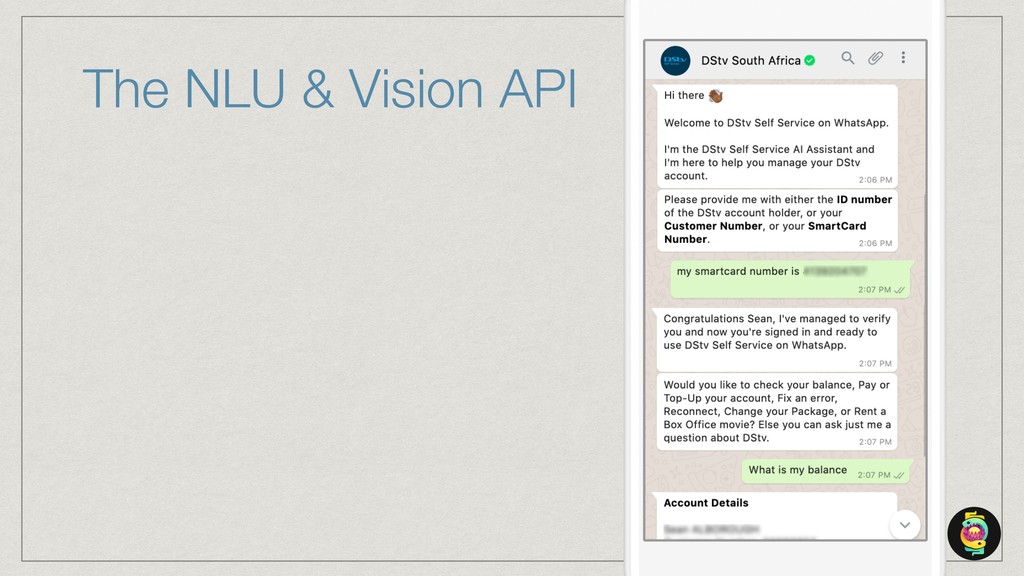
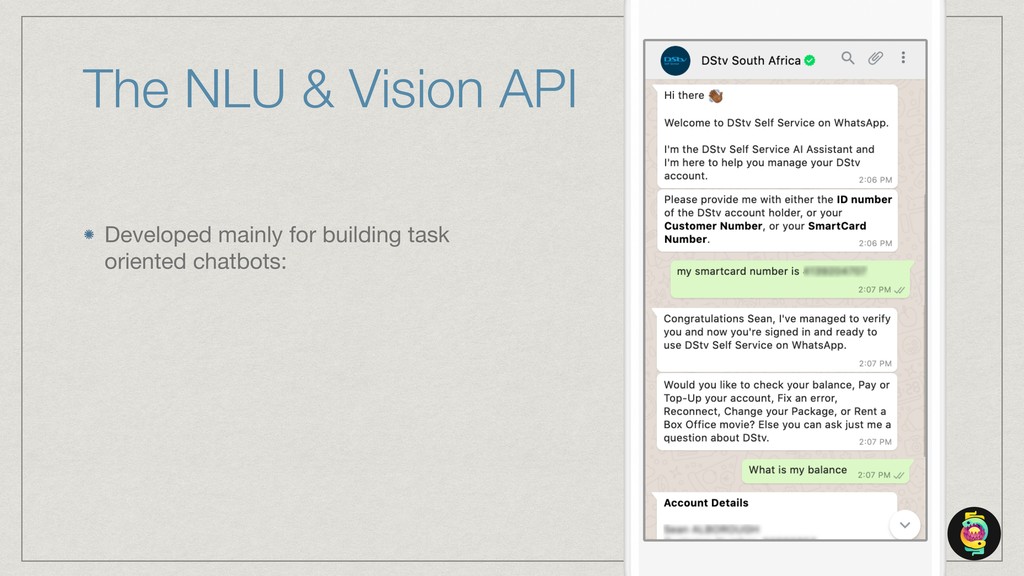
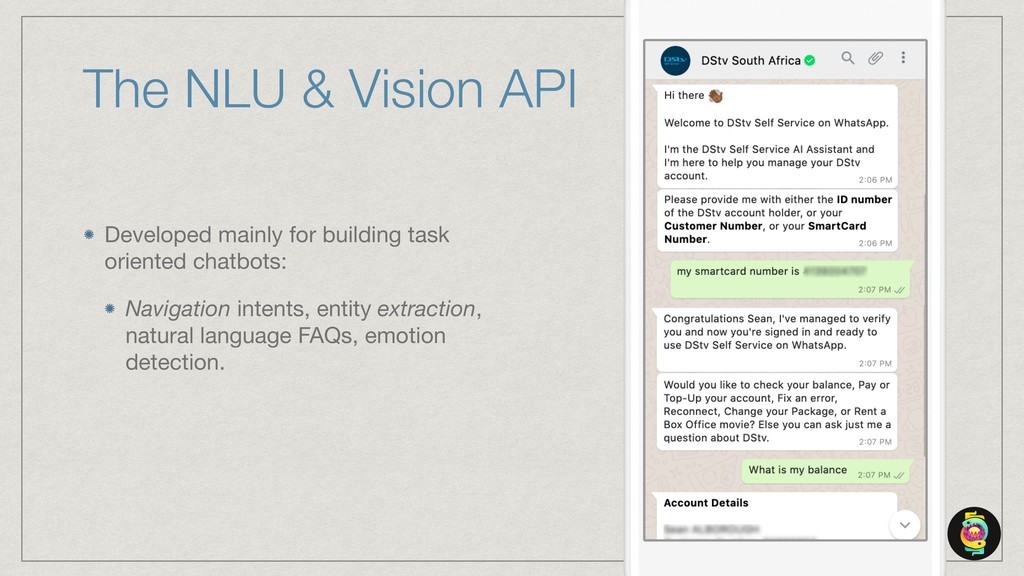
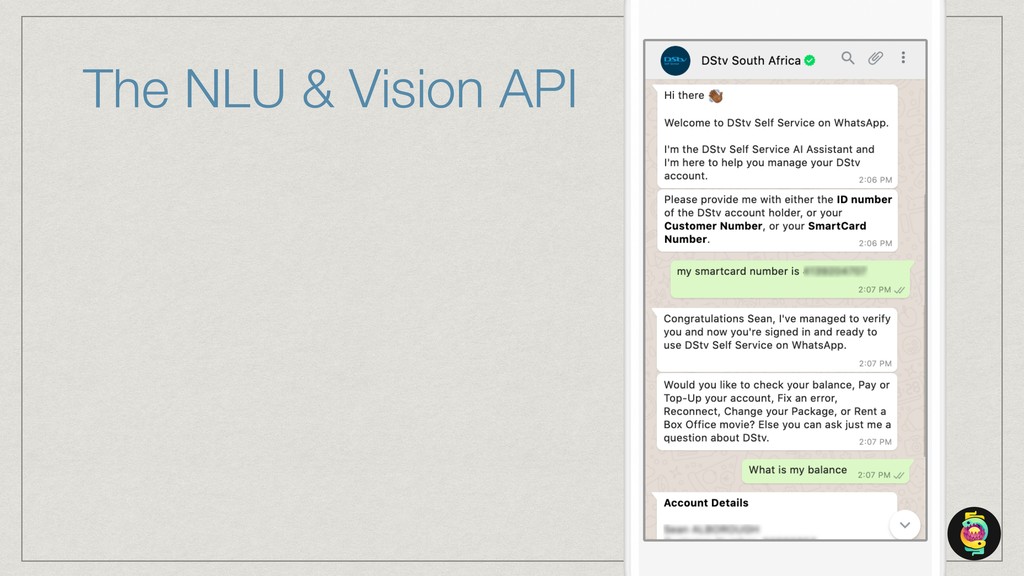
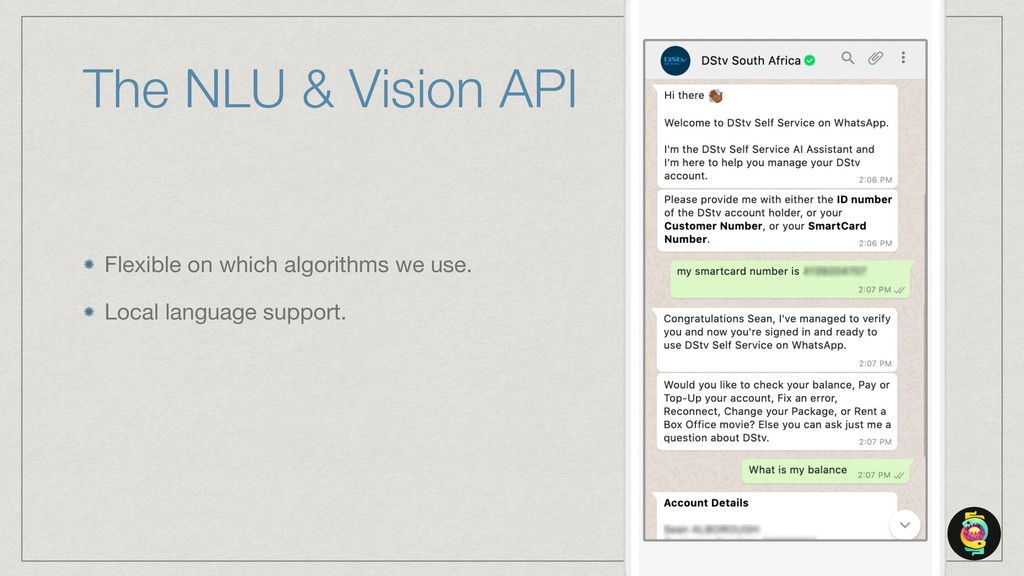
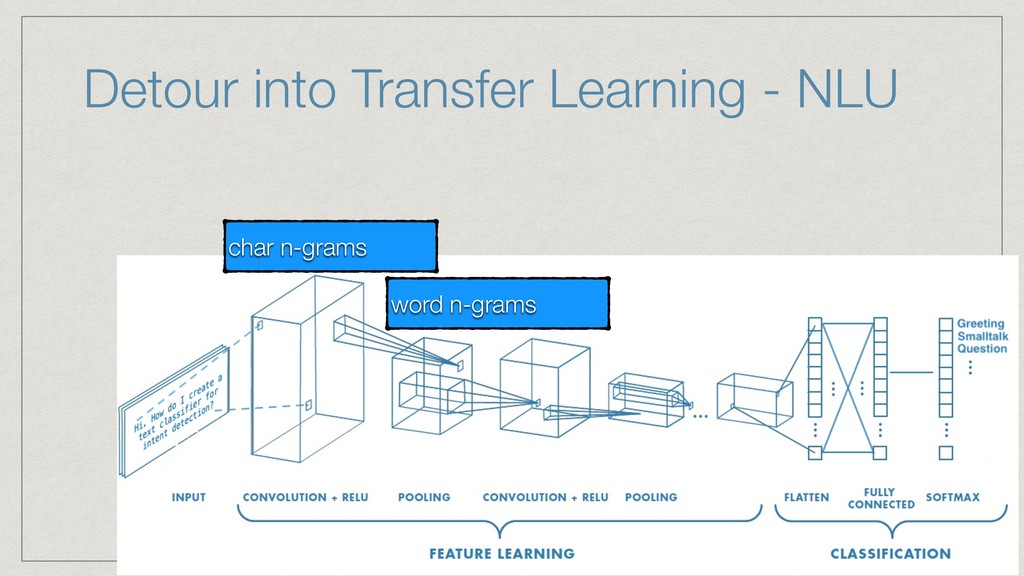
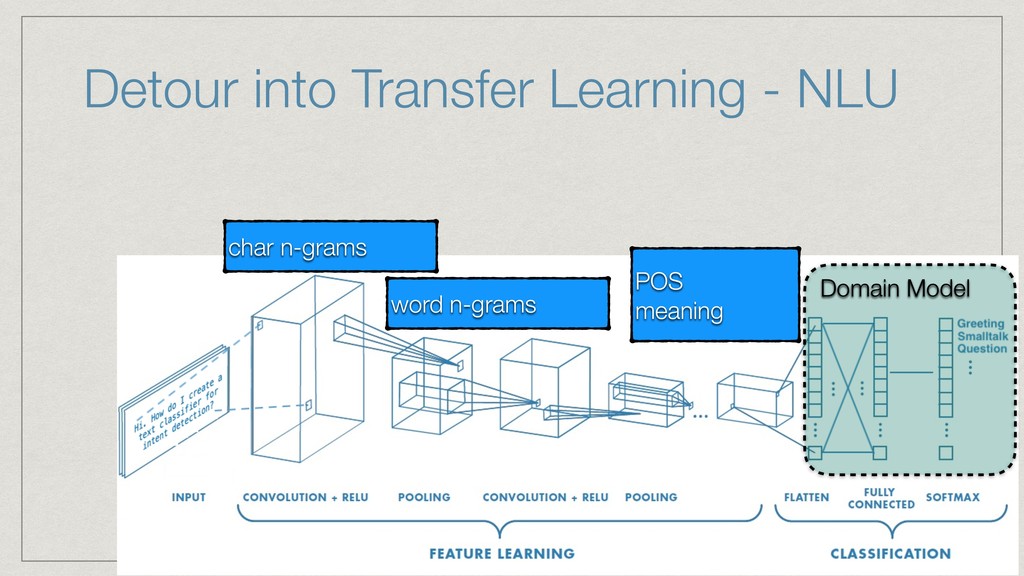
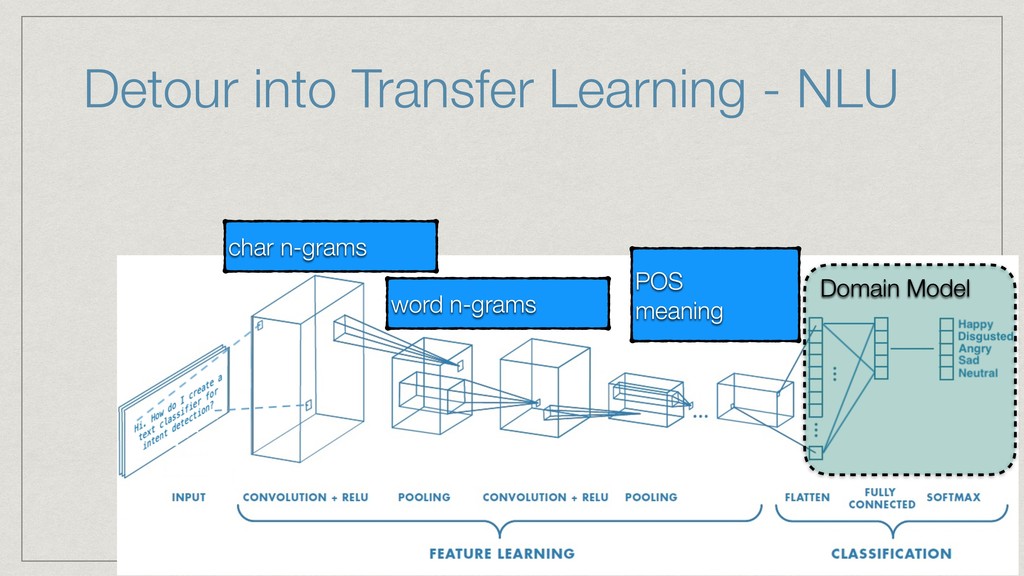
