Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
チームとしての障害対応時間削減に向けて取り組んだこと/20211222-rakusmeetup...
Search
Sponsored
·
SiteGround - Reliable hosting with speed, security, and support you can count on.
→
Rakus_Dev
January 06, 2022
Technology
4.1k
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
チームとしての障害対応時間削減に向けて取り組んだこと/20211222-rakusmeetup-nishie
Rakus_Dev
January 06, 2022
More Decks by Rakus_Dev
See All by Rakus_Dev
螺旋型キャリアの生存戦略 / kinoko-conf2026
rakus_dev
1
980
AIで久々にコードを書いたらエンジニアへの依頼が"増えた" ── 元エンジニアのPdMの話 / Using AI to Code Again After a Long Break Increased My Requests to Engineers: Insights from a Former Engineer PdM
rakus_dev
0
460
主体的に活躍する内製QA組織の作り方と組織文化の醸成 / How to Build a Proactive In-house QA Organization and Foster Its Culture
rakus_dev
0
280
AI実装による「レビューボトルネック」を解消する仕様駆動開発(SDD)/ ai-sdd-review-bottleneck
rakus_dev
0
330
仕様駆動開発の組織的定着に向けた取り組み ~『楽楽電子保存』開発チームの事例~ / Establishing SDD: Organizational Initiatives
rakus_dev
0
580
全エンジニアのAI活用状況を可視化する~Lookerを用いたアンケート分析と今後の推進策~ / Visualizing AI Adoption Across Engineering
rakus_dev
0
6.2k
出してみてわかったAIエージェントプロダクトの舞台裏 〜楽楽AIエージェント for 楽楽精算〜 / Behind the Scenes of Rakuraku AI Agent
rakus_dev
0
610
プロダクトマネージャーの目標と評価 / Goal Setting for Product Managers
rakus_dev
1
1.1k
【pmconf2025】AI時代の『ジュニア不要論』に異議あり! 未経験から戦力PdMを生み出すOJT戦略とは?
rakus_dev
1
1.2k
Other Decks in Technology
See All in Technology
クレデンシャル流出 ― 攻撃 3 時間 vs 復旧 10 時間。この非対称性にどう備えるか
kazzpapa3
3
560
AIが自律的に回る開発ループを設計してチーム開発に組み込む
nekorush14
0
130
When Platform Engineering Meets GenAI
sucitw
0
170
Microsoft のサポートとフィードバック総まとめ
murachiakira
PRO
0
110
MySQL & MySQL HeatWave Report - June 2026
freshdaz
0
120
データレイクの「見えない問題」を可視化する
sansantech
PRO
1
200
PostgreSQL 19 新機能概要 OSC Hokkaido 2026
nori_shinoda
0
240
フィジカル版Github Onshapeの紹介
shiba_8ro
0
320
AI Agentをシステムに組み込む前にゆるく向き合ってみる
hayama17
0
140
LayerX コーポレートエンジニアリング室におけるサプライチェーンセキュリティへの取り組み / Supply Chain Security at LayerX Corporate Engineering
yuyatakeyama
3
840
WebGIS AI Agentの紹介
_shimizu
0
560
AWS Security Agent といっしょに脅威モデリングをやってみよう
amarelo_n24
1
210
Featured
See All Featured
WCS-LA-2024
lcolladotor
0
650
Reality Check: Gamification 10 Years Later
codingconduct
0
2.2k
The Web Performance Landscape in 2024 [PerfNow 2024]
tammyeverts
12
1.2k
Believing is Seeing
oripsolob
1
150
AI Search: Where Are We & What Can We Do About It?
