Обучение нейронной сети: обучение нейросети с библиотекой автоматического дифференцирования TensorFlow, нейросеть 3 нейрона, распознавание цифр MNIST
- Матчасть: производная и теория вероятностей - раньше; линейная алгебра, операции над матрицами - сейчас
- Библиотеки автоматического дифференцирования: Theano, TensorFlow, PyTorch и т.п.
- TensorFlow 1.4 vs 2.x
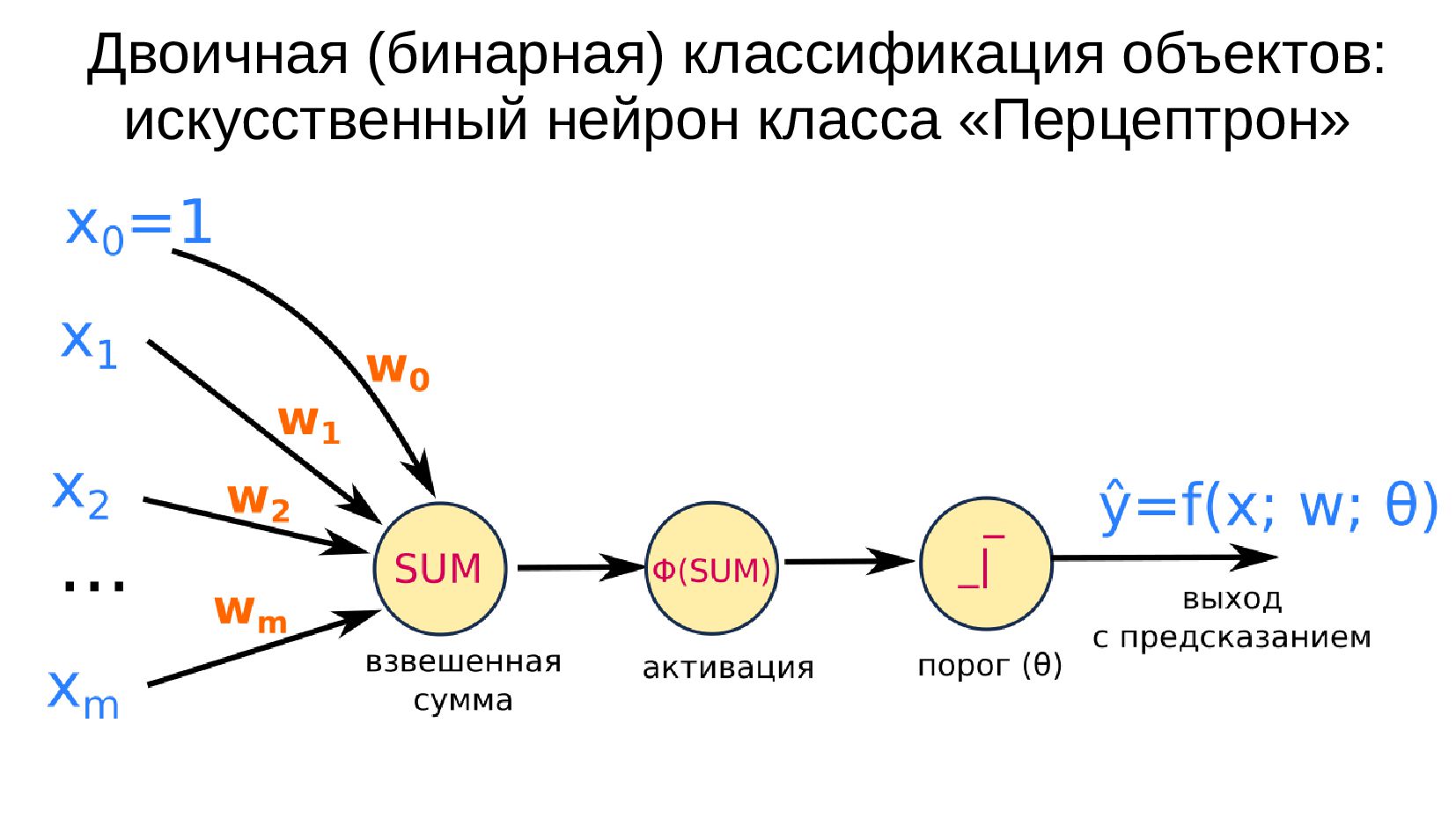
- Реализуем рассмотренные ранее модели на TensorFlow: линейный нейрон, нейрон с активацией-сигмоидой, нейросеть из 3-х элементов
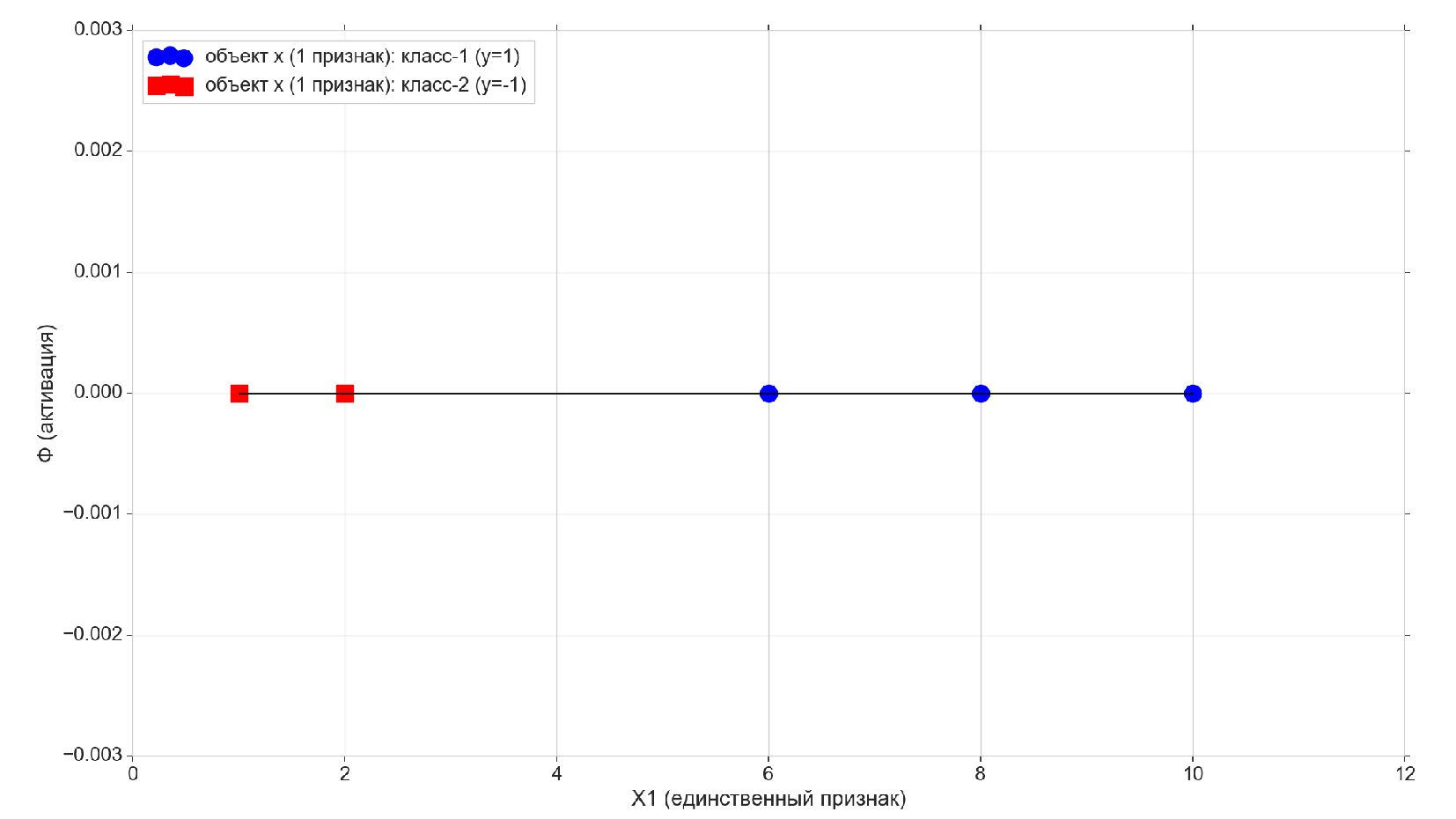
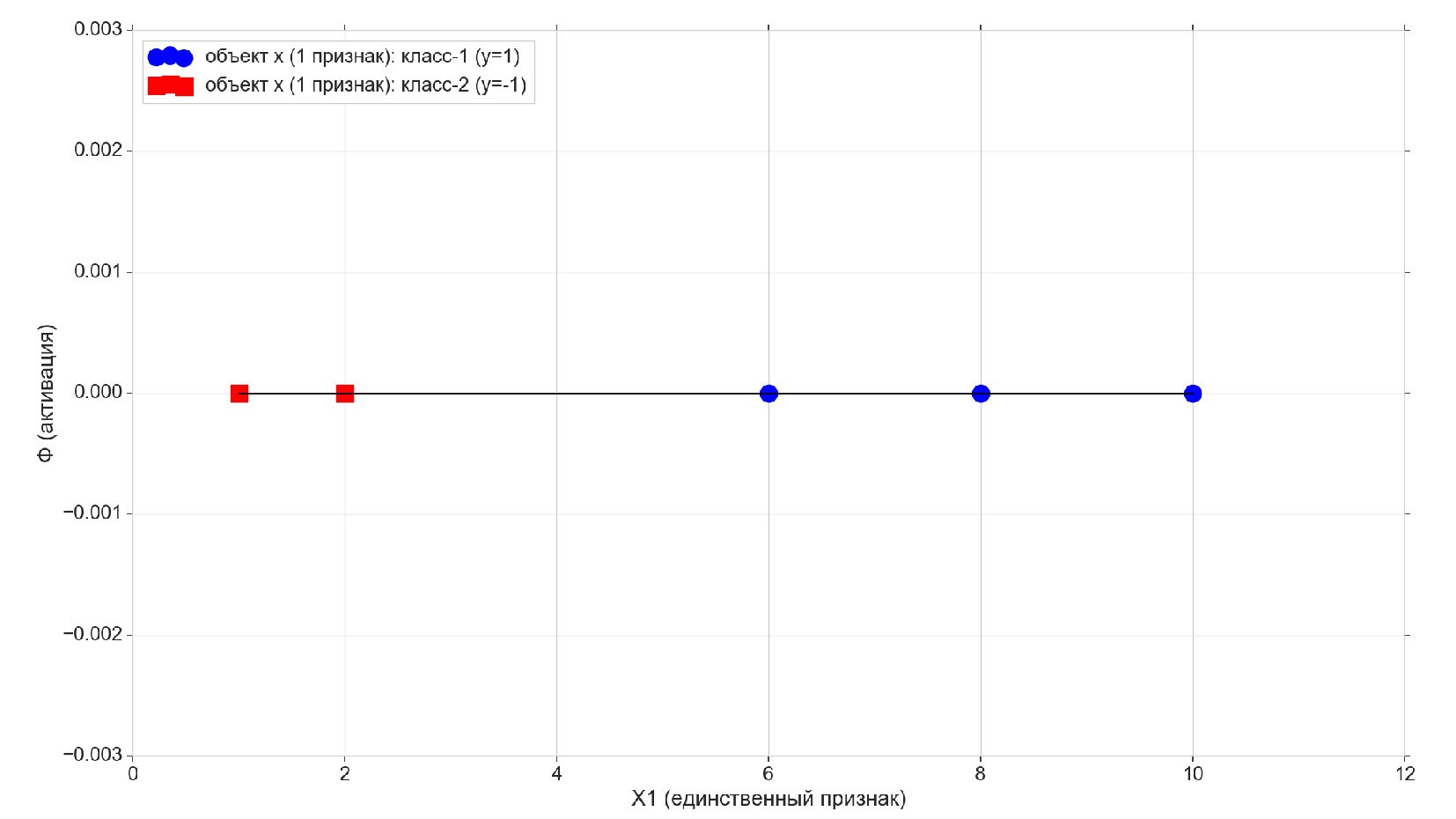
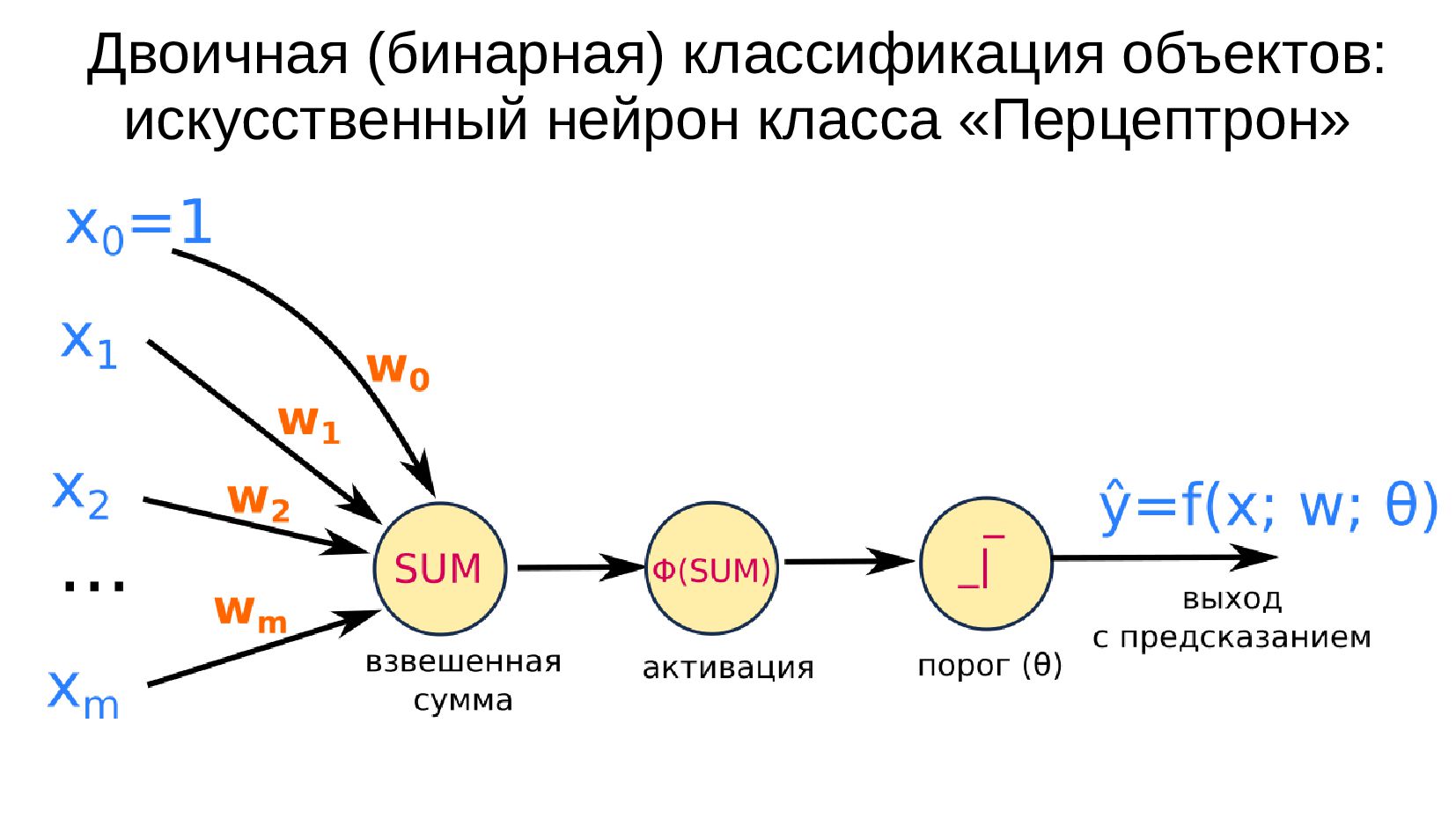
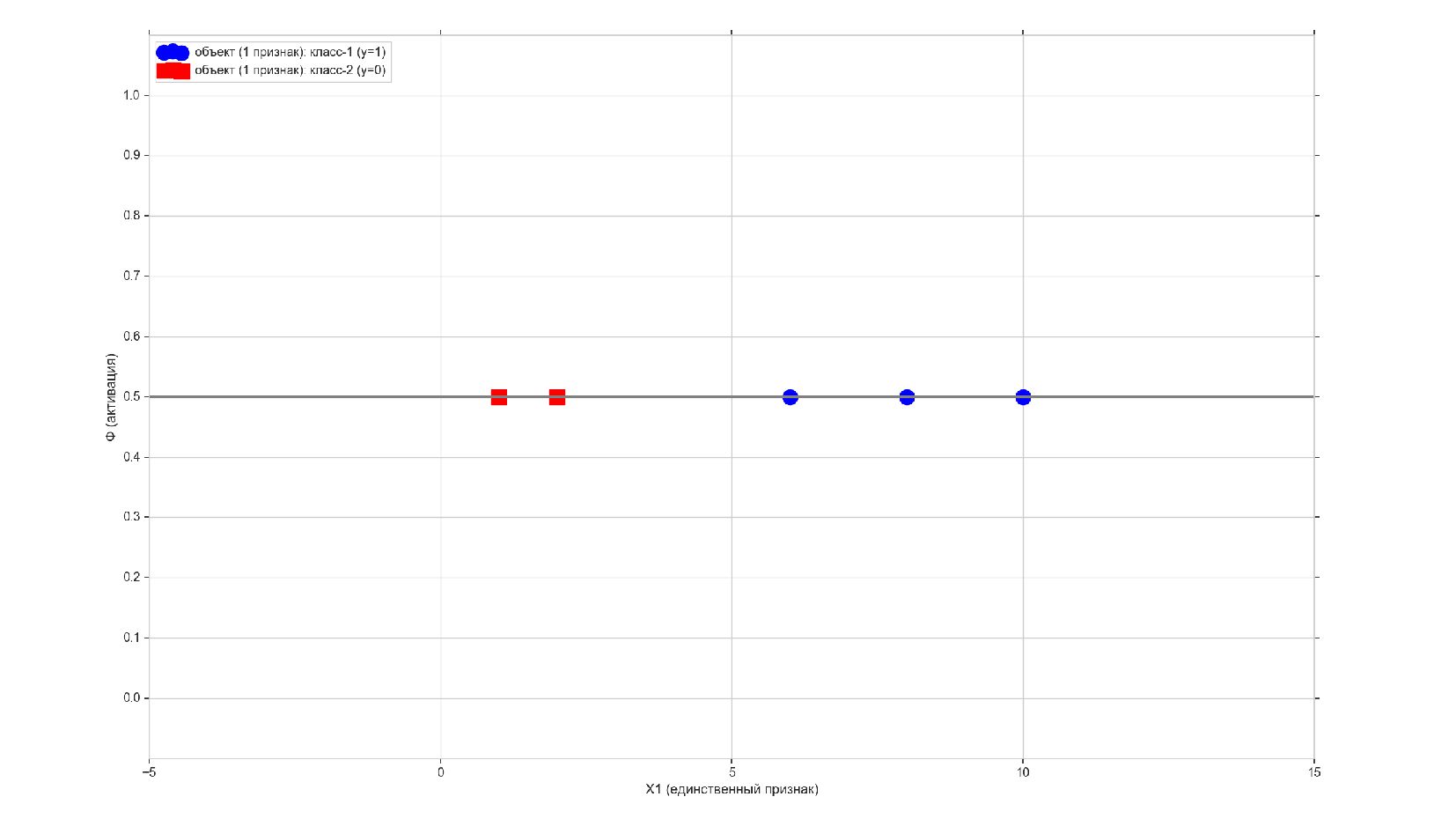
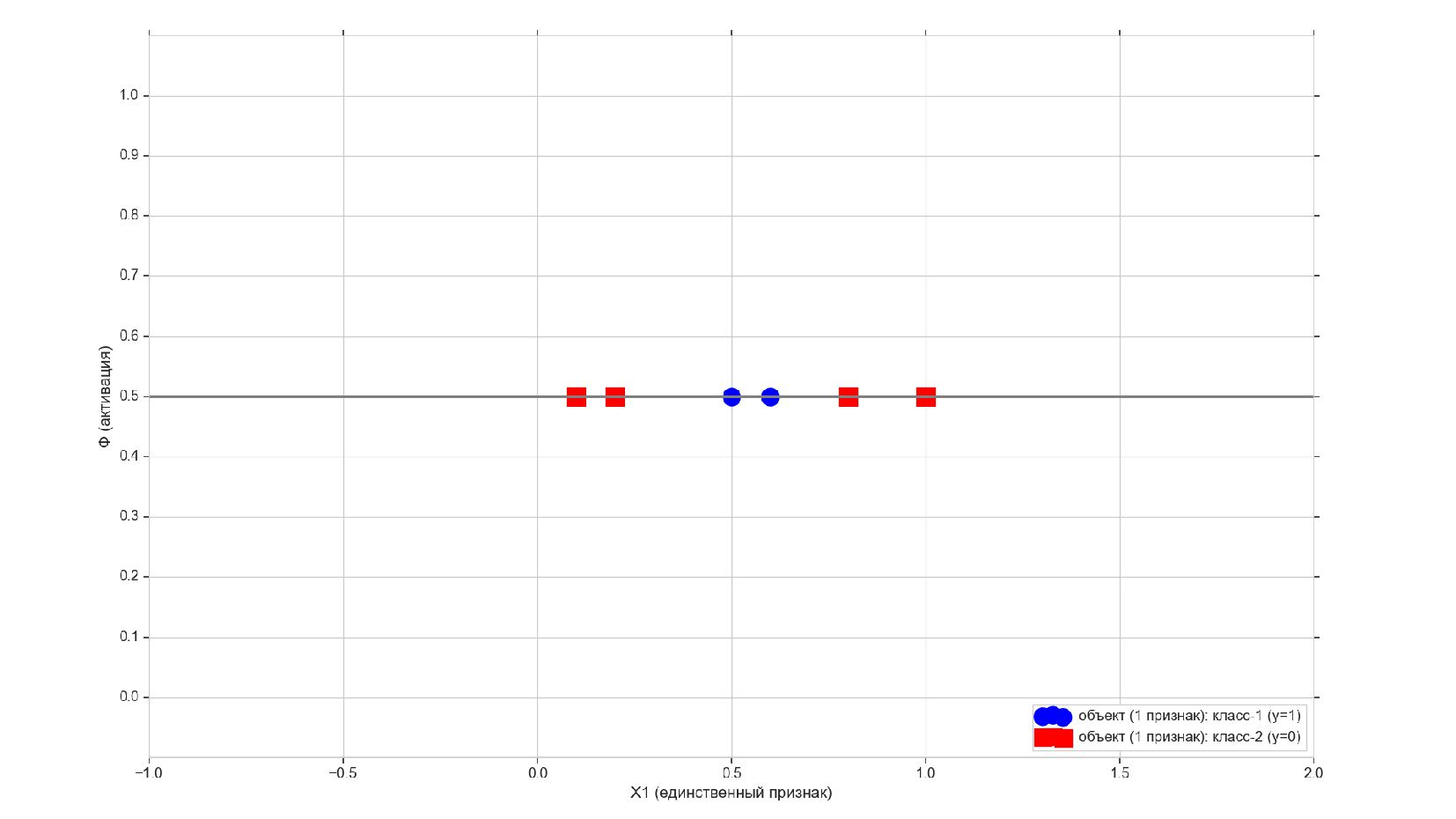
- Реализация линейного нейрона: двоичная классификация, объекты с единственным признаком
