Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Elasticsearch第2回報告会資料 #elasticsearch
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
sakura818uuu
September 28, 2017
Technology
1.1k
1
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Elasticsearch第2回報告会資料 #elasticsearch
Elasticsearch 5.6.1
- 検索する手順を追う
- セキュリティ
- 速度計測
sakura818uuu
September 28, 2017
More Decks by sakura818uuu
See All by sakura818uuu
ITと知的財産の勉強会_発表資料
sakura818uuu
0
96
IRReading2022fall 発表資料
sakura818uuu
0
220
吉祥寺.pm LT 「IR Reading 2019秋に行ってきました」
sakura818uuu
0
940
料理動画アプリ「クラシル」の検索について.pdf
sakura818uuu
3
5.1k
月刊「検索」10月号
sakura818uuu
0
250
Other Decks in Technology
See All in Technology
Network Firewallやっていき!
news_it_enj
0
170
Devsumi 2026 Summer 人もAIも使える共通基盤を事業の加速装置にする~デザインシステム運用に学ぶ組織レバレッジ~ 渡辺 凌央
legalontechnologies
PRO
1
230
関数型の考えを TypeScript に持ち込んで、テストしやすい純粋関数を増やす / Pure at the Core, Effects at the Edge: Bringing Functional Thinking into TypeScript
kaminashi
2
130
凡エンジニアがこの先生きのこるためには。〜TypeScript完全に理解したい〜
alchemy1115
2
310
DatabricksにおけるMCPソリューション
taka_aki
1
270
Terraform共通モジュールをチーム横断で“変えられる”運用へ ― リリースと適用の分離
kekke_n
1
3.3k
SREとQA 二人三脚で進めるSLO運用/sre-qa-slo
sugitak
0
830
CDKで書くECSのベストプラクティス、 改めて考え直す2026 #cdkconf2026
makies
3
760
実践!既存 Project への AI-Driven Development 適用〜 一ヶ月で Project 唯一のフロントエンドエンジニアを作り出せ〜
lycorptech_jp
PRO
0
200
しぶいSRE: サーバから見えない障害にどう向き合うか。ラストワンマイルのデバッグ実践 / Shibui SRE
kanny
13
6.5k
生成AI×AWS CDK×AWS FISで"振り返れる"ミニGameDayをつくろう
yoshimi0227
1
370
ruby.wasmとPicoRuby.wasmに対応した仮想DOMライブラリを作ってる話 #kaigieffect_kaigi
sue445
PRO
0
150
Featured
See All Featured
svc-hook: hooking system calls on ARM64 by binary rewriting
retrage
2
340
KATA
mclloyd
PRO
35
15k
Site-Speed That Sticks
csswizardry
13
1.3k
How to make the Groovebox
asonas
2
2.3k
BBQ
matthewcrist
89
10k
The SEO Collaboration Effect
kristinabergwall1
1
510
The Curious Case for Waylosing
cassininazir
1
430
Automating Front-end Workflow
addyosmani
1370
210k
What does AI have to do with Human Rights?
axbom
PRO
1
2.2k
Max Prin - Stacking Signals: How International SEO Comes Together (And Falls Apart)
techseoconnect
PRO
0
200
Design in an AI World
tapps
1
260
Raft: Consensus for Rubyists
vanstee
141
7.6k
Transcript
Elasticsearch 第2回報告会資料 sakura@818uuu 1
概要 • 検索する手順を追う • セキュリティ • 速度計測 *Elasticsearchのバージョンは5.6.1を使用しています 2
検索する手順を追う 3
検索する手順を追う 例えばこんな表データがあったとします。 id name text created_at (登録日時) 1 東京スカイツリーにいって隅田川の花火を みよう!
