Change [Cassotti+, 2023] XL-LEXEME: WiC Pretrained Model for Cross- Lingual LEXical sEMantic changE [Periti and Tahmasebi, 2024a] A Systematic Comparison of Contextualized Word Embeddings for Lexical Semantic Change [Periti and Tahmasebi, 2024b] Towards a Complete Solution to Lexical Semantic Change: an Extension to Multiple Time Periods and Diachronic Word Sense Induction [Aida and Bollegala, 2024] A Semantic Distance Metric Learning approach for Lexical Semantic Change Detection 52
2015] Statistically Significant Detection of Linguistic Change [Hu+, 2019] Diachronic Sense Modeling with Deep Contextualized Word Embeddings: An Ecological View [Giulianelli+, 2020] Analysing Lexical Semantic Change with Contextualised Word Representations 53
Word Embedding as Implicit Matrix Factorization [Shoemark+, 2017] Room to Glo: A Systematic Comparison of Semantic Change Detection Approaches with Word Embeddings [Nulund+, 2024] Time is Encoded in the Weights of Finetuned Language Models 54
{kind=link}
{kind=link}
![背景:通時的な意味変化 ◼ 通時的な意味変化とは時代により単語の意味が変化する事象 ◼ 単語埋め込みの変化を分析するタスク ◼ 分布仮説:周辺単語により単語の意味が決まることを仮定 2 [Hamilton+, 2016]より引用](https://files.speakerdeck.com/presentations/bf6312c3389846dca9e17f445b71460a/slide_2.jpg){kind=link}
