Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
機械学習で作った ポケモン対戦bot で 遊ぼう!
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
Yusuke Fukasawa
February 21, 2026
Research
340
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
機械学習で作った ポケモン対戦bot で 遊ぼう!
リモートポケモン学会 2026/02/21 の発表です。
https://x.com/rimopoke/status/2022628011590537676?s=20
Yusuke Fukasawa
February 21, 2026
More Decks by Yusuke Fukasawa
See All by Yusuke Fukasawa
ポケモン対戦を自動で 記録する PCBL(Pokémon Champions Battle Logger) の紹介
fufufukakaka
1
470
LLMアプリケーションの透明性について
fufufukakaka
0
250
やるべきときにMLをやる AIエージェント開発
fufufukakaka
2
1.5k
社内データ分析AIエージェントを できるだけ使いやすくする工夫
fufufukakaka
1
1.1k
コミューンのデータ分析AIエージェント「Community Sage」の紹介
fufufukakaka
0
2.7k
ファインディLT_ポケモン対戦の定量的分析
fufufukakaka
0
2.6k
対戦におけるポケモンの “意味変化”を追う_リモートポケモン学会
fufufukakaka
0
310
機械学習を用いたポケモン対戦選出予測
fufufukakaka
2
2.7k
Poke_Battle_Logger の紹介: リモポケ学会20230714
fufufukakaka
1
1.2k
Other Decks in Research
See All in Research
研究室単位での自律的 IPv6接続性確立に向けたAS共同運用モデルの提案と実証
reokashiwa
PRO
0
140
Scalable dynamic origin-destination demand estimation enhanced by high-resolution satellite imagery data
satai
3
330
Cross-Media Information Spaces and Architectures
signer
PRO
0
310
AIを叩き台として、 「検証」から「共創」へと進化するリサーチ
mela_dayo
0
300
Sequences of Logits Reveal the Low Rank Structure of Language Models
sansantech
PRO
1
280
Model Discovery and Graph Simulation: A Lightweight Gateway to Chaos Engineering
anatolykr
0
210
進学校の生徒にはア行の苗字が多いのか
ozekinote
0
470
Φ-Sat-2のAutoEncoderによる情報圧縮系論文
satai
4
830
コーディングエージェントとABNを再考
hf149
2
750
2026年3月1日(日)福島「除染土」の公共利用をかんがえる
atsukomasano2026
0
660
2026 東京科学大 情報通信系 研究室紹介 (大岡山)
icttitech
0
4k
明日から使える!研究効率化ツール入門
matsui_528
13
7.4k
Featured
See All Featured
Art, The Web, and Tiny UX
lynnandtonic
304
22k
Efficient Content Optimization with Google Search Console & Apps Script
katarinadahlin
PRO
1
670
Writing Fast Ruby
sferik
630
63k
30 Presentation Tips
portentint
PRO
1
340
Design of three-dimensional binary manipulators for pick-and-place task avoiding obstacles (IECON2024)
konakalab
0
480
技術選定の審美眼(2025年版) / Understanding the Spiral of Technologies 2025 edition
twada
PRO
118
120k
Rails Girls Zürich Keynote
gr2m
96
14k