-- Объекты-плейсхолдеры (заглушки) - обучающая выборка и истинные метки
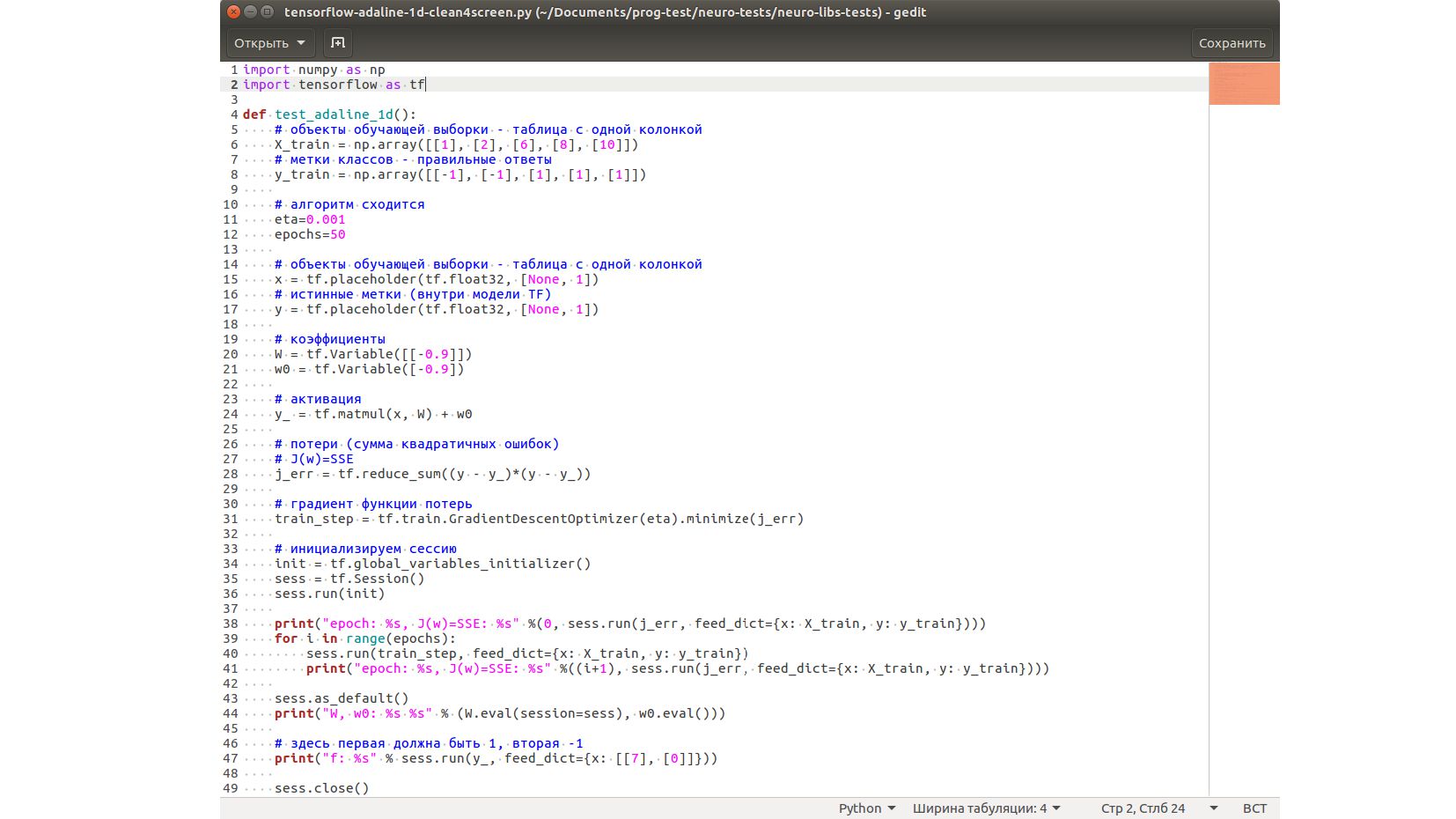
-- Инициализация весовых коэффициентов
-- Шаблон для функции активации - матричные операции с тензорами
-- Шаблон для функции потерь
-- Градиент функции потерь (волшебство автоматического дифференцирования любой сложной функции в одной строчке)
-- Инициализация и запуск сессии
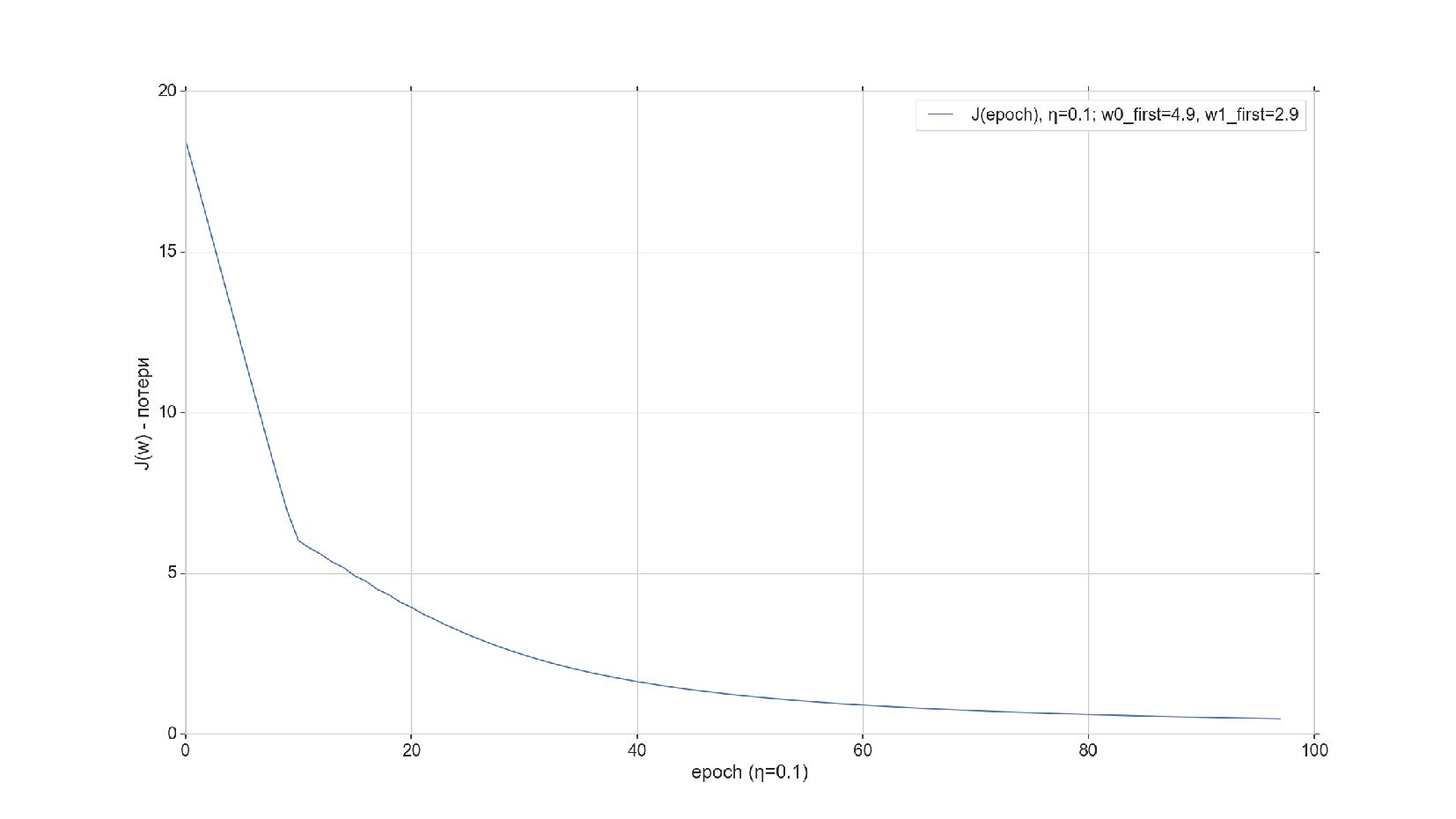
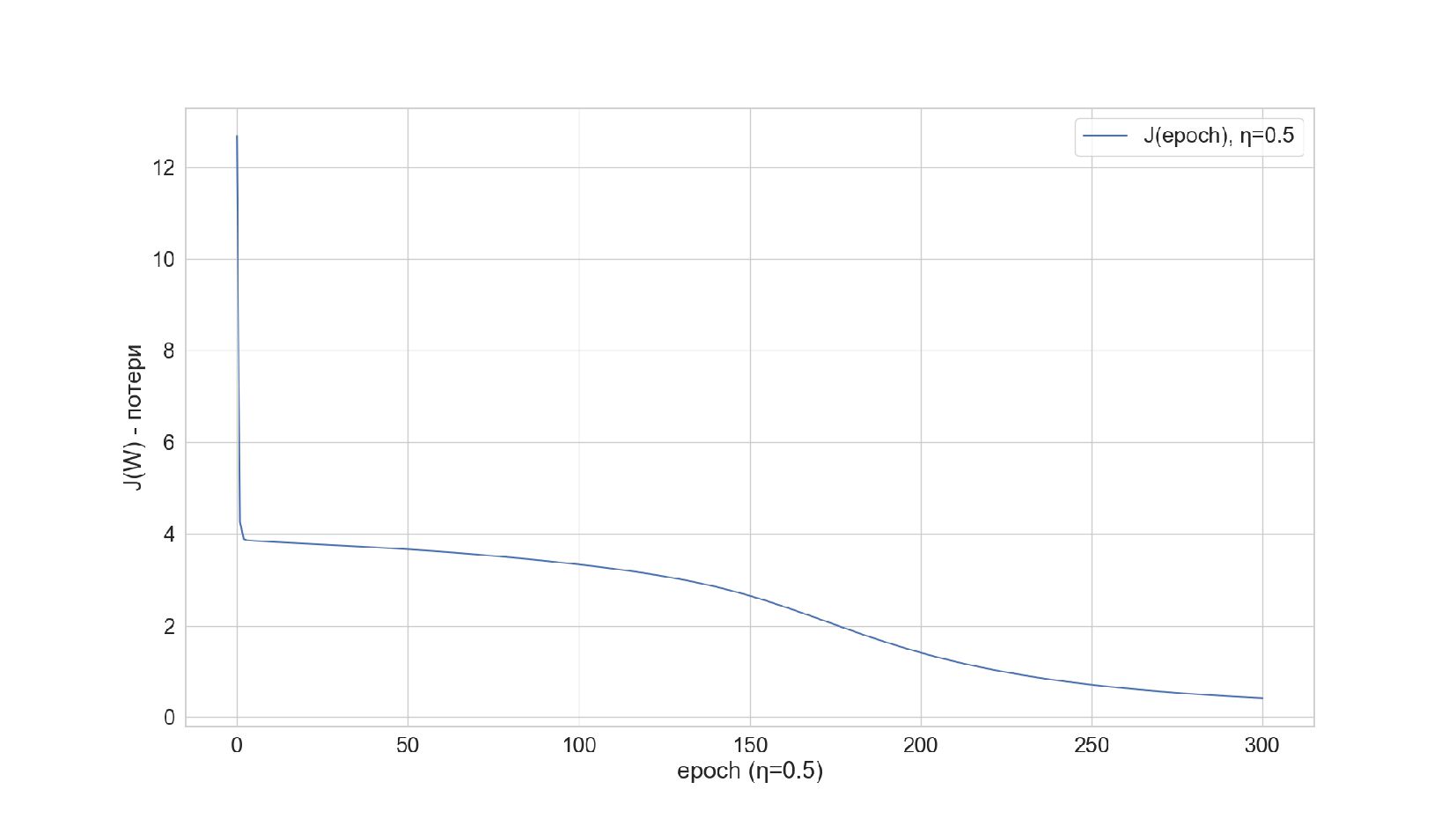
-- Спуск по градиенту (обучение) по эпохам: передача данных в сессию, выполнение шаблона функции спуска внутри сессии, получение данных из сессии (смотрим значение ошибки на каждом шаге)
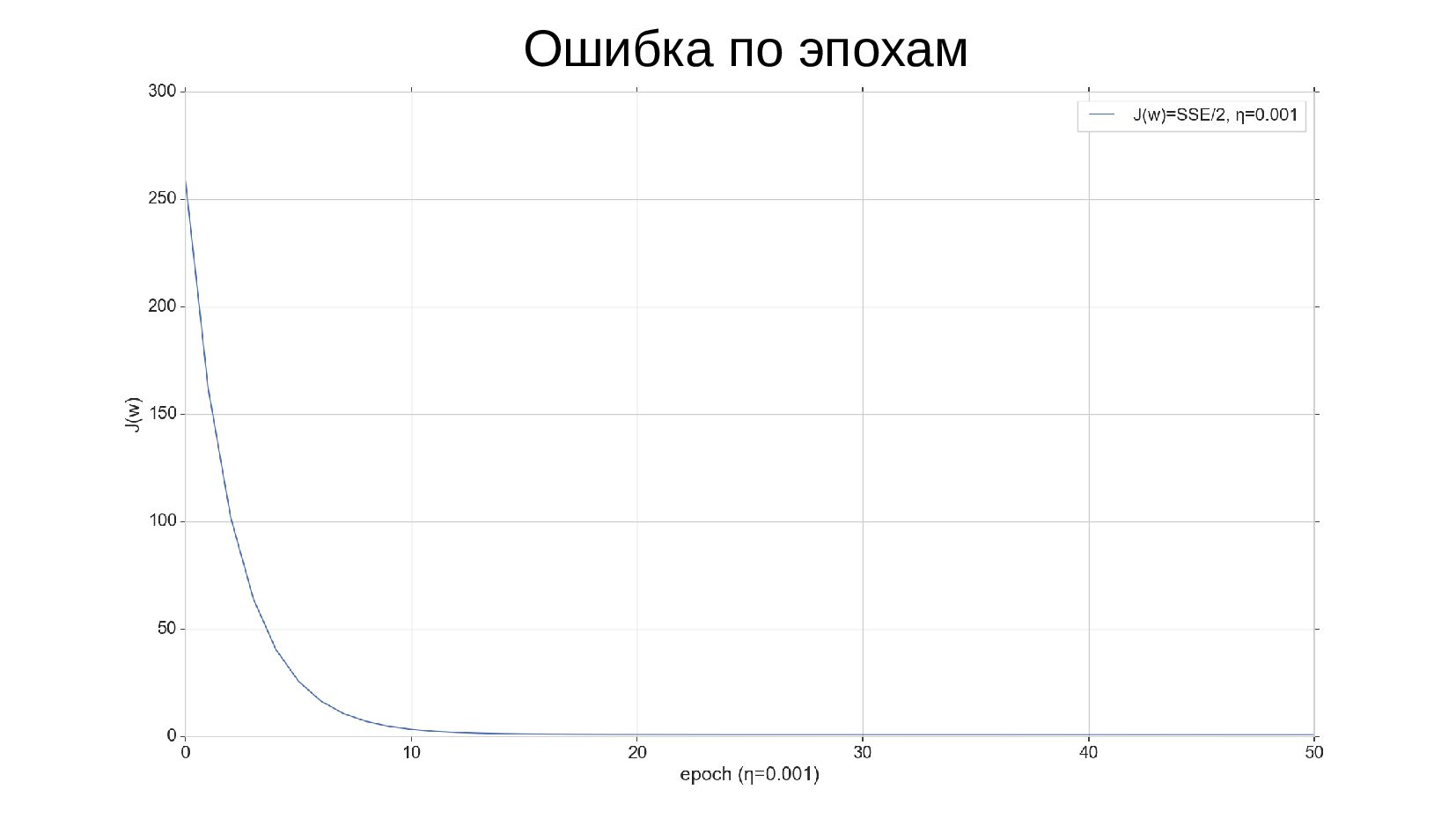
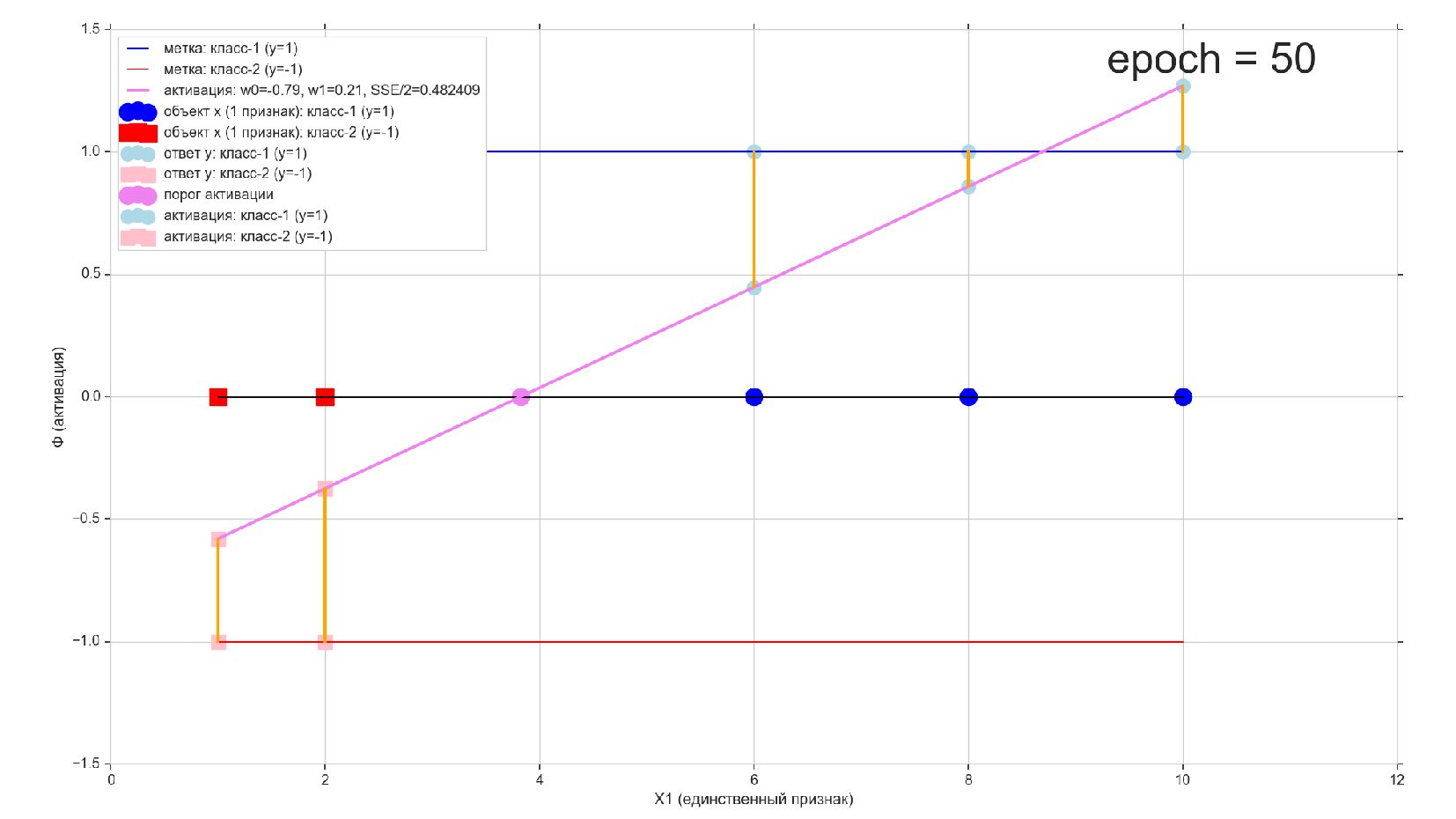
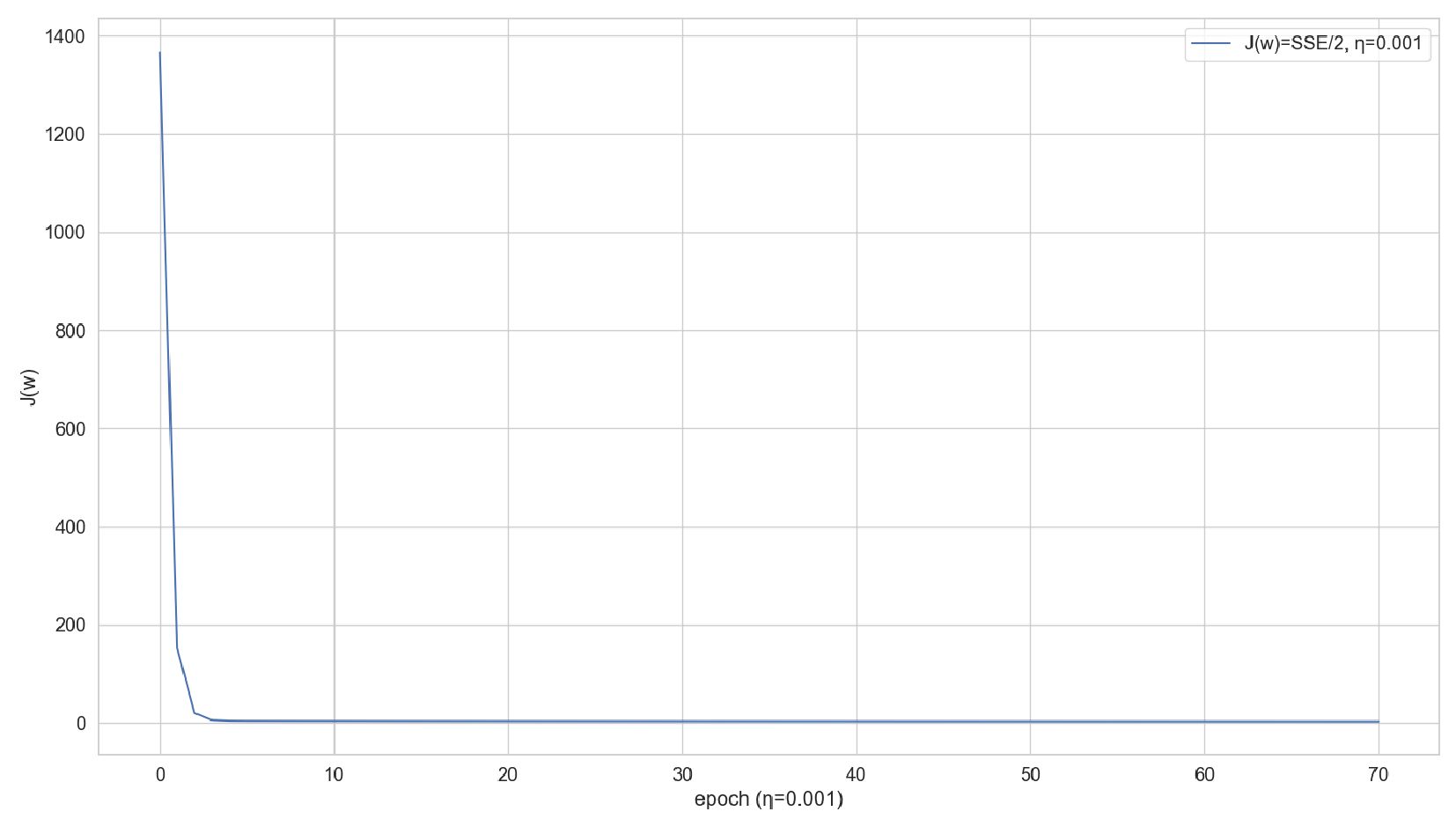
