reserved. Program Agenda • Introduction • Inside Hadoop! • Integration with MySQL • Facebook's usage of MySQL & Hadoop • Twitter's usage of MySQL &Hadoop
reserved. Introduction • 12 million product installations • 65,000 downloads each day • Part of the rapidly growing open source LAMP stack • MySQL Commercial Editions Available MySQL
reserved. Introduction • Highly scalable Distributed Framework o Yahoo! has a 4000 node cluster! • Extremely powerful in terms of computation o Sorts a TB of random integers in 62 seconds! Hadoop
reserved. Introduction • A scalable system for data storage and processing. • Fault tolerant • Parallelizes data processing across many nodes • Leverages its distributed file system (HDFS)* to cheaply and reliably replicate chunks of data. Hadoop is ..
reserved. Introduction • Yahoo: Ad Systems and Web Search. • Facebook: Reporting/analytics and machine learning. • Twitter: Data warehousing, data analysis. • Netflix: Movie recommendation algorithm uses Hive ( which uses Hadoop, HDFS & MapReduce underneath) Who uses Hadoop?
reserved. Introduction MySQL Hadoop Data Capacity TB+ (may require sharding) PB+ Data per query GB? PB+ Read/Write Random read/write Sequential scans, Append - only Query Language SQL Java MapReduce, scripting languages, Hive QL Transaction Yes No Indexes Yes No Latence Sub-second (hopefully) Minutes to hours Data structure Structured Structured or unstructured MySQL Vs Hadoop Courtesy: Leveraging Hadoop to Augment MySQL Deployments, Sarah Sproehnle, Cloudera, 2010
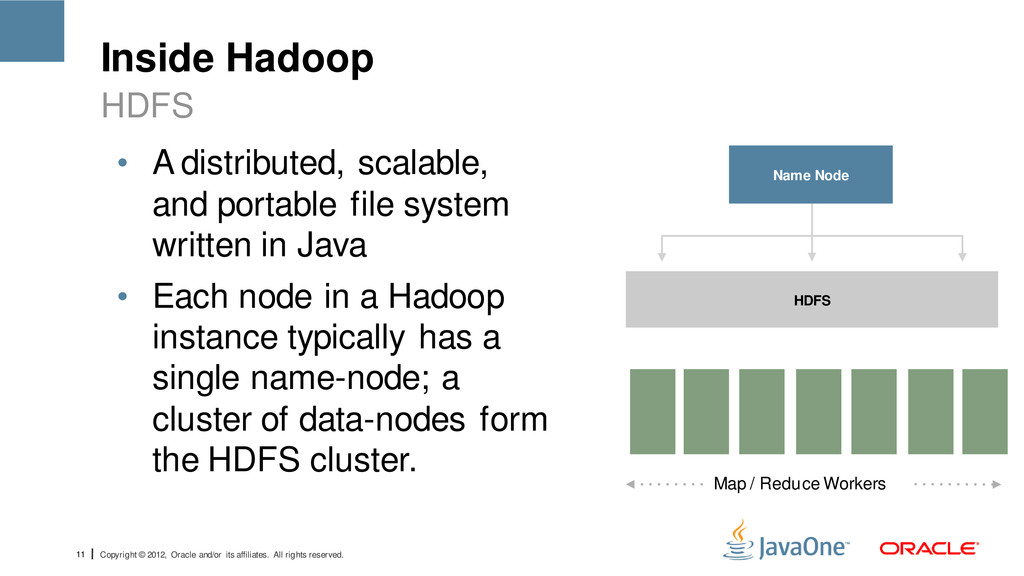
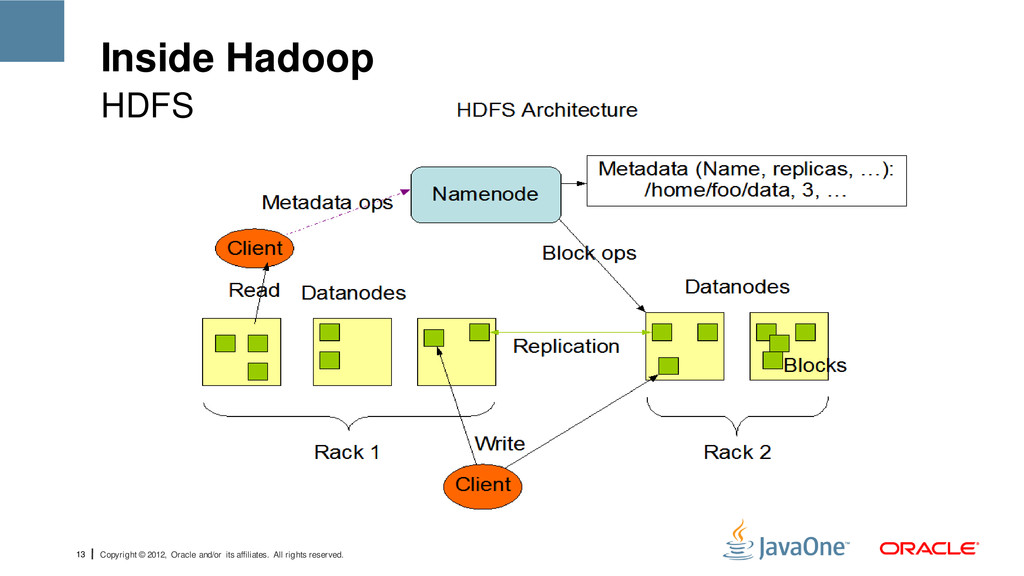
reserved. Inside Hadoop • A distributed, scalable, and portable file system written in Java • Each node in a Hadoop instance typically has a single name-node; a cluster of data-nodes form the HDFS cluster. HDFS Name Node HDFS Map / Reduce Workers
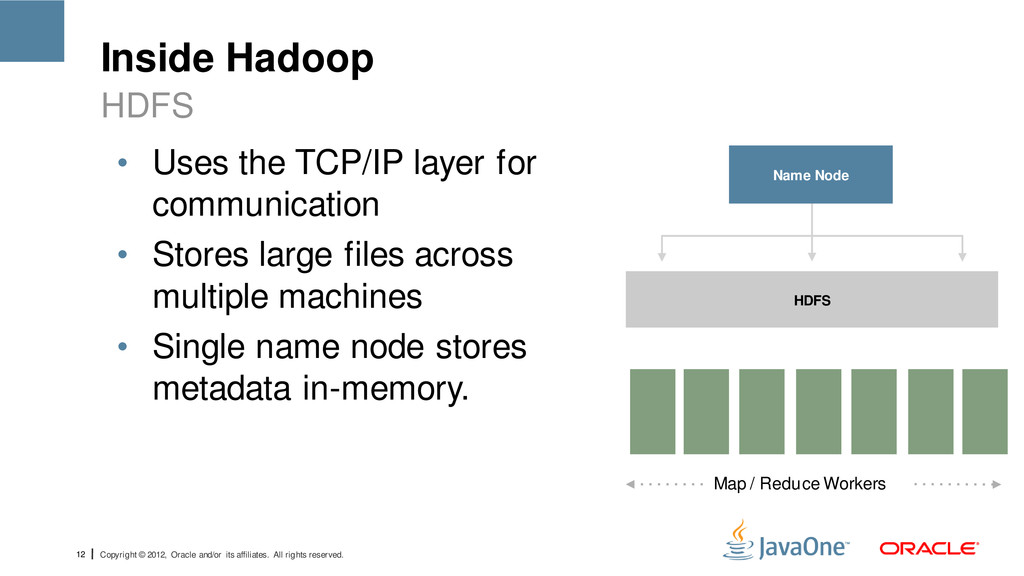
reserved. Inside Hadoop • Uses the TCP/IP layer for communication • Stores large files across multiple machines • Single name node stores metadata in-memory. HDFS Name Node HDFS Map / Reduce Workers
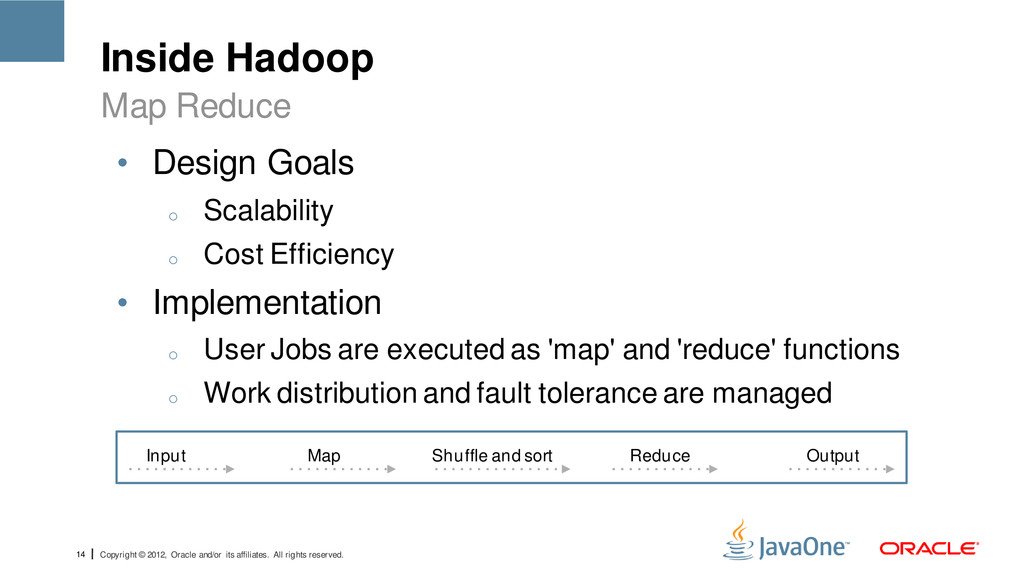