![背景:2つの時期と複数時期の意味変化 [Periti and Tahmasebi, 2024b] ◼ 2つの時期の意味変化 [Cassotti+, 2023][Periti and](https://files.speakerdeck.com/presentations/bf6312c3389846dca9e17f445b71460a/slide_3.jpg){kind=link}
![背景:2つの時期と複数時期の意味変化 [Periti and Tahmasebi, 2024b] ◼ 2つの時期の意味変化 [Cassotti+, 2023][Periti and](https://files.speakerdeck.com/presentations/bf6312c3389846dca9e17f445b71460a/slide_4.jpg){kind=link}
![背景:2つの時期と複数時期の意味変化 [Periti and Tahmasebi, 2024b] ◼ 2つの時期の意味変化 [Cassotti+, 2023][Periti and](https://files.speakerdeck.com/presentations/bf6312c3389846dca9e17f445b71460a/slide_5.jpg){kind=link}
![背景:複数時期の意味変化の課題1 ◼ 隣接時期間における変化点検出 [Kulkarni+, 2015] ◼ 隣り合う時期同士で意味変化度合いを計測 ◼ 2つの時期間の意味変化の自然な拡張 ◼](https://files.speakerdeck.com/presentations/bf6312c3389846dca9e17f445b71460a/slide_6.jpg){kind=link}
![背景:複数時期の意味変化の課題2 ◼ BERT-basedな手法を用いた語義のクラスタリング[Hu+, 2019][Giulianelli+, 2020] ◼ 対象単語の埋め込みをクラスタリングして語義の割合を分析 ◼ 語義の時間的な遷移が分析できる ◼](https://files.speakerdeck.com/presentations/bf6312c3389846dca9e17f445b71460a/slide_7.jpg){kind=link}
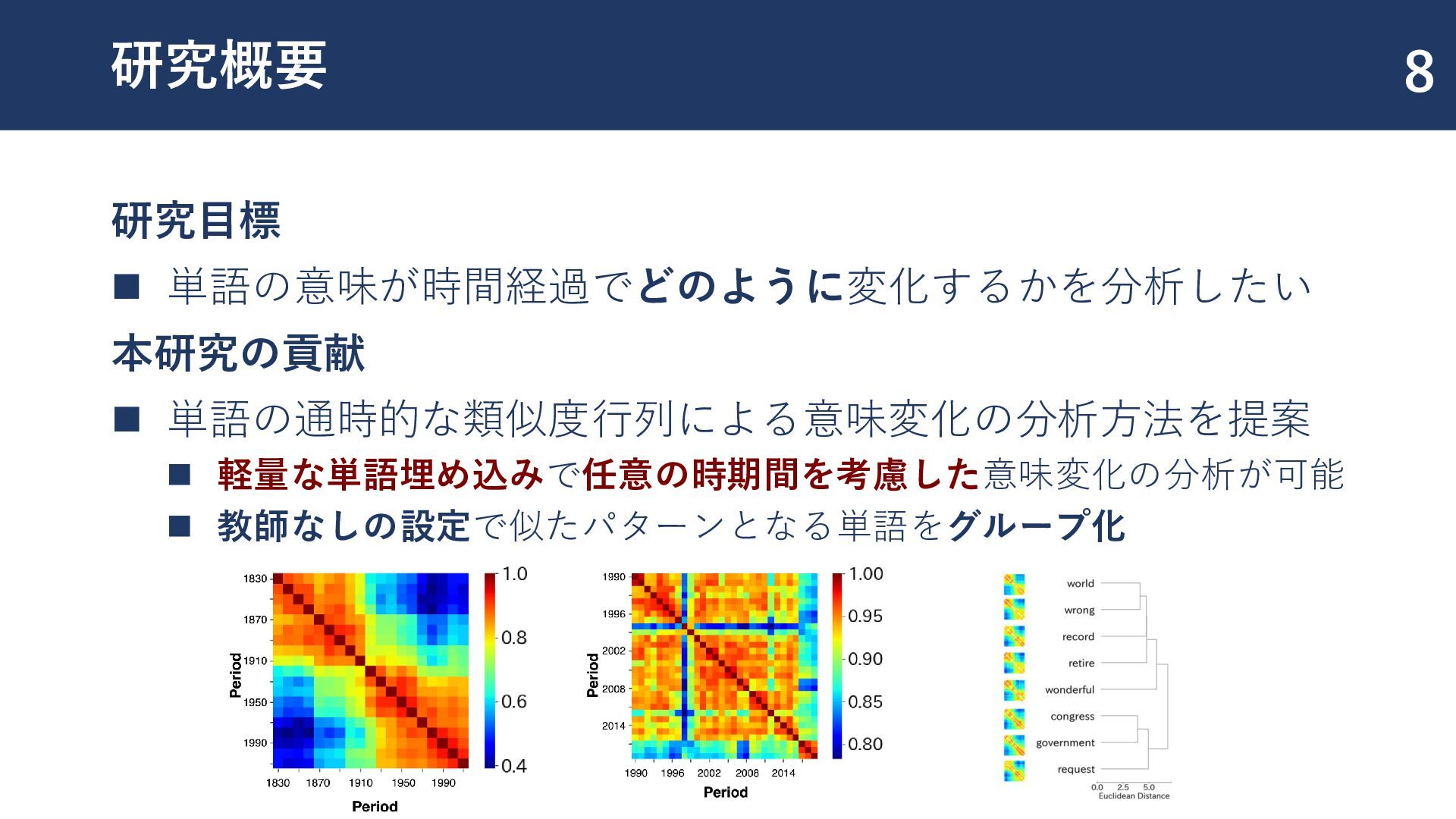{kind=link}
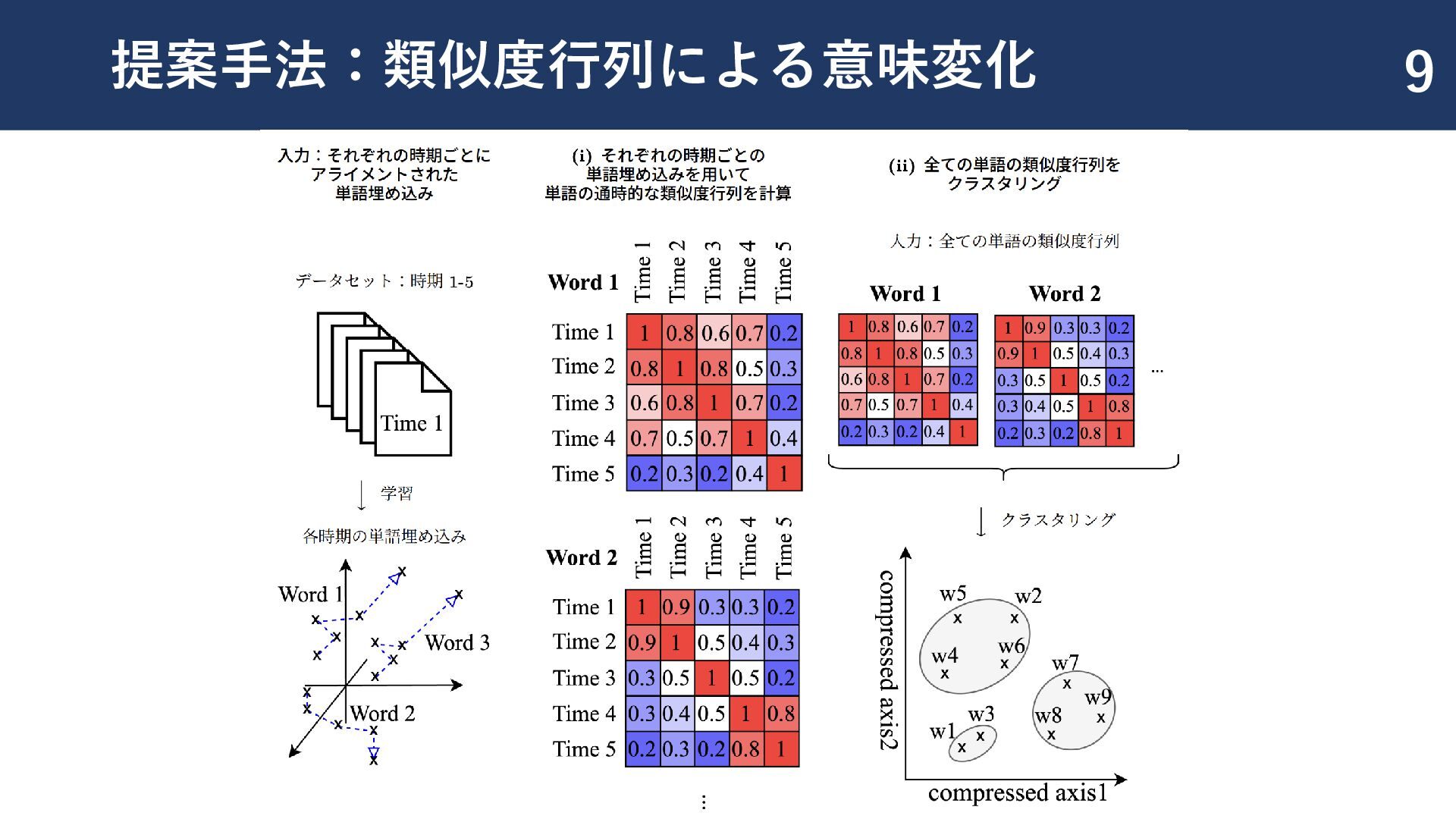{kind=link}
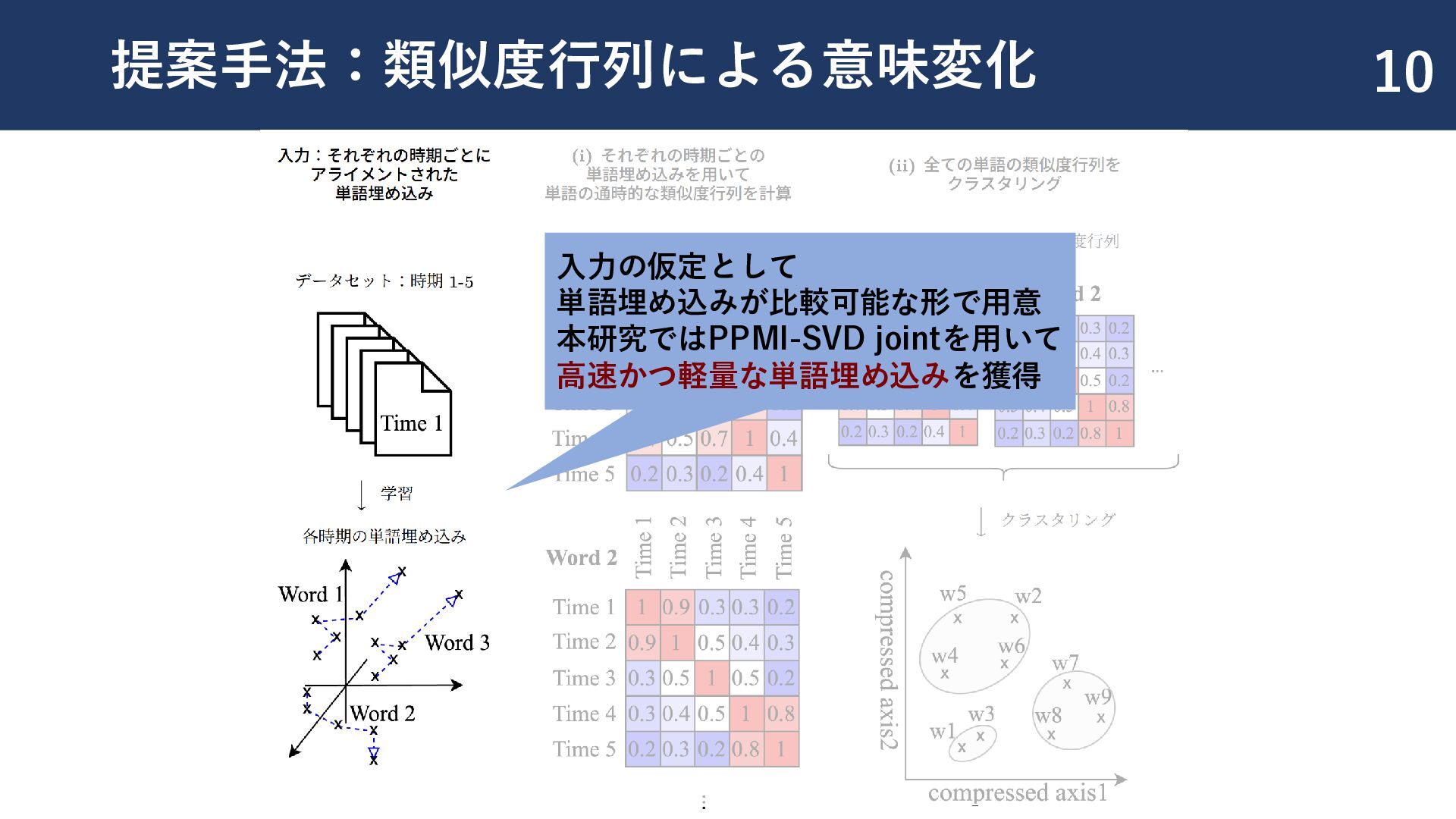{kind=link}
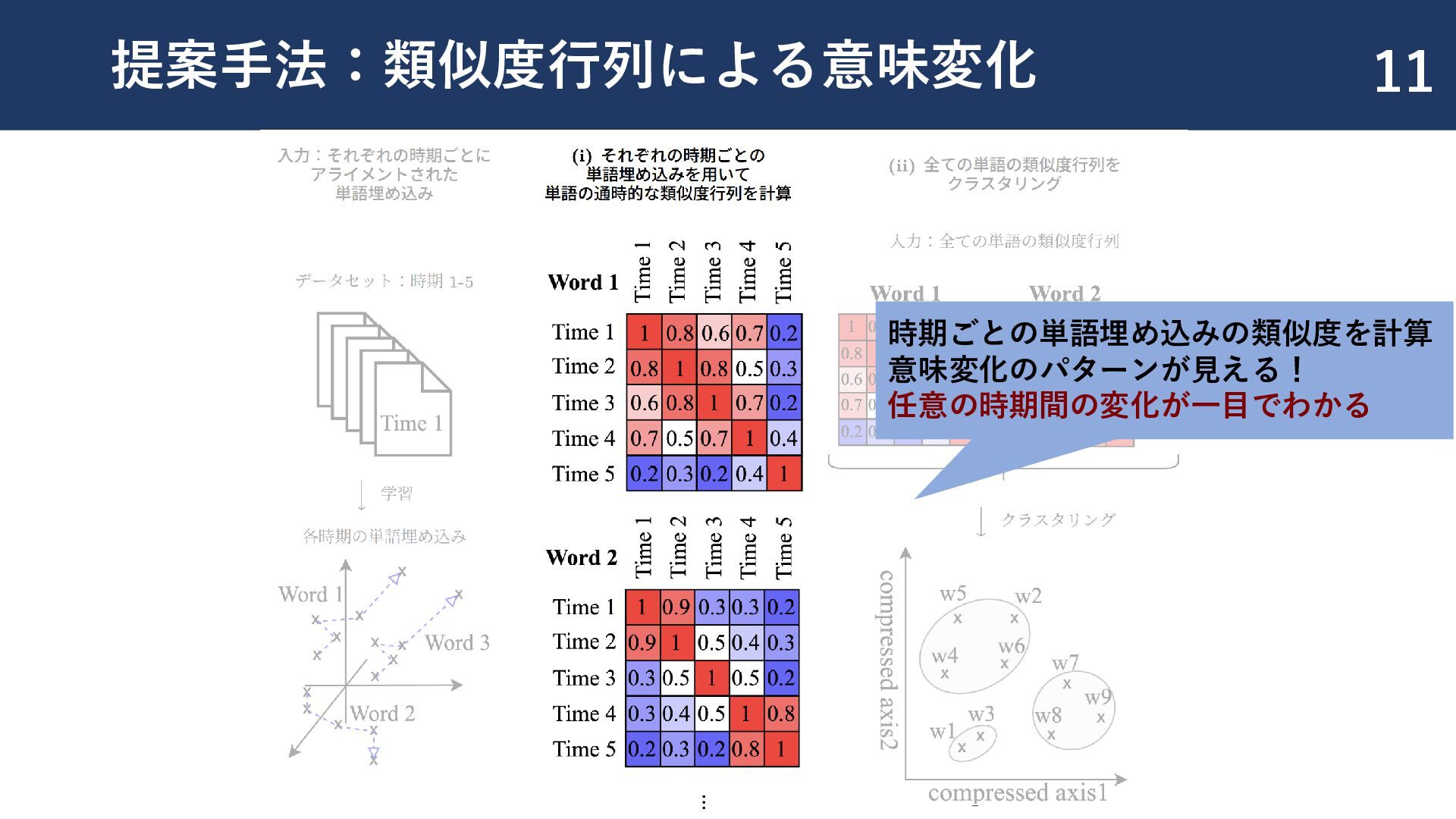{kind=link}