Building a Modern Day E-commerce SEO Strategy
aleyda
45
9.1k
A Soul's Torment
seathinner
6
3k
How to Align SEO within the Product Triangle To Get Buy-In & Support - #RIMC
aleyda
2
1.6k
Getting science done with accelerated Python computing platforms
jacobtomlinson
2
260
Leo the Paperboy
mayatellez
8
1.9k
Transcript
機械学習で作った ポケモン対戦bot で 遊ぼう! fufufukakaka 2026/02/21 リモポケ学会
• fufufukakaka, fu3ka3 (ふか) • 機械学習エンジニア ◦ 自然言語処理・推薦をはじめとして全般 • ポケモン
◦ SVは全シーズン遊び切りました ◦ チャンピオンズが出たらまず動画解析用のアノテーションを頑張らない と...と怯えている ◦ 過去に対戦動画解析・選出予測・プレゼンの自動要約などで発表 自己紹介
ポケモン対戦 (シングル・ランクバトル)
6体同士を見せあって、3体を選んで戦う
これまでの取り組み
本日の内容は以下の記事 +α という感じになっています https://zenn.dev/fufufukakaka/articles/0f9edbb85e5990#%E8%A9%95%E4%BE%A1%E5%AE%9F%E9%A8%93
そろそろ 実際の対戦に 機械学習を活かしたい...
まず先行研究を調べてみる
先行研究: foul-play pokemon-showdown でのみ 機能するイカサマ showdown のデータから 相手の技構成を仮定して あり得る世界をできるだけ シミュレートし良い手を選ぶ
(MonteCalro-Tree-Search) https://github.com/pmariglia/foul-play
先行研究: LLM系 大規模言語モデルを使うのが最近の流行 • PokéLLMon ◦ GPT-4 などの LLM に対戦ログを与えたうえで次の行動を
提案させる手法を提案 • PokeChamp ◦ PokéLLMon を発展させた LLM + ミニマックス探索エージェント • Metamon ◦ Showdown の膨大な人間対戦ログから オフライン RL で エージェントを学習
先行研究に感謝 ...🙏
先行研究の問題点 1. 選出が全く考慮されていないこと (showdownのbotは基本的にsmogonフォーマットなのでシングル66) しかし公式ルールは 6-3 なので大きな乖離が発生している
2. Showdown を用いていること • そもそも実対戦環境とはかなり乖離している(気がする) ◦ ダブル(VGC)はまだしも、シングルは構築を組んでいる 途中の練習場みたいな扱い ◦ なので、そこから得られる対戦ログは
あまり良質ではないのでは?という仮説 • 権利的にもできるだけ距離を取りたい 先行研究の問題点
3. 不完全情報の扱い方 • 結構モデルに全部ぽんと渡してうまくいく、みたいな主張が多い • でも、ポケモン対戦って「相手の持ち物はなんだろう」 「努力値はなんだろう」という仮説を置いて、観測された情報でそれを更新 して勝ち筋を見定めるのが本質なんじゃないか? と思っている •
プレイヤーの直感に近い手法も試したい 先行研究の問題点
新モデル; 選出を提案するモデル + 不完全情報を考慮した行動モデル
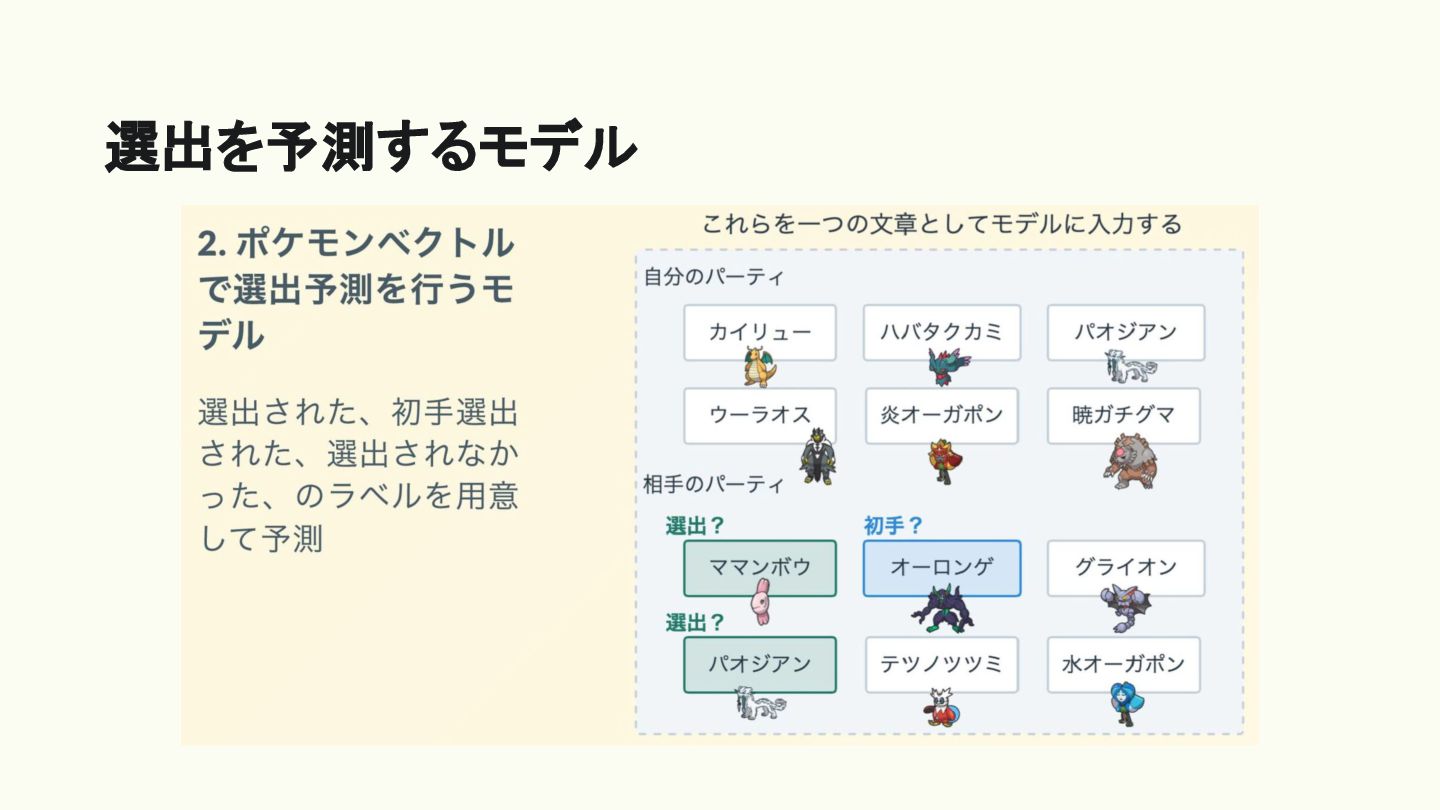
選出を予測するモデル (自分の)過去研究を 使います
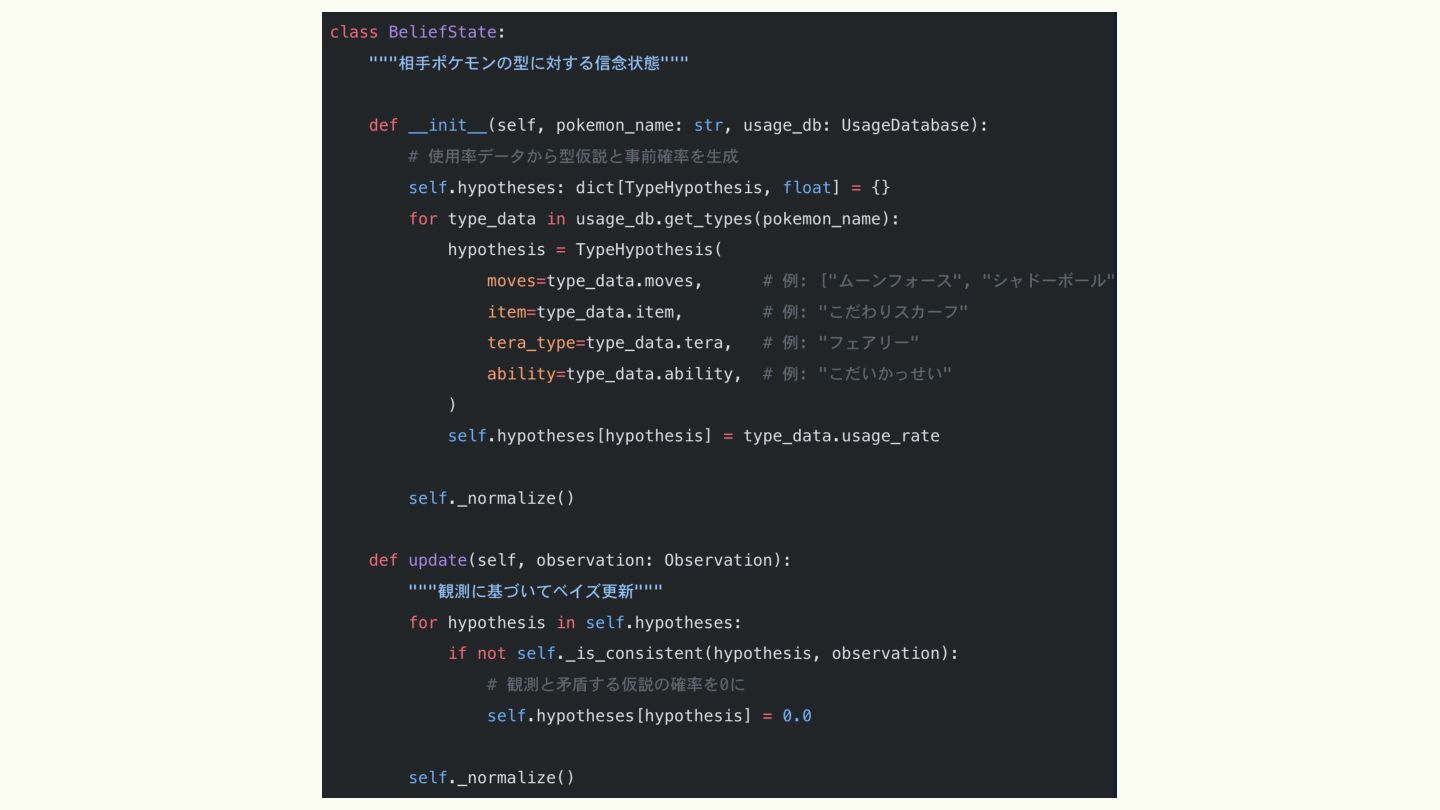
選出を予測するモデル • バトルデータベースにて公開されている上位構築パーティを用いる • Masked Language Model でポケモンを単語とみなした BERT を
学習 ◦ 構築のうち1匹が欠けているとして、この一匹を推定させる ◦ これによって「カイリューってこういう意味を持ってるかも」を学習して もらう
選出を予測するモデル
不完全情報を考慮した行動モデル
不完全情報を考慮した行動モデル https://ai.meta.com/blog/rebel-a-general-game-playing-ai-bot-that-excels-at-poker-and-more/
不完全情報を考慮した行動モデル • meta が 2020年に提案した ReBel を用いる • これはポーカーの対戦アルゴリズムとして提案されたもの •
公開されている情報と「相手がこのカードを持っているのでは?」 という 仮定から確率分布を推定 • 仮定に従い、各あり得る世界線での最適手を探索した後 確率に基づいて価値を重み付けして最終的な最適手を選ぶ びっくりテラスには どうしても 負けやすい...
