Slides from http://velocityconf.com/velocityny2014/public/schedule/detail/35815
Video at https://www.youtube.com/watch?v=PJbKTJN3ThY
See https://speakerdeck.com/rjpcal/velocity-ny-2014-deploying-on-the-edge for slides without notes
We operate a global edge network that delivers many types of modern web traffic, including dynamic applications, websites, mobile apps, live and on-demand streams, and large-file downloads. We strive to maintain reliability, performance, and functionality as we develop and deploy the http server software that handles this traffic. In this talk we’ll cover the evolution of our deployment best practices as we have learned from the community and from our own experiences, including the following:
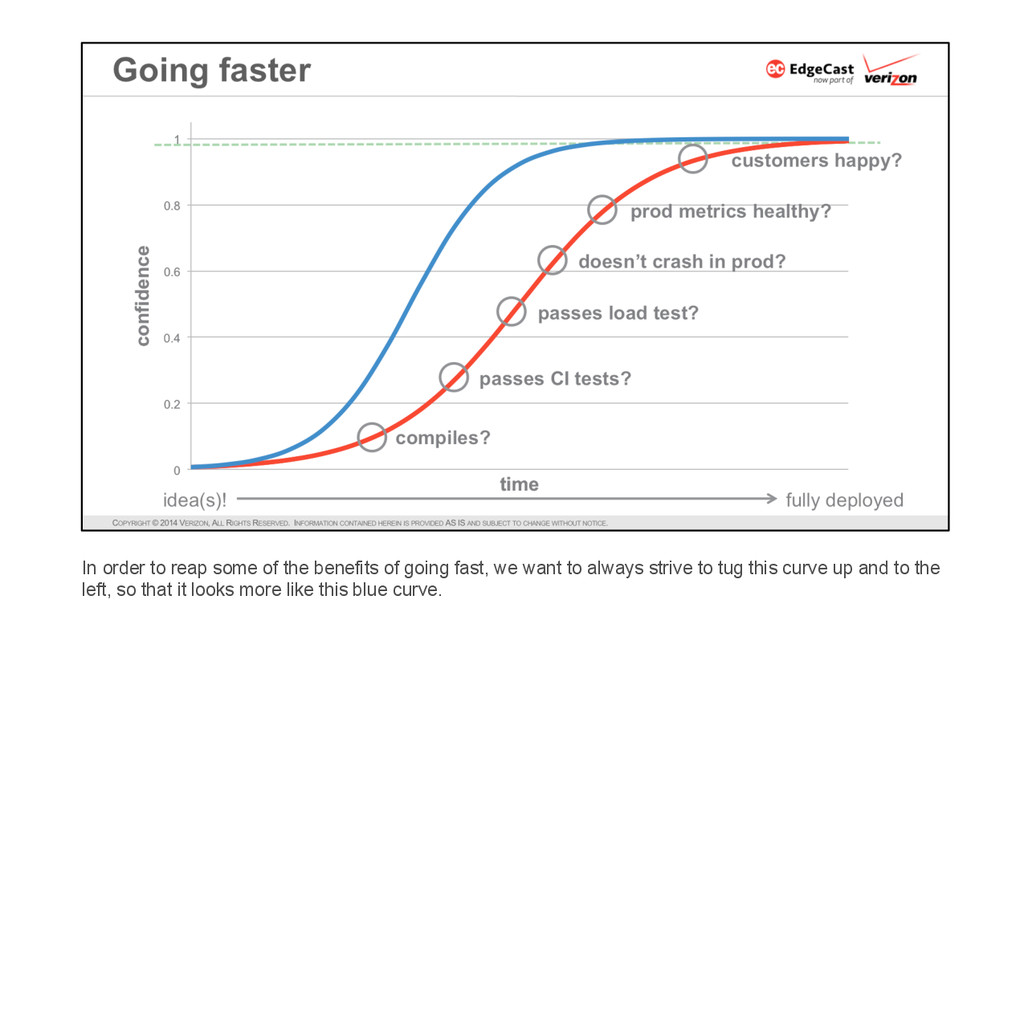
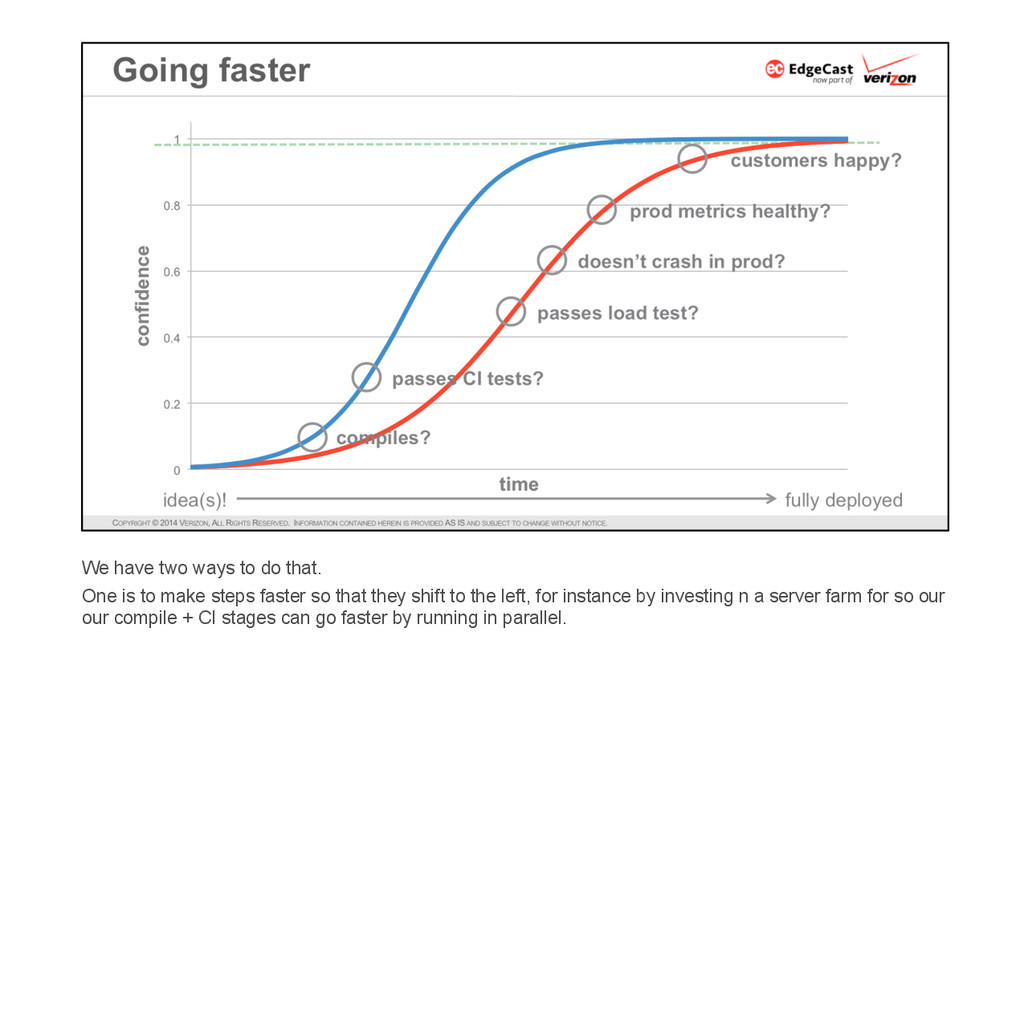
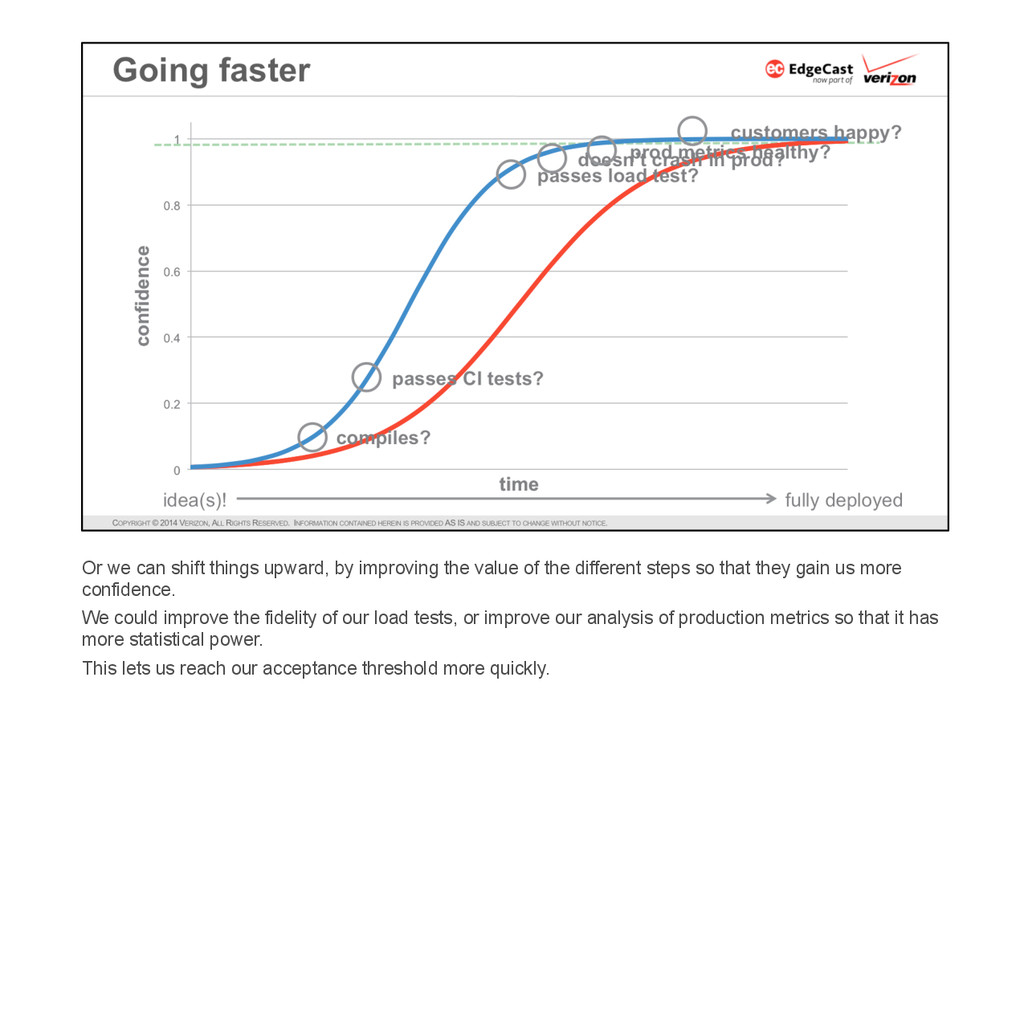
* Go fast — the deployment cycle should be as short as possible in order to minimize batch size (so as to constrain the scope of the unexpected, because there is always something unexpected) and reduce risk and mean-time-to-recovery.
