Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
論文紹介 Taking Notes on the Fly Helps Language Pre...
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
Reo
June 10, 2021
Research
44
0
Share
論文紹介 Taking Notes on the Fly Helps Language Pre-Trainig
Reo
June 10, 2021
More Decks by Reo
See All by Reo
論文紹介 Reformer: The Efficient Transformer
reo11
0
260
EMNLP論文紹介 The Myth of Double-Blind Review Revisited: ACL vs. EMNLP
reo11
0
170
論文読み会 How Large Are Lions? Inducing Distributions over Quantitative Attributes
reo11
1
270
ACL読み会 Give Me More Feedback II: Annotating Thesis Strength and Related Attributes in Student Essays
reo11
0
190
NAACL読み会 Attention is not Explanation
reo11
0
180
Other Decks in Research
See All in Research
ForestCast: Forecasting Deforestation Risk at Scale with Deep Learning
satai
3
600
ドメイン知識がない領域での自然言語処理の始め方
hargon24
1
280
姫路市 -都市OSの「再実装」-
hopin
0
1.7k
AIスーパーコンピュータにおけるLLM学習処理性能の計測と可観測性 / AI Supercomputer LLM Benchmarking and Observability
yuukit
1
780
An Open and Reproducible Deep Research Agent for Long-Form Question Answering
ikuyamada
0
370
言語モデルから言語について語る際に押さえておきたいこと
eumesy
PRO
5
1.9k
業界横断 副業コンプライアンス調査 三者(副業者・本業先・発注者)におけるトラブル認知ギャップの構造分析
fkske
0
1.2k
湯村研究室の紹介2025 / yumulab2025
yumulab
0
330
SkySense V2: A Unified Foundation Model for Multi-modal Remote Sensing
satai
3
710
オーストリア流 都市の公共交通サービス水準評価@公共交通オープンデータ最前線2026
trafficbrain
0
110
生成的情報検索時代におけるAI利用と認知バイアス
trycycle
PRO
0
420
R&Dチームを起ち上げる
shibuiwilliam
1
210
Featured
See All Featured
What’s in a name? Adding method to the madness
productmarketing
PRO
24
4k
Bash Introduction
62gerente
615
210k
How to Grow Your eCommerce with AI & Automation
katarinadahlin
PRO
1
160
The SEO Collaboration Effect
kristinabergwall1
0
410
Reflections from 52 weeks, 52 projects
jeffersonlam
356
21k
What the history of the web can teach us about the future of AI
inesmontani
PRO
1
500
Data-driven link building: lessons from a $708K investment (BrightonSEO talk)
szymonslowik
1
990
Learning to Love Humans: Emotional Interface Design
aarron
275
41k
Max Prin - Stacking Signals: How International SEO Comes Together (And Falls Apart)