-- Результат обучения: ошибка уменьшается на каждой эпохе
-- Сверяем результат с ручным спуском из прошлой лекции (ошибки по эпохам совпадают до знака, но нужно скорректировать функцию ошибки)
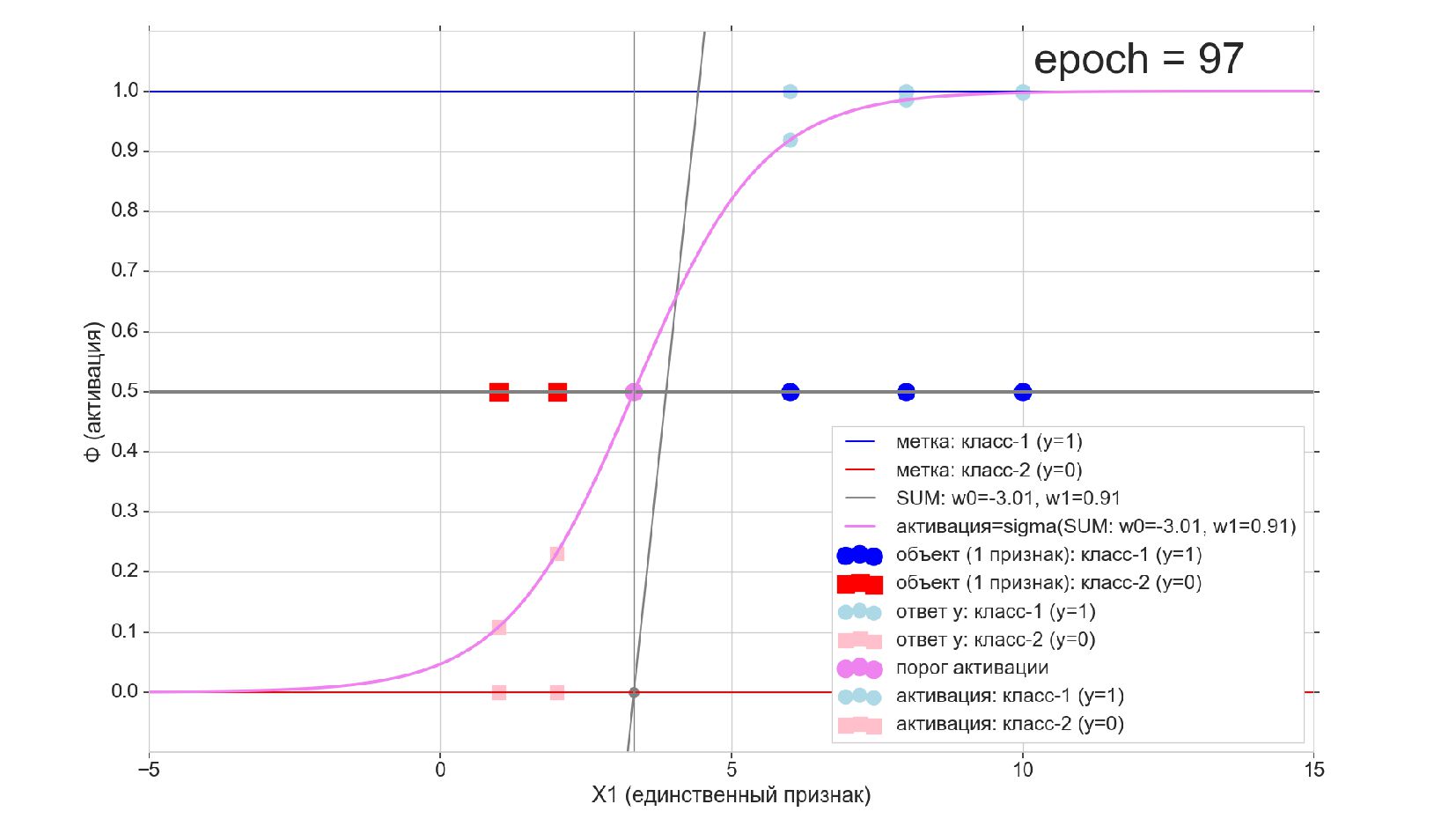
-- Проверка обученного нейрона: предсказание класса для новых объектов
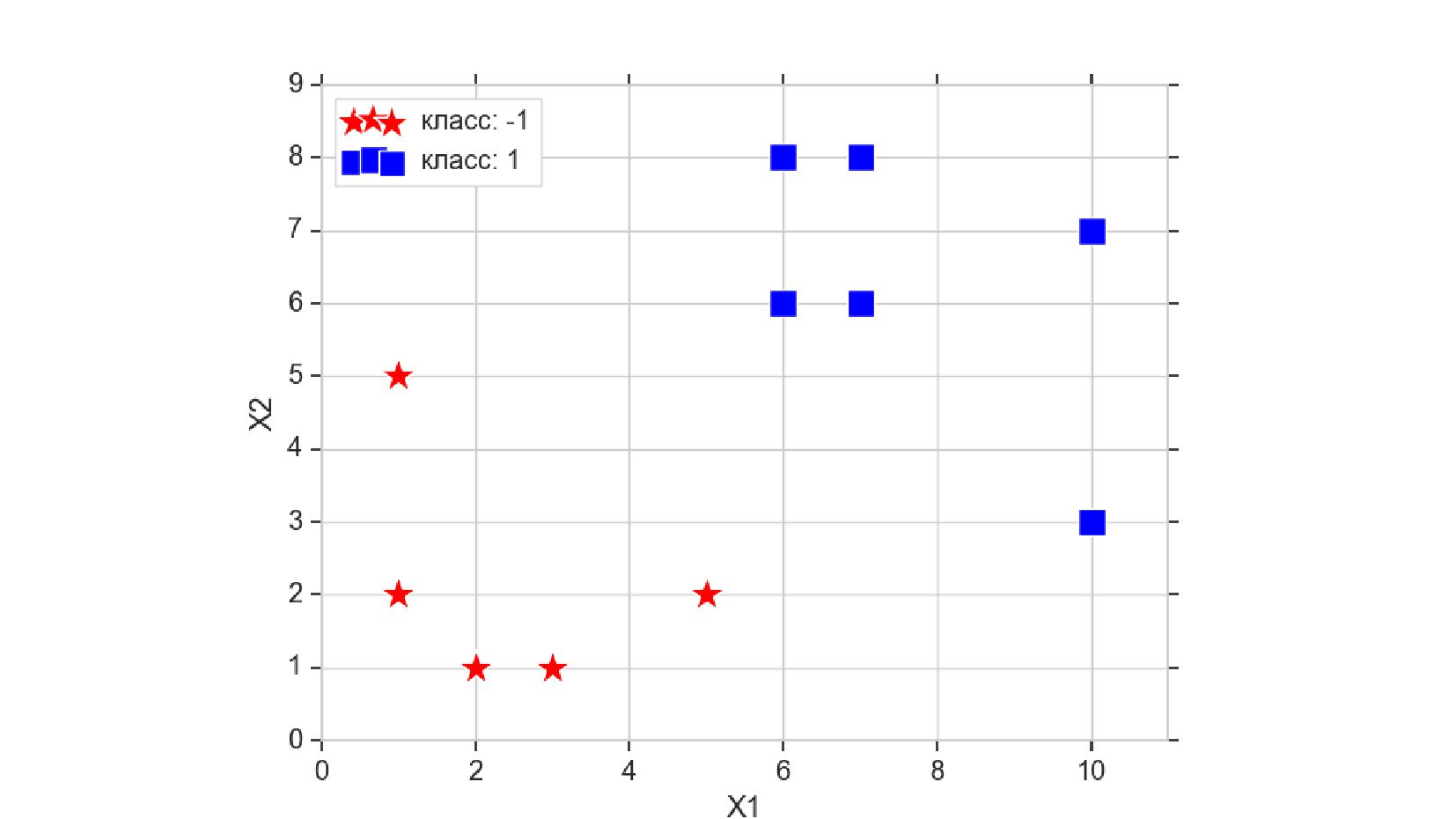
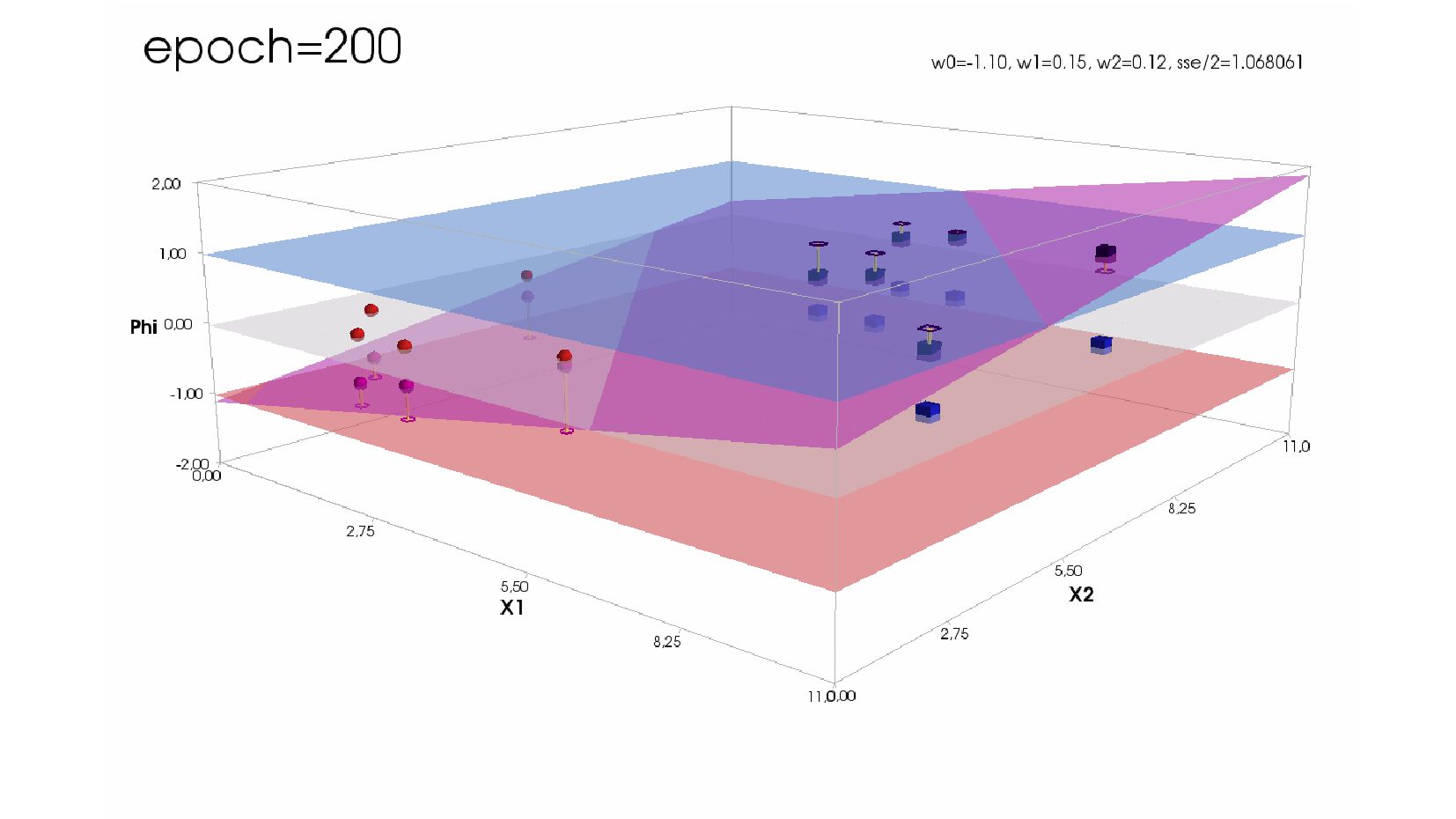
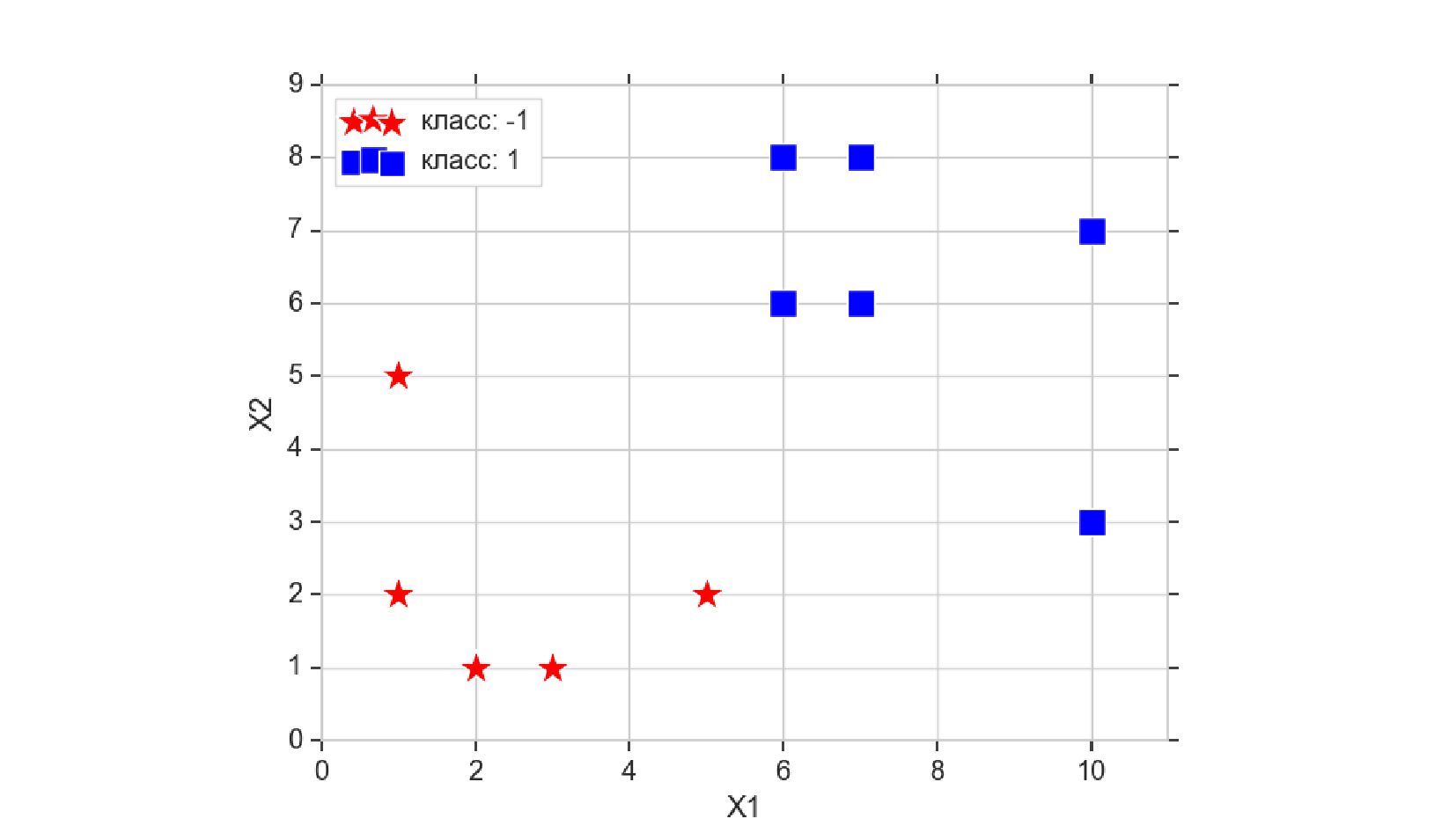
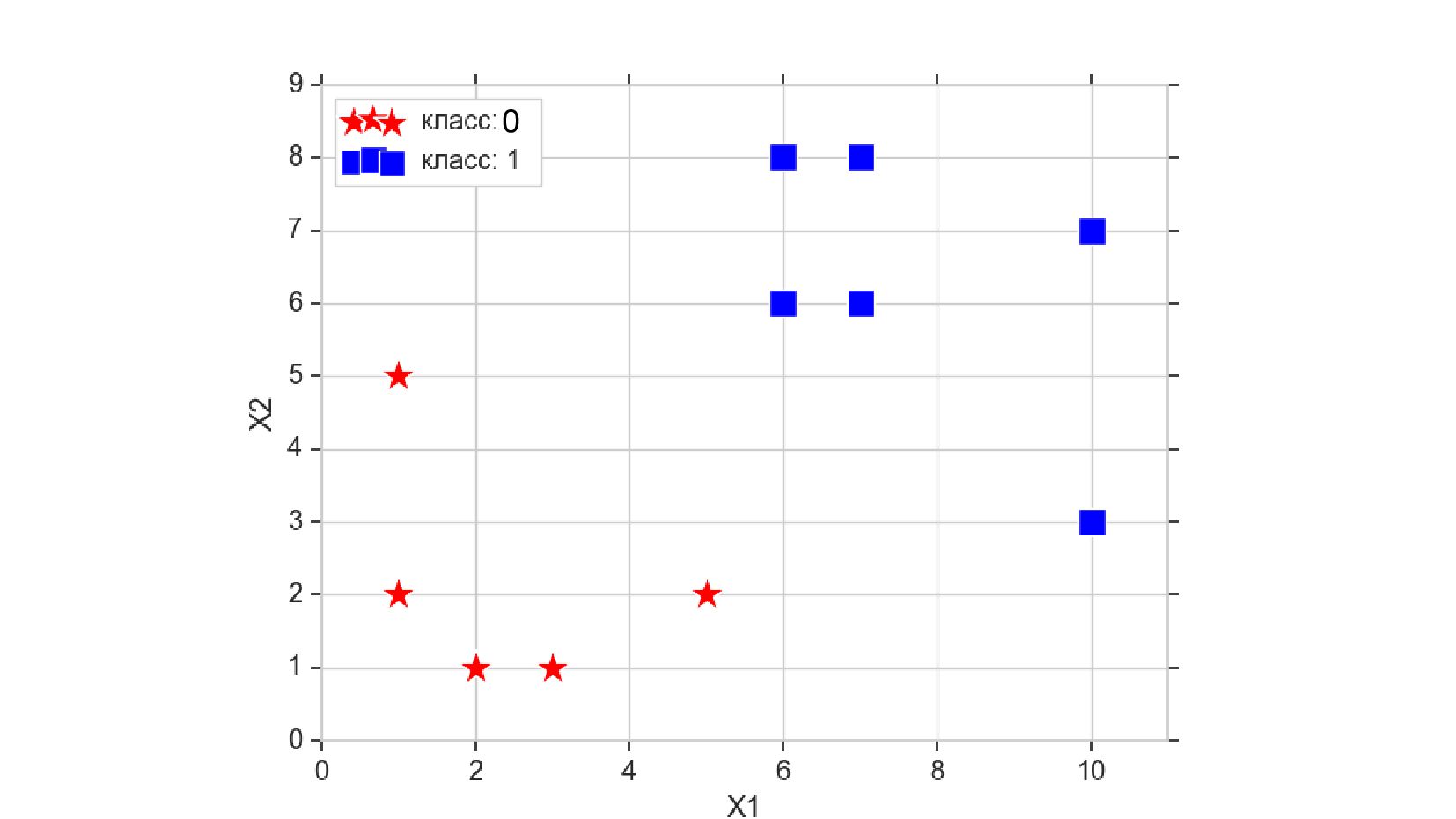
- Реализация линейного нейрона для классификации объектов с 2-мя признаками
- Реализация нейрона с активацией-сигмоидой (логистическая регрессия) для классификации объектов с одним признаком: поменяли в коде одну строчку с шаблоном функции активации
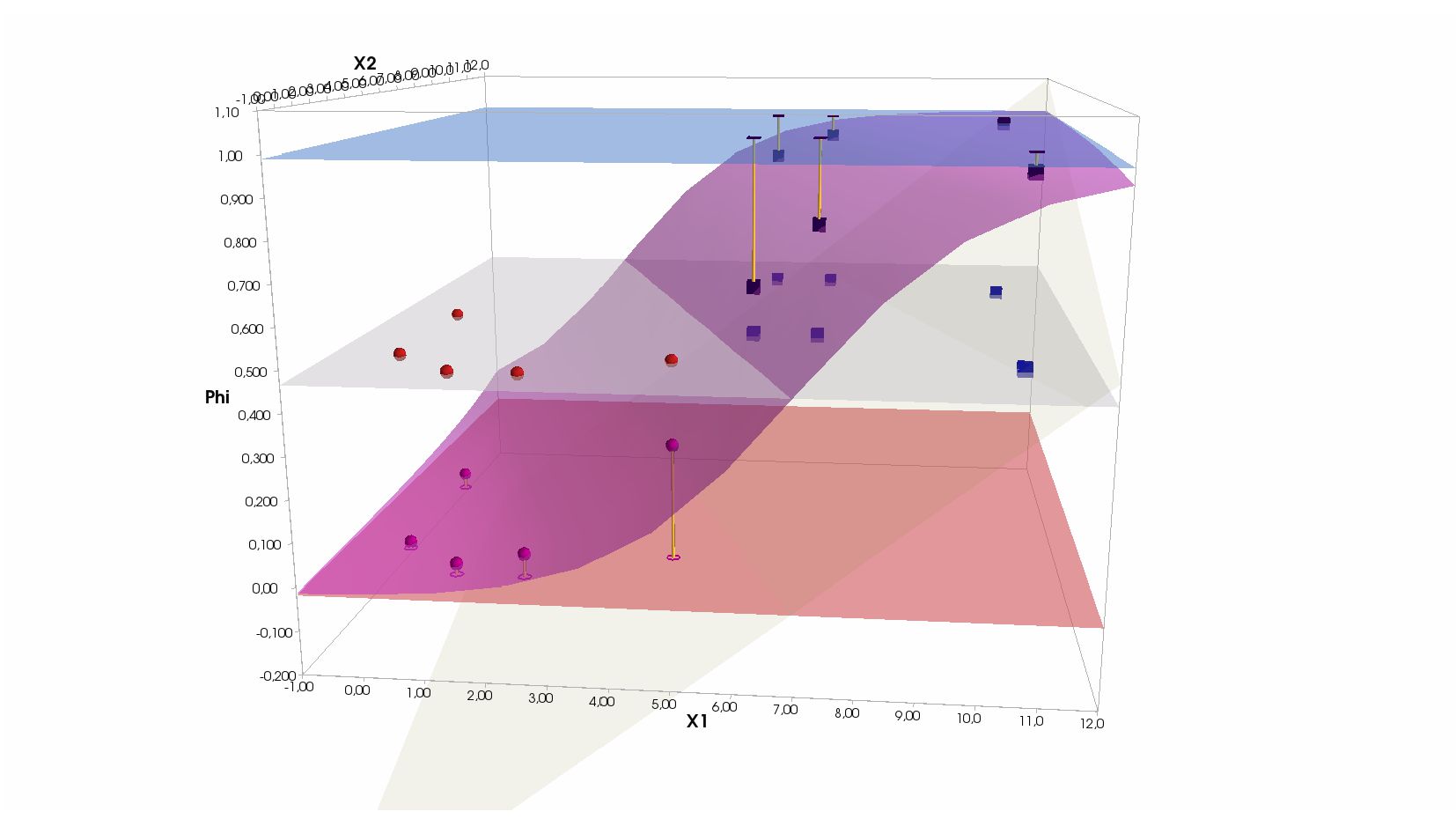
- Реализация нейрона с активацией-сигмоидой (логистическая регрессия): объект с 2-мя признаками