今回仮定する情報 情報 説明 観測による更新 相手の選出したポケモン 3体; 最初の予測情報からスタートする 交代などで判明
技構成 4つの技 技使用時に判明 持ち物 きあいのタスキ、こだわりスカーフ等 持ち物発動時に判明 テラスタイプ テラスタル時のタイプ テラスタル使用時に判明 特性 いかく、ばけのかわ等 特性発動時に判明 努力値配分 AS振り、HB振り等 技使用時に推定
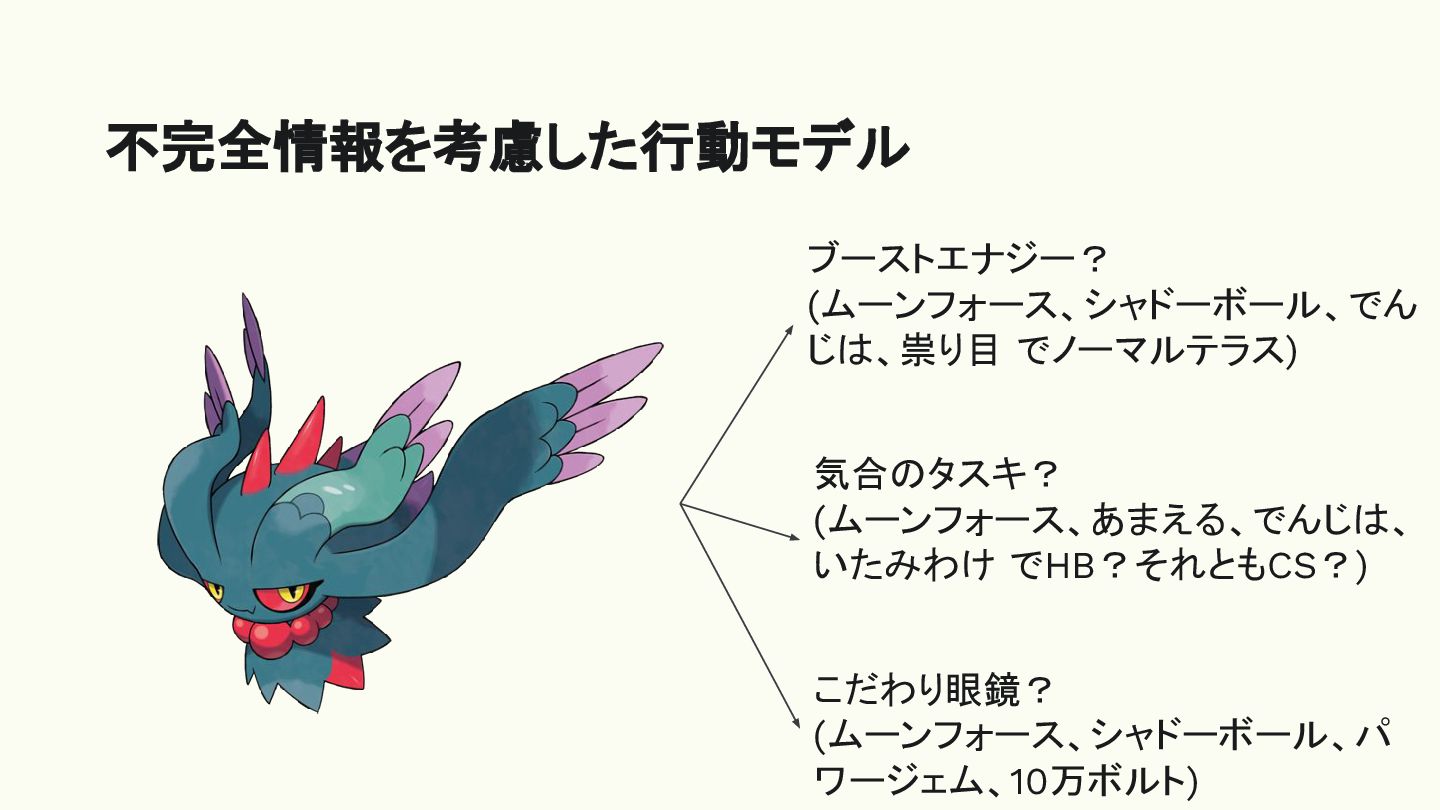
不完全情報を考慮した行動モデル ブーストエナジー? (ムーンフォース、シャドーボール、でん じは、祟り目 でノーマルテラス) 気合のタスキ? (ムーンフォース、あまえる、でんじは、 いたみわけ でHB?それともCS?) こだわり眼鏡?
(ムーンフォース、シャドーボール、パ ワージェム、10万ボルト)
None
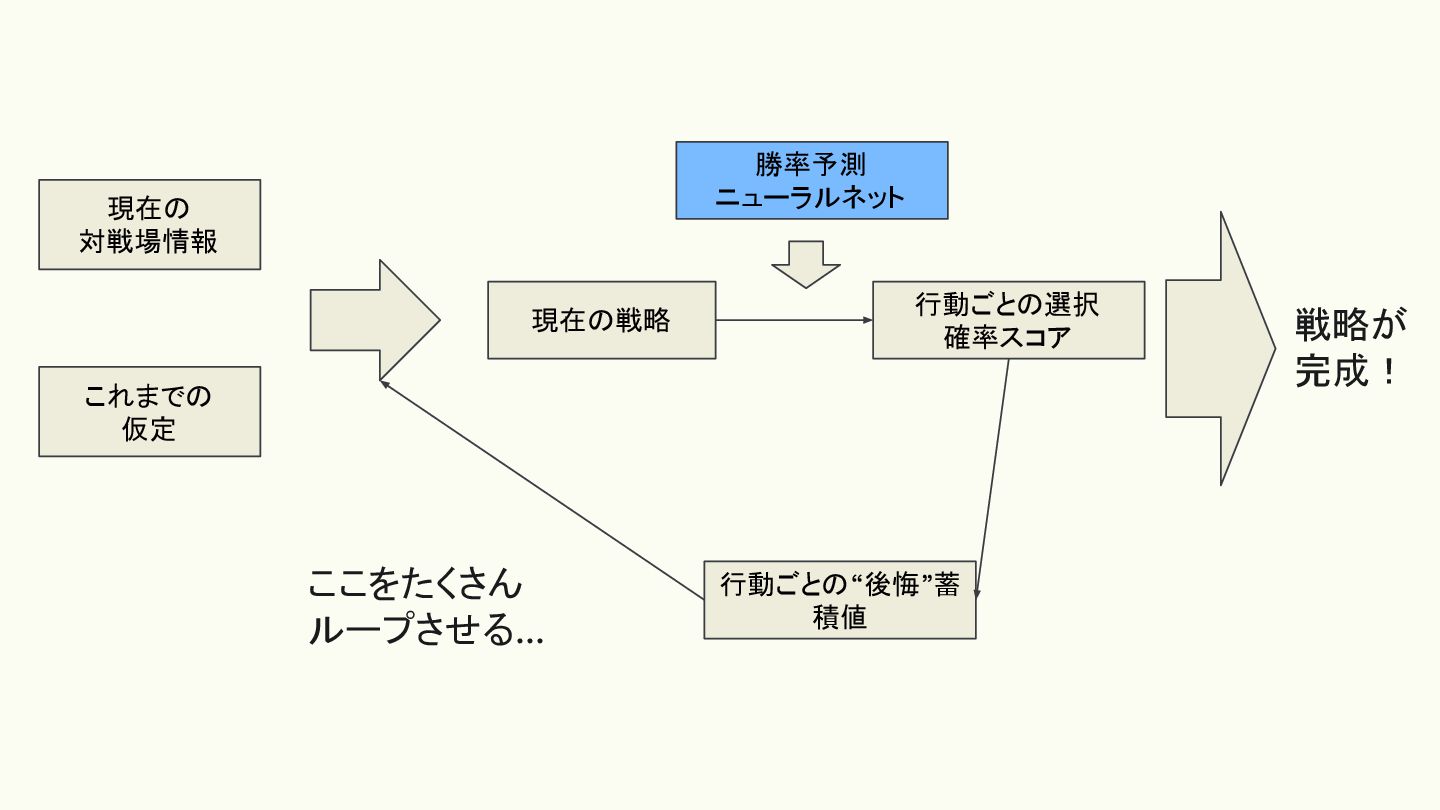
CFRアルゴリズムによる ”後悔”最小化アルゴリズム • ReBeL では CFR というアルゴリズムを使ってナッシュ均衡に近い戦略を 選ぶ • 「相手がどの型であっても、平均的に最も良い結果が得られる
行動」(安定行動)を選ぶイメージ • 各行動について「もしこの行動を選んでいたら、どれだけ良かった(悪かっ た)か」を計算→一番、後悔しない行動を選ぶ • 「後悔を最小化する」というアプローチを繰り返すと、理論的にはナッシュ 均衡(お互いに最善を尽くしている状態)に収束することが証明されていま す
現在の 対戦場情報 これまでの 仮定 勝率予測 ニューラルネット 行動ごとの“後悔”蓄 積値 行動ごとの選択 確率スコア
現在の戦略 ここをたくさん ループさせる... 戦略が 完成!