* But not too fast — the deployment cycle should be long enough to be very confident that the latest release has no new issues before moving on to the next release. The time to “long enough” may vary significantly depending on the layer of the software stack.
* Monitor everything — you can’t fix a problem until you can visualize it.
* But really monitor just a few things — find the smallest set of vital signs that can reliably indicate “is everything running smoothly?”
* Be able to roll forward/backward almost instantly, keeping in mind that the links between command/control and edge systems may be slow and/or lossy.
* Be “lazy" — a programmer’s “lazy” can mean spending days building something that turns a 10-second task into a 2-second task. This is exactly the right approach when it comes to deployment, where it means spending extra time to ensure that new code and configurations are built in such a way that they can be deployed painlessly. This often amounts to strict compatibility between the default behaviors of adjacent versions, configurability to easily turn new functionality on/off, and comprehensive hooks for testing and monitoring.
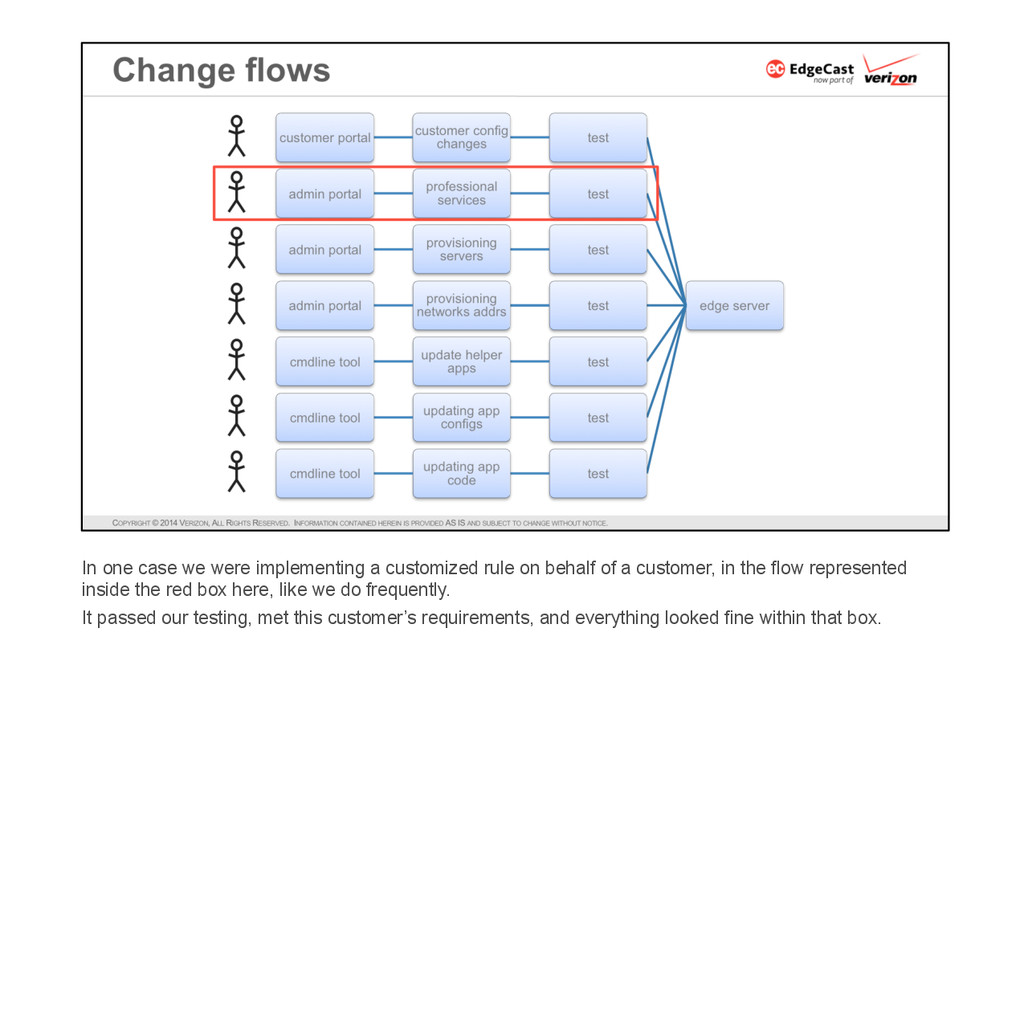
* Minimize risk in the deployment process itself — while each new software update may have different and unique changes, the procedure for deploying the update can be the same every time.
