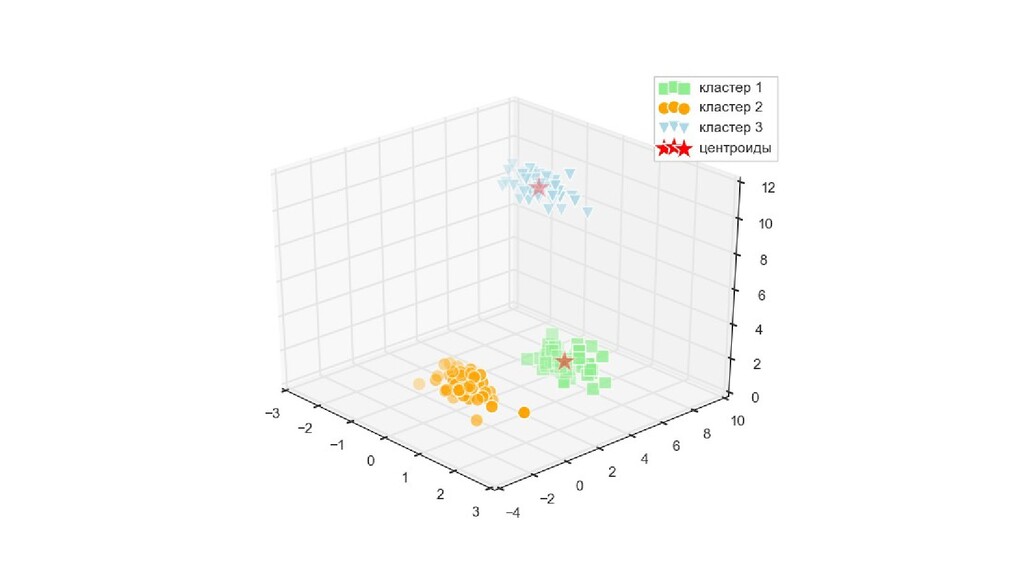
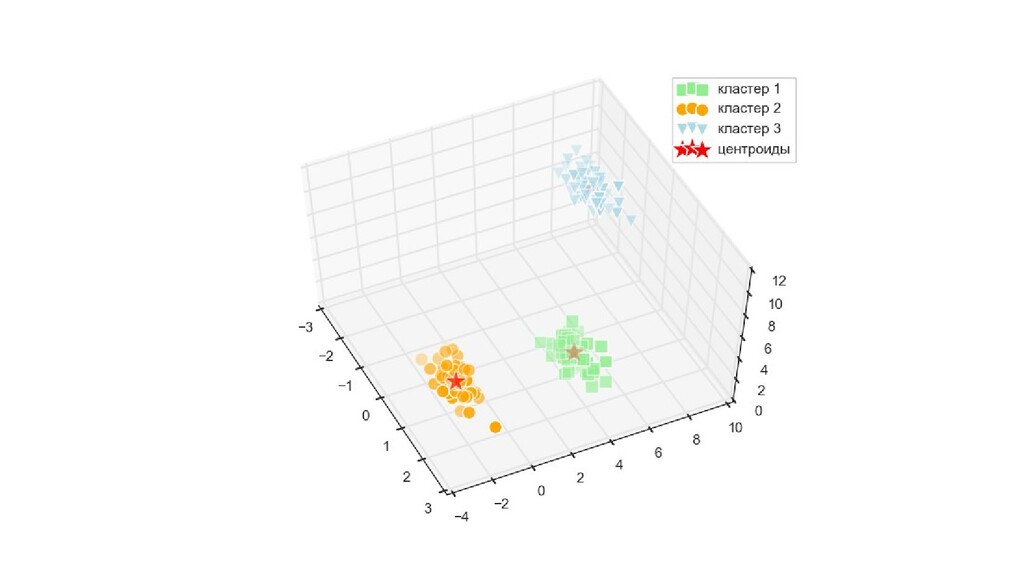
= fig.add_subplot(111, projection='3d') ax.scatter(X[y_km == 0, 0], X[y_km == 0, 1], X[y_km == 0, 2], s=100, c='lightgreen', marker='s', label=u'кластер 1') ax.scatter(X[y_km == 1, 0], X[y_km == 1, 1], X[y_km == 1, 