モデルを学習させてみよう!
モデルの学習 • 先行事例として、SV対戦を Python でシミュレートするコードを作っている 方がいたので、そちらのコードを拝借(了解を得ております) https://hfps4469.hatenablog.com/entry/2024/09/29/200912
モデルの学習 • ReBel で動くボットを2体用意して自己対戦させる ◦ このとき、レギュレーションJ の上位構築の中から 毎試合ランダムに一つ選んで対戦してもらう ◦ ReBel
の信念は最初、レギュJ最後のポケモンHOME使用率 データから始める
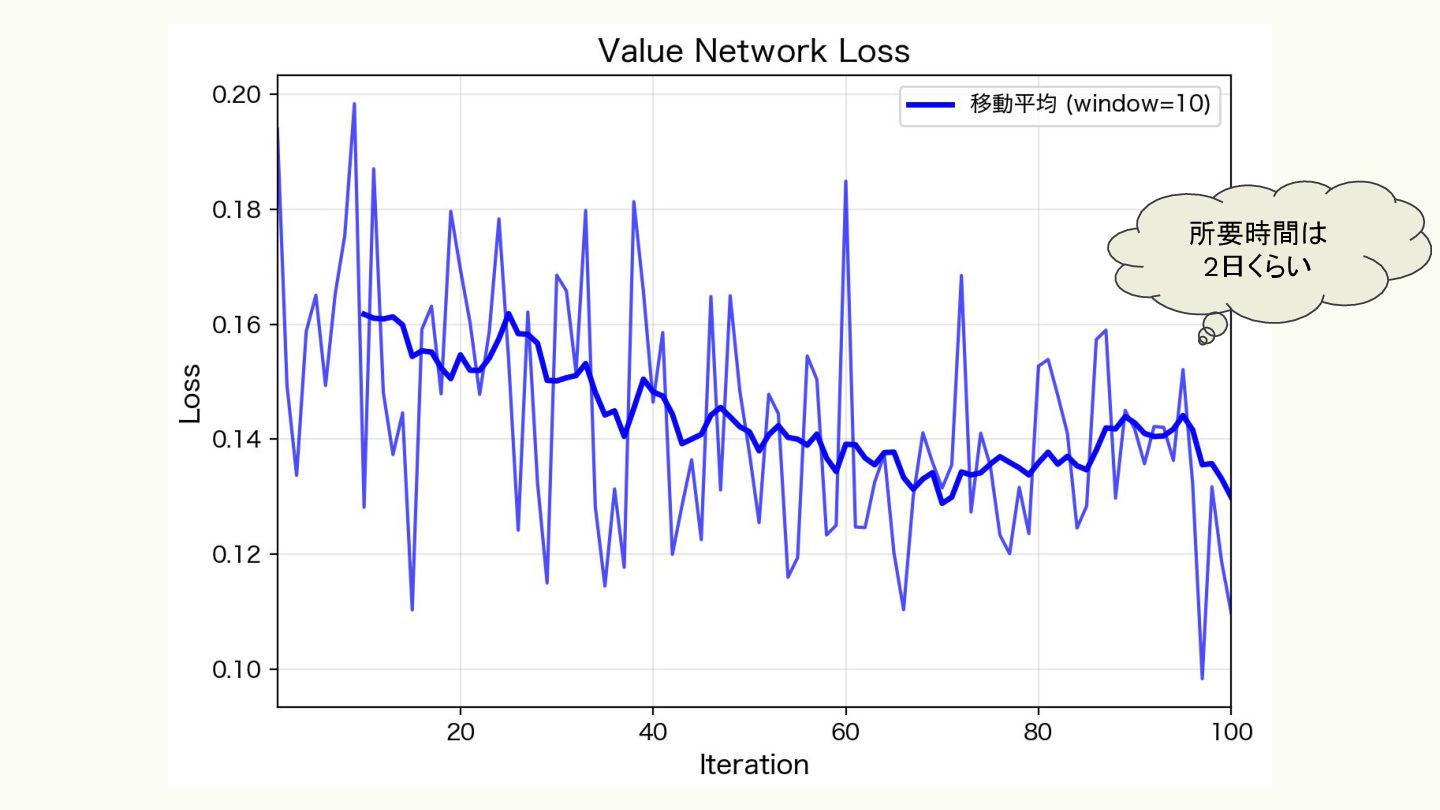
• Value Network(勝率予測) ◦ 盤面の状態から「この状況での勝率」を予測するネットワーク ◦ CFR の _evaluate_action で使用され、各行動の価値を評価
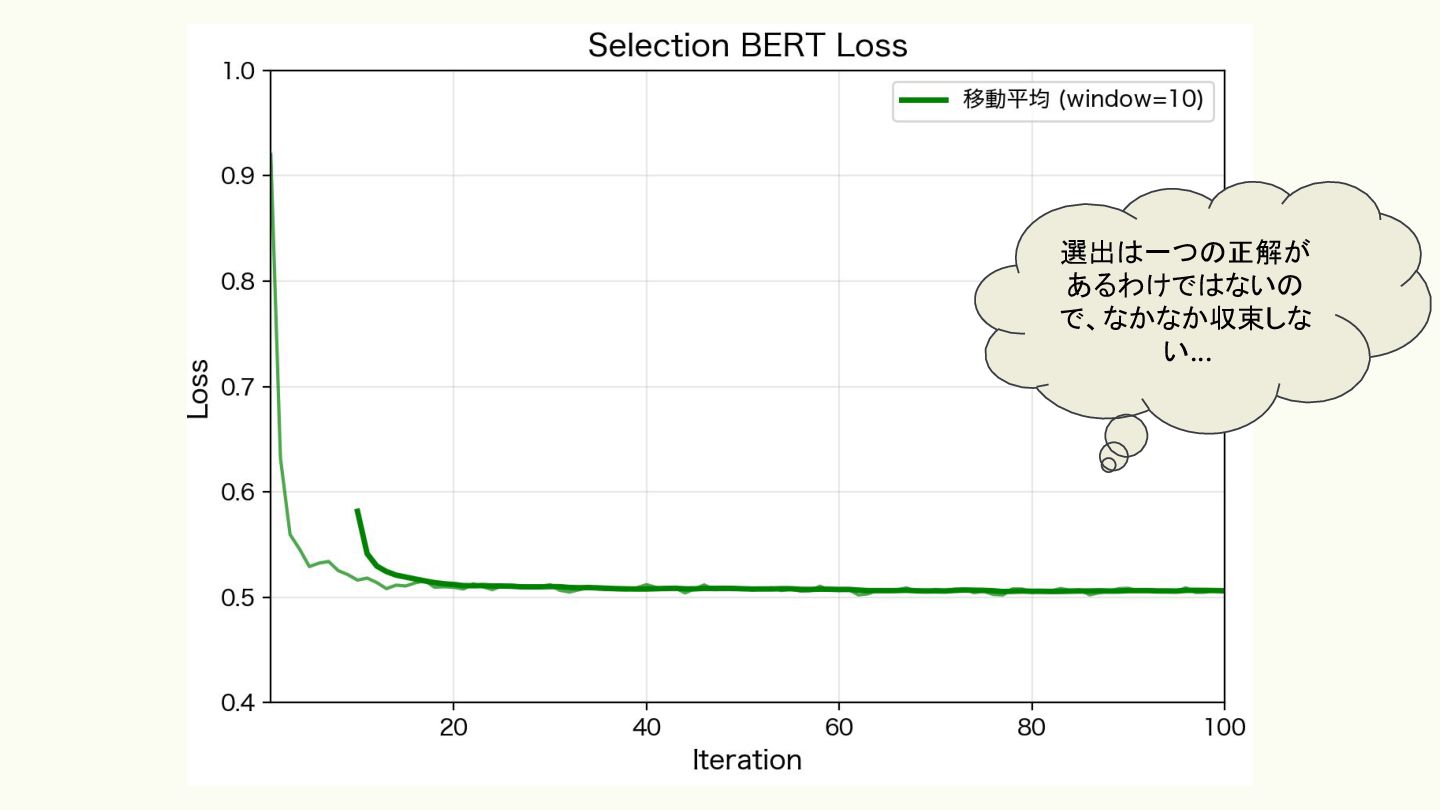
• Selection BERT(選出予測) ◦ 前述の選出提案モデル ◦ Self-Play の結果から「勝った試合での選出」を学習することで、より 強い選出ができるようになる(はず) 学習させるネットワーク
所要時間は 2日くらい
選出は一つの正解が あるわけではないの で、なかなか収束しな い...