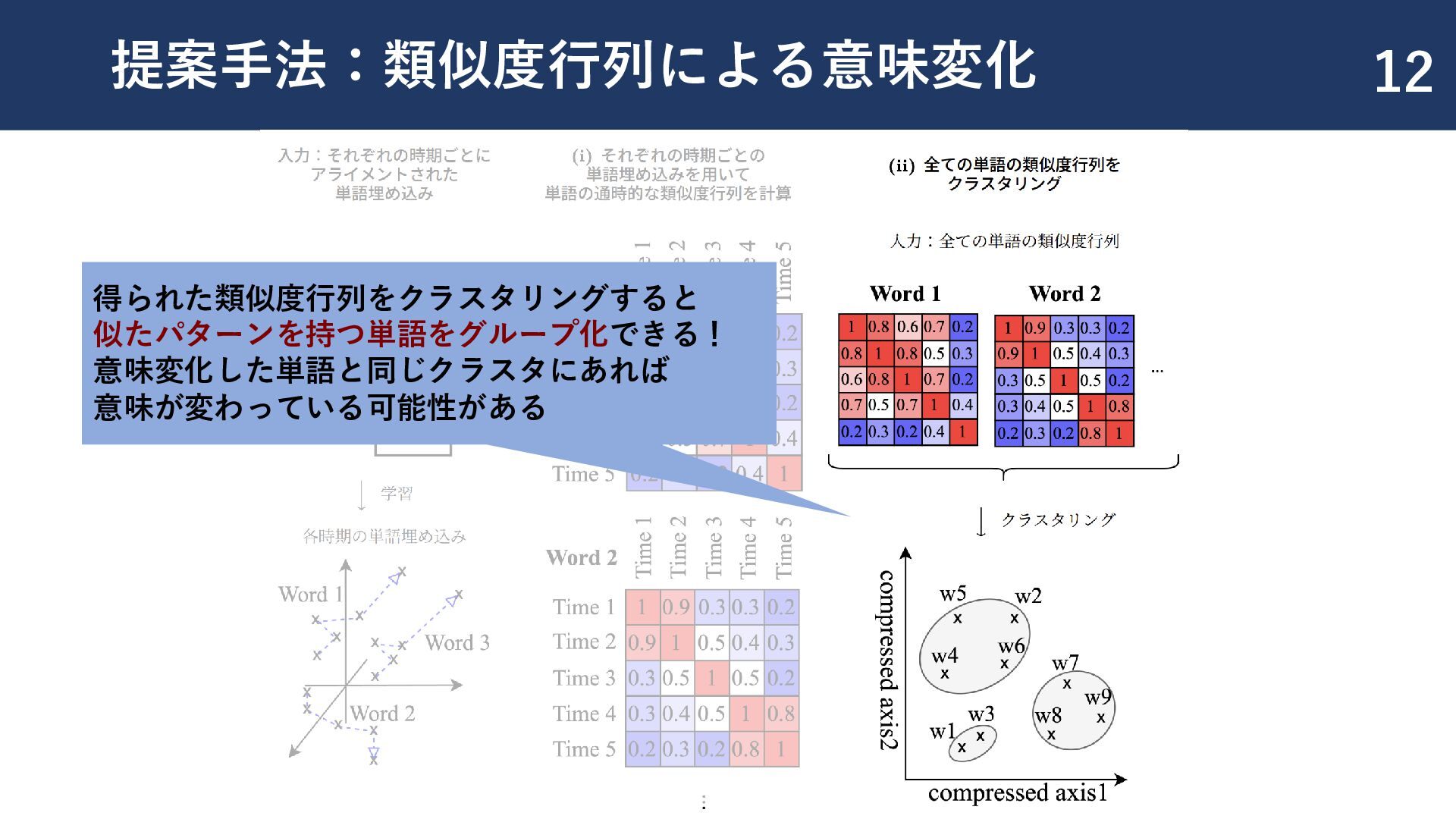{kind=link}
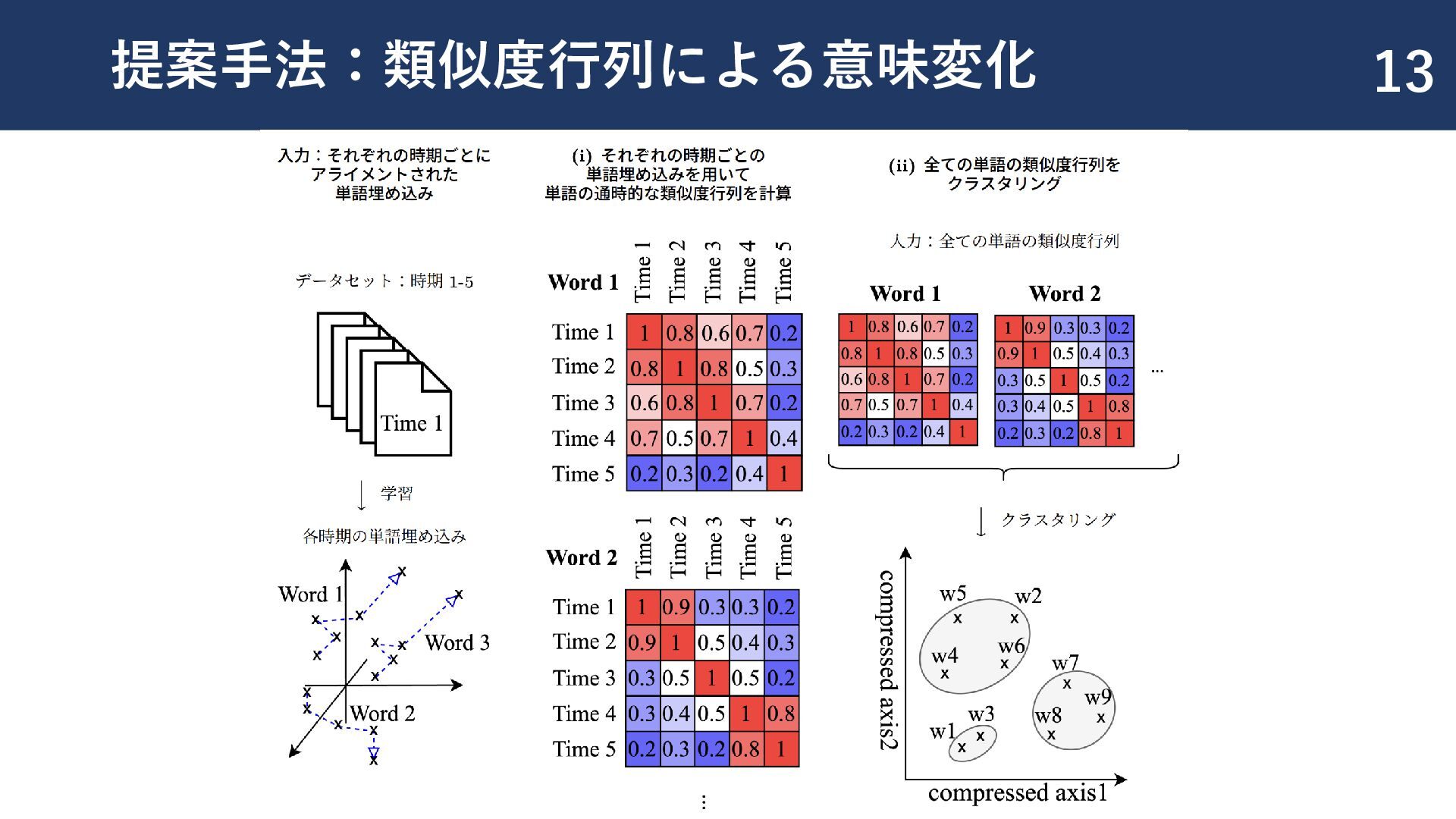{kind=link}
{kind=link}
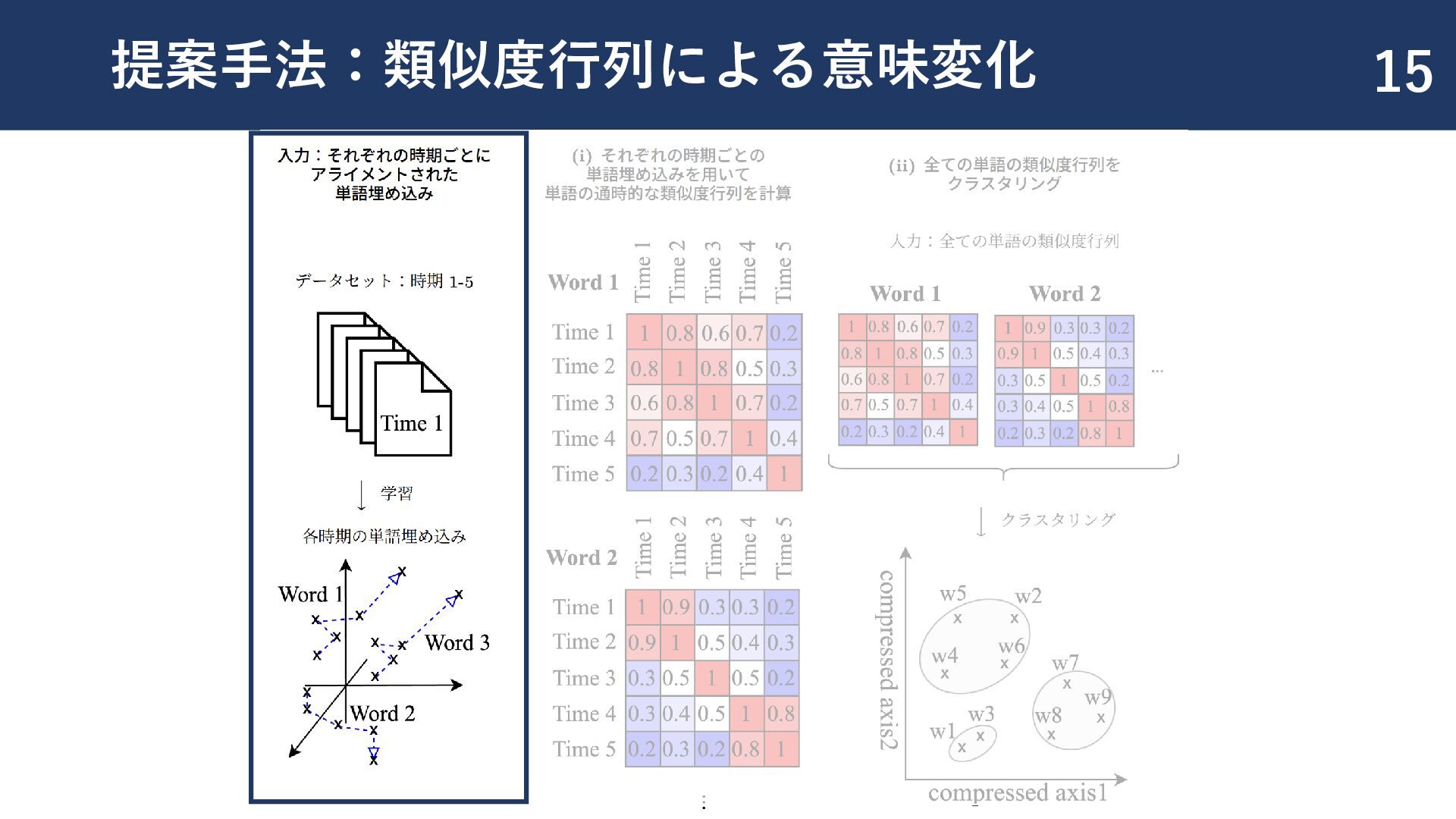{kind=link}
{kind=link}
{kind=link}
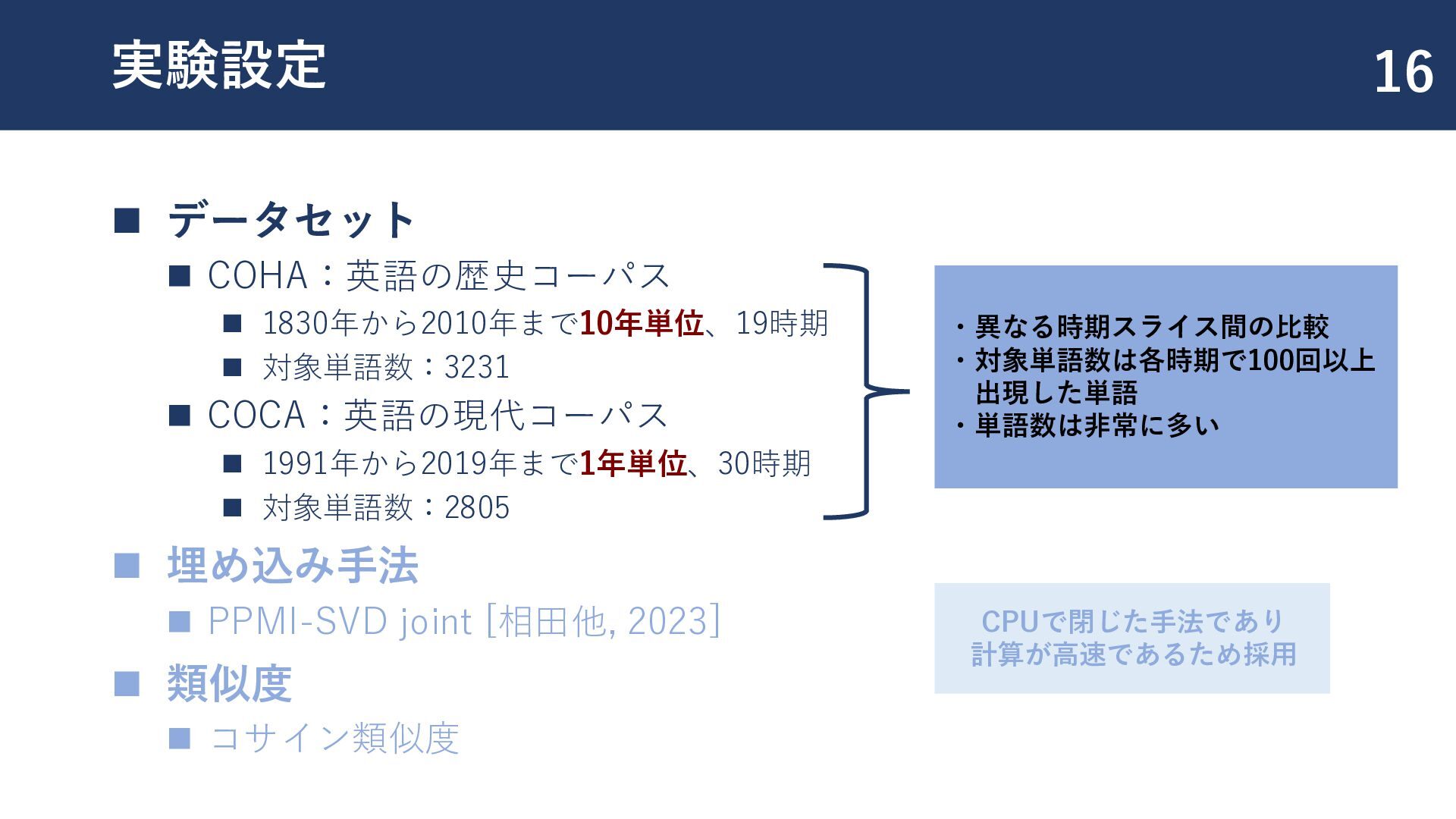
![埋め込み手法:PPMI-SVD joint ◼ PPMI-SVD [Levy and Goldberg, 2014] ◼ 正の自己相互情報量行列を特異値分解](https://files.speakerdeck.com/presentations/bf6312c3389846dca9e17f445b71460a/slide_18.jpg){kind=link}
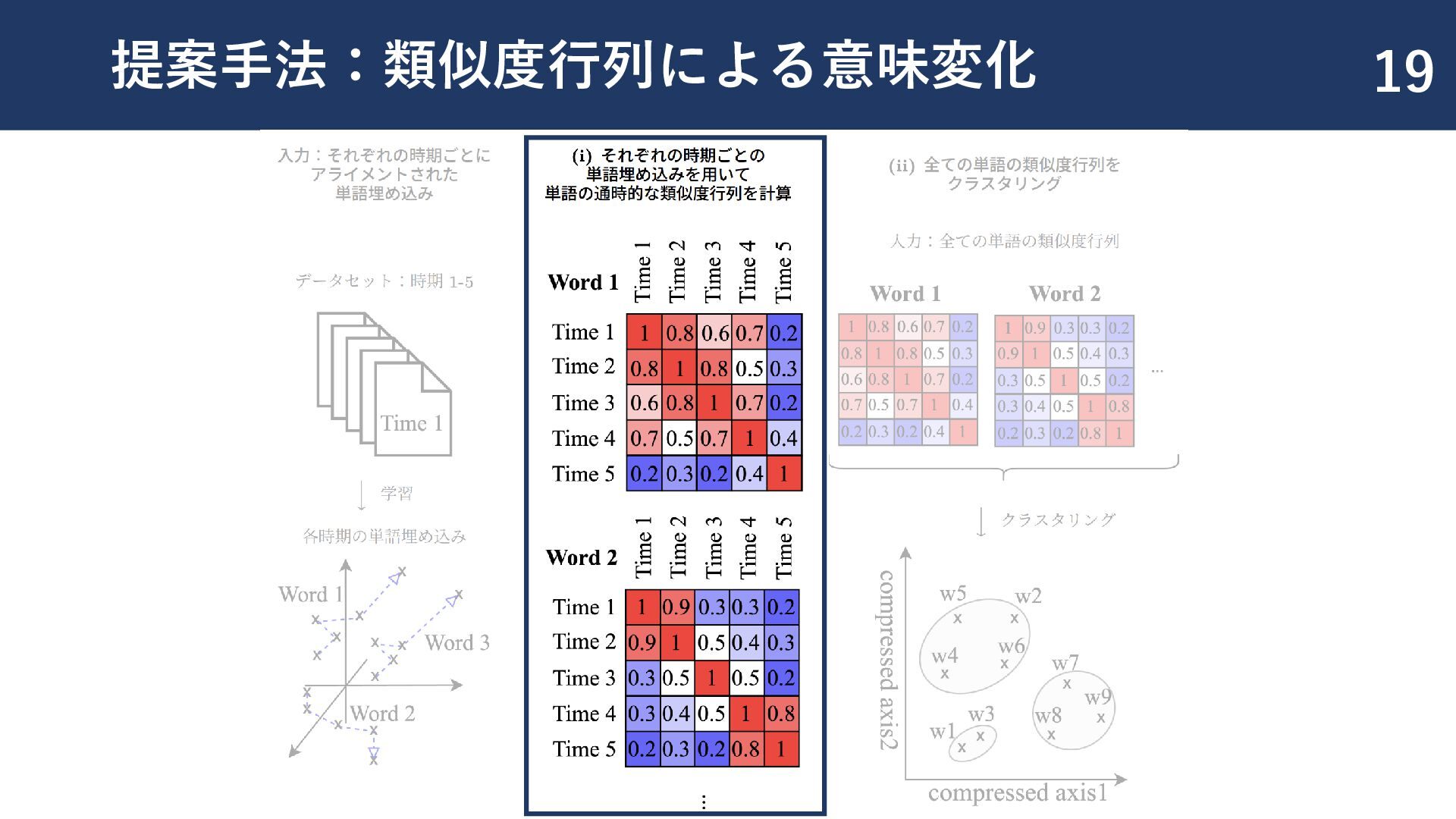{kind=link}
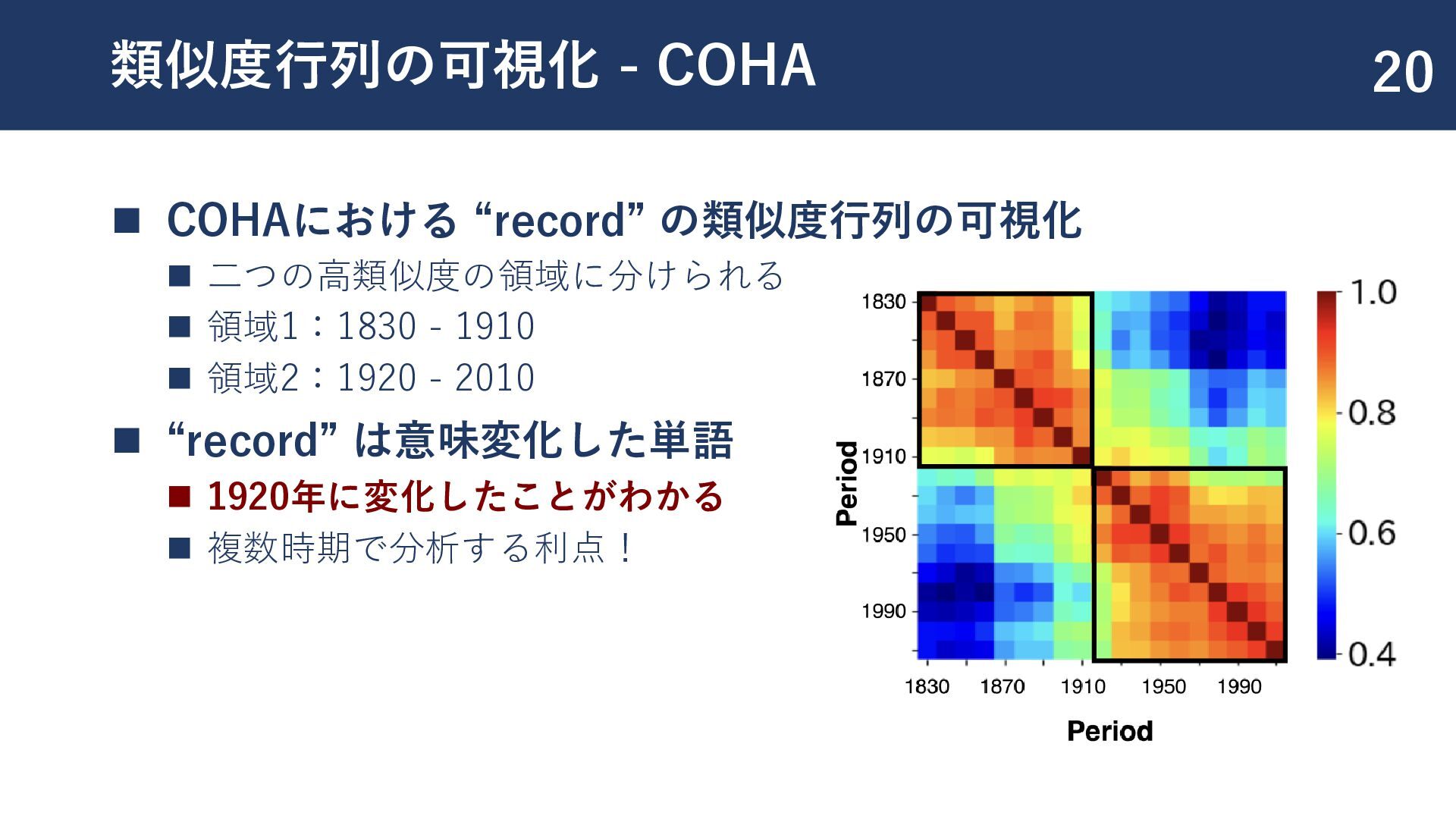{kind=link}
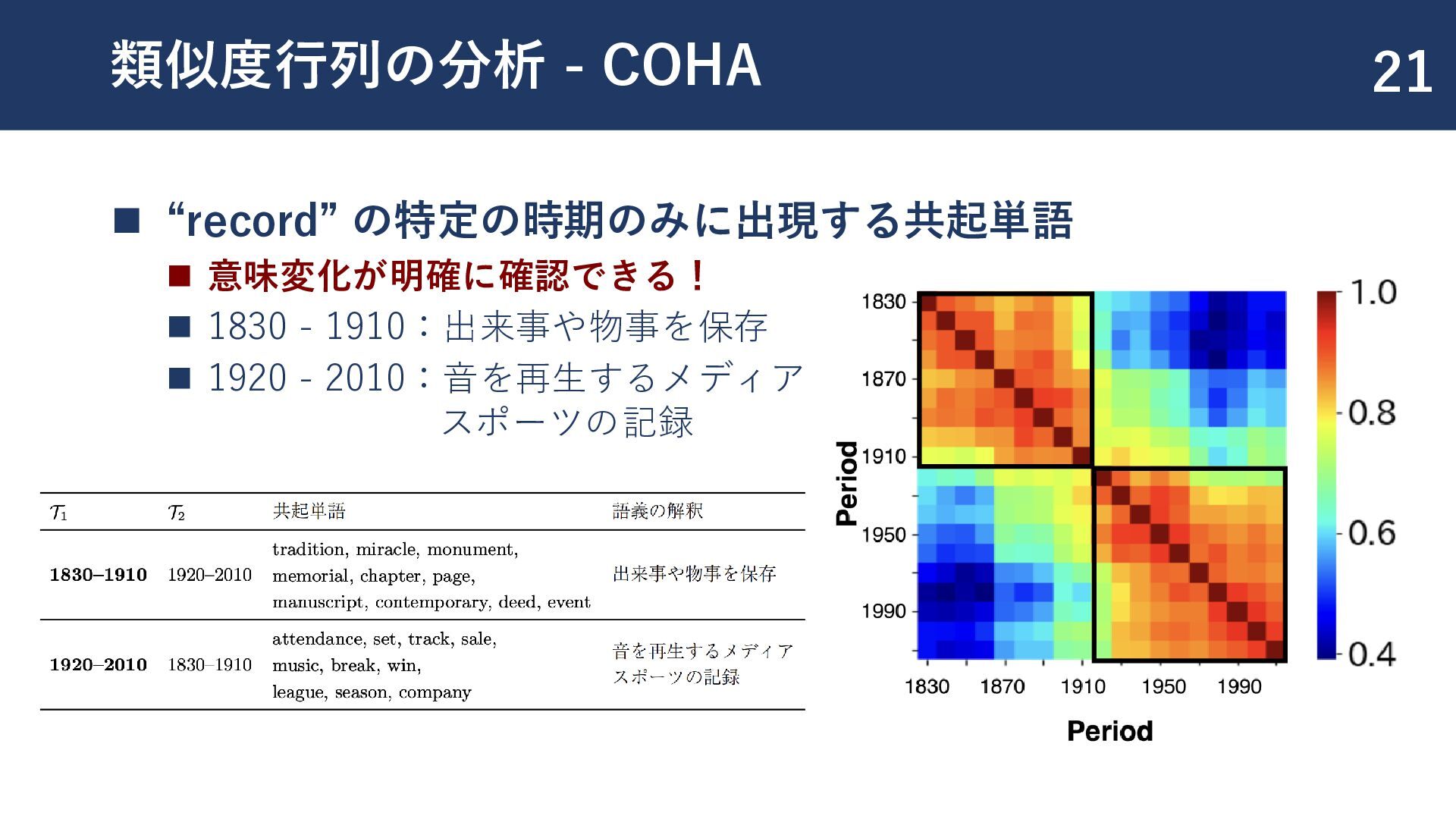{kind=link}
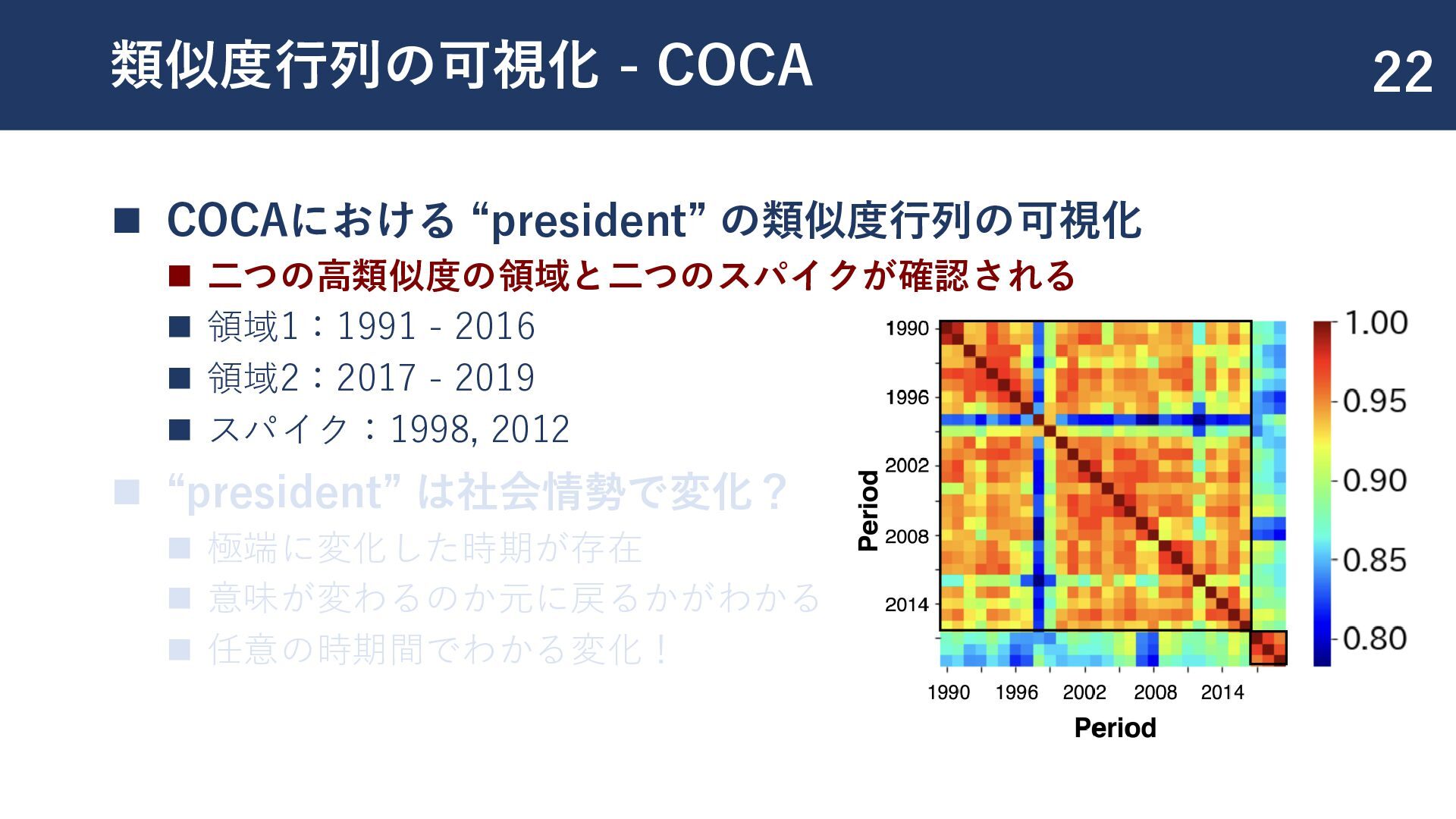{kind=link}
