As the world's data grows, so does its aptitude for AI.
In the context of business, however, translating black-box-magic into something more accessible for business-users to engage with is tricky. While this speaks to a larger problem of upskilling and making education more accessible, one method of translation is through story telling.
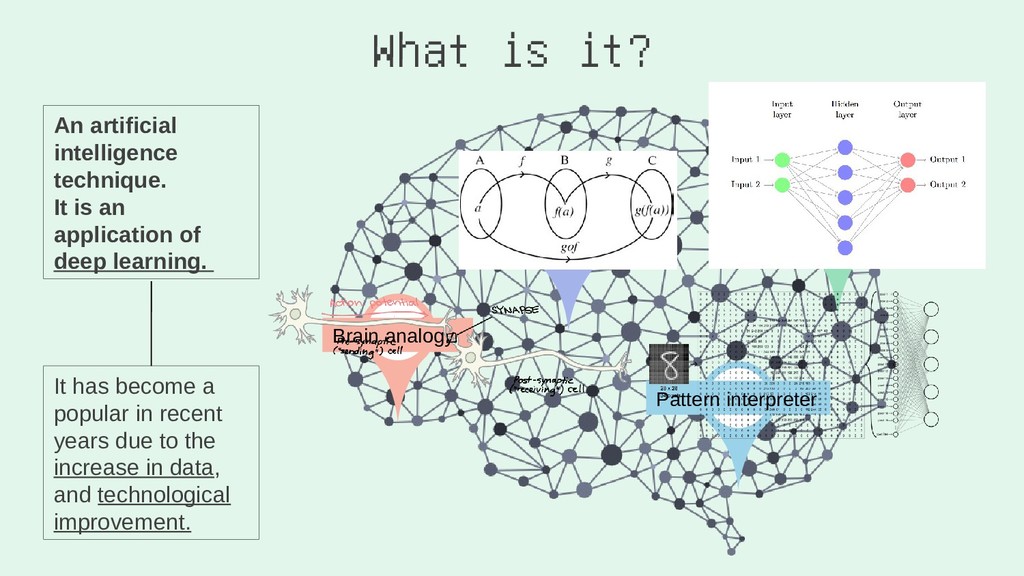
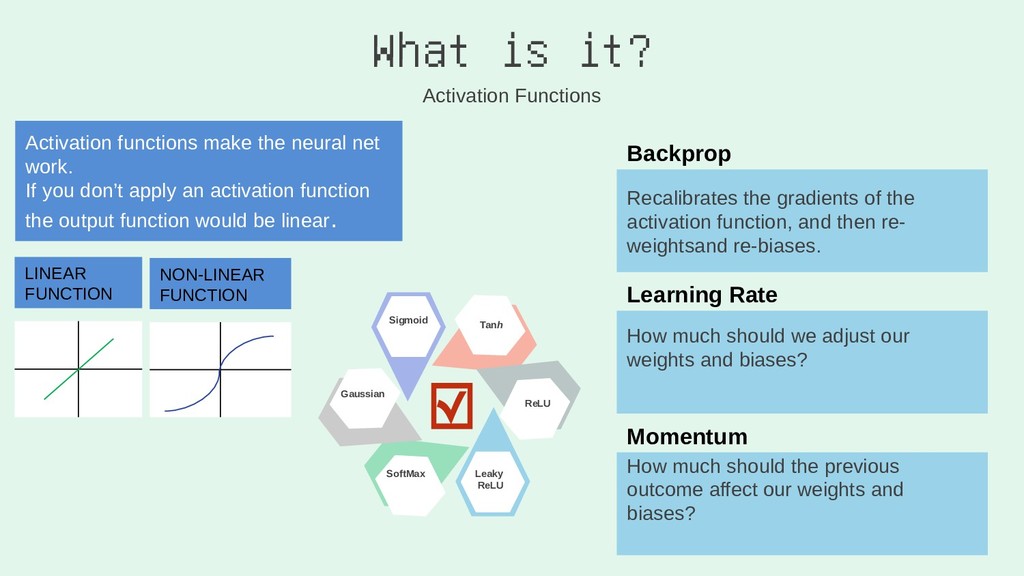
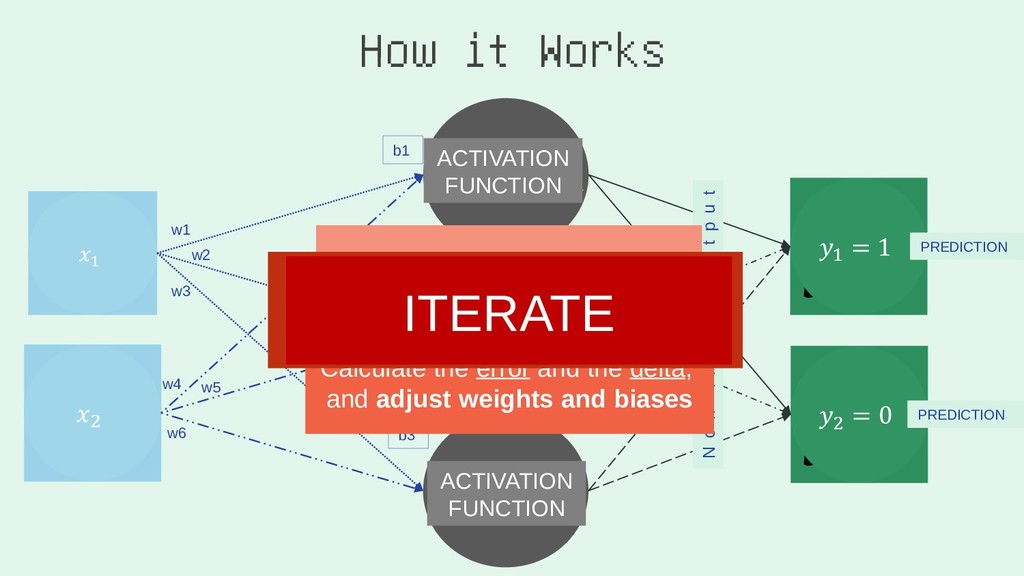
I learn best when an idea is relatable, simple, and colourful. This talk is going to look at how to convey complex ideas simply. I'm going to be covering two sections:
