Microsoft Azure and am an AWS Community Builder and Microsoft Certified Trainer • Instructor and Author (Wrote the Azure AI Engineer Associate Study Guide) • International speaker at 50+ events and conferences • Organizer of the Melbourne Python meetup • Enjoy all things AWS, open-source, generative AI, and Virtual Reality Renaldi Gondosubroto Author and Senior Software Engineer @Renaldig @renaldigondosubroto @renaldig About Me @therenaldigram
12 recovery patterns, with examples and trade-offs • System-aware design through retries, receipts, degradation and rescue mode • Incident-ready UX with customer-facing runbooks and comms • Worksheet to audit one feature in a sprint • Q&A 1/24
built for the sunny day But customers live in the messy middle. • Users mistype, misclick, and change their mind mid-flow • Networks wobble, services time out, and retries happen • Safety patterns turn panic into progress • The goal: fewer tickets, fewer pages, calmer users
are normal Design for these as first-class states. • Double-clicks and repeated taps under pressure • Refresh, back button, tab close, and session expiry • Latency spikes, partial responses, 429s, and 5xxs • Mobile backgrounding and offline transitions
Product, design, and engineering can align on “recovery”. • Reversible actions instead of irreversible mistakes • Durable intent that survives retries and refresh • Explainable failures with an obvious next step • Safe resumption from a checkpoint with one click
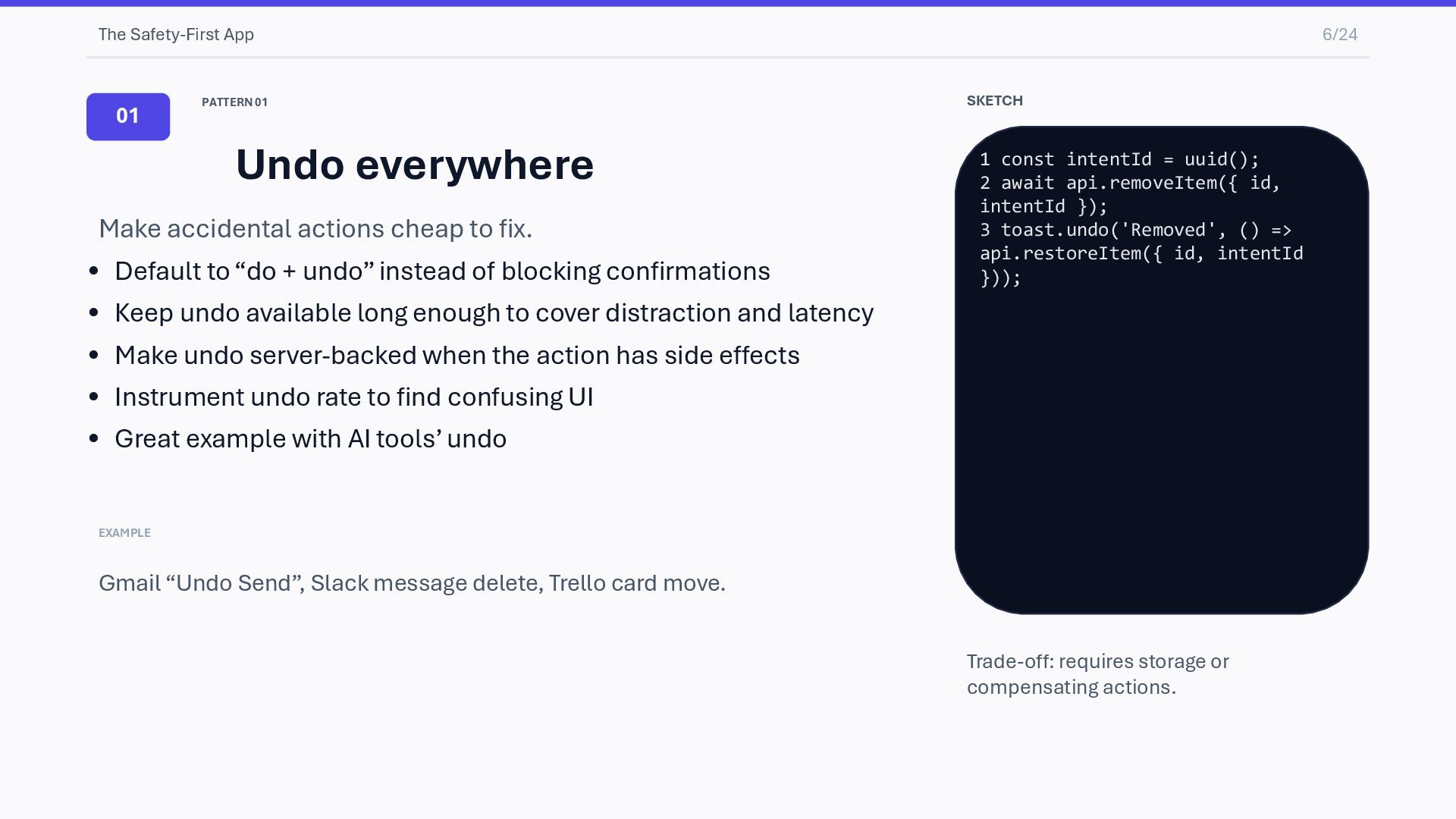
accidental actions cheap to fix. • Default to “do + undo” instead of blocking confirmations • Keep undo available long enough to cover distraction and latency • Make undo server-backed when the action has side effects • Instrument undo rate to find confusing UI • Great example with AI tools’ undo EXAMPLE Gmail “Undo Send”, Slack message delete, Trello card move. SKETCH 1 const intentId = uuid(); 2 await api.removeItem({ id, intentId }); 3 toast.undo('Removed', () => api.restoreItem({ id, intentId })); Trade-off: requires storage or compensating actions.
