Raw Audio: https://deepmind.com/blog/wavenet-generative- model-raw-audio/ • [van den Oord; ’16a] Aaron van den Oord, Nal Kalchbrenner, Koray Kavukcuoglu, “Pixel Recurrent Neural Networks ”. ICML 2016. • [van den Oord; ’16b] Aaron van den Oord, Nal Kalchbrenner, Oriol Vinyals, et al, “Conditional Image Generation with PixelCNN Decoders”, NIPS 2016. • [van den Oord; ’16c] Aaron van den Oord, Sander Dieleman, Heiga Zen, et al, "WaveNet: A Generative Model for Raw Audio", arXiv:1609.03499, Sep 2016. • [Salimans: ‘17] Tim Salimans, Andrej Karpathy, Xi Chen, et al, “PixelCNN++: Improving the PixelCNN with Discretized Logistic Mixture Likelihood and Other Modifications, Jan 2017. • [van den Oord; ‘17] Aaron van den Oord, Yazhe Li, Igor Babuschkin, et al, "Parallel WaveNet: Fast High-Fidelity Speech Synthesis", arXiv:1711.10433, Nov 2017. • [Wang; ‘17] Yuxuan Wang, RJ Skerry-Ryan, Daisy Stanton, et al, “Tacotron: Towards End-to-End Speech Synthesis”, arXiv:1703.10135, Apr. 2017. • [Shen; ’17] Jonathan Shen, Ruoming Pang, Ron J. Weiss, et al, "Natural TTS Synthesis by Conditioning WaveNet on Mel Spectrogram Predictions", arXiv:1712.05884, Dec 2017. 36
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
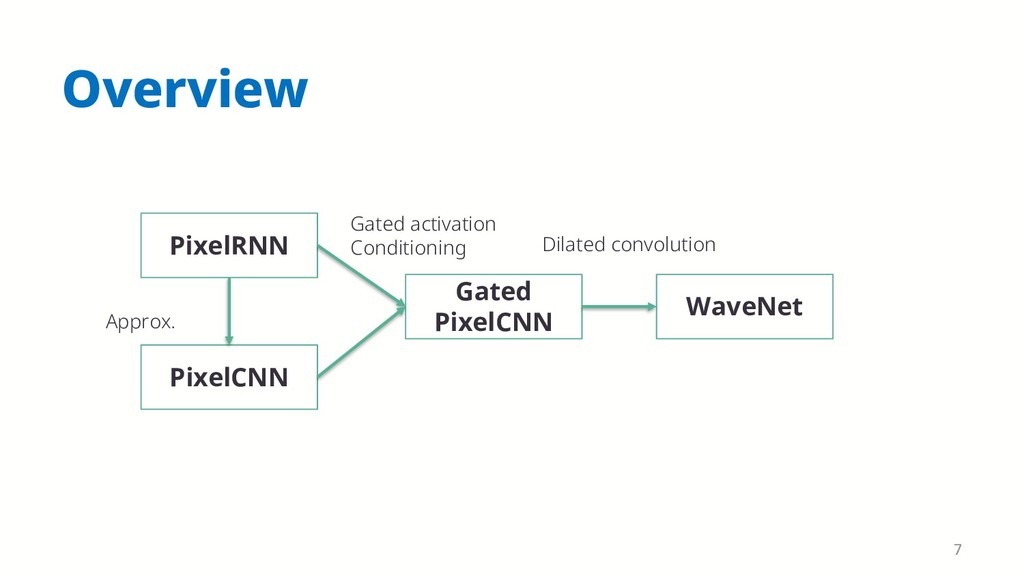{kind=link}