どれくらいの強さになった?
ベースラインには全て勝ち越し • Selection BERTの有無で勝率に差が出た ◦ ランダム行動時: 100% → 90% ◦
ランダムは行動で巻き返せないので、選出の影響がでかい ▪ Selection BERT はそれなりの影響力があったといえる • CFR相手はそれなりの行動をしてくるので選出の影響は少なかった • (50回しか対戦していないので、ランダム性による差かも)
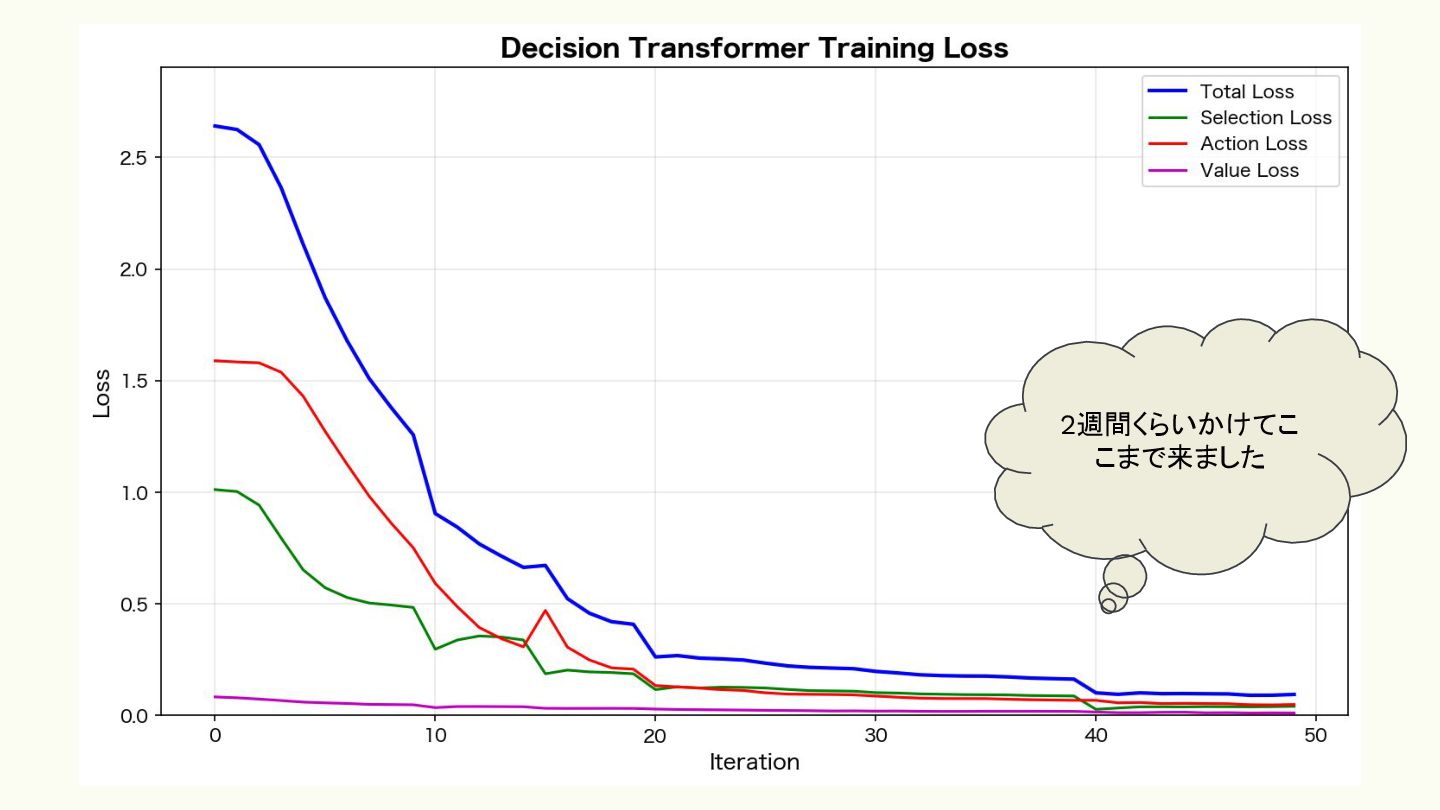
機械学習ベースの比較対象も用意してみた! • Decision Transformer • 強化学習を「系列予測問題」として再定義したアーキテクチャ • 入力系列: `[目標リターン₁, 状態₁,
行動₁, 目標リターン₂, 状態₂, 行動₂, ...]` ◦ 推論時は「勝ちたい(RTG=1.0)」を条件として与え、その目標を達成す るような行動を自己回帰的に生成 • MCTS を組み合わせて数手先まで読んで、一番良い行動を提案する