毎年7月に行われる隅田川花火大 会。東京スカイツリーでは … 2017-07-25 2 鎌倉・江ノ島でおいしいものをたくさん食べ るツアー 神奈川県を代表する観光スポット 鎌倉・江ノ島。特にしらす丼が有名 ですが、鎌倉野菜や … 2017-05-08 3 湯島のおいしいお魚ランチ 今年の夏に湯島に移転した「旬菜 なんてん」。ランチには煮魚定食や ミックスフライ定食… 2017-09-01 4
Elasticsearchに先程の表データを登録 する前に 1. インデックスを作成する 2. タイプとidをきめる 3. データをJSONファイルに加工する やっていきます 5
Elasticsearchにインデックスを作成する Elasticsearchのインデックス ≒ RDBのデータベース インデックス名はtokyotravelにしました。 $ curl -X PUT http://localhost:9200/tokyotravel
インデックスの確認 $ curl 'http://localhost:9200/_cat/indices?v' 参考 {HOST}:{PORT}/{index}/{type}/{id} 6
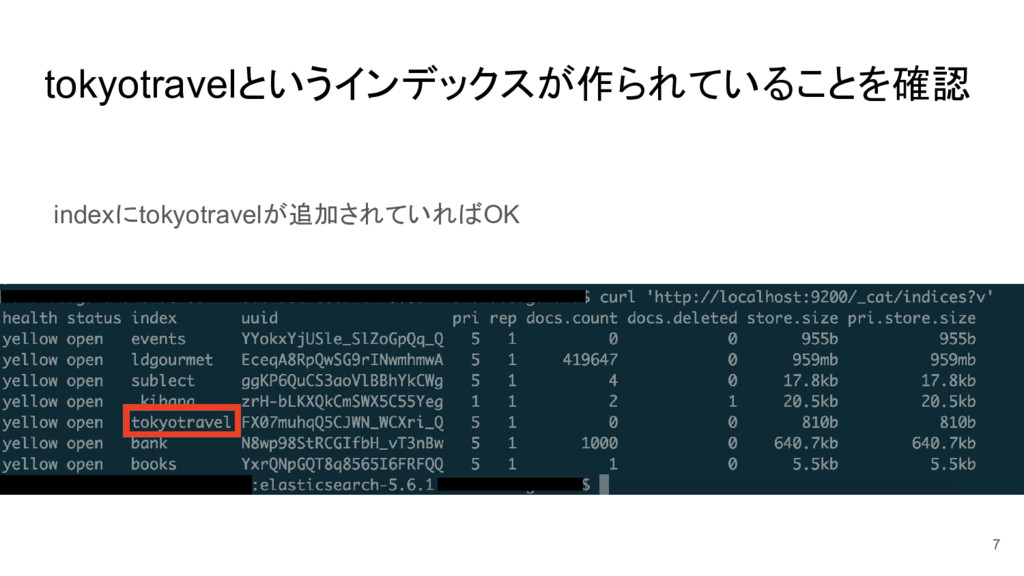
tokyotravelというインデックスが作られていることを確認 7 indexにtokyotravelが追加されていればOK
タイプとidをきめる Elasticsearchのタイプ ≒ RDBのテーブル タイプはrecommendpageにしました。 http://localhost:9200/tokyotravel/recommendpage Elasticsearchのid≒RDBのid http://localhost:9200/tokyotravel/recommendpage/1 http://localhost:9200/tokyotravel/recommendpage/2 http://localhost:9200/tokyotravel/recommendpage/3
参考 {HOST}:{PORT}/{index}/{type}/{id} 8
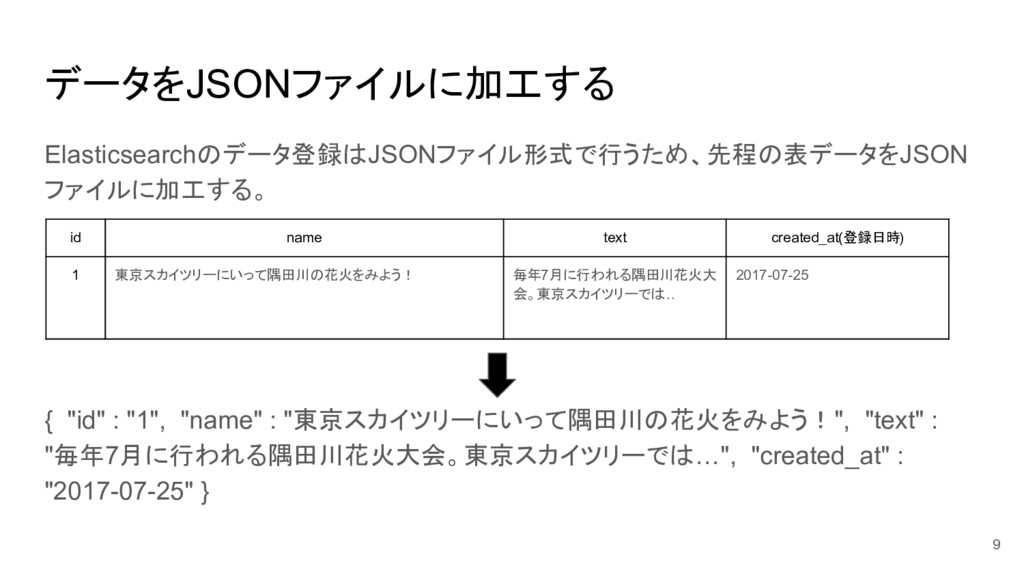
データをJSONファイルに加工する Elasticsearchのデータ登録はJSONファイル形式で行うため、先程の表データをJSON ファイルに加工する。 { "id" : "1", "name" : "東京スカイツリーにいって隅田川の花火をみよう!",
