Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
論文紹介 Reformer: The Efficient Transformer
Search
Sponsored
·
SiteGround - Reliable hosting with speed, security, and support you can count on.
→
Reo
May 27, 2020
Technology
260
0
Share
論文紹介 Reformer: The Efficient Transformer
I will give a presentation on the following paper.
https://openreview.net/forum?id=rkgNKkHtvB
Reo
May 27, 2020
More Decks by Reo
See All by Reo
論文紹介 Taking Notes on the Fly Helps Language Pre-Trainig
reo11
0
44
EMNLP論文紹介 The Myth of Double-Blind Review Revisited: ACL vs. EMNLP
reo11
0
170
論文読み会 How Large Are Lions? Inducing Distributions over Quantitative Attributes
reo11
1
270
ACL読み会 Give Me More Feedback II: Annotating Thesis Strength and Related Attributes in Student Essays
reo11
0
190
NAACL読み会 Attention is not Explanation
reo11
0
180
Other Decks in Technology
See All in Technology
Databricks Appsで実現する社内向けAIアプリ開発の効率化
r_miura
0
160
JEDAI認定プログラム JEDAI Order 2026 受賞者一覧 / JEDAI Order 2026 Winners
databricksjapan
0
410
15年メンテしてきたdotfilesから開発トレンドを振り返る 2011 - 2026
giginet
PRO
2
250
RGBに陥らないために -プロダクトの価値を届けるまで-
righttouch
PRO
0
130
Bill One 開発エンジニア 紹介資料
sansan33
PRO
5
18k
最大のアウトプット術は問題を作ること
ryoaccount
0
210
TUNA Camp 2026 京都Stage ヒューリスティックアルゴリズム入門
terryu16
0
650
Oracle Cloud Infrastructure(OCI):Onboarding Session(はじめてのOCI/Oracle Supportご利⽤ガイド)
oracle4engineer
PRO
2
17k
Navigation APIと見るSvelteKitのWeb標準志向
yamanoku
2
130
自分をひらくと次のチャレンジの敷居が下がる
sudoakiy
3
1.1k
フルカイテン株式会社 エンジニア向け採用資料
fullkaiten
0
11k
【AWS】CloudTrail LakeとCloudWatch Logs Insightsの使い分け方針
tsurunosd
0
130
Featured
See All Featured
Why You Should Never Use an ORM
jnunemaker
PRO
61
9.8k
SEO for Brand Visibility & Recognition
aleyda
0
4.4k
What the history of the web can teach us about the future of AI
inesmontani
PRO
1
500
Building the Perfect Custom Keyboard
takai
2
720