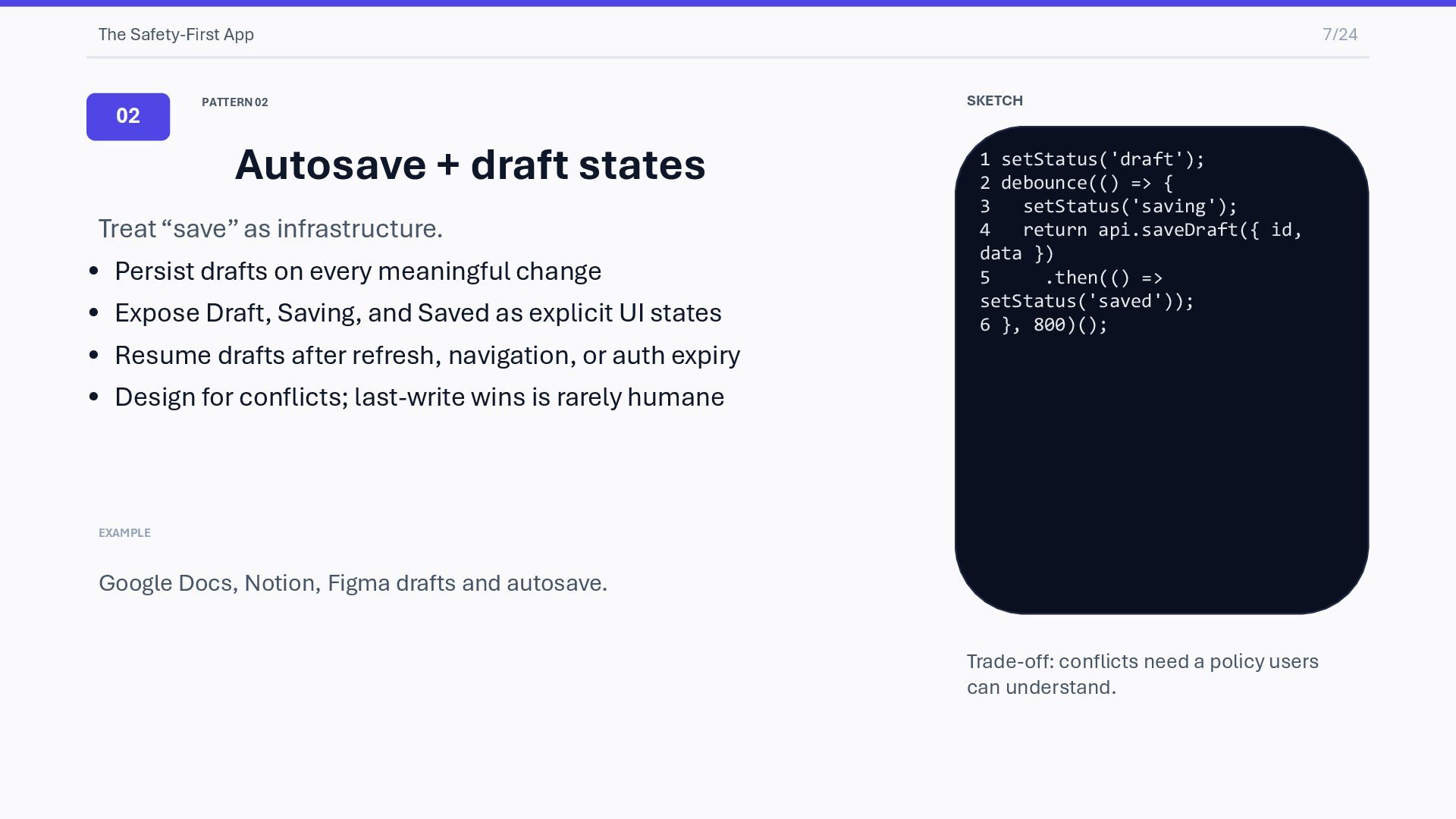
states Treat “save” as infrastructure. • Persist drafts on every meaningful change • Expose Draft, Saving, and Saved as explicit UI states • Resume drafts after refresh, navigation, or auth expiry • Design for conflicts; last-write wins is rarely humane EXAMPLE Google Docs, Notion, Figma drafts and autosave. SKETCH 1 setStatus('draft'); 2 debounce(() => { 3 setStatus('saving'); 4 return api.saveDraft({ id, data }) 5 .then(() => setStatus('saved')); 6 }, 800)(); Trade-off: conflicts need a policy users can understand.
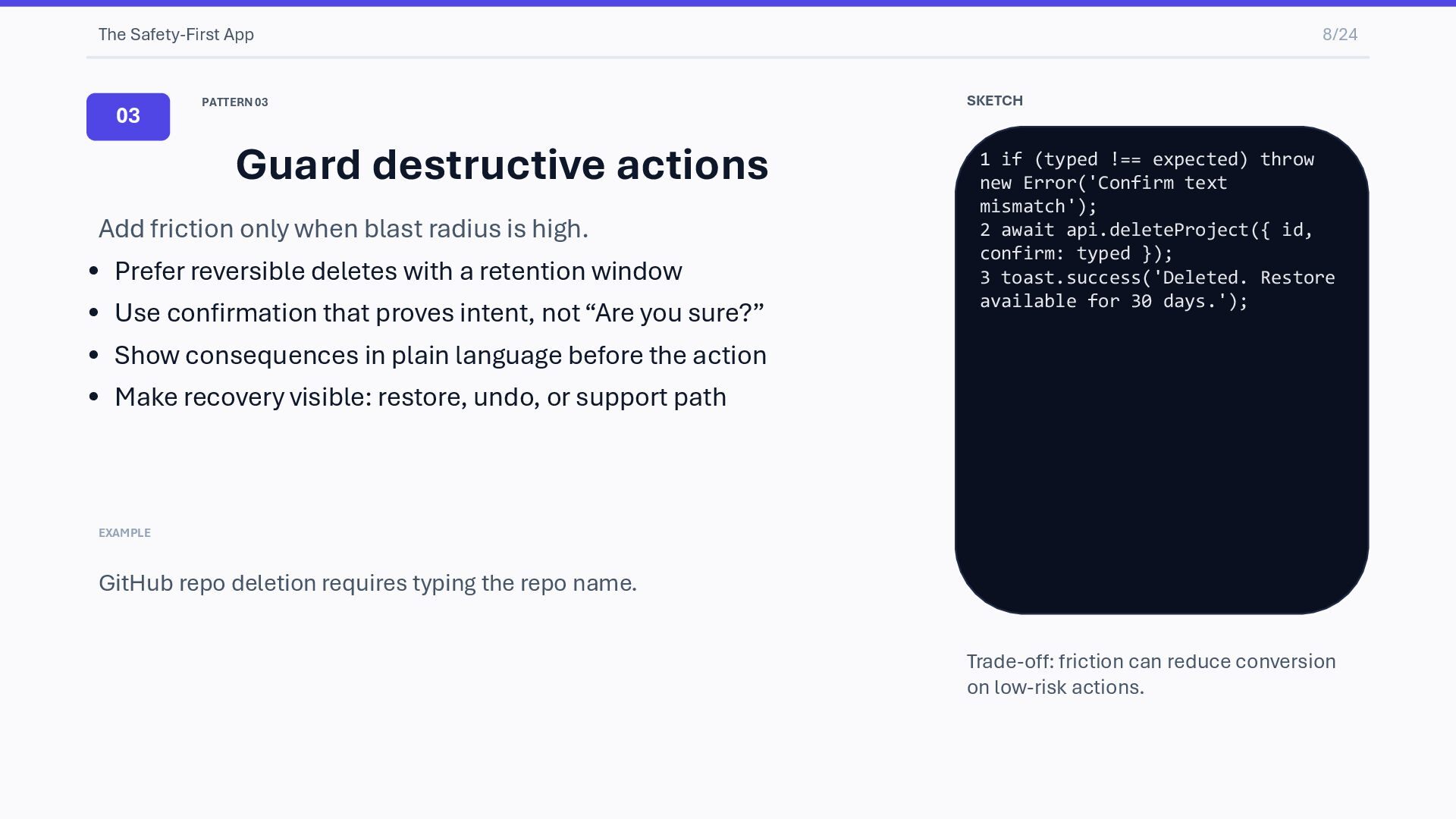
Add friction only when blast radius is high. • Prefer reversible deletes with a retention window • Use confirmation that proves intent, not “Are you sure?” • Show consequences in plain language before the action • Make recovery visible: restore, undo, or support path EXAMPLE GitHub repo deletion requires typing the repo name. SKETCH 1 if (typed !== expected) throw new Error('Confirm text mismatch'); 2 await api.deleteProject({ id, confirm: typed }); 3 toast.success('Deleted. Restore available for 30 days.'); Trade-off: friction can reduce conversion on low-risk actions.