"text" : "毎年7月に行われる隅田川花火大会。東京スカイツリーでは…", "created_at" : "2017-07-25" } 9 id name text created_at(登録日時) 1 東京スカイツリーにいって隅田川の花火をみよう! 毎年7月に行われる隅田川花火大 会。東京スカイツリーでは … 2017-07-25
Elasticsearchに先程のJSONファイルを登録 今回はわかりやすいように1件ずつ登録していきます。 $ curl -X PUT http://localhost:9200/tokyotravel/recommendpage/1?pretty -d ' {
"id" : "1", "name" : "東京スカイツリーにいって隅田川の花火をみよう!", "text" : "毎年7月に行われる隅田川花火大会。東京スカイツリーでは…", "created_at" : "2017-07-25" }' テンプレート: $ curl -X PUT {HOST}:{PORT}/{index}/{type}/{id}?pretty -d 'JSONデー タ' 参考 {HOST}:{PORT}/{index}/{type}/{id} 10
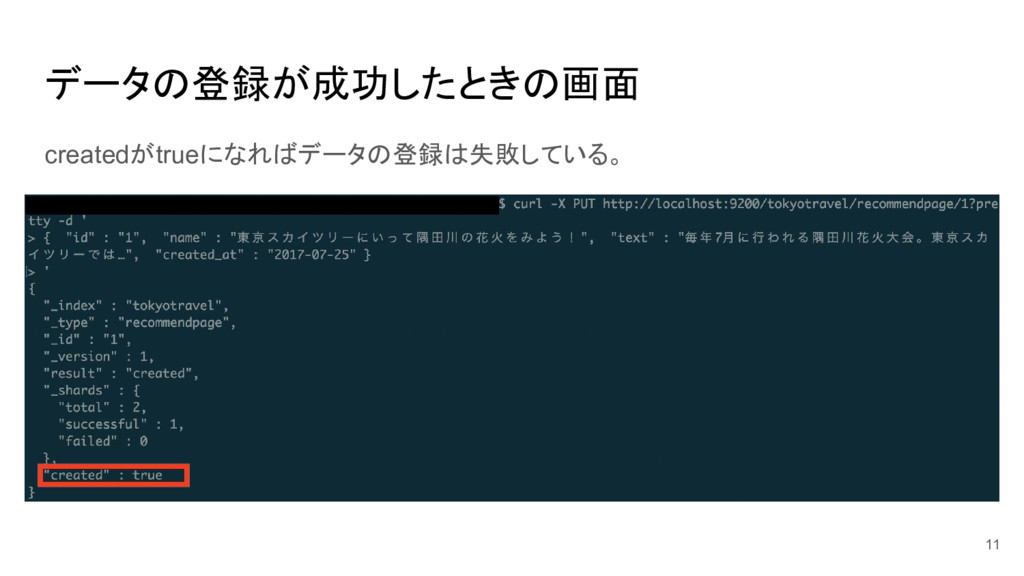
データの登録が成功したときの画面 createdがtrueになればデータの登録は失敗している。 11
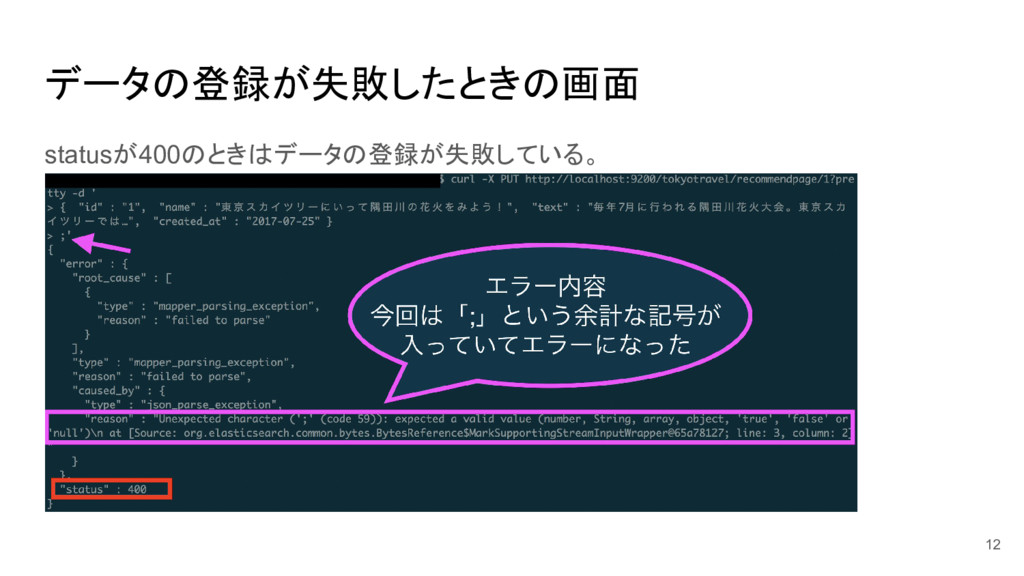
データの登録が失敗したときの画面 statusが400のときはデータの登録が失敗している。 12
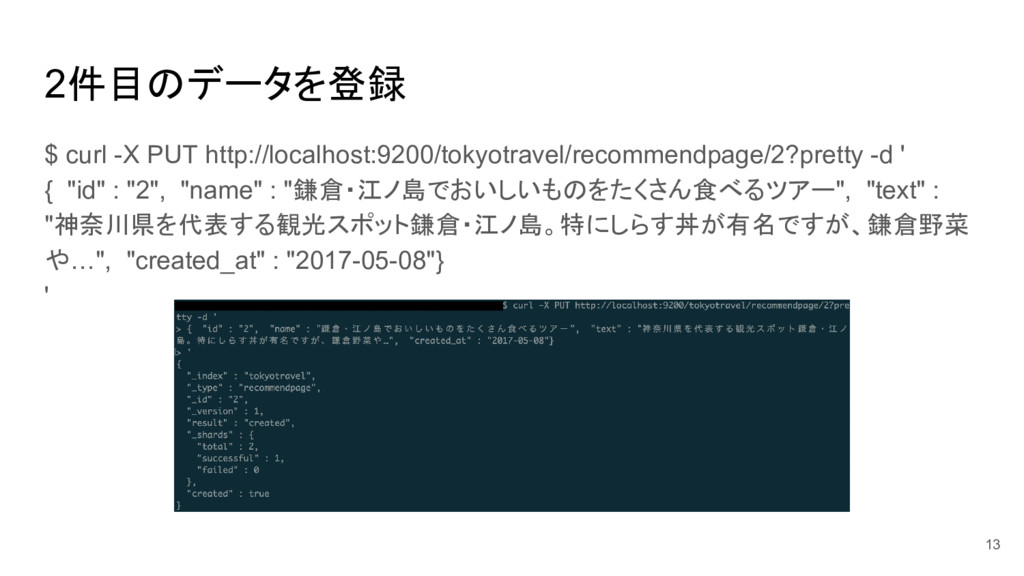
2件目のデータを登録 $ curl -X PUT http://localhost:9200/tokyotravel/recommendpage/2?pretty -d ' { "id"
: "2", "name" : "鎌倉・江ノ島でおいしいものをたくさん食べるツアー", "text" : "神奈川県を代表する観光スポット鎌倉・江ノ島。特にしらす丼が有名ですが、鎌倉野菜 や…", "created_at" : "2017-05-08"} ' 13
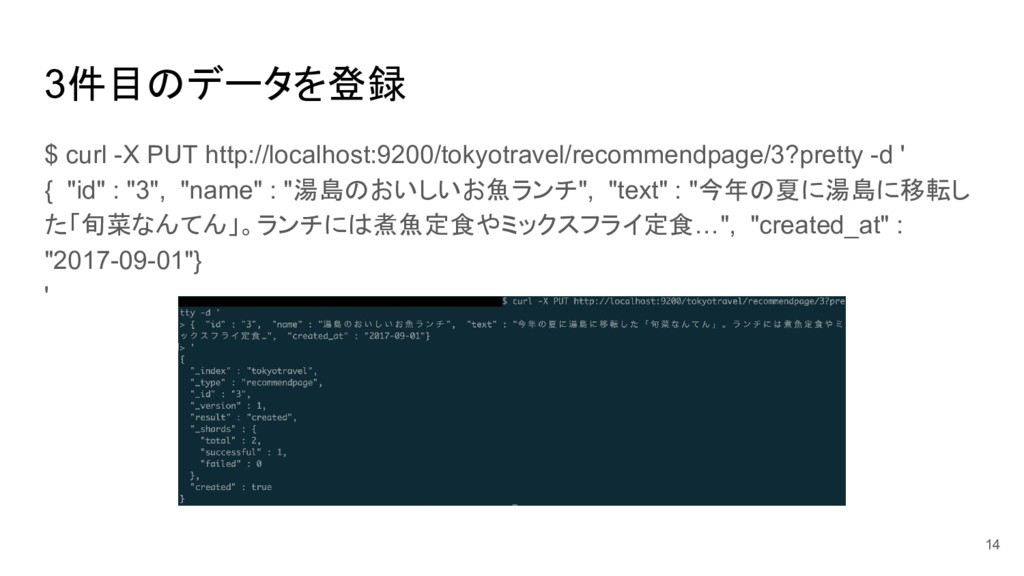
3件目のデータを登録 $ curl -X PUT http://localhost:9200/tokyotravel/recommendpage/3?pretty -d ' { "id"
: "3", "name" : "湯島のおいしいお魚ランチ", "text" : "今年の夏に湯島に移転し た「旬菜なんてん」。ランチには煮魚定食やミックスフライ定食…", "created_at" : "2017-09-01"} ' 14