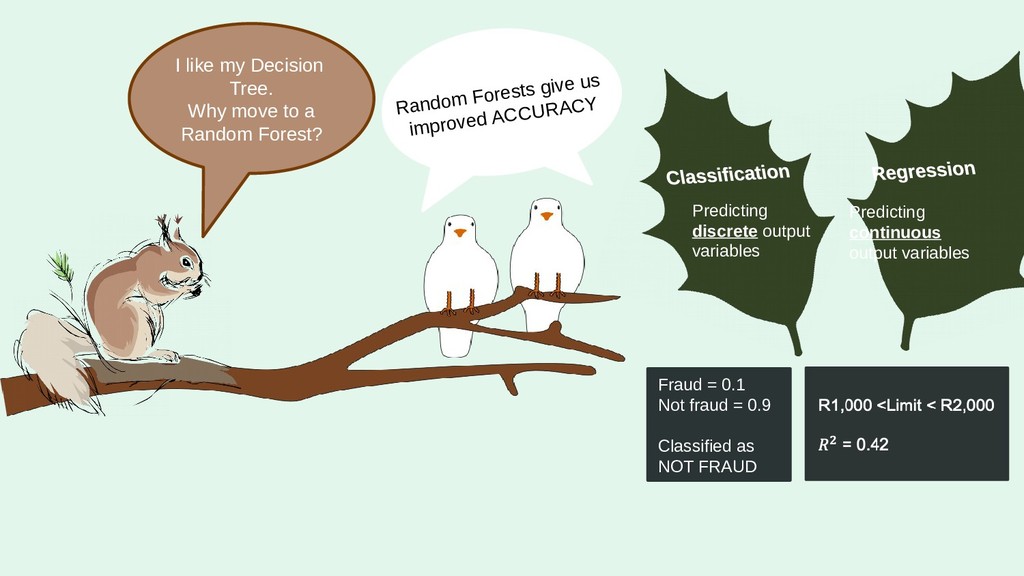
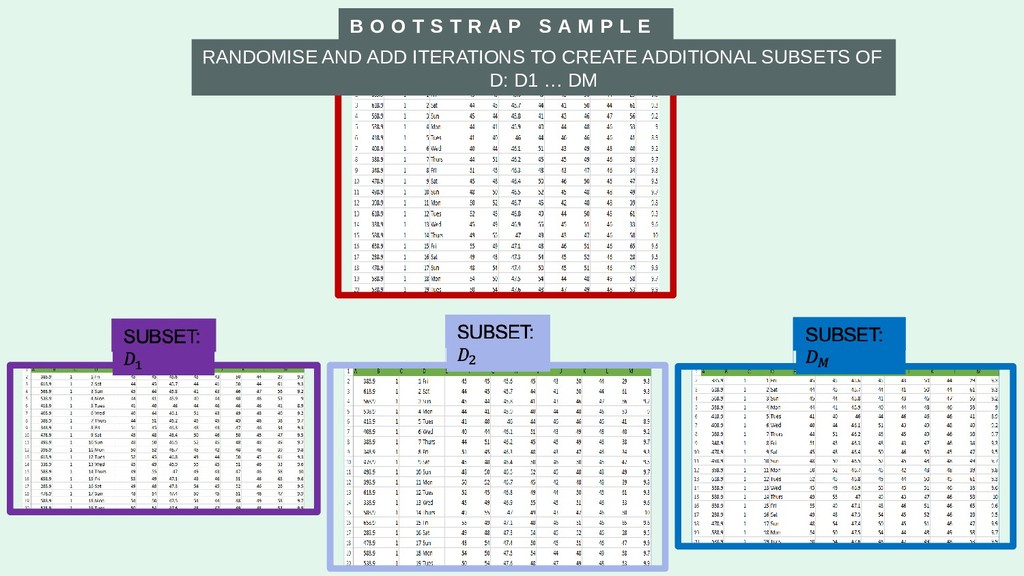
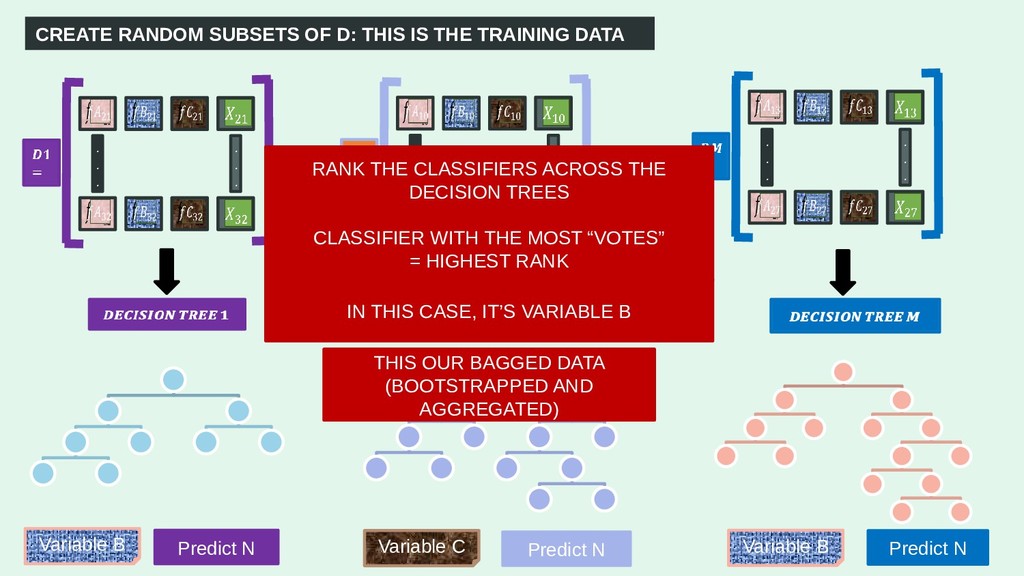
1. That's So Random (Forests)!
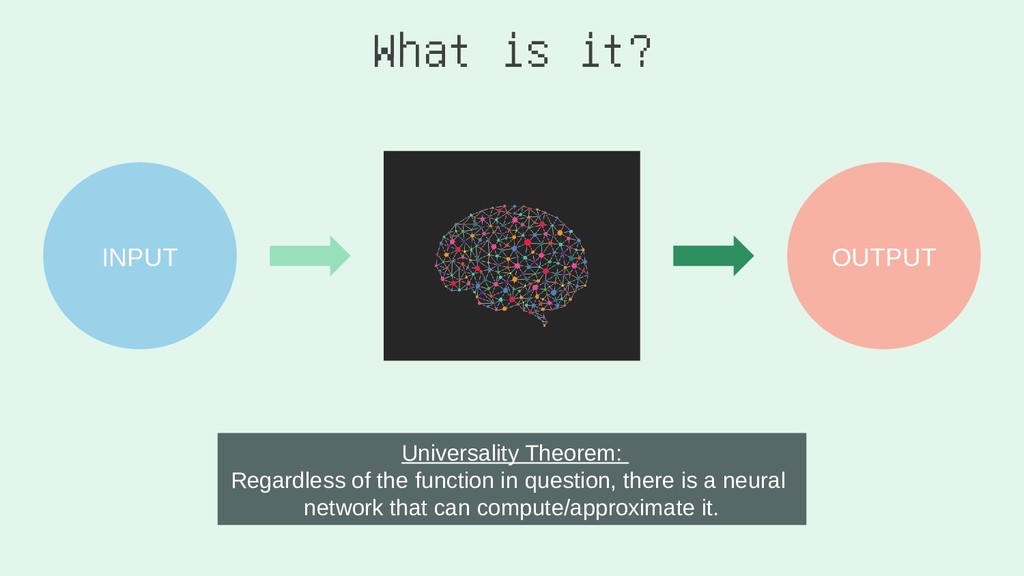
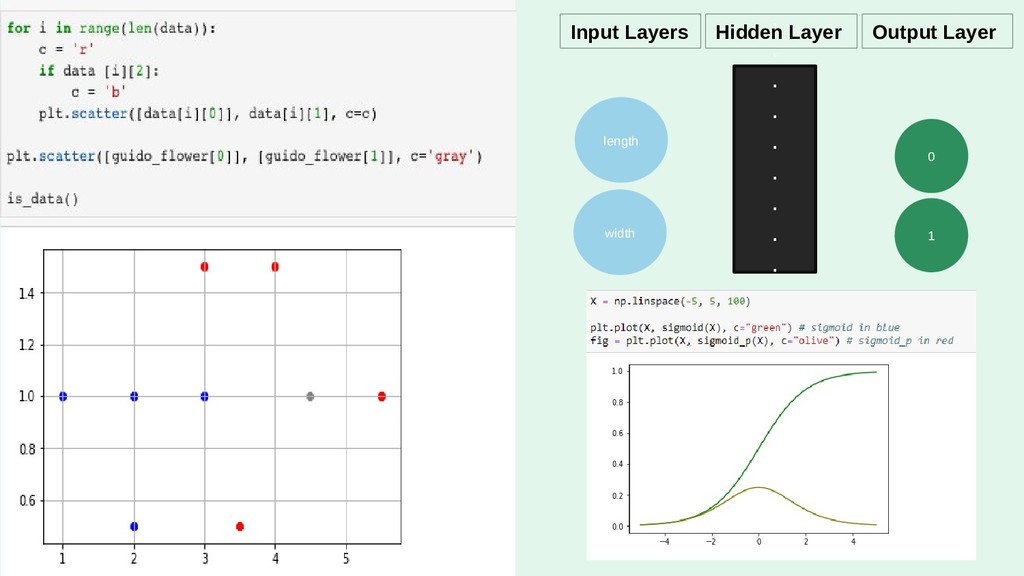
