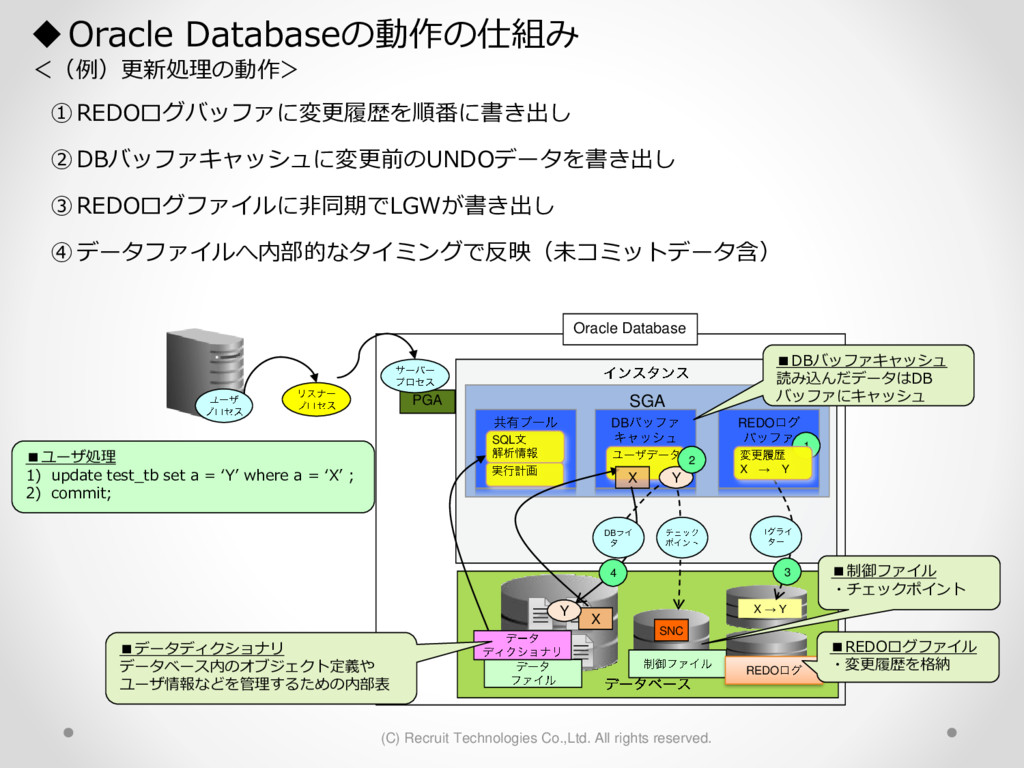
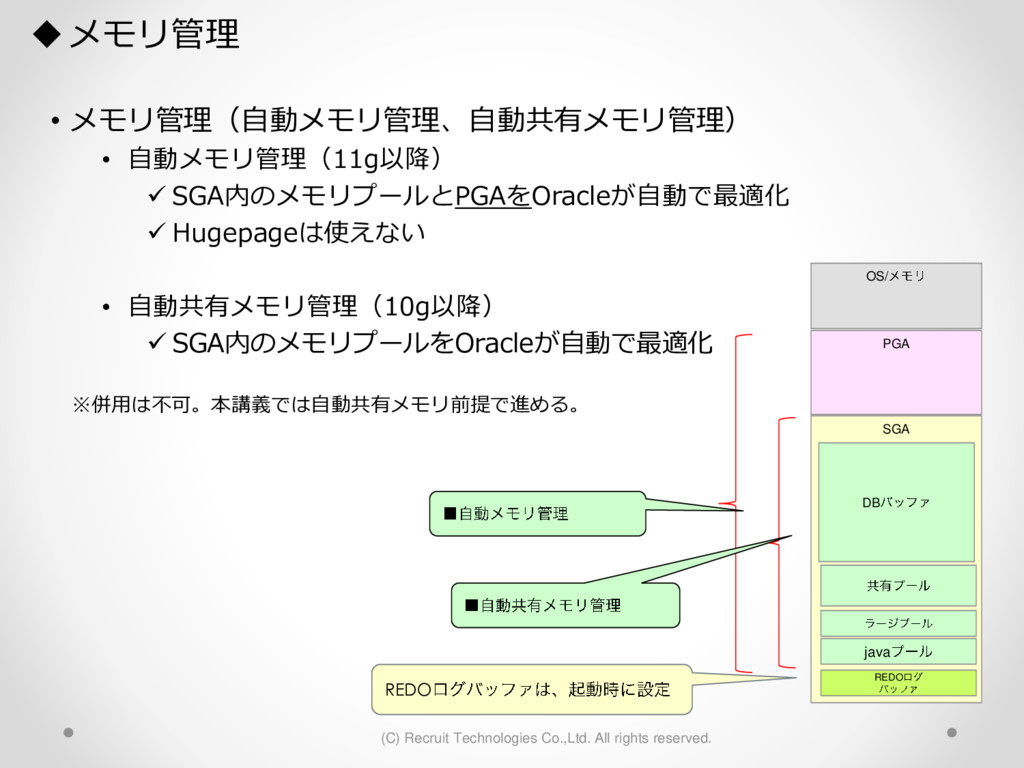
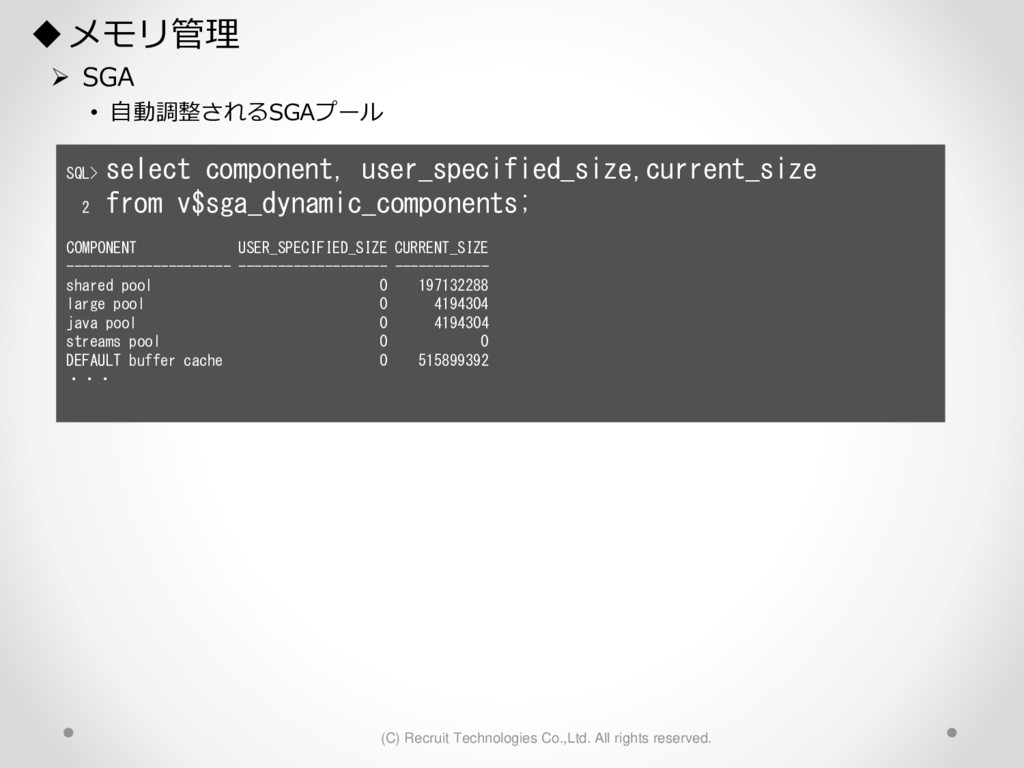
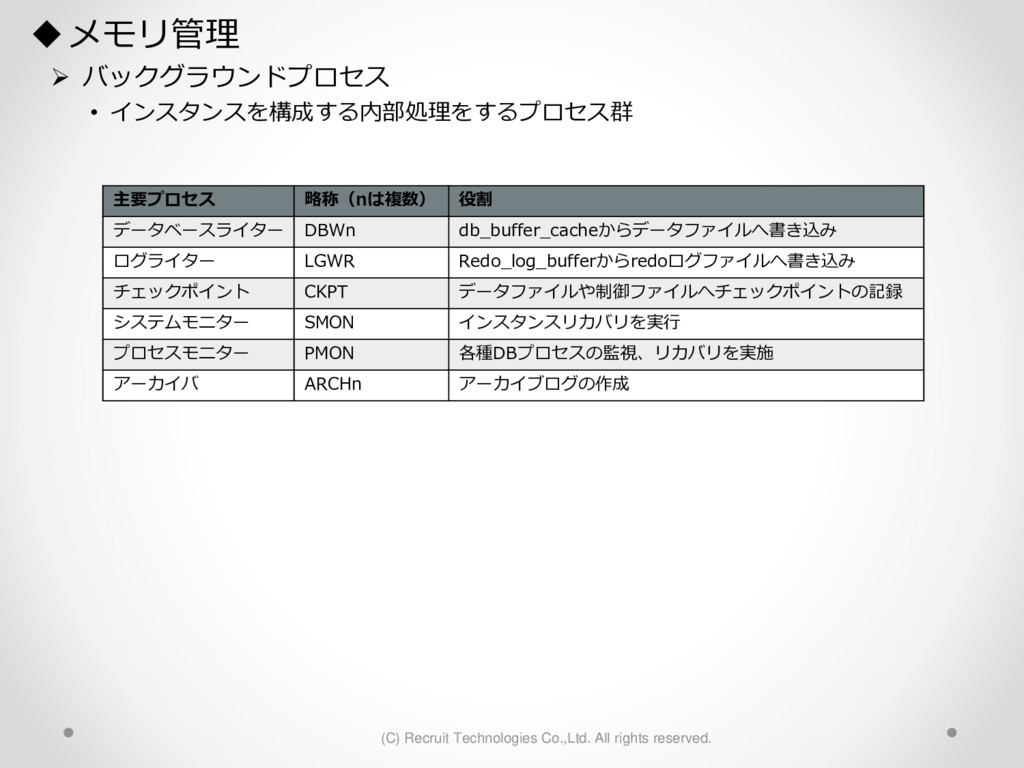
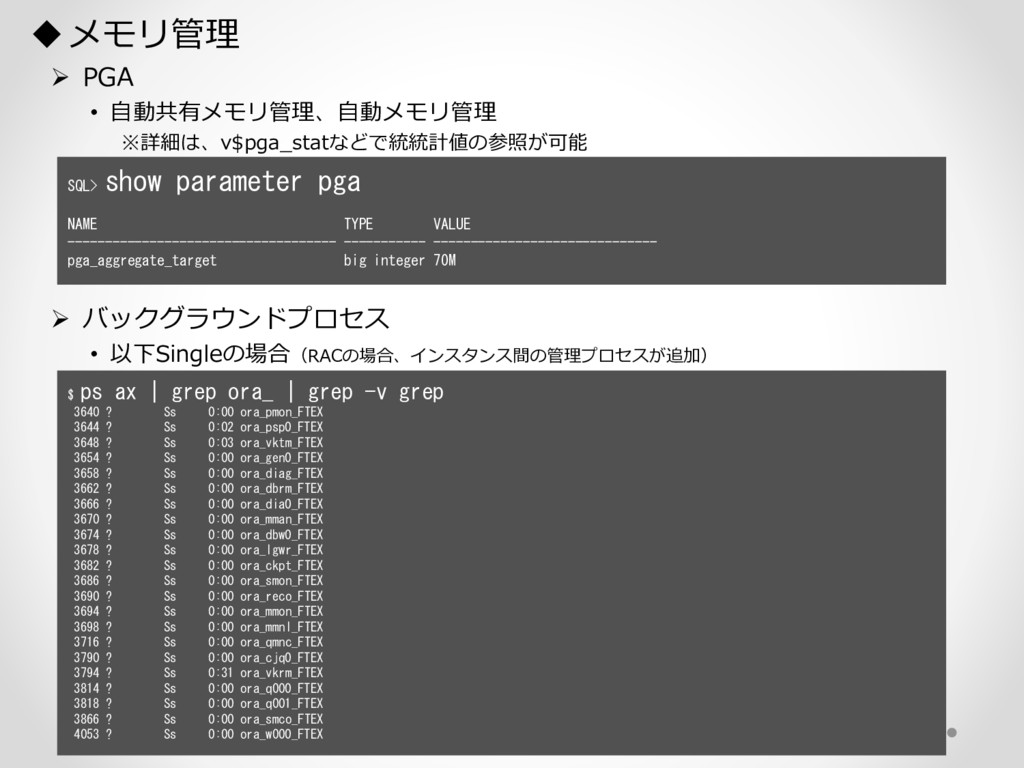
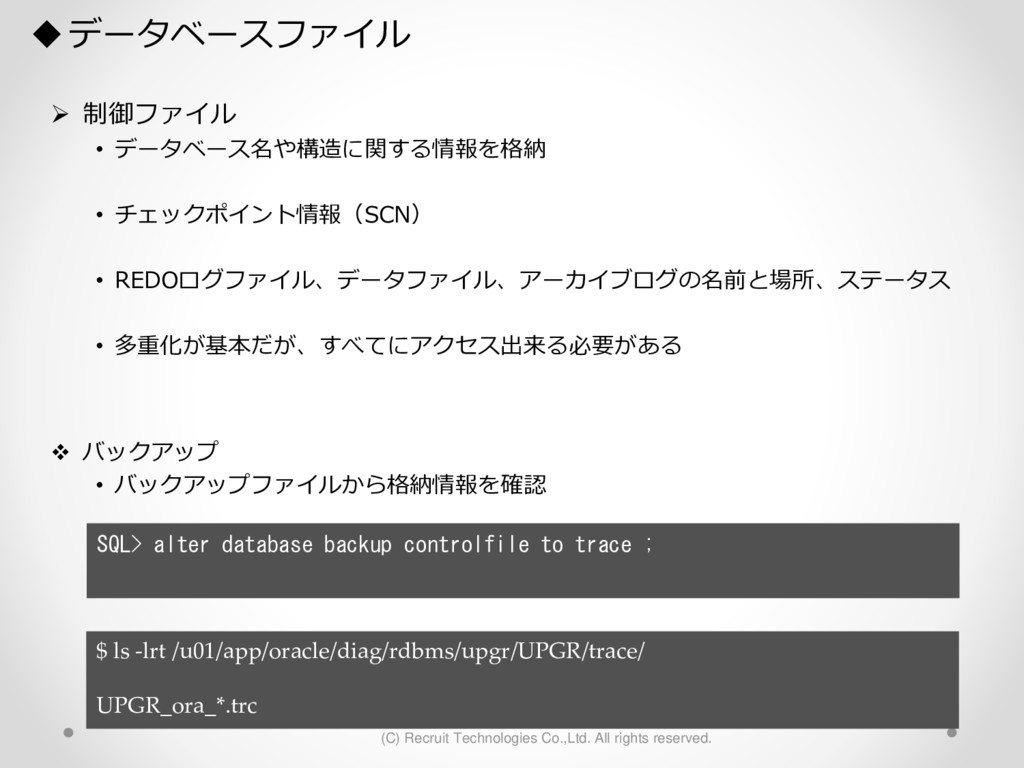
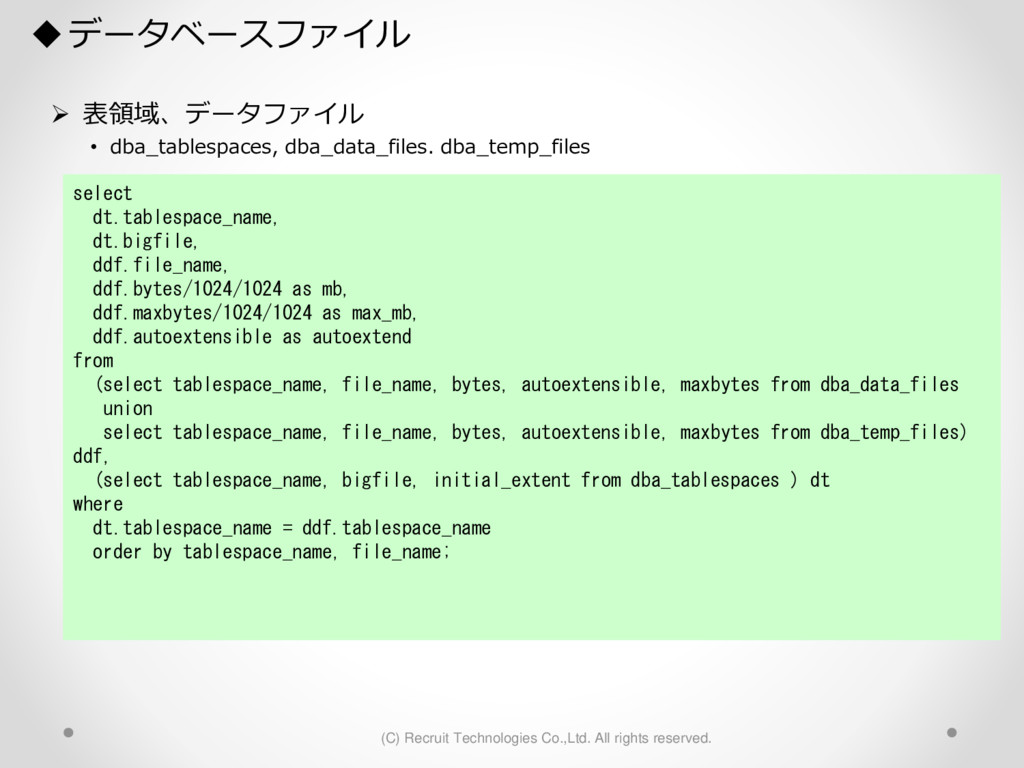