3件のデータの登録が完了したので、検索をする テンプレート: $ curl -X GET http://localhost:9200/tokyotravel/recommendpage/_search?pretty -d 'クエリ' /_searchの前が検索する範囲を意味している。インデックス名tokyotravelのタイプ名
recommendpageタイプの範囲から検索する。 prettyはレスポンスを整形するという意味 参考 {HOST}:{PORT}/{index}/{type}/{id} 15
nameフィールドに「隅田川」が入っているデータを検索 する $ curl -X GET http://localhost:9200/tokyotravel/recommendpage/_search?pretty -d '{ "query":
{ "bool": { "must": { "match": { "name": "隅田川" } } } } }' 16
きちんと1件目のデータがヒットしている took:検索の処理時間(msec) hitsのtotal:検索結果件数 hitsのmax_score:検索結果の データの中で最も高かった関連度 の数値 _source:ヒットしたデータの詳細 17
nameとtextのフィールドどちらにも「隅田川」が入ってい るデータを検索する $ curl -X GET http://localhost:9200/tokyotravel/recommendpage/_search?pretty -d ' {
"query": { "bool": { "must": [ { "match": { "name": "隅田川" } }, { "match": { "text": "隅田川" } } ] } } }' 参考: mustはAND条件, shouldはOR条件となる 18
これもきちんと1件目のデータがヒットしている 検索の処理時間:7msec 検索結果件数:1件 max_score:1.5427719 _source:1件目のデータの詳細 19
nameまたはtextのフィールドに「隅田川」が入っている データを検索する $ curl -X GET http://localhost:9200/tokyotravel/recommendpage/_search?pretty -d ' {
"query": { "bool": { "should": [ { "match": { "name": "隅田川" } }, { "match": { "text": "隅田川" } } ] } } }' 参考: mustはAND条件, shouldはOR条件となる 20
