Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
スタートアップの初期設計、今ならこうする
Search
Sponsored
·
Ship Features Fearlessly
Turn features on and off without deploys. Used by thousands of Ruby developers.
→
rn0rno
February 04, 2026
Technology
16
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
スタートアップの初期設計、今ならこうする
2026.2.4 ひとり開発・少人数開発で全部やったエンジニア LT 会 & オフライン交流会
https://ydm.connpass.com/event/380280/
rn0rno
February 04, 2026
More Decks by rn0rno
See All by rn0rno
スクラム開発を始 めて捨てた一年の棚卸し
rn0rno
0
60
アーカイブ配信でもライブ感を味わいたい / cookpad_tech_kitchen#23
rn0rno
0
1k
Other Decks in Technology
See All in Technology
生成 AI × MCP で切り拓く次世代 SRE!自律型運用への挑戦と開発者体験の進化
_awache
0
170
ChatworkとBPaaS 異なる特性で学んだAI機能開発の ベストプラクティス
kubell_hr
2
3.2k
MCP Appsを作ってみよう
iwamot
PRO
4
160
マーケットプレイス版Oracle WebCenter Content For OCI
oracle4engineer
PRO
5
1.8k
運用を見据えたAIエージェント設計実践
amacbee
1
3.3k
美味しいスイスチーズを作ろう🧀🐭
taigamikami
1
260
チームで実践する AI-DLC 思考の軌跡を残すチェックポイント設計
belongadmin
0
3k
Chart.js が簡単に使えるようになっていたので OGP 画像生成に使った話
kamekyame
0
170
MIERUNE JCT 発表資料「宇宙から伊能忠敬ごっこ」
syuchimu
0
190
Dario Amodi『Policy on the AI Exponential』を理解する
nagatsu
0
200
AI Engineering Summit Tokyo 2026 AIの前に、やることがある 〜医療データ企業の4フェーズ〜
dtaniwaki
0
2.2k
Platform Engineering as a Product: Criteria for Improvement and Multi-Tenant Design
kumorn5s
0
530
Featured
See All Featured
The Illustrated Children's Guide to Kubernetes
chrisshort
51
52k
Done Done
chrislema
186
16k
世界の人気アプリ100個を分析して見えたペイウォール設計の心得
akihiro_kokubo
PRO
71
40k
Measuring & Analyzing Core Web Vitals
bluesmoon
9
860
A brief & incomplete history of UX Design for the World Wide Web: 1989–2019
jct
2
390
Future Trends and Review - Lecture 12 - Web Technologies (1019888BNR)
signer
PRO
0
3.6k