2. You Gotta (Neural) Network to Get Work
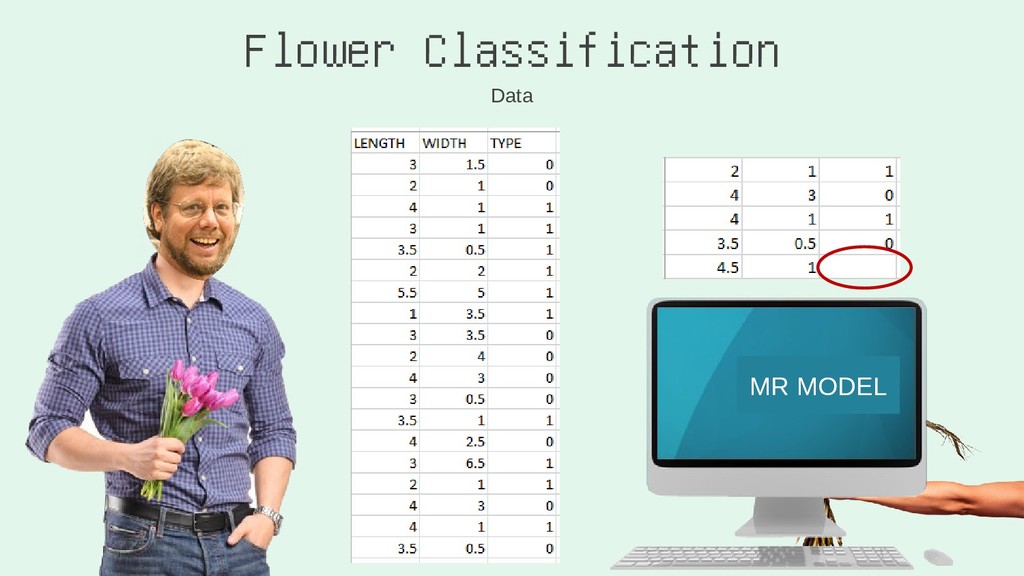
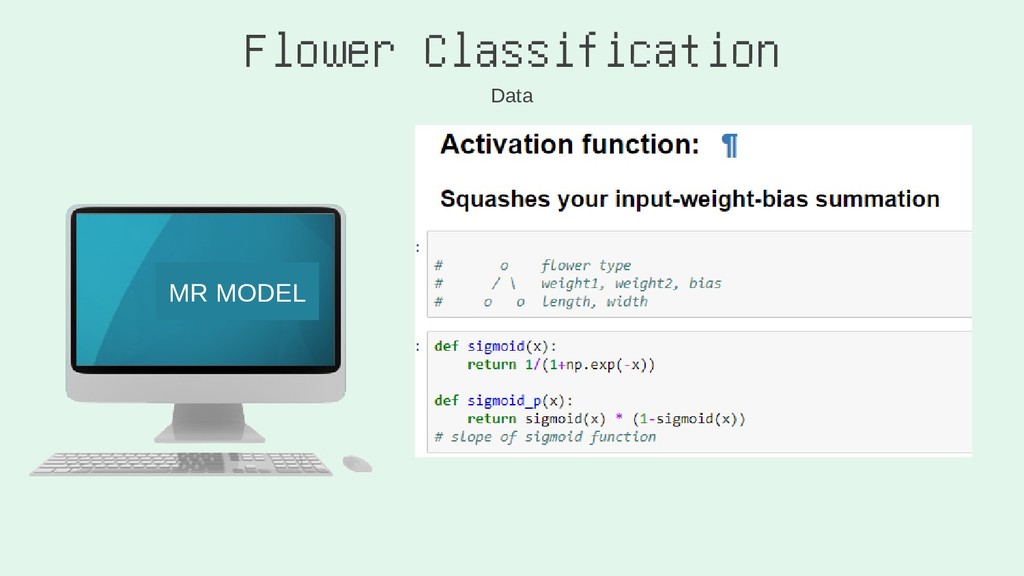
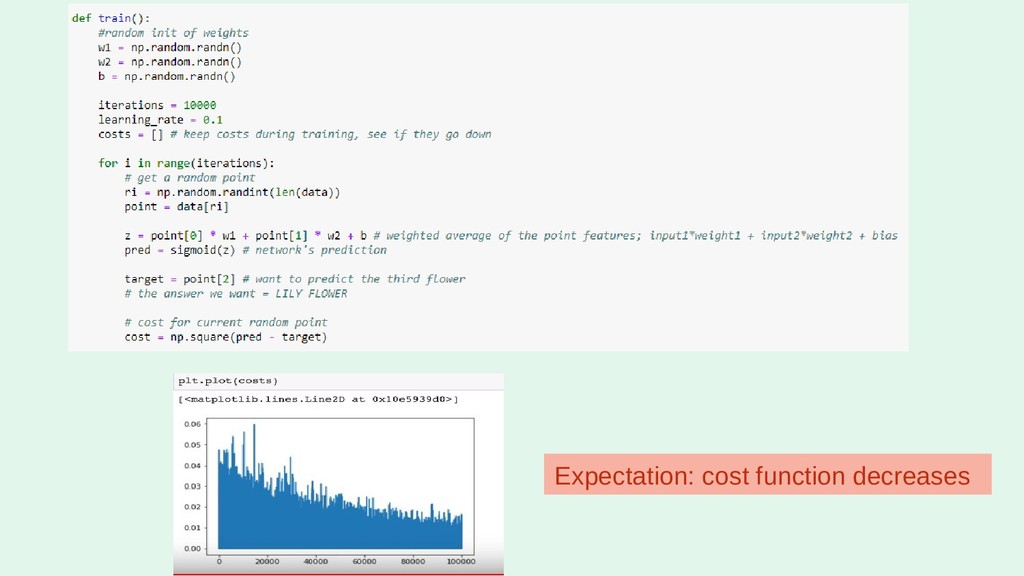
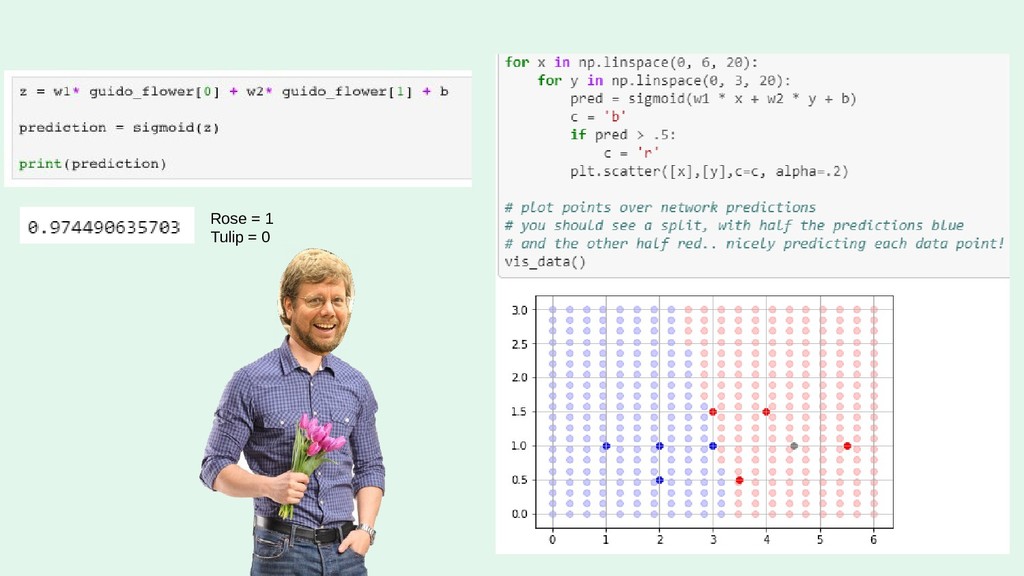