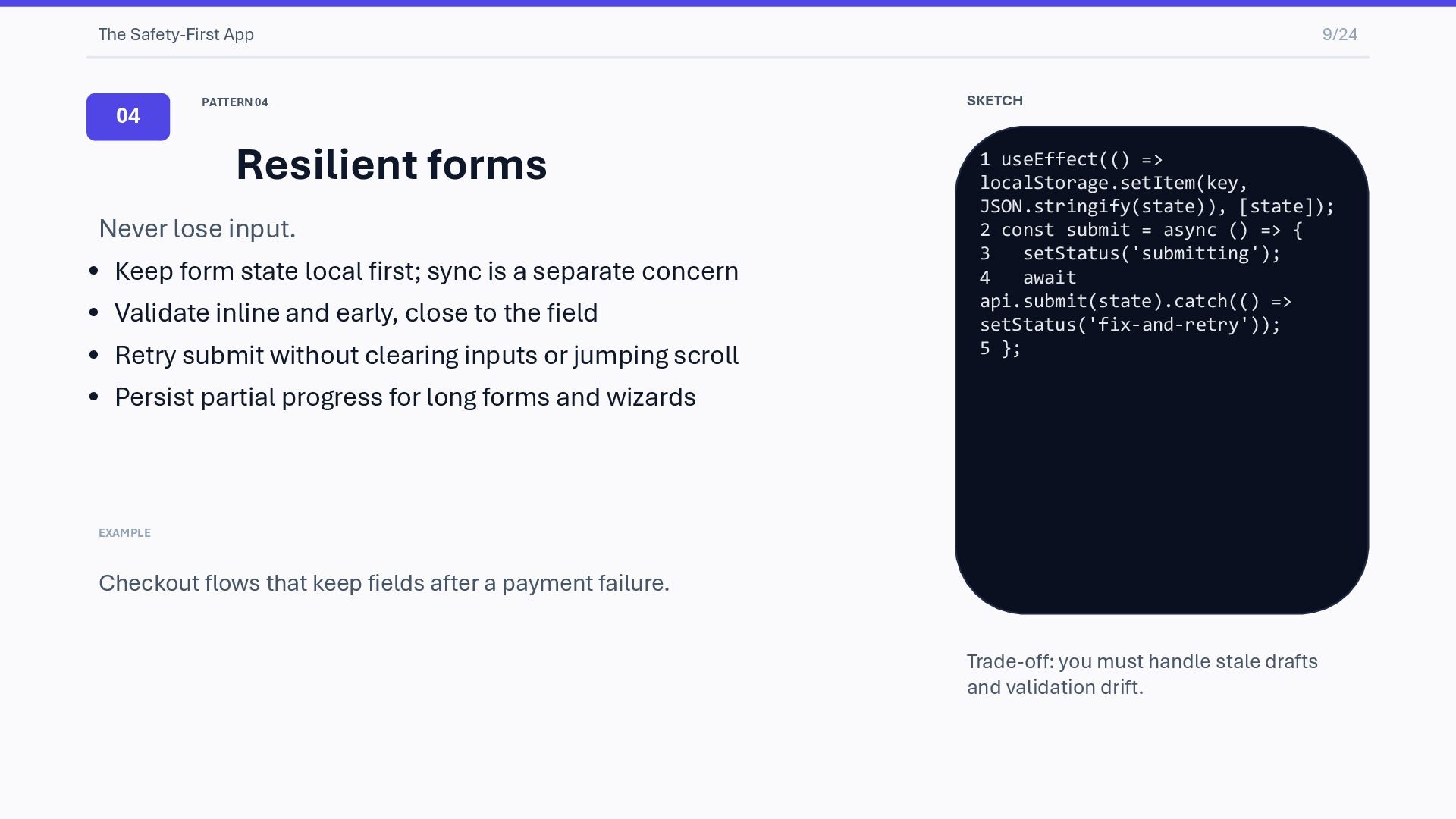
lose input. • Keep form state local first; sync is a separate concern • Validate inline and early, close to the field • Retry submit without clearing inputs or jumping scroll • Persist partial progress for long forms and wizards EXAMPLE Checkout flows that keep fields after a payment failure. SKETCH 1 useEffect(() => localStorage.setItem(key, JSON.stringify(state)), [state]); 2 const submit = async () => { 3 setStatus('submitting'); 4 await api.submit(state).catch(() => setStatus('fix-and-retry')); 5 }; Trade-off: you must handle stale drafts and validation drift.