これも1件目だけのデータのはず……ではない!? 1件目と2件目のデータがヒットしてひいる 2件目のデータに「隅田川」という文字がな いのに検索結果にヒットするのはなぜ? nameフィールドだけで「隅田川」を検索したときはヒッ トしなかったが、この結果から考えるともしかして text フィールドで「隅田川」を検索するとヒットする …? 21
textフィールドに「隅田川」が入っているデータを検索す る $ curl -X GET http://localhost:9200/tokyotravel/recommendpage/_search?pretty -d '{ "query":
{ "bool": { "must": { "match": { "text": "隅田川" } } } } }' 22
2件目もヒットしている なぜ? 先程の予想通り、「隅田川」がはいってい ないのに2件目のデータがひっかかってい る。 推測:Elasticsearchは必ず検索キーワード を含めるものをヒットさせるのではなく、関 連度でヒットさせる方針をとっていると考え られる。 神奈川県の「川」と隅田川の「川」に少なからず関連があったの かもしれない……
23
話をもどしてnameまたはtextのフィールドに「隅田川」が 入っているデータを検索し、かつ、登録日時順(降順)に 並び替える $ curl -X GET http://localhost:9200/tokyotravel/recommendpage/_search?pretty -d '
{ "query": { "bool": { "should": [ { "match": { "name": "隅田川" } }, { "match": { "text": "隅田川" } } ] } }, "sort" :{ "created_at" : "desc" } }' 24
降順に並び替えることができた クエリに"sort" :{ "created_at" : "desc" } を足すことにより、降順に並び替えることが できた 確認のために昇順もやってみる
25
話をもどしてnameまたはtextのフィールドに「隅田川」が 入っているデータを検索し、かつ、登録日時順(昇順)に 並び替える $ curl -X GET http://localhost:9200/tokyotravel/recommendpage/_search?pretty -d '
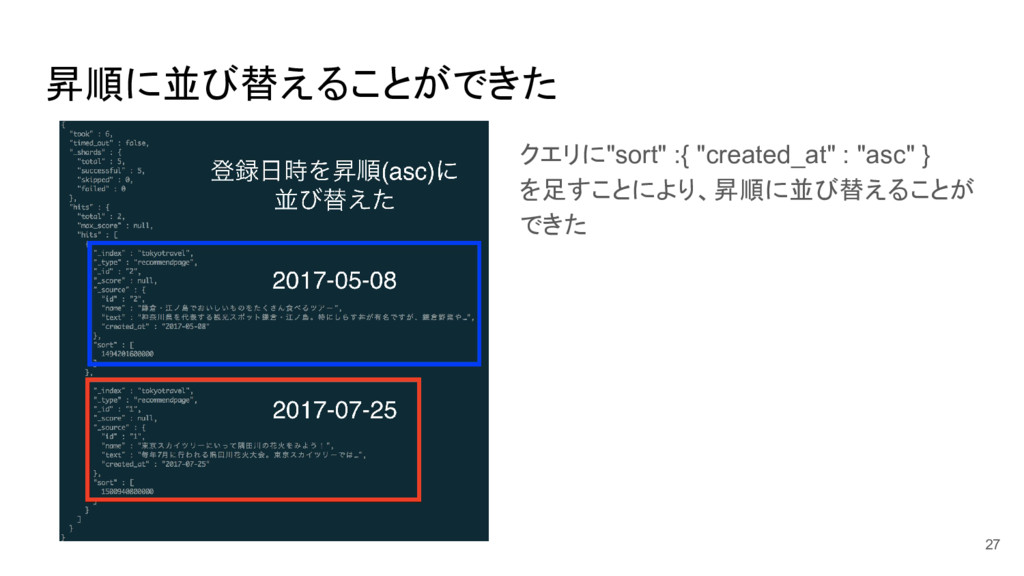
{ "query": { "bool": { "should": [ { "match": { "name": "隅田川" } }, { "match": { "text": "隅田川" } } ] } }, "sort" :{ "created_at" : "asc" } }' 26