Exploring the Power of Turbo Streams & Action Cable | RailsConf2023
kevinliebholz
37
6.5k
A Tale of Four Properties
chriscoyier
163
24k
Connecting the Dots Between Site Speed, User Experience & Your Business [WebExpo 2025]
tammyeverts
11
940
What's in a price? How to price your products and services
michaelherold
247
13k
Designing Experiences People Love
moore
143
24k
How to Create Impact in a Changing Tech Landscape [PerfNow 2023]
tammyeverts
55
3.4k
Transcript
スタートアップの 『初期設計』、 今ならこうする Momose Ryoya (@rn0rno) AnyReach株式会社
自己紹介 新規サービスの「0→1」「1→10」フェーズが 大好きです。 とにかく速く作って検証する、いわゆる爆速 開発が得意領域。 現在はAnyReachにて、開発全般と技術選 定、組織づくりに奔走しています。 Momose Ryoya
AnyReach株式会社 #0→1立ち上げ #PoC #Prototyping #組織づくり coloria 0→1 coloria 香りのギフト 0→1 AnyGift Wedding 0→1 AnyGift 1→10 cookpadTV(現natslive) 0→1 storeLive 0→1 @rn0rno
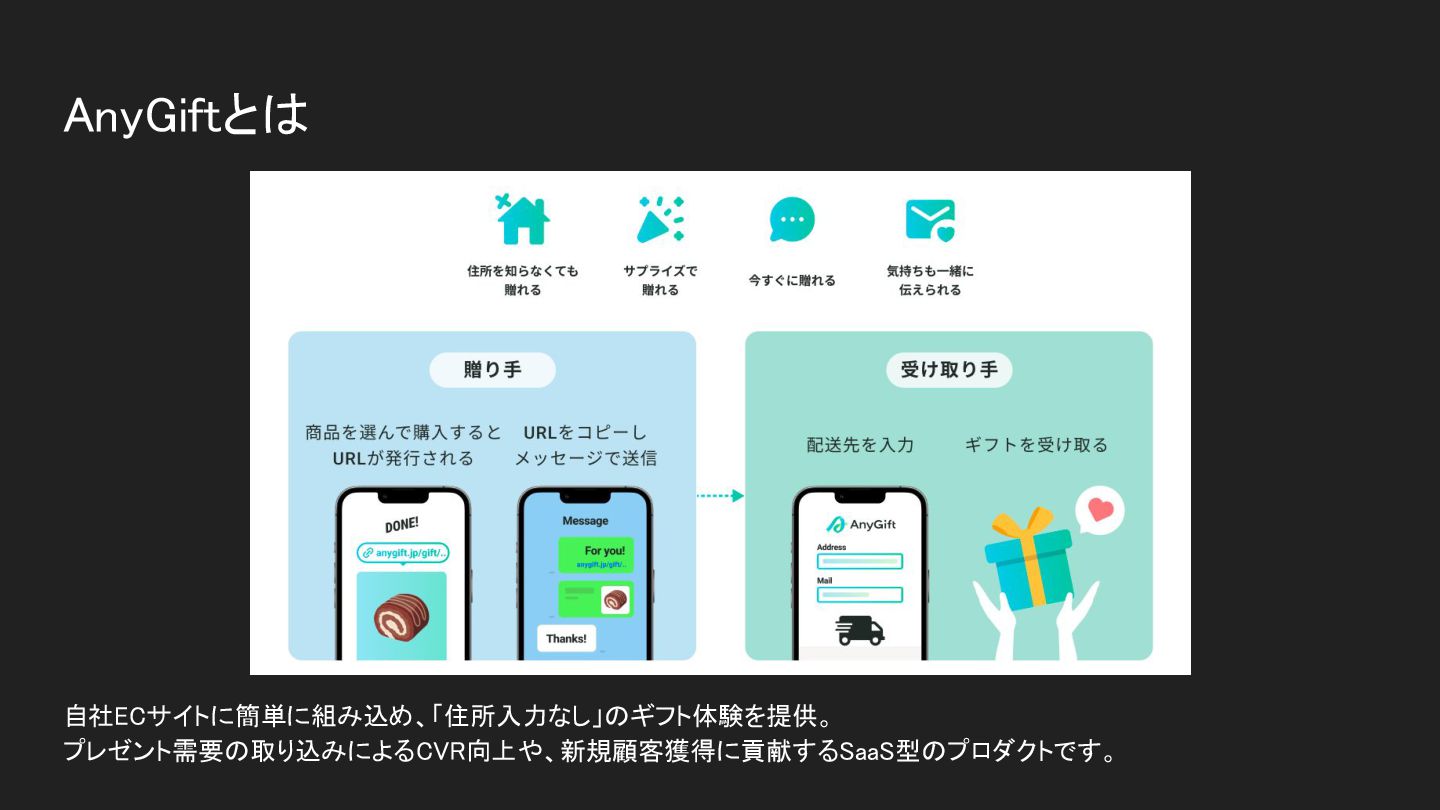
AnyGiftとは 自社ECサイトに簡単に組み込め、「住所入力なし」のギフト体験を提供。 プレゼント需要の取り込みによるCVR向上や、新規顧客獲得に貢献するSaaS型のプロダクトです。
今起きている「痛み」 絶え間ないエラー通知 DynamoDBの スロットリング ログコストの肥大化 Slackに大量のエラー通知が鳴
り止まない状態。 どれが本当に重要なのかが埋 もれてしまい、開発チーム全体 が「アラート疲れ」に陥ってい る。 サービス成長に伴い検索要件 が増加。 無理なScan操作やインデック ス不足により、スロットリングエ ラーやバックエンド処理の肥大 化によるタイムアウトも頻発。 ユーザー体験にも影響が。 調査のために「とりあえず全部 出す」方針でログを出力しすぎ た結果、CloudWatch Logsのコ ストが増加。 ログの量も多く、肝心なときに 欲しい情報を見つけるための 調査コストも大きい。 💔 精神的負荷の増大 🚫 パフォーマンス低下 💸 インフラコスト圧迫
原因①: NoSQLの罠 立ち上げ時の判断 成長後の現実 ⚡ 開発スピード最優先 🌐 サーバレスへの期待
🗒 JSONを投げるだけ 仕様が固まっていないため、スキーマ レスで柔軟に変更できるDynamoDBが 魅力的に見えた。 インフラ管理コストをゼロにしたく、ス ケーリングもAWS任せで楽ができそう。 バックエンドからはJSON構造を投げる だけで保存でき、実装がシンプルだっ た。 🔎 複雑な検索要件が増加 📈 Scan & Filter の乱用 🗃 GSIが増大 「日付範囲で絞りたい」「商品名で部分 一致検索がしたい」など管理画面の要 件にNoSQLが不向き。 キー設計が合わず、結局全件スキャン したあとアプリ側でフィルタリングし、コ ストと速度が悪化。 検索パターンの数だけインデックスが 増え、書き込みコストが肥大化。
学び①: データベース選定 ☑ 1年後の検索クエリは想像できるか? ☑ アクセスパターンは「固定」か? ☑ リレーショナルなデータ構造か? ☑ 将来の分析(DWH/ETL)は見据えるか?