* Don’t be too portable/configurable — if the application should never run in production without package XYZ, then it shouldn’t pretend to be portable to an environment without XYZ.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
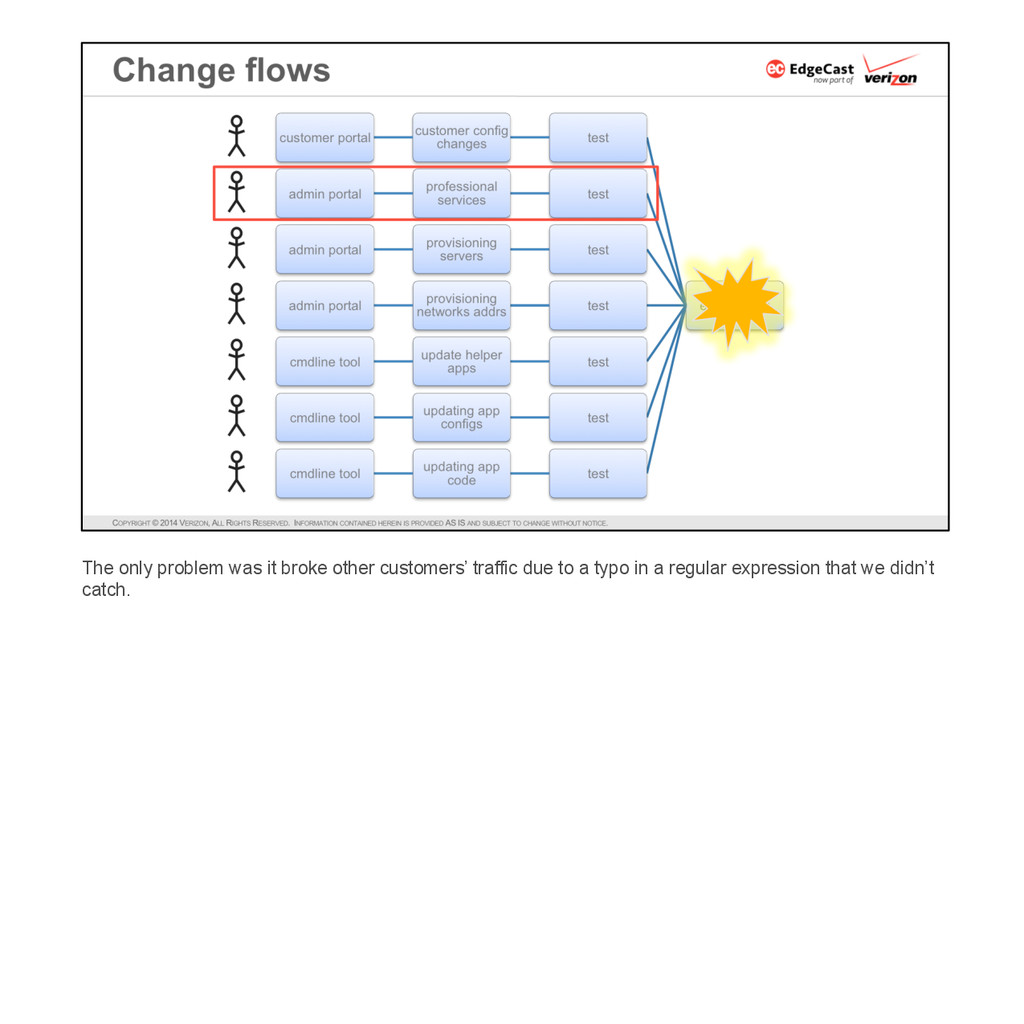{kind=link}
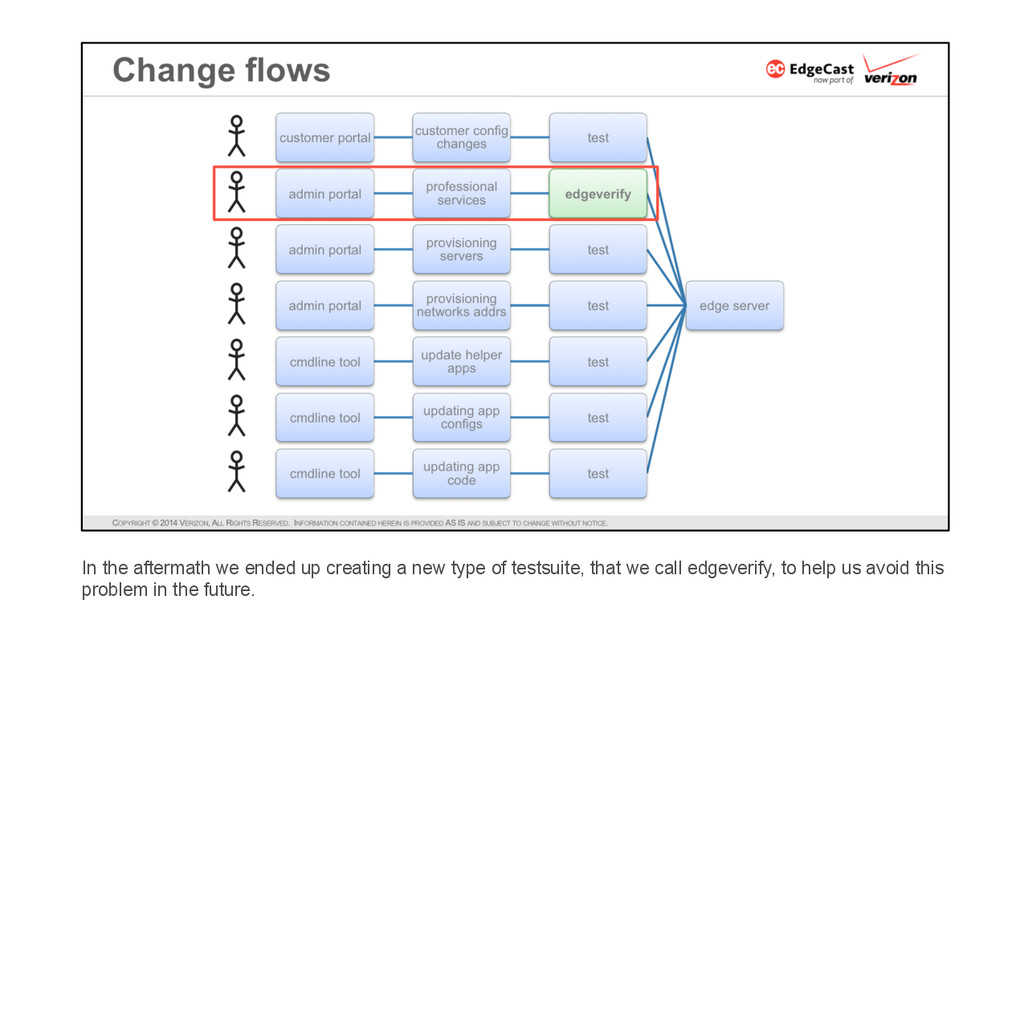{kind=link}
{kind=link}
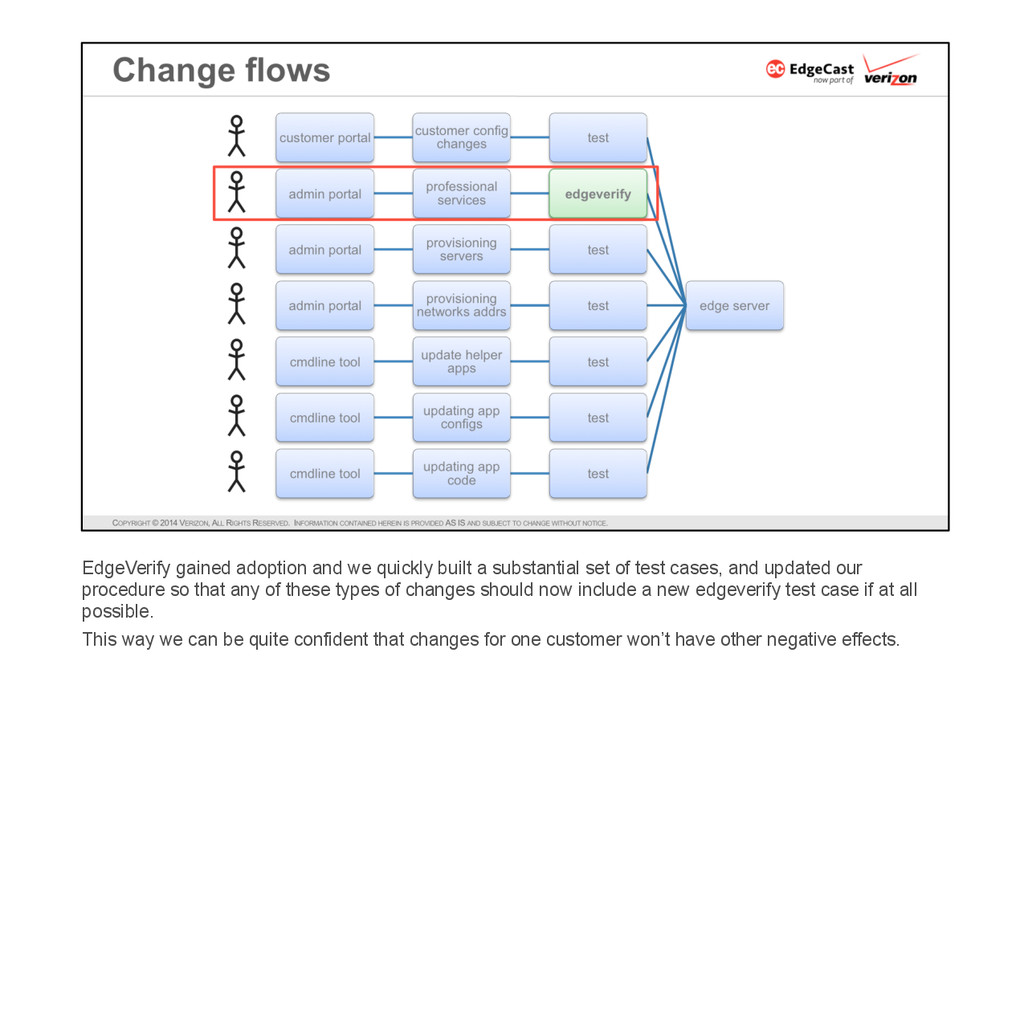{kind=link}