2], s=100, c='orange', marker='o', label=u'кластер 2') ax.scatter(X[y_km == 2, 0], X[y_km == 2, 1], X[y_km == 2, 2], s=100, c='lightblue', marker='v', label=u'кластер 3') ax.scatter(km.cluster_centers_[:, 0], km.cluster_centers_[:, 1], km.cluster_centers_[:, 2], s=350, c='red', marker='*', label=u'центроиды') plt.legend() plt.show()
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
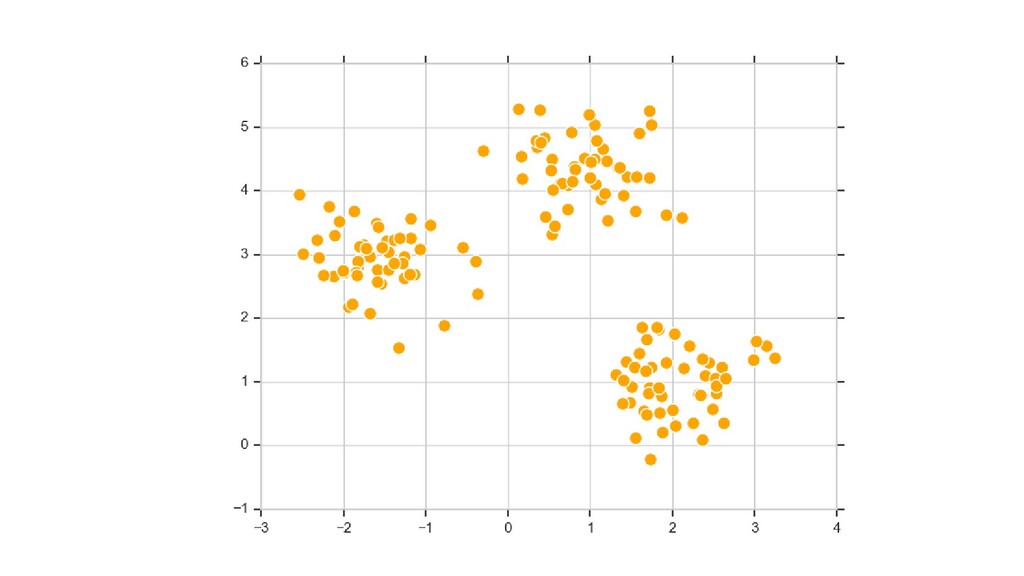{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![sklearn.cluster.KMeans plt.scatter(X[y_km == 0, 0], X[y_km == 0, 1], s=100,](https://files.speakerdeck.com/presentations/5848bcc420c24865b4c8e28832711e7a/slide_12.jpg){kind=link}