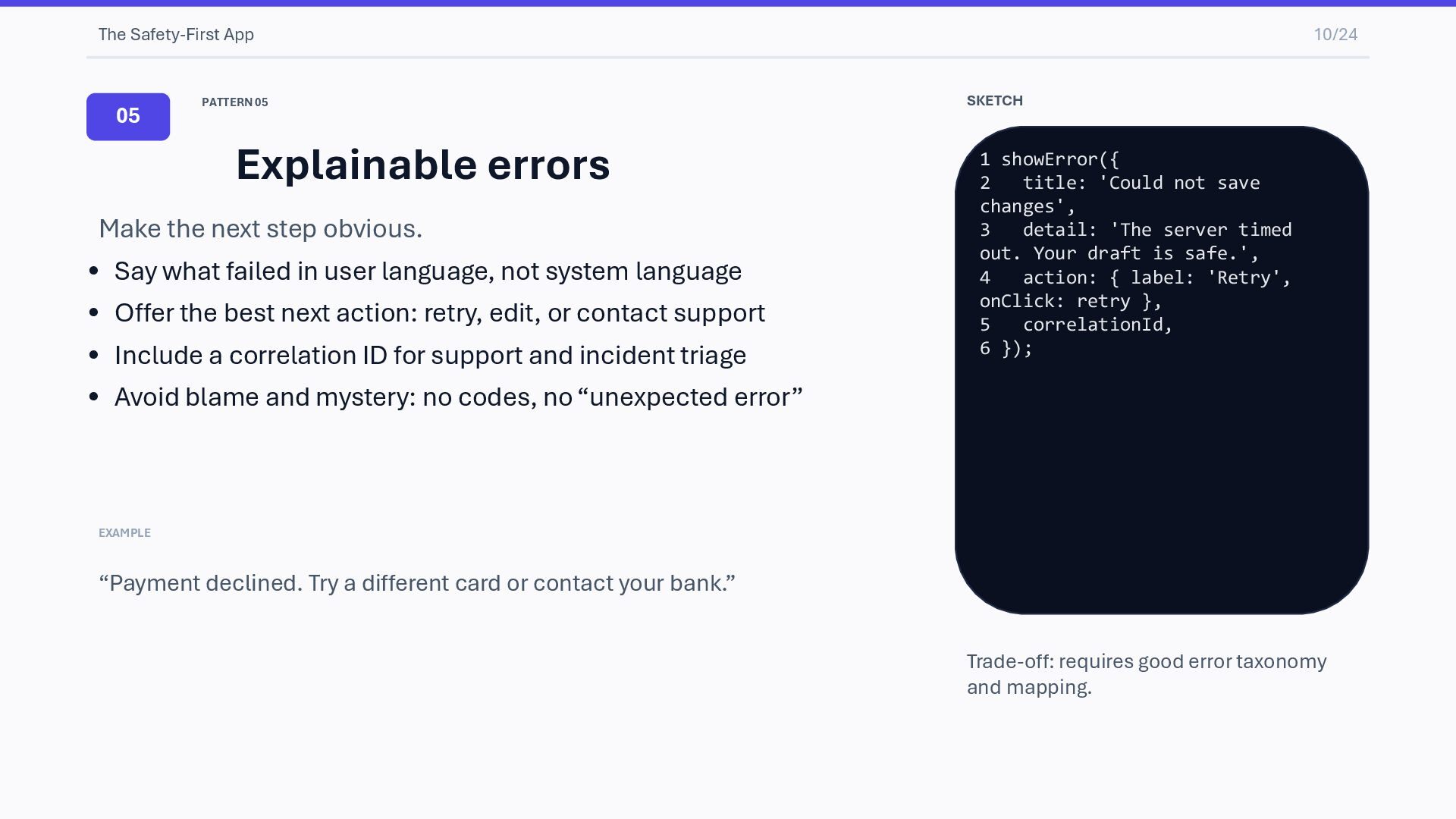
the next step obvious. • Say what failed in user language, not system language • Offer the best next action: retry, edit, or contact support • Include a correlation ID for support and incident triage • Avoid blame and mystery: no codes, no “unexpected error” EXAMPLE “Payment declined. Try a different card or contact your bank.” SKETCH 1 showError({ 2 title: 'Could not save changes', 3 detail: 'The server timed out. Your draft is safe.', 4 action: { label: 'Retry', onClick: retry }, 5 correlationId, 6 }); Trade-off: requires good error taxonomy and mapping.
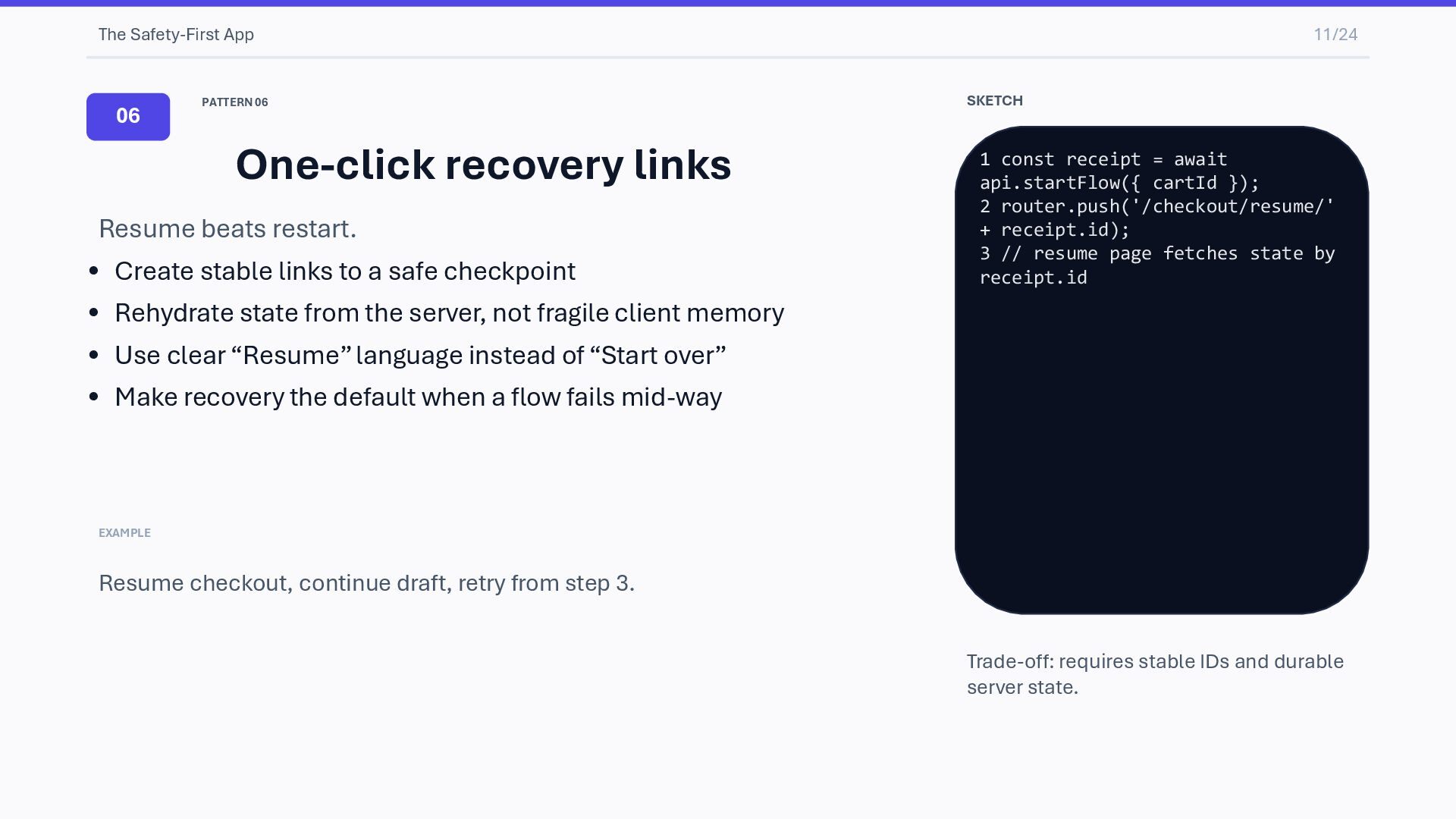
Resume beats restart. • Create stable links to a safe checkpoint • Rehydrate state from the server, not fragile client memory • Use clear “Resume” language instead of “Start over” • Make recovery the default when a flow fails mid-way EXAMPLE Resume checkout, continue draft, retry from step 3. SKETCH 1 const receipt = await api.startFlow({ cartId }); 2 router.push('/checkout/resume/' + receipt.id); 3 // resume page fetches state by receipt.id Trade-off: requires stable IDs and durable server state.