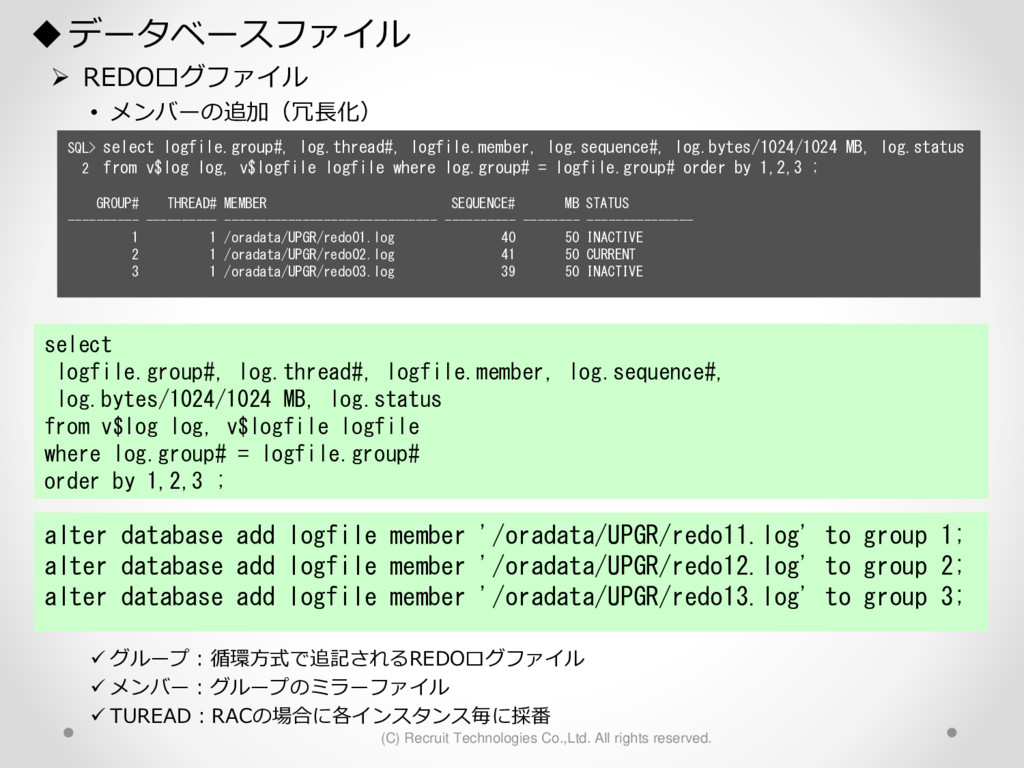
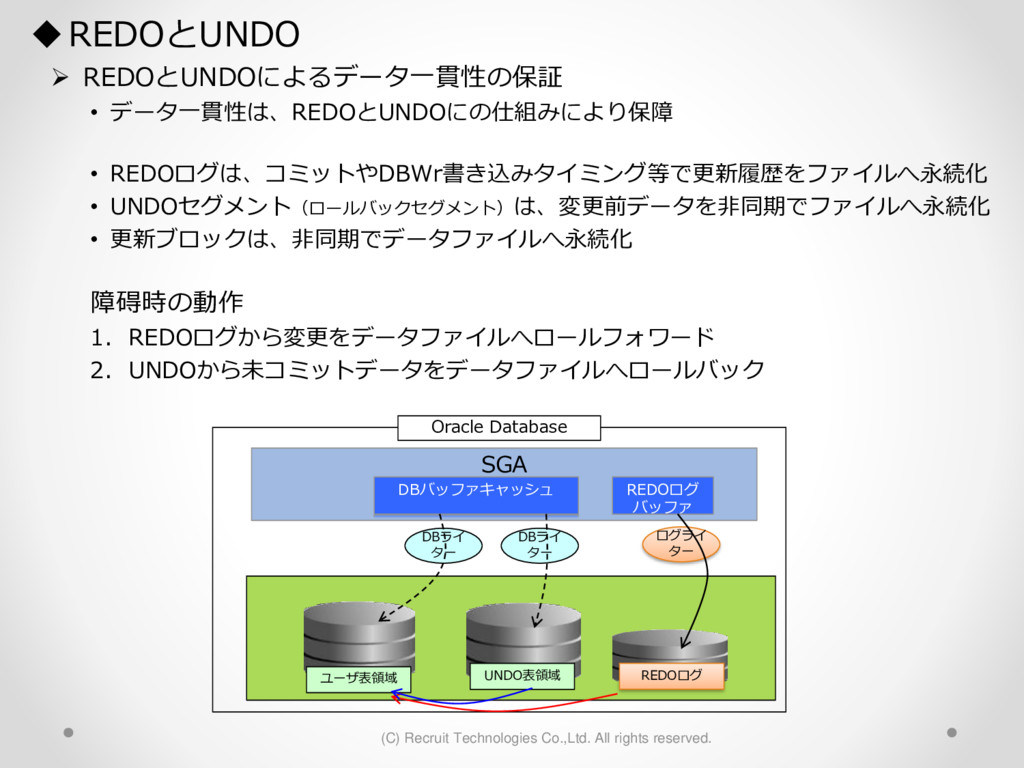
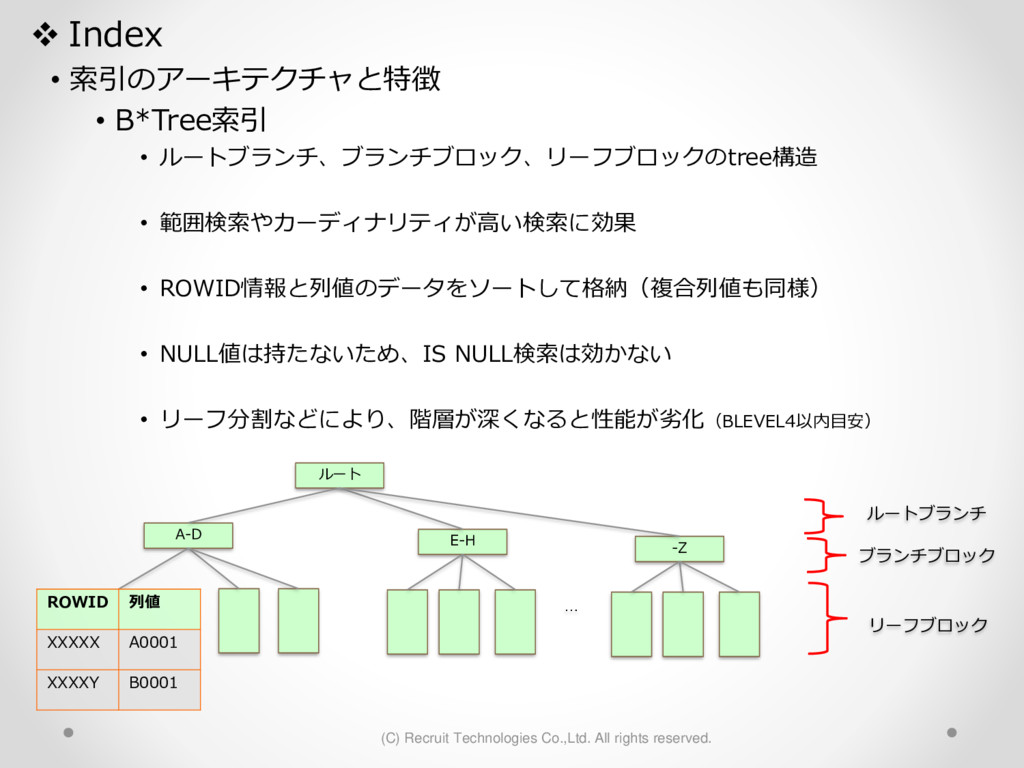
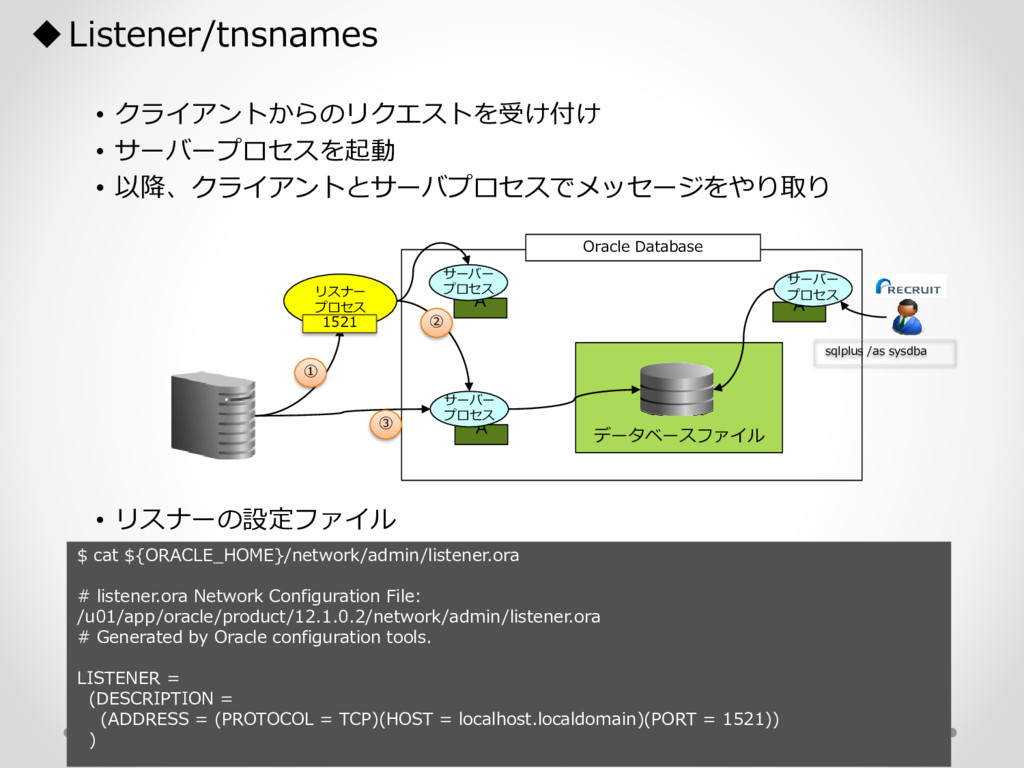
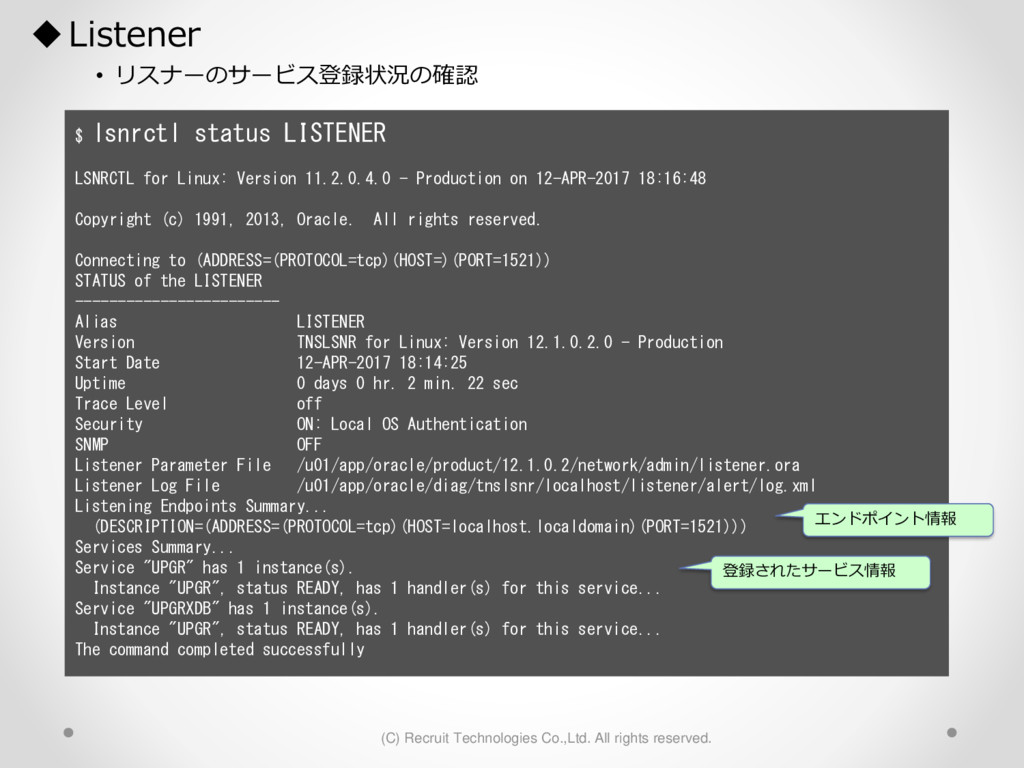
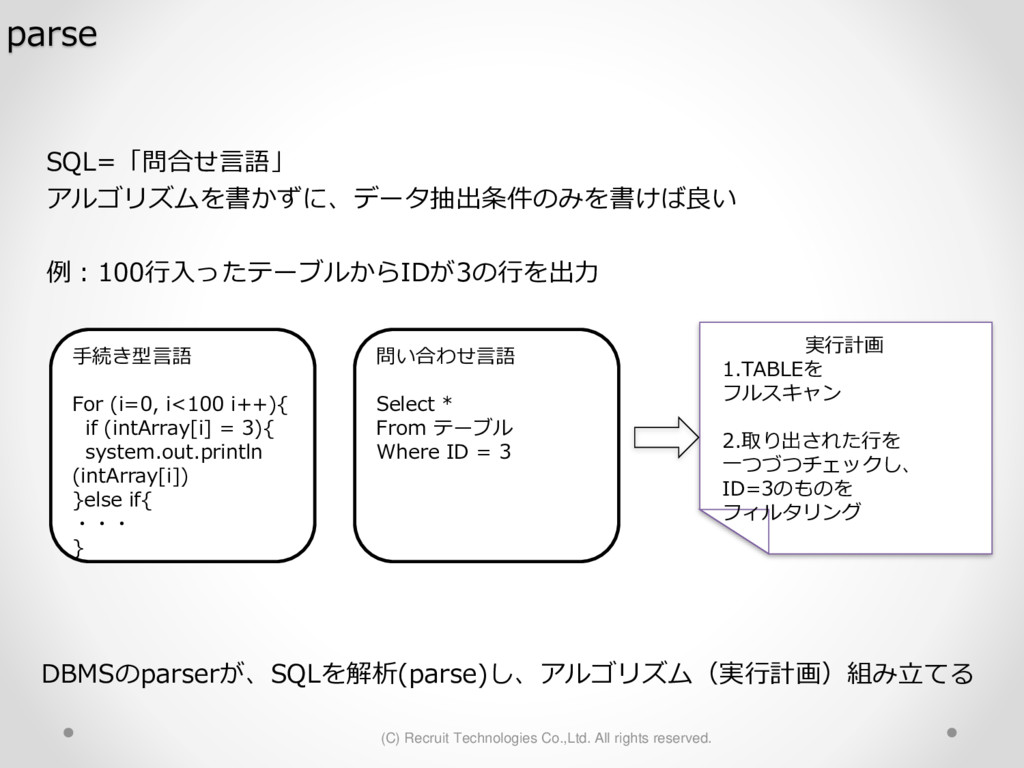
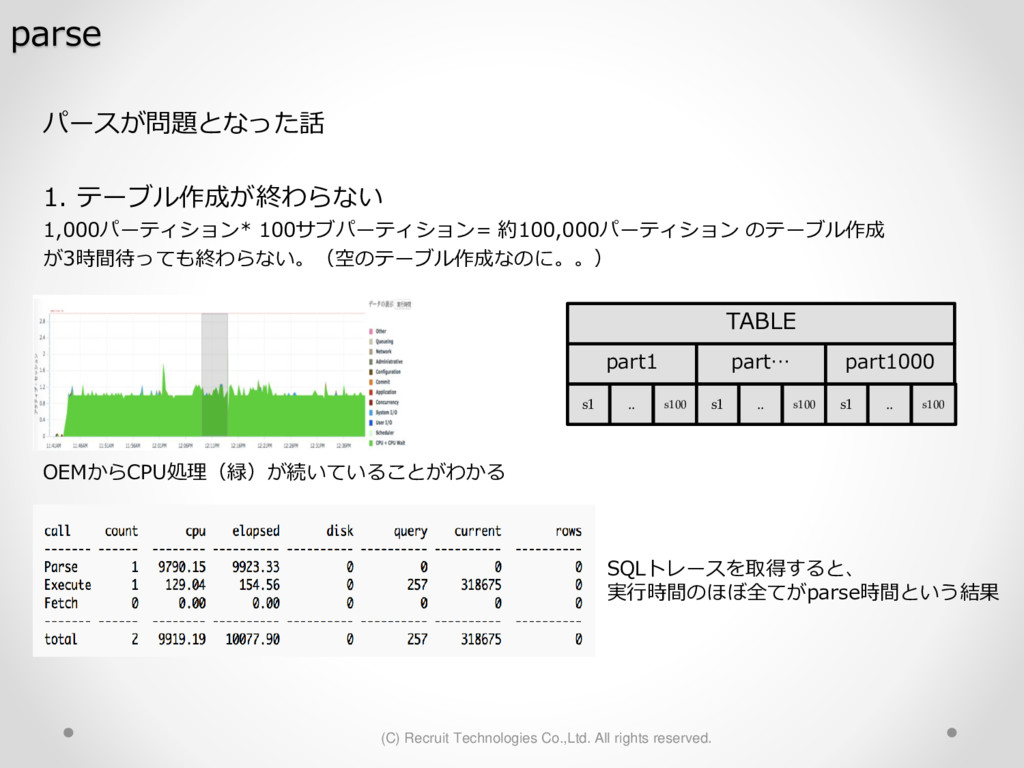