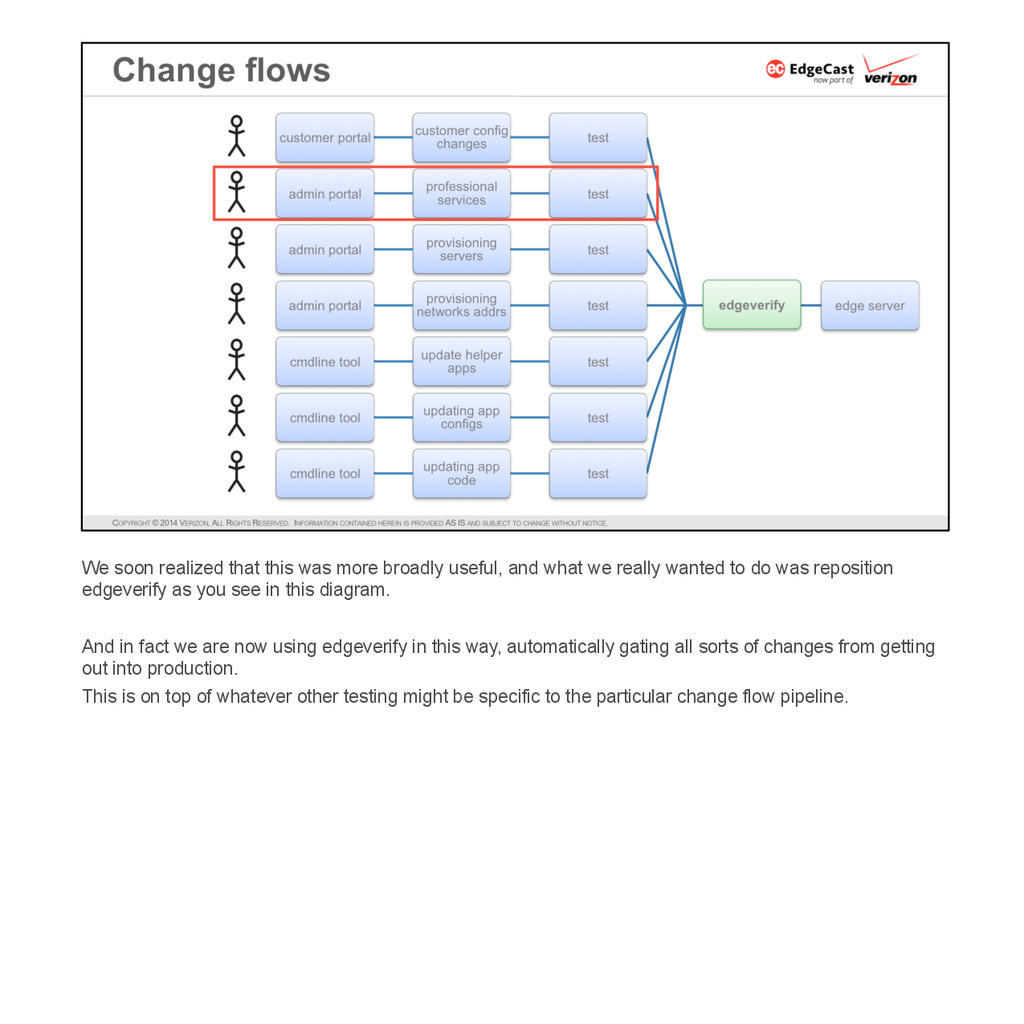{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
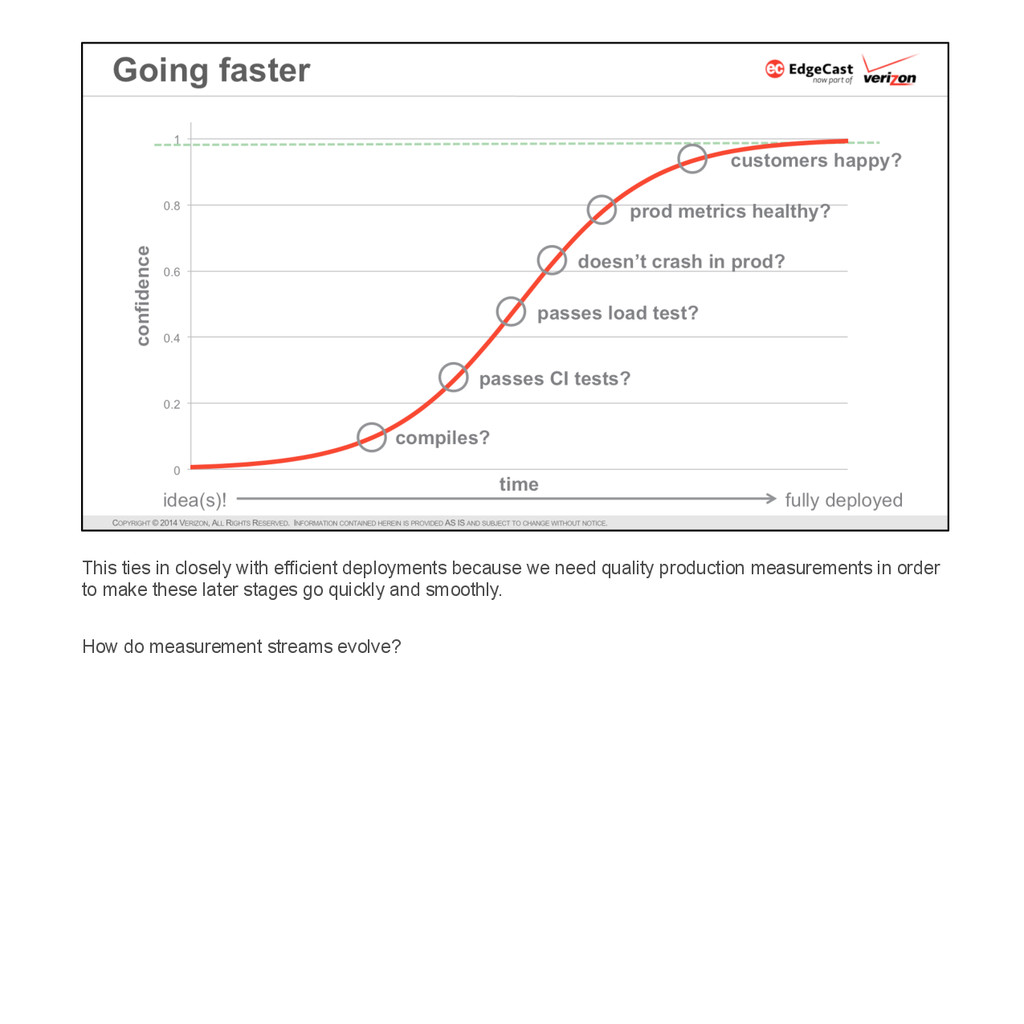{kind=link}
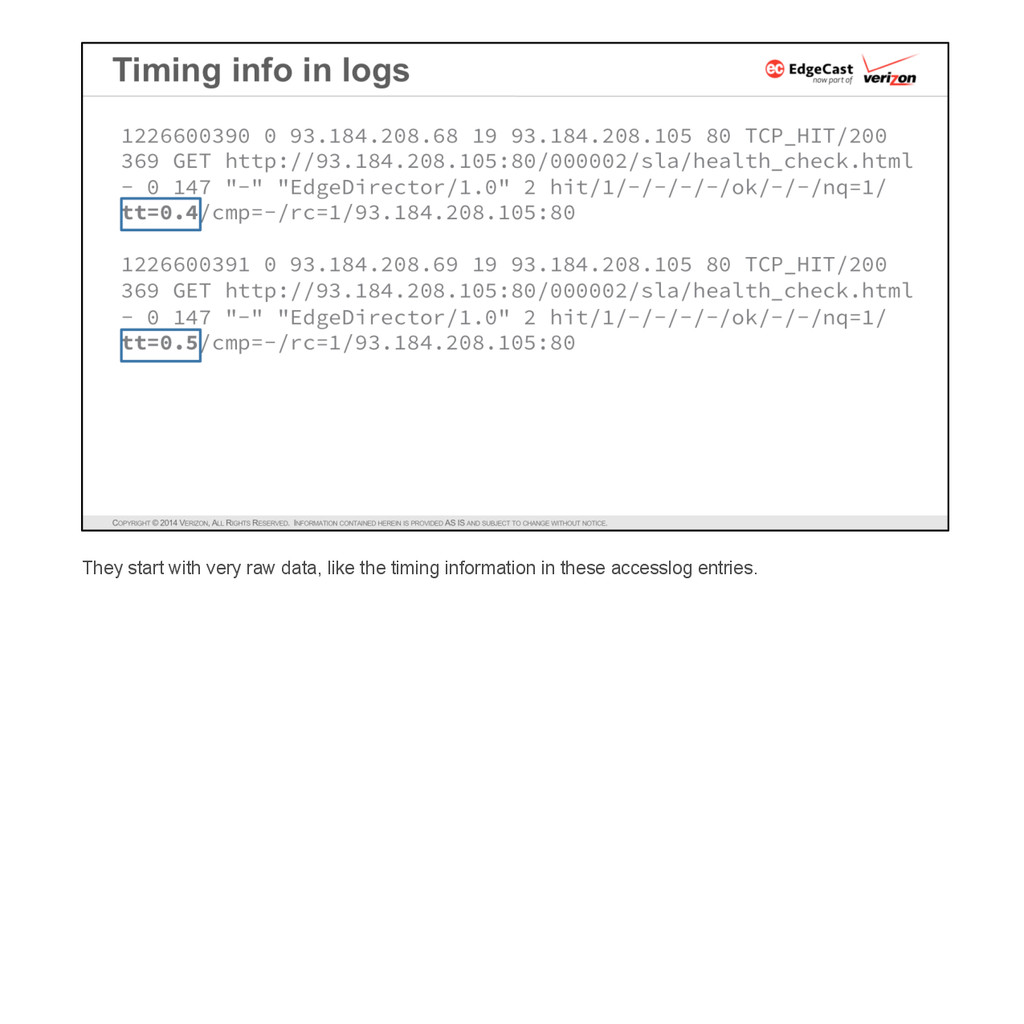{kind=link}
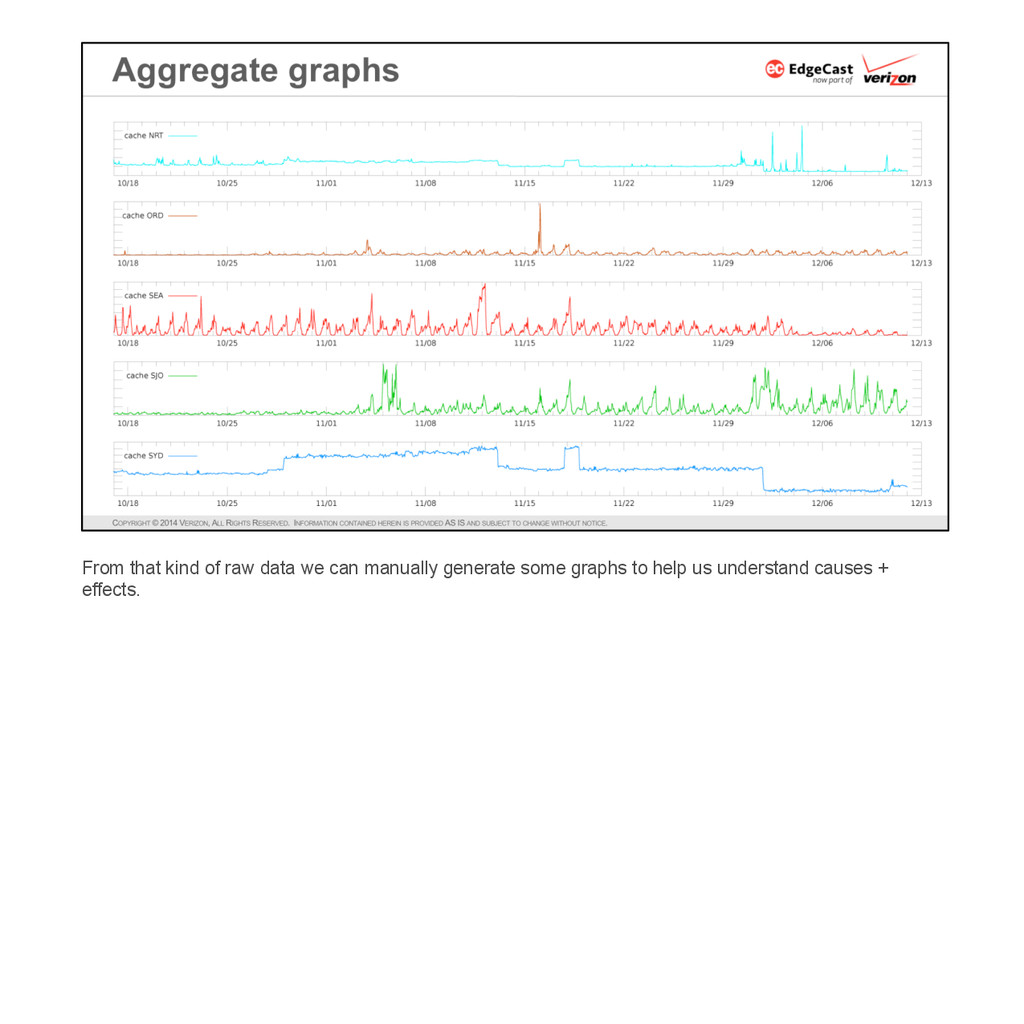{kind=link}