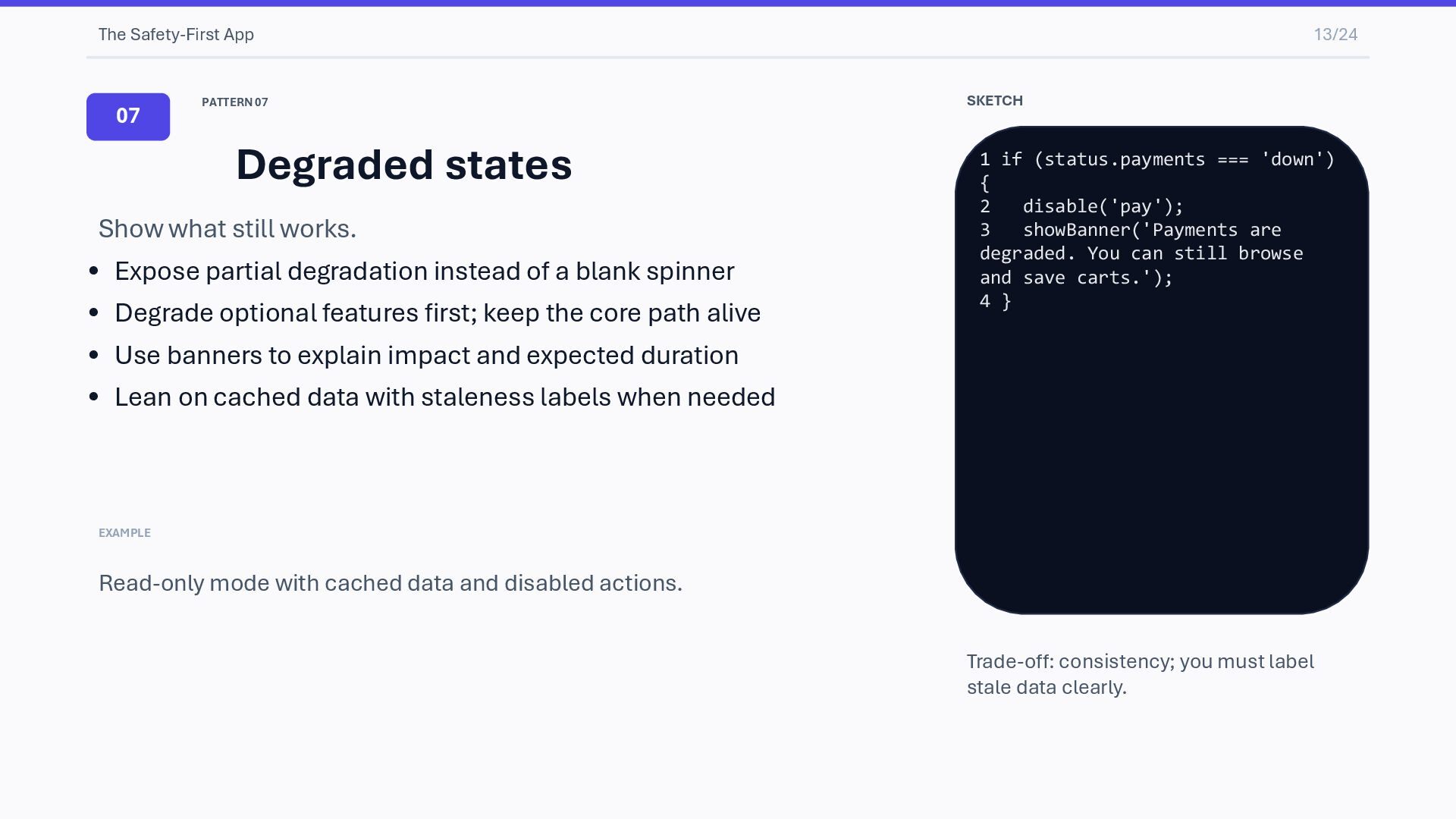
what still works. • Expose partial degradation instead of a blank spinner • Degrade optional features first; keep the core path alive • Use banners to explain impact and expected duration • Lean on cached data with staleness labels when needed EXAMPLE Read-only mode with cached data and disabled actions. SKETCH 1 if (status.payments === 'down') { 2 disable('pay'); 3 showBanner('Payments are degraded. You can still browse and save carts.'); 4 } Trade-off: consistency; you must label stale data clearly.
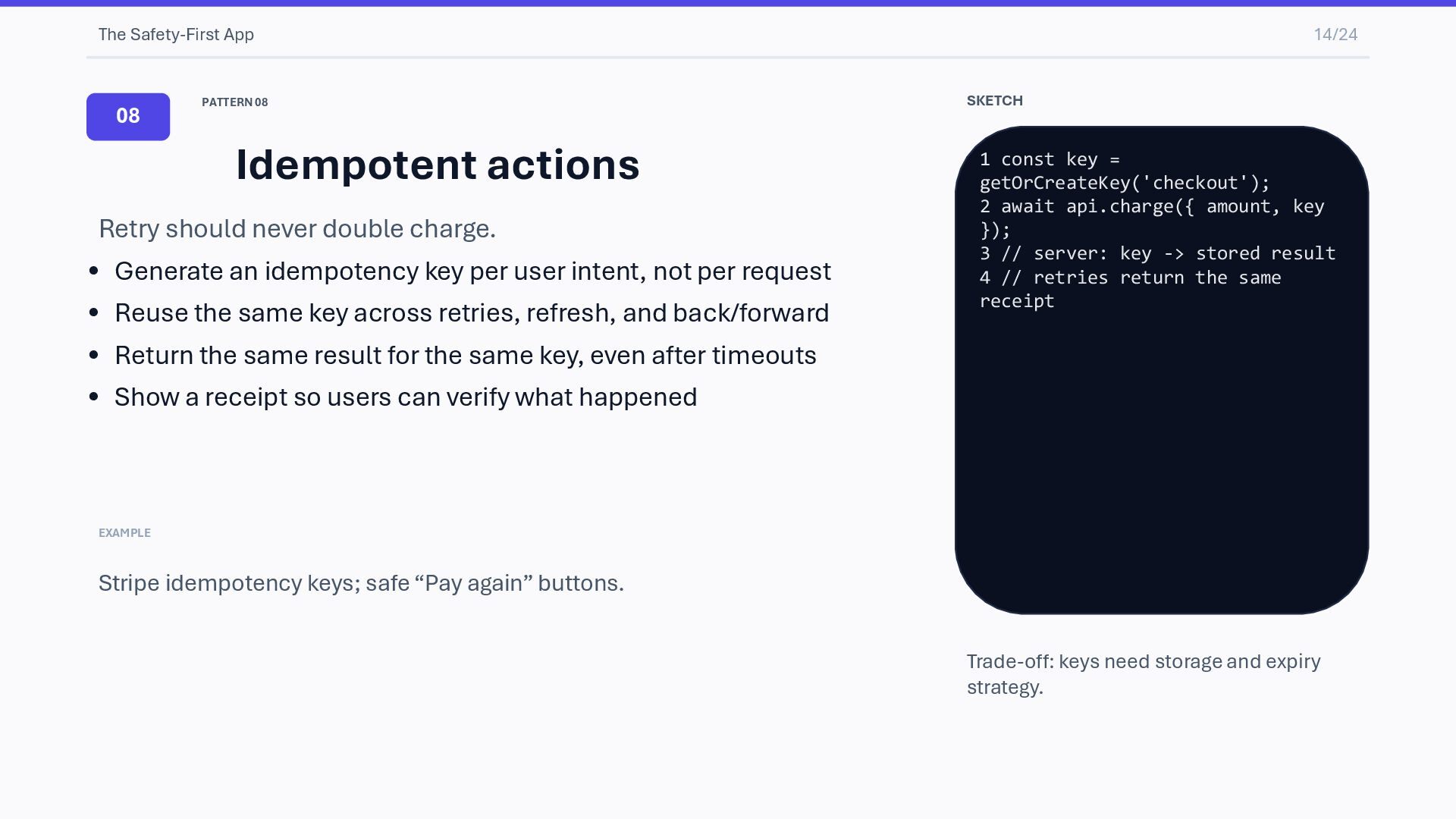
should never double charge. • Generate an idempotency key per user intent, not per request • Reuse the same key across retries, refresh, and back/forward • Return the same result for the same key, even after timeouts • Show a receipt so users can verify what happened EXAMPLE Stripe idempotency keys; safe “Pay again” buttons. SKETCH 1 const key = getOrCreateKey('checkout'); 2 await api.charge({ amount, key }); 3 // server: key -> stored result 4 // retries return the same receipt Trade-off: keys need storage and expiry strategy.