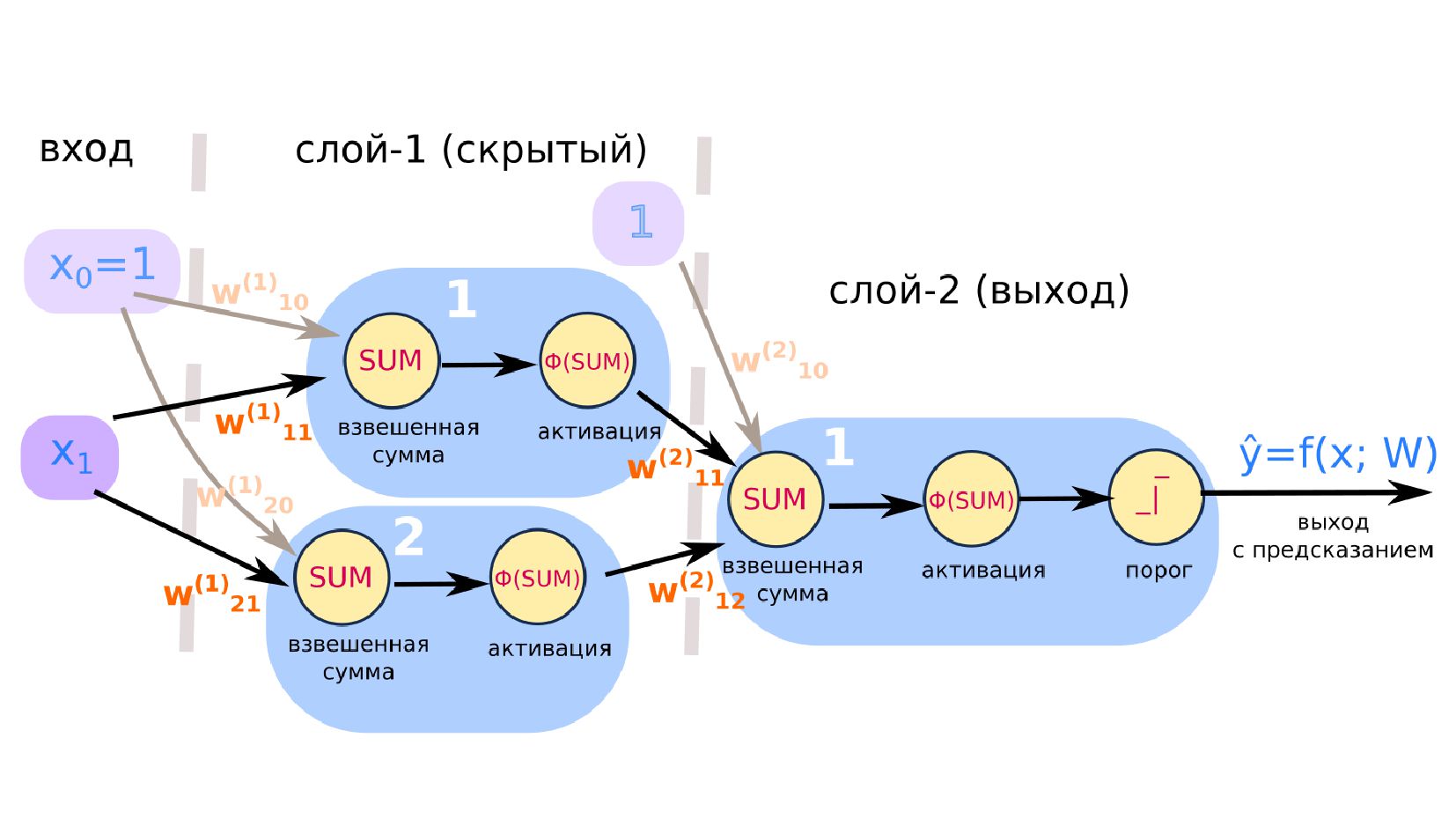
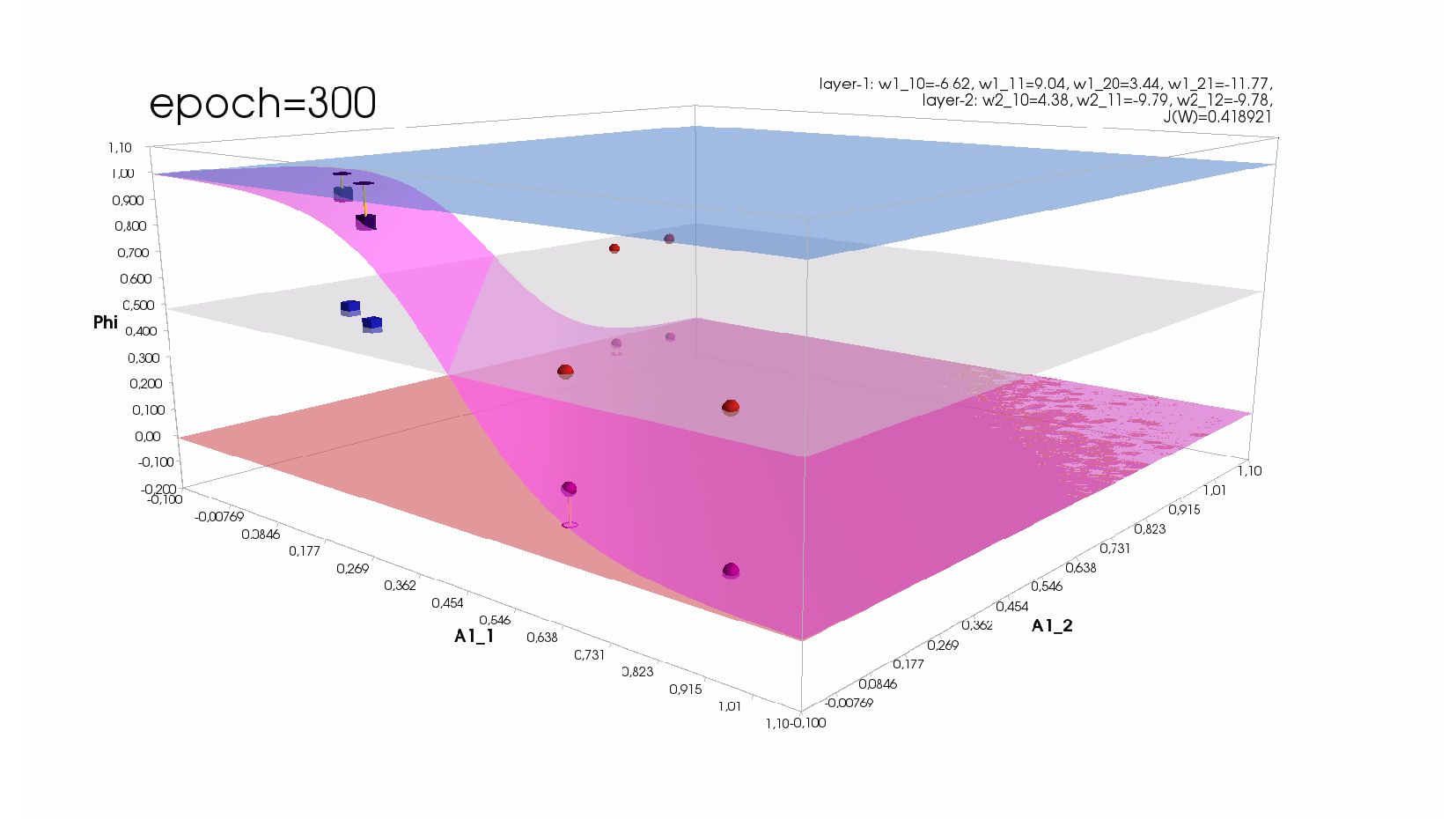
- Реализация нейросети из 3-х нейронов: меняем размерности входных матриц и матриц весовых коэффициентов, код активации и обучения остаётся как есть
- Самостоятельно: попробовать другие функции активации
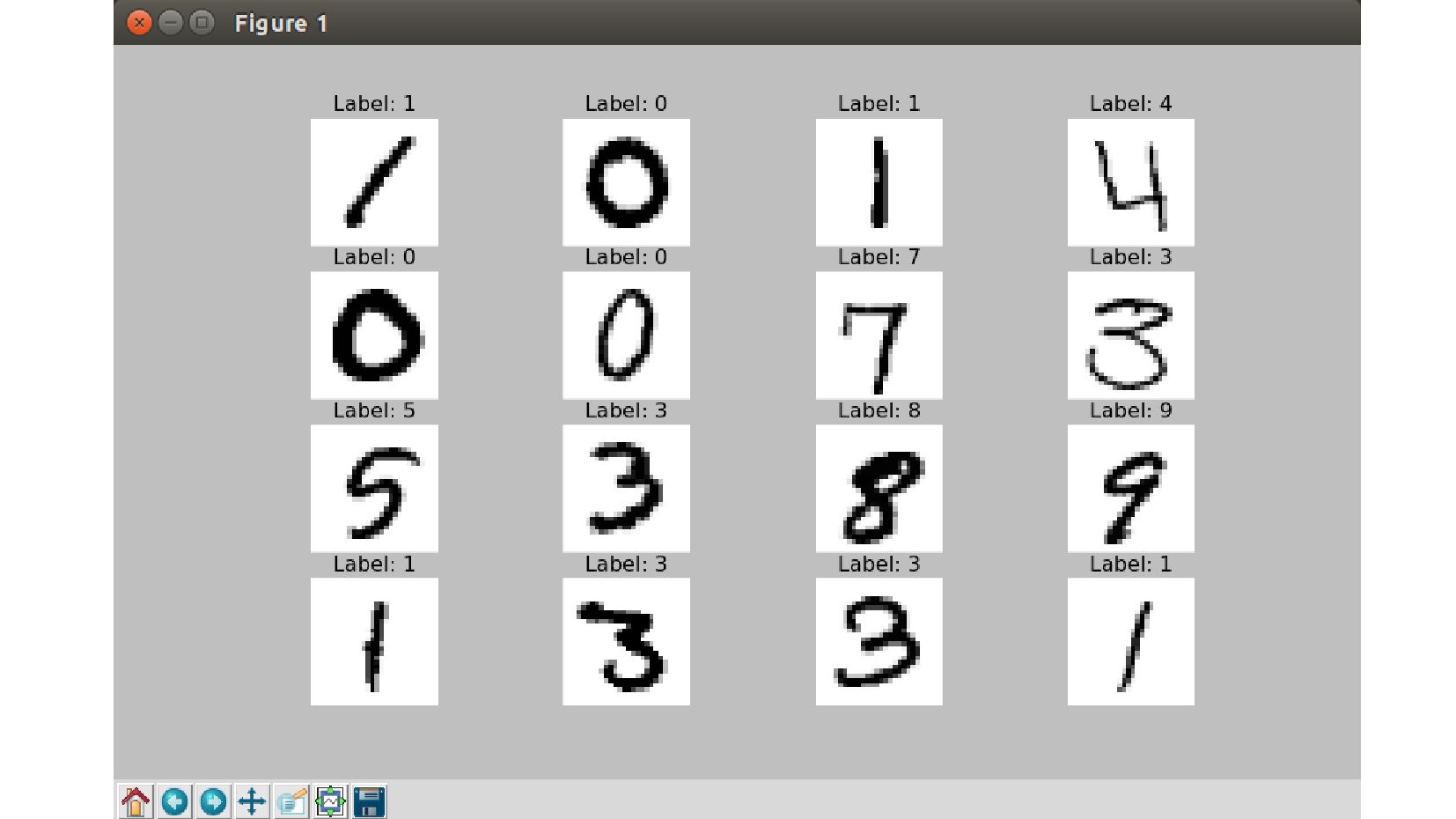
- Классификатор рукописных цифр MNIST
-- о датасете MNIST
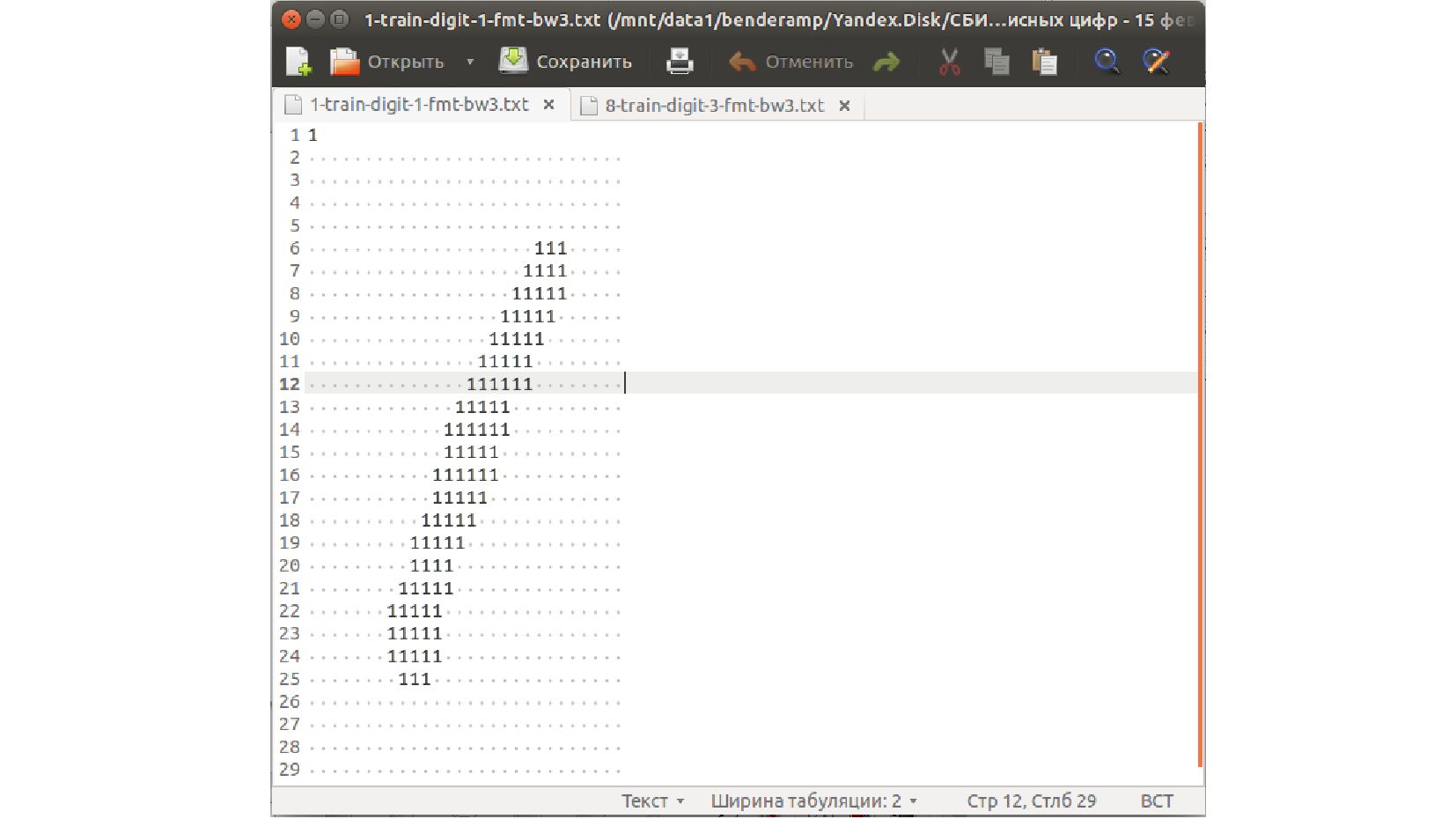
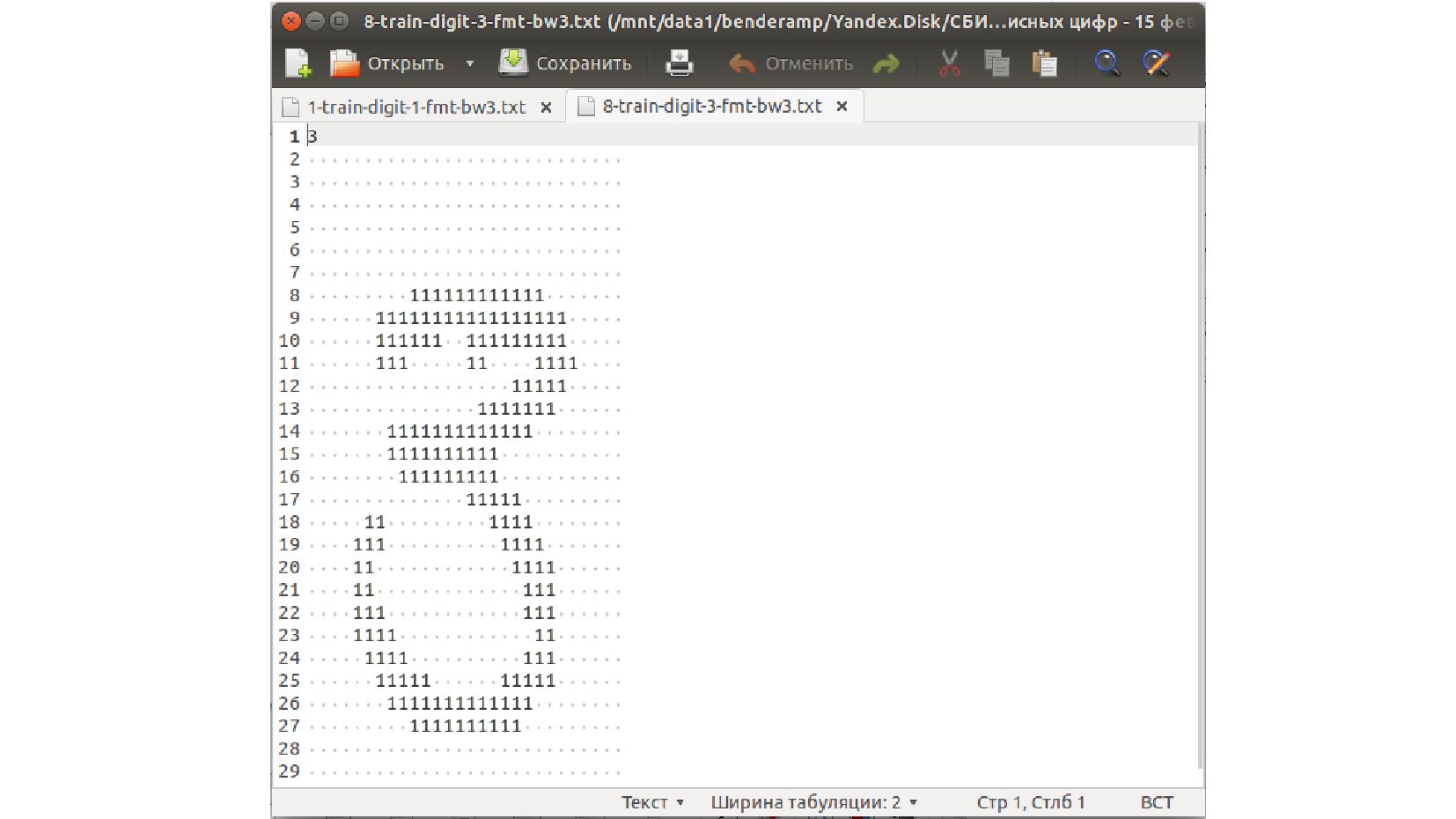
-- структура файла с данными MNIST: изображения представлены текстом
-- загружаем данные
-- кодирование метки символа в набор двоичных признаков при помощи кодировщика OneHotEncoder
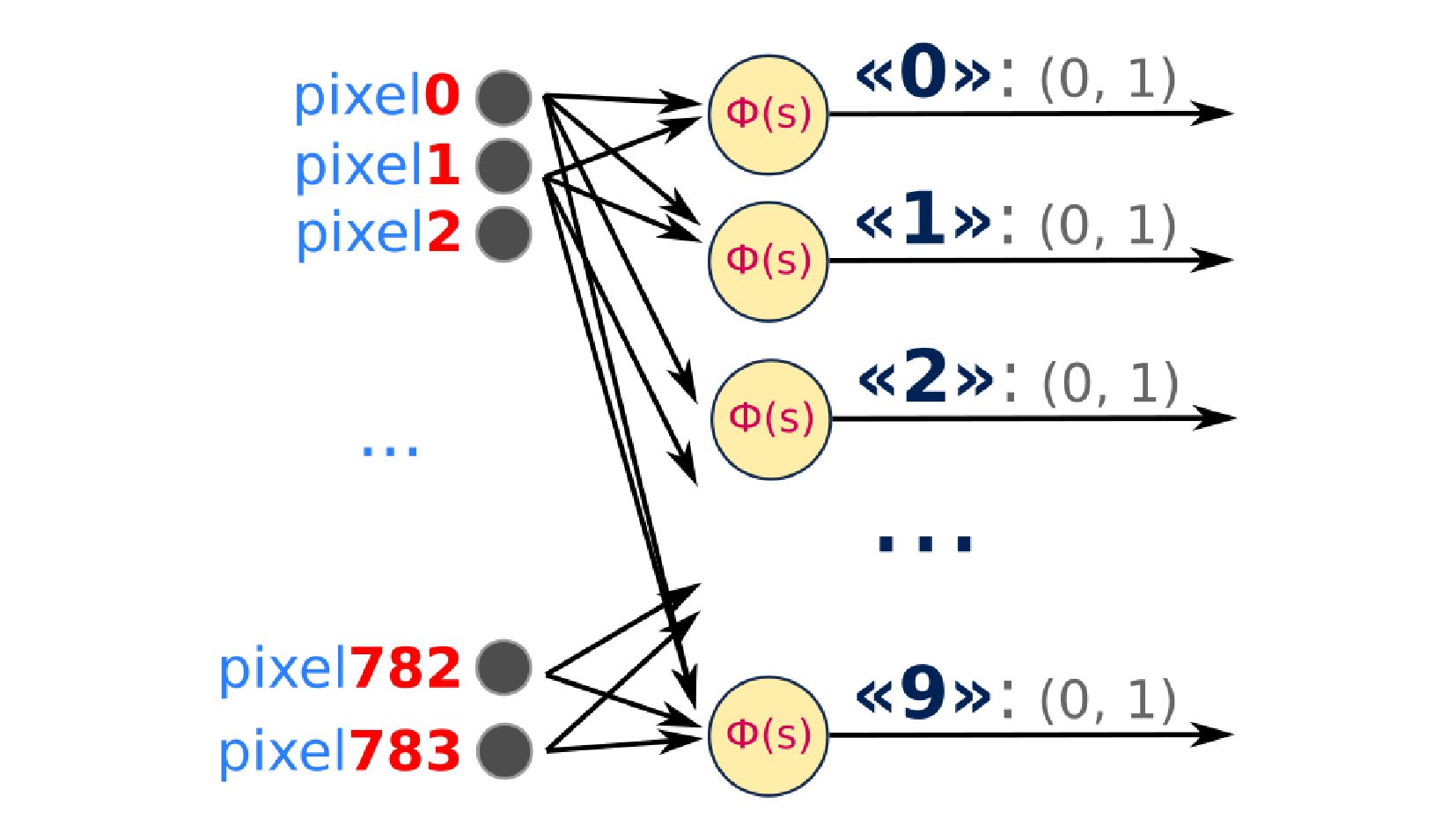
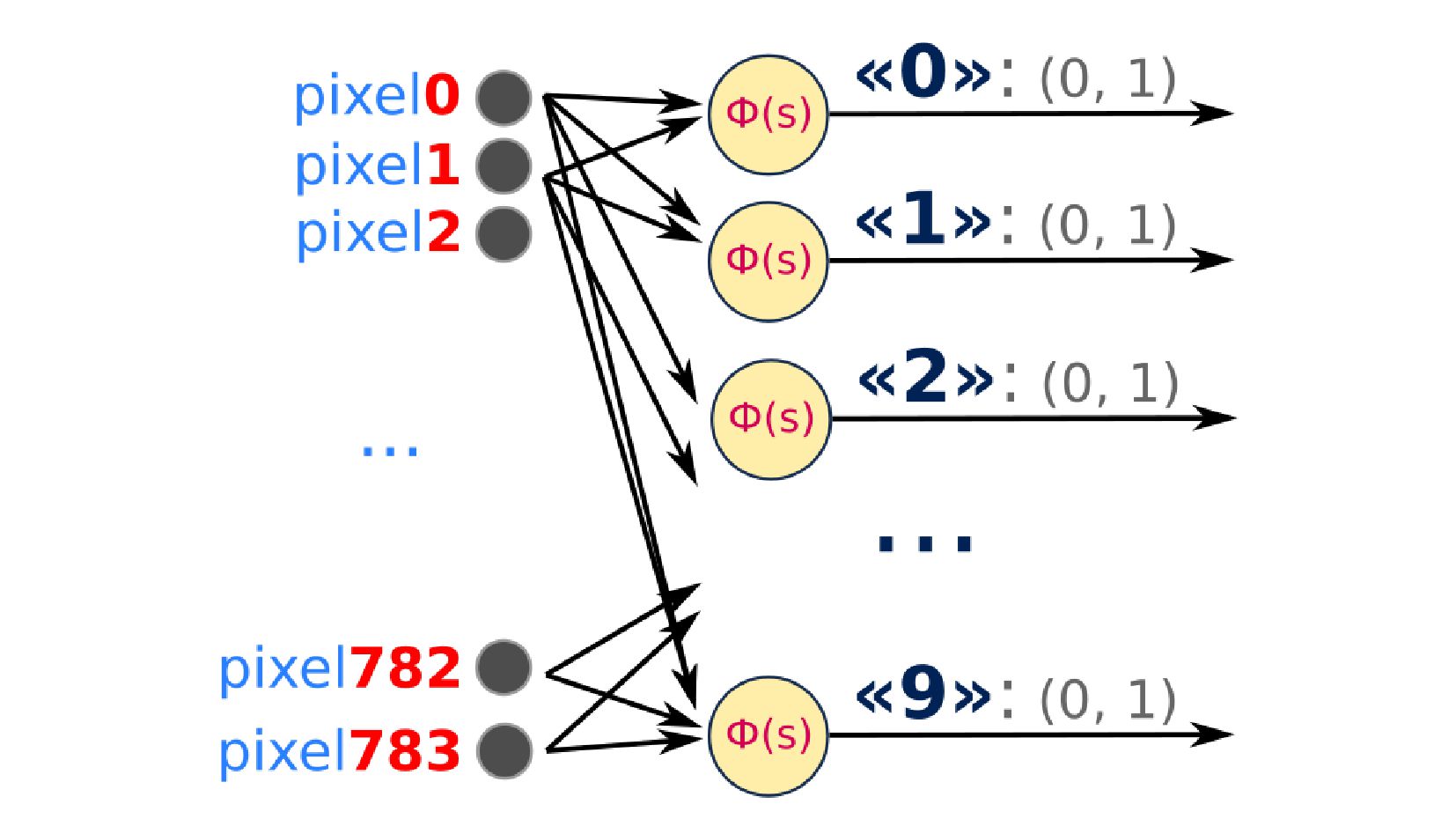