aleyda
0
7.6k
End of SEO as We Know It (SMX Advanced Version)
ipullrank
3
4.2k
Sharpening the Axe: The Primacy of Toolmaking
bcantrill
46
2.9k
Organizational Design Perspectives: An Ontology of Organizational Design Elements
kimpetersen
PRO
1
750
Ecommerce SEO: The Keys for Success Now & Beyond - #SERPConf2024
aleyda
1
2k
How to build a perfect <img>
jonoalderson
1
5.7k
Leveraging LLMs for student feedback in introductory data science courses - posit::conf(2025)
minecr
1
300
The Cult of Friendly URLs
andyhume
79
6.9k
Transcript
#RAKUSMeetup ©2021 RAKUS Co., Ltd. ©2021 RAKUS Co., Ltd. チームとしての障害対応時間
削減に向けて取り組んだこと 株式会社ラクス インフラ開発部 西江 正義
#RAKUSMeetup ©2021 RAKUS Co., Ltd. 自己紹介 西江 正義(にしえ まさよし) ▪経歴
大手SIer、通信系ベンダにてインフラの構築・運用を 10数年経験後、2013年ラクス入社。 インフラ開発部にて、メールディーラー および チャットディーラー の運用チームリーダを担当。 ▪趣味 旅行(※できるだけ携帯電話がつながらないところ)
#RAKUSMeetup ©2021 RAKUS Co., Ltd. 発表内容について メールディーラーとチャットディーラーで合わせて1,000台近い サーバを運用していますが、それだけサーバがあると、様々な 障害が発生します。 中でも仮想基盤機器やネットワーク機器で障害が発生した場合は、
影響範囲が大きくなりやすいため、主にそういったものに対し、 どうすればチームとして迅速に対応できるようになるか? ということを考え、実践したことについて発表させていただきます。
#RAKUSMeetup ©2021 RAKUS Co., Ltd. 障害対応における問題の分析
#RAKUSMeetup ©2021 RAKUS Co., Ltd. 過去発生した障害について 過去3年以内に発生した以下のような障害について分析した結果、 ある問題が見えてきました。 (※複数サーバに影響があったもの) ・仮想基盤用機器のダウン
・インターネット回線障害 ・DoS/DDoS攻撃 etc…
#RAKUSMeetup ©2021 RAKUS Co., Ltd. 問題とは・・・ 障害発生後、関係者への周知に 時間がかかっている
#RAKUSMeetup ©2021 RAKUS Co., Ltd. 障害概要 影響範囲 原因 発生時間 復旧時間
周知時間 仮想基盤用 機器ダウン 仮想サーバ32台 で再起動が発生 機器故障 19:41 19:47 20:23 インターネット 回線障害 約800台のサー バに外部からア クセス不可 他ユーザによ る回線圧迫 6:21 6:24 7:54 DoS/DDoS攻 撃 不明 (数十台~) 外部からの攻 撃 15:47 16:03 不明 (おそらく 16:30頃) 【障害例】 6分 36分 3分 90分 16分 ※サービスは数分~十数分で復旧しているが、周知に数十分かかっている
#RAKUSMeetup ©2021 RAKUS Co., Ltd. 関係者への周知(情報共有)に 時間がかかると何が問題か?
#RAKUSMeetup ©2021 RAKUS Co., Ltd. ・顧客からの問合せに対し、サポートが 何も回答することができない ・上層部が何かしらの判断を行うにも、 状況がわからないと判断のしようがない ・サービス復旧、事後対応に必要な他部署の
協力を得にくくなる(遅くなる)
#RAKUSMeetup ©2021 RAKUS Co., Ltd. 周知に時間がかかる要因は?