Claude Code どこまでも/ Claude Code Everywhere
nwiizo
64
54k
Speed Design
sergeychernyshev
33
1.6k
Pawsitive SEO: Lessons from My Dog (and Many Mistakes) on Thriving as a Consultant in the Age of AI
davidcarrasco
0
96
Become a Pro
speakerdeck
PRO
31
5.9k
Building AI with AI
inesmontani
PRO
1
840
Visualization
eitanlees
150
17k
Let's Do A Bunch of Simple Stuff to Make Websites Faster
chriscoyier
508
140k
Dealing with People You Can't Stand - Big Design 2015
cassininazir
367
27k
Transcript
Reformer: The Efficient Transformer Nikita Kitaev*, Lukasz Kaiser*, Anselm Levskaya*
*Google Research ICLR 2020 紹介者: 平尾 礼央(TMU, M1, 小町研究室) 26 May, 2020 @論文紹介
Abstract • Transformerの計算時間、メモリ使用量を効率化したReformerの提案 • Attention Weightが小さいものを計算するのは無駄 ➢ Locality Sensitive Hashingで近いものだけ計算
• 逆伝播のために各レイヤで値を保持しておくのがメモリを圧迫 ➢ Reversible Layerで逆伝播時に毎回計算 • Transformerと同程度の性能でメモリ効率を改善し、長い系列で高速化する 事に成功
Introduction • Transformerを使ったモデルは様々なNLPタスクでSoTA • 最近のモデルはレイヤ数、系列長が増加し、パラメータ数も膨大 • 計算資源がある限られた研究所だけが訓練できる • 計算が増える原因と対策: ◦
Attentionの計算では系列長Lに対して、時間、空間(メモリ)共に O(L^2)で増加 ➢ Locality Sensitive Hashingでクラスタに分け、近い単語のみを計算 ◦ レイヤ数がN倍になるとそれぞれのレイヤが格納しておくべき activationがN倍 ➢ Reversible Layerで全体で1つのactivation(1つ後のレイヤ出力)さえあればよい
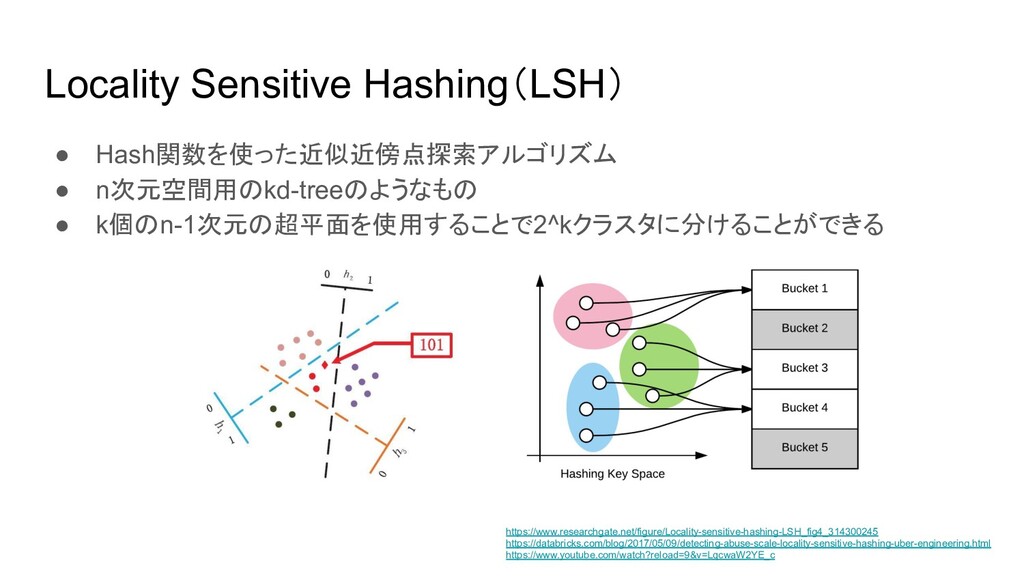
Locality Sensitive Hashing(LSH) • Hash関数を使った近似近傍点探索アルゴリズム • n次元空間用のkd-treeのようなもの • k個のn-1次元の超平面を使用することで2^kクラスタに分けることができる https://www.researchgate.net/figure/Locality-sensitive-hashing-LSH_fig4_314300245
https://databricks.com/blog/2017/05/09/detecting-abuse-scale-locality-sensitive-hashing-uber-engineering.html https://www.youtube.com/watch?reload=9&v=LqcwaW2YE_c
Locality Sensitive Hashing Attention LSHによる ハッシュ化 同じグループ 同士で計算
Complexity in Attention Part • nr: ハッシュを繰り返す回数 ◦ LSHはシードによって異なる bucketに分けられる可能性があるため
• nc: LSHのchunk数 ◦ Lが長くなるほど増えるため、 L/ncが実質logL ➢ これでAttentionの計算量の問題は解決!では逆伝播は?