昇順に並び替えることができた クエリに"sort" :{ "created_at" : "asc" } を足すことにより、昇順に並び替えることが できた 27
ところで、キーワード検索を関連度ではなく、ただキー ワードが一致するものだけをヒットさせたい場合はどうし たらいいのか 答え:queryではなくfilterを使用する。 $ curl -X GET http://localhost:9200/tokyotravel/recommendpage/_search?pretty -d
' { "query": { "bool": { "should": [ { "match": { "name": "隅田川" } }, { "match": { "text": "隅田川" } } ] } } }' 28 ←これは先程の「nameまたはtextの フィールドに「隅田川」が入っている データを検索する」を検索してなぜか 2件目もヒットしたときのクエリ これ
queryとfilterの違いってなに? query - 検索したキーワードとドキュメントの関連度を測り検索結果を構成する - パラメータ「_score」で判定して検索結果のランキングをつける - 検索キーワードが登録したドキュメントに含まれていなくても関連があれば、「隅田 川」の時のように検索結果には表示される filter
- 検索したキーワードがドキュメントの中に入っているか/いないか - パラメータ「_score」は無視する 29
実際にfilterを使って検索してみよう シンプルにqureyをfilterにおきかえてみる $ curl -X GET http://localhost:9200/tokyotravel/recommendpage/_search?pretty -d ' {
"filter": { "bool": { "should": [ { "match": { "name": "隅田川" } }, { "match": { "text": "隅田川" } } ] } } }' 30 ここをqueryからfilterにおきかえた
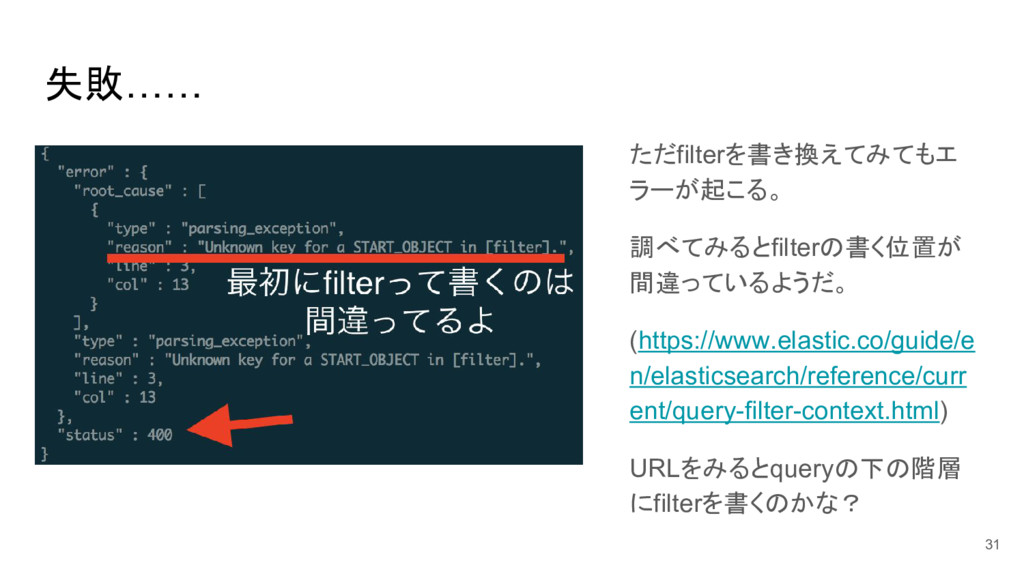
失敗…… ただfilterを書き換えてみてもエ ラーが起こる。 調べてみるとfilterの書く位置が 間違っているようだ。 (https://www.elastic.co/guide/e n/elasticsearch/reference/curr ent/query-filter-context.html) URLをみるとqueryの下の階層 にfilterを書くのかな?