-- структура сети: один слой, по одному нейрону на каждую цифру (по сути это, не сеть, а несколько отдельных нейронов, каждый из которых делит всё множество на два класса: "цифра X"-"НЕ цифра X")
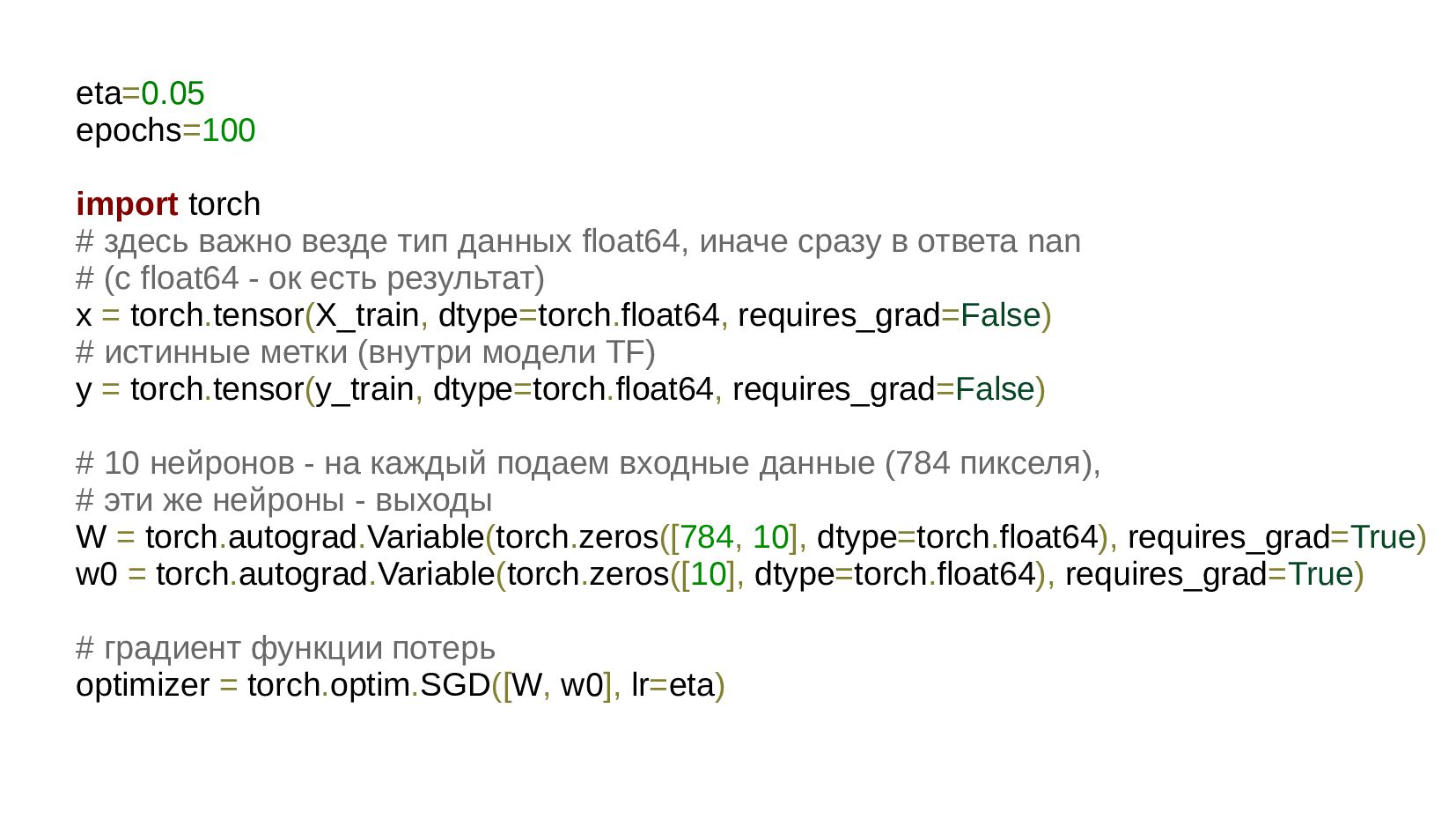
-- создание сети
-- обучение (немного схитрим: возьмем только первые 100 изображений)
-- проверка обученной сети
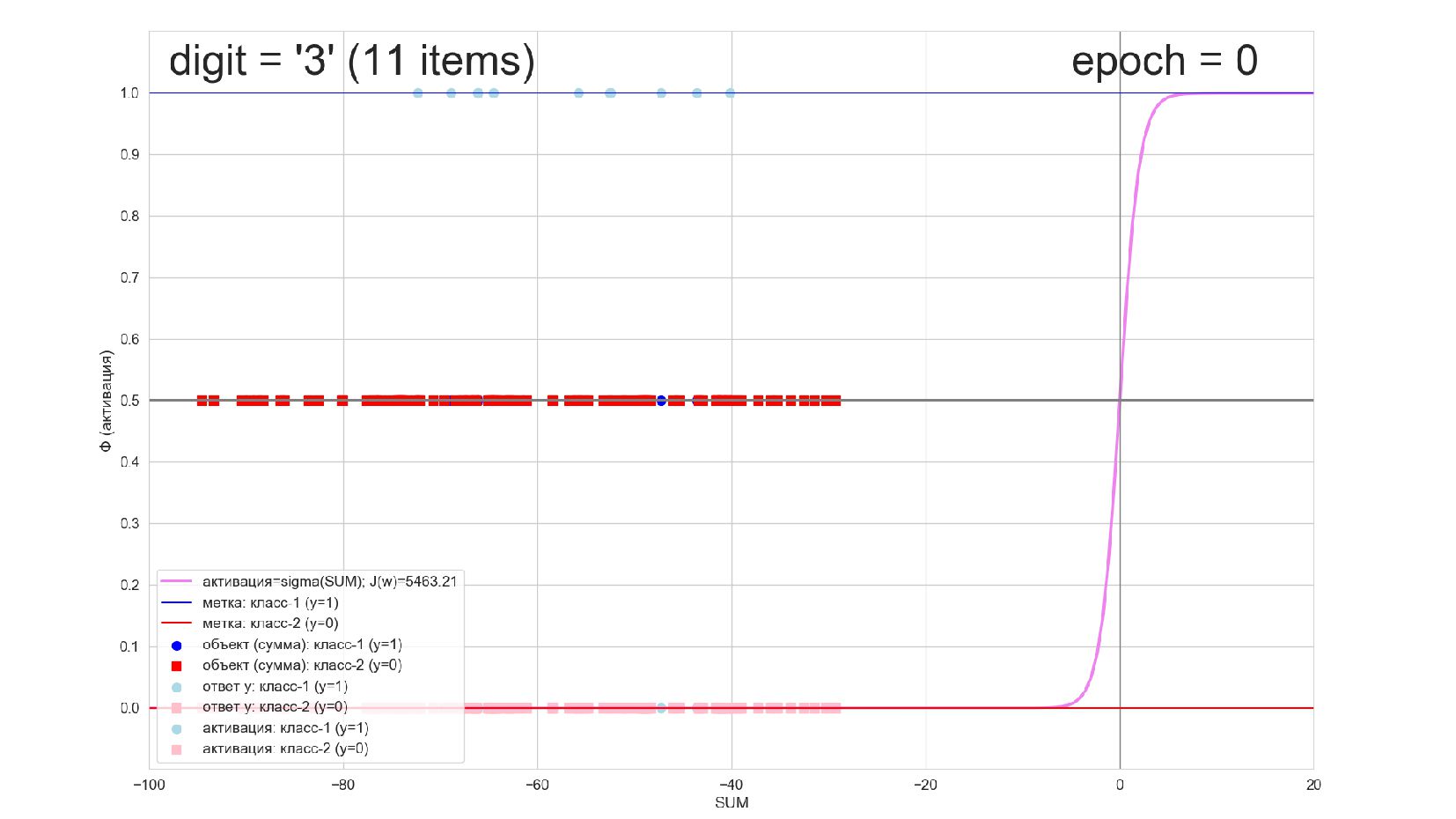
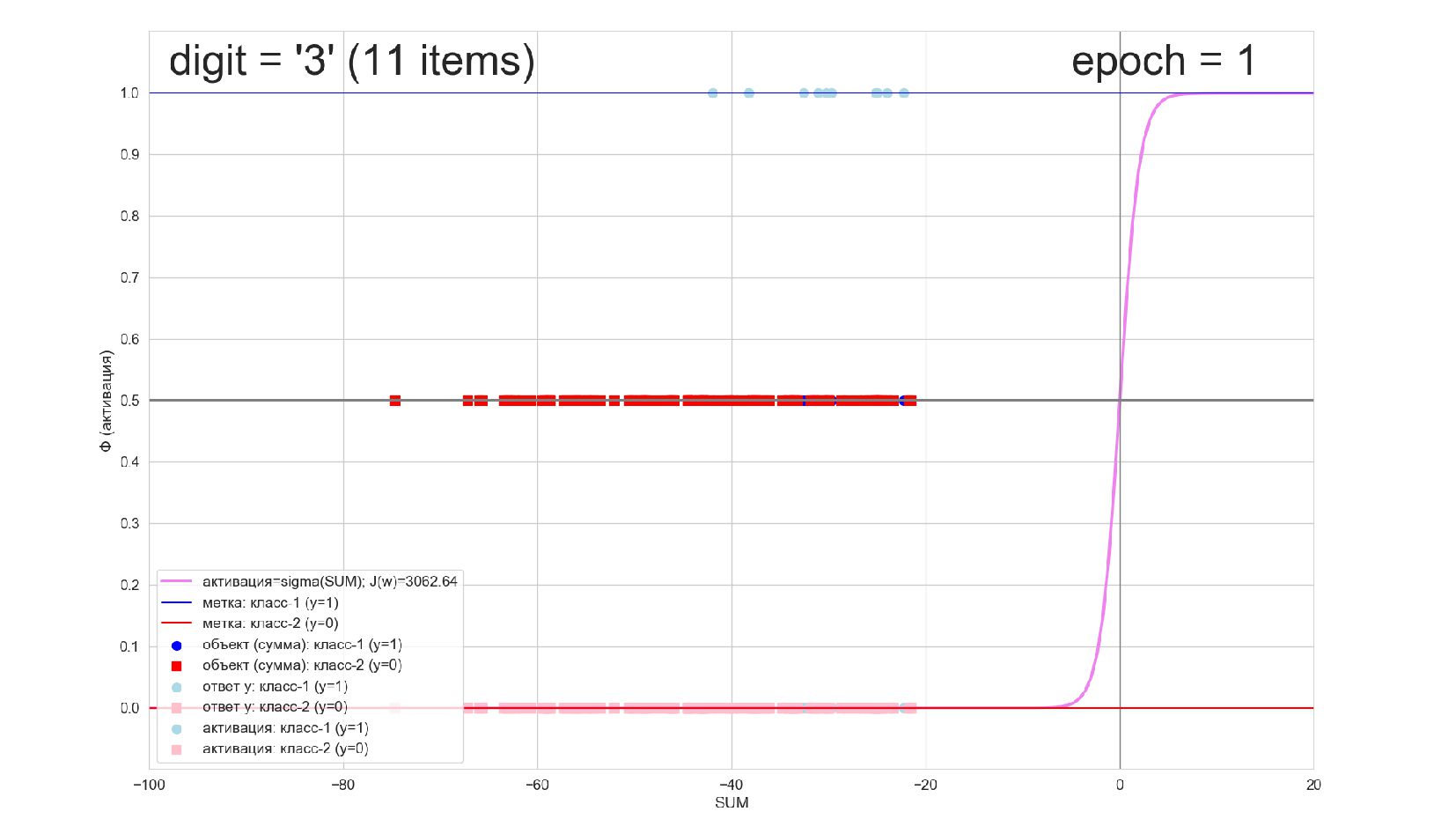
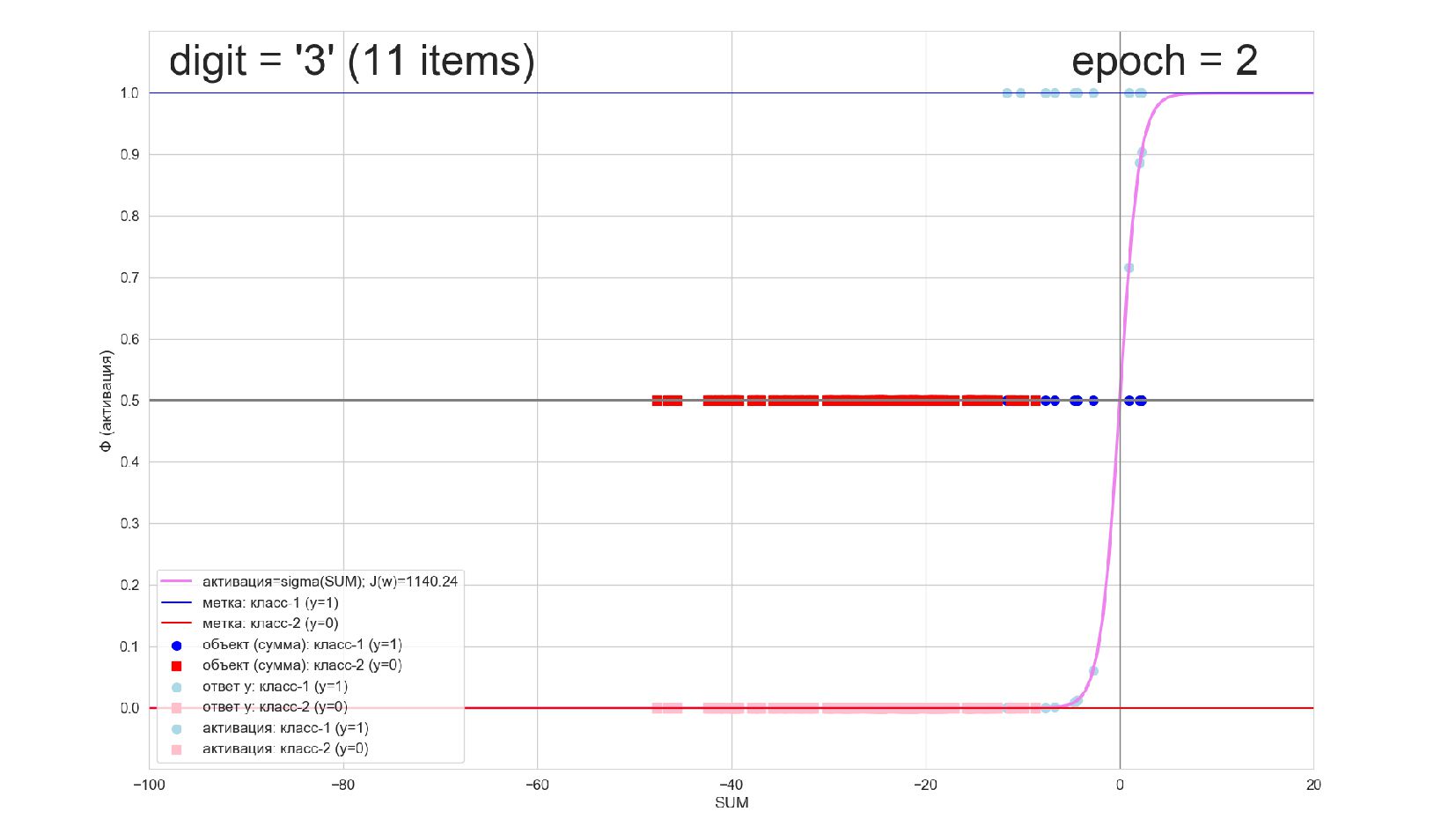
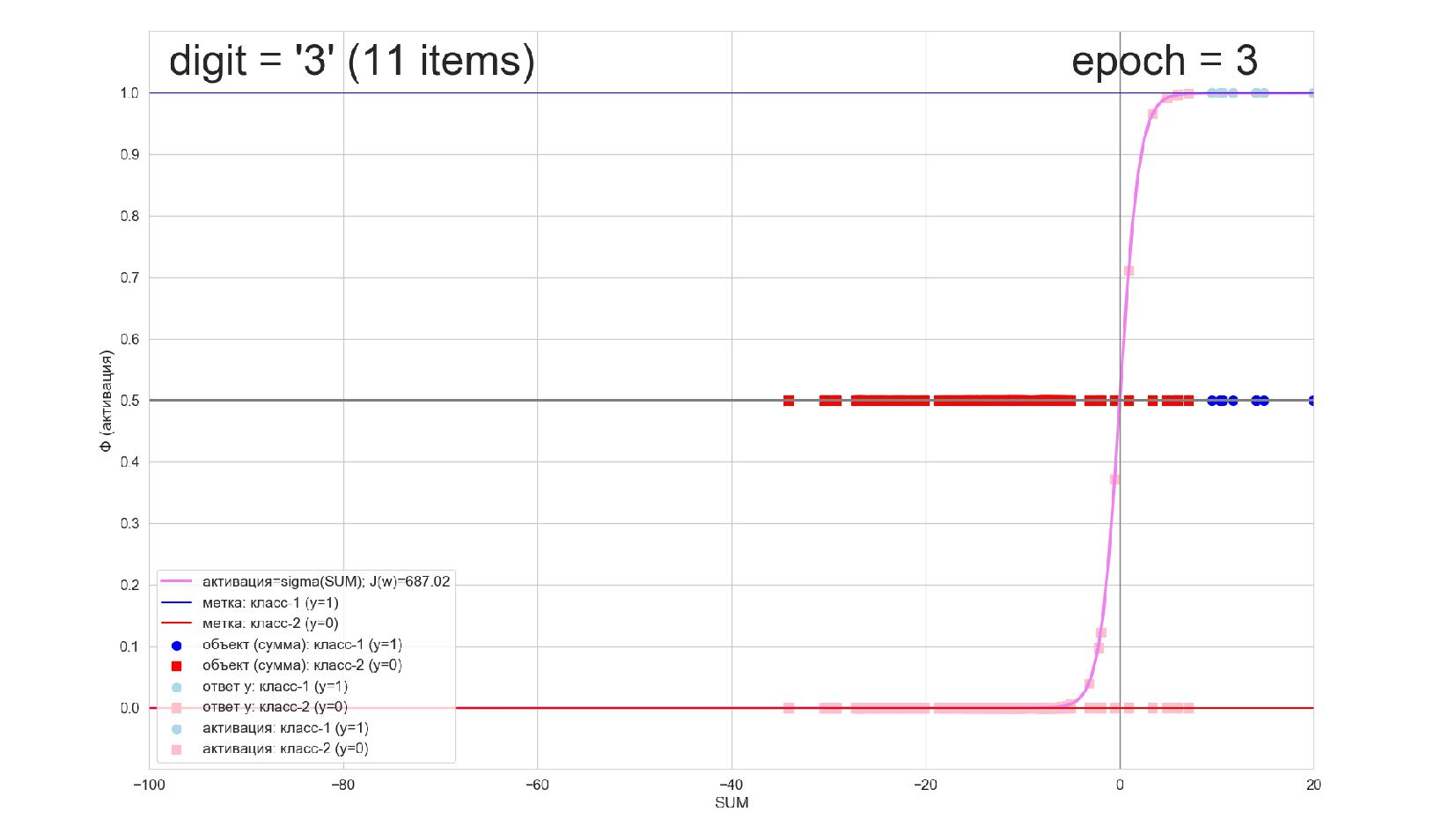
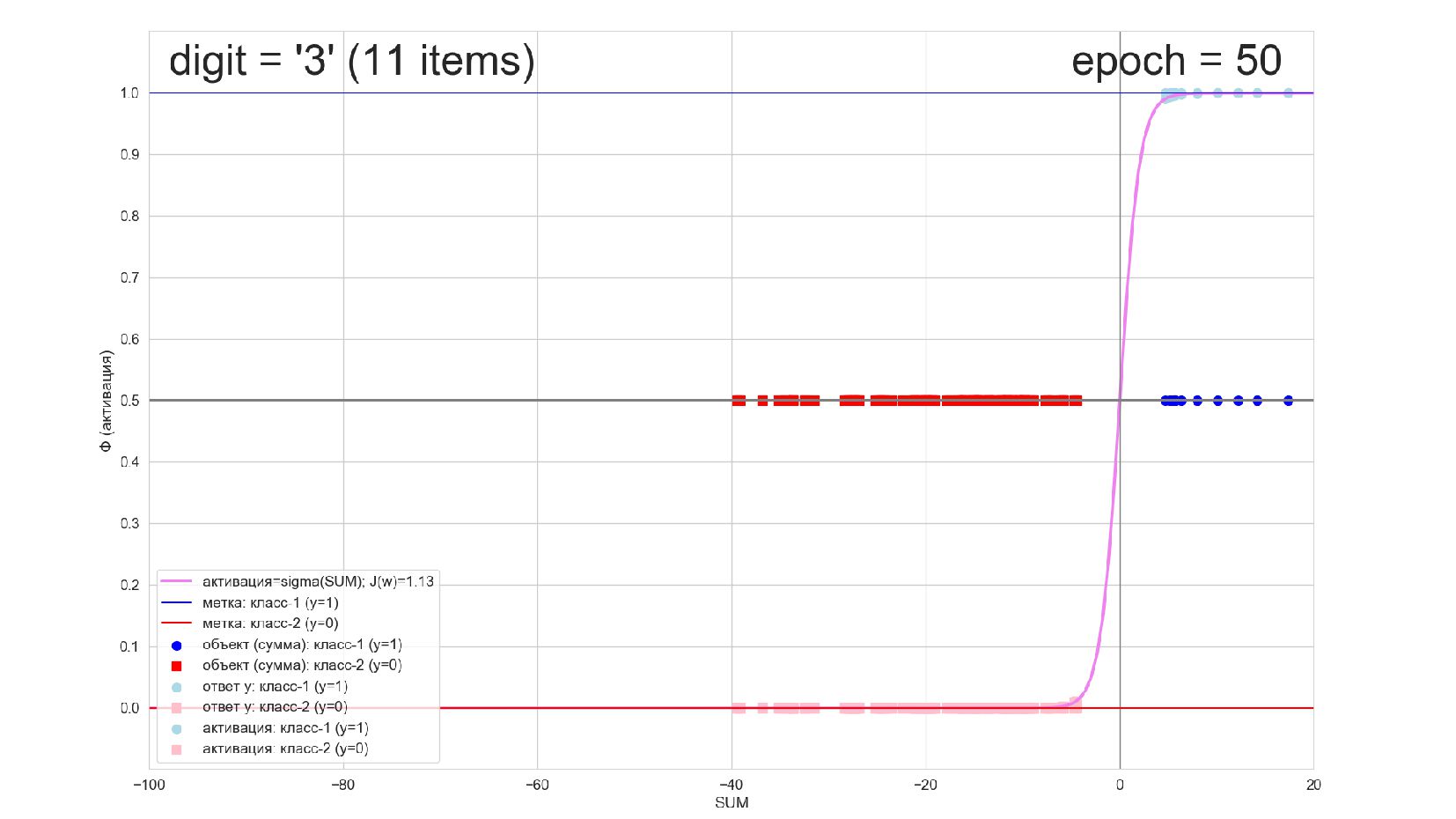
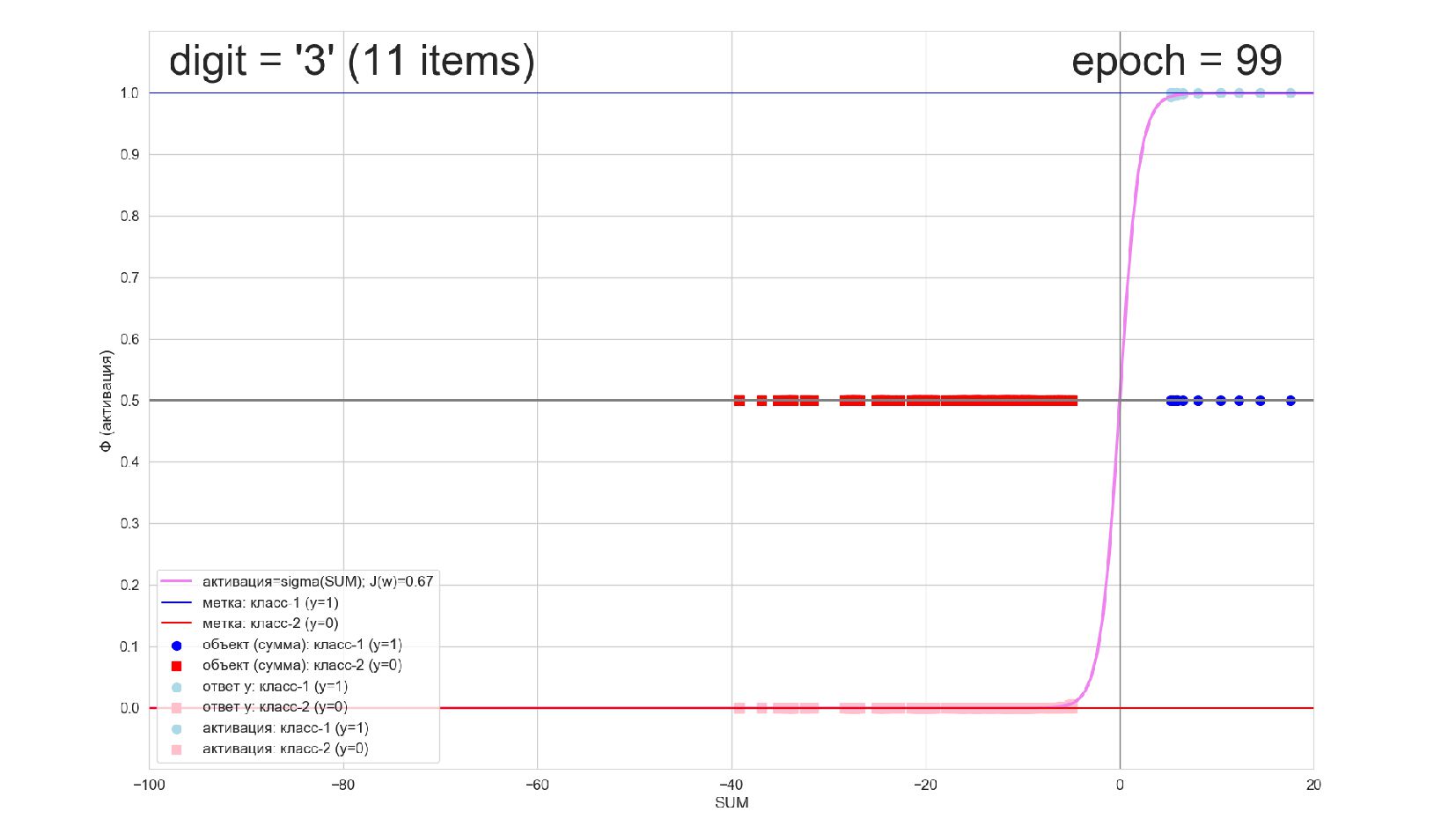
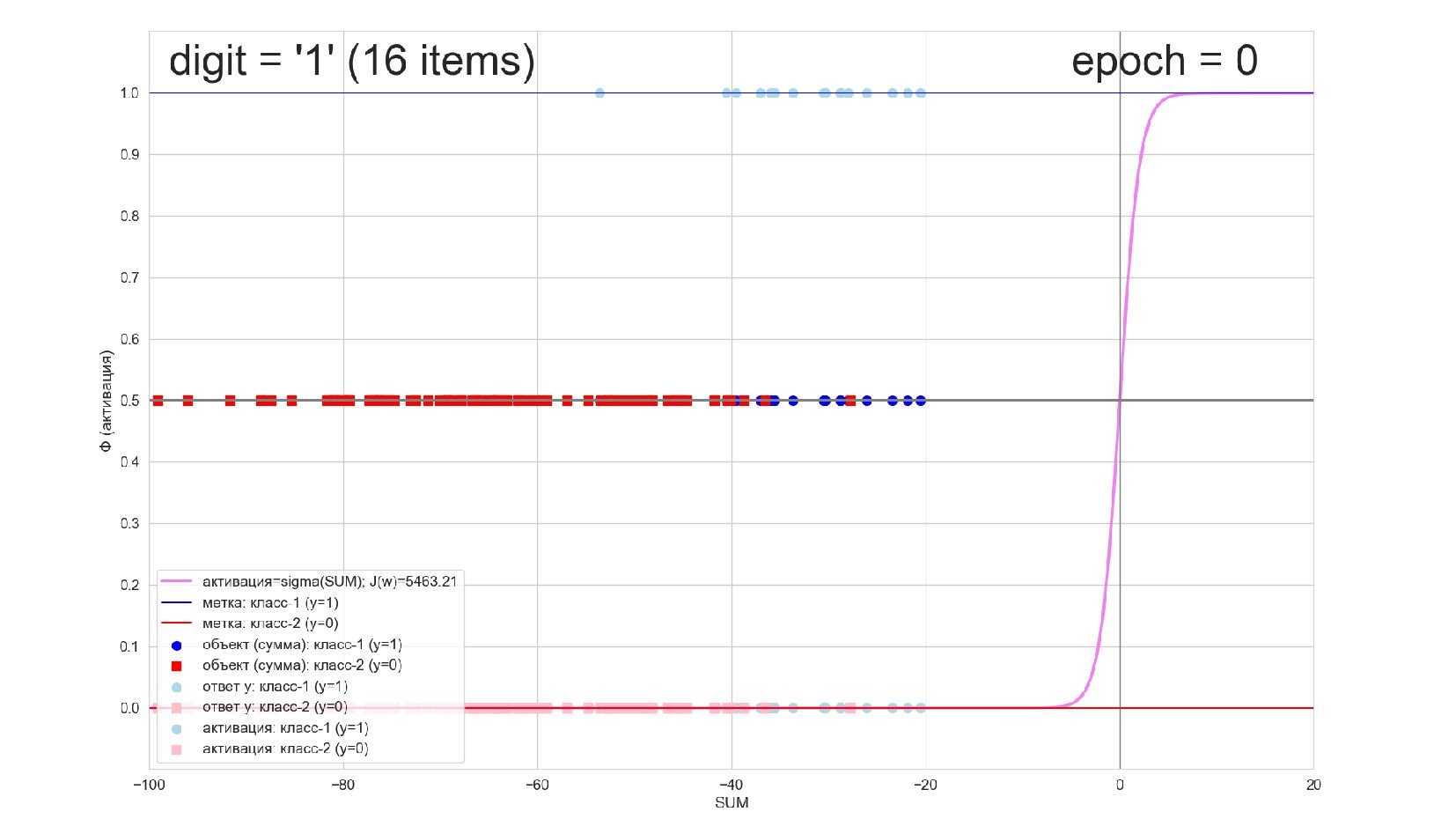
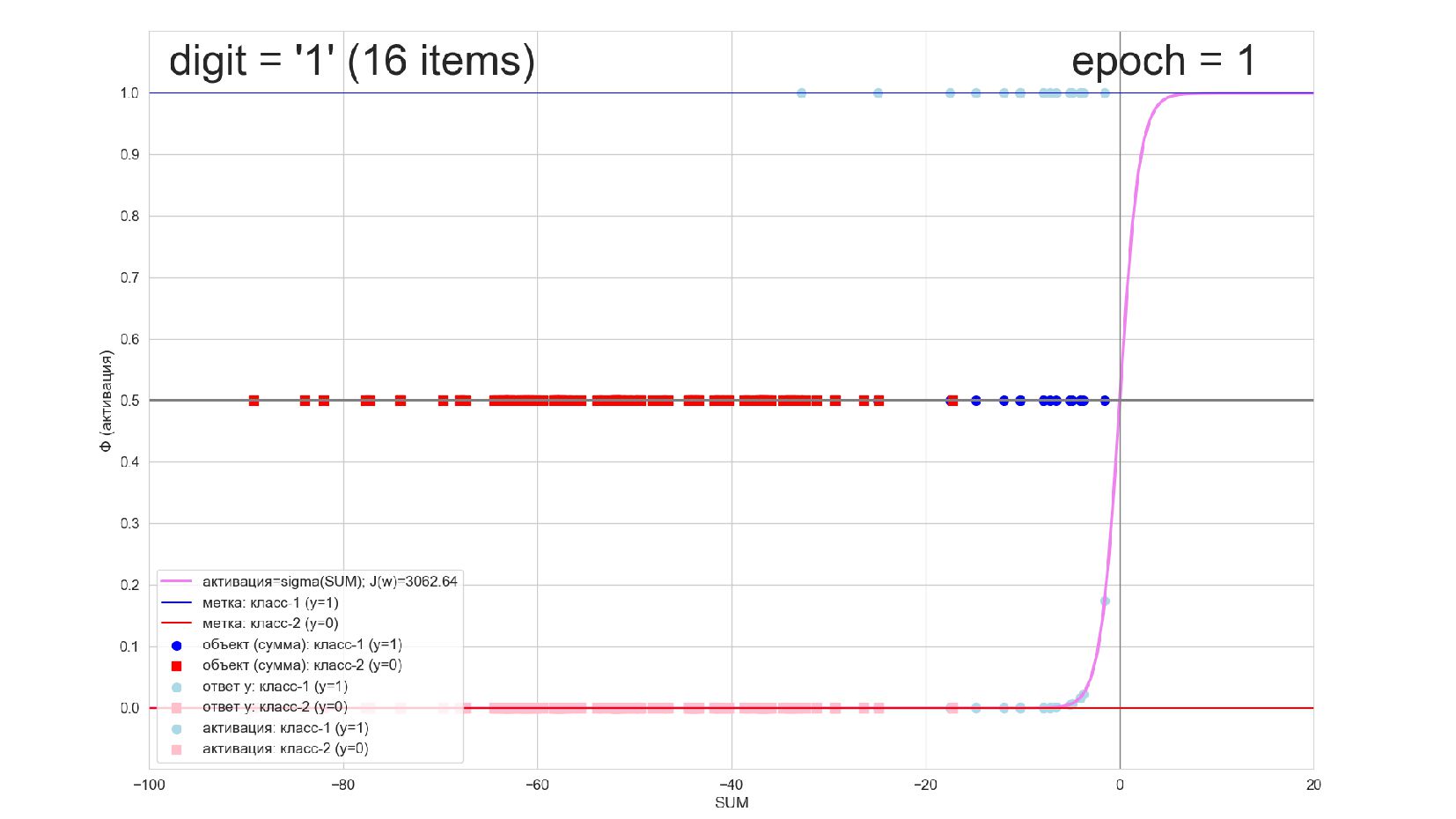
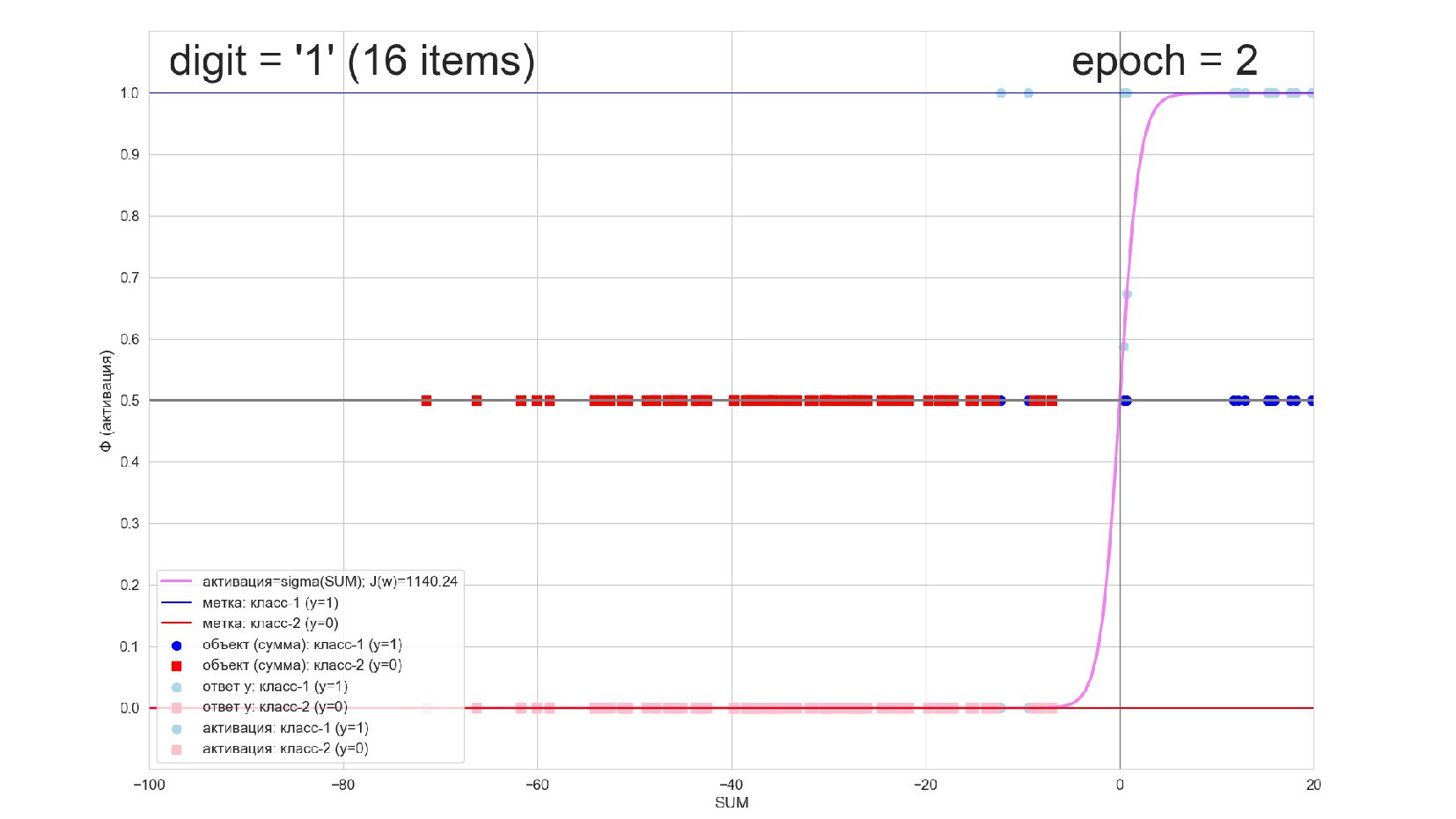
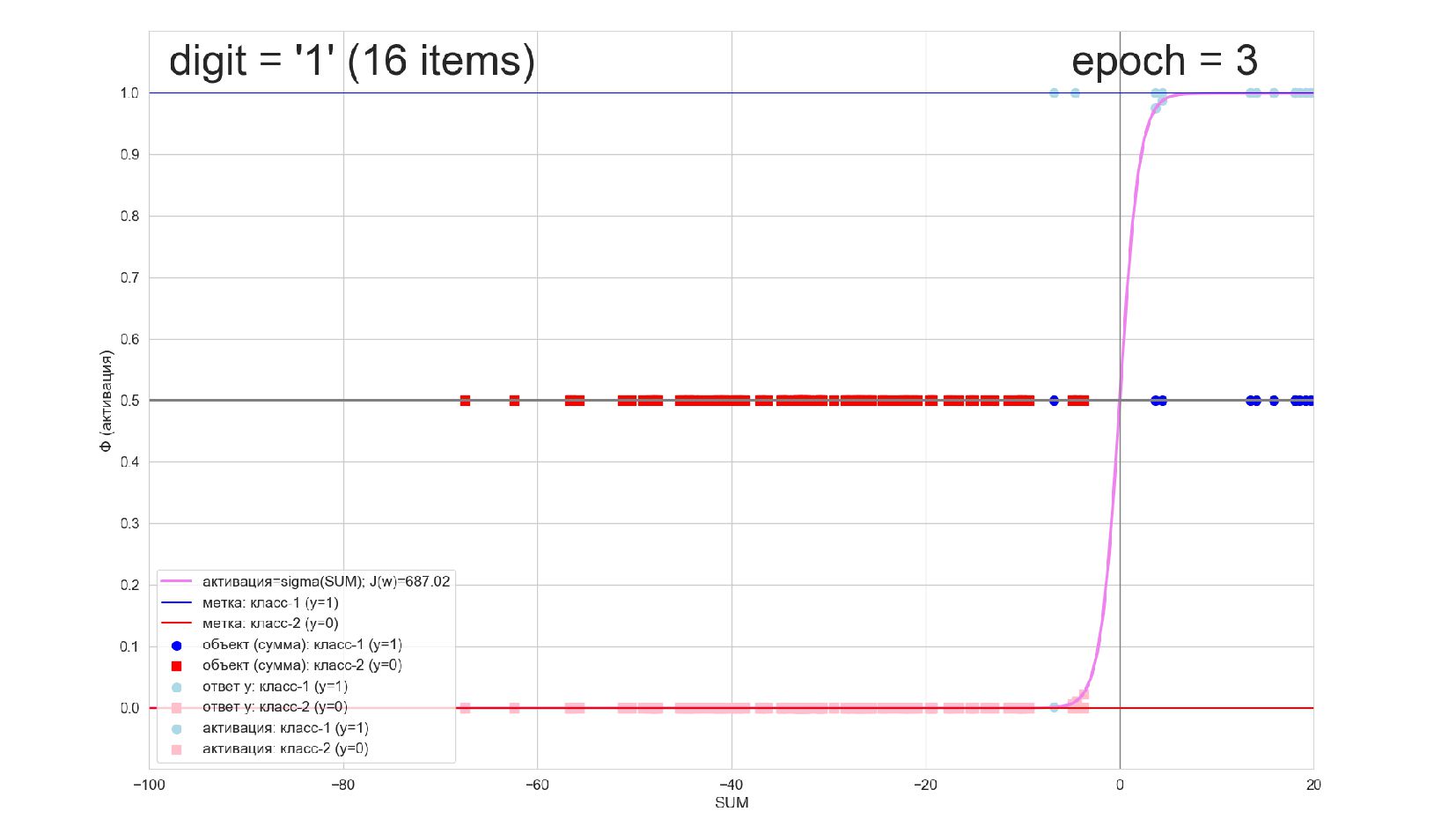
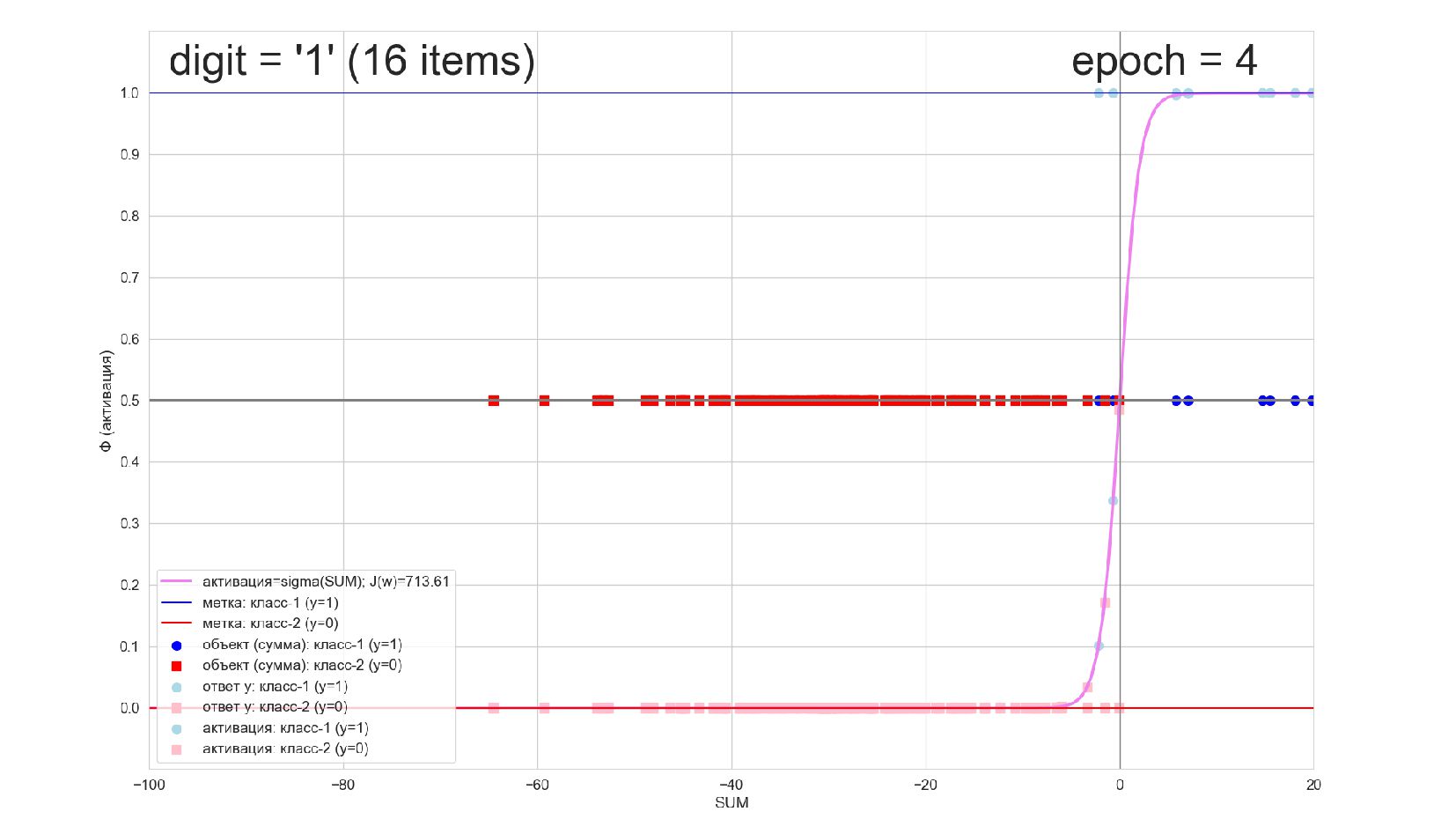
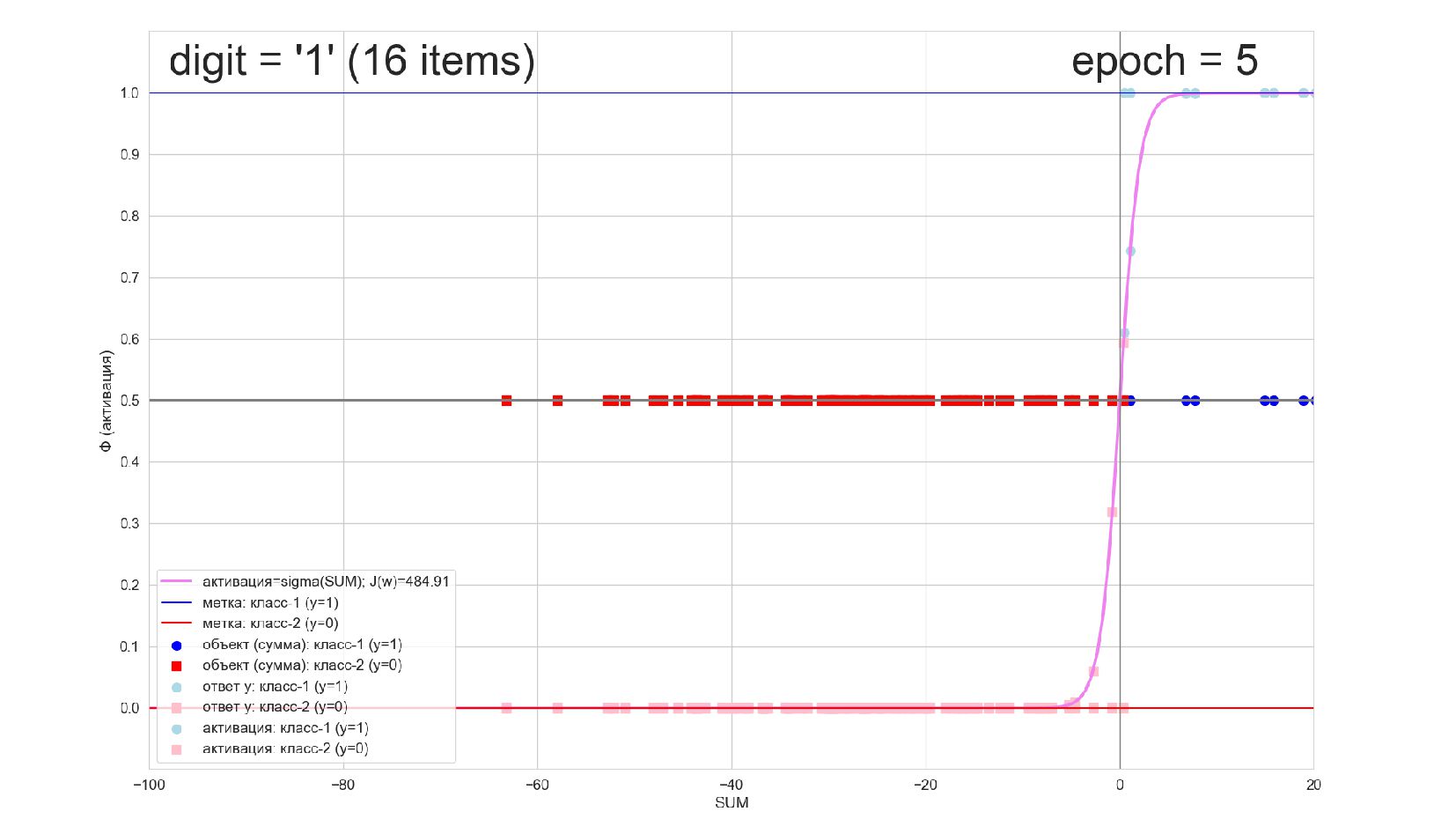