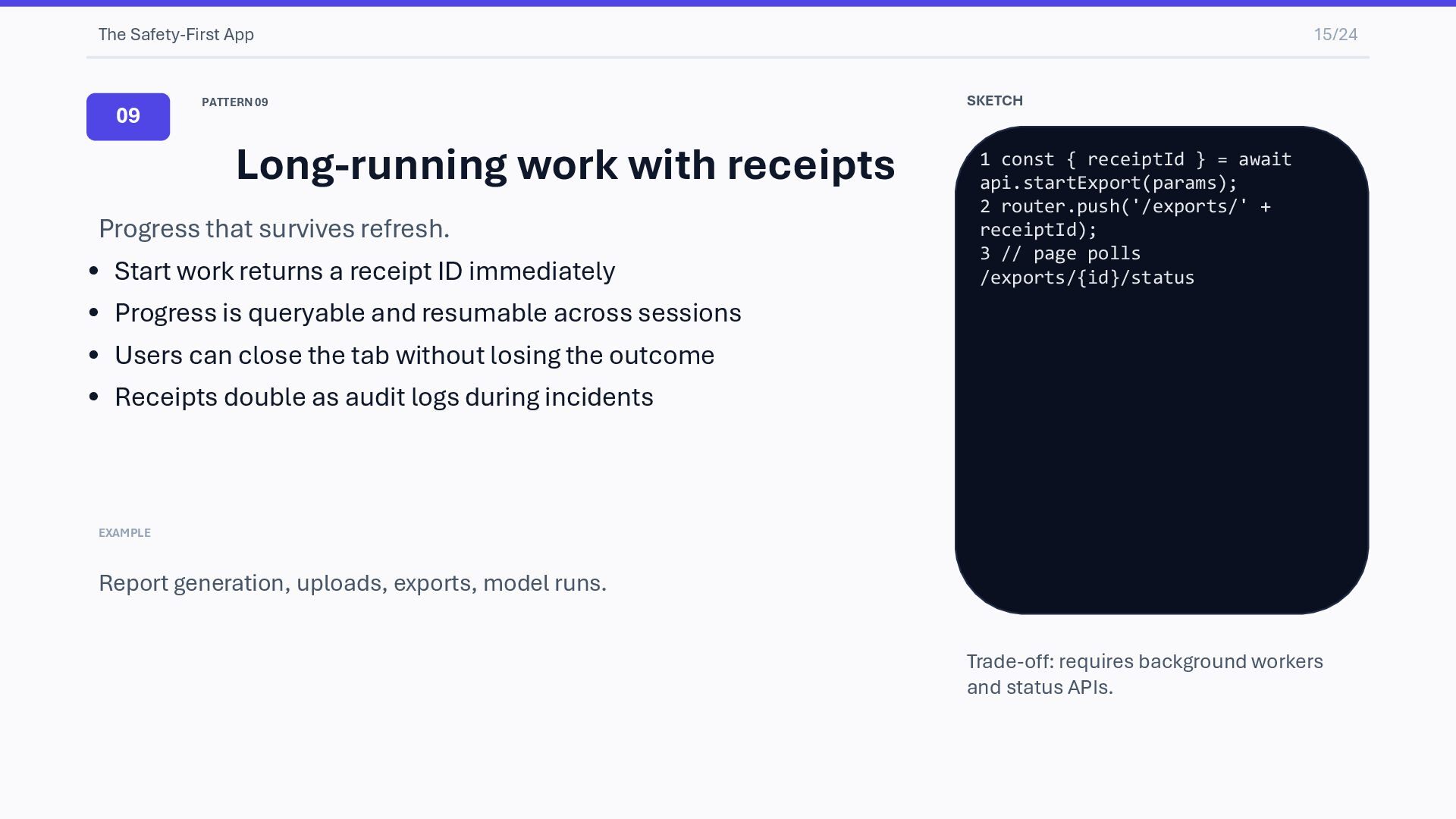
receipts Progress that survives refresh. • Start work returns a receipt ID immediately • Progress is queryable and resumable across sessions • Users can close the tab without losing the outcome • Receipts double as audit logs during incidents EXAMPLE Report generation, uploads, exports, model runs. SKETCH 1 const { receiptId } = await api.startExport(params); 2 router.push('/exports/' + receiptId); 3 // page polls /exports/{id}/status Trade-off: requires background workers and status APIs.