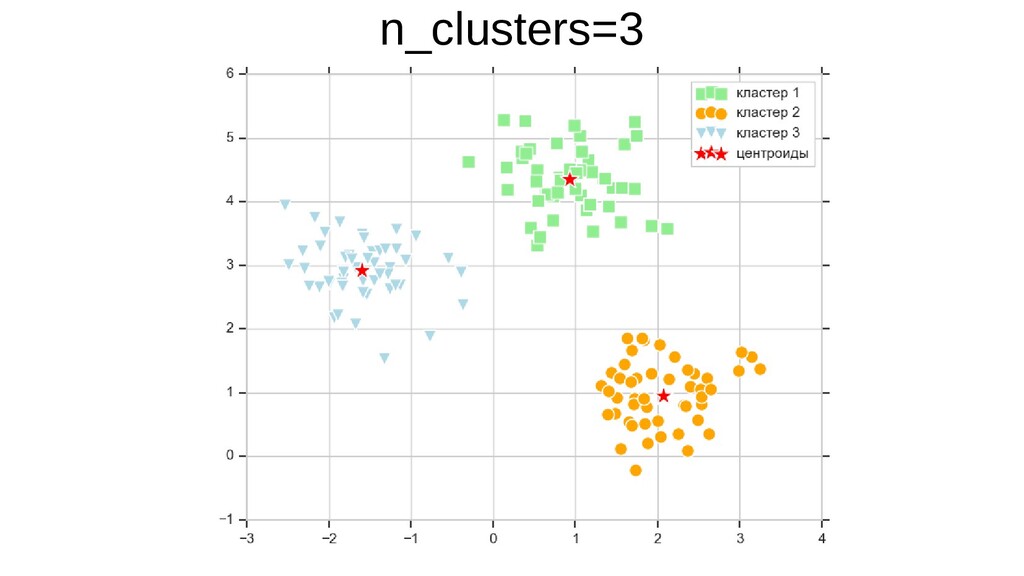{kind=link}
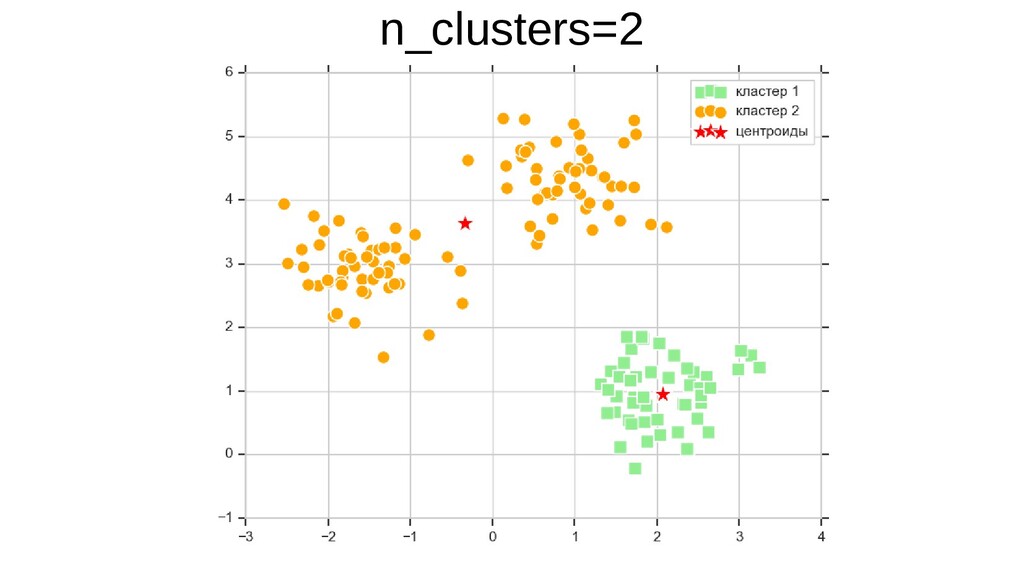{kind=link}
{kind=link}
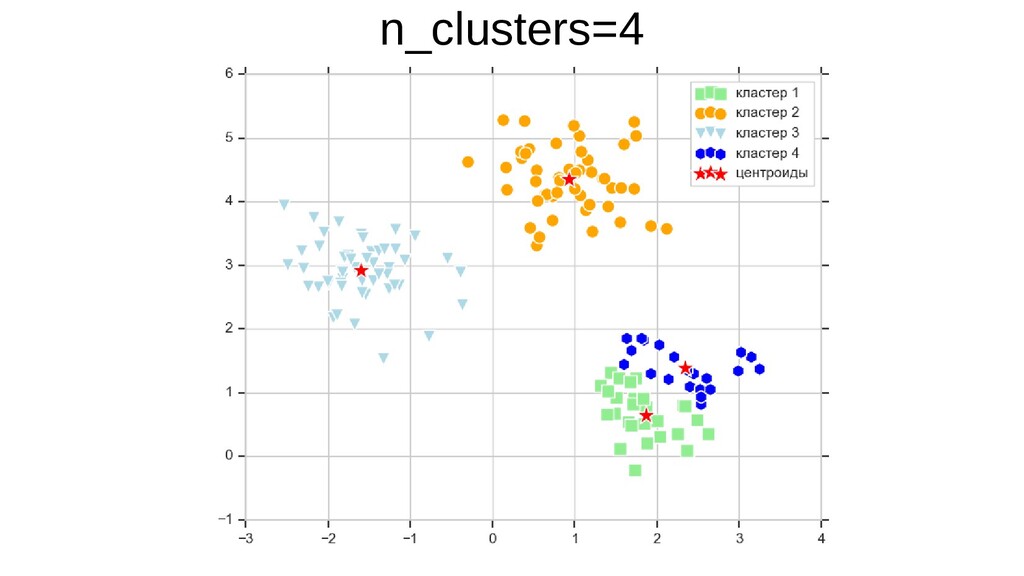{kind=link}
{kind=link}
{kind=link}
{kind=link}
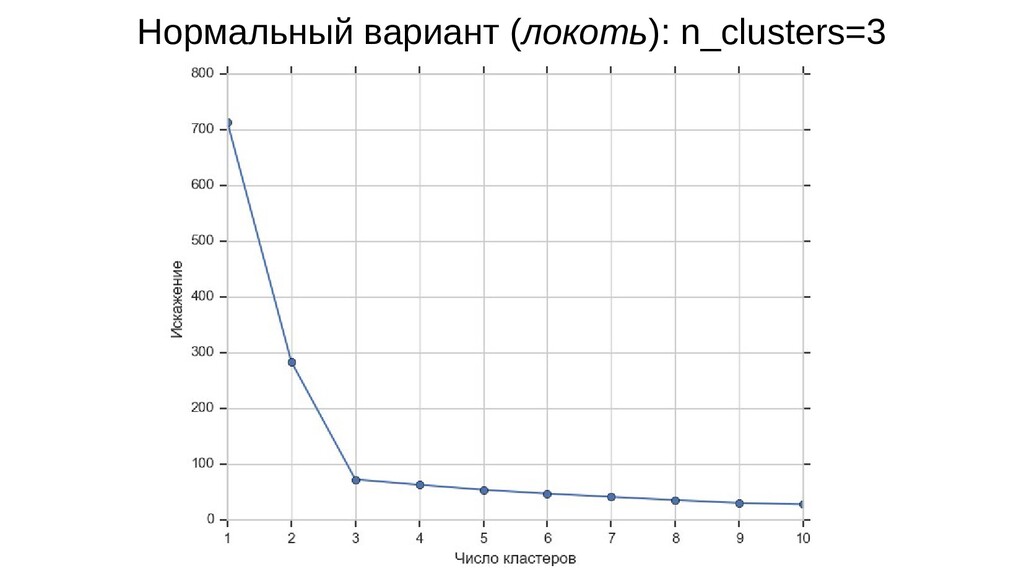