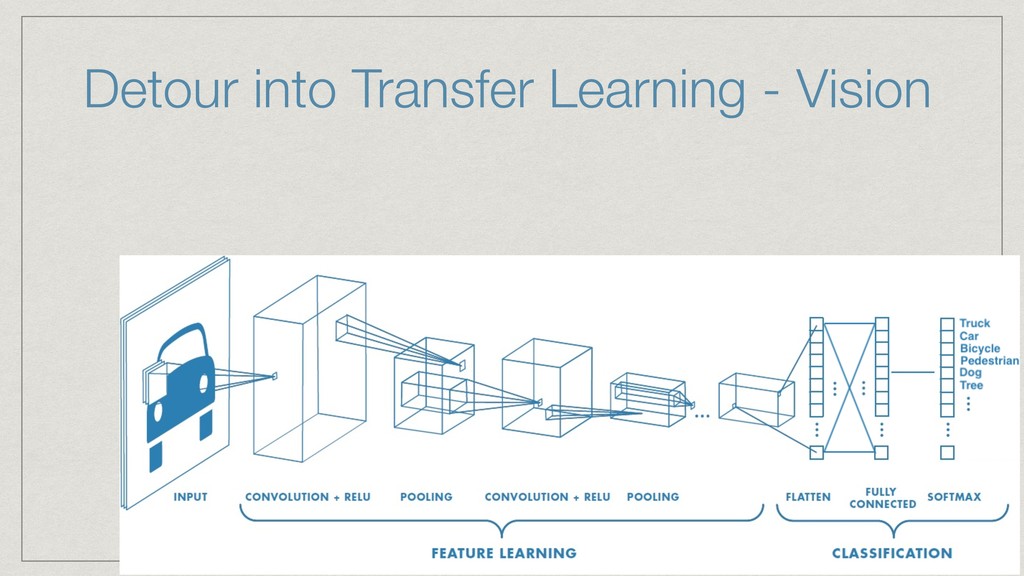
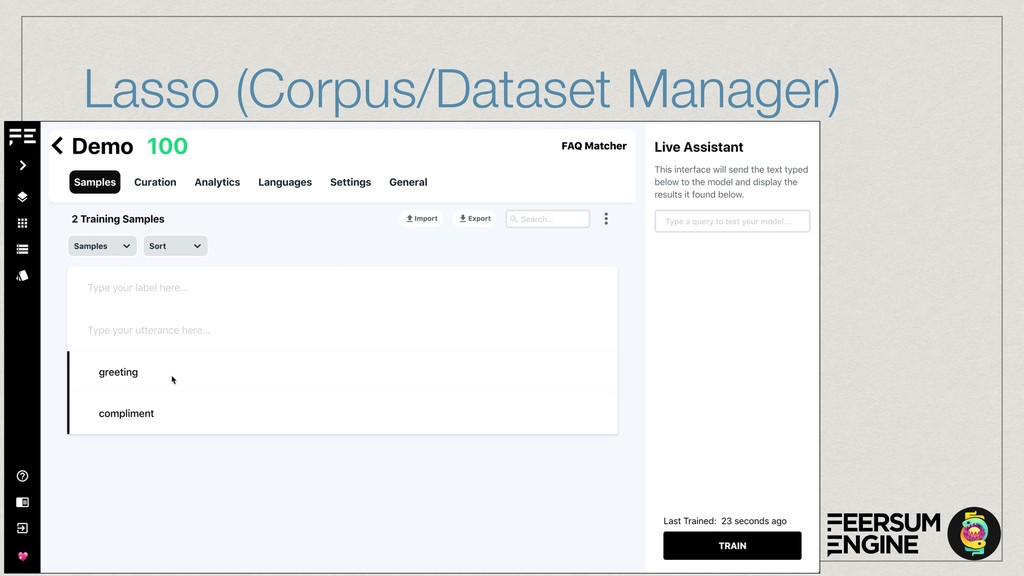
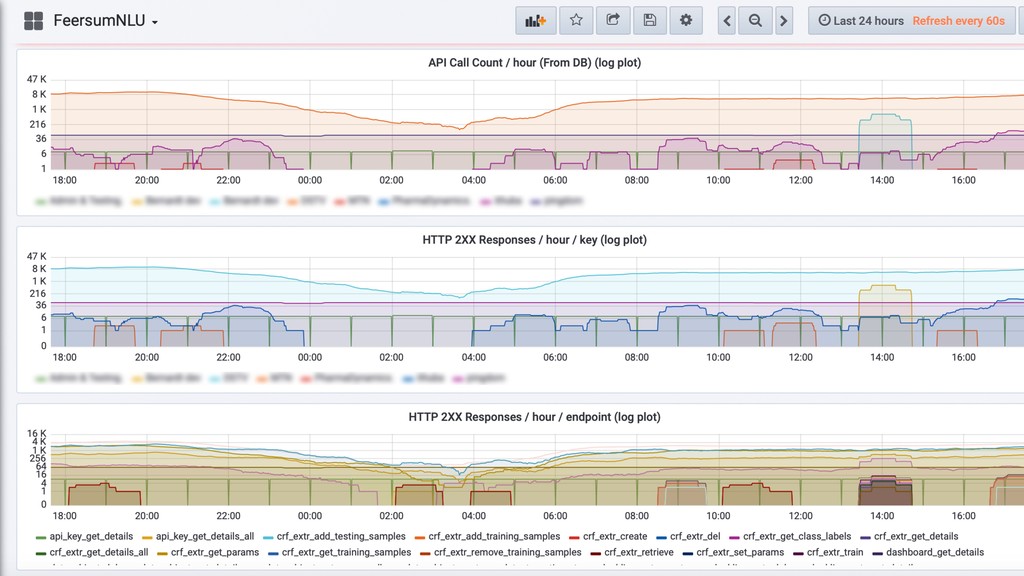
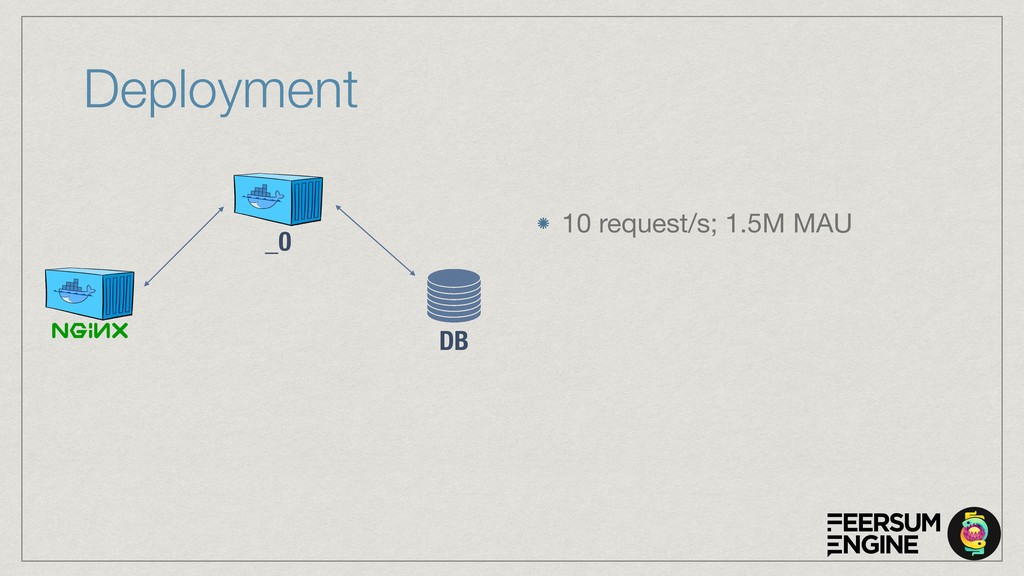
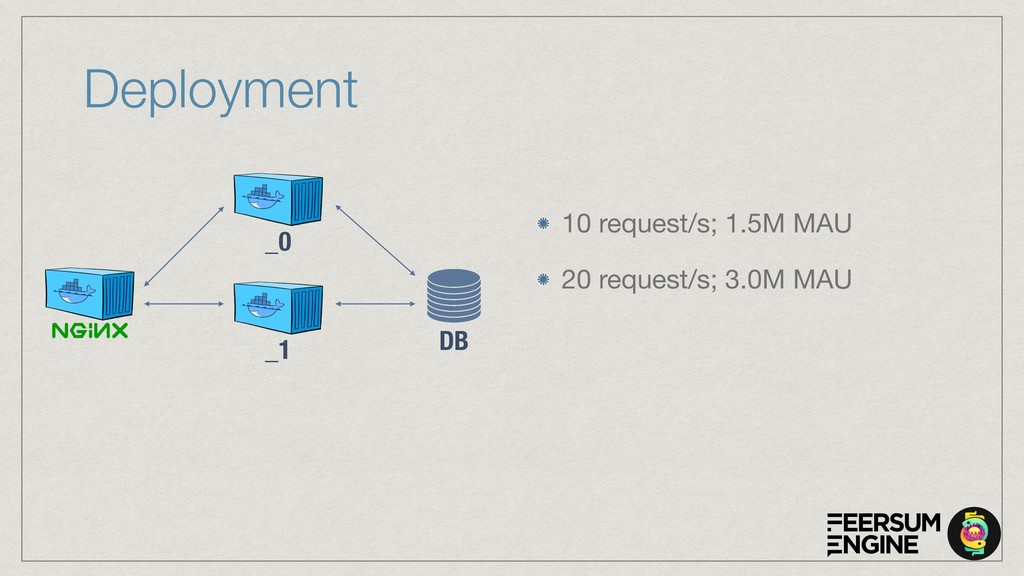
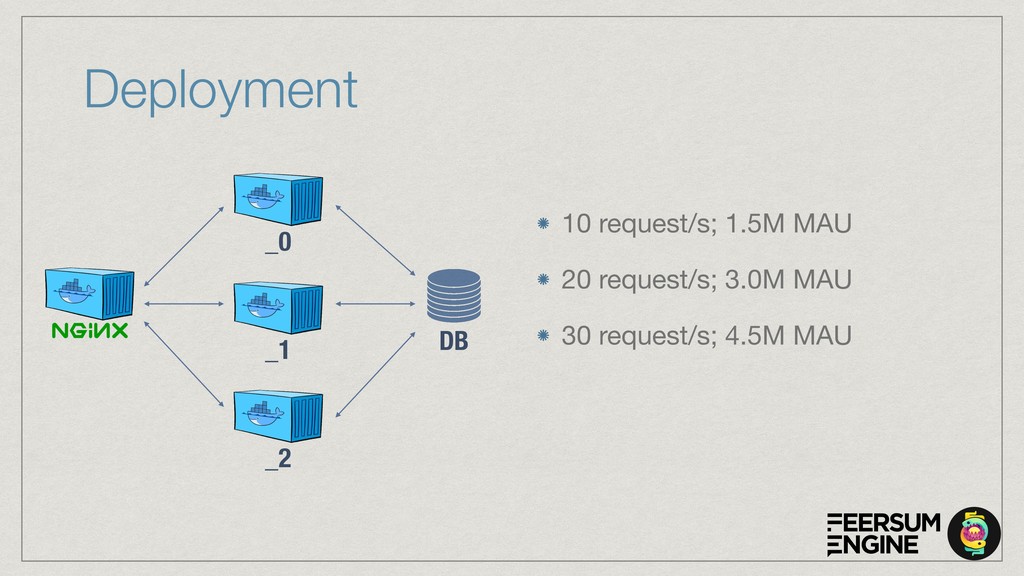
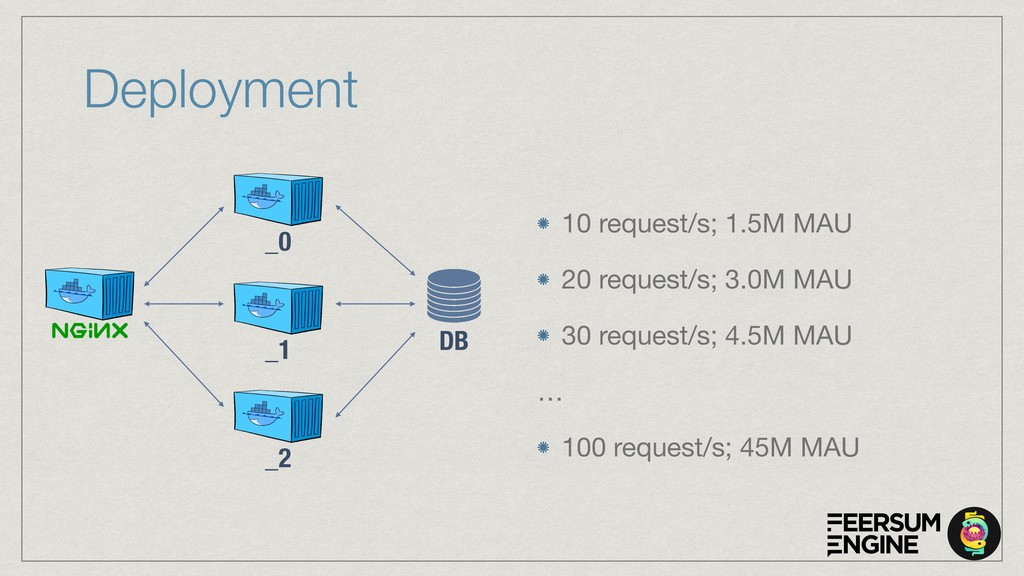
