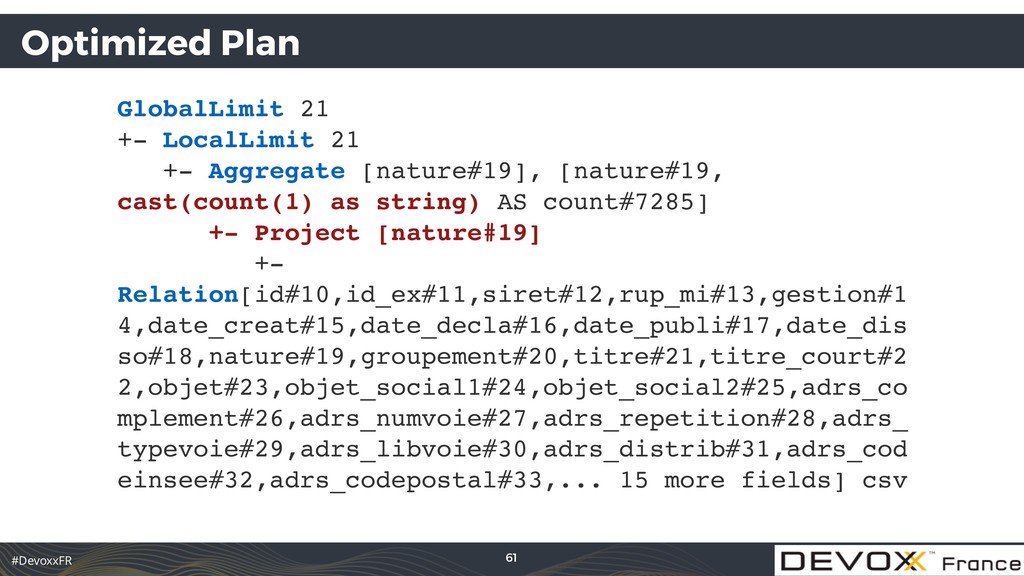
[cast(nature#19 as string) AS nature#7284, cast(count#7276L as string) AS count#7285] +- Aggregate [nature#19], [nature#19, count(1) AS count#7276L] +- Relation[id#10,id_ex#11,siret#12,rup_mi#13,gestion#14,d ate_creat#15,date_decla#16,date_publi#17,date_disso#18, nature#19,groupement#20,titre#21,titre_court#22,objet#2 3,objet_social1#24,objet_social2#25,adrs_complement#26, adrs_numvoie#27,adrs_repetition#28,adrs_typevoie#29,adr s_libvoie#30,adrs_distrib#31,adrs_codeinsee#32,adrs_cod epostal#33,... 15 more fields] csv 55