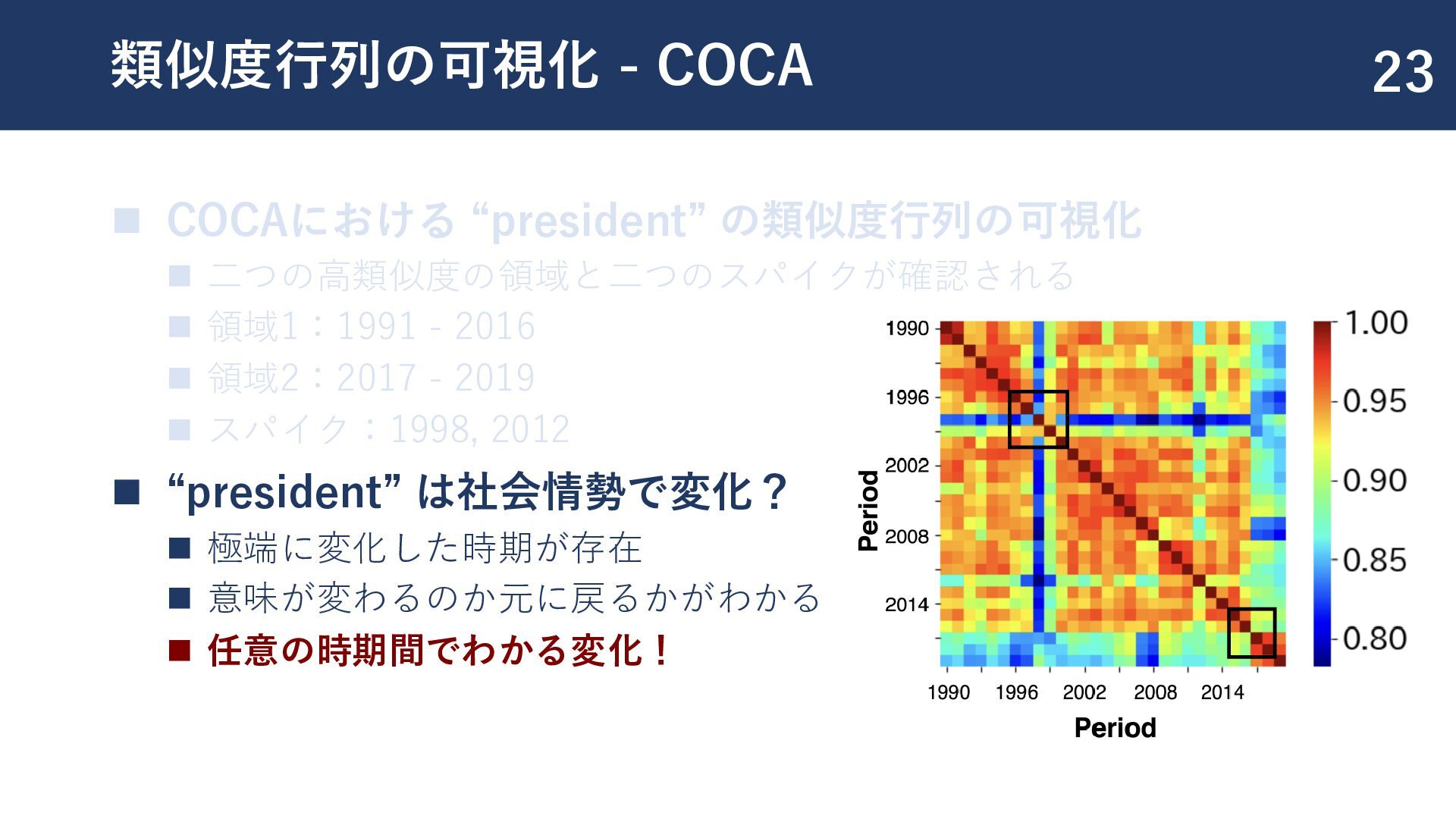{kind=link}
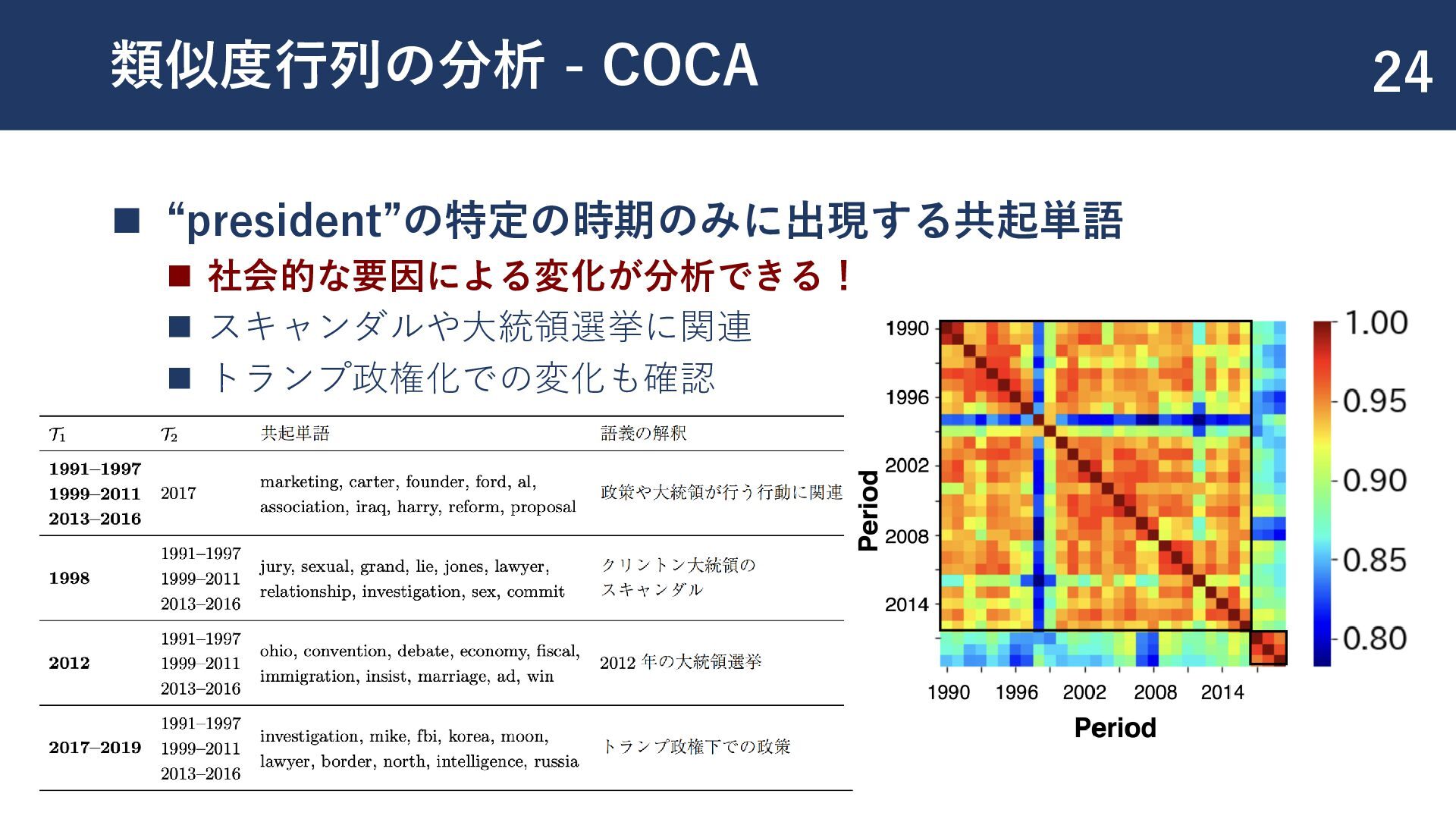{kind=link}
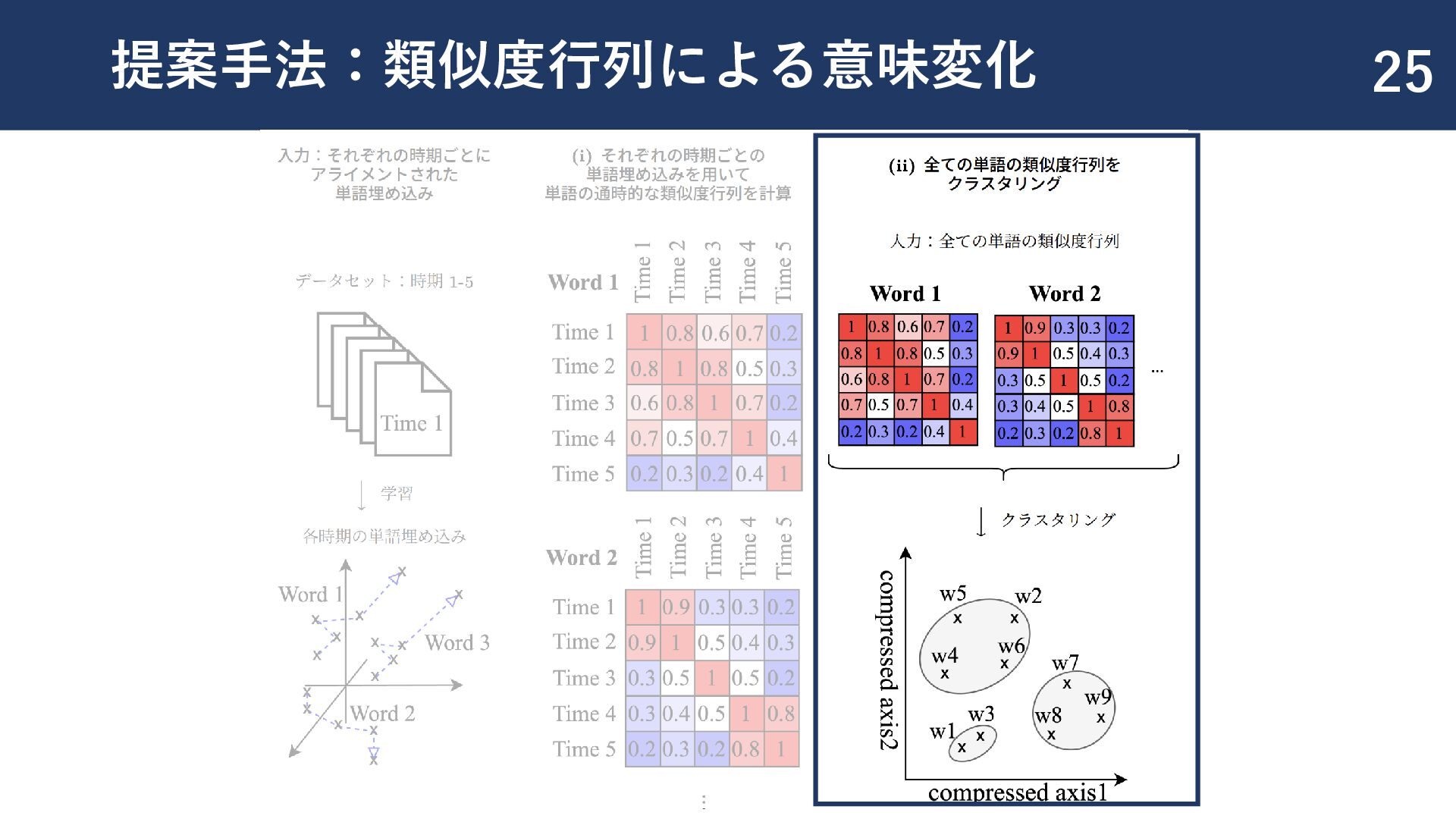{kind=link}
{kind=link}
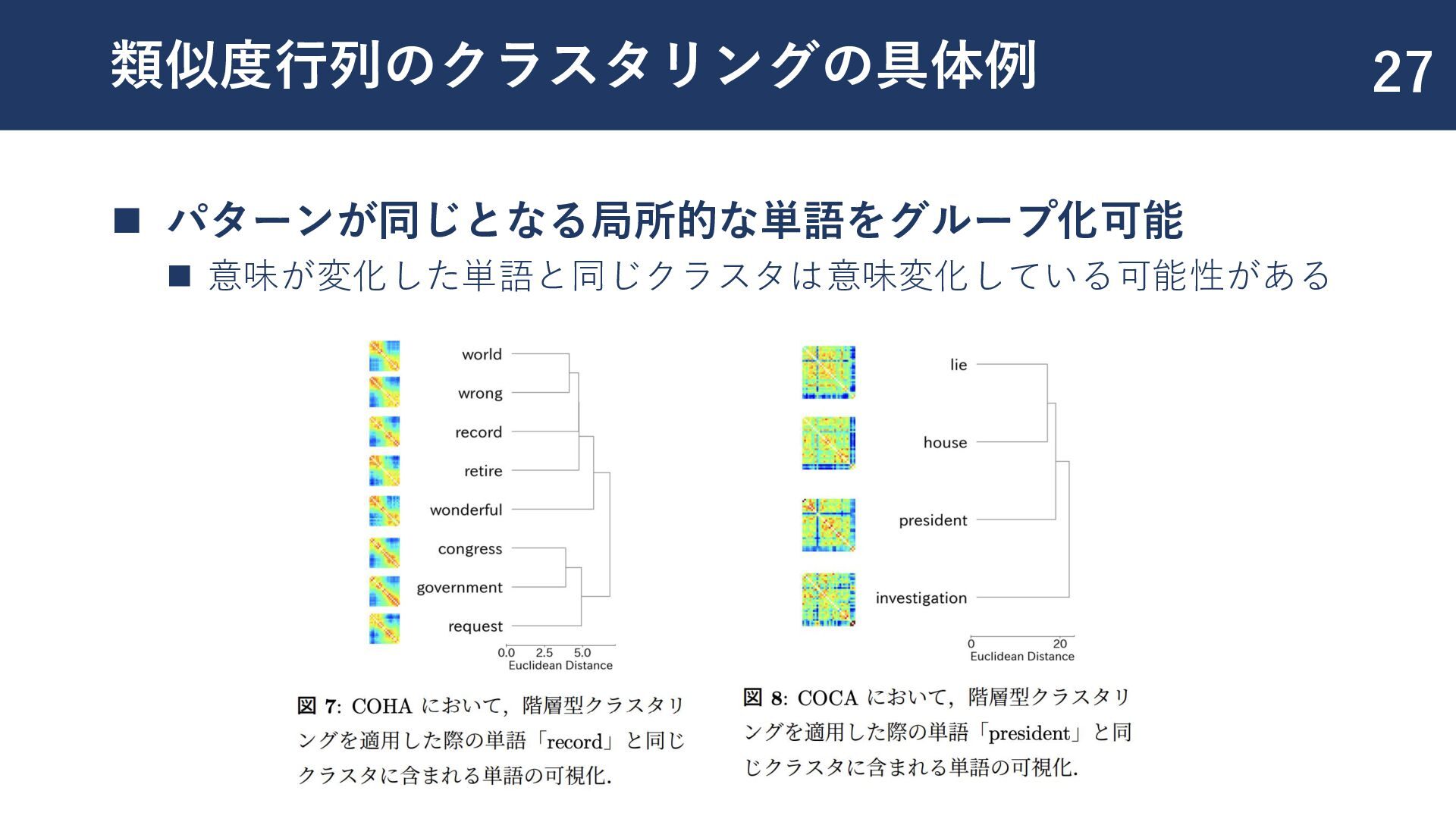{kind=link}
{kind=link}
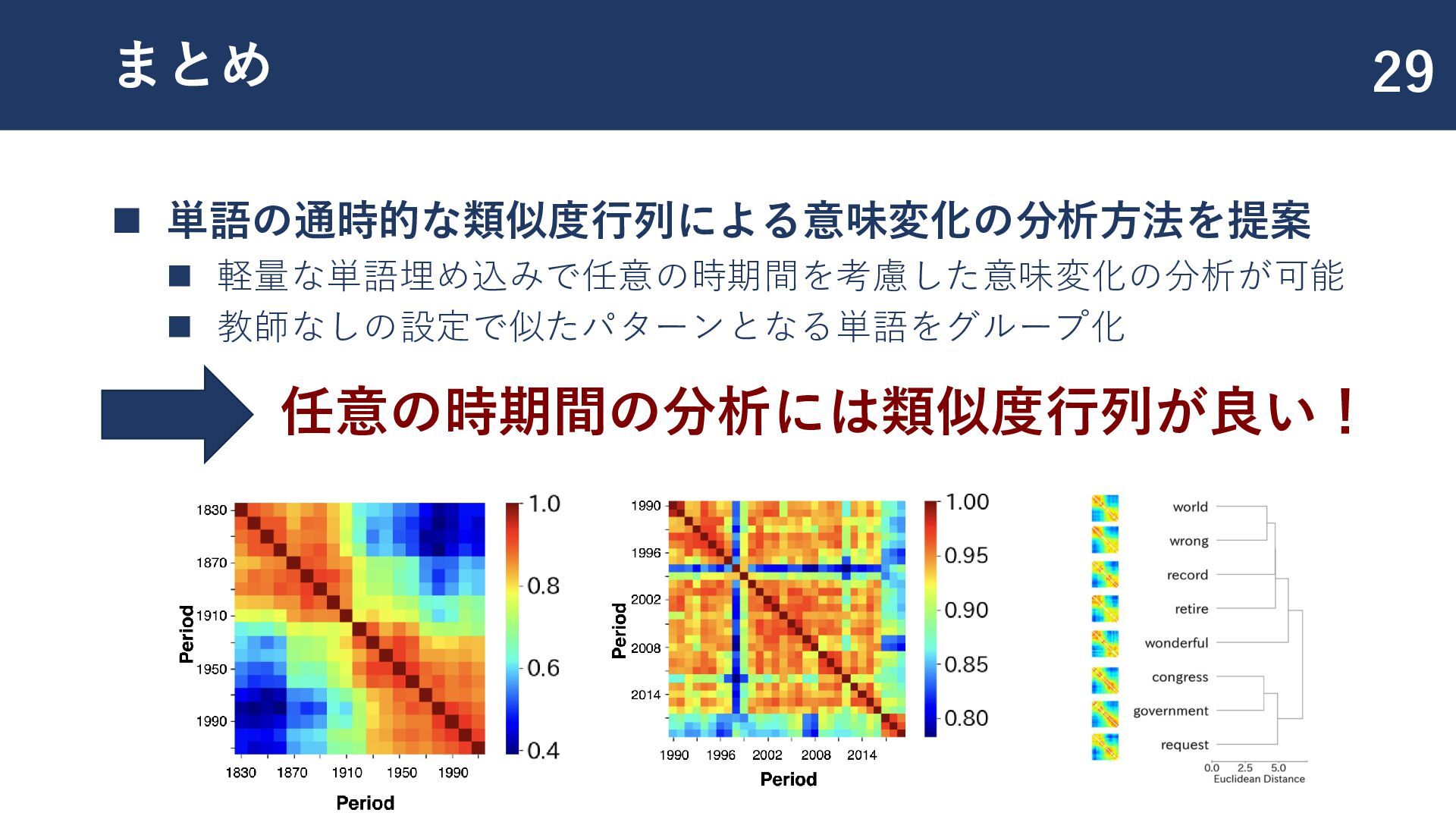{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
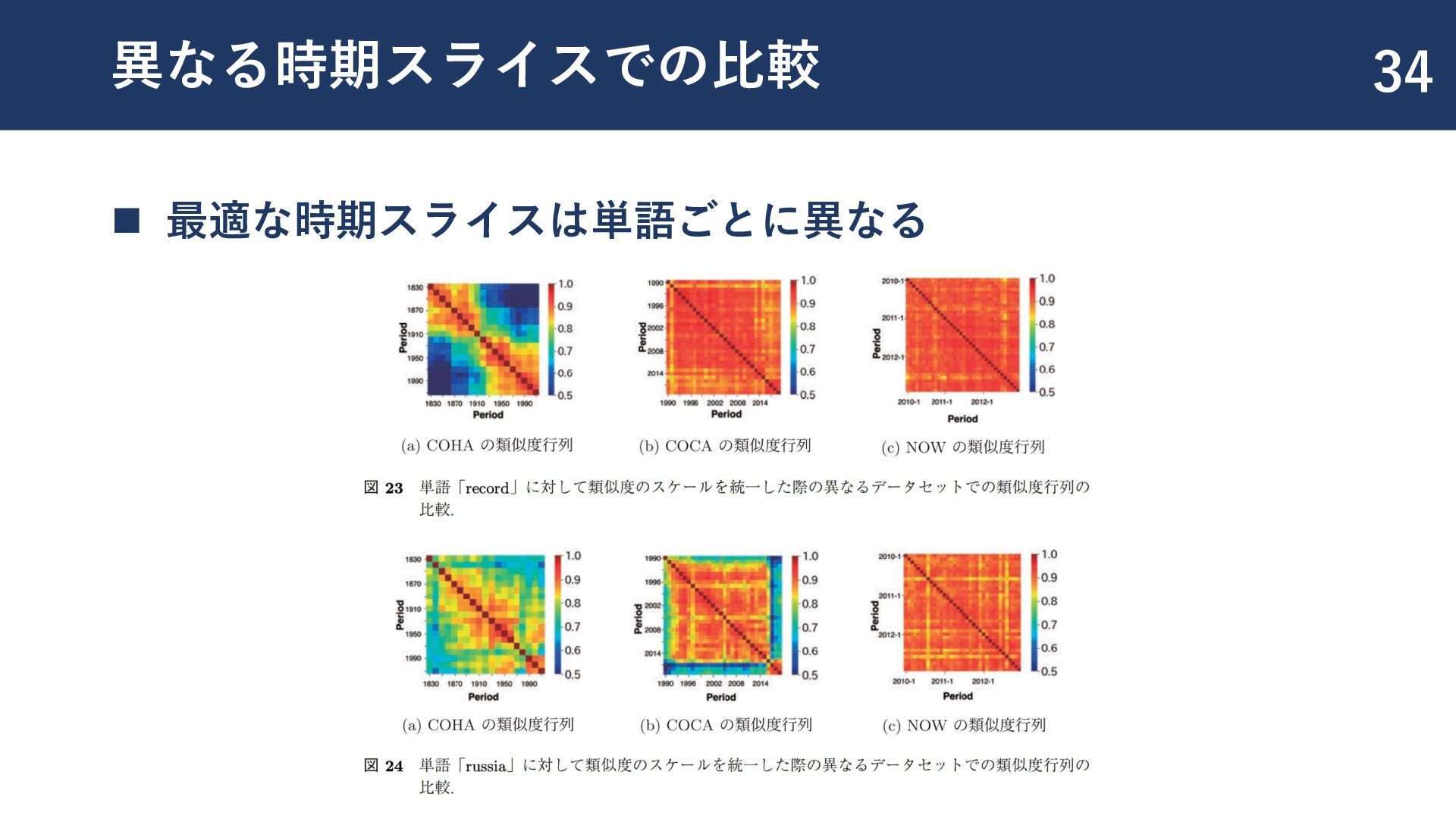{kind=link}
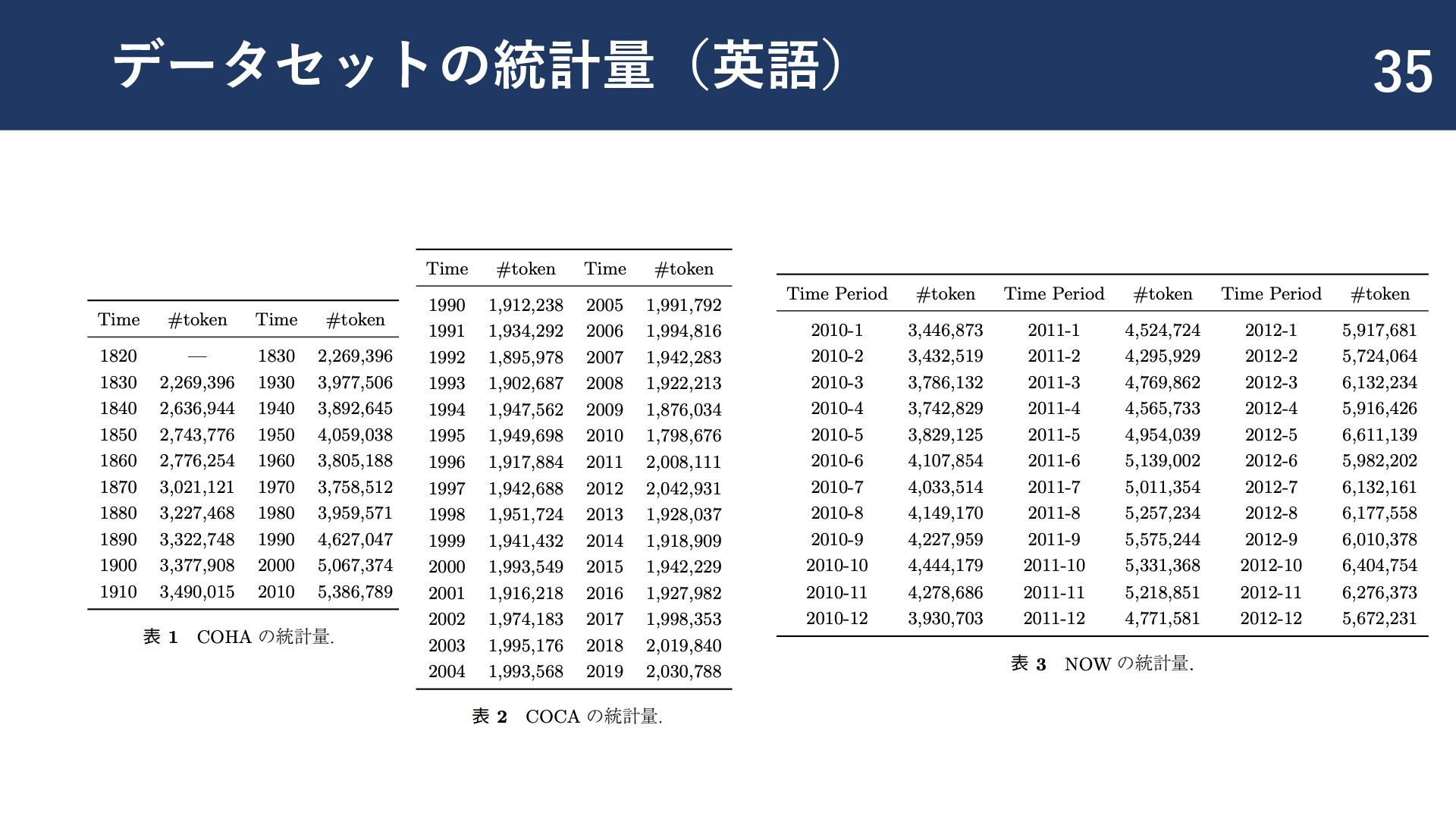{kind=link}
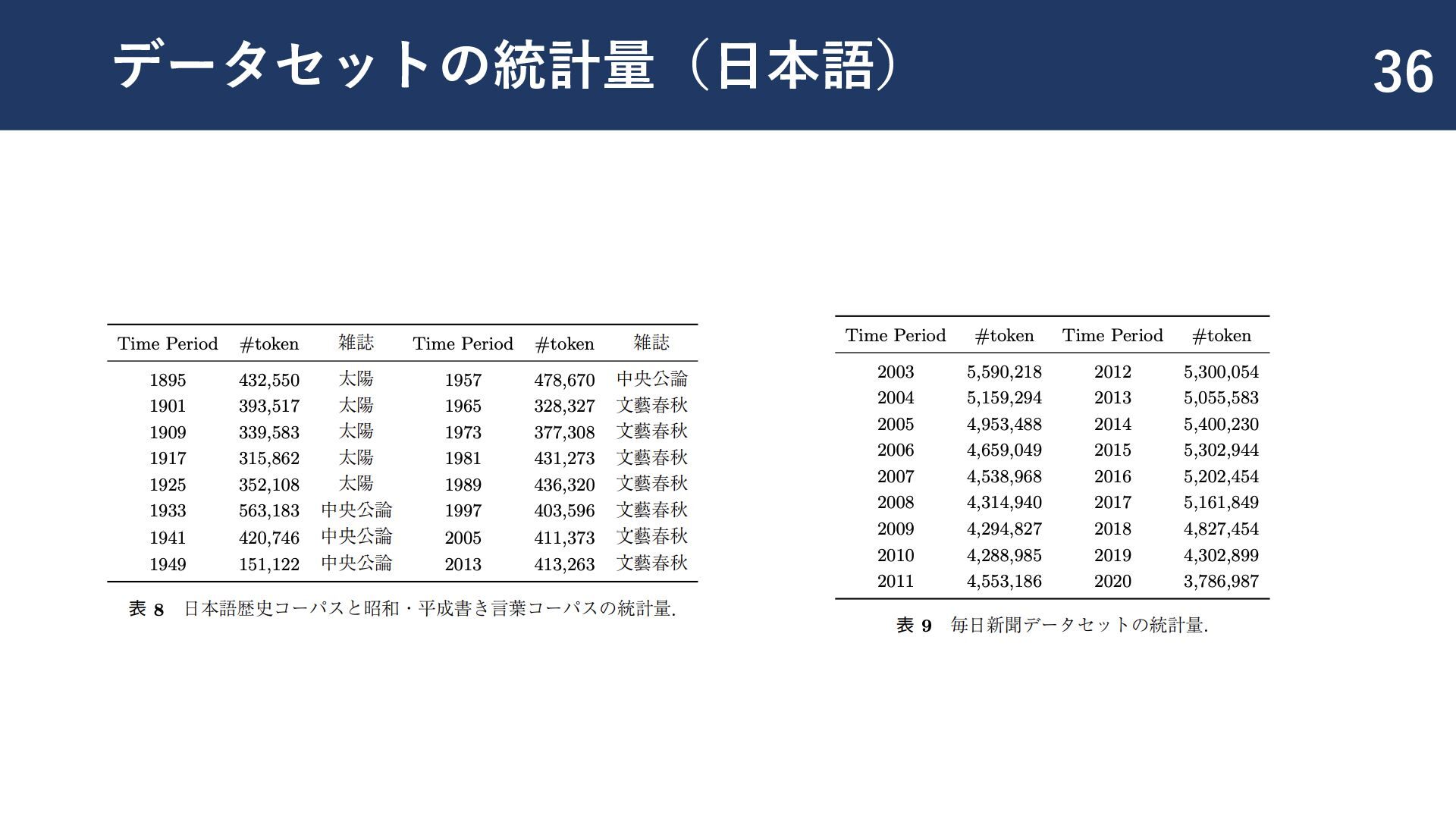{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
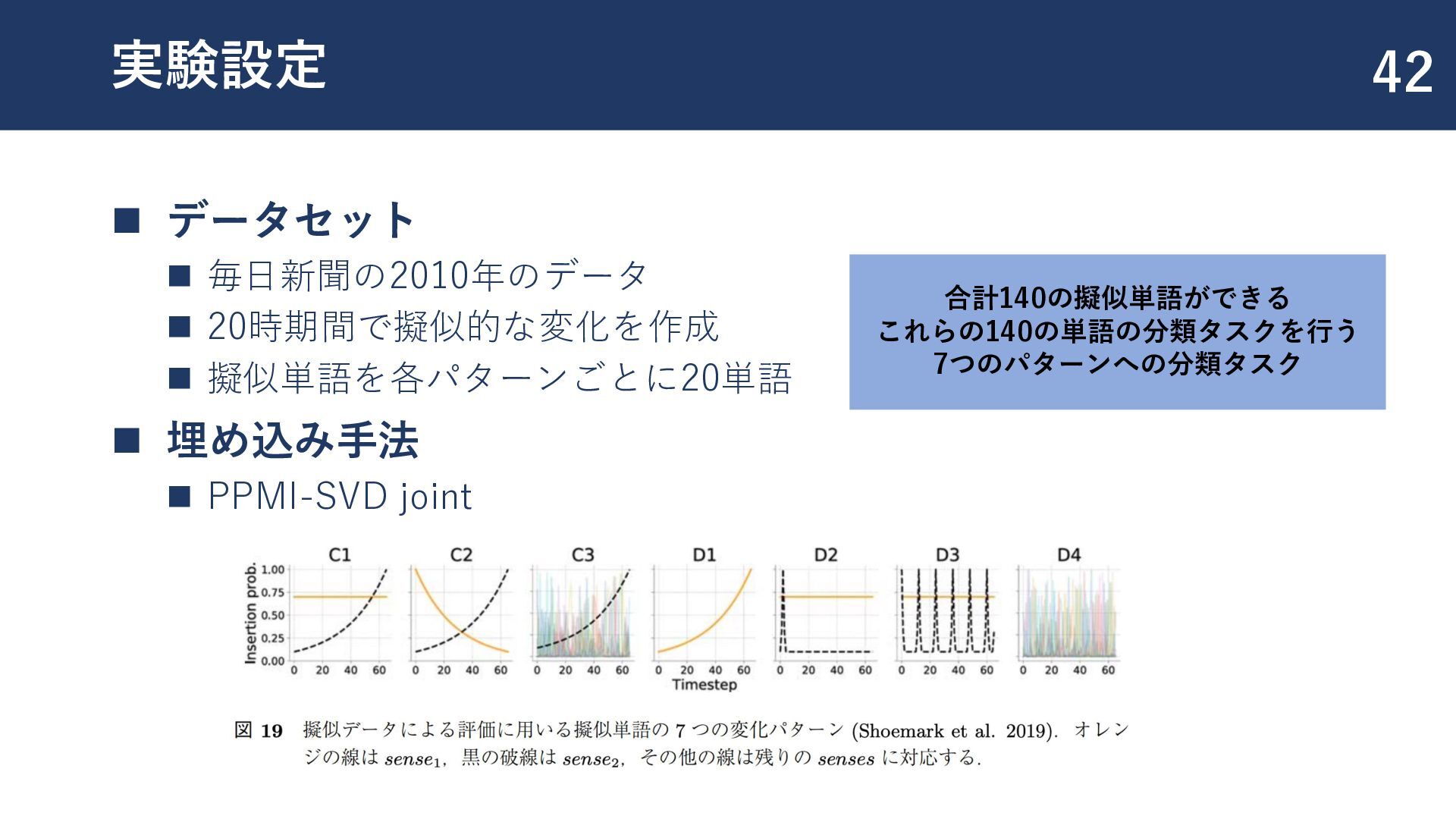
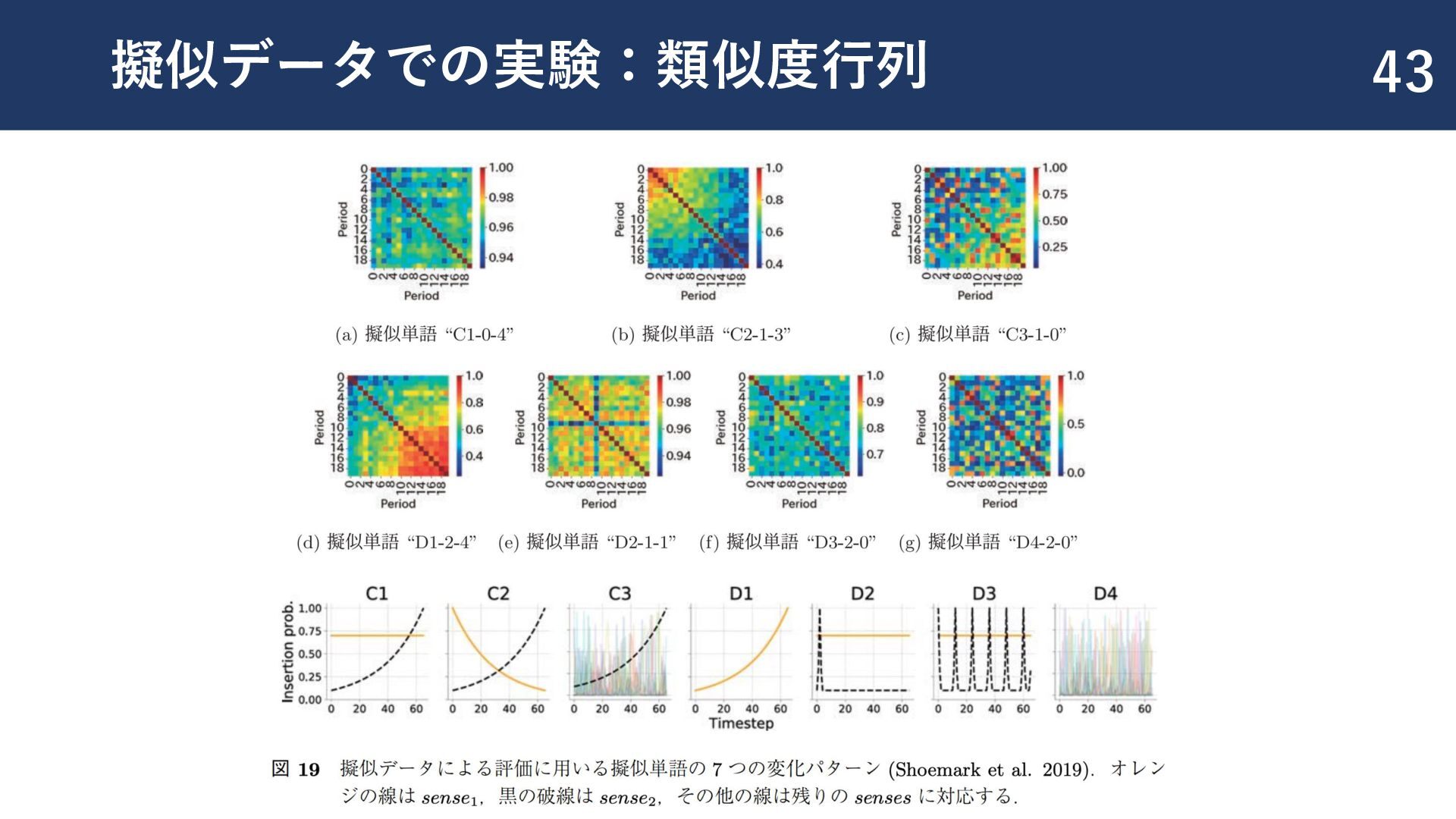