The talk will show how (and why) we’ve built our own natural language understanding and machine vision cloud service. The service is used mostly for intelligent dialog agents and the production instances see 5M+ queries a month.
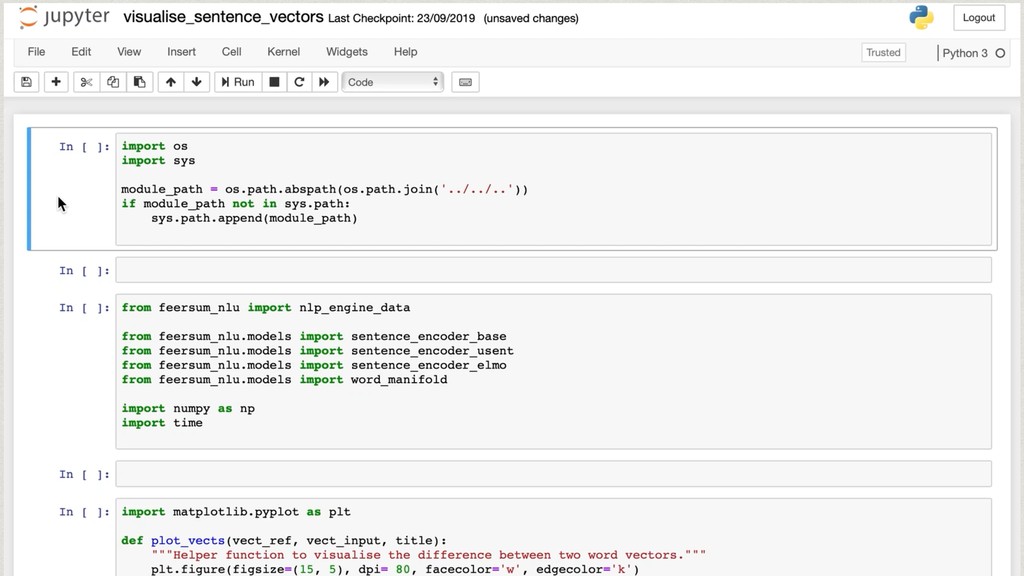
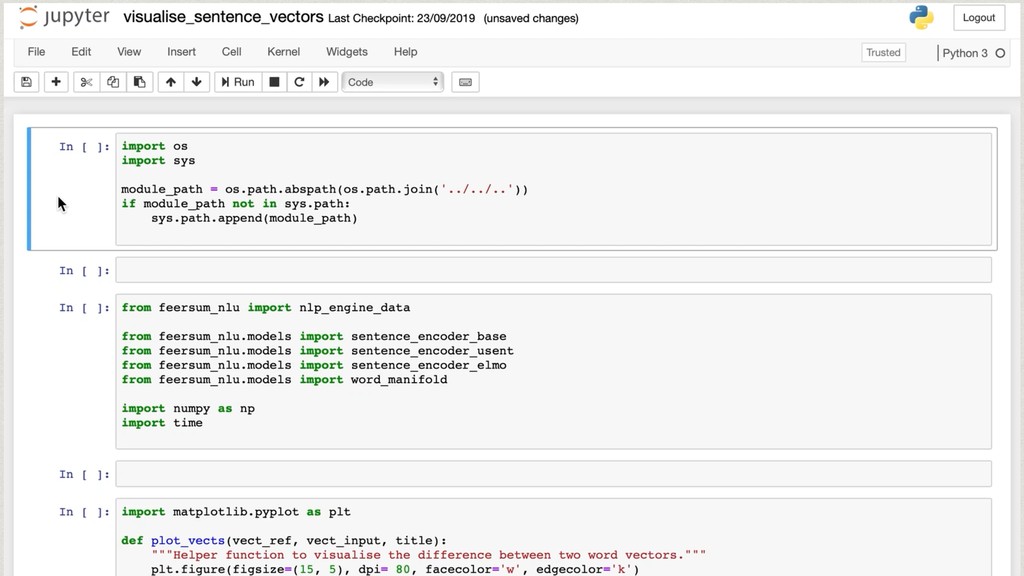