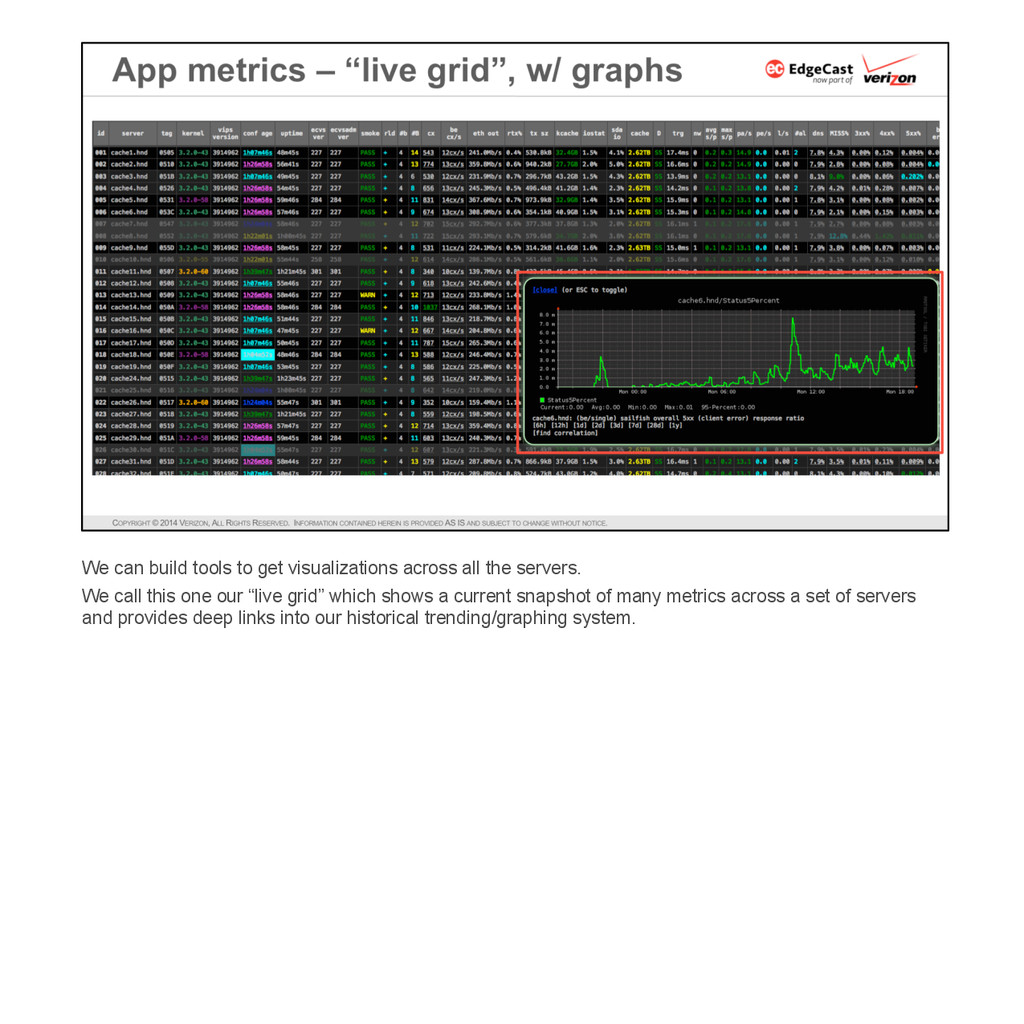{kind=link}
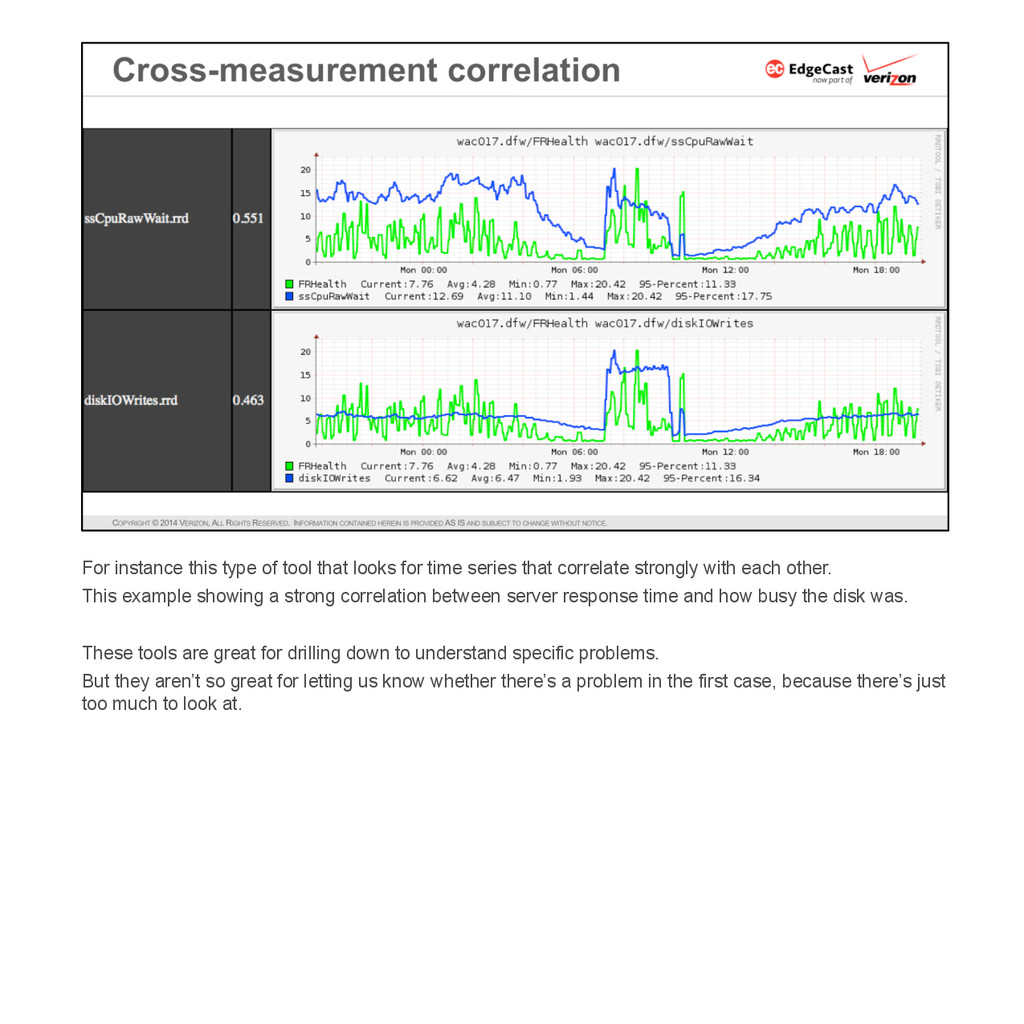{kind=link}
{kind=link}
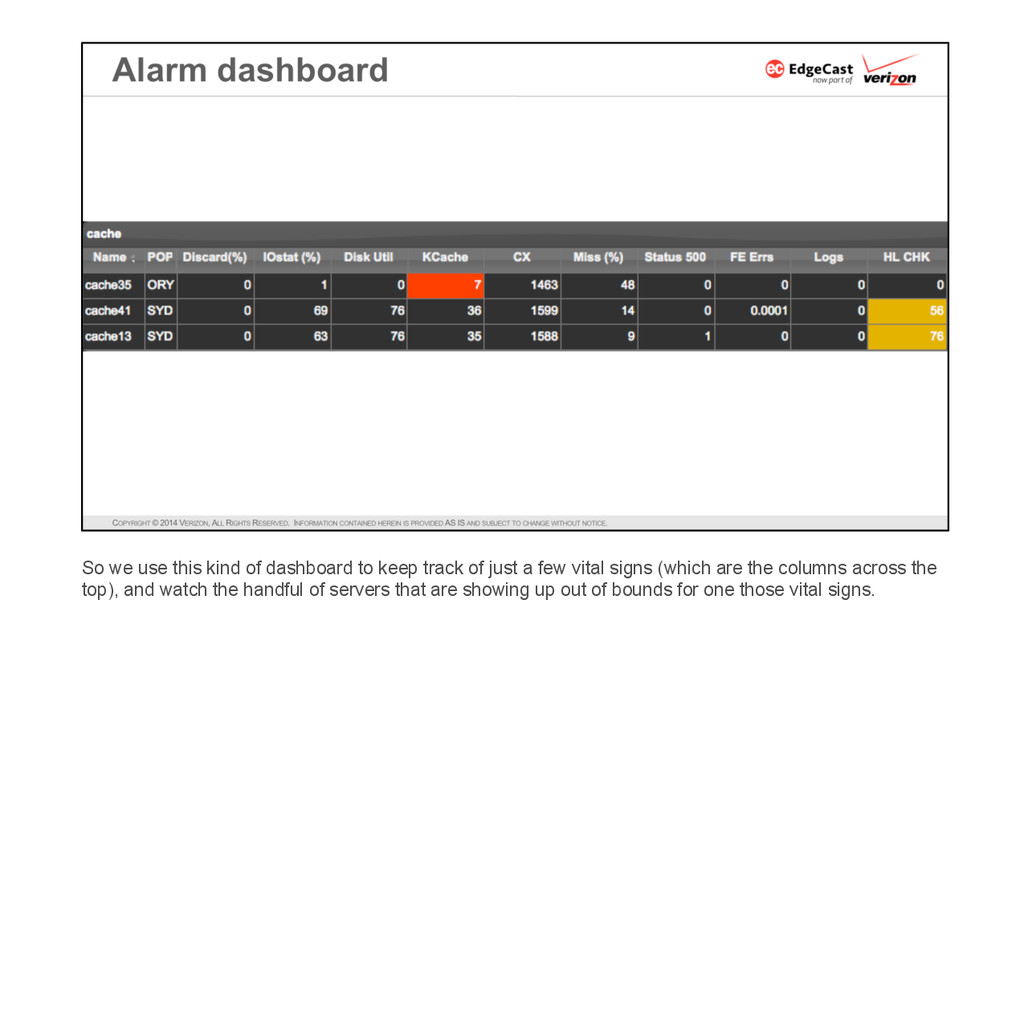{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