![График локтя from sklearn.cluster import KMeans distorts = [] #](https://files.speakerdeck.com/presentations/5848bcc420c24865b4c8e28832711e7a/slide_20.jpg){kind=link}
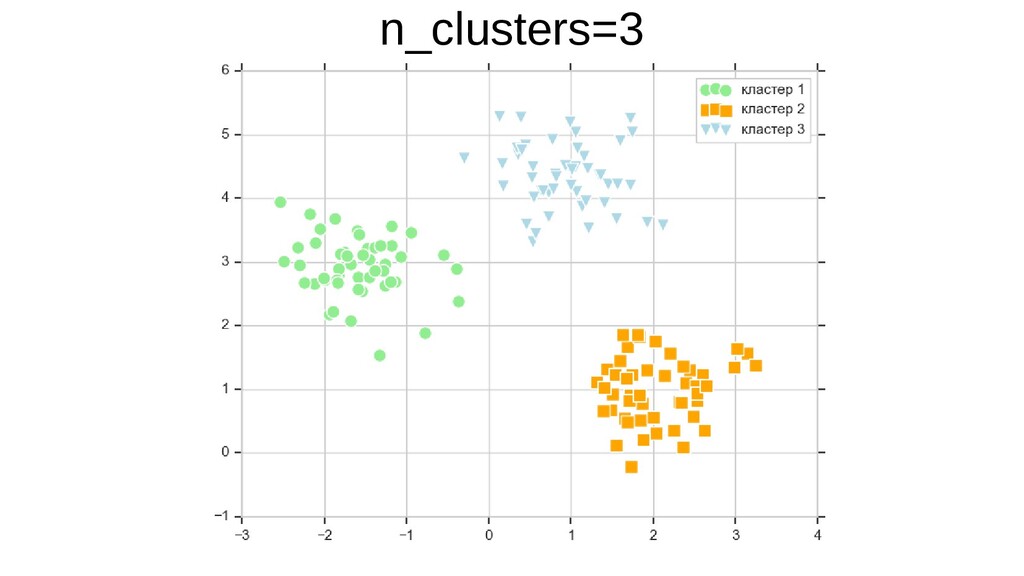
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![sklearn.cluster.AgglomerativeClustering plt.scatter(X[y_ac == 0, 0], X[y_ac == 0, 1], s=100,](https://files.speakerdeck.com/presentations/5848bcc420c24865b4c8e28832711e7a/slide_28.jpg){kind=link}
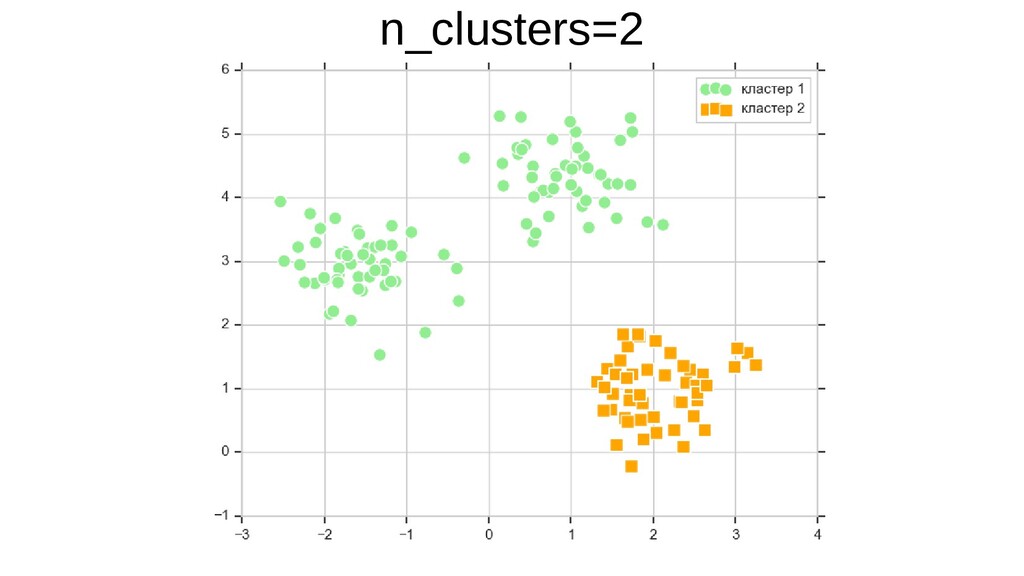
{kind=link}
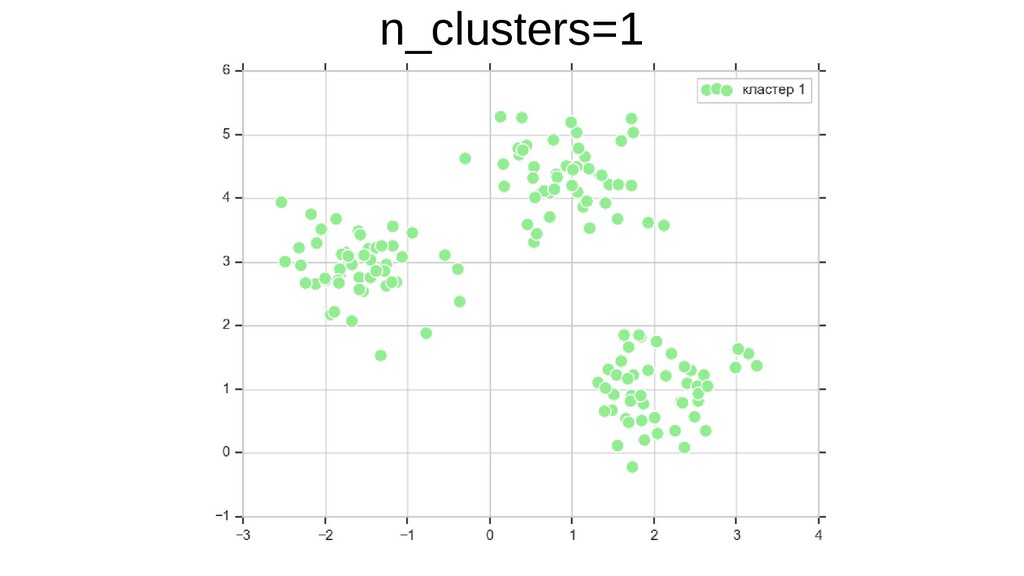
{kind=link}
{kind=link}
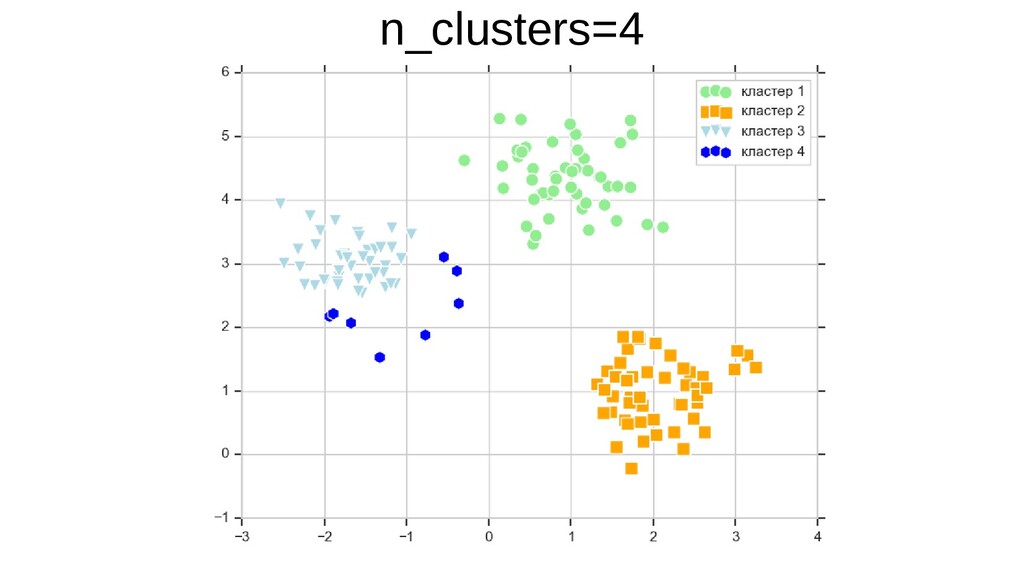{kind=link}