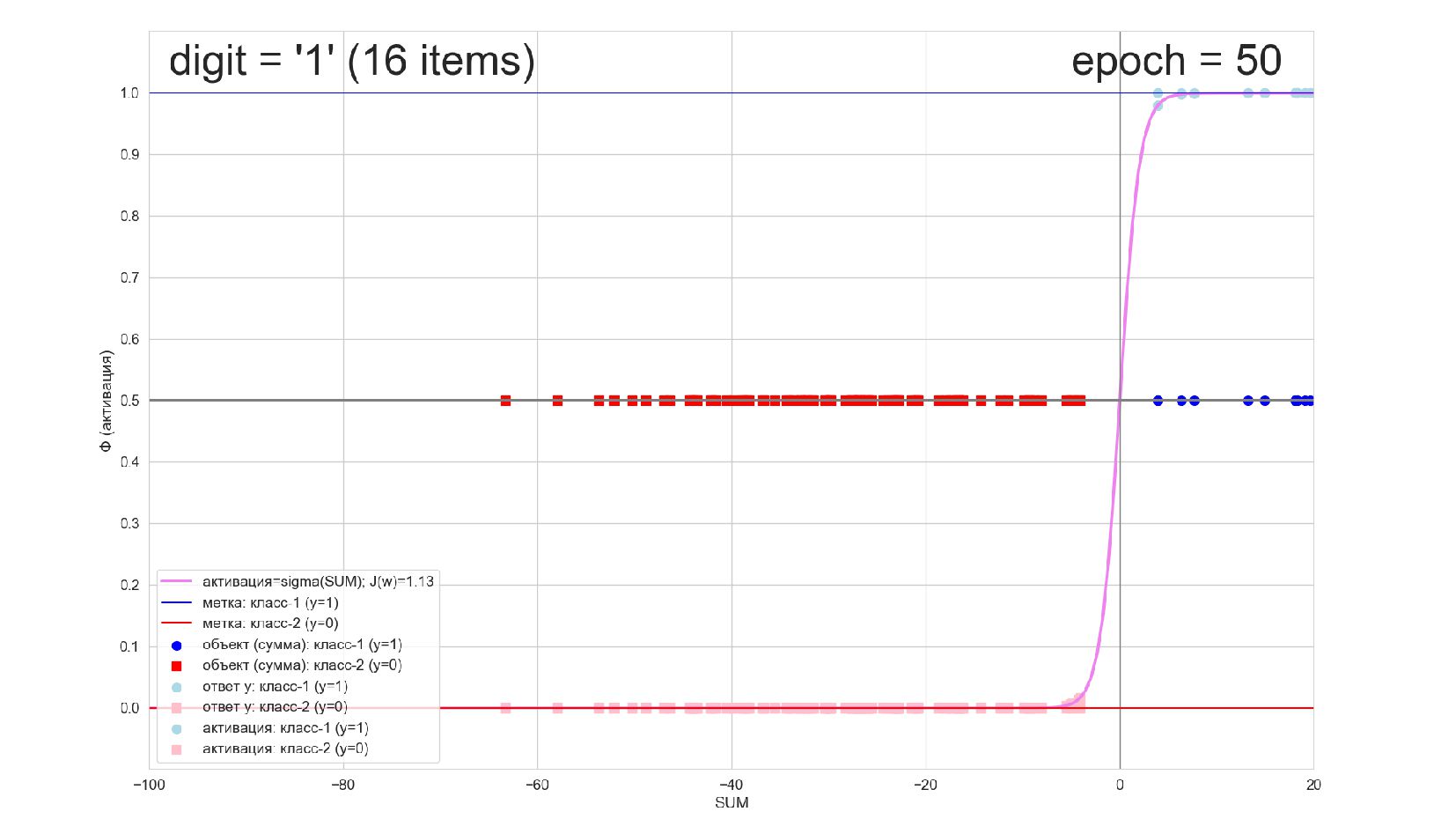
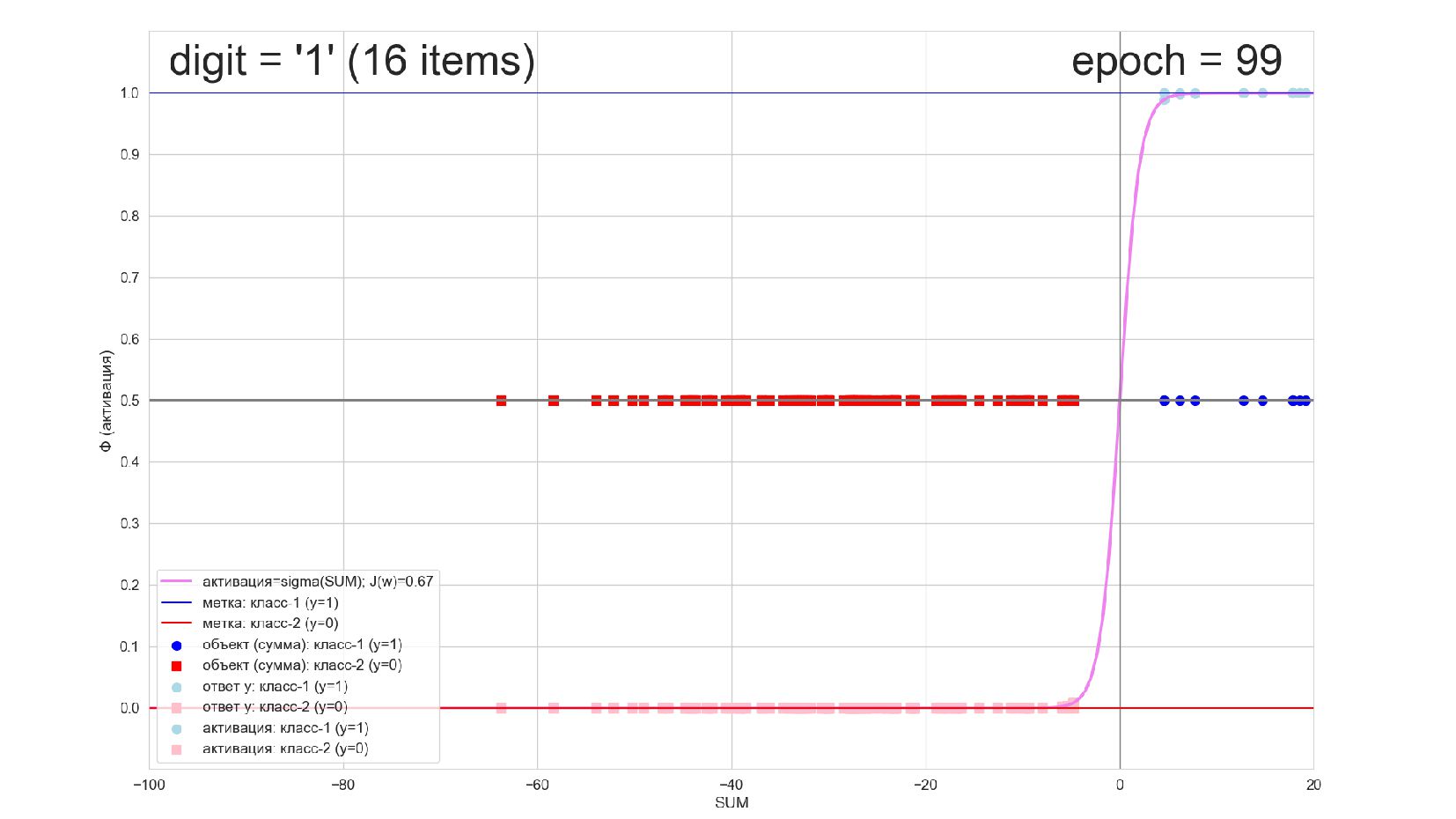
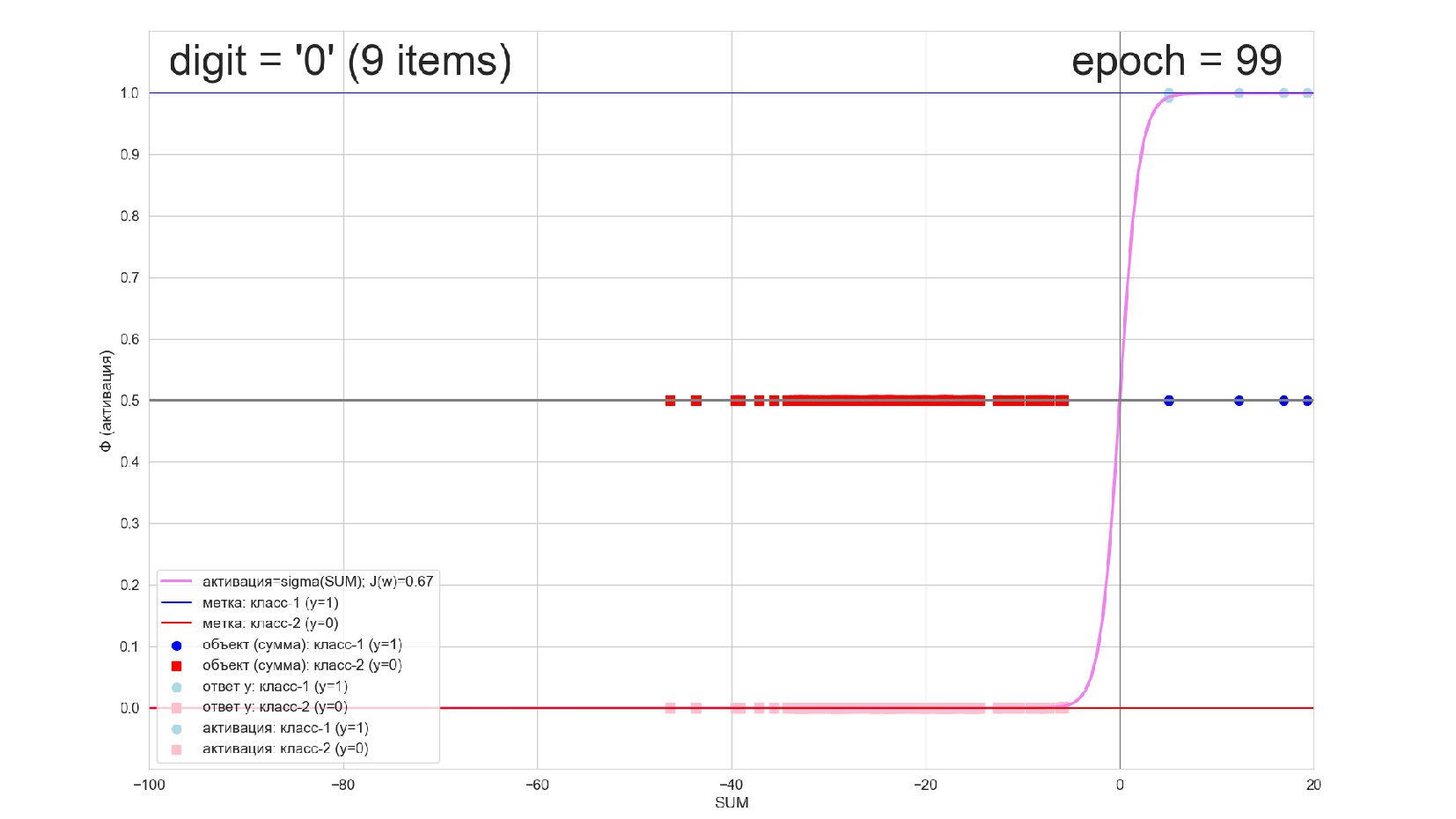
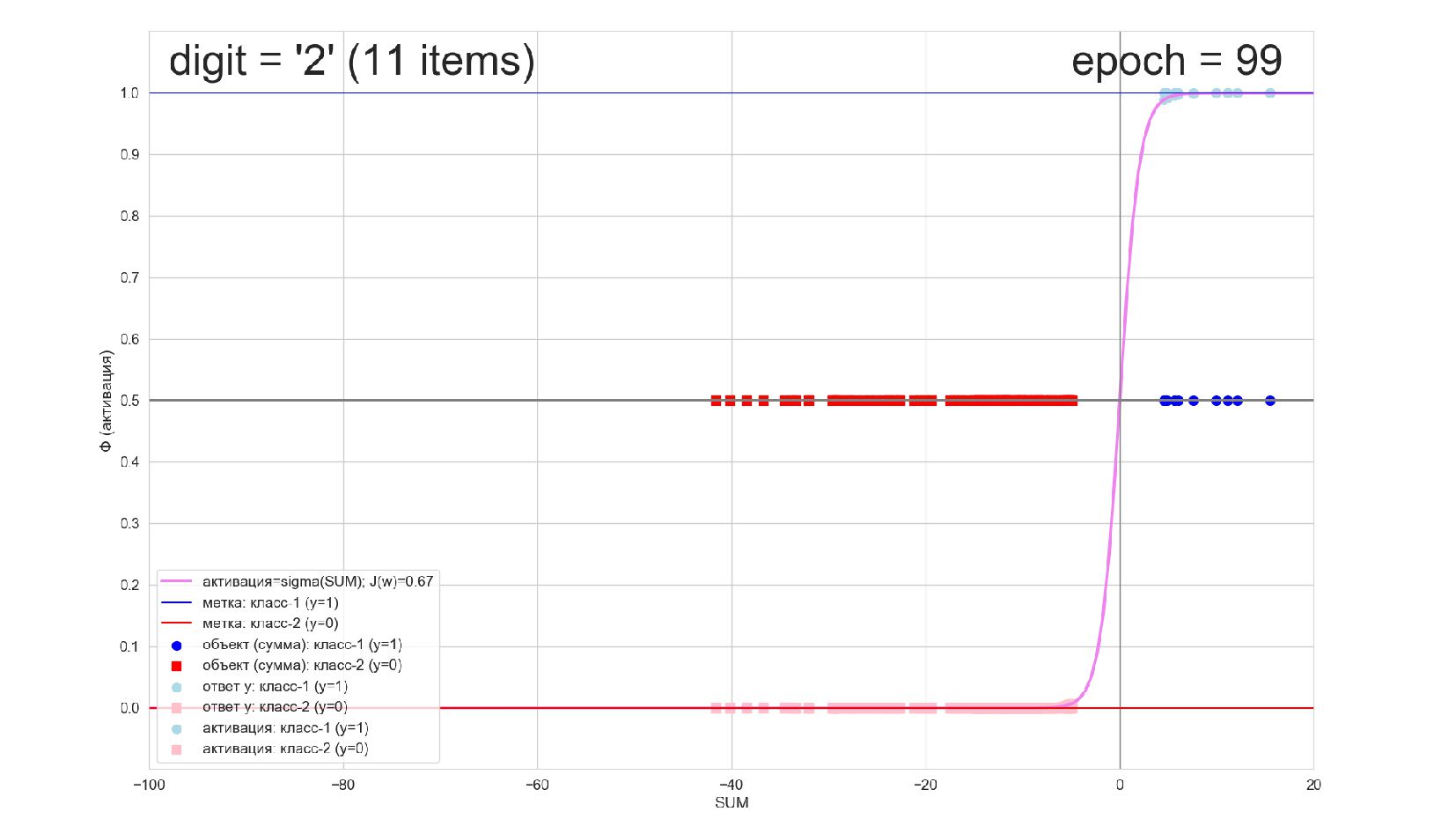
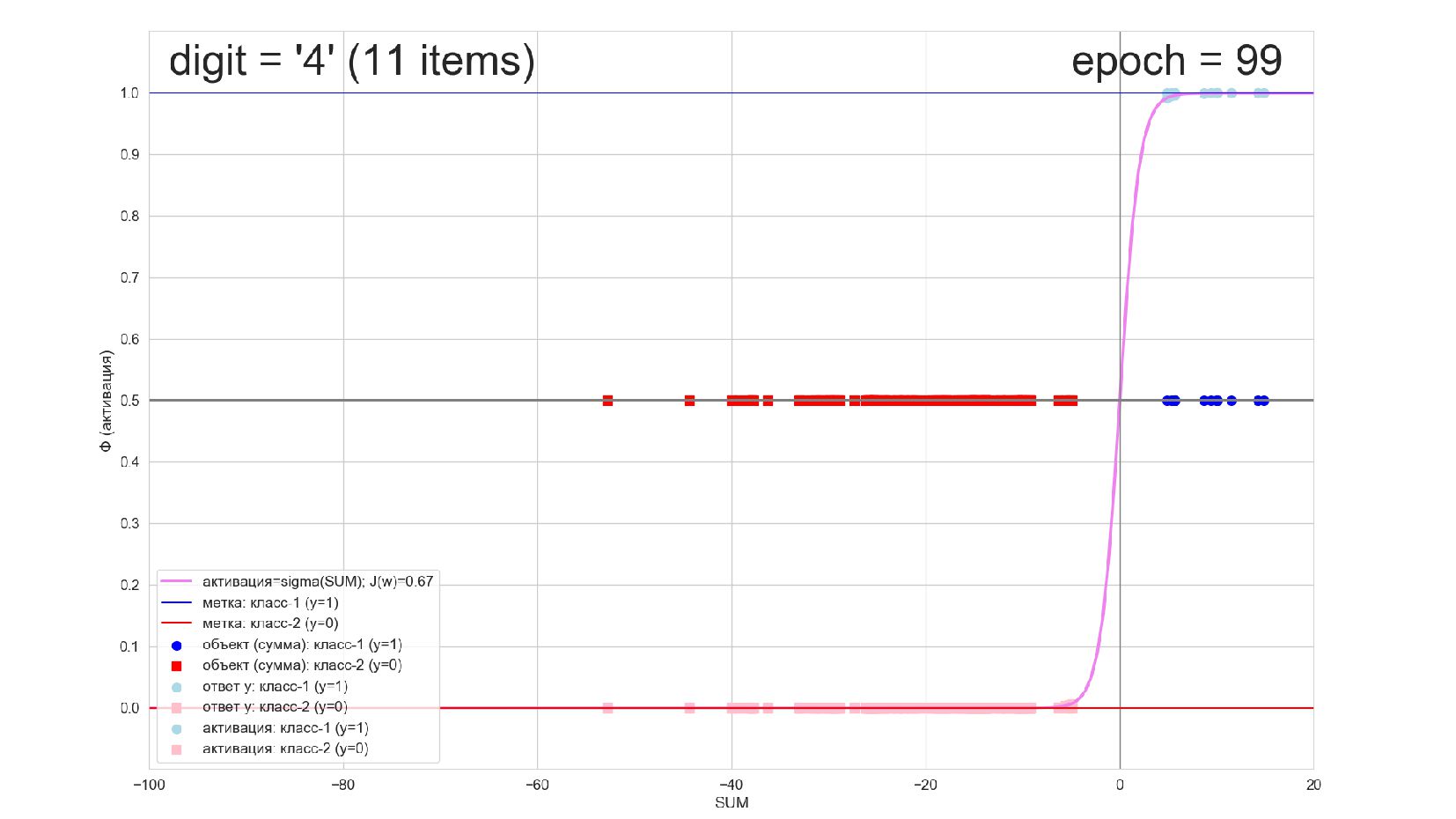
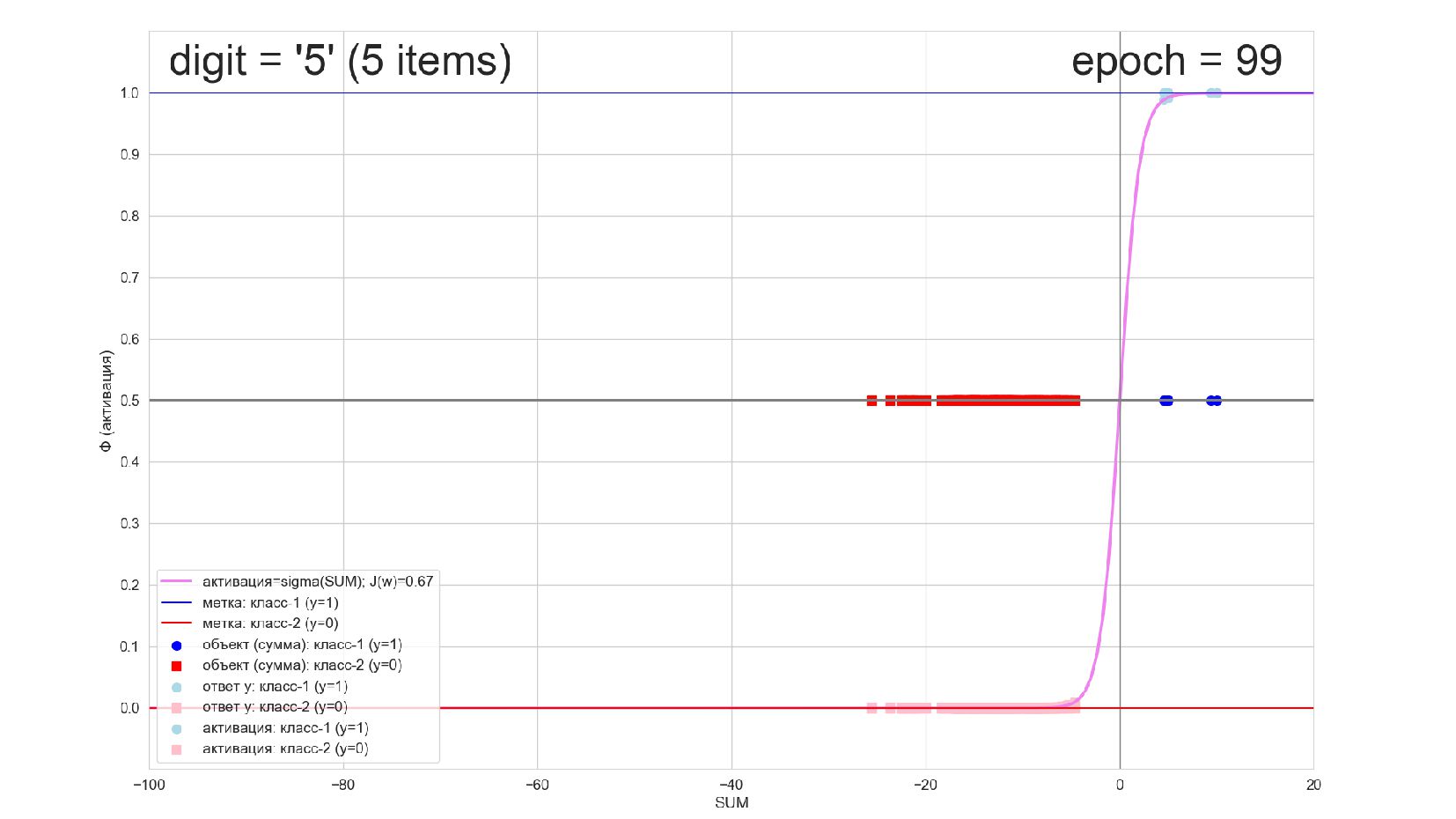
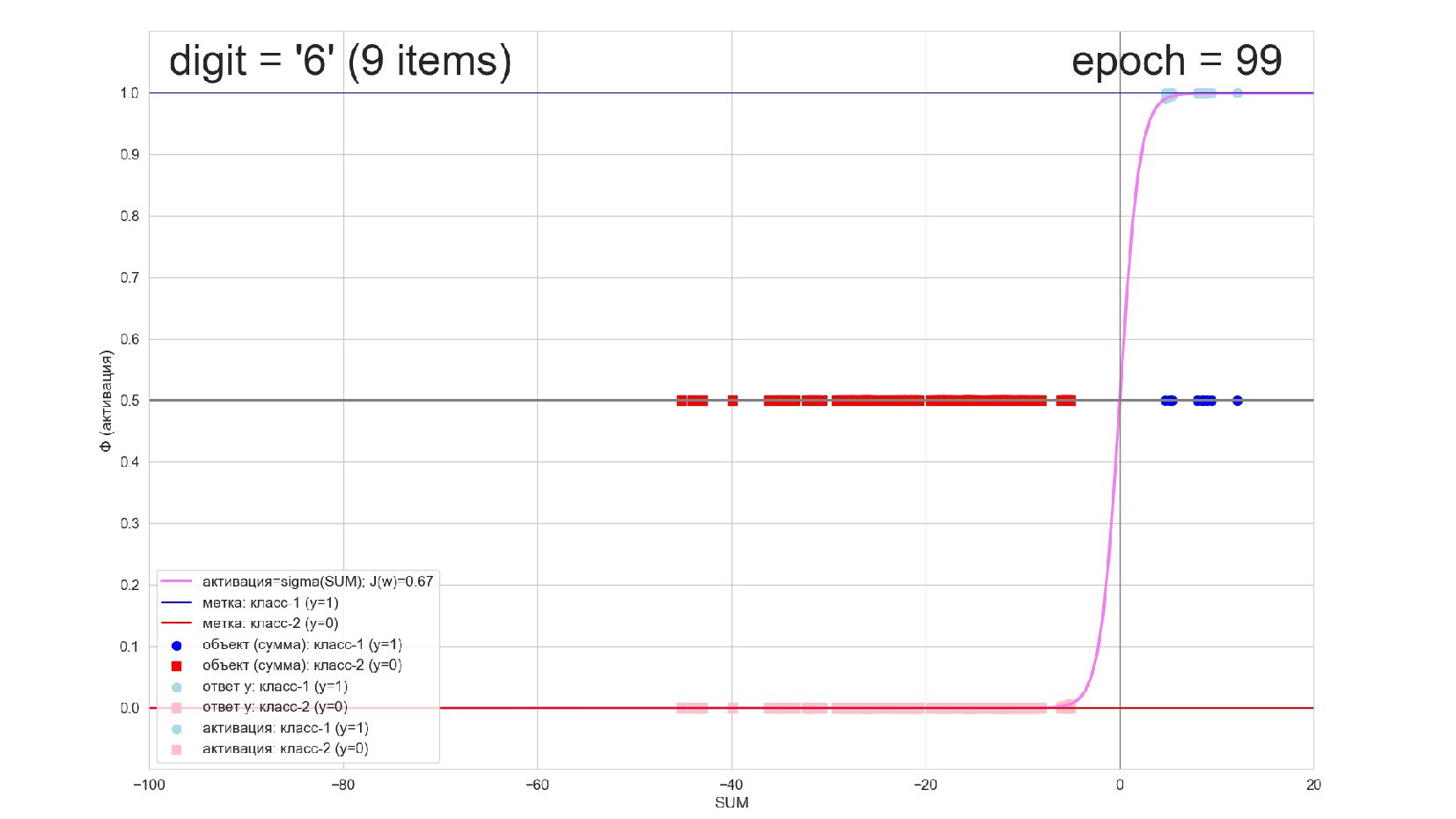
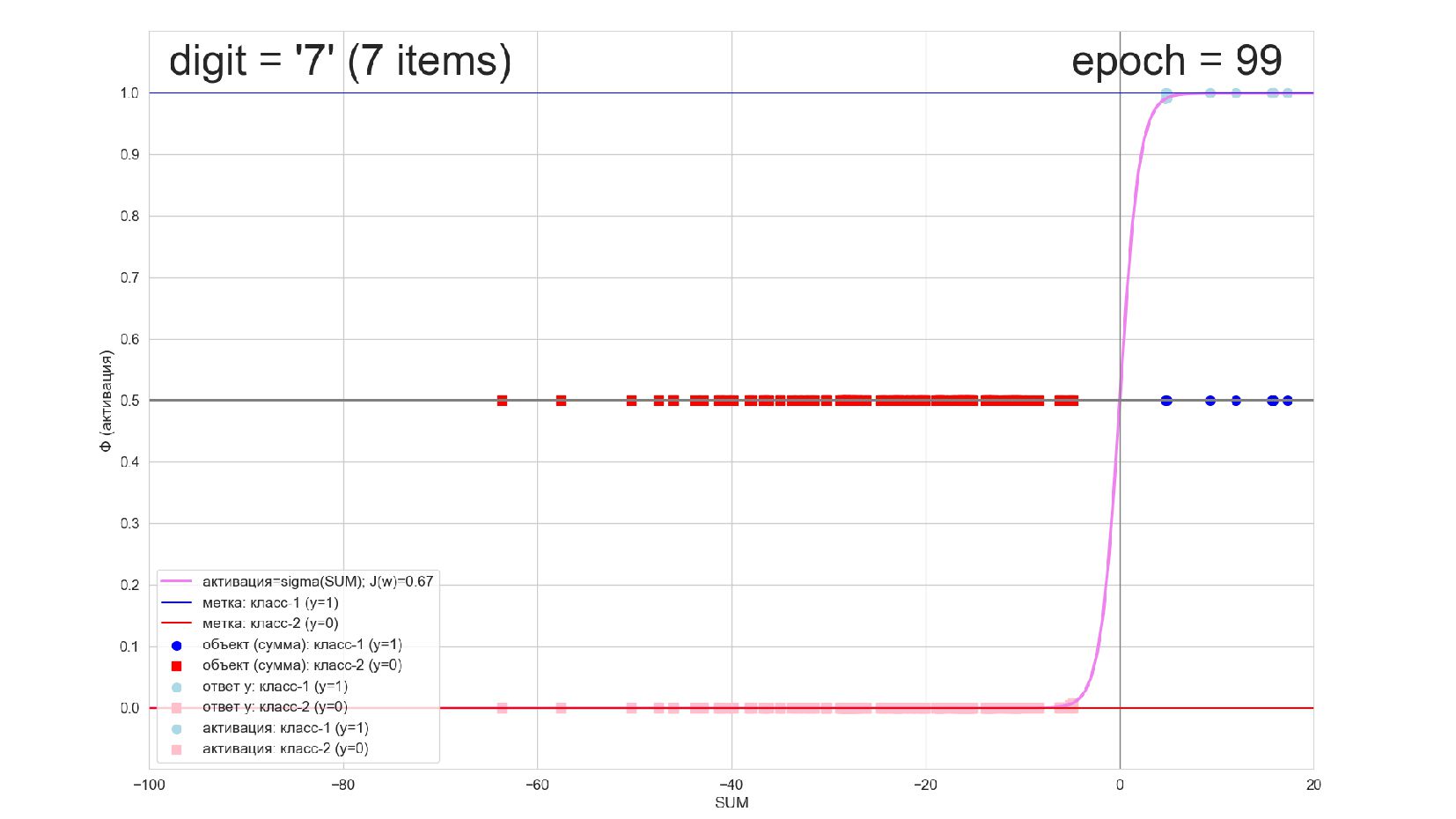
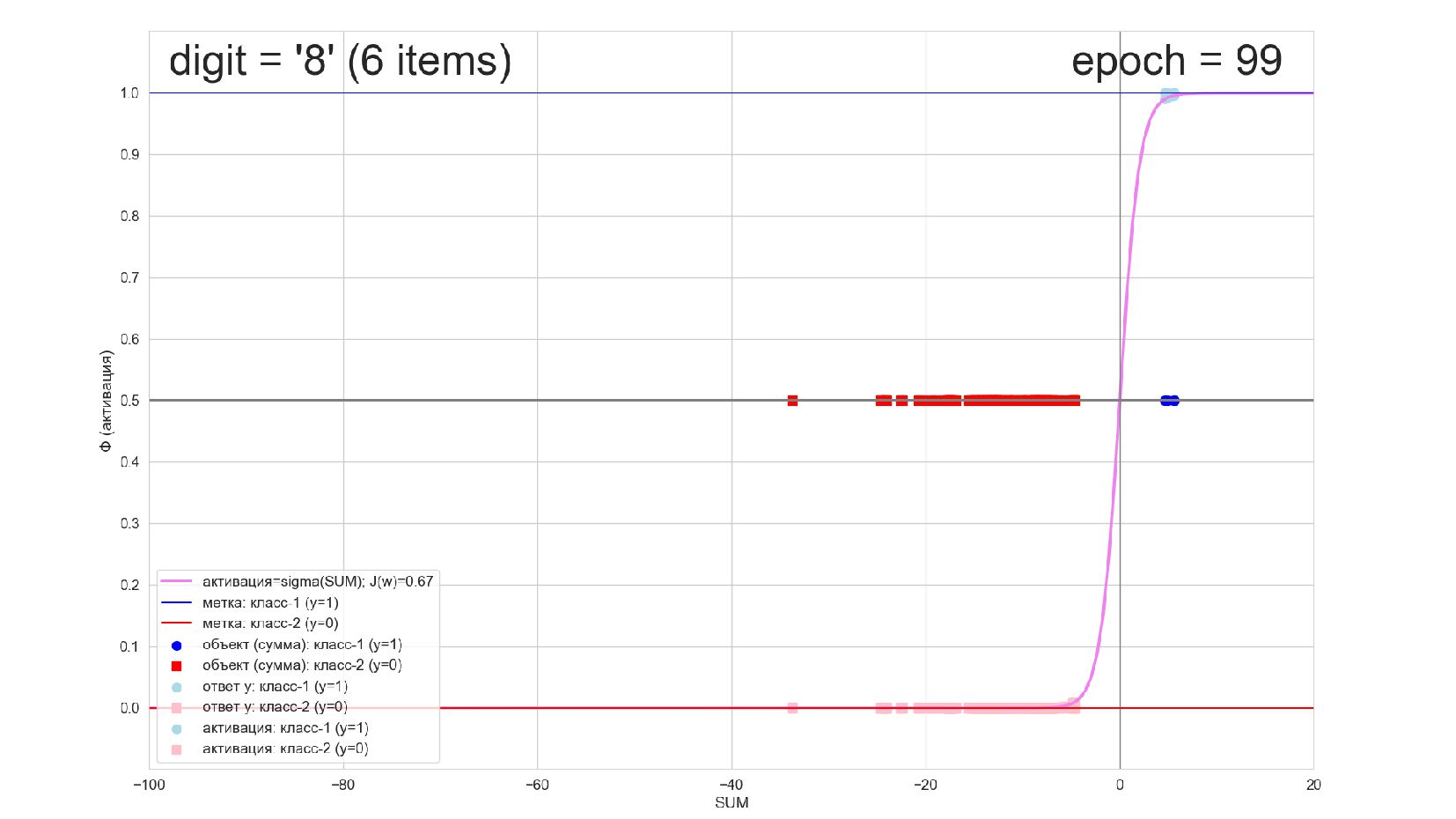
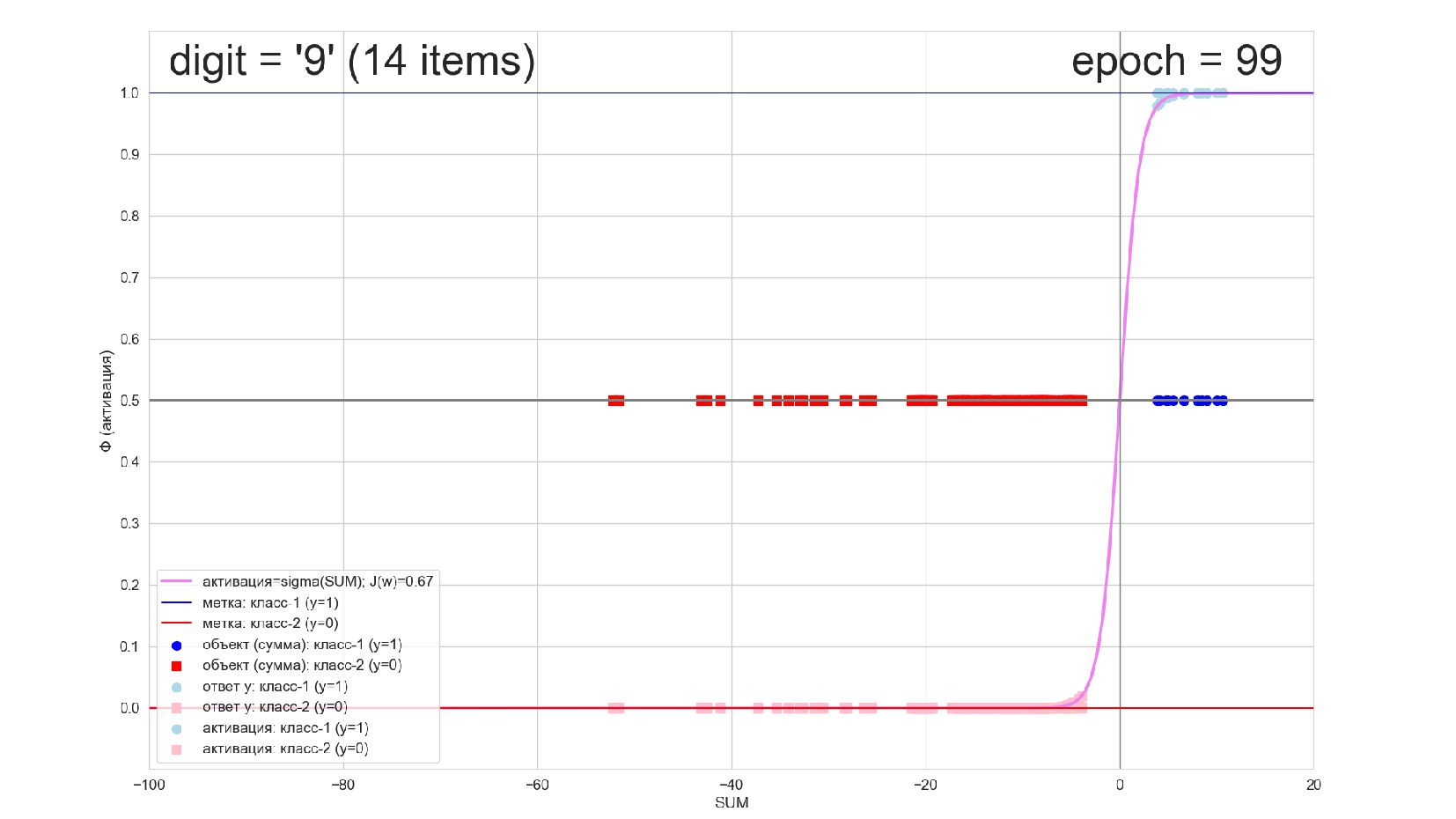
-- визуализация внутренней кухни процесса обучения: как нейрон делит множество символов на "цифра X"-"НЕ цифра X" в 784-мерном пространстве (схлопнутом во взвешенную сумму)
- Самостоятельно
- Бонус: код PyTorch (не помню уже, рабочий ли он)
первый вариант лекции: 29.05.2020
https://vk.com/video53223390_456239477
https://www.youtube.com/watch?v=Rl9CZX3R-38
https://www.youtube.com/playlist?list=PLSu-UfrQJjQky3LrVLb3hnJ7cnPxjZUQP