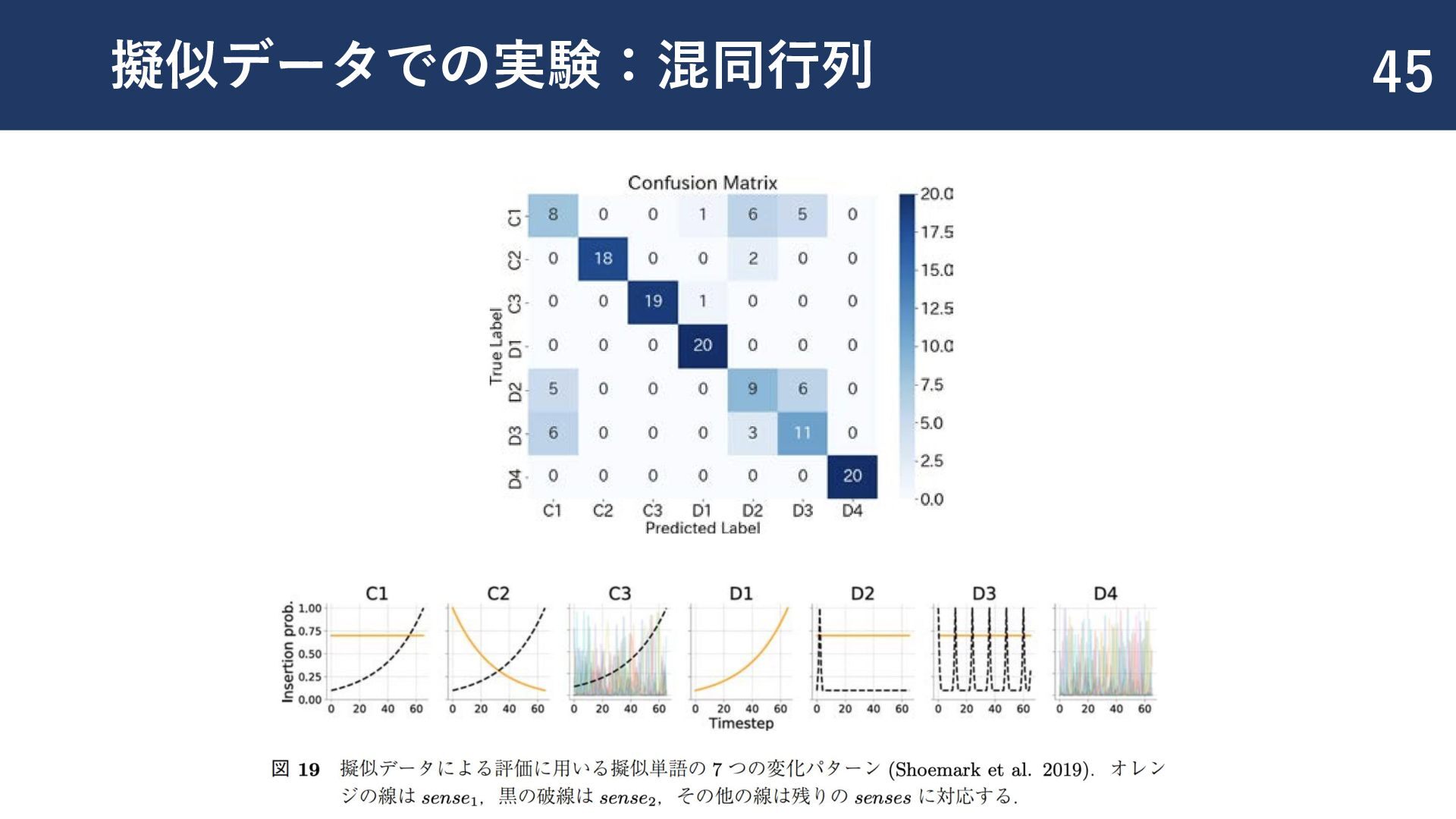
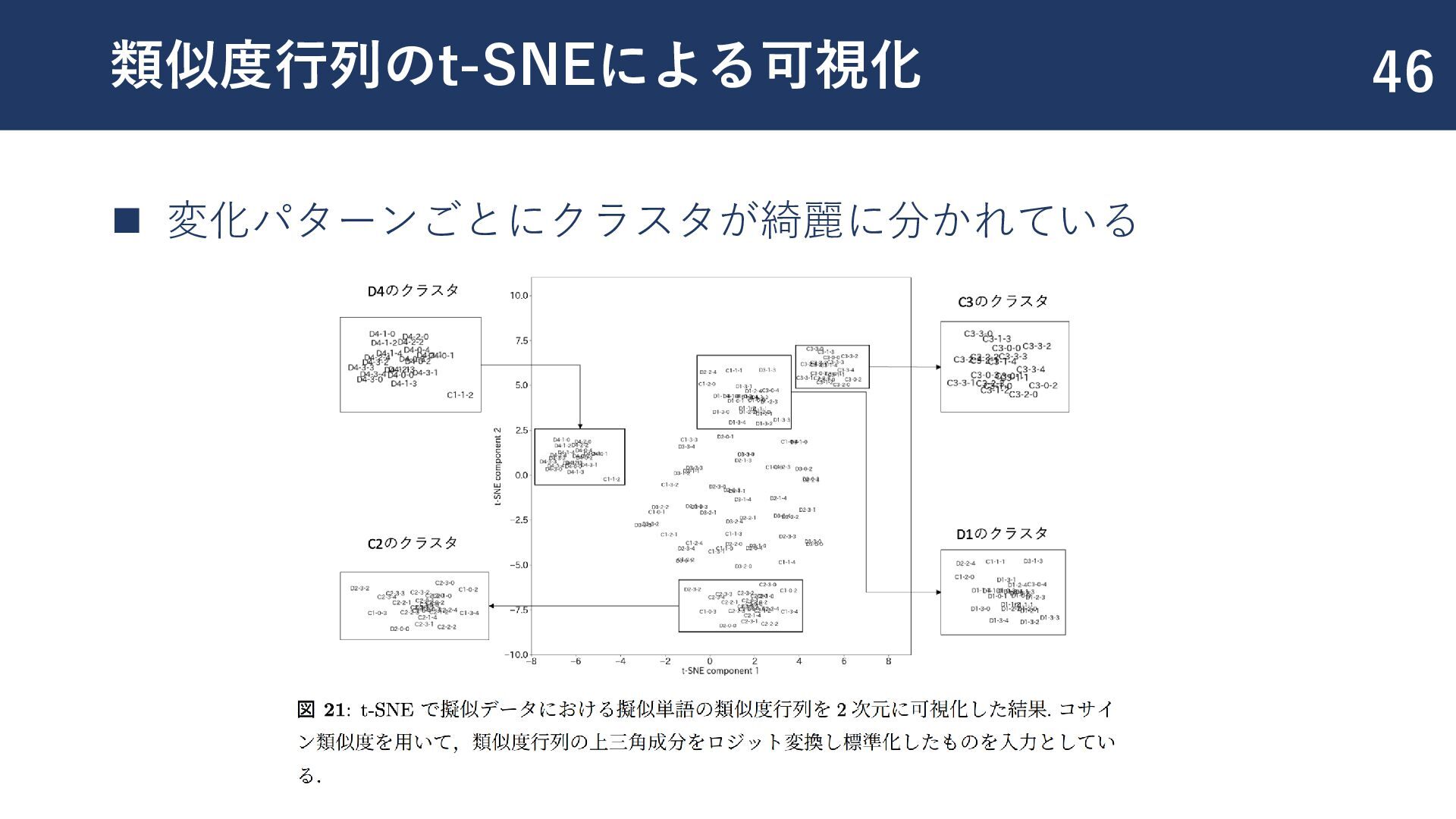
![変化パターンの分類 41 ◼ [Shoemark+,2017] の7つの変化パターンの分類タスクを実施 ◼ C1:新しい意味の獲得 ◼ C2:意味の転移 ◼](https://files.speakerdeck.com/presentations/bf6312c3389846dca9e17f445b71460a/slide_41.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![変化パターンの限界 ◼ [Shoemark+,2017] が定義した変化パターンを用いた分類 ◼ この変化パターンが全てのパターンを網羅はしていない ◼ 提案手法の性能を過大/過小評価している可能性 ◼ どのような変化パターンが検出できると嬉しいのか?](https://files.speakerdeck.com/presentations/bf6312c3389846dca9e17f445b71460a/slide_47.jpg){kind=link}
{kind=link}
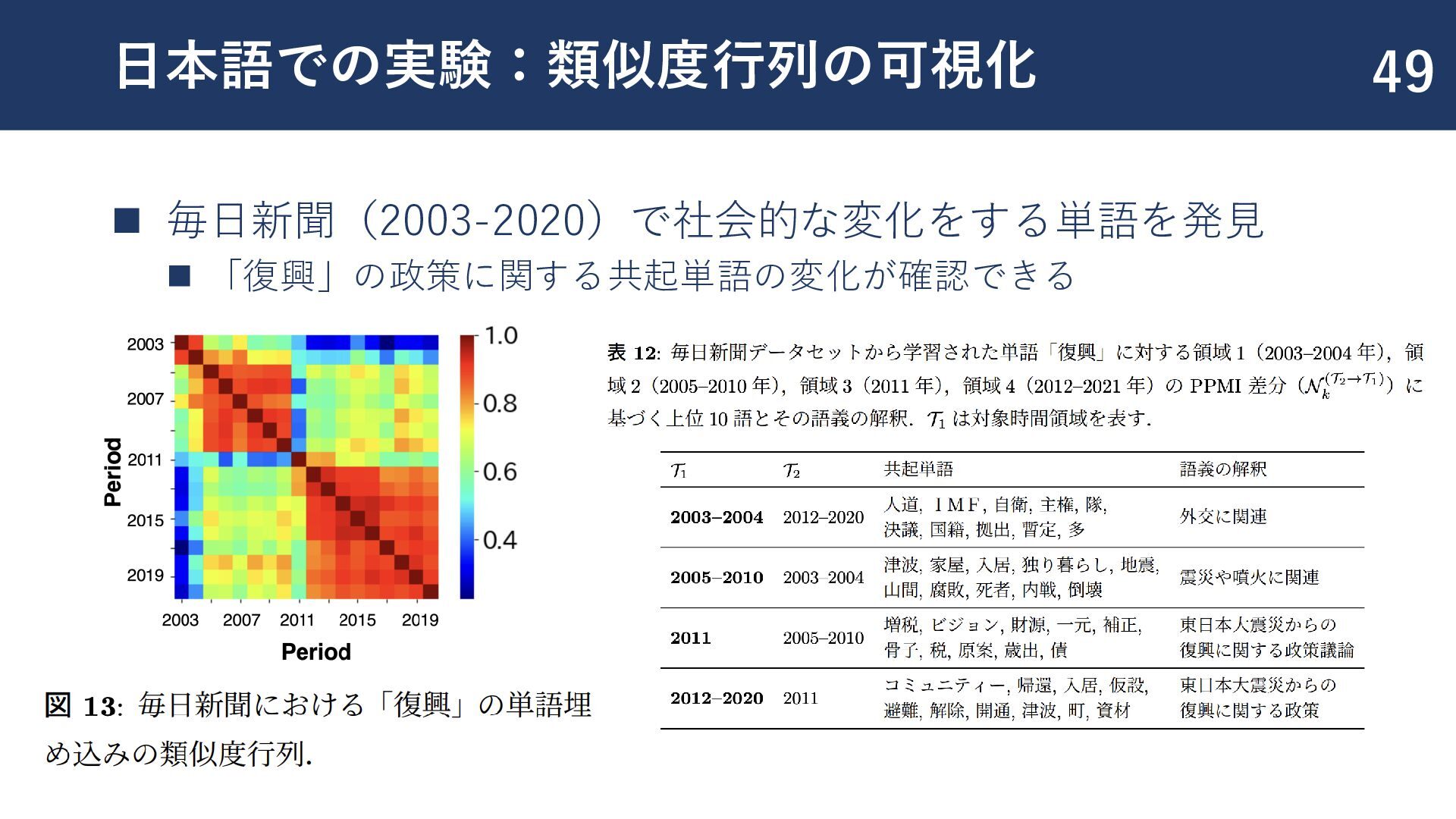{kind=link}