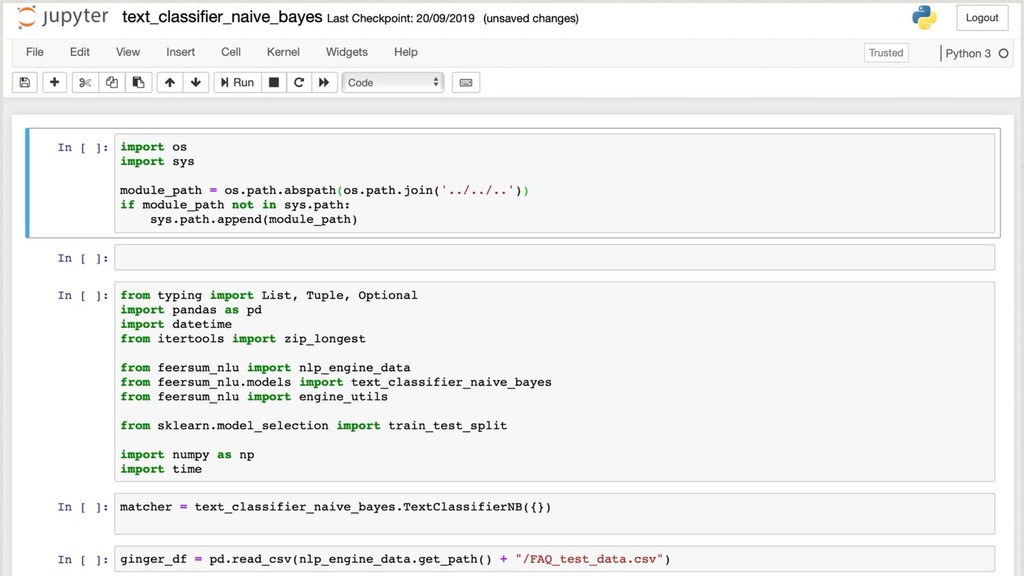
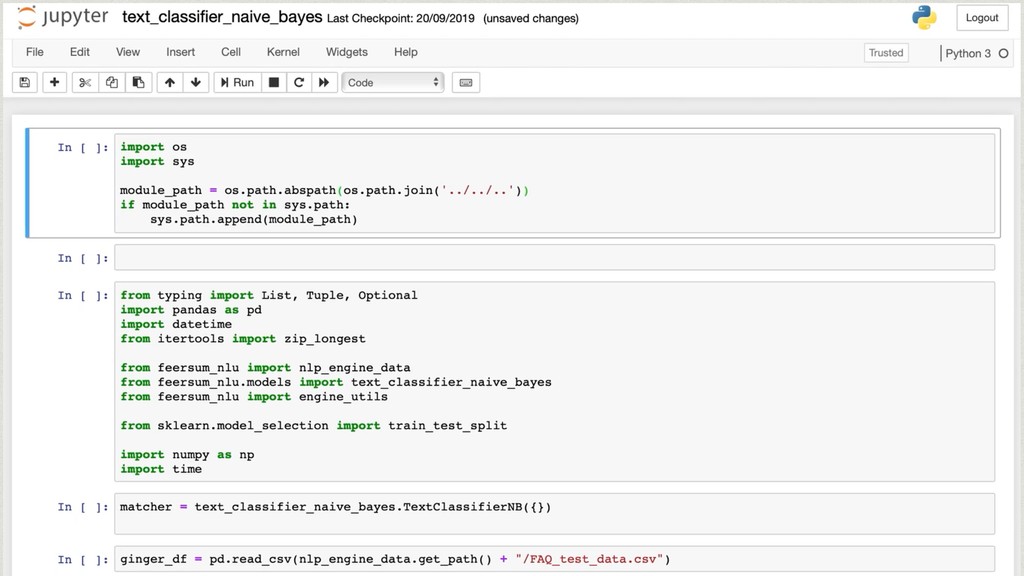
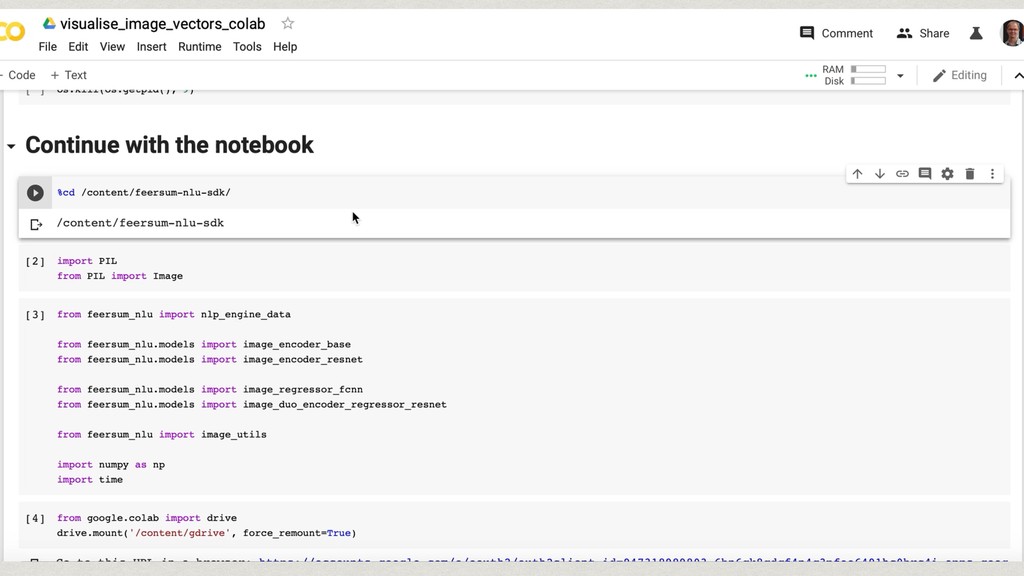
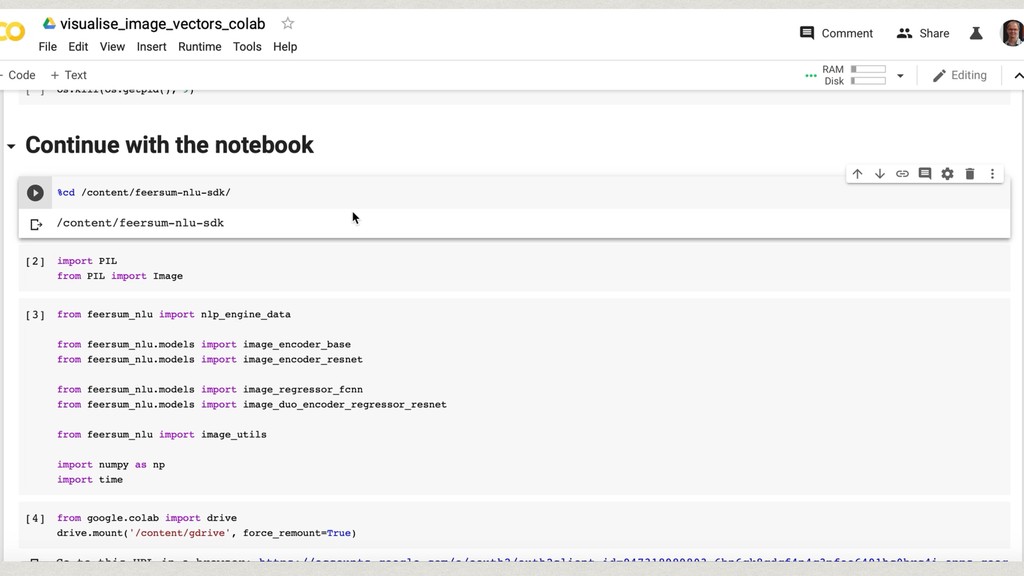
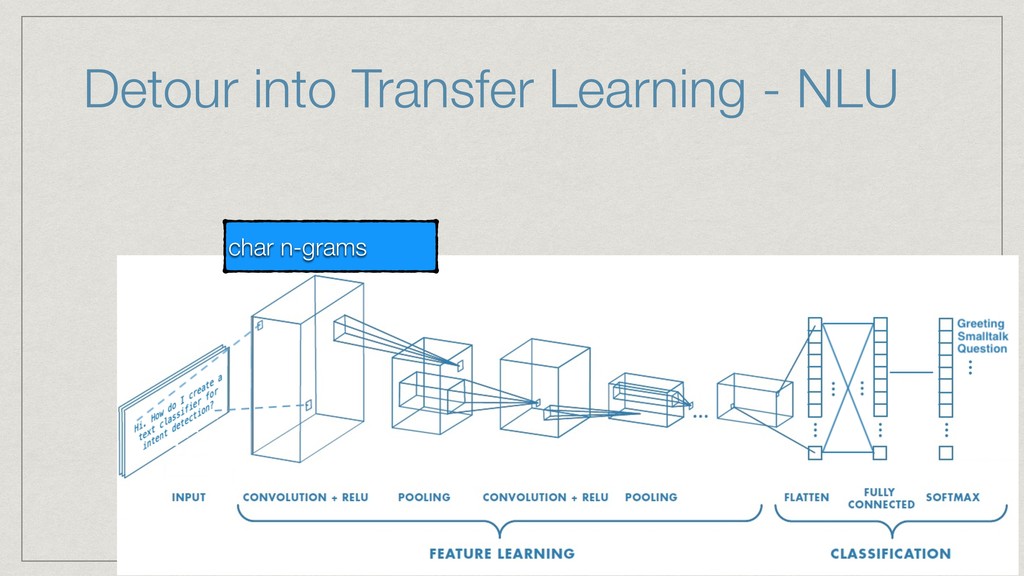
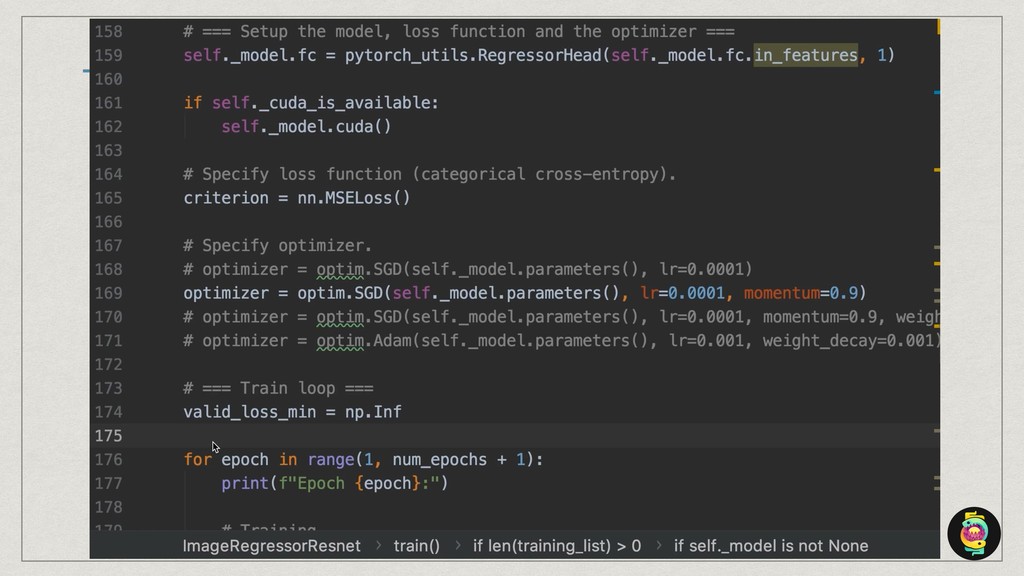
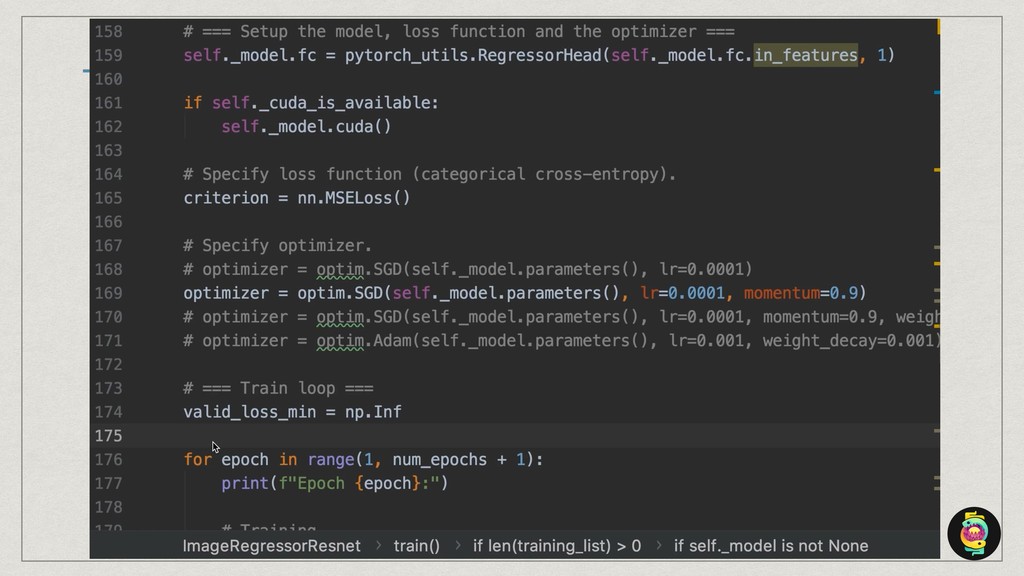
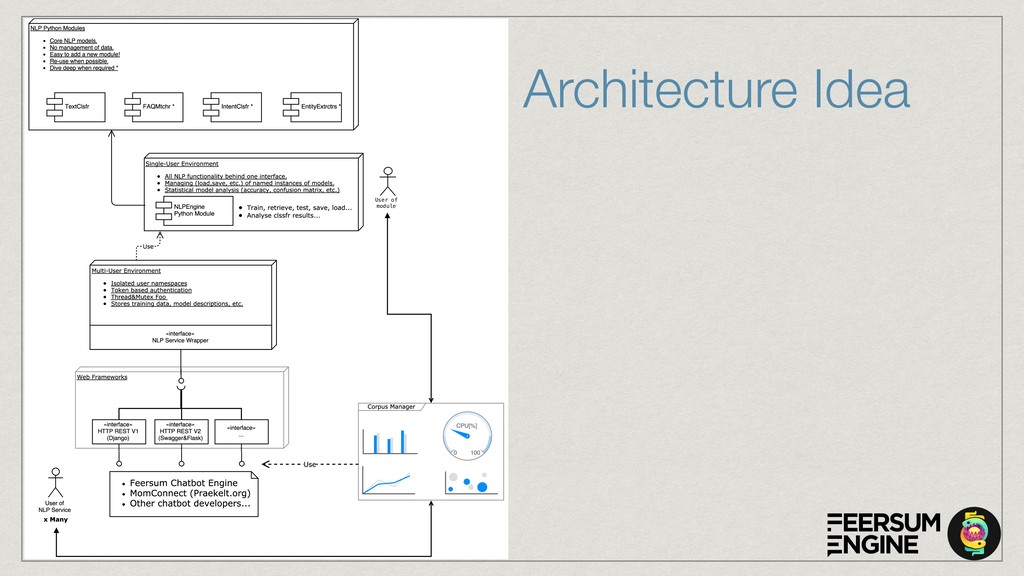