обновлено: 27.05.2021
https://1i7.livejournal.com/155603.html
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![# весовые коэффициенты #W = tf.Variable(tf.zeros([1, 1])) #w0 = tf.Variable(tf.zeros([1]))](https://files.speakerdeck.com/presentations/a4fed87d1f814cf087124bb3bf31203f/slide_27.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![# весовые коэффициенты #W = tf.Variable(tf.zeros([2, 1])) #w0 = tf.Variable(tf.zeros([1]))](https://files.speakerdeck.com/presentations/a4fed87d1f814cf087124bb3bf31203f/slide_59.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![# весовые коэффициенты #W = tf.Variable(tf.zeros([1, 1], dtype=tf.float64), dtype=tf.float64) #w0](https://files.speakerdeck.com/presentations/a4fed87d1f814cf087124bb3bf31203f/slide_85.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![# весовые коэффициенты W = tf.Variable(tf.zeros([2, 1])) w0 = tf.Variable(tf.zeros([1]))](https://files.speakerdeck.com/presentations/a4fed87d1f814cf087124bb3bf31203f/slide_108.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
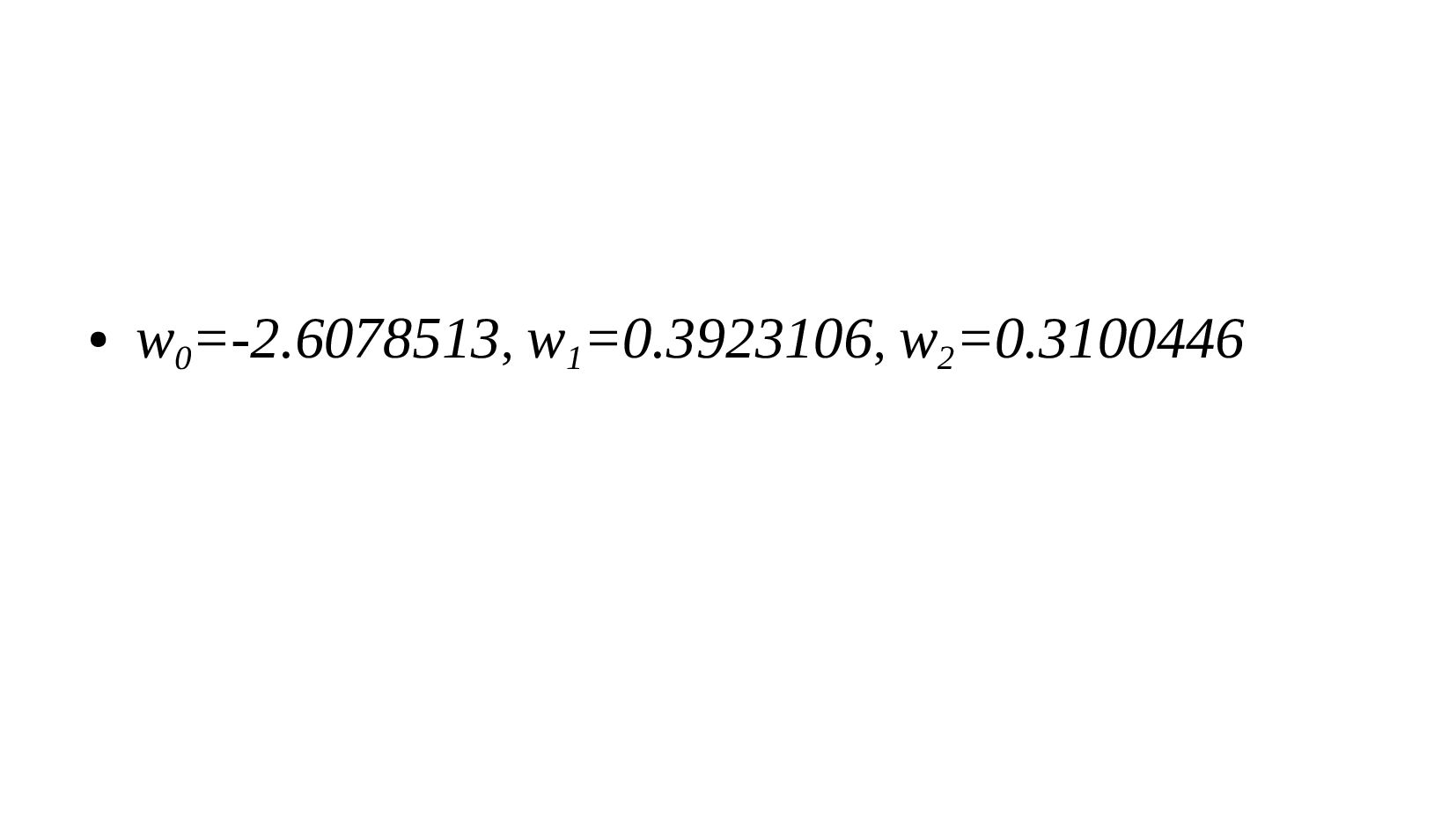{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Весовые коэффициенты (уже интереснее) # слой-1 #W_1 = tf.Variable(tf.zeros([1, 2]))](https://files.speakerdeck.com/presentations/a4fed87d1f814cf087124bb3bf31203f/slide_130.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![print("labels:") print(train_labels[:5]) labels: [1 0 1 4 0] print("one-hot labels:")](https://files.speakerdeck.com/presentations/a4fed87d1f814cf087124bb3bf31203f/slide_168.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}