#RAKUSMeetup ©2021 RAKUS Co., Ltd. ・ 各自バラバラに対応して、ムダが生じている ・ 第一報までの目標時間を定めていない ・
周知文に記載する内容を都度考えている ・ 影響範囲特定に必要なアクションが不明瞭 主な要因として、以下のようなものが挙げられる
#RAKUSMeetup ©2021 RAKUS Co., Ltd. すなわち、「障害発生時における対応方針が決まっ ていない」ということが周知に時間がかかっている 原因であるといえる。 そのため今回、障害発生時の対応方針として「時間 を意識してチームとして効率的に動く」という方針を
定めた。
#RAKUSMeetup ©2021 RAKUS Co., Ltd. 前ページで定めた方針に沿って、 それぞれの要因に対する対策を考えました。
#RAKUSMeetup ©2021 RAKUS Co., Ltd. 役割分担表の作成 各自バラバラに対応しており、ムダが生じている 要因 対策 【資料の一部抜粋(イメージ)】
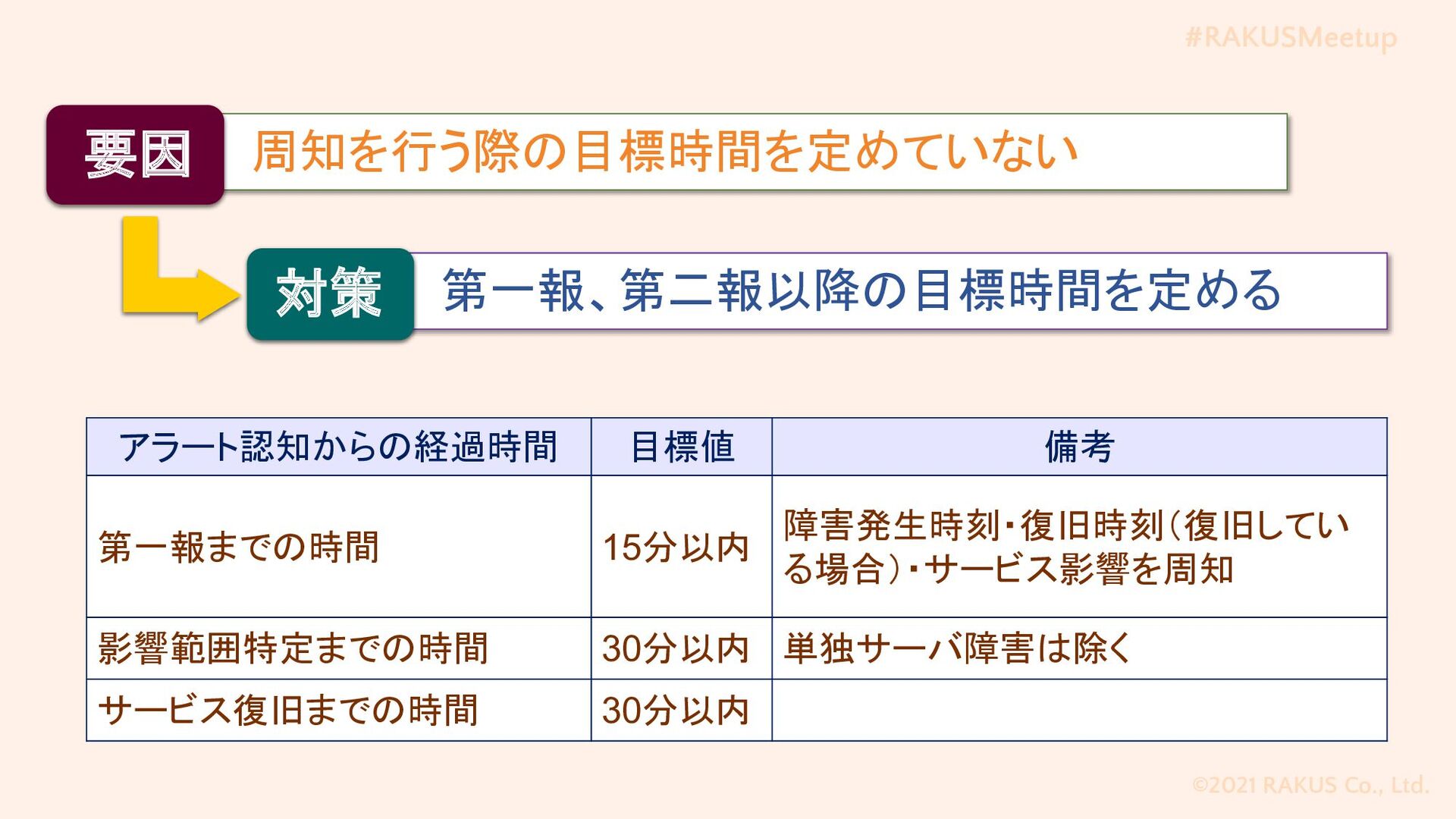
#RAKUSMeetup ©2021 RAKUS Co., Ltd. 第一報、第二報以降の目標時間を定める 周知を行う際の目標時間を定めていない 要因 対策 アラート認知からの経過時間
目標値 備考 第一報までの時間 15分以内 障害発生時刻・復旧時刻(復旧してい る場合)・サービス影響を周知 影響範囲特定までの時間 30分以内 単独サーバ障害は除く サービス復旧までの時間 30分以内
#RAKUSMeetup ©2021 RAKUS Co., Ltd. 周知文のフォーマットを用意する 周知文に記載する内容を都度考えている 要因 対策 【資料の一部抜粋(イメージ)】
#RAKUSMeetup ©2021 RAKUS Co., Ltd. 影響範囲特定方法をまとめる 影響範囲特定に必要なアクションが不明瞭 要因 対策 ・