{kind=link}
![[van den Oord; ’16a] PixelRNN/CNN: Autoregressive models for image !](https://files.speakerdeck.com/presentations/b186b3b4d18b4f08ae2d7af6e962b60f/slide_8.jpg){kind=link}
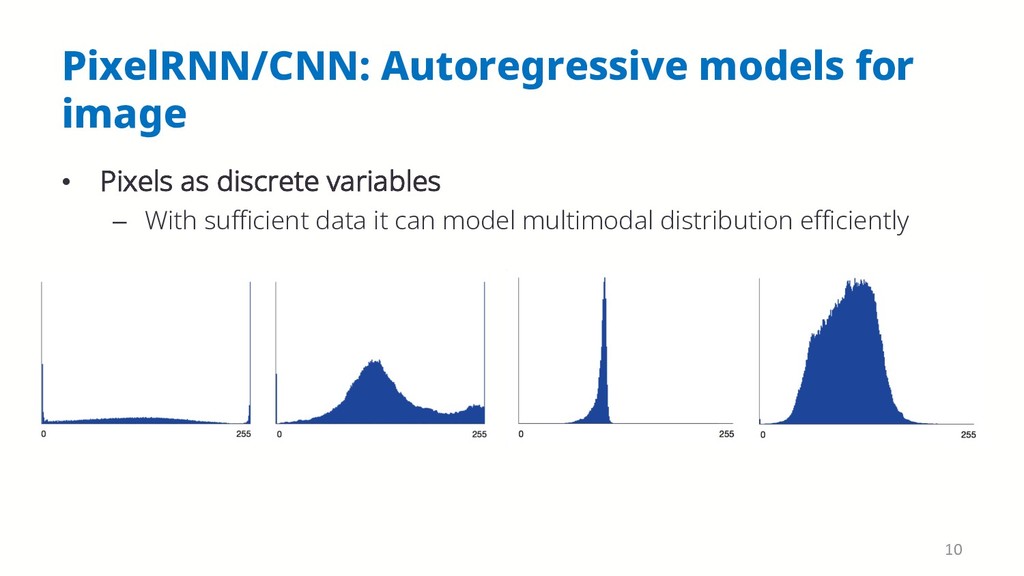{kind=link}
{kind=link}
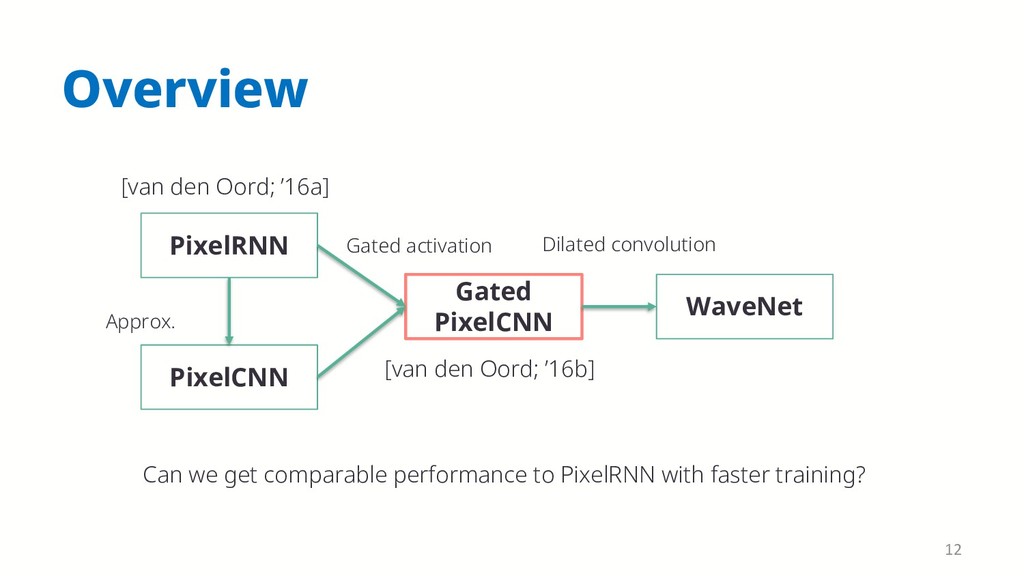{kind=link}
![[van den Oord; ’16b] Gated PixelCNN • Extended work of](https://files.speakerdeck.com/presentations/b186b3b4d18b4f08ae2d7af6e962b60f/slide_12.jpg){kind=link}
{kind=link}
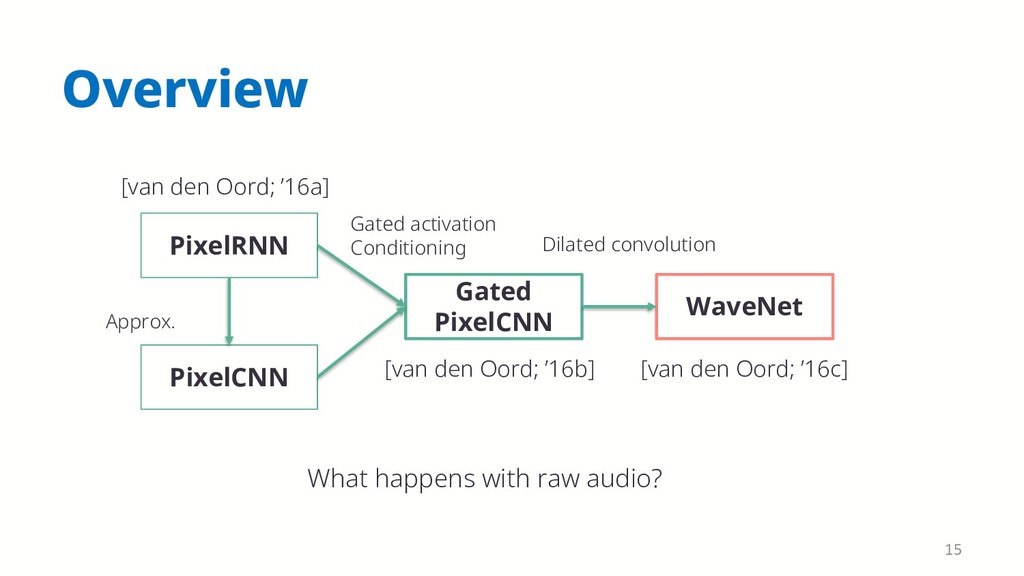{kind=link}
![[van den Oord; ’16c] WaveNet: A Generative Model for Raw](https://files.speakerdeck.com/presentations/b186b3b4d18b4f08ae2d7af6e962b60f/slide_15.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![[Salimans; ‘17] PixelCNN++ • The problem of softmax output –](https://files.speakerdeck.com/presentations/b186b3b4d18b4f08ae2d7af6e962b60f/slide_21.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![1/2 References • [DeepMind; ‘16] WaveNet: A Generative Model for](https://files.speakerdeck.com/presentations/b186b3b4d18b4f08ae2d7af6e962b60f/slide_35.jpg){kind=link}
![2/2 References • [Le Paine; ‘16] Tom Le Paine, Pooya](https://files.speakerdeck.com/presentations/b186b3b4d18b4f08ae2d7af6e962b60f/slide_36.jpg){kind=link}
{kind=link}