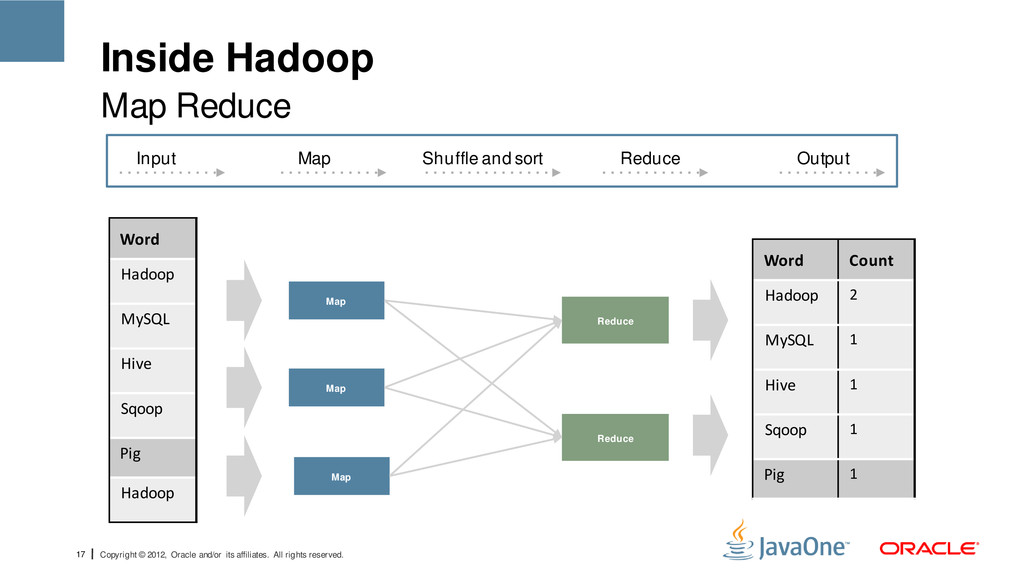
reserved. Inside Hadoop • Design Goals o Scalability o Cost Efficiency • Implementation o User Jobs are executed as 'map' and 'reduce' functions o Work distribution and fault tolerance are managed Map Reduce Input Map Shuffle and sort Reduce Output
reserved. Inside Hadoop • Map o Map Reduce job splits input data into independent chunks o Each chunk is processed by the map task in a parallel manner o Generic key-value computation Map Reduce Input Map Shuffle and sort Reduce Output
reserved. Inside Hadoop • Reduce o Data from data nodes is merge sorted so that the key-value pairs for a given key are contiguous o The merged data is read sequentially and the values are passed to the reduce method with an iterator reading the input file until the next key value is encountered Map Reduce Input Map Shuffle and sort Reduce Output
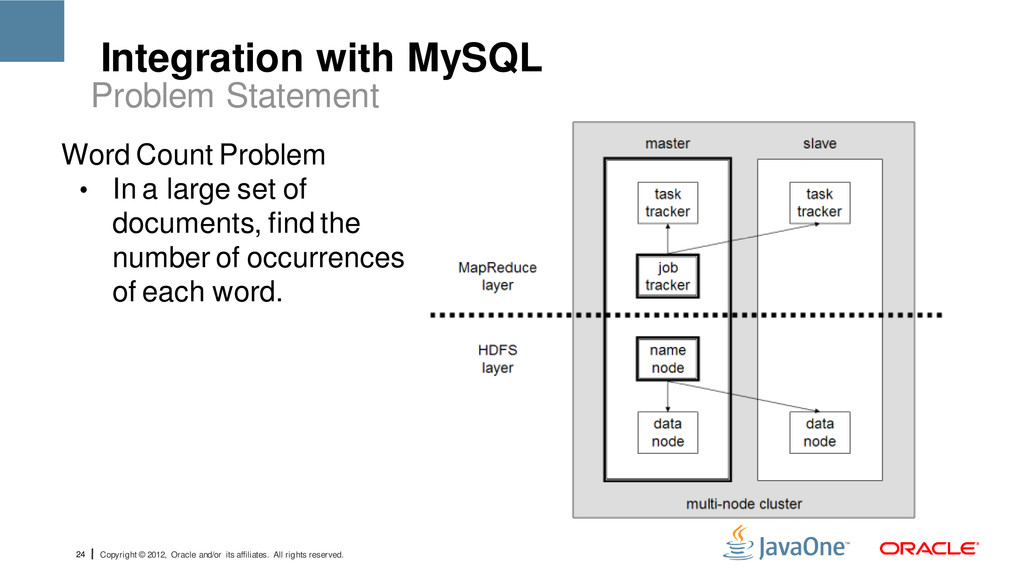