{kind=link}
{kind=link}
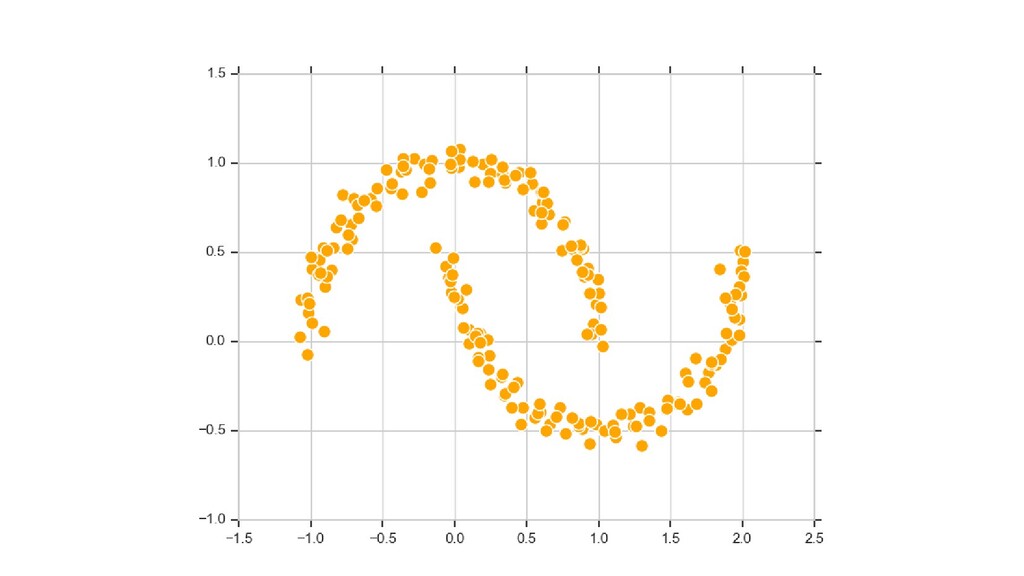{kind=link}
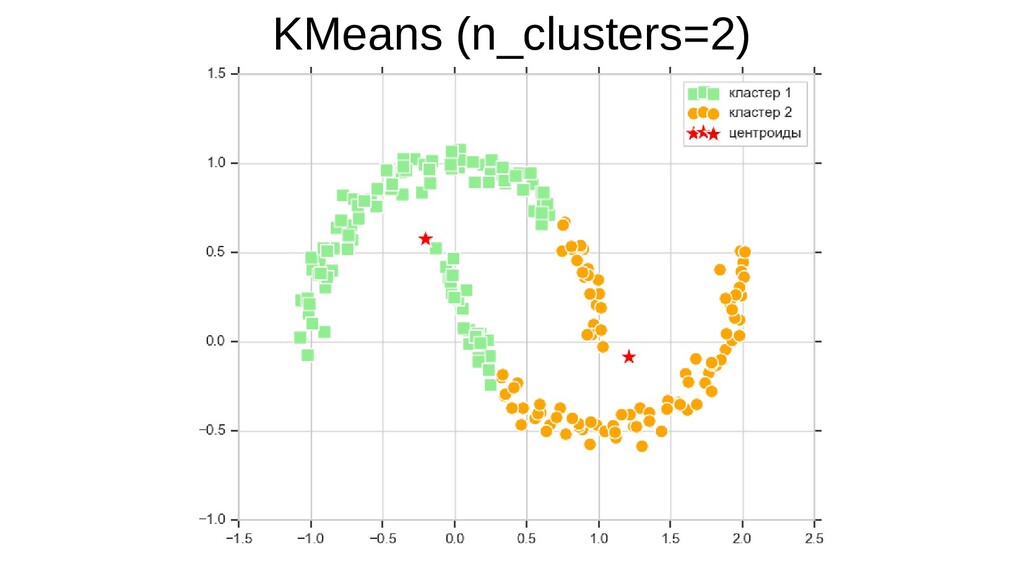{kind=link}
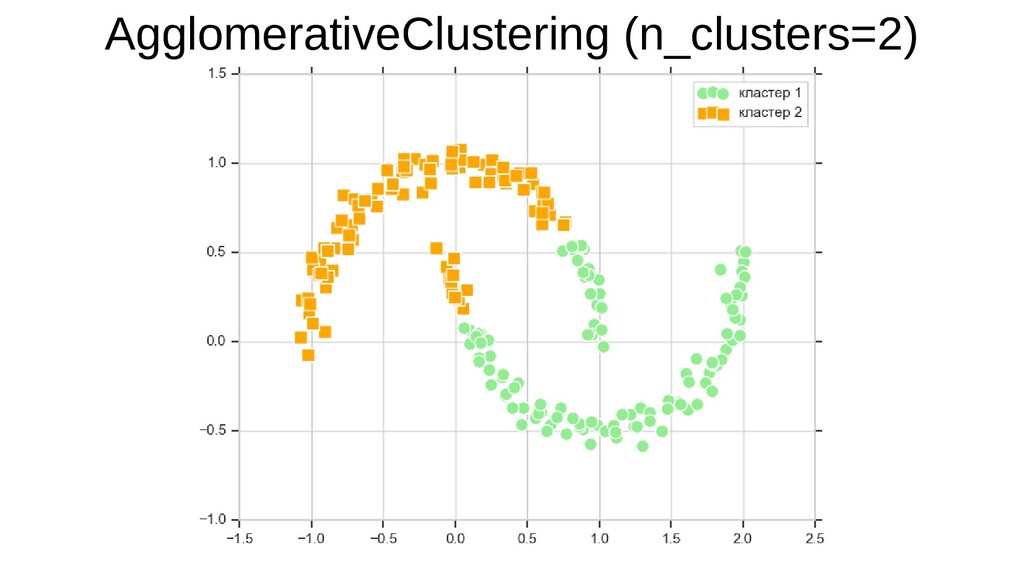{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
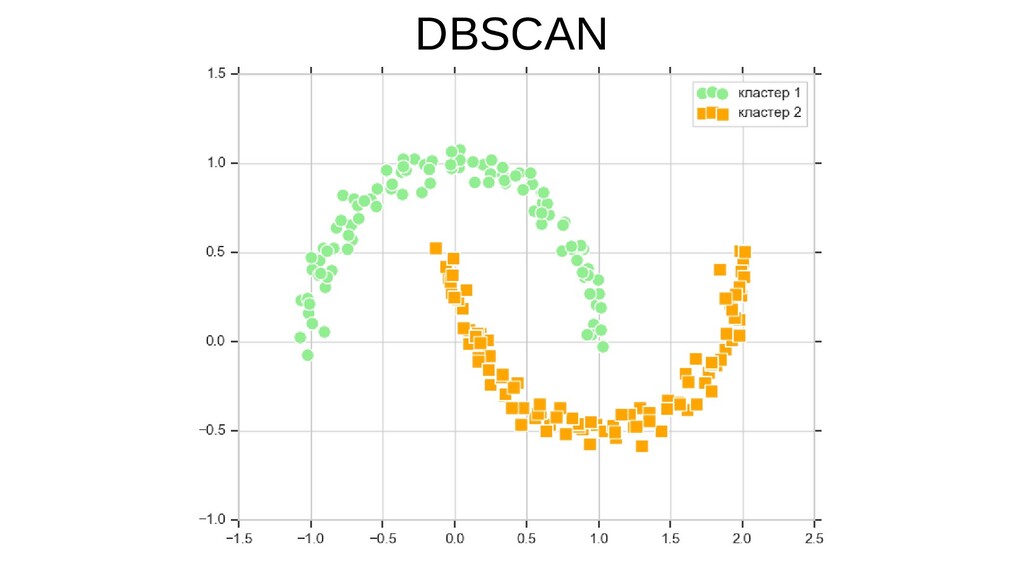
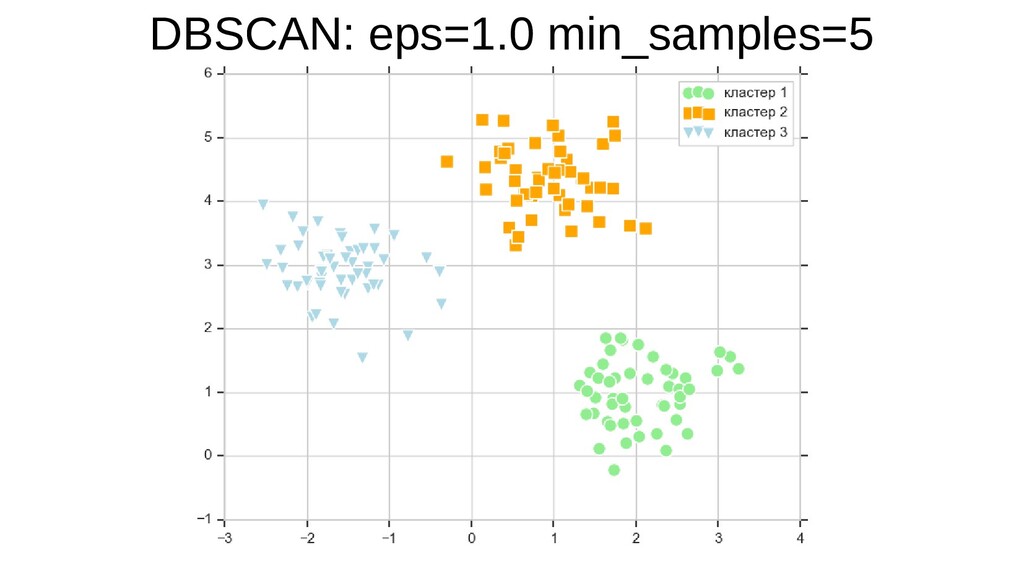