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![#DevoxxFR RDD API 11 RDD[T] <=> Seq[T]](https://files.speakerdeck.com/presentations/4e72303327e8466ca34b8f81506ac0a9/slide_23.jpg){kind=link}
![#DevoxxFR Transformations vs Actions 12 RDD[T] => RDD[U] map flatMap](https://files.speakerdeck.com/presentations/4e72303327e8466ca34b8f81506ac0a9/slide_24.jpg){kind=link}
{kind=link}
![#DevoxxFR DATAFRAME API 14 Dataframe <=> Seq[Map[String,Any]]](https://files.speakerdeck.com/presentations/4e72303327e8466ca34b8f81506ac0a9/slide_26.jpg){kind=link}
{kind=link}
![#DevoxxFR DATASET API 16 Dataset[T] <=> Seq[T]](https://files.speakerdeck.com/presentations/4e72303327e8466ca34b8f81506ac0a9/slide_28.jpg){kind=link}
![#DevoxxFR DATASET API 16 Dataset[T] <=> Seq[T] type Dataframe =](https://files.speakerdeck.com/presentations/4e72303327e8466ca34b8f81506ac0a9/slide_29.jpg){kind=link}
![#DevoxxFR Exemple case class WikiArticle(content: String) spark.read.parquet("wikipedia") .as[WikiArticle] .flatMap(_.content.split(" "))](https://files.speakerdeck.com/presentations/4e72303327e8466ca34b8f81506ac0a9/slide_30.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
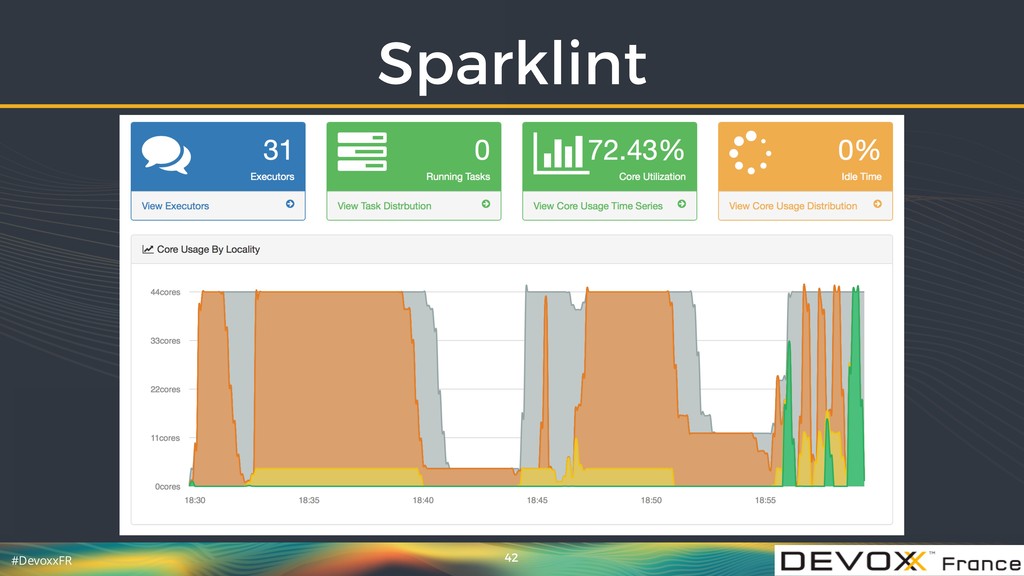{kind=link}
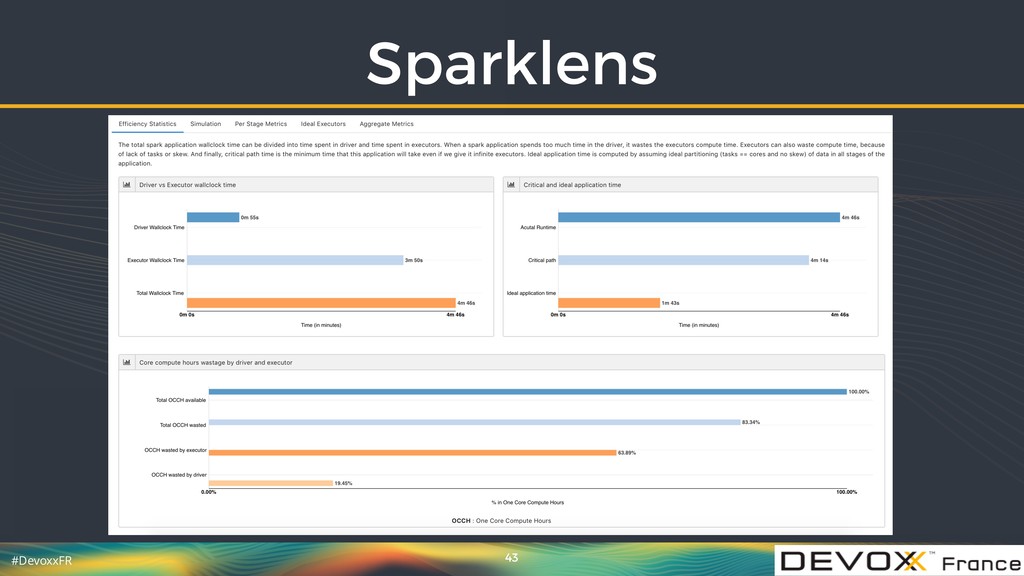{kind=link}