reserved. Inside Hadoop • Framework consists of a single master JobTracker and one slave TaskTracker per cluster-node. • Master o Schedules the jobs' component tasks on the slaves o Monitors the jobs o Re-executes the failed tasks • Slave o Executes the tasks as directed by the master. How does hadoop use Map-Reduce
reserved. Inside Hadoop • Language support o Java, PHP, Hive, Pig, Python, Wukong (Ruby), Rhipe (R) . • Scales Horizontally • Programmer is isolated from individual failed tasks • Tasks are restarted on another node Why Map Reduce ?
reserved. Inside Hadoop • Not a good fit for problems that exhibit task-driven parallelism. • Requires a particular form of input - a set of (key, pair) pairs. • A lot of MapReduce applications end up sharing data one way or another. Map Reduce Limitations
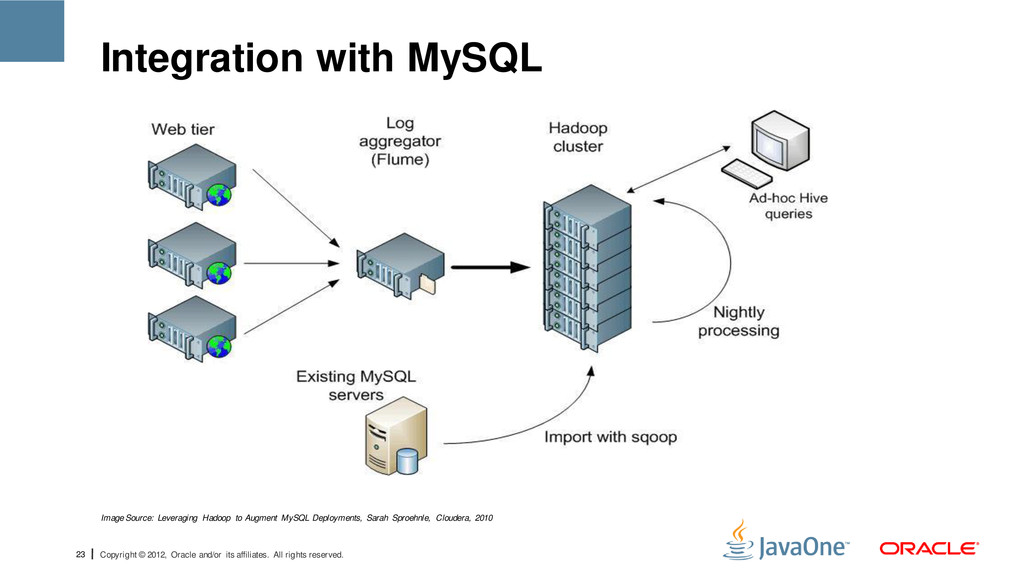
reserved. Integration with MySQL • The benefits of MySQL to developers is the speed, reliability, data integrity and scalability it provides. • It can successfully process large amounts of data (in petabytes). • But for applications that require a massive parallel processing we may need the benefits of a parallel processing system, such as hadoop.