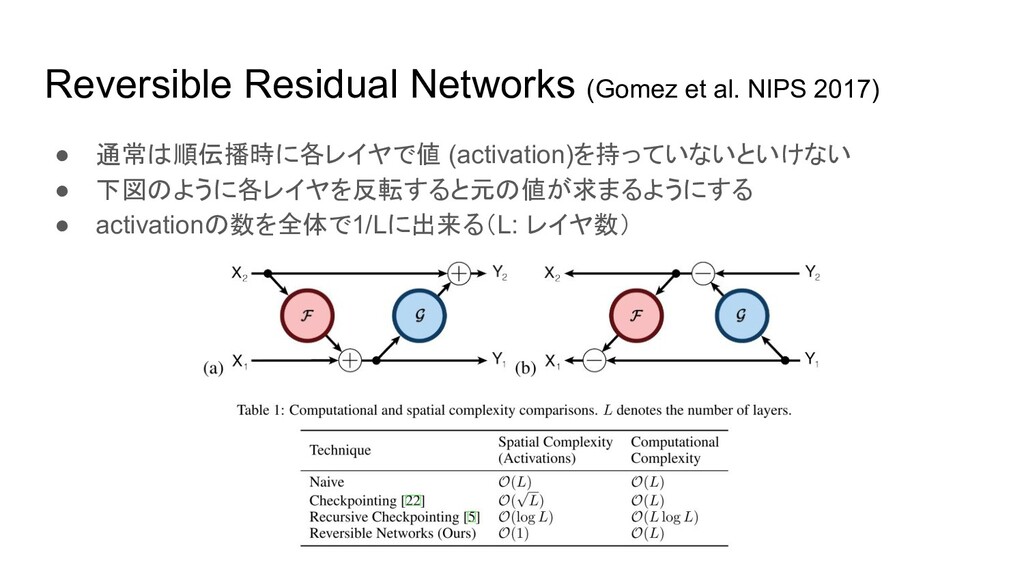
Reversible Residual Networks (Gomez et al. NIPS 2017) • 通常は順伝播時に各レイヤで値
(activation)を持っていないといけない • 下図のように各レイヤを反転すると元の値が求まるようにする • activationの数を全体で1/Lに出来る(L: レイヤ数)
Complexity of Reformer • Reversible Residual Networksと同様に各レイヤで反転できるように変更 • 空間、時間計算量共にLが取れてc(O(logL)) になっている
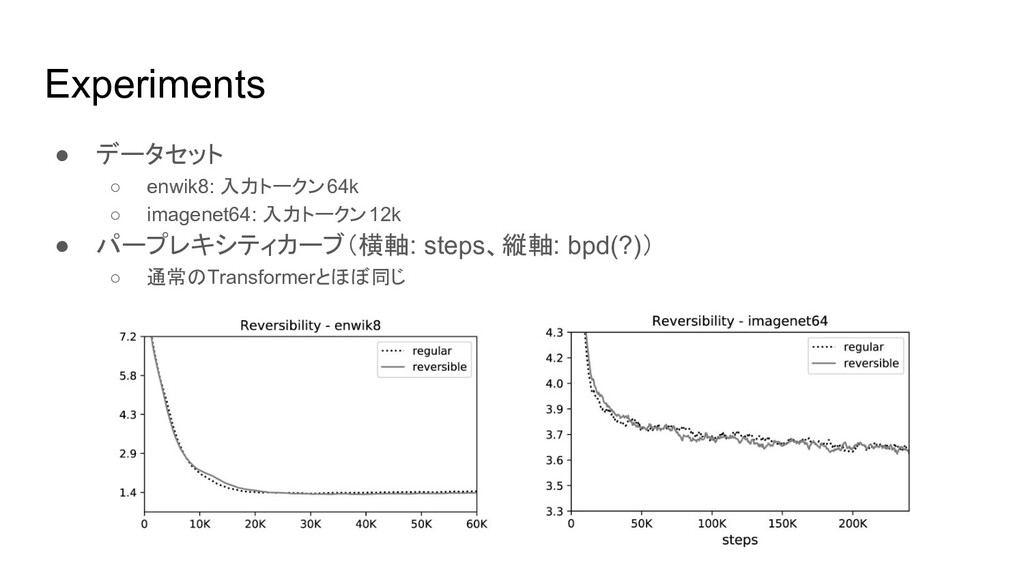
Experiments • データセット ◦ enwik8: 入力トークン64k ◦ imagenet64: 入力トークン12k •
パープレキシティカーブ(横軸: steps、縦軸: bpd(?)) ◦ 通常のTransformerとほぼ同じ
Translation Task • WMT2014 English-to-German ◦ オリジナルのTransformerとほぼ同じ