サービス影響があったサーバを特定するには、原則として 遠隔監視用サーバでアラート検知したものとする → アラート一覧画面からCSVファイルとして出力する
#RAKUSMeetup ©2021 RAKUS Co., Ltd. まだこれで終わりではない
#RAKUSMeetup ©2021 RAKUS Co., Ltd. せっかく対策を考えても、実際に障害が起こったときに、そ の対策に沿って動けなければ意味がない どうするんだっけ? ※こうなってはいけない
#RAKUSMeetup ©2021 RAKUS Co., Ltd. そのためには、普段からの訓練が重要 ⇒ 障害を想定したリハーサルを行う
#RAKUSMeetup ©2021 RAKUS Co., Ltd. 影響範囲 障害箇所 障害内容 (例) 単体サーバ
サーバ本体 サーバがディスクフルになった 複数サーバ スイッチ スイッチが故障した Firewall Firewallが故障した 仮想基盤 仮想基盤用機器がダウンした 以下のような障害が発生したと仮定した障害対応の リハーサルを行いました。 実際に障害を起こすことが難しいものについては、該当機器に障害が発生した場合に 検知すると思われるアラート一覧を事前に用意しておき、「こんなアラートを検知したと したらどう対応するか?」 という形で実施しました。
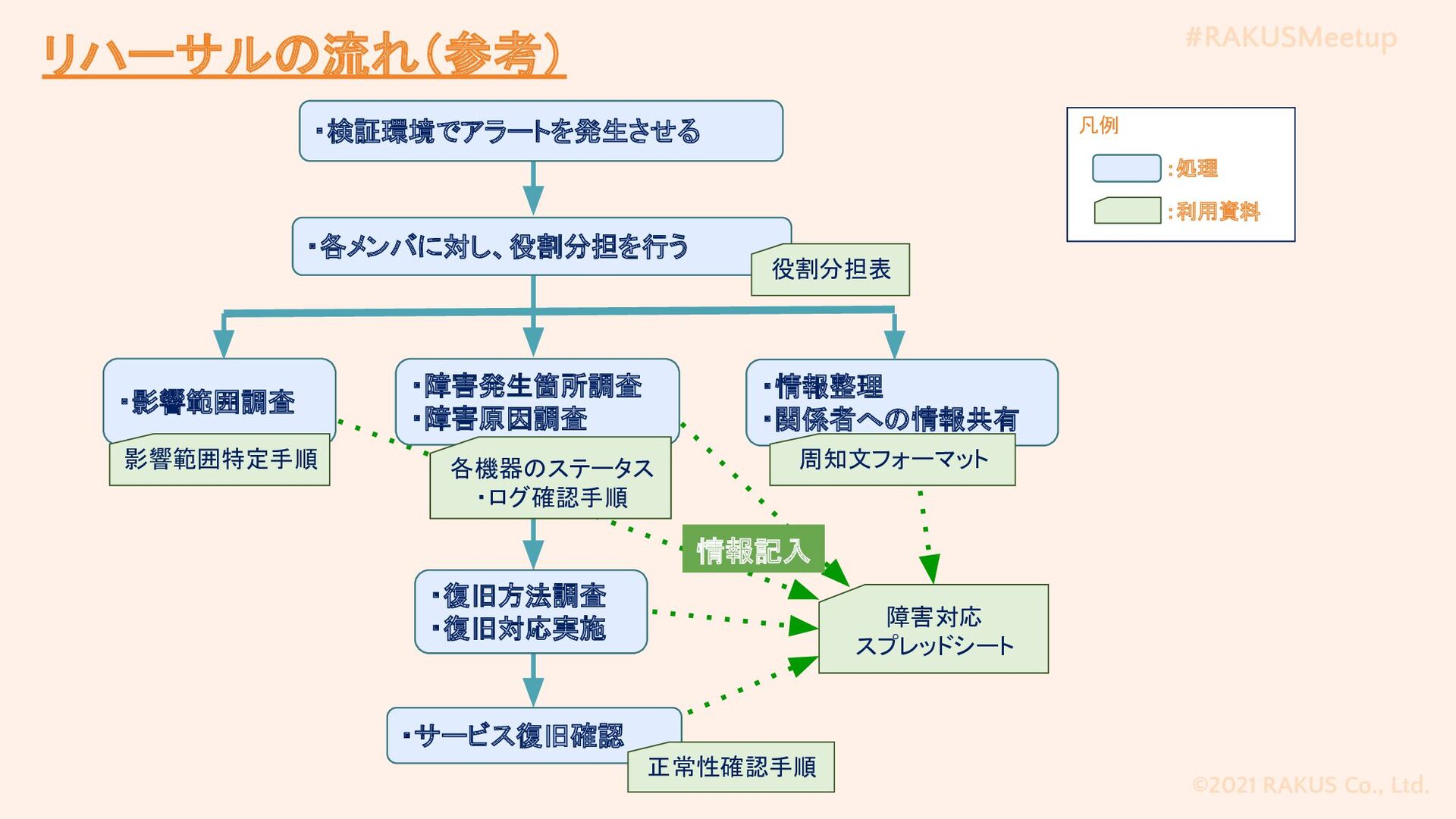
#RAKUSMeetup ©2021 RAKUS Co., Ltd. 障害対応 スプレッドシート ・影響範囲調査 ・障害発生箇所調査 ・障害原因調査
影響範囲特定手順 ・情報整理 ・関係者への情報共有 周知文フォーマット ・サービス復旧確認 凡例 :処理 :利用資料 ・各メンバに対し、役割分担を行う ・検証環境でアラートを発生させる 役割分担表 正常性確認手順 各機器のステータス ・ログ確認手順 ・復旧方法調査 ・復旧対応実施 情報記入 リハーサルの流れ(参考)