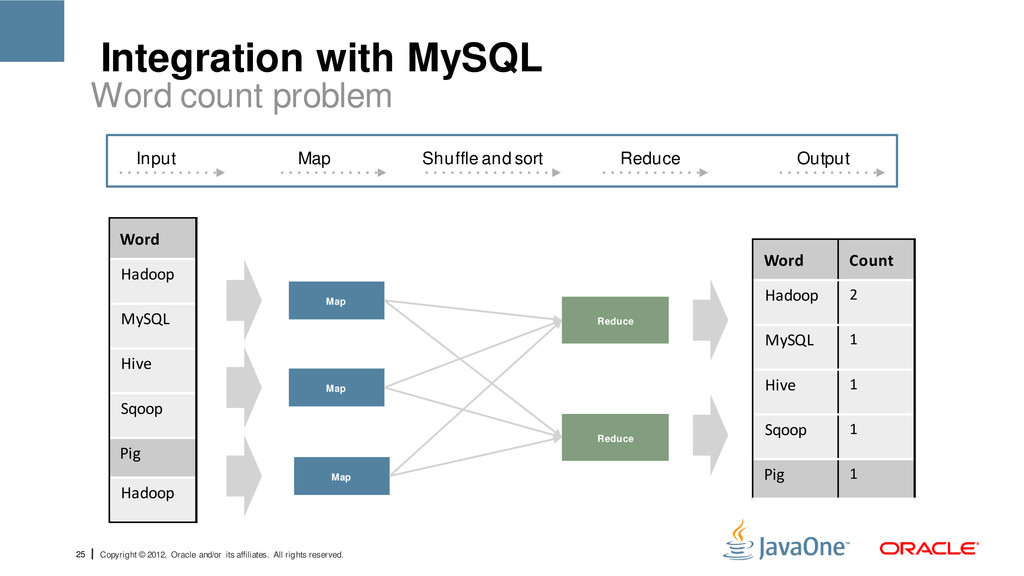
reserved. Integration with MySQL Word count problem Word Hadoop MySQL Hive Sqoop Pig Hadoop Reduce Map Map Map Reduce Word Count Hadoop 2 MySQL 1 Hive 1 Sqoop 1 Pig 1 Input Map Shuffle and sort Reduce Output
reserved. Integration with MySQL Mapping Map(key, value) foreach(word in the value) output(word,1) Key and Value represent a row of data: key is the byte office, value in a line. Intermediate Output <word1>, 1 <word2>, 1 <word3>, 1
reserved. Integration with MySQL Reducing Reduce(key, list) sum the list Output(key, sum) Hadoop aggregates the keys and calls reduce for each unique key: <word1>, (1,1,1,1,1,1…1) <word2>, (1,1,1) <word3>, (1,1,1,1,1,1) . Final result: <word1>, 45823 <word2>, 1204 <word3>, 2693
reserved. Facebook's usage of MySQL & Hadoop • Facebook collects TB of data everyday from around 800 million users. • MySQL handles pretty much every user interaction: likes, shares, status updates, alerts, requests, etc. • Hadoop/Hive Warehouse – 4800 cores, 2 PetaBytes (July 2009) – 4800 cores, 12 PetaBytes (Sept 2009) • Hadoop Archival Store – 200 TB
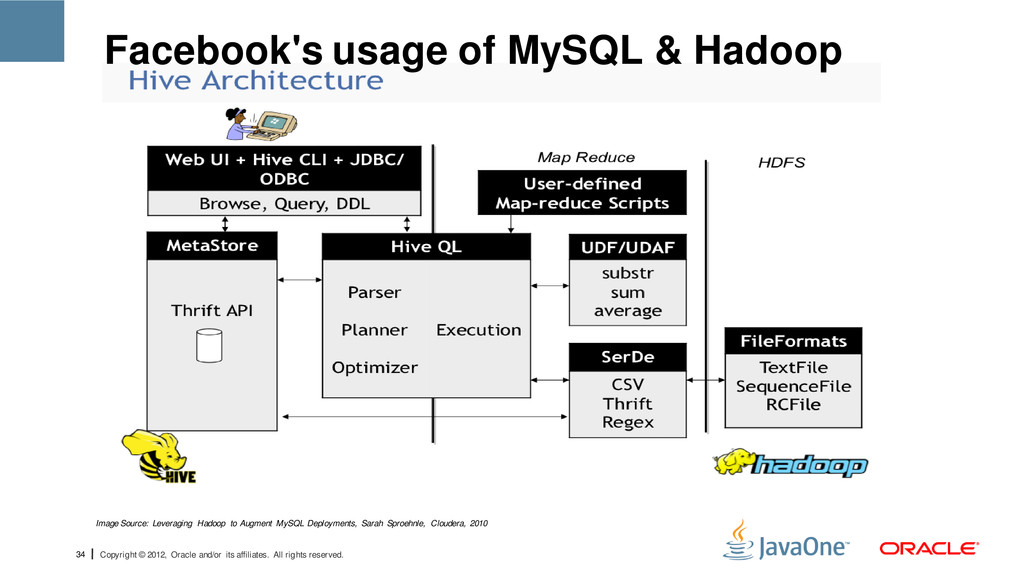
