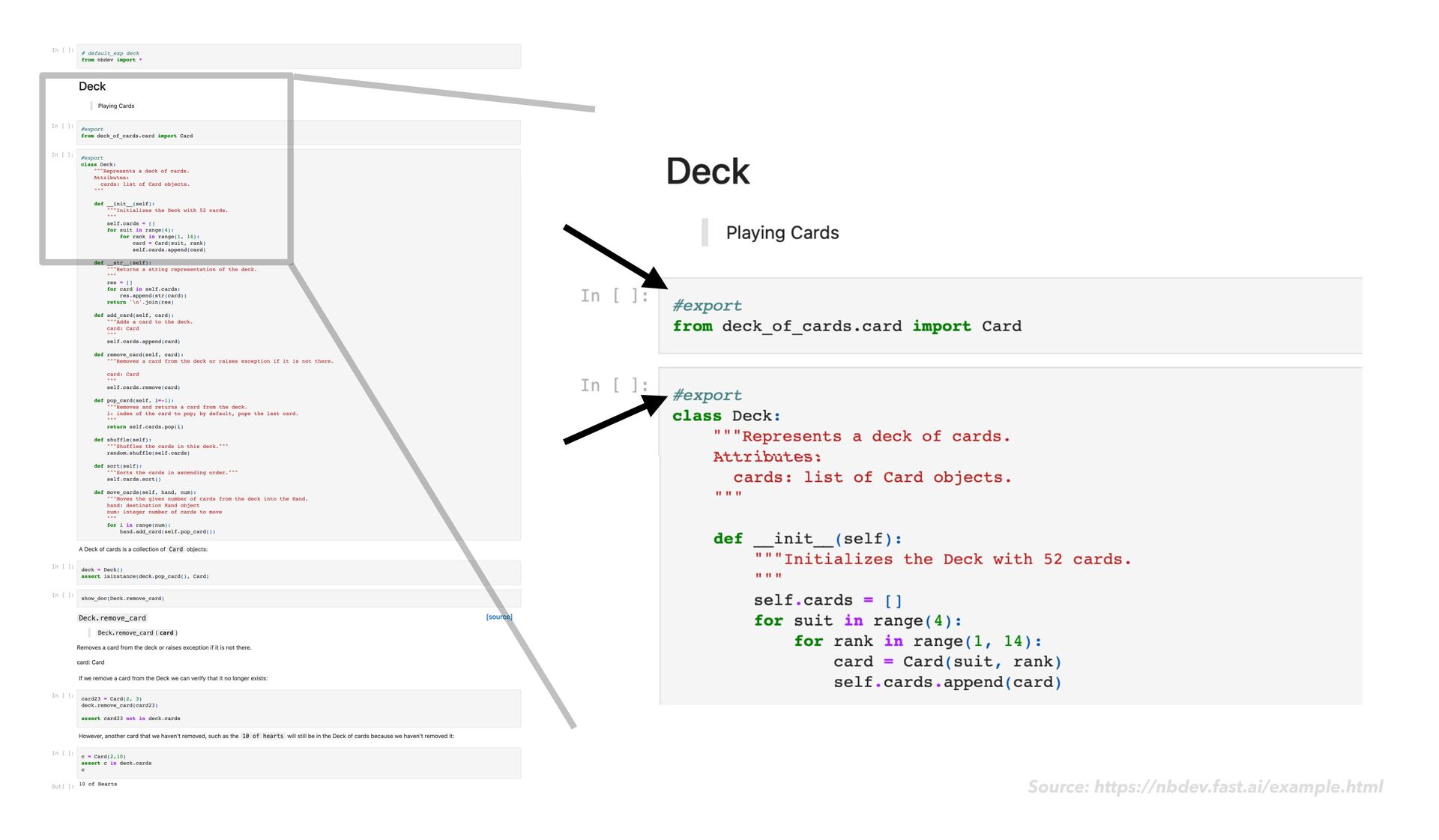{kind=link}
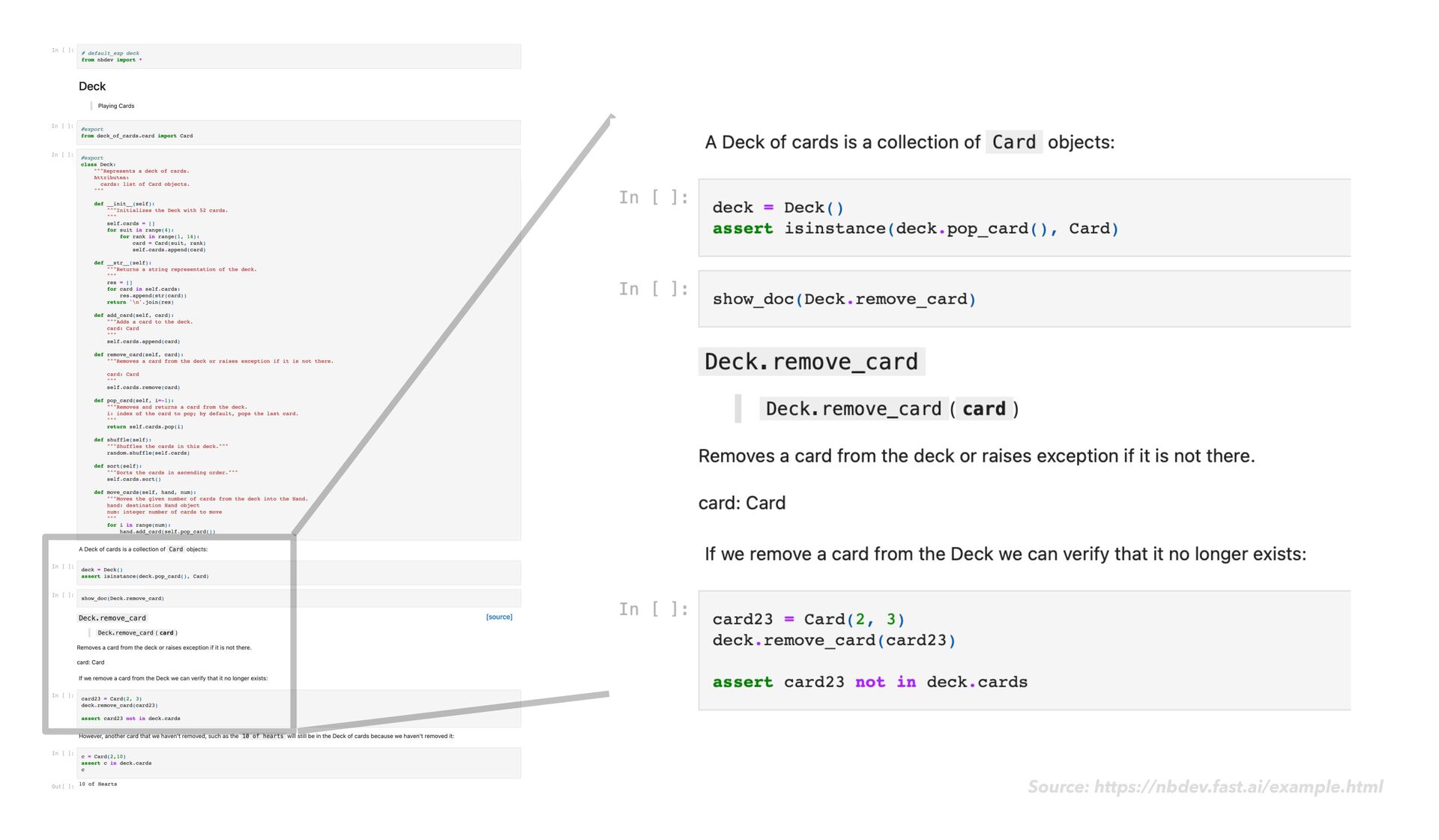{kind=link}
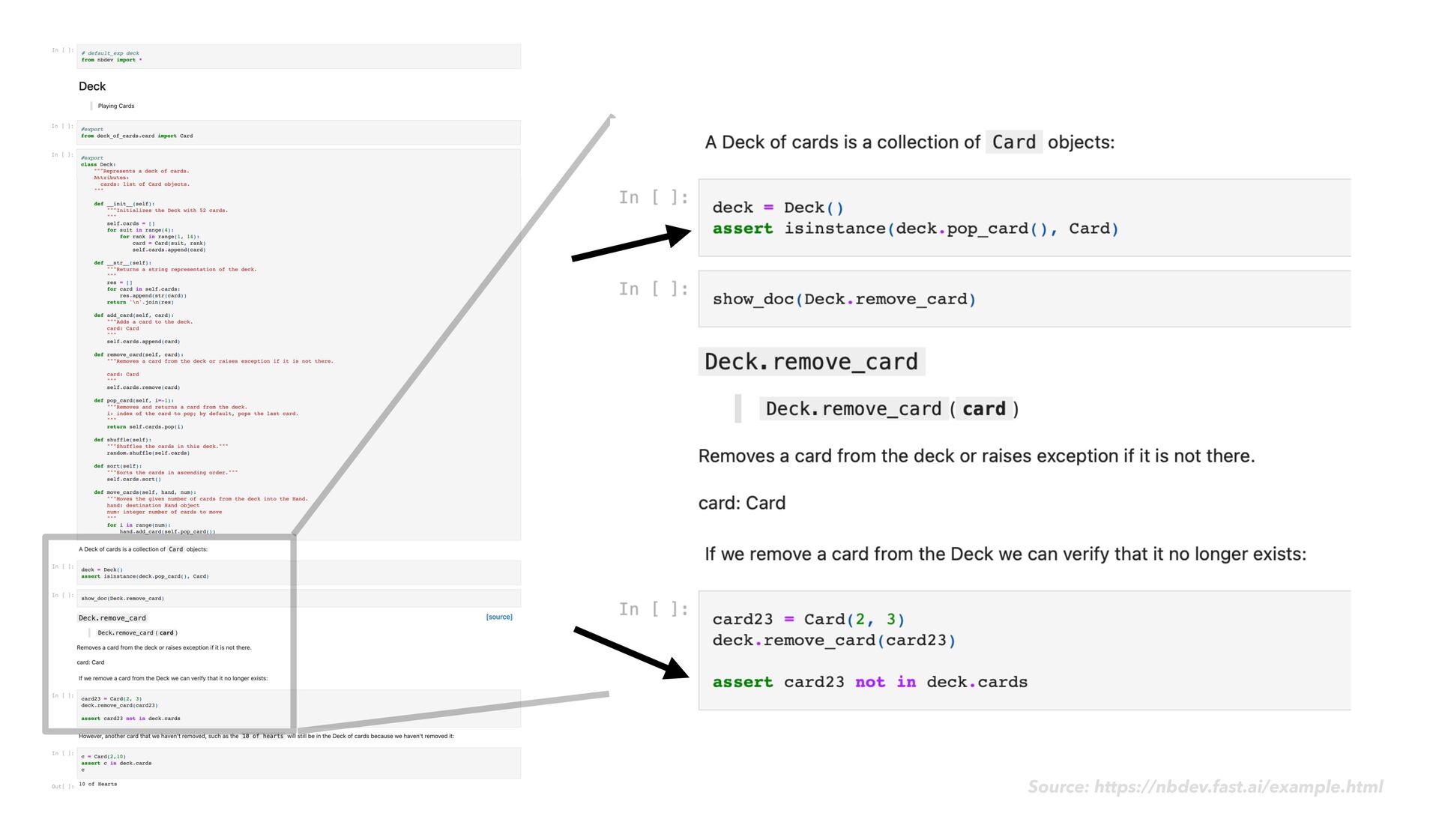{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![“[nbdev] incentives us to write clear code, use proper Git](https://files.speakerdeck.com/presentations/b61640e56cf84958a65d58769cf1424a/slide_129.jpg){kind=link}
![“[nbdev] incentives us to write clear code, use proper Git](https://files.speakerdeck.com/presentations/b61640e56cf84958a65d58769cf1424a/slide_130.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![“[W]e’ve gained a key improvement over a non-notebook execution pattern:](https://files.speakerdeck.com/presentations/b61640e56cf84958a65d58769cf1424a/slide_183.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}