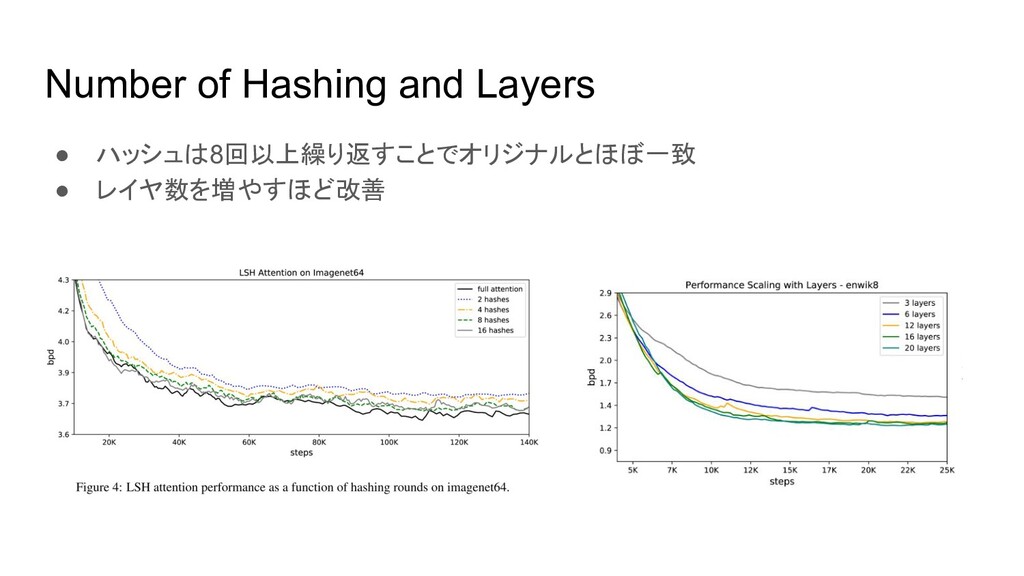
Number of Hashing and Layers • ハッシュは8回以上繰り返すことでオリジナルとほぼ一致 • レイヤ数を増やすほど改善
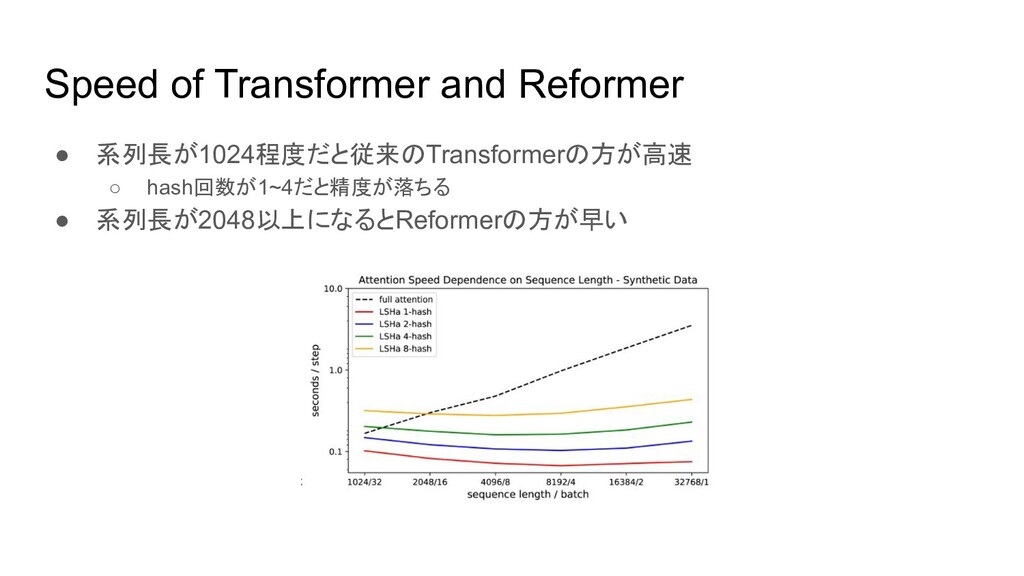
Speed of Transformer and Reformer • 系列長が1024程度だと従来のTransformerの方が高速 ◦ hash回数が1~4だと精度が落ちる •
系列長が2048以上になるとReformerの方が早い
Conclusion • ReformerはTransformerと同程度の表現力を持つ • 長い系列でも効率的に実行でき、レイヤ数が増えても少ないメモリ使用量で実行で きる • これにより、計算資源が少なくても大きいTransformerモデルを扱える • 時系列や動画、音楽など幅広い分野でTransformerを使うことできる
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}