Убедимся, что парсинг - не вымышленная задача • Разберём несколько способов парсинга • Рассмотрим типичные проблемы и их решения • Введения в лексический анализ и парсинг • Подробнейшего разбора какого-то из инструментов • Академической точности
Убедимся, что парсинг - не вымышленная задача • Разберём несколько способов парсинга • Рассмотрим типичные проблемы и их решения • Введения в лексический анализ и парсинг • Подробнейшего разбора какого-то из инструментов • Академической точности ✅
Убедимся, что парсинг - не вымышленная задача • Разберём несколько способов парсинга • Рассмотрим типичные проблемы и их решения • Введения в лексический анализ и парсинг • Подробнейшего разбора какого-то из инструментов • Академической точности А ещё будут бенчмарки! ✅
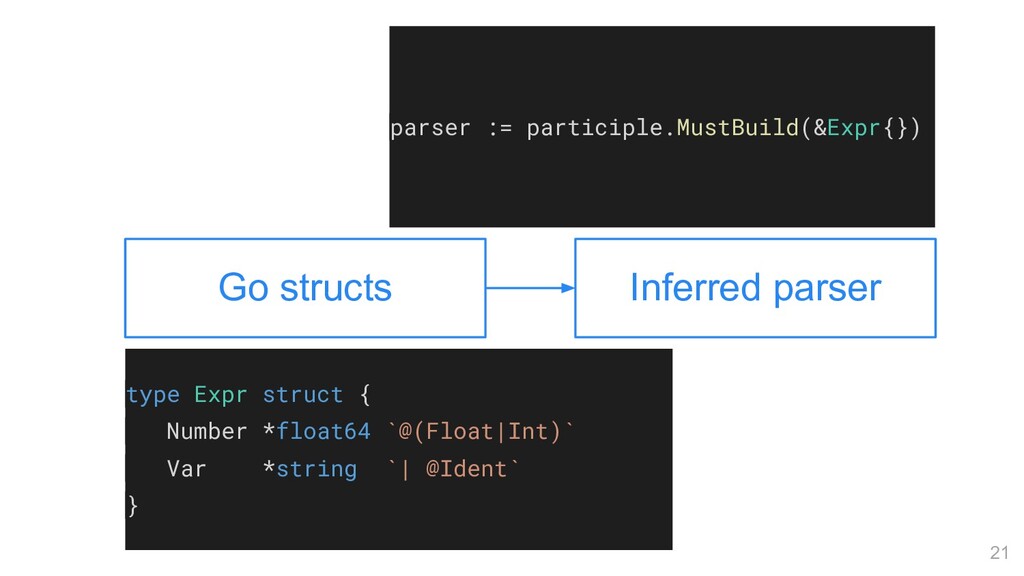
@<expr> Парсим expr, кладём в поле @@ Парсим по типу поля, кладём туда же Ident, Int, ... Парсим именованный токен "foo" Парсим токен с ровно таким текстом <expr> | <expr> Парсим альтернативы (or) <expr>* Парсим expr 0-n раз (результат - слайс) <expr>? Парсим expr 0-1 раз
утилиты типа yacc • Легко парсить простые форматы • Может получиться не очень удобное AST • Нет простых способов работы с приоритетами операторов • Парсер может получиться медленным Плюсы participle (+) Минусы Participle (-) 34
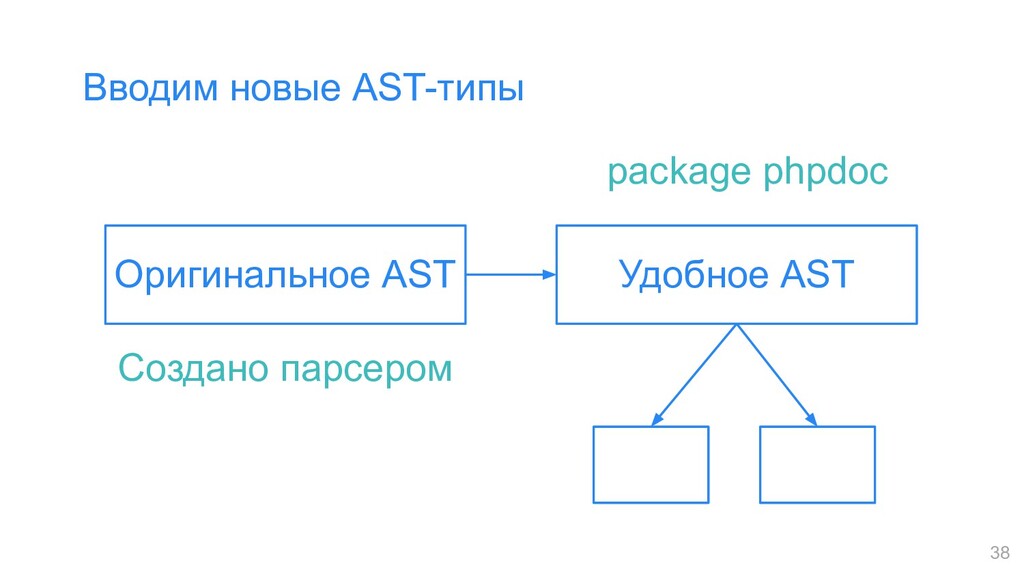