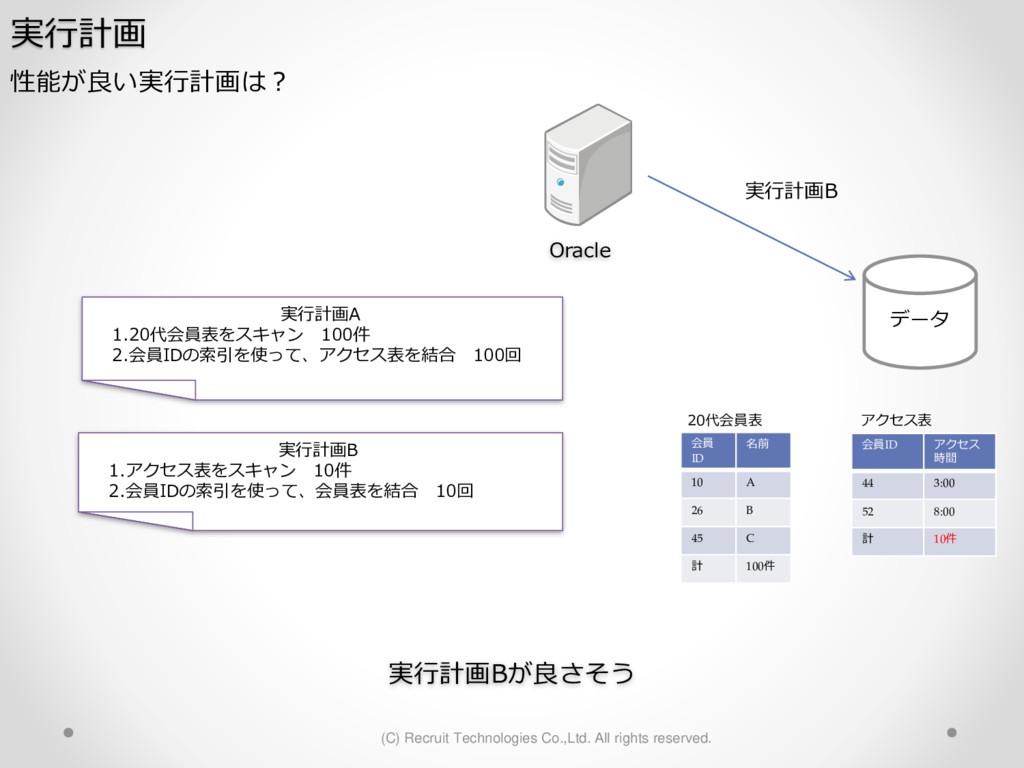
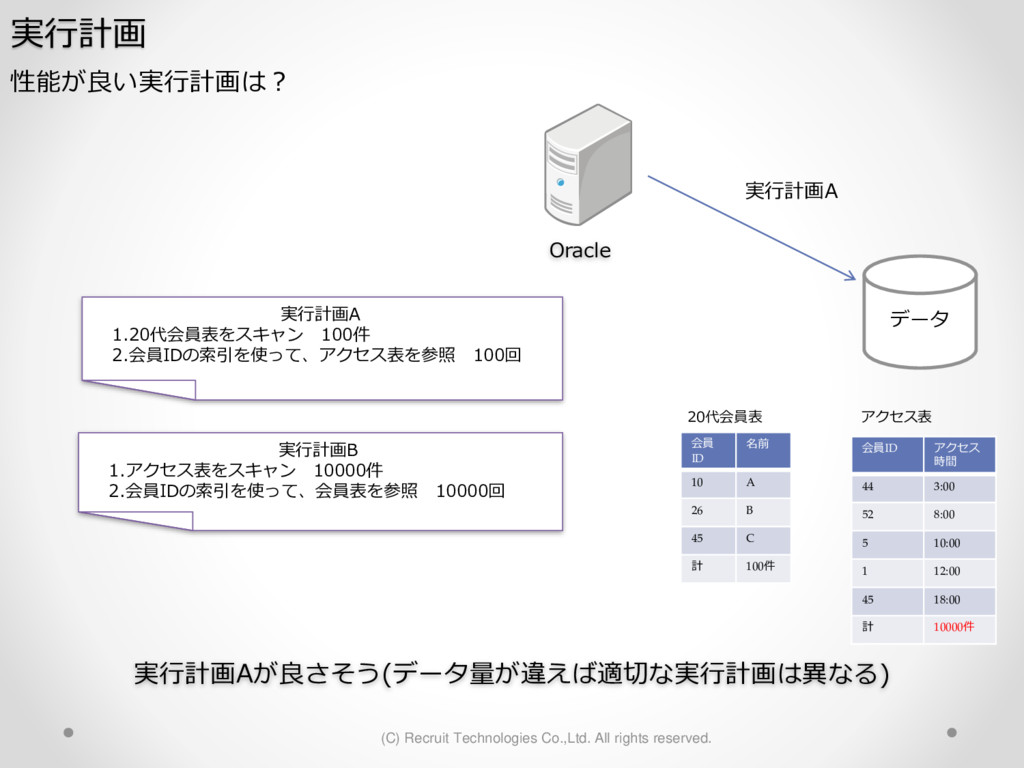
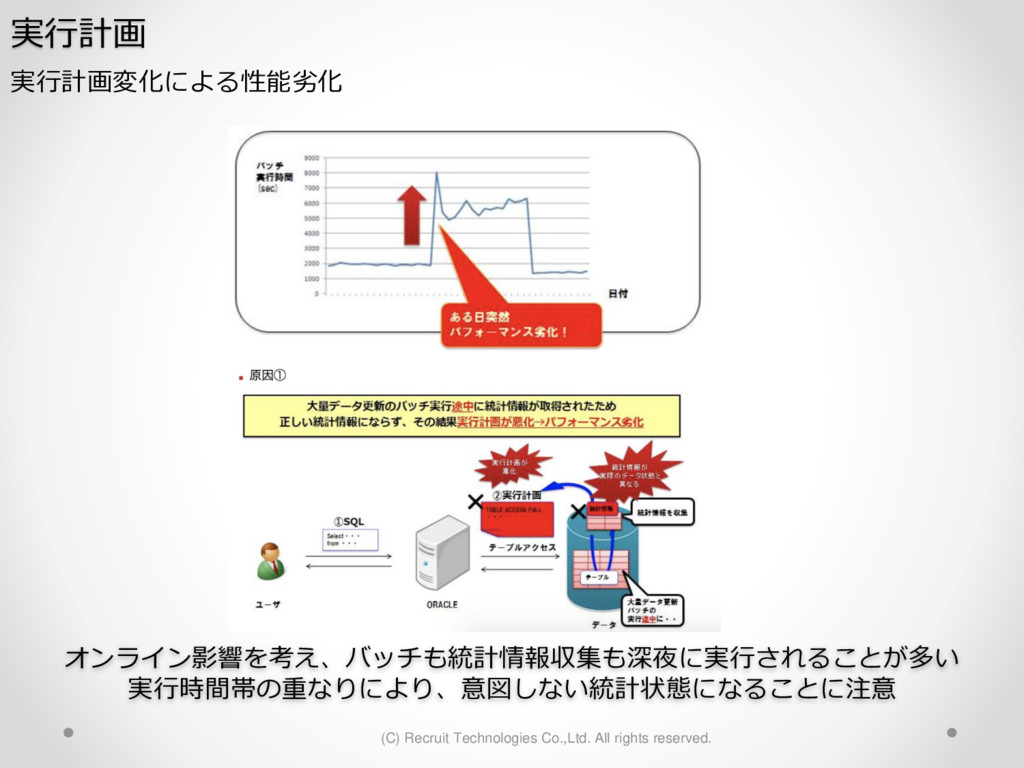
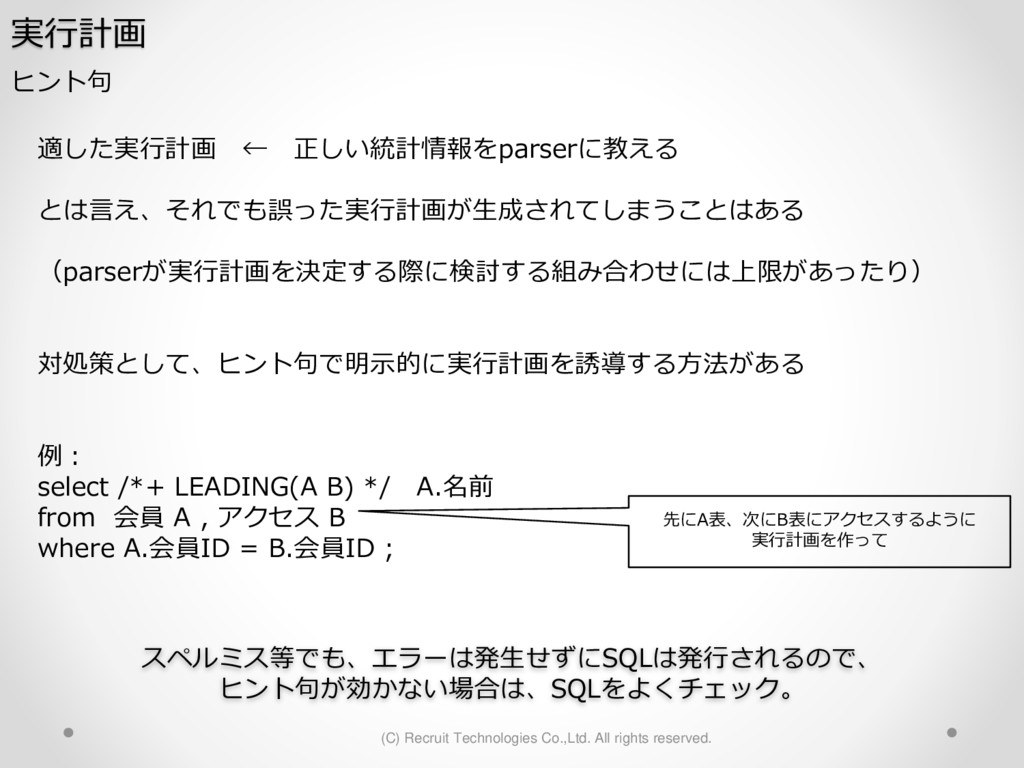
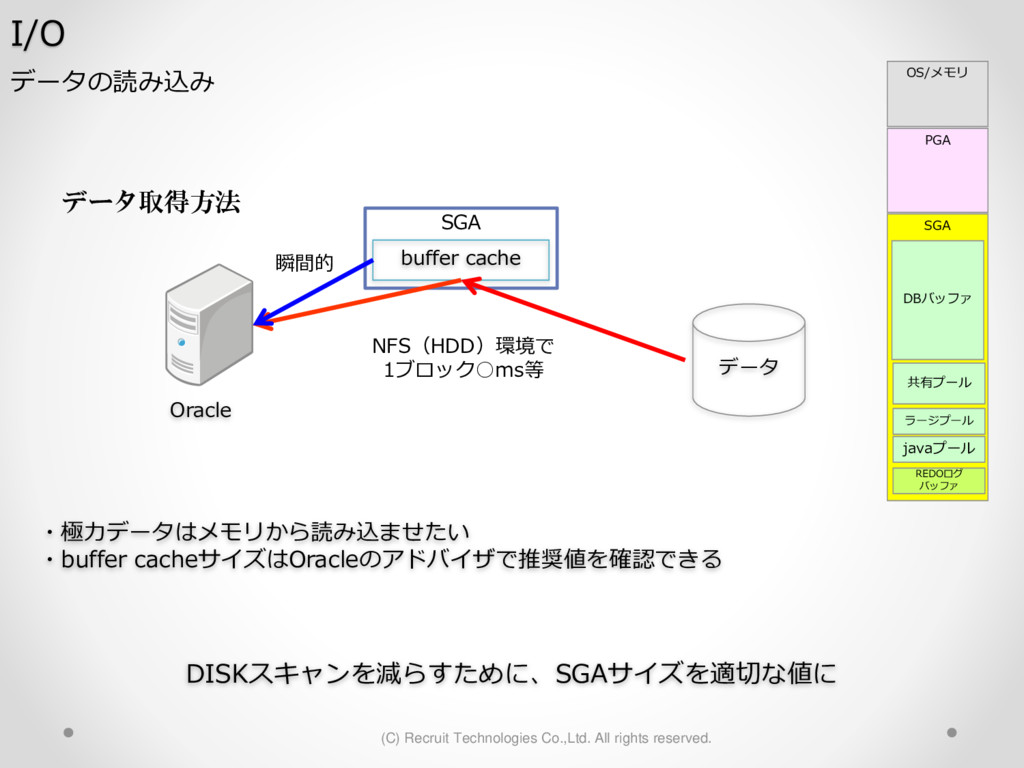
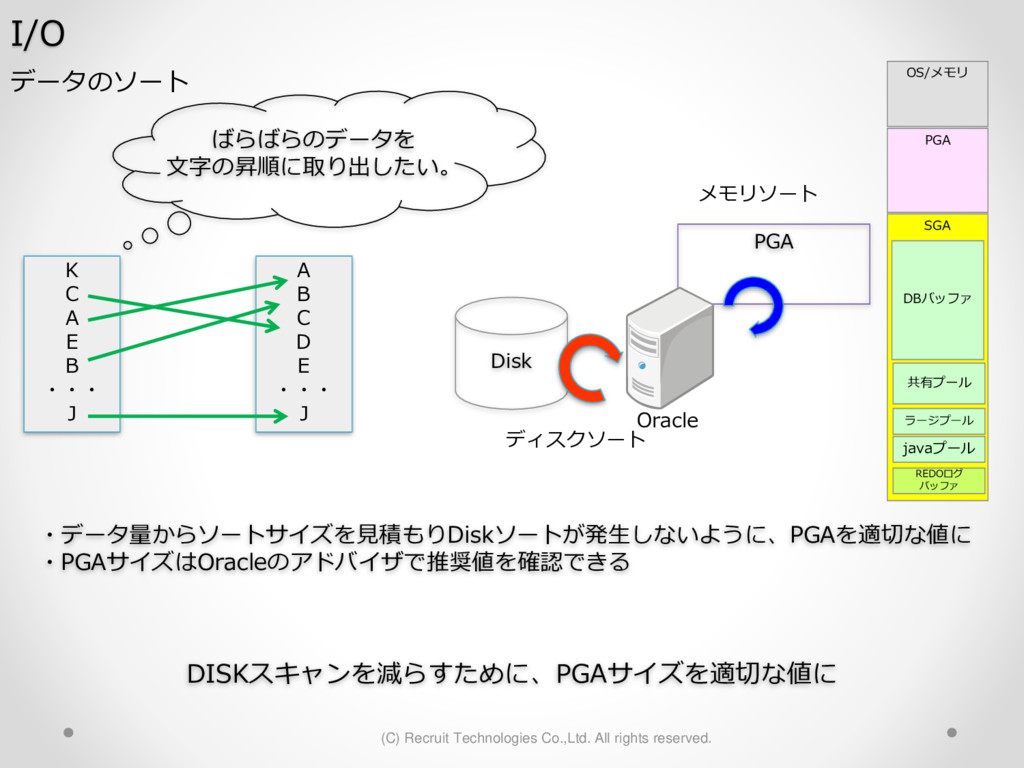
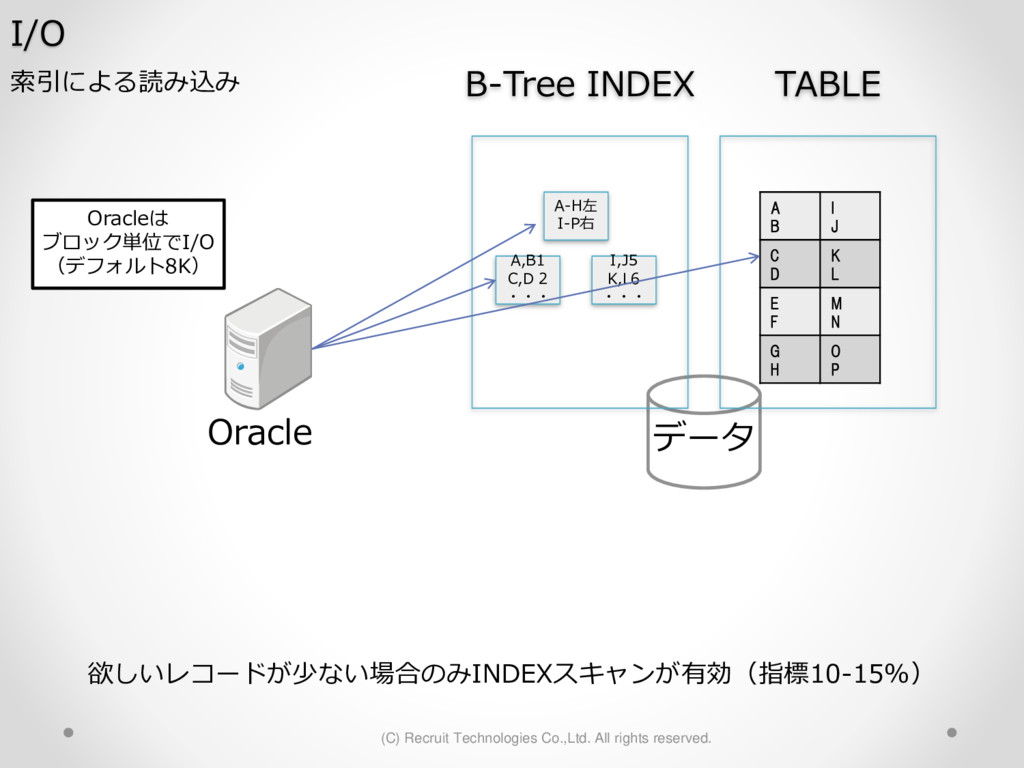