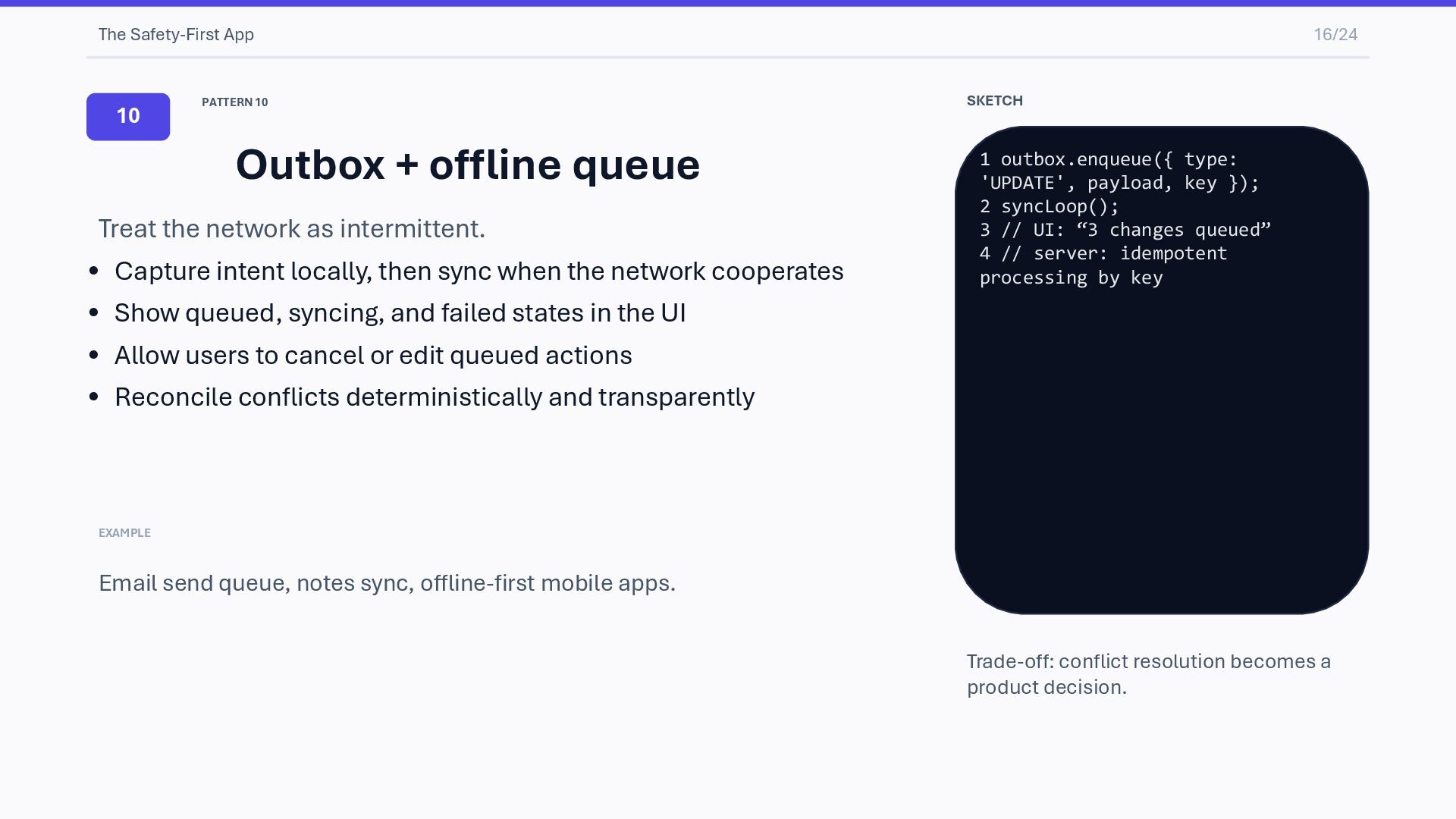
queue Treat the network as intermittent. • Capture intent locally, then sync when the network cooperates • Show queued, syncing, and failed states in the UI • Allow users to cancel or edit queued actions • Reconcile conflicts deterministically and transparently EXAMPLE Email send queue, notes sync, offline-first mobile apps. SKETCH 1 outbox.enqueue({ type: 'UPDATE', payload, key }); 2 syncLoop(); 3 // UI: “3 changes queued” 4 // server: idempotent processing by key Trade-off: conflict resolution becomes a product decision.
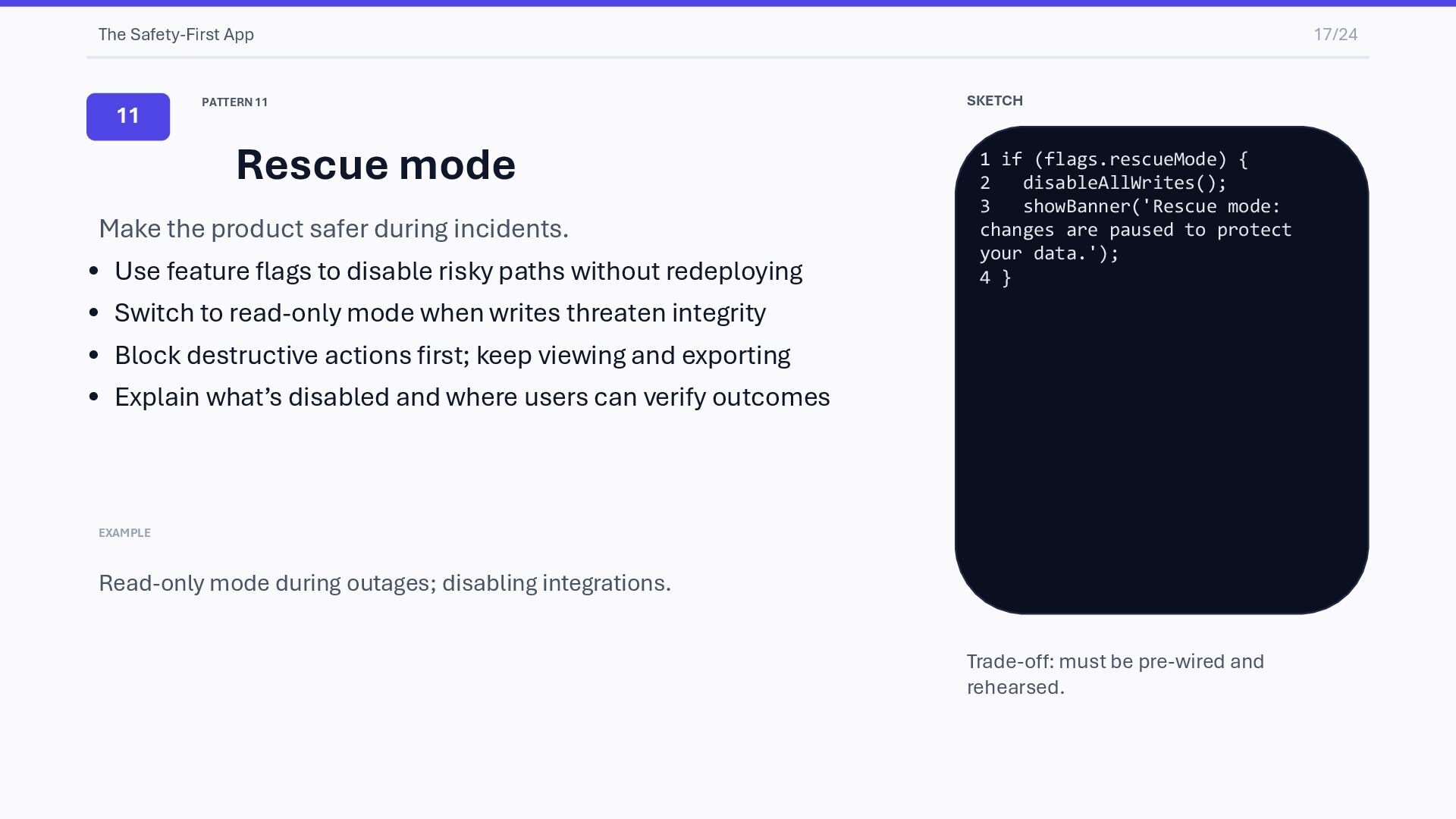
the product safer during incidents. • Use feature flags to disable risky paths without redeploying • Switch to read-only mode when writes threaten integrity • Block destructive actions first; keep viewing and exporting • Explain what’s disabled and where users can verify outcomes EXAMPLE Read-only mode during outages; disabling integrations. SKETCH 1 if (flags.rescueMode) { 2 disableAllWrites(); 3 showBanner('Rescue mode: changes are paused to protect your data.'); 4 } Trade-off: must be pre-wired and rehearsed.