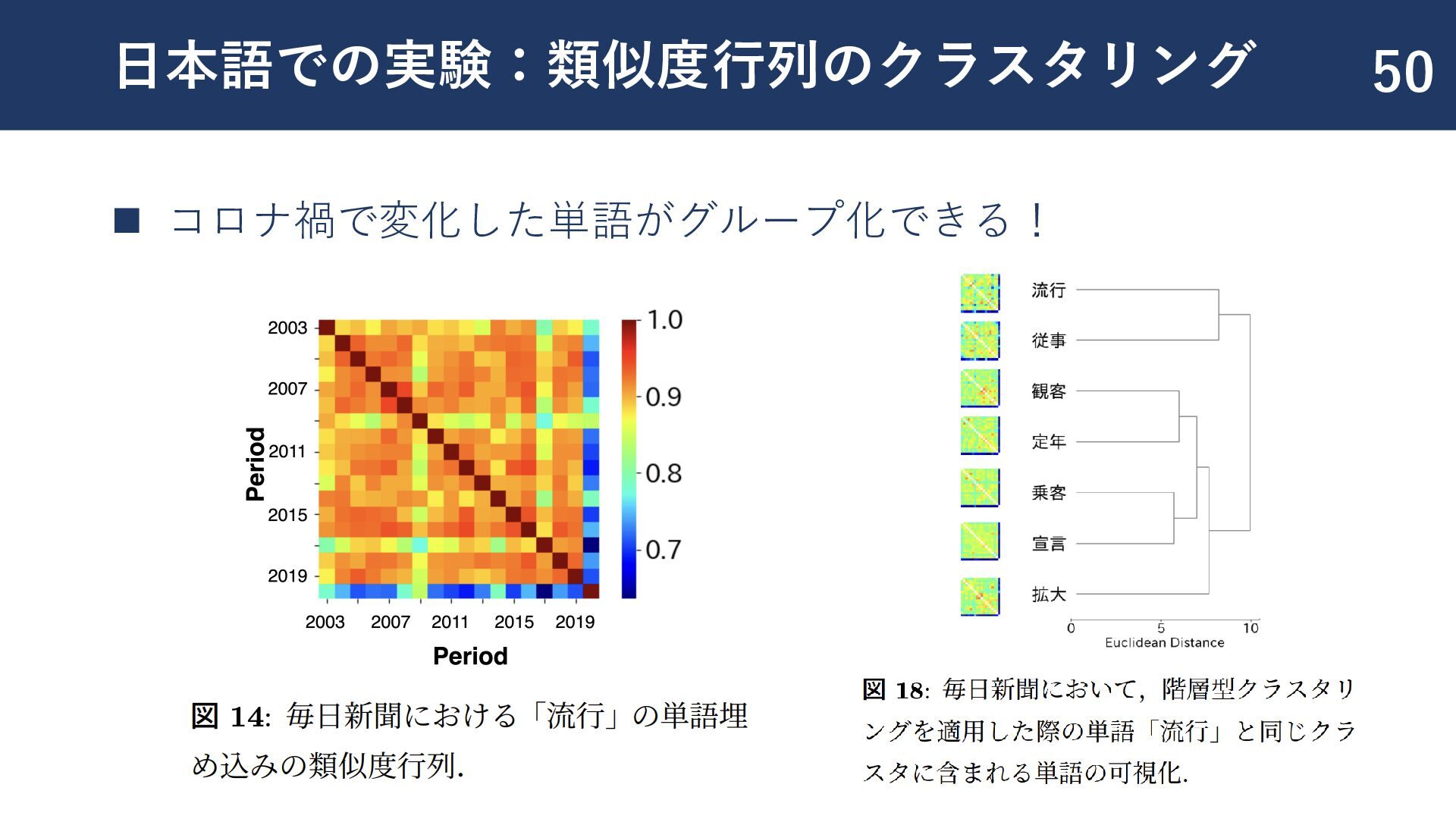{kind=link}
{kind=link}
![関連研究1 [Hamilton+,2016] Diachronic Word Embeddings Reveal Statistical Laws of Semantic](https://files.speakerdeck.com/presentations/bf6312c3389846dca9e17f445b71460a/slide_52.jpg){kind=link}
![関連研究2 [Periti+, 2024] Analyzing Semantic Change through Lexical Replacements [Kulkarni+,](https://files.speakerdeck.com/presentations/bf6312c3389846dca9e17f445b71460a/slide_53.jpg){kind=link}
![関連研究3 [相田他, 2023] 異なる時期での意味の違いを捉える単語分散表現 の結合学習 [Levy and Goldberg, 2014] Neural](https://files.speakerdeck.com/presentations/bf6312c3389846dca9e17f445b71460a/slide_54.jpg){kind=link}