1,000パーティション* 100サブパーティション= 100,000パーティション のテーブル作成 が3時間待っても終わらない。(空のテーブル作成なのに。。) create table a (id char(10),dy date) partition by hash(id) subpartition by range(dy)( partition p1 ( subpartition p1_2016_01_01 values less than (to_date('2016-01-01','YYYY-MM-DD')) ,subpartition p1_2016_01_02 values less than (to_date('2016-01-02','YYYY-MM-DD')) : ) ,partition p2 ( subpartition p500_2016_01_01 values less than (to_date('2016-01-01','YYYY-MM-DD')) ,subpartition p500_2016_01_02 values less than (to_date('2016-01-02','YYYY-MM-DD')) : ) ,partition p3 ( subpartition p500_2016_01_01 values less than (to_date('2016-01-01','YYYY-MM-DD')) ,subpartition p500_2016_01_02 values less than (to_date('2016-01-02','YYYY-MM-DD')) : ) : : ,partition p1000 ( subpartition p500_2016_01_01 values less than (to_date('2016-01-01','YYYY-MM-DD')) ,subpartition p500_2016_01_02 values less than (to_date('2016-01-02','YYYY-MM-DD')) : ) create table a (id char(10),dy date) partition by hash(id) subpartition by range(dy) subpartition template ( subpartition 2016_01_01 values less than (to_date('2016-01-01','YYYY-MM-DD')) ,subpartition 2016_01_02 values less than (to_date('2016-01-02','YYYY-MM-DD')) : ,subpartition 2016_04_08 values less than (to_date('2016-04-08','YYYY-MM-DD')) ,subpartition 2016_04_09 values less than (to_date('2016-04-09','YYYY-MM-DD')) ) ( partition p1 ,partition p2 : ,partition p1000 ); サブパーティションテンプレート利用で3分で完了 元のクエリイメージ parse 修正後のクエリイメージ
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}