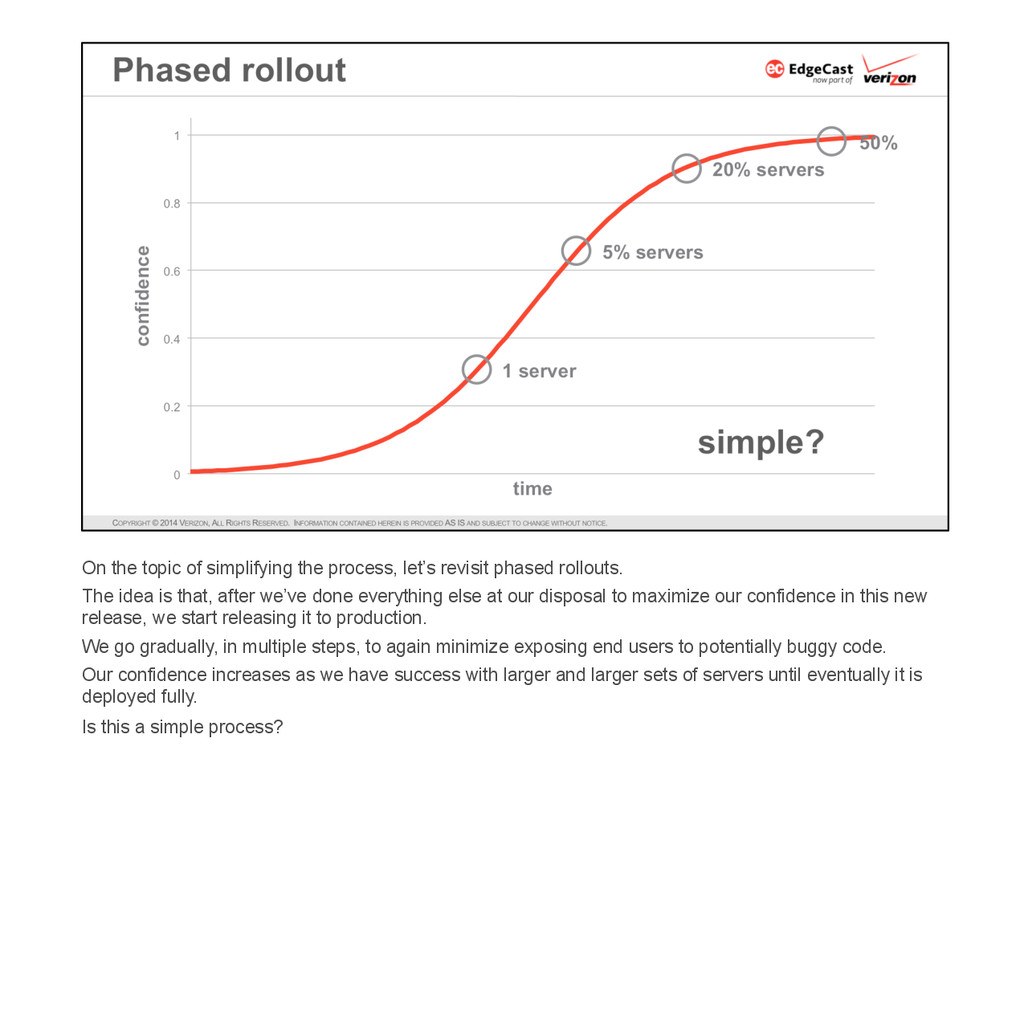{kind=link}
{kind=link}
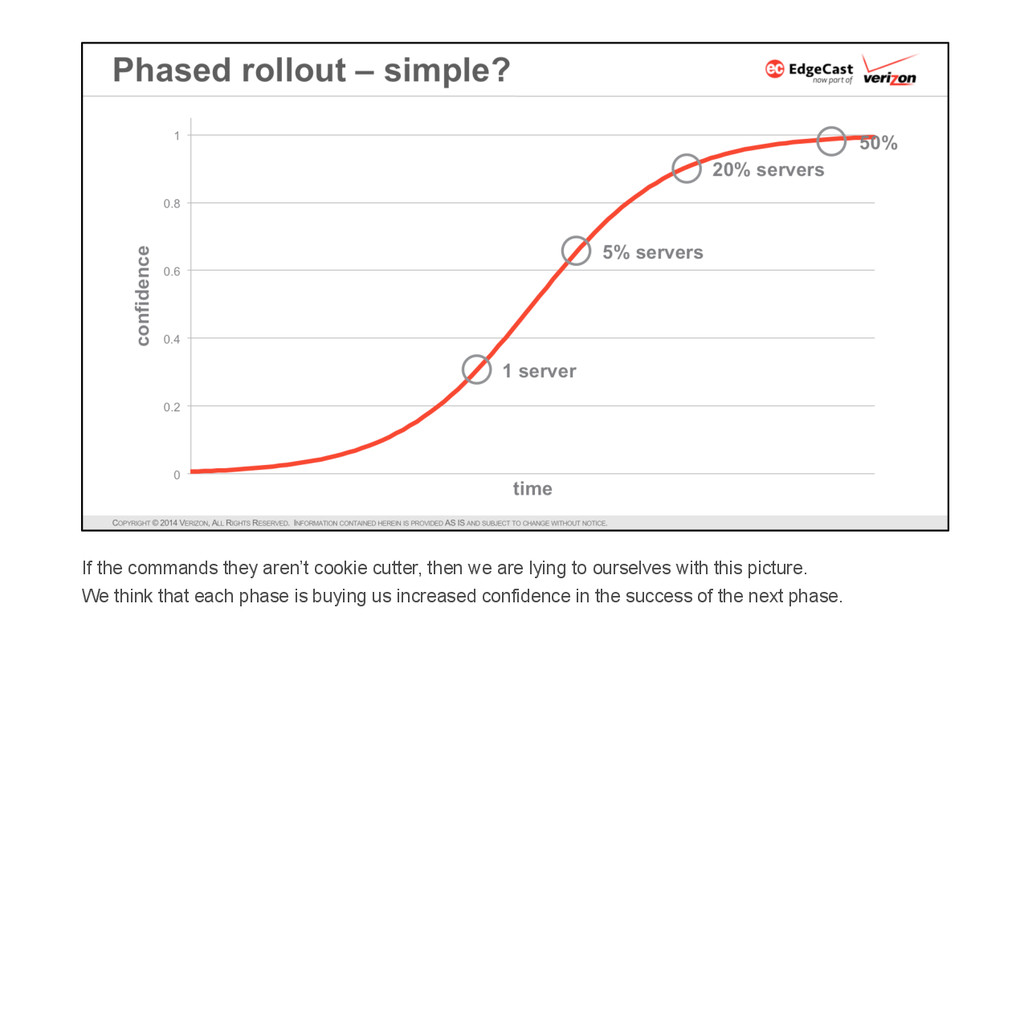{kind=link}
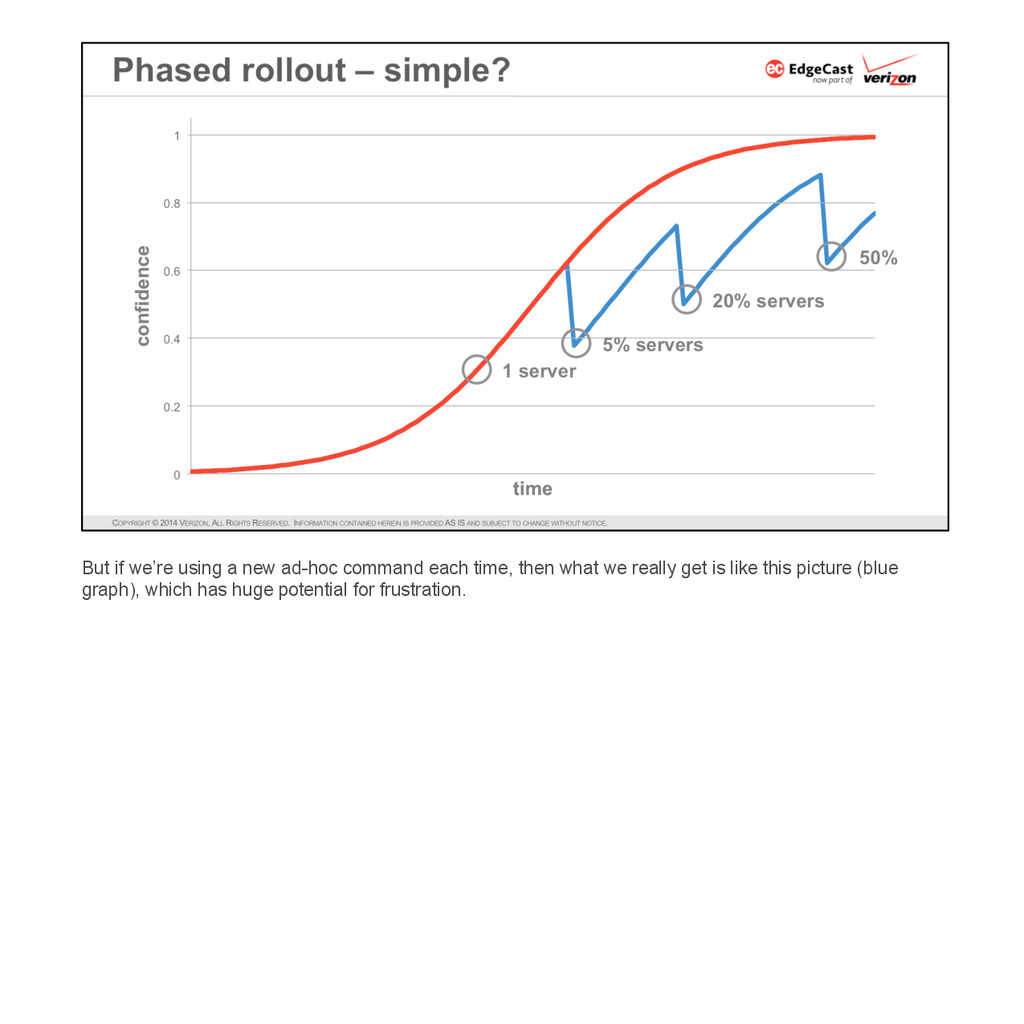{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
