正規化、トークン化 ◦ ACLデータセットにおける vocabは全論文で頻出の50,000語 (Hitschler et al., 2017) ◦ EMNLPデータセットでは、最小の頻度を 5回とした約23,000語 • 符号化 ◦ vocab外の単語は”unk”トークンにする ◦ 系列長が短い場合、ゼロパディング ◦ 引用箇所の周辺の文字系列 (100 words) を使用し、引用に関する単語を素性とする • 品詞タグ付け ◦ Stanford POS tagger https://github.com/kermitt2/grobid
{kind=link}
{kind=link}
{kind=link}
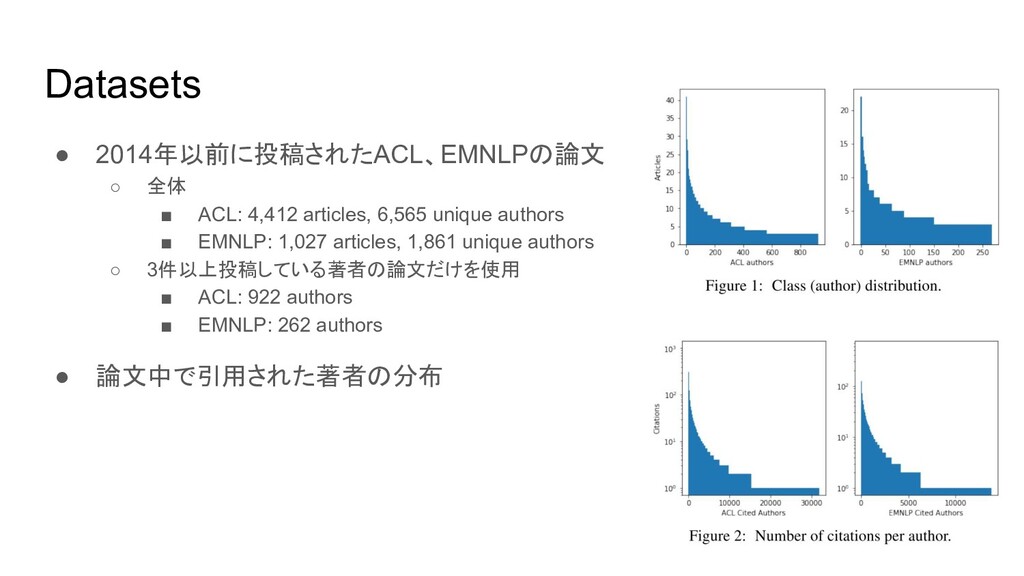{kind=link}
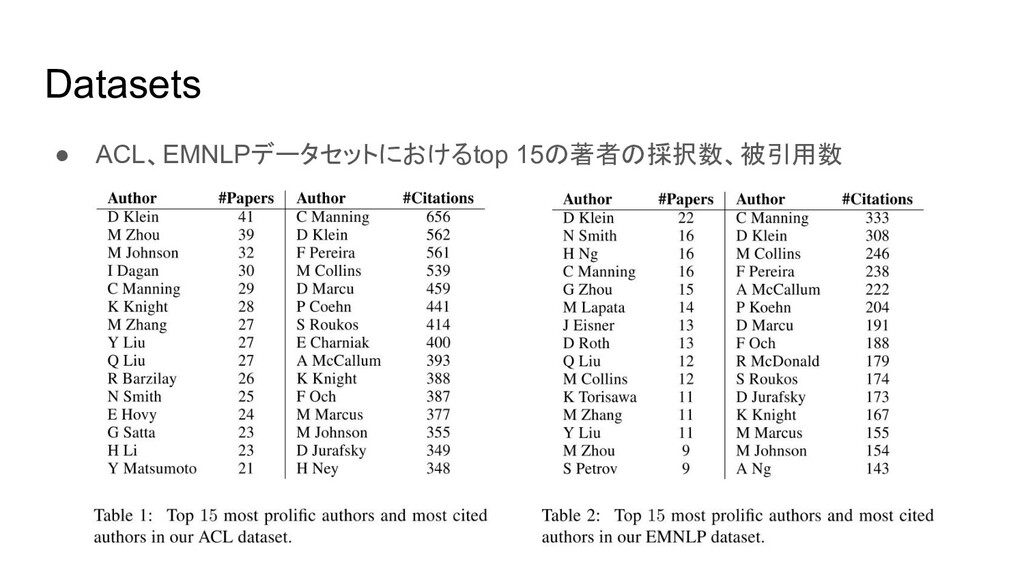{kind=link}
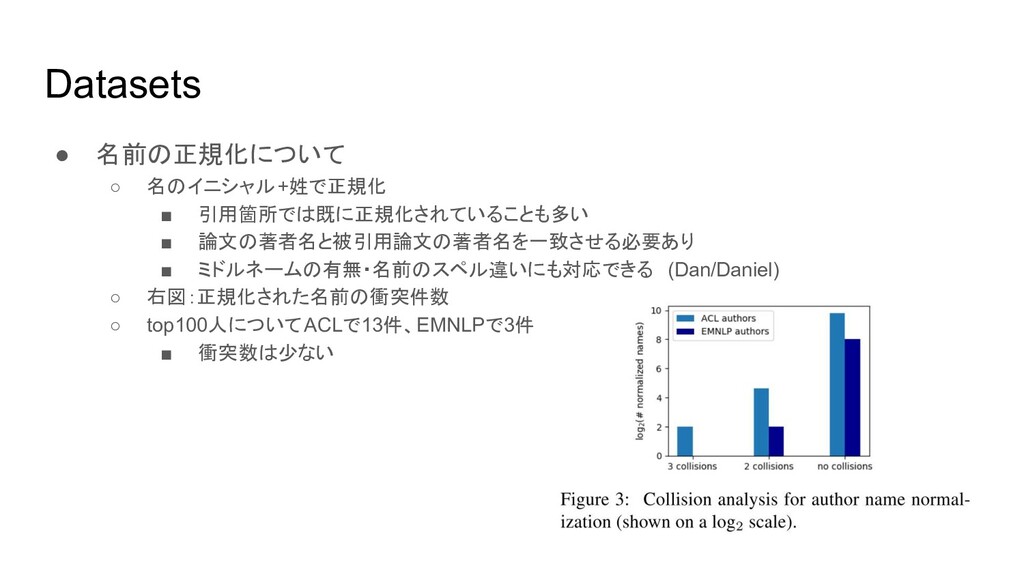{kind=link}
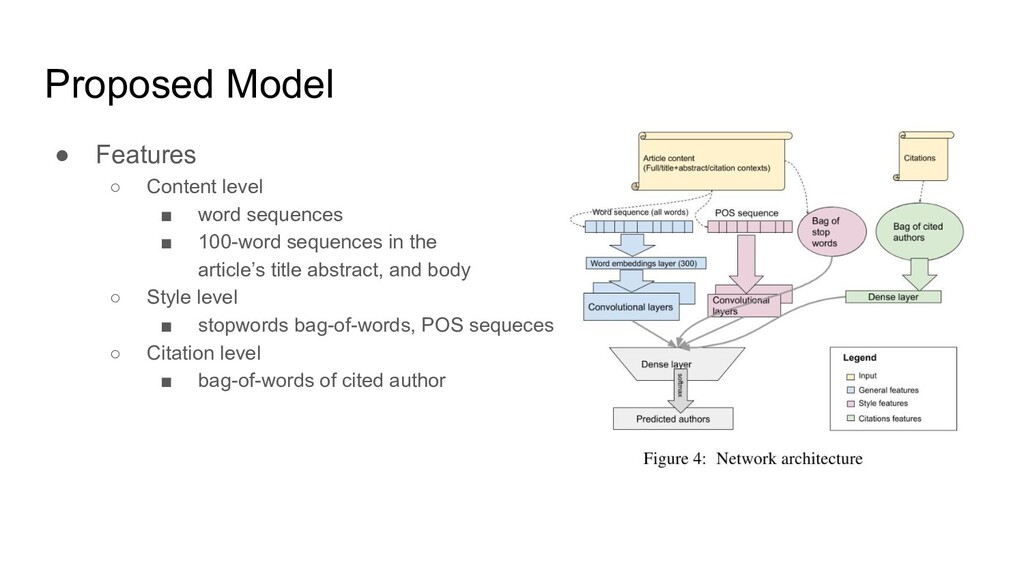{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}