31
こうか? queryの下の階層にfilterをかいてみる $ curl -X GET http://localhost:9200/tokyotravel/recommendpage/_search?pretty -d ' {
"query": { "filter": { "should": [ { "match": { "name": "隅田川" } }, { "match": { "text": "隅田川" } } ] } } }' 32 queryの下の階層にfilterを置いてみた
失敗2 no [query] registered for [filter] というエラーがでる。 フィルタにクエリが登録されてい ません…どういうことだ… もう1回公式サイトを見ると
「shouldやmatchはqueryのコン テキストである」と書いてあるのを 発見した。だったら… 33
こうですか? shouldを削除して、matchの代わりにtermを使用してみた。 $ curl -X GET http://localhost:9200/tokyotravel/recommendpage/_search?pretty -d ' {
"query": { "filter": [ { "term": { "name": "隅田川" } }, { "term": { "text": "隅田川" } } ] } }' 34
失敗3 [filter] query malformed, no start_object after query name というエラーが出ました。
むむ… filterの使い方は今回の発表ま でにわかりませんでした。 今度別の資料としてfilterの使い 方を発表します: & 35
セキュリティに関して 36
セキュリティ ・標準機能ではユーザー認証や通信の暗号化を提供していない ・X-Pack(有償プラグインをひとまとめにパッケージ化されたもの)でセキュリティ機能が 提供されている - ユーザー認証 - 通信の暗号化 - 監査ログ
公式にはX-Packの値段が書かれていなかったが推定100万くらい…?(掲示板に書いて あったものなので確証は低い) 37
Elasticsearchを狙うランサムウェア攻撃 今年の1月に発表された記事。アクセス制 限がきちんとされておらず公開されたイン スタンスがランサムウェア攻撃の被害に あった。 (https://japan.zdnet.com/article/3509506 5/ ) Elasticsearch自体に認証機能はないた め、アクセス管理を徹底して行う必要があ
る。 38
X-Packを使わない場合、どうアクセス制限するのか ・./config/elasticsearch.yml - Network and HTTP (参考: http://www.tree-tips.com/elasticsearch/config/elasticsearch_yml/) ・GCPのVPCネットワーク -
ファイアウォールルールなど 39
このブログが最も詳しい ・elasticsearchをランサムウェアから守るには #elastic - ( https://www.creationline.com/blog/15761 ) - 日本語・elasticsearch.ymlの設定などが書かれている ・Securing
Your Elasticsearch Cluster By Alex Brasetvik - ( https://www.elastic.co/blog/found-elasticsearch-security) - 英語・elastic社公式のドキュメント 40
速度計測 41
結論からいうと正確なデータがとれていません まとめ • ElasticsearchとMySQLの検索結果速度の比較検証をしよう考えた。 • 検証目的は、検索結果速度は Elasticsearch>MySQL と個人的に思っていて、 そ れを実証したかったから。
• 有効なデータを得るにはElasticsearchとMySQLを同等な検証環境にする必要が ある。それが想定していたよりもものすごく難しい。 • そもそもこの2つを比べることは公正なのか? *この章は文字が多いです。 42
ElasticsearchとMySQLの検索結果速度の比較検証を しよう考えた。 検索ははやいほうがいい、当たり前のことである。 前回MySQL InnoDB FTS Ngram(n=2) IN BOOLEAN MODEを調査した時、検索結
果速度がめちゃくちゃ遅かったことがネックだった。 今回調査しているElasticsearchは様々なブログをみても遅いということをあまり見たこと がないし、ざっくりとした仕組みから考えても少なくともMySQL InnoDB FTS Ngram(n=2) IN BOOLEAN MODEははやいだろう。 →だとしたら検索結果速度の比較検証をしてみよう 43