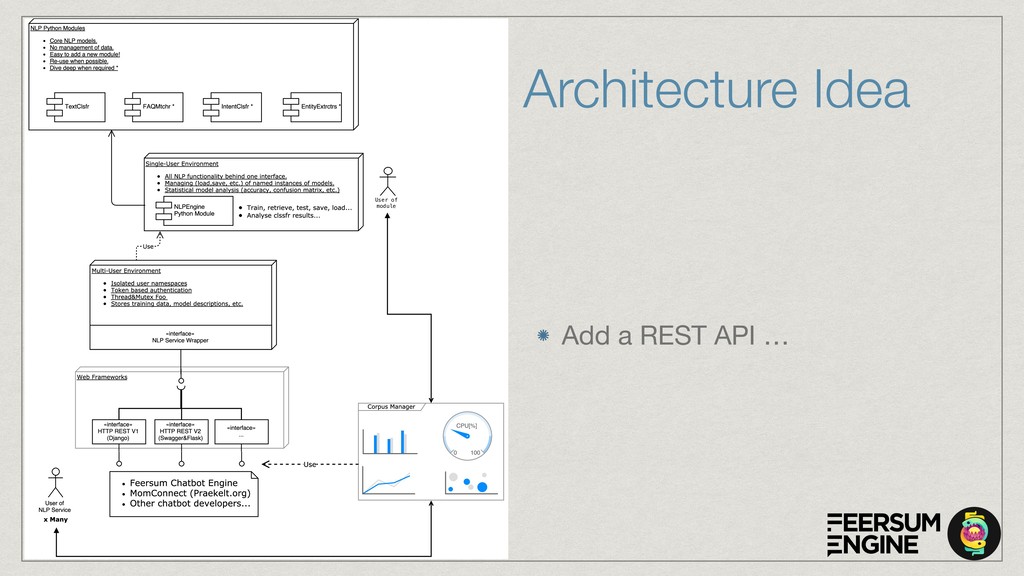
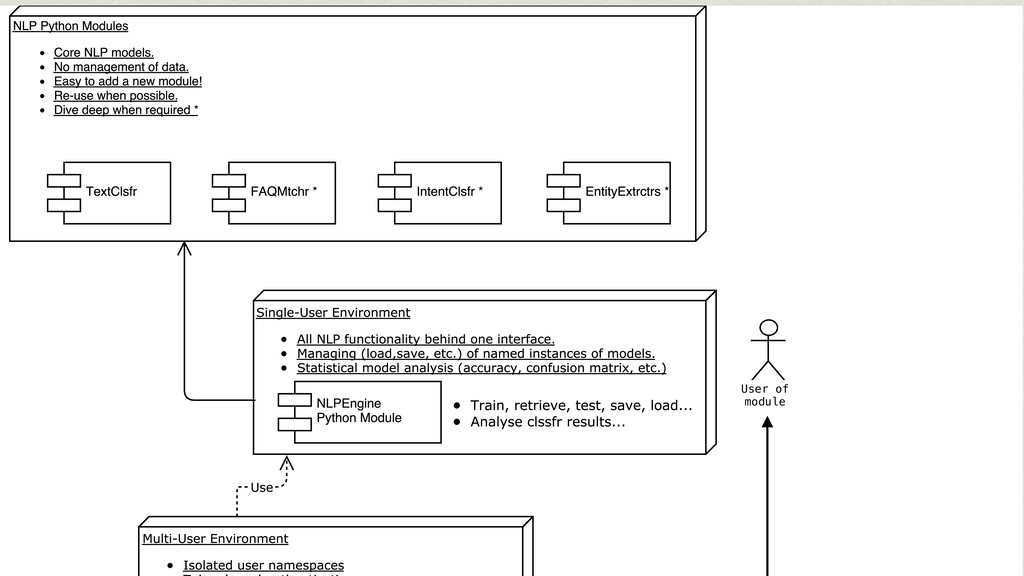
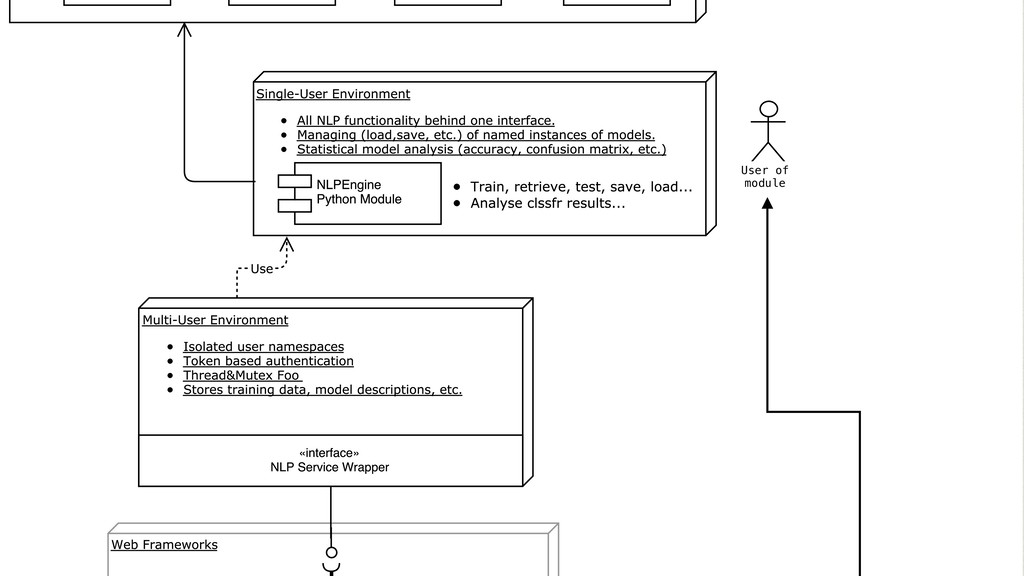
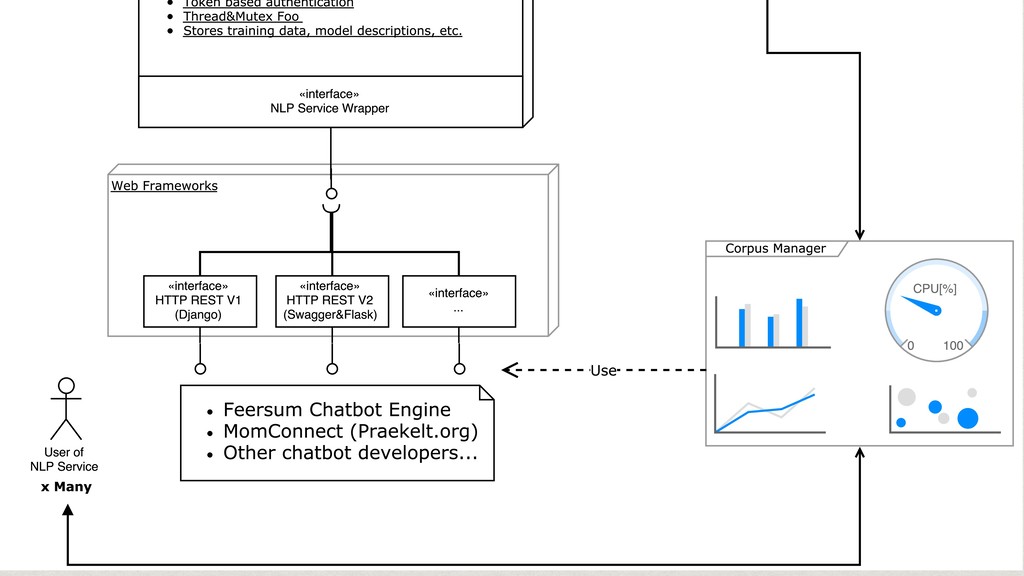
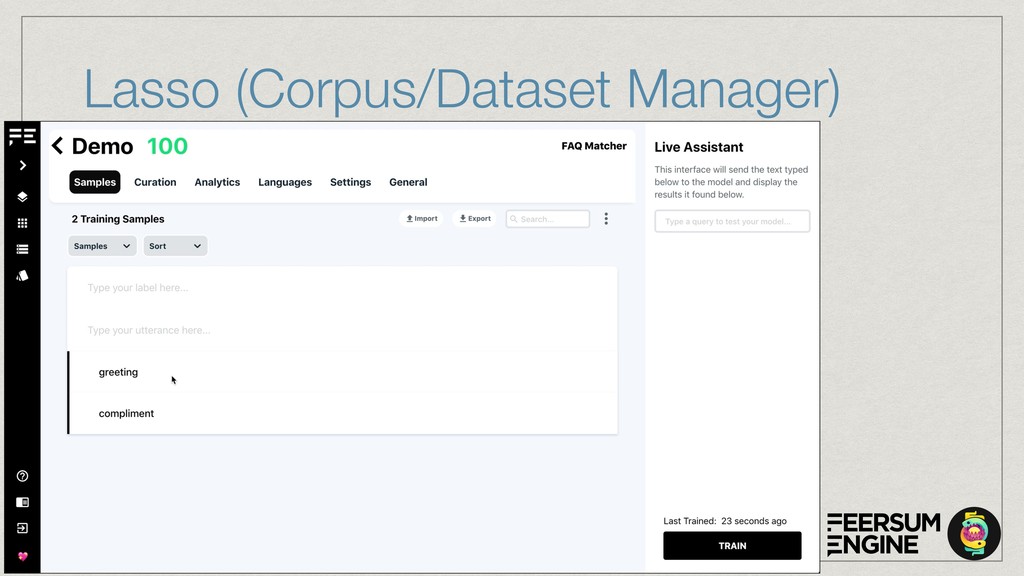
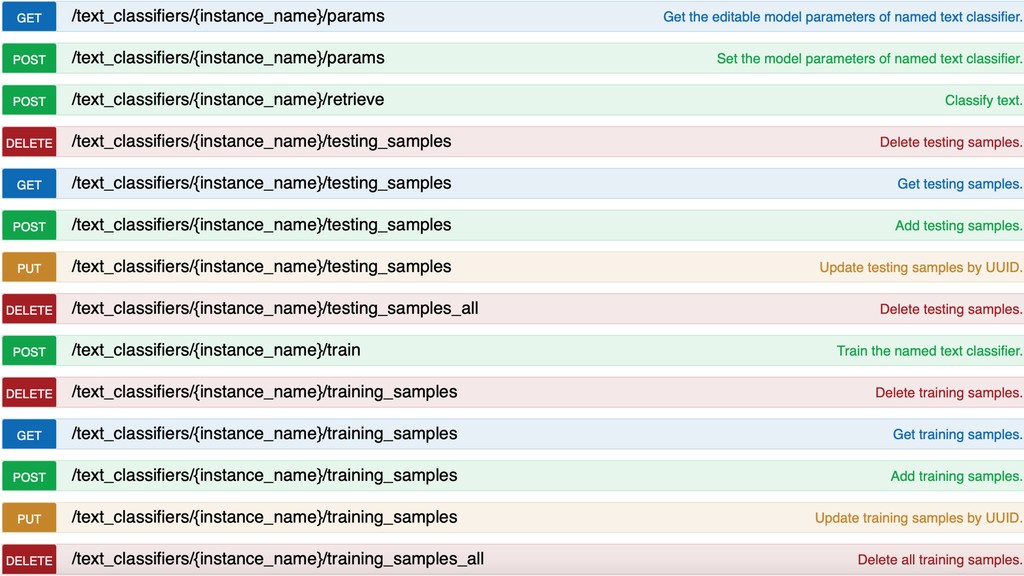
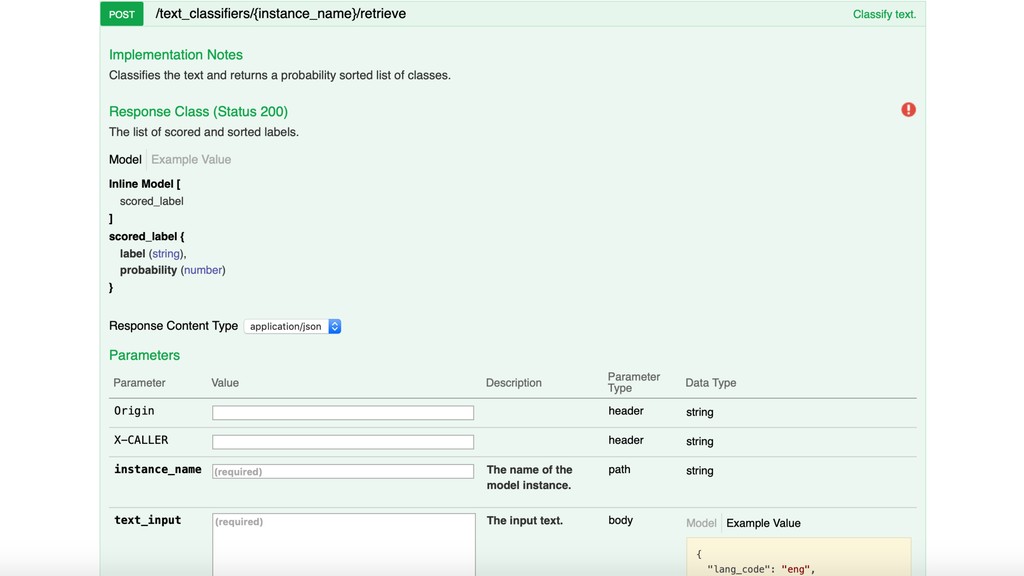