UnionType struct { Left Type Right Type } type ClassName struct { Parts []string } type Type interface { String() string } type IntersectionExpr struct { Left *PostfixExpr `@@` Right *IntersectionExpr `("&" @@)?` } type UnionExpr struct { Left *IntersectionExpr `@@` Right *UnionExpr `("|" @@)?` } type ClassNameExpr struct { Part string `@Ident` Next *ClassNameExpr `("\\" @@)?` } Новое AST 👍 Старое AST 👎 39
do the lexing. It also stores // the parse result inside itself. type yyLex struct { s scanner.Scanner result phpdoc.Type } Вводим заготовку для лексера 50
do the lexing. It also stores // the parse result inside itself. type yyLex struct { s scanner.Scanner result phpdoc.Type } Вводим заготовку для лексера 51 yy?! дефолтный префикс для yacc
<tok> T_FLOAT %token <tok> T_STRING %token <tok> T_BOOL %token <text> T_NAME phpdoc.y: декларация токенов 57 Ассоциированные id токенов Для них будут созданы константы
if tok == scanner.Ident { text := l.s.TokenText() if tok, ok := nameToToken[text]; ok { return tok } sym.text = text return T_NAME } return tok } Реализуем лексер 67
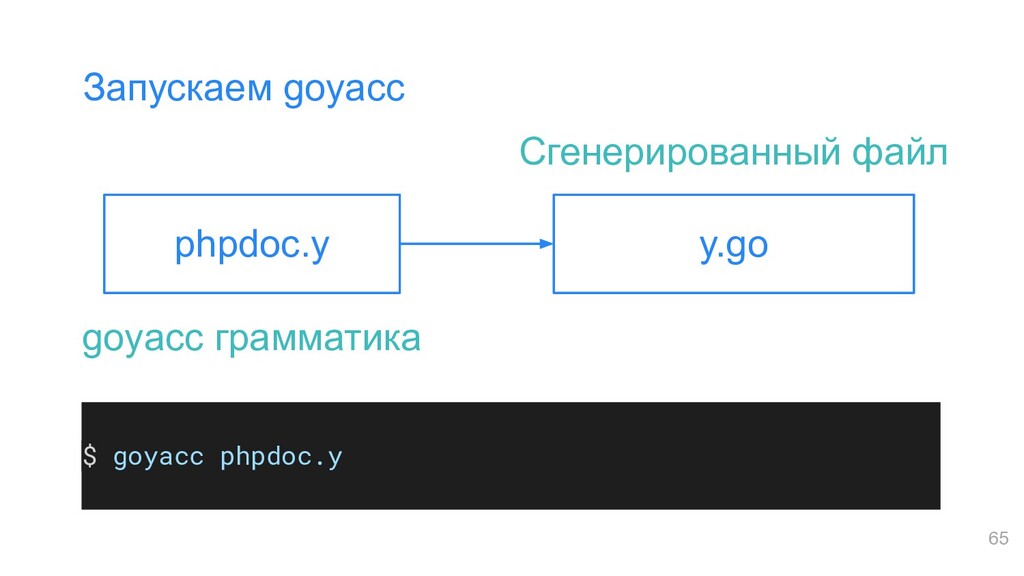
• Удобно описывать приоритеты и ассоциативность • Требует стороннюю утилиту (goyacc) • Не очень красивая интеграция с Go (но в целом ОК) Плюсы goyacc (+) Минусы goyacc (-) 71
// текущее смещение (внутри data) pe := len(data) // позиция окончания eof := pe // позиция EOF // ts и te - это начало/конец токена var cs, ts, te, act int Boilerplate 80
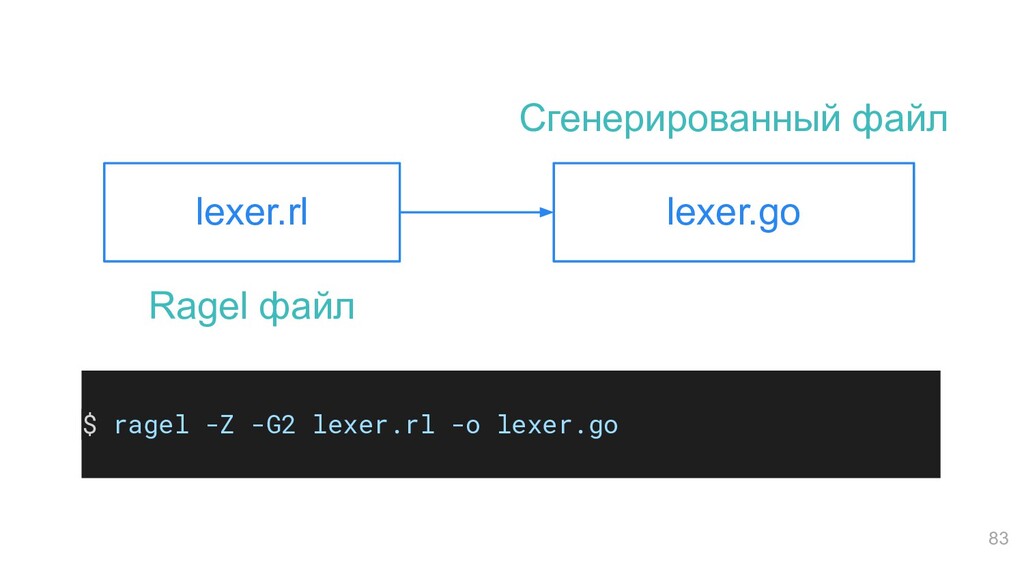
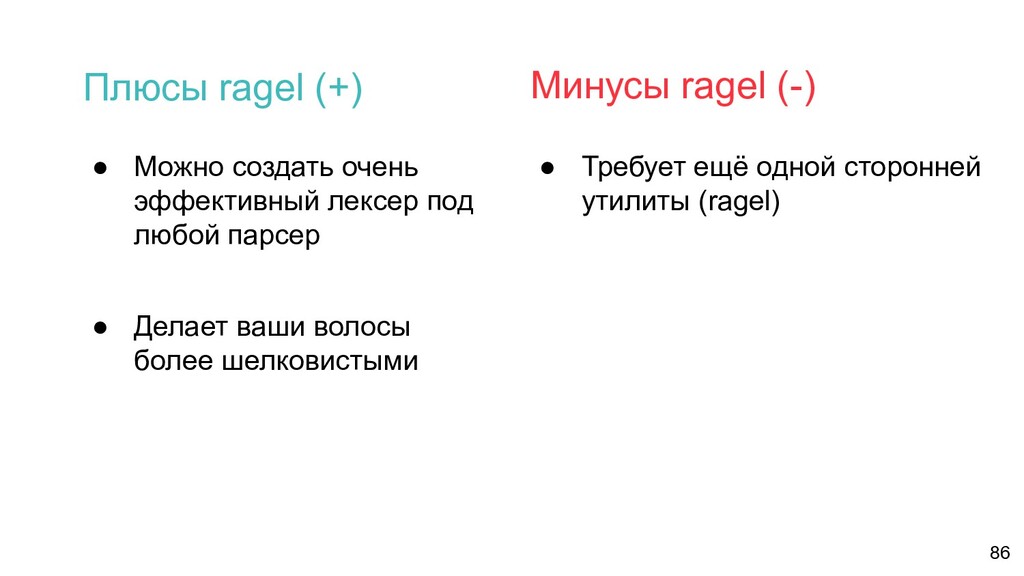
использовании (лучше golex) • Полезен не только для лексеров/парсеров Почему именно Ragel, а не golex? 85 Рандомный факт: php-parser когда-то использовал golex вместо ragel