2週間くらいかけてこ こまで来ました
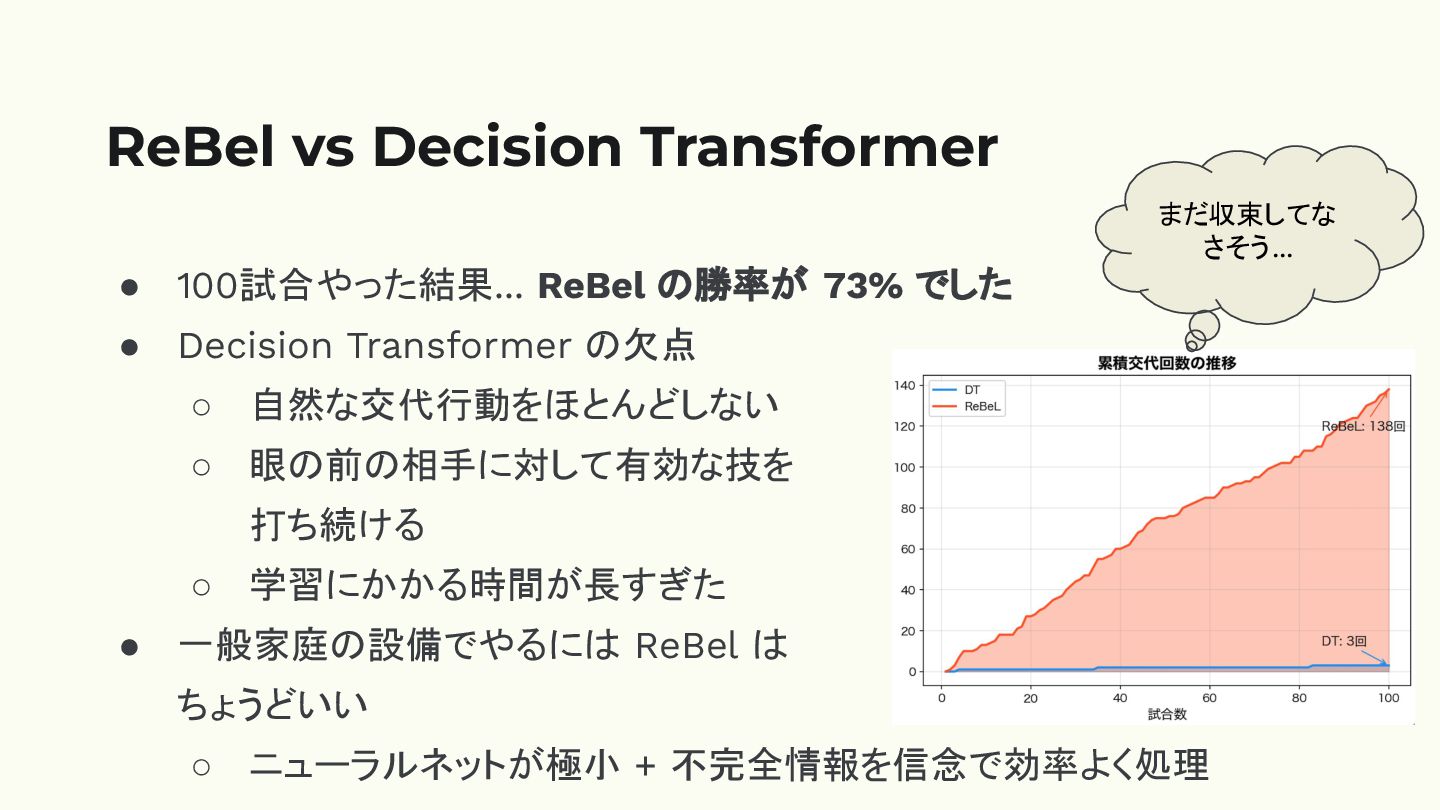
ReBel vs Decision Transformer • 100試合やった結果... ReBel の勝率が 73% でした
• Decision Transformer の欠点 ◦ 自然な交代行動をほとんどしない ◦ 眼の前の相手に対して有効な技を 打ち続ける ◦ 学習にかかる時間が長すぎた • 一般家庭の設備でやるには ReBel は ちょうどいい ◦ ニューラルネットが極小 + 不完全情報を信念で効率よく処理 まだ収束してな さそう...
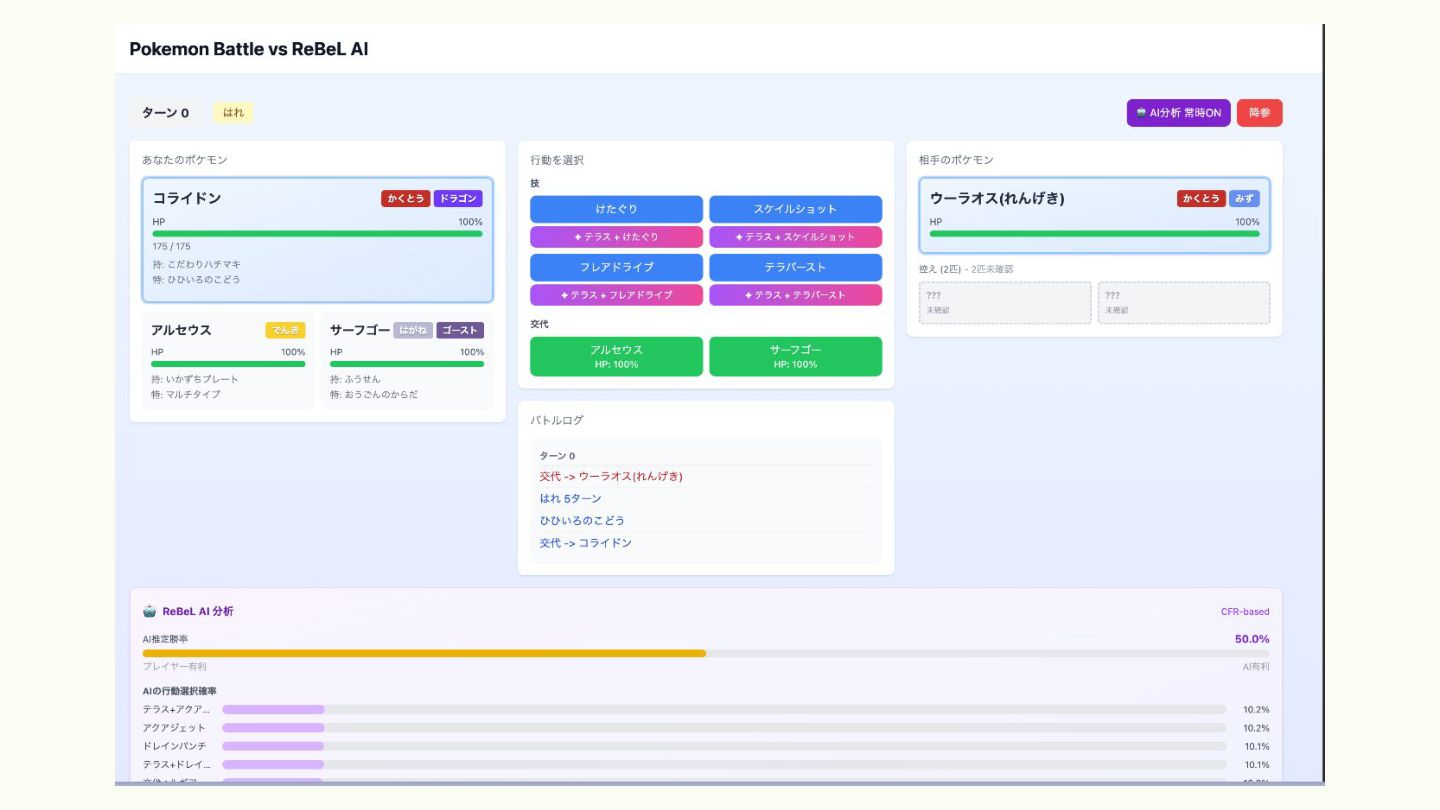
ReBel モデルと対戦してみた
None