The core of the service is built with Python, NumPy, PyTorch, TensorFlow, OpenCV, TorchVision, scikit-learn and SQLAlchemy. We're undertaking to also build a framework within which machine comprehension models can be developed in isolation and have their own unit tests. The service and deployment related aspects (like dataset management, multi-tenancy and even the database interaction) are handled in a service layer that is well isolated from model development.
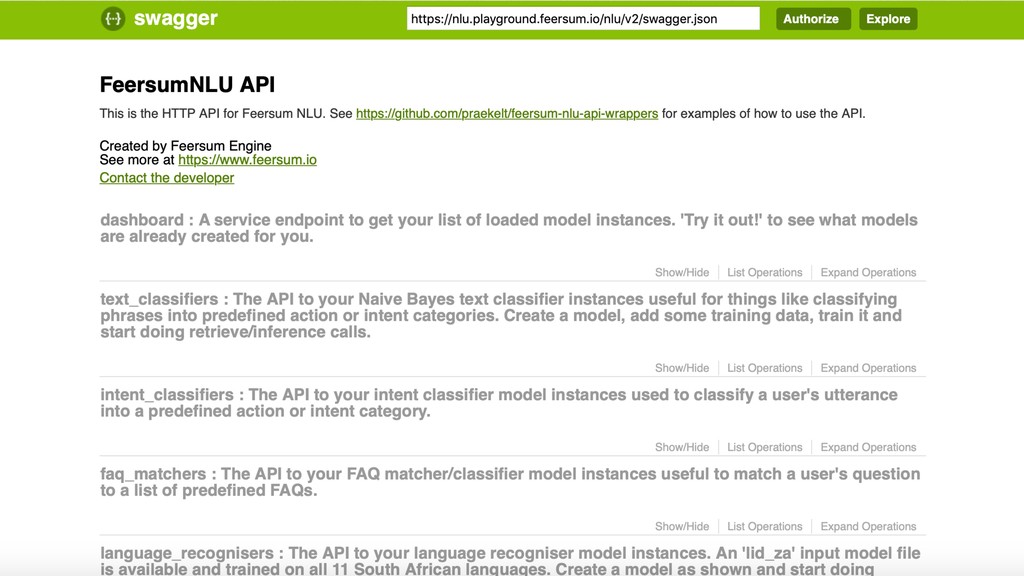
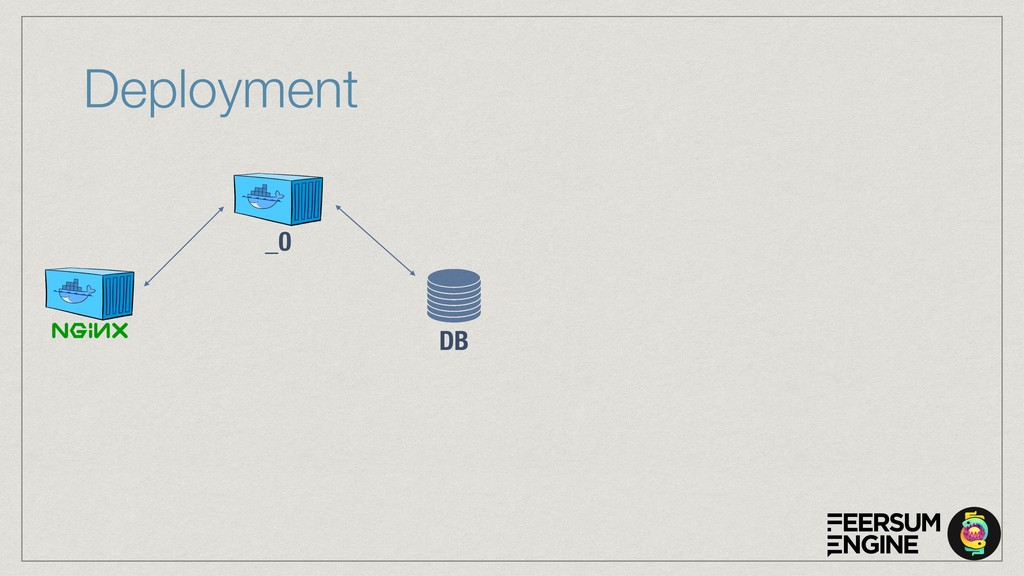
The cloud service is implemented with OpenAPI/Swagger & Connexion (Flask) to simplify development and maintenance. The connexion flask app is deployed using Gunicorn and we typically use NGINX as a reverse proxy and load balancer. The model DB is a shared PostgreSQL or Google CloudSQL DB. Everything is containerised and deployed on Kubernetes with Rancher.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}