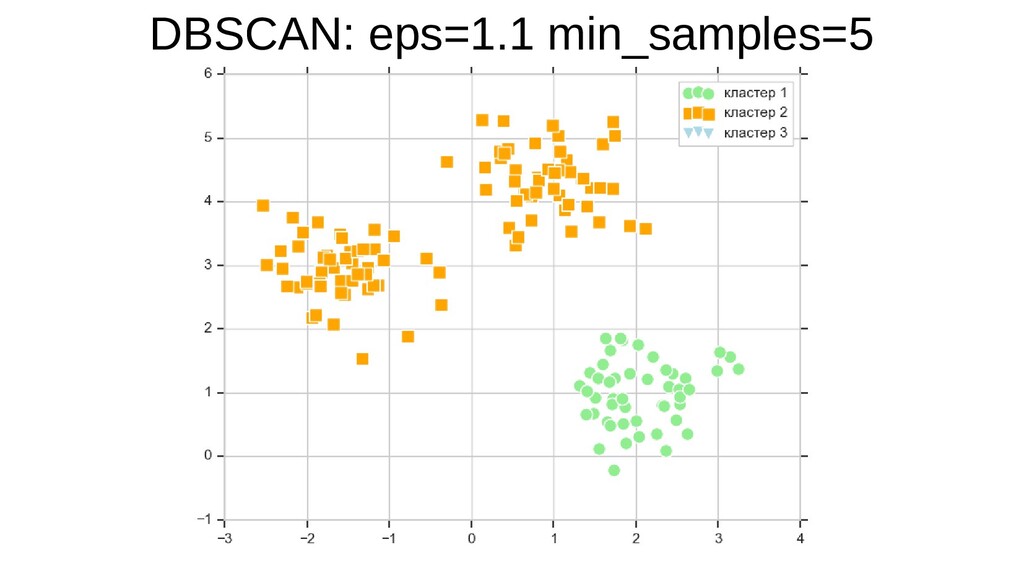
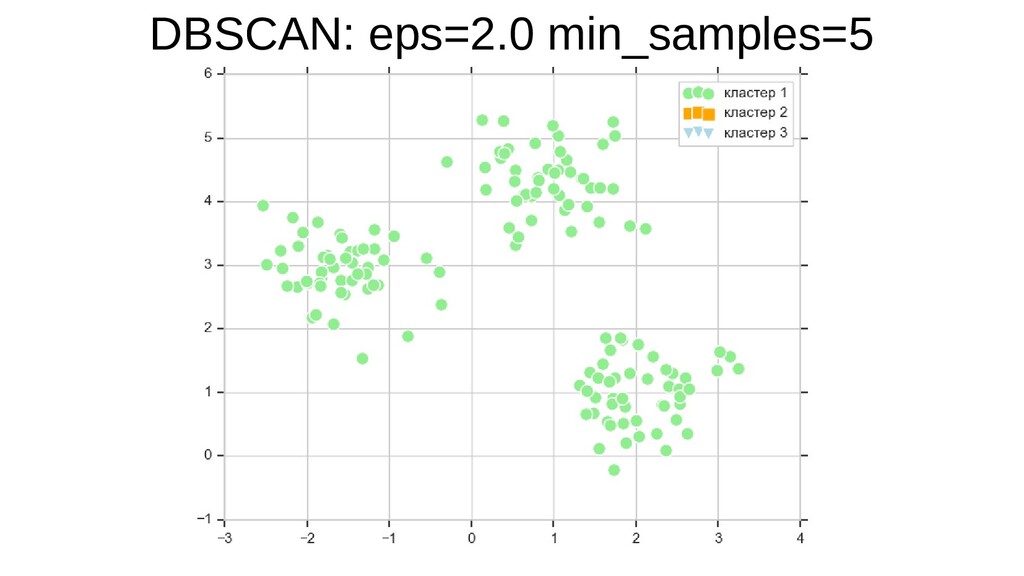
![sklearn.cluster.DBSCAN plt.scatter(X[y_db == 0, 0], X[y_db == 0, 1], s=100,](https://files.speakerdeck.com/presentations/5848bcc420c24865b4c8e28832711e7a/slide_43.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}