techseoconnect
PRO
0
140
Optimizing for Happiness
mojombo
378
71k
Easily Structure & Communicate Ideas using Wireframe
afnizarnur
194
17k
Agile Actions for Facilitating Distributed Teams - ADO2019
mkilby
0
160
Transcript
Taking Notes on the Fly Helps Language Pre-Training Qiyu Wu,
Chen Xing, Yatao Li, Guolin Ke, Di He, Tie-Yan Liu Peking University, Nankai University, Microsoft Research ICLR 2021 紹介者: 平尾 礼央(TMU, M2, 小町研究室) 9 June, 2021 @論文紹介
Abstract • 言語モデルの低頻度語問題 ◦ BERT等のモデルは教師なしで言語表現を学習しているが、低頻度語は十分なデータがな く、最適化が不十分でノイズとなりやすい • 低頻度語の辞書を別に用意することで解決 ◦ 低頻語の辞書(Note
Embedding)を追加する、Taking Notes on the Fly(TNF)を提案 ◦ 低頻度語出現時にそちらのベクトルも使用、更新 • BERT、ELECTRAで実験 ◦ 同じlossになるまでの事前学習時間が 60%短縮 ◦ 同じiteration数でGLUEスコア上昇
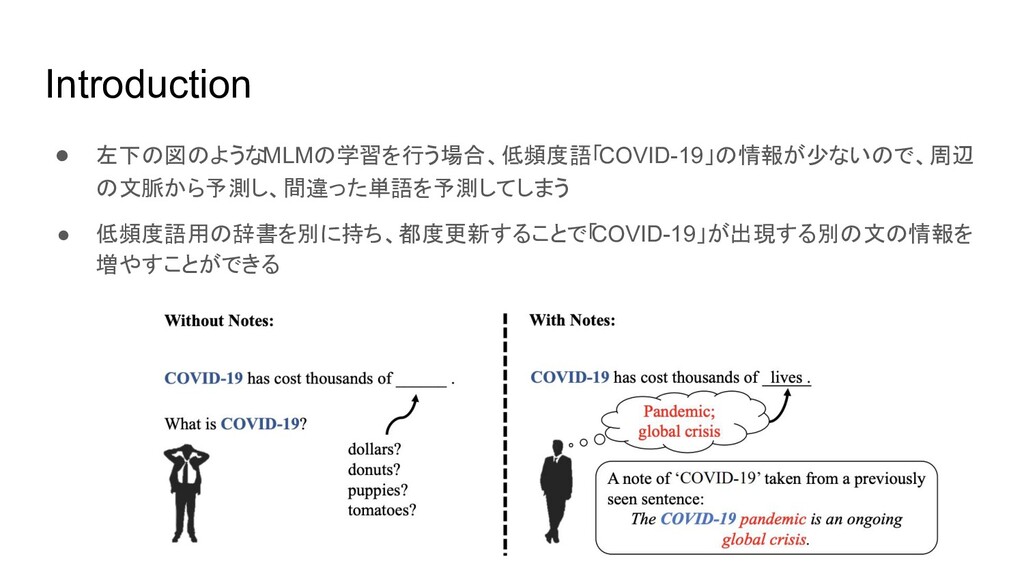
Introduction • 左下の図のようなMLMの学習を行う場合、低頻度語「COVID-19」の情報が少ないので、周辺 の文脈から予測し、間違った単語を予測してしまう • 低頻度語用の辞書を別に持ち、都度更新することで「 COVID-19」が出現する別の文の情報を 増やすことができる
Taking Notes on the Fly • データセット ◦ BERTと同じWikipedia corpusとBook
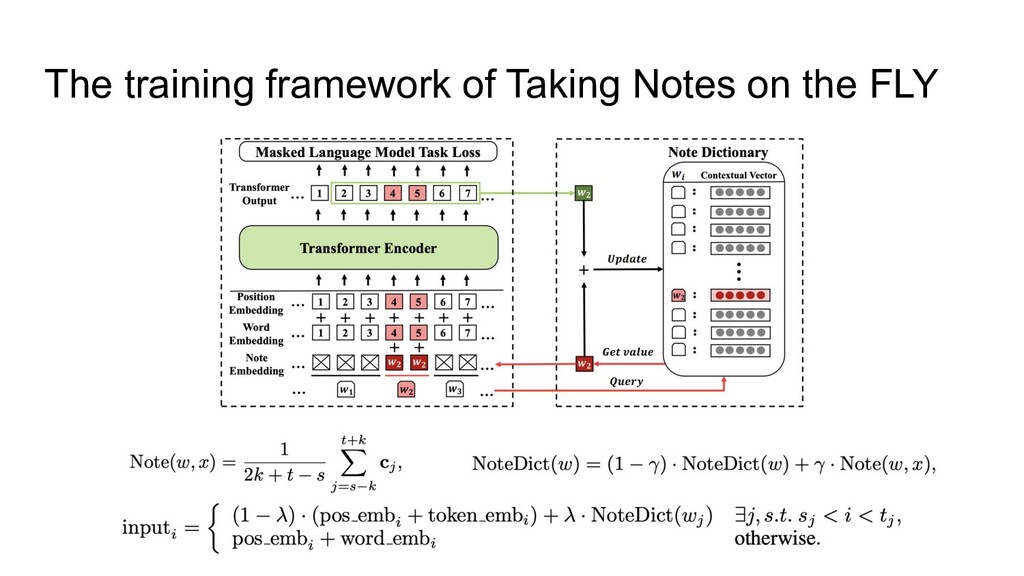
corpus ◦ 合計3.47B words • 低頻度語の定義 ◦ 事前学習データセットの中で 100~500回出現する単語 ◦ 合計200K words程度出現 • 低頻度語の辞書(NoteDict) ◦ word/positional embeddingと同様の方法で初期化、以下の式で更新 ◦ Note: 単語wと入力系列xに対する、wのサブワードに対応する encoder出力(s-k~t+kでkは周辺語の 知識獲得の為のwindow幅) ◦ NoteDict: 学習時の更新方法(今回は γ=0.1, k=16)
The training framework of Taking Notes on the FLY
Pre-training Efficiency • 事前学習 ◦ BERT: Masked Language Modelのみ、ELECTRA: Replace
Token Detection • 事前学習の学習効率、GLUEスコア改善 ◦ 下図 (a), (b)で、TNFを使った方がlossの減りが早い ◦ (c)では、同じIteration数でもTNFの方がGLUEスコアが高い ▪ TNFにより低頻度語のノイズを減らせたため効率 ↑
Results • GLUEの各タスクと全体のスコア ◦ F: fine-tune時もNoteDictの更新 ◦ U: fine-tune時はback-propagationにより学習 ◦
TNFは下流タスクのデータが小さい時に特に効果的な初期状態を提供する
Conclusion • 言語モデル学習時の低頻度語問題に注目 ◦ 低頻度語の不十分な学習による、全体の事前学習効率低下の可能性を指摘 ◦ 低頻度語用の辞書を持つ Taking Notes on
the Fly(TNF)を提案 • 低頻度語用の辞書 ◦ 使用時にその辞書から呼び出すことで情報強化 ◦ encoder出力を使用し、直接更新をかける • まとめ ◦ 同じ性能に達するまでの事前学習時間 60%短縮 ◦ 同じ数のiteration数でTNFを使った方がGLUEスコアが高い ◦ 特に下流タスクのデータが少ない場合に有効 • open reviewのコメント ◦ シンプルな手法で良い結果になっているが、分析が不十分( 6,6,6,7)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}