{kind=link}
{kind=link}
{kind=link}
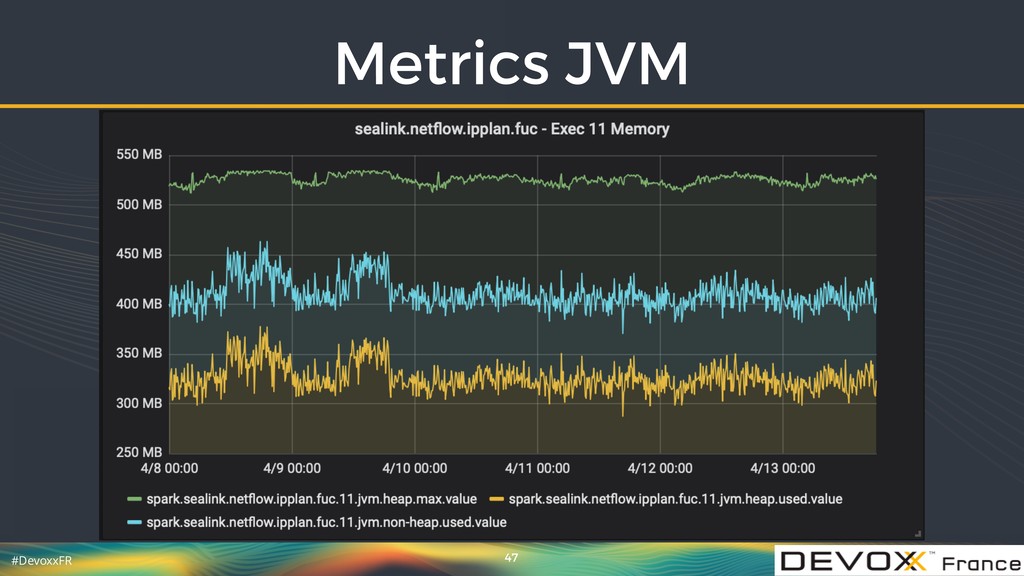{kind=link}
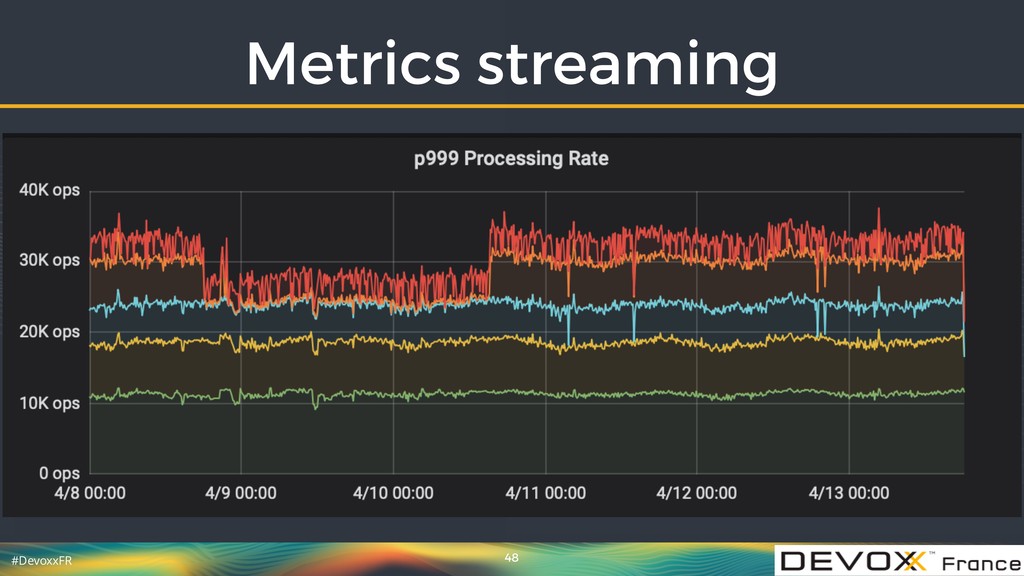{kind=link}
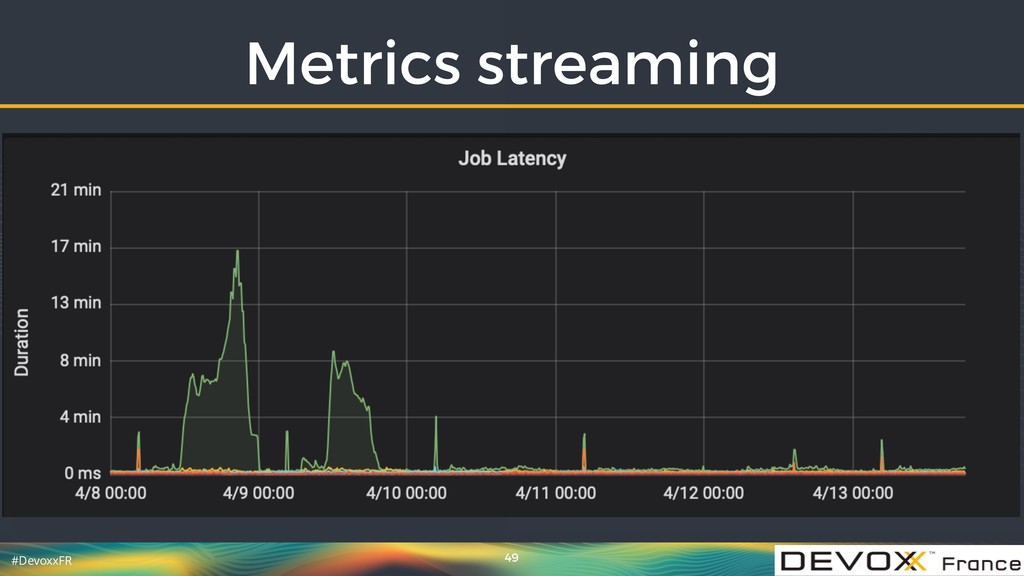{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
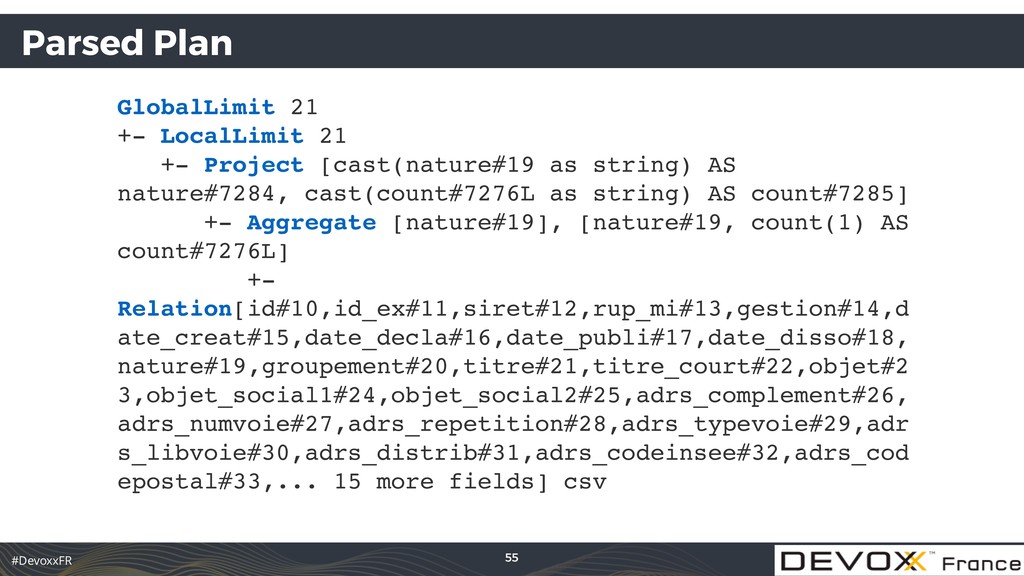{kind=link}
![#DevoxxFR Parsed -> Analyzed 56 Relation [...fields...] csv Aggregate [nature]](https://files.speakerdeck.com/presentations/4e72303327e8466ca34b8f81506ac0a9/slide_91.jpg){kind=link}
![#DevoxxFR Parsed -> Analyzed 56 Relation [...fields...] csv id, siret,](https://files.speakerdeck.com/presentations/4e72303327e8466ca34b8f81506ac0a9/slide_92.jpg){kind=link}