• Написать грамматику для формата слишком сложно • Нужно разбирать частично некорректные данные • Вы feeling lucky ¯\_(ツ)_/¯ Зачем вообще писать парсер руками? 89
для AST элементов • participle с Ragel лексером и альтернативной грамматикой • Пулы объектов для парсеров • Некоторые другие либы, типа pigeon (аналог participle) • Как ещё тестировать парсеры (тесты позиций) • Что делать с комментариями (freefloating токены) • Левая рекурсия и прочие заболевания ... Что мы не разобрали (домашнее задание) 98
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![/** * @return ?int|void|string[] */ function check_rights() { return false;](https://files.speakerdeck.com/presentations/c1423cfcfb3b44c5976f2e814497d238/slide_15.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![tests := []struct { input string expect string }{ {`int`,](https://files.speakerdeck.com/presentations/c1423cfcfb3b44c5976f2e814497d238/slide_43.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![var nameToToken = map[string]rune{ "int": T_INT, "float": T_FLOAT, "null": T_NULL,](https://files.speakerdeck.com/presentations/c1423cfcfb3b44c5976f2e814497d238/slide_67.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![data := l.src // string или []byte p := l.pos](https://files.speakerdeck.com/presentations/c1423cfcfb3b44c5976f2e814497d238/slide_79.jpg){kind=link}
![whitespace = [\t ]; ident_first = [a-zA-Z_] | (0x0080..0x00FF); ident_rest](https://files.speakerdeck.com/presentations/c1423cfcfb3b44c5976f2e814497d238/slide_80.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}