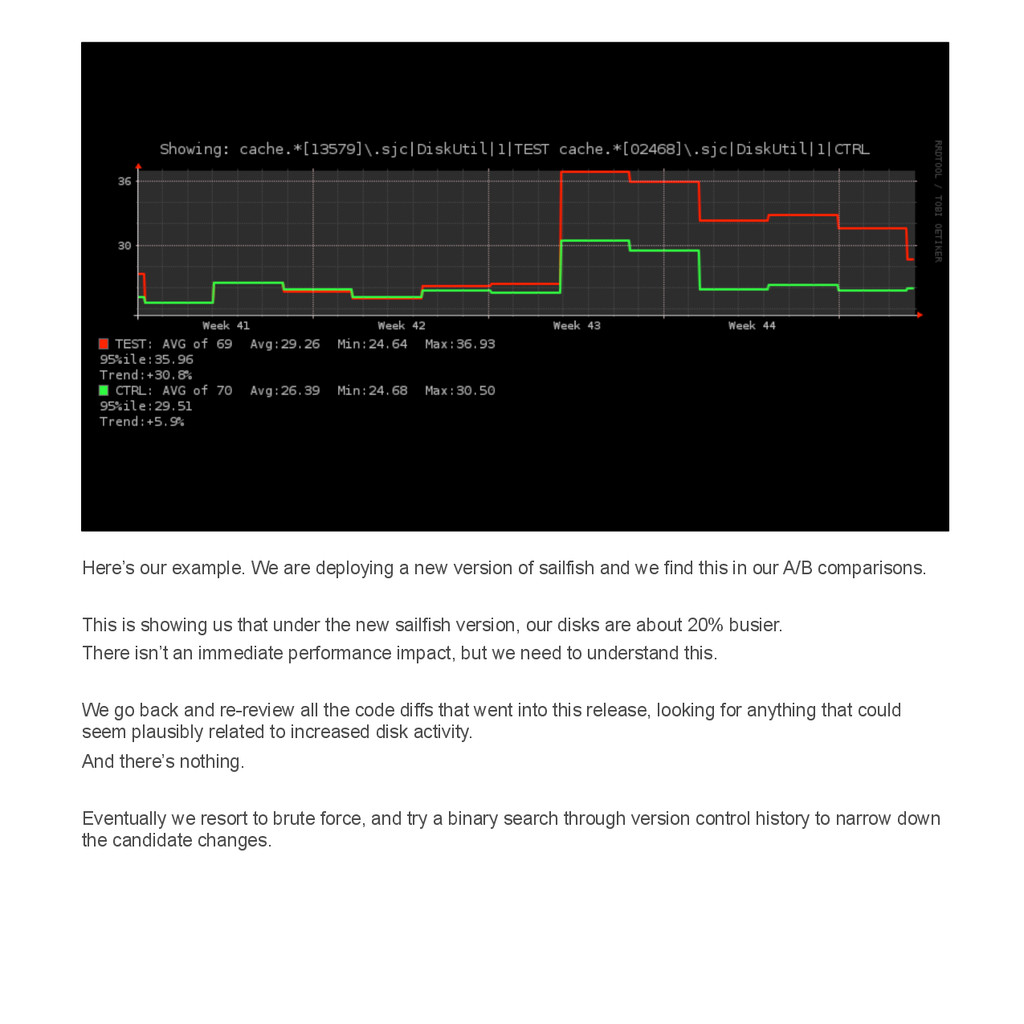{kind=link}
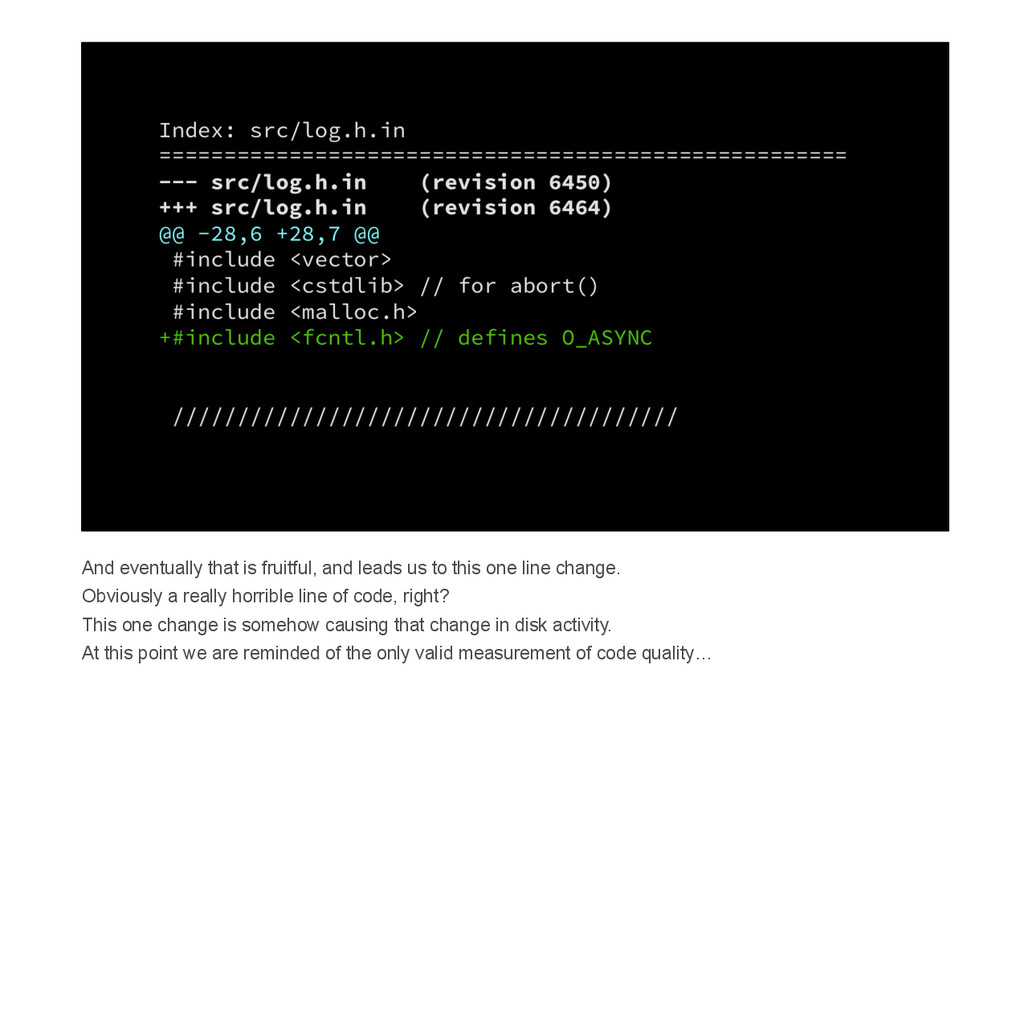{kind=link}
{kind=link}
{kind=link}
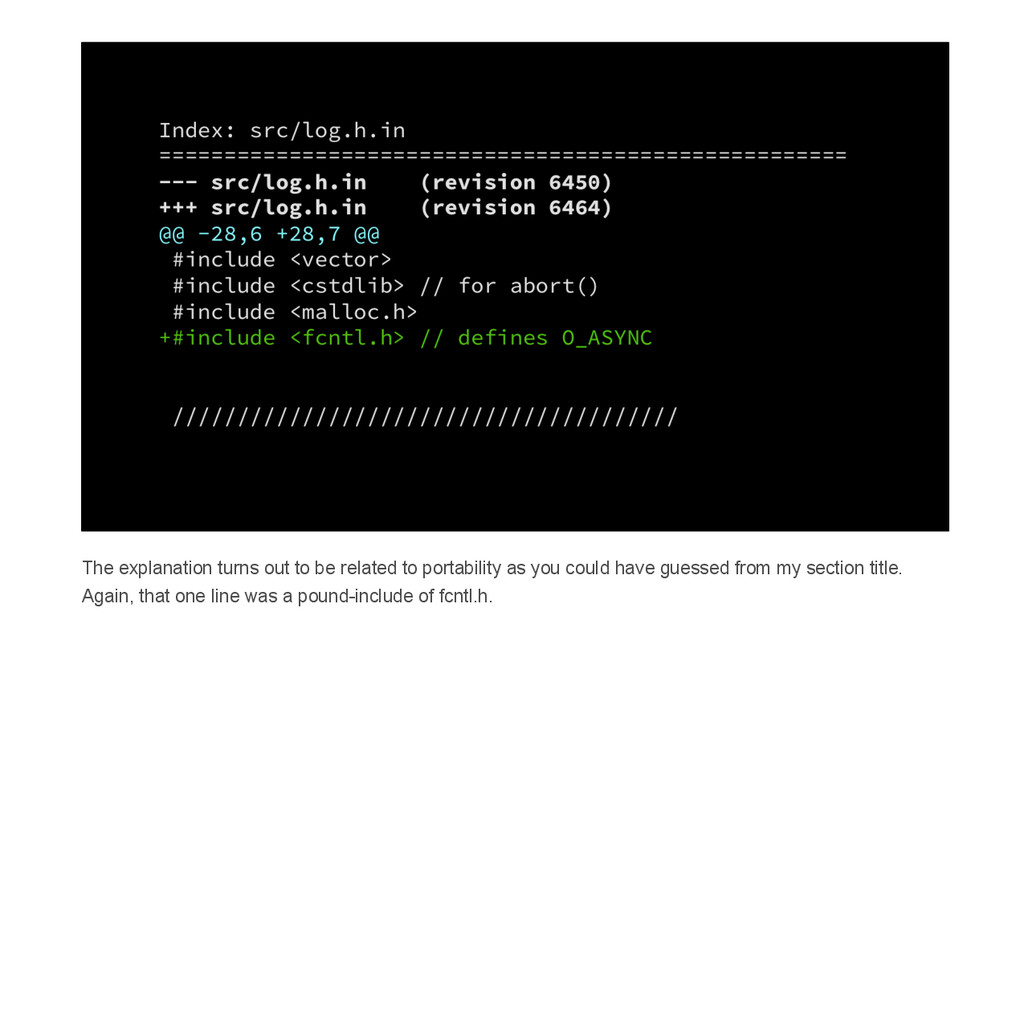{kind=link}
{kind=link}
{kind=link}
{kind=link}