None
None
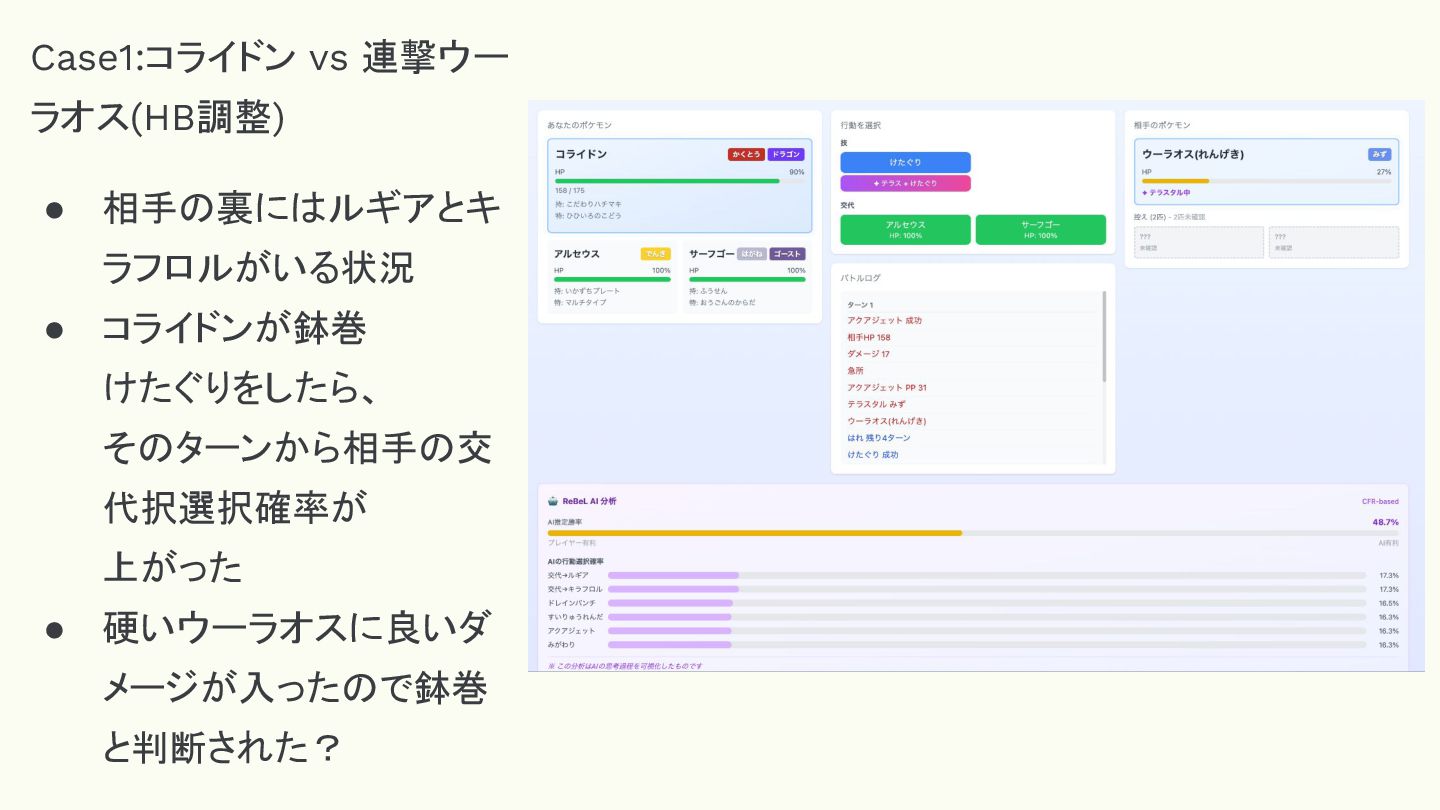
Case1:コライドン vs 連撃ウー ラオス(HB調整) • 相手の裏にはルギアとキ ラフロルがいる状況 • コライドンが鉢巻 けたぐりをしたら、
そのターンから相手の交 代択選択確率が 上がった • 硬いウーラオスに良いダ メージが入ったので鉢巻 と判断された?
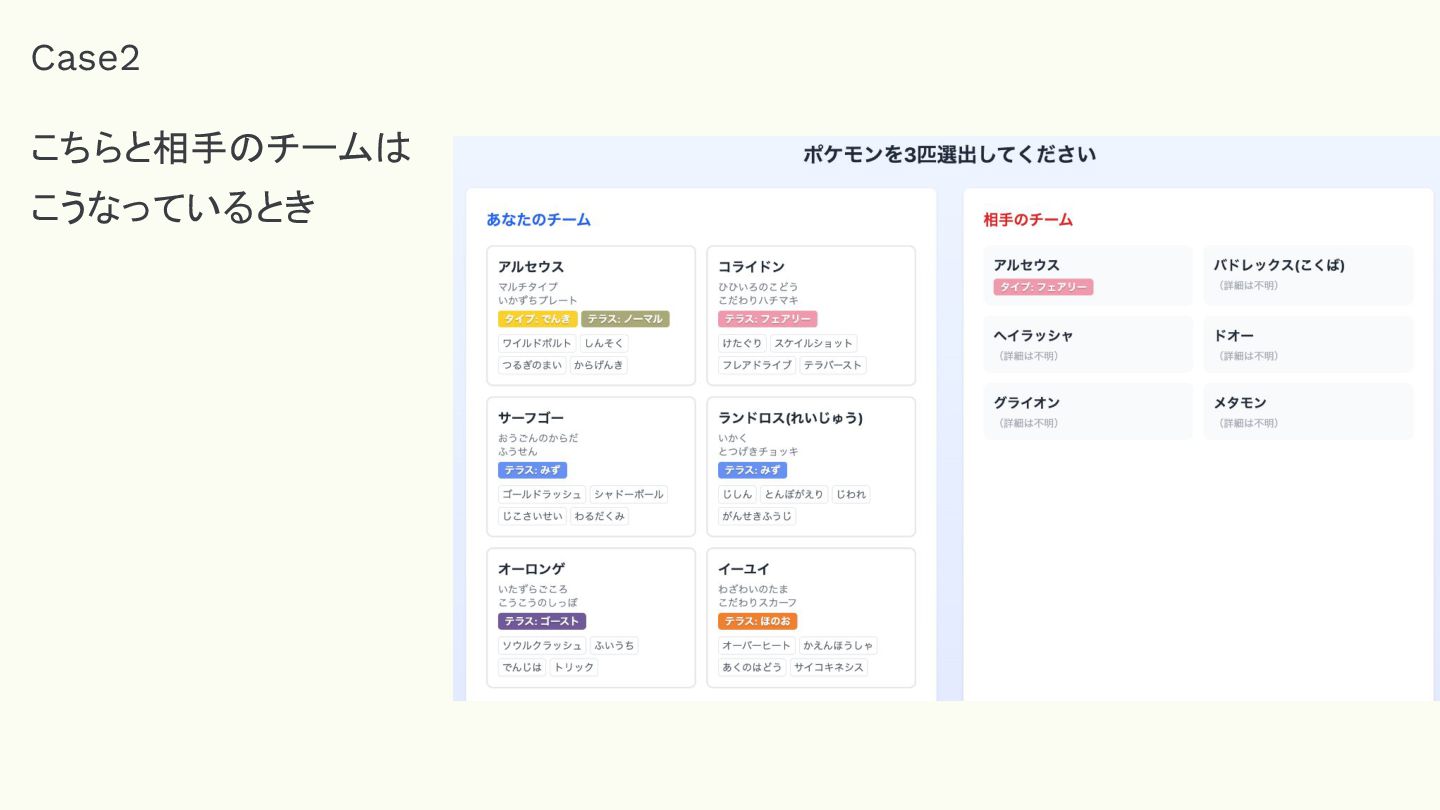
Case2 こちらと相手のチームは こうなっているとき
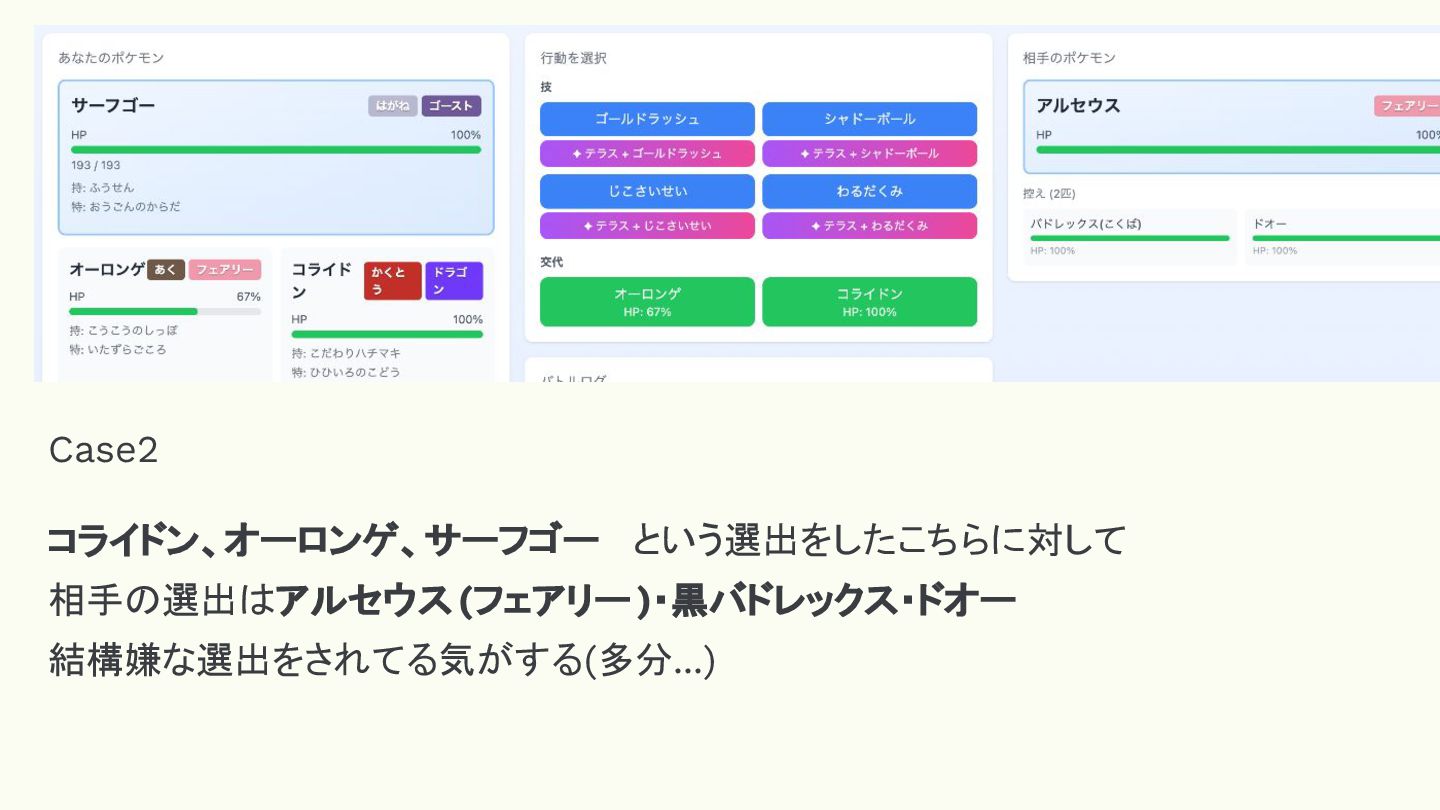
Case2 コライドン、オーロンゲ、サーフゴー という選出をしたこちらに対して 相手の選出はアルセウス (フェアリー )・黒バドレックス・ドオー 結構嫌な選出をされてる気がする(多分...)
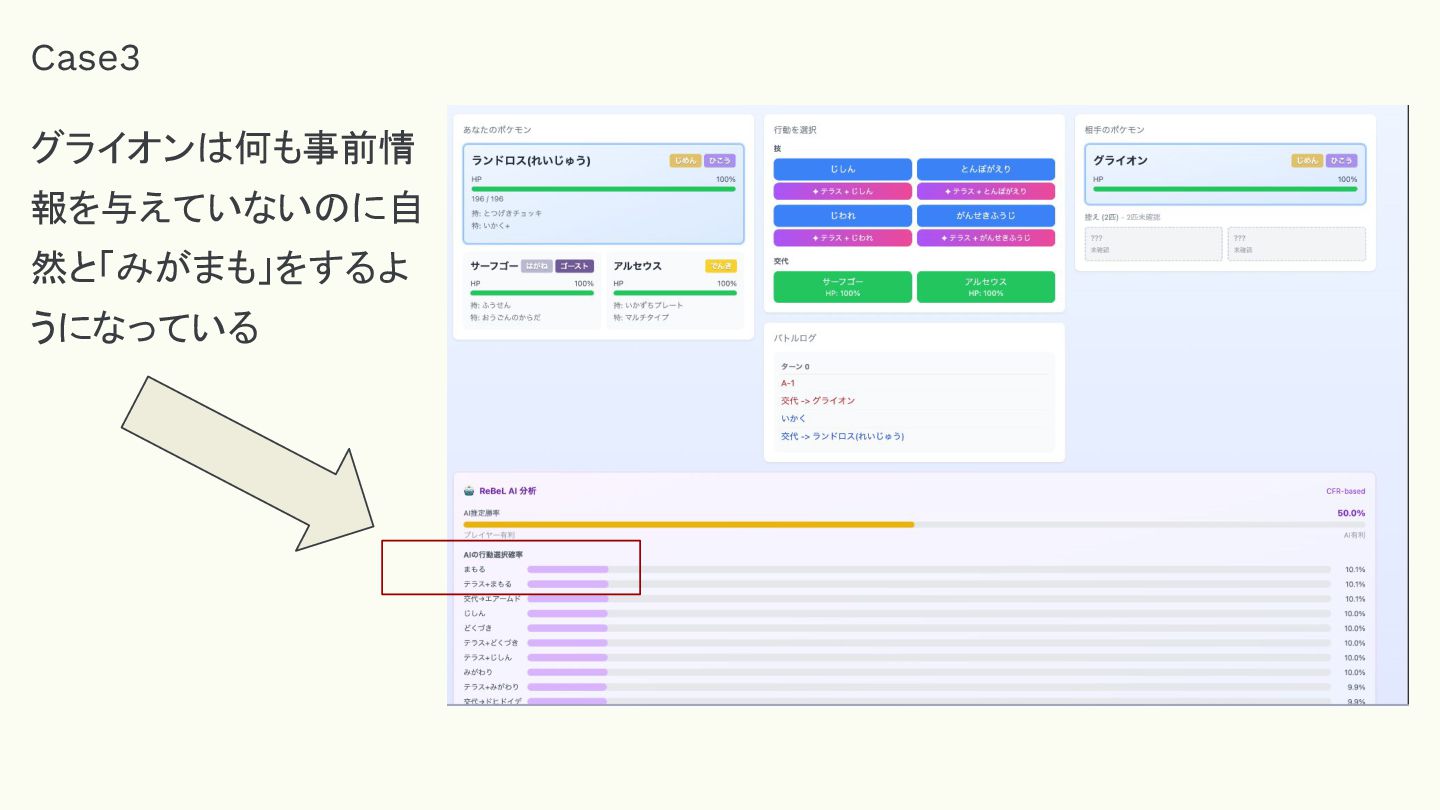
Case3 グライオンは何も事前情 報を与えていないのに自 然と「みがまも」をするよ うになっている
• ReBel による対戦ボットを作った話を紹介しました ◦ 不完全情報を「信念」として扱い、ベイズ更新で絞り込んでいく ◦ CFR でナッシュ均衡に近い戦略を計算する ◦ BERT
による選出予測も組み合わせた • そこそこ強いボットができた ◦ どでかいニューラルネットよりも上手く機能する • 今後: 人間と比べてどれくらい強いのか、という実験もしたい まとめ
こちらの記事もぜひ! https://zenn.dev/fufufukakaka/articles/0f9edbb85e5990#%E8%A9%95%E4%BE%A1%E5%AE%9F%E9%A8%93
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}