![#DevoxxFR Parsed -> Analyzed 56 Relation [...fields...] csv id, siret,](https://files.speakerdeck.com/presentations/4e72303327e8466ca34b8f81506ac0a9/slide_93.jpg){kind=link}
![#DevoxxFR Parsed -> Analyzed 56 Relation [...fields...] csv id, siret,](https://files.speakerdeck.com/presentations/4e72303327e8466ca34b8f81506ac0a9/slide_94.jpg){kind=link}
![#DevoxxFR Parsed -> Analyzed 56 Relation [...fields...] csv id, siret,](https://files.speakerdeck.com/presentations/4e72303327e8466ca34b8f81506ac0a9/slide_95.jpg){kind=link}
![#DevoxxFR Parsed -> Analyzed 56 Relation [...fields...] csv id, siret,](https://files.speakerdeck.com/presentations/4e72303327e8466ca34b8f81506ac0a9/slide_96.jpg){kind=link}
{kind=link}
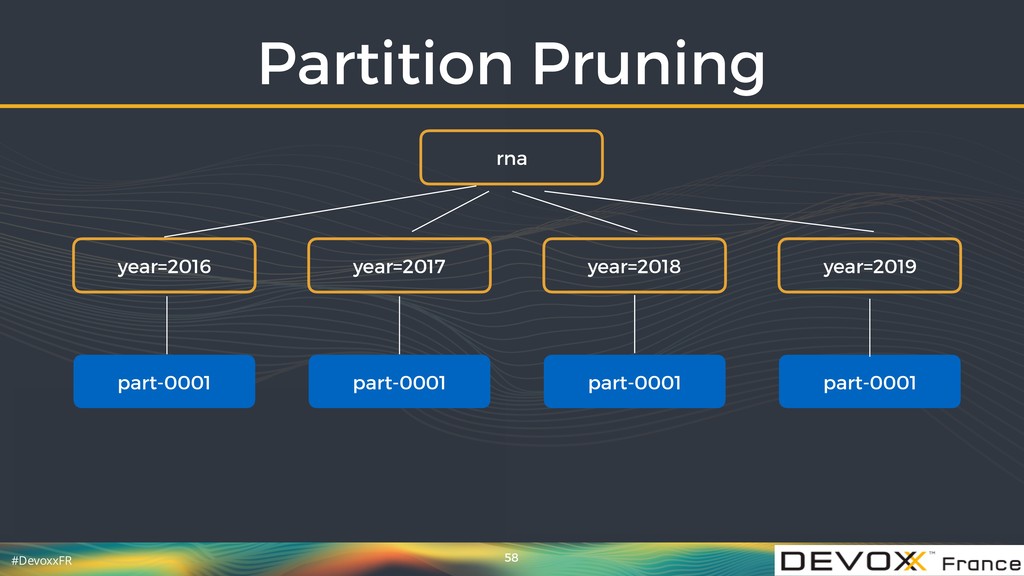{kind=link}
{kind=link}
{kind=link}
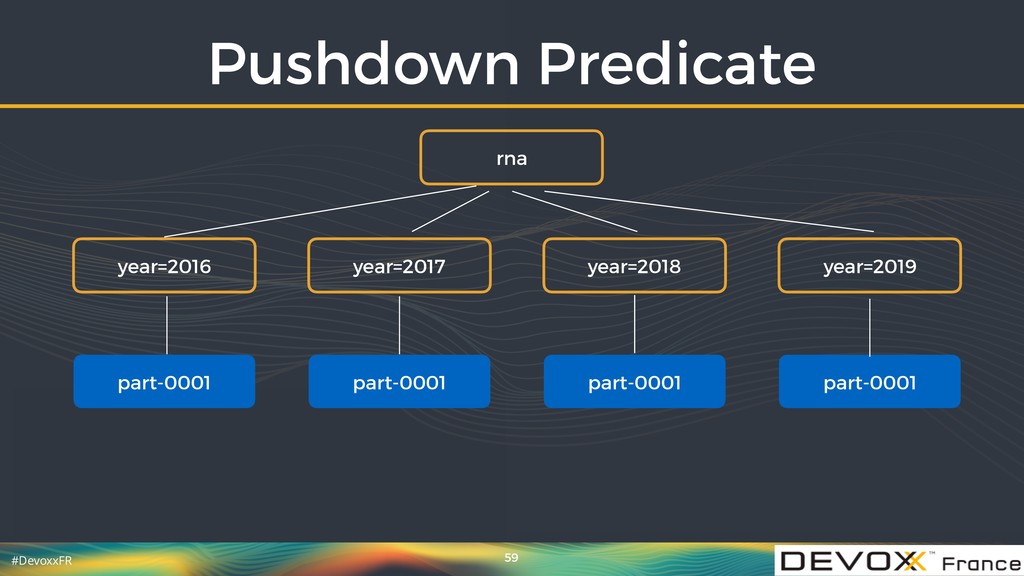{kind=link}
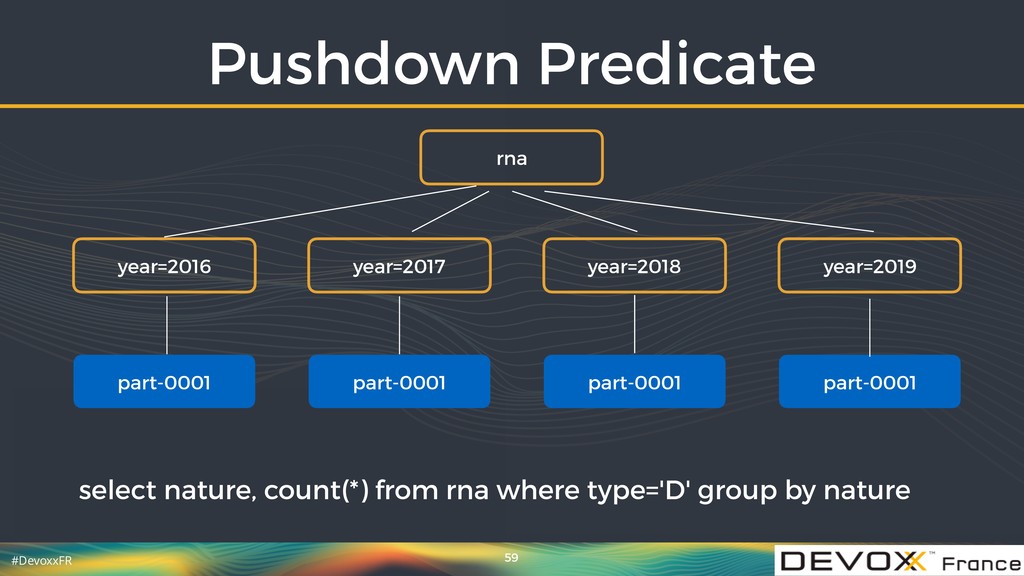{kind=link}
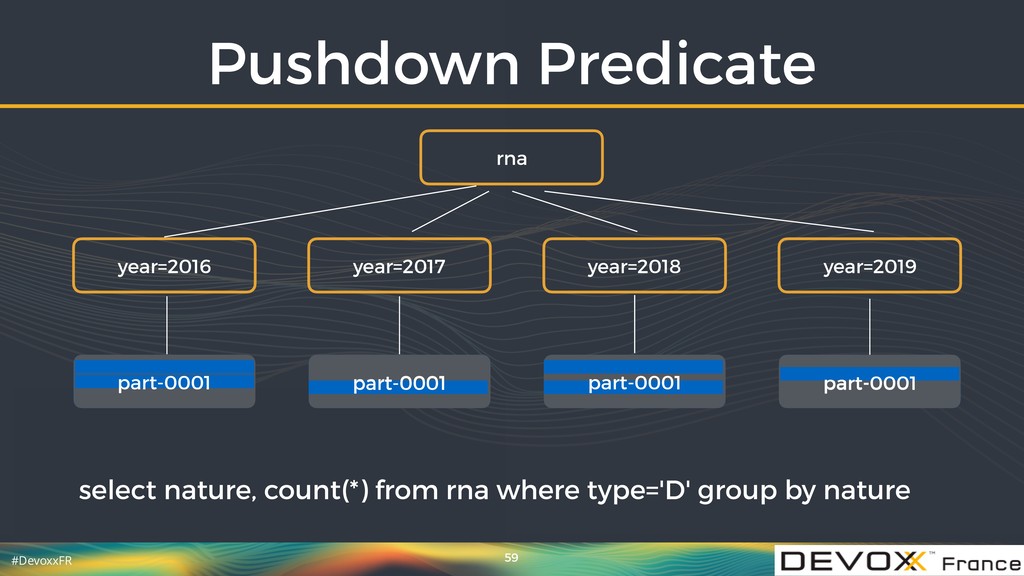{kind=link}
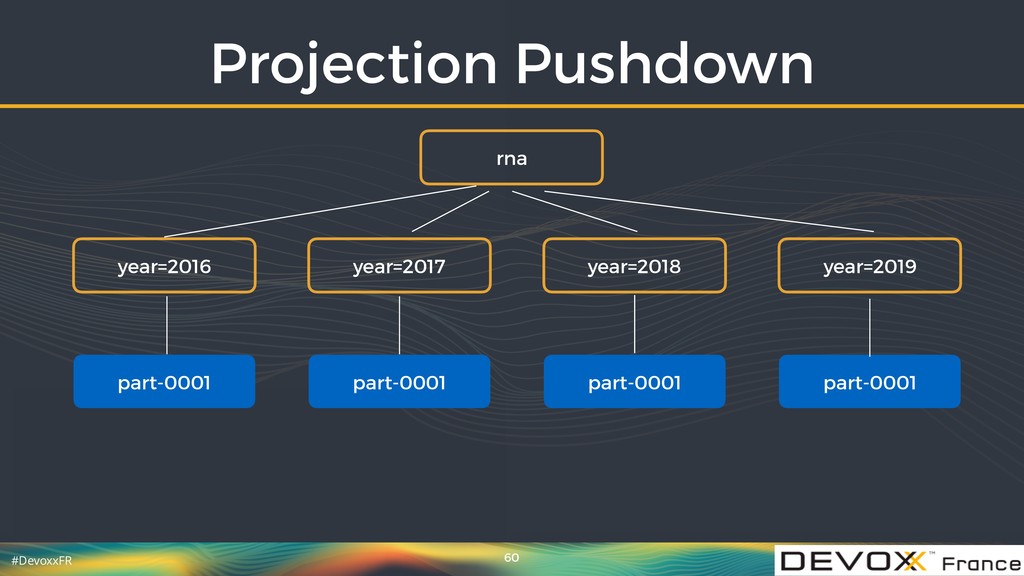{kind=link}
{kind=link}
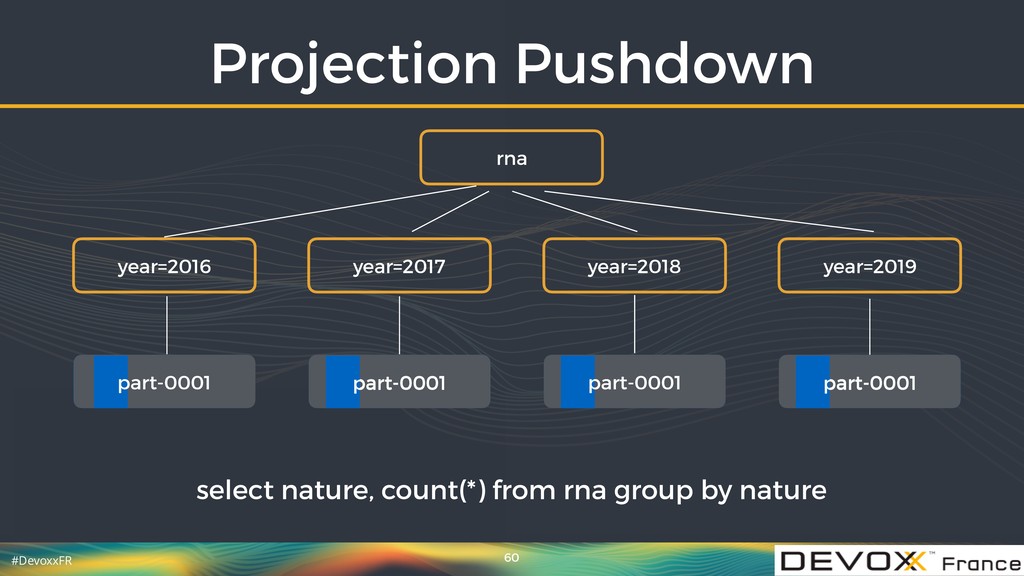{kind=link}
{kind=link}
![#DevoxxFR Physical Plan CollectLimit 21 +- *(2) HashAggregate(keys=[nature#19], functions=[count(1)], output=[nature#19,](https://files.speakerdeck.com/presentations/4e72303327e8466ca34b8f81506ac0a9/slide_108.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![#DevoxxFR RDD vs Dataset 69 RDD[MyClass] Dataset[Row] Dataset[MyClass] Analyse Compilation](https://files.speakerdeck.com/presentations/4e72303327e8466ca34b8f81506ac0a9/slide_115.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![#DevoxxFR RDD vs Dataset 114 RDD[MyClass] Dataset[Row] Dataset[MyClass] Analyse Compilation](https://files.speakerdeck.com/presentations/4e72303327e8466ca34b8f81506ac0a9/slide_180.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}