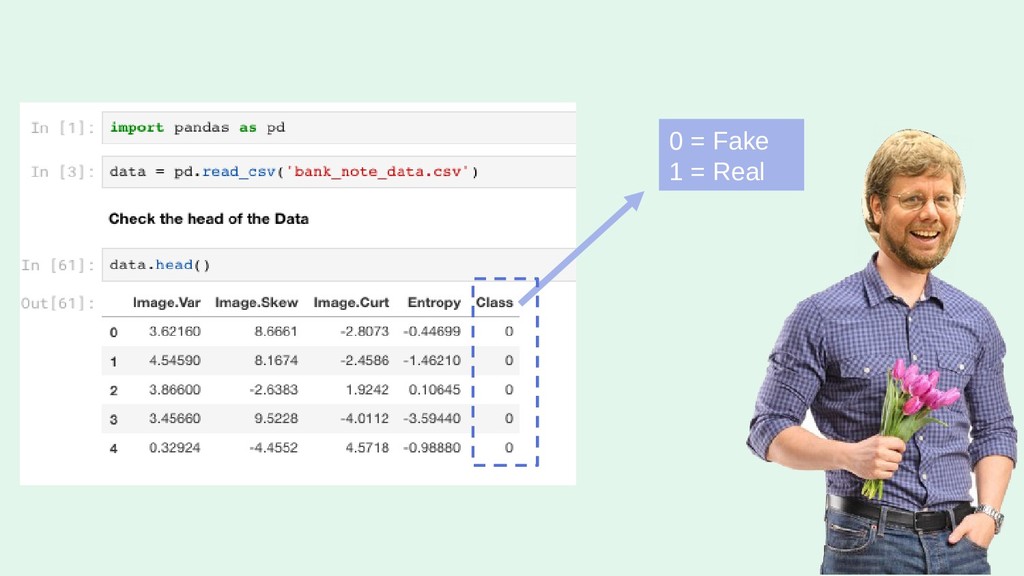
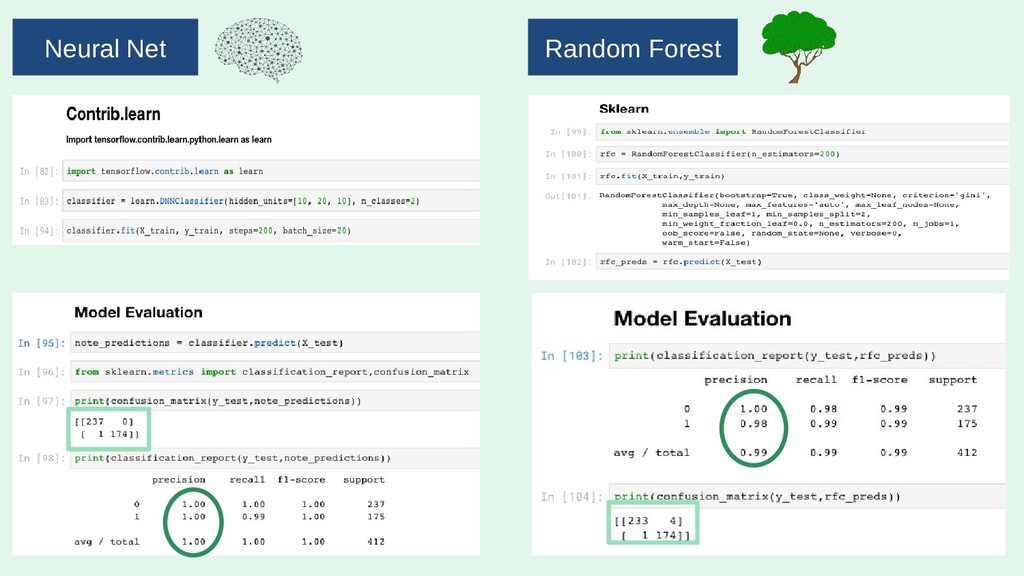
I'll run through the high level concepts and methodologies, and then show the work/code that was done to create a random forest, and a neural network. Note: this will cover how I built the RF, and NN using Python via Jupyter Notebook.
This session is for anyone who uses/wants to use ML to solve problems but struggles with translating the black-box-magic.
It's going to be an engaging, and slightly animated, talk with the intention of reinforcing concepts and showcasing different ways of explaining them.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}