#RAKUSMeetup ©2021 RAKUS Co., Ltd. その後、障害対応における周知ま での時間はどうなったか?
#RAKUSMeetup ©2021 RAKUS Co., Ltd. 【結果】約半分の時間に短縮されました! (42分 → 22分) 2021/11/6(土)
22:12に仮想基盤を構成するノードの1台がダウンするという 障害が発生しました。 (これにより、仮想マシン38台で再起動が発生) このとき、アラート検知から関係者への情報共有にかかった時間は「22 分」でした。 → 障害発生時刻、復旧時刻、対象、サービス影響内容、 この時点で想定される原因、について報告を行った。 ※ 前回、同様の障害が発生した際は「42分」かかっていました。 しかも、今回は、土曜日の夜という ”業務時間外” に 発生した障害。
#RAKUSMeetup ©2021 RAKUS Co., Ltd. 今後の改善予定
#RAKUSMeetup ©2021 RAKUS Co., Ltd. • 各機器への疎通・ステータス確認、サーバの正常性確認の自動化 → jenkinsなどにあらかじめPingの実行先IPアドレスや
HTTPS・SMTPのポート接続先アドレスを登録しておき、 ワンクリックで確認できるようにする。 • アラート検知を契機とした自動復旧の仕組み作り → Zabbixでのアラート検知時に、自動的に処理が実行 されるようにする。 (例)サービス停止検知時、起動コマンドを自動発行する
#RAKUSMeetup ©2021 RAKUS Co., Ltd. ご清聴ありがとうございました。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}