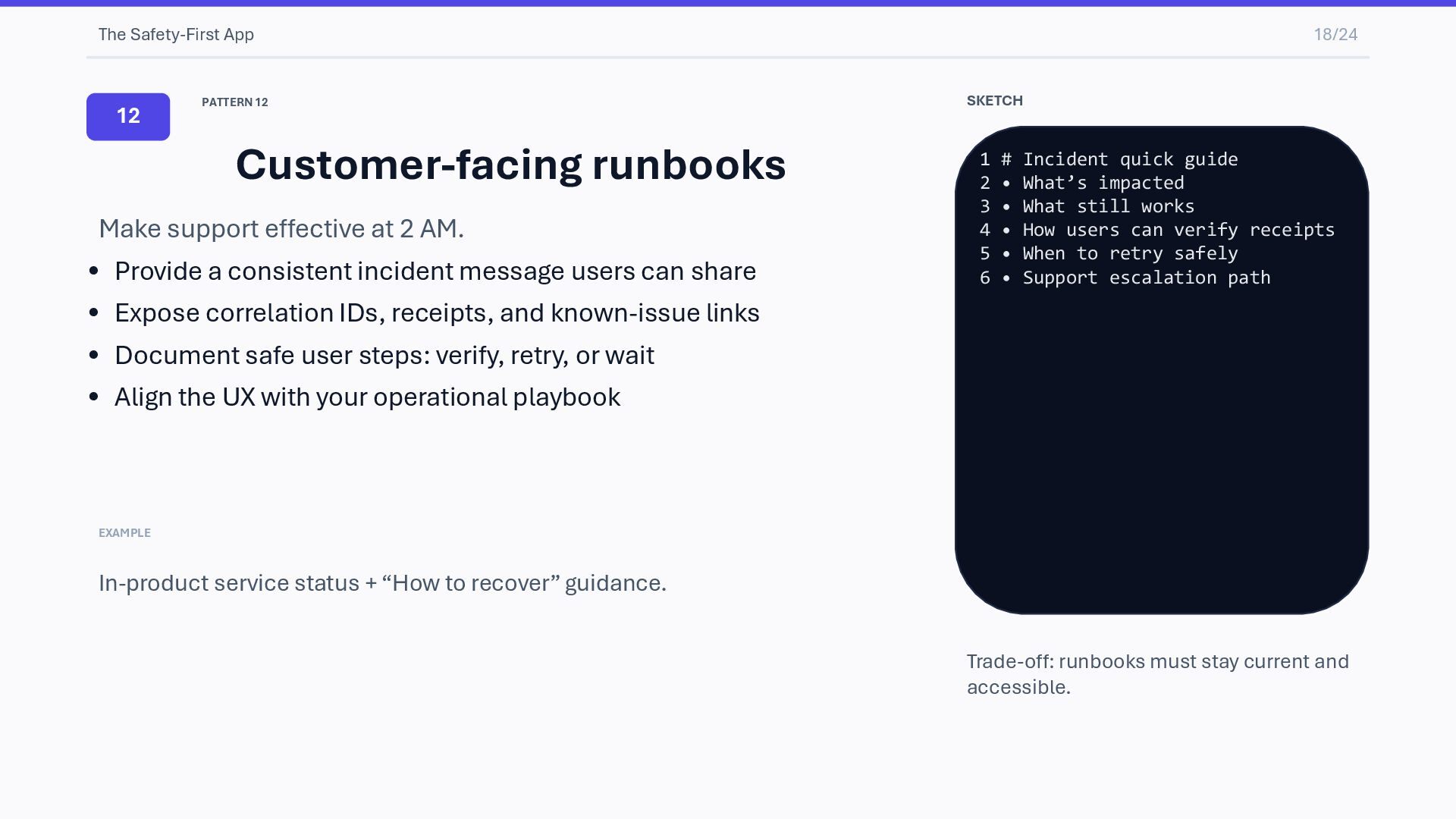
support effective at 2 AM. • Provide a consistent incident message users can share • Expose correlation IDs, receipts, and known-issue links • Document safe user steps: verify, retry, or wait • Align the UX with your operational playbook EXAMPLE In-product service status + “How to recover” guidance. SKETCH 1 # Incident quick guide 2 • What’s impacted 3 • What still works 4 • How users can verify receipts 5 • When to retry safely 6 • Support escalation path Trade-off: runbooks must stay current and accessible.
safety tool Prefer reversibility, then durability, then friction. • Can we make it reversible instead of confirmable? • What is the blast radius if this goes wrong? • Is retry safe, or can it duplicate side effects? • Do users have a stable place to resume and verify? • Can support diagnose this without engineering? • Are you putting enough safety in AI tools?
Checkout Flow Same backend. Different product outcomes. Before: fragile After: recoverable • Remove item requires confirmation modal • Form clears after a payment failure • Timeout forces a start over • Retry can double-charge • More complaints received • Undo on remove item • Autosaved draft checkout details • Receipt page survives refresh • Idempotent “Pay” with safe retries • More user satisfaction
one feature. Aim to finish in a single sprint. 1. What is the most common accidental action and is it undoable? 2. Does user input persist across refresh, navigation, and errors? 3. Are destructive actions reversible or guarded with intent proof? 4. Do errors explain what happened and the best next step? 5. Is there a one-click recovery link to a safe checkpoint? 6. Can retries duplicate side effects or are actions idempotent? 7. Do long tasks have durable receipts and resumable progress? 8. Does the UI show degraded states instead of hiding behind spinners? 9. Is there an outbox for queued work when the network is flaky? 10. Can we switch to rescue mode quickly during incidents? 11. Can support answer “what happened” with receipts and IDs? 12. Have we run the rainy-day test for this flow? Tip: Screenshot this slide, then audit one high-impact flow.
one sprint Small surface area. High leverage. • Pick one flow with high ticket volume or revenue risk • Add receipts and safe retries first as they unlock many patterns • Layer in undo, drafts, and explainable errors on top • Instrument through undo rate, error rate, abandon rate, and time-to-recover • Write the support runbook as you build as it exposes gaps fast
when users recover quickly and confidently. • Undo usage and reversal success rate • Autosave success rate and draft resume rate • Retry success rate without duplicate side effects • Time-to-recover after an error or timeout • Support tickets per 1,000 sessions for the target flow
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}