データベース以外のインフラで回避するならNoSQLでもOK 全体の開発工数を踏まえたデータベース選定を 迷ったらRDBを選びたい (スキーマの変更柔軟性より、クエリの変更柔軟性) 「とりあえずGetItem」だけでなく、管理画面での絞り込みや全文検索は必要になりそうか? NoSQLはアクセスパターン設計が命。将来の機能追加でアクセスパターンが増えそうならRDBが無難。 注文、ユーザー、商品、決済…と、JOIN(結合)が前提のデータモデルではないか? 「SQLでサクッと分析したい」というビジネスサイドの要求にどう応えるか?
原因②: 追えないエラー EC特有の外部連携 大量のログに疲弊 🔌 多種多様なAPIコール 🚀 非同期処理がブラックボックス化
決済、メール配信、物流連携、カート連 携など1つの注文処理で複数の外部 サービスと通信。 相手先のメンテナンス、一時的なタイム アウトや、レート制限エラーが日常的に 混在。 注文処理と、それに伴う外部サービス への通信が非同期化しており、一連の 流れが追えない。 📝 テキストログ頼みの限界 ⏰ 調査コストの肥大化 「エラーログはでているが、最終的にリ トライで成功したのか?」はgrepしないと わからない。 1件の問い合わせ調査にエンジニアが 30分張り付き、開発時間が削られると いう悪循環。
学び②: 調査容易性と回復戦略 調査容易性 回復戦略 ✅ Trace IDの伝搬 APIリクエストのIDを、Lambda、SQS、 DB保存まで一貫して引き回し、マイクロ
サービスでも簡単にログを追えるように する。 「何が起きたか」をデータで把握 「失敗は必ず起こる」前提で ✅ 重要なイベントはDBへ 注文処理結果などはログではなく、SQL で即座に引ける「履歴テーブル」「監査 テーブル」に保存する。 ✅ 冪等性の担保 リトライしたときに、二重決済や二重送信 が行われないように冪等キーなどを利用 した冪等実装を。 ✅ 適切なリトライ戦略 リトライすれば回復するエラーと、そうで はないエラーを切り分けた上で、適切な 間隔でリトライを実施する。 ✅ 再試行限界に達したときのアラート あとから手動でリカバリするため、再試行 にも失敗したことを検知できるようにす る。
まとめ データ特性でDB選定 重要なイベントは テーブルへ 失敗前提の 回復戦略
「なんとなくNoSQL」「スキーマ 設計を楽しよう」は危ない。将 来のアクセスパターンや結合 要件を想像して判断。 ログは「流れ」を追うものと定義 して、「結果」や「状態」は履歴 テーブル、イベントテーブルに 永続化し調査コストを下げる。 外部連携は失敗する前提で、 リトライ、冪等性、DLQの初期 設計を行う。 あとからの運用コストを下げ る。 ⚡ スタートアップにおいて、スピードは正義 ただし、未来の自分のスピードを苦しめないようなガードレールを作っておこう
AnyReach株式会社 We are hiring!
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}