比較検証にはまず何が必要? 必要だと考えて実際に用意したもの • Elasticsearchの環境とサンプルデータ(JSON) • 前回調査したMySQLの環境とサンプルデータ(CSV) 44 今見るとざっくりしすぎ。 あとでわかるがこの時点で考えが 足りない。
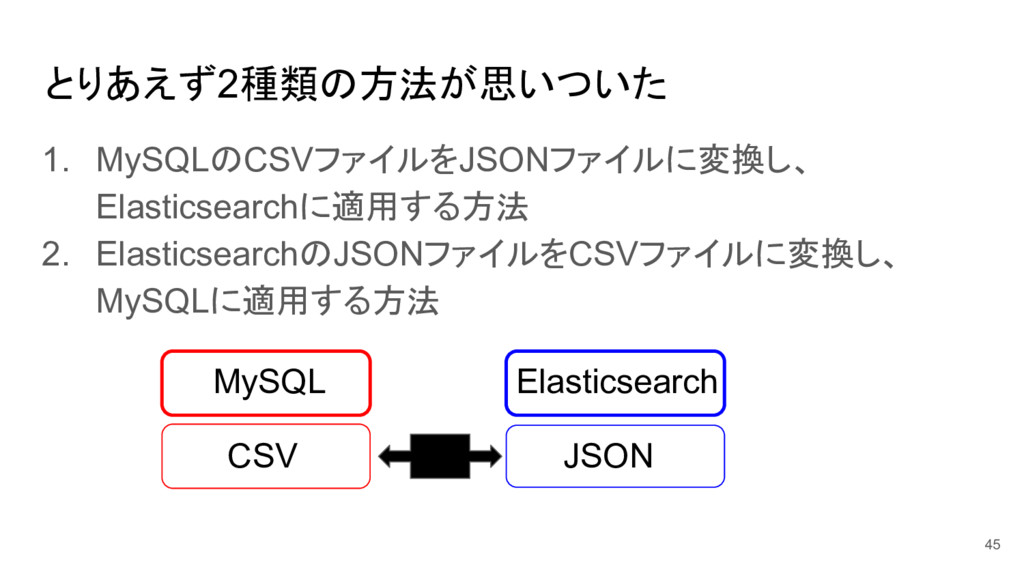
とりあえず2種類の方法が思いついた 1. MySQLのCSVファイルをJSONファイルに変換し、 Elasticsearchに適用する方法 2. ElasticsearchのJSONファイルをCSVファイルに変換し、 MySQLに適用する方法 45 MySQL CSV
JSON Elasticsearch
1.MySQLのCSVファイルをJSONファイルに変換し、 Elasticsearchに適用する方法 ElasticsearchはJSONが基本であり、CSVファイルをJSONファイルに変換する必要が ある。ここで2つ方法がある。 1. CSVファイルをJSONファイルに変換させるブラウザ上にあるツールを使用する方 法→変換するのは簡単、しかしidの問題がある 2. 前回紹介したElastic stackのLog
stash(Fluentdみたいなデータの集約・転送をす るツール、データをインプット→変換→アウトプットするもの)を使い、CSVファイルを JSONファイルに変換し、そのままElasticsearchと連携させる方法→Log stashに 関してはまだ試せていない 46
2.ElasticsearchのJSONファイルをCSVファイルに変換 し、MySQLに適用する方法 MySQLはバージョン5.7からJSONを取り扱えるようになったけど…詳しくはこののブロ グに書かれている。 (https://www.webprofessional.jp/use-json-data-fields-mysql-databases/) とりあえずJSONファイルをCSVファイルに変換してみる?それは簡単にできる →でもそもそもそれってなんか違くない?(MySQLにはMySQLの特徴があって、 ElasticsearchにはElasticsearchの特徴があるということをいいたい。) 47
そもそもMySQLとElasticsearchを比べることは公正な の? • MySQLは事前にスキーマが決まっているデータが適していし、正規化をする必要 がある。 • ElasticsearchはREST&JSON&スキーマレスという特徴を生かして、リアルタイム データを検索することに適している。 私は、データの特徴から検索の方法(ElasticsearchやMySQLなど)を選ぶのがいいの かもしれないと思った。
もし、MySQLとElasticsearchを同等な検証環境にすれば、公正なデータといえるかもし れない。しかし、同等な検証環境を用意するのは難しい。 48
速度計測のはなしはどこにいったんだ Elasticsearchの検索結果速度がはやいということを検証したかったんだった。 Elasticsearchがはやいということは単体で今度示そうと思います。 49
まとめ 50
学び ・検索の前準備が結構必要 ・セキュリティに関しては、アクセス制限に注意す る ・速度計測の比較検証は難しい 51
今後知りたいこと ・filterの使い方 ・Elasticsearchの速度に関して ・大規模データの扱い方 52
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![失敗2 no [query] registered for [filter] というエラーがでる。 フィルタにクエリが登録されてい ません…どういうことだ… もう1回公式サイトを見ると](https://files.speakerdeck.com/presentations/849eb9f1393b4a8f9feb2af3913d2a0e/slide_32.jpg){kind=link}
{kind=link}
![失敗3 [filter] query malformed, no start_object after query name というエラーが出ました。](https://files.speakerdeck.com/presentations/849eb9f1393b4a8f9feb2af3913d2a0e/slide_34.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}