reserved. Facebook's usage of MySQL & Hadoop • Data warehouse system for Hadoop. • Facilitates easy data summarization. • Hive translates HiveQL to MapReduce code. • Querying o Provides a mechanism to project structure onto this data o Allows querying the data using a SQL-like language called HiveQL Hive
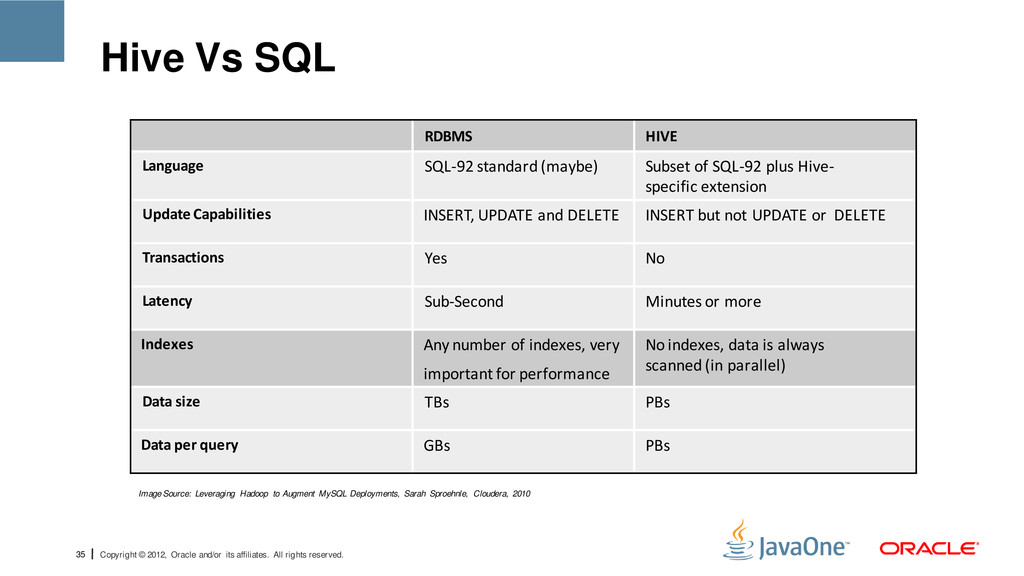
reserved. Hive Vs SQL RDBMS HIVE Language SQL-92 standard (maybe) Subset of SQL-92 plus Hive- specific extension Update Capabilities INSERT, UPDATE and DELETE INSERT but not UPDATE or DELETE Transactions Yes No Latency Sub-Second Minutes or more Indexes Any number of indexes, very important for performance No indexes, data is always scanned (in parallel) Data size TBs PBs Data per query GBs PBs Image Source: Leveraging Hadoop to Augment MySQL Deployments, Sarah Sproehnle, Cloudera, 2010
reserved. Hadoop Implementation • > 12 terabytes of new data per day! • Most stored data is LZ0 compressed • Uses Scribe to write logs to Hadoop o Scribe: a log collection framework created and open- sourced by Facebook. • Hadoop used for data warehousing, data analysis. At Twitter
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}