digital products & services. • Prototypes, not presentations. • One team: Client + Work & Co. • Fewer people. More senior people. • Good products requires good development. • We’re hiring! Find me. :)
development / homologation environments negatively impact in our prototype-based deliveries • We prefer to spend time configuring production infrastructure instead • Containerization Concept: majority of customers never had contact with it
homologation environments and related infrastructure. • Developers want to develop, not doing server things • Give a automated path to developers create and deploy projects with ease / quick feedback
teams per project across New York, Portland, Sao Paulo, Rio de Janeiro, Belgrade and other cities. • Common questions for each new project: • Hire / reallocate a DevOps guy? • A new CI / CD server? • For each new application, a pipeline setup • A tedious and repetitive step
and want to maintain Jenkins / Go / CircleCI / whatever CI / CD solutions because: • Scope-based projects • After our final delivery, customers traditionally embraces this responsibility using their CI / CD solution • CI / CD servers can be totally different between our projects
a simple solution that fits our philosophy? • Fast feedback from PR’s • Easy way to see build logs • Easy way to deploy a specific branch in any environment • Automate deployments for a specific environment / branch • Developer knows how to generate artifacts from project, give them this power • Docker, Docker, Docker! (To run locally and distribute releases as images)
Service goods: • Experience from previous projects • Rock solid • Tradeoffs: • Complex to orchestrate new deployments (task definitions, tasks) • Not bleeding-edge Docker version
Reliable • Cloud agnostic • Tradeoffs: • Complexity • High learning curve not applicable to our urgent needs • We rely a lot on our Docker Compose standards, what implies in some kind of transformation to create a Kubernetes configuration file
• Cloud agnostic • Swarm stacks fits very well our needs • Tradeoffs: • At the time of research, a experimental feature • When something goes wrong, be prepared for the worst.
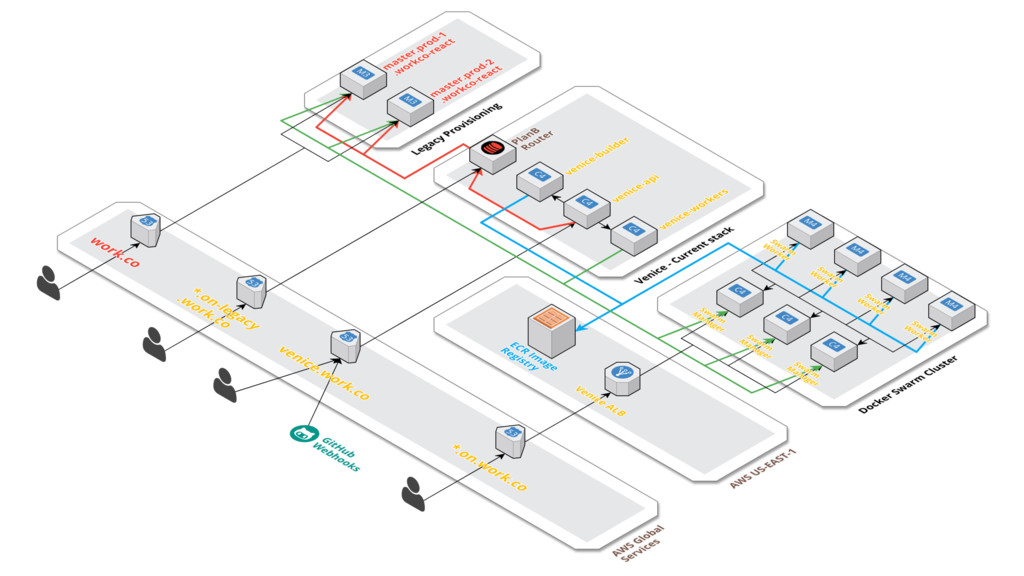
on AWS: • Classic ELB • EC2 instances (c4.large for managers, m4.2xlarge for workers) • ECR to store Docker images • Traefik as Load Balancer for containers • Docker Swarm 1.13 (at the time of launch), today 17.09.0-ce • $ 0.02 tip: AWS Internal Traffic is much more cheaper and brutally fast; consider it • Terraform (provisioning) • Ansible (configuration management) • Sysdig Cloud (monitoring)
a Docker Swarm cluster? With a Service. • Docker Swarm Services are a definition of a container you want to run in the cluster • You can run a service in all Swarm servers or in a specific server using constraints • For example: Traefik
containers? With Stacks. • Docker Swarm Stacks are a definition from a group of services • Docker Compose Version 3 is specially developed to support deployment of stacks using a docker-compose.yml file (or another file name you want)
July 22: a new Swarm election was triggered and one of managers got a memory peak during this period and was stuck. • Root cause: https://github.com/moby/ moby/issues/29087 • July 27: another Swarm election was triggered and another manager falls down with same behavior • July 28: the remaining Swarm manager falls down as same reason as others
Side effect: deploys on Swarm cluster during this period starts to have bizarre behaviors: • Old stack definitions conflicting with newest ones, causing services to start two containers instead of one (i.e. master-1.0.0 vs master-1.0.1) • Traefik consequently returning HTTP 502 when requesting some containers • Removing / Adding Swarm managers and workers to the cluster not works • Known issue: https://github.com/moby/moby/ issues/32195 • Upgraded to 17.06.0~ce-0
August 18: Traefik starts to return HTTP 502 from all containers running in a specific Swarm worker server • After upgrading to 17.06.1, Swarm servers fails to join into the cluster. One. By. One • Tried to provision a new EC2 instance and join into the cluster. Failed • During removal, another services starts to fail with the same behavior • Known Issue: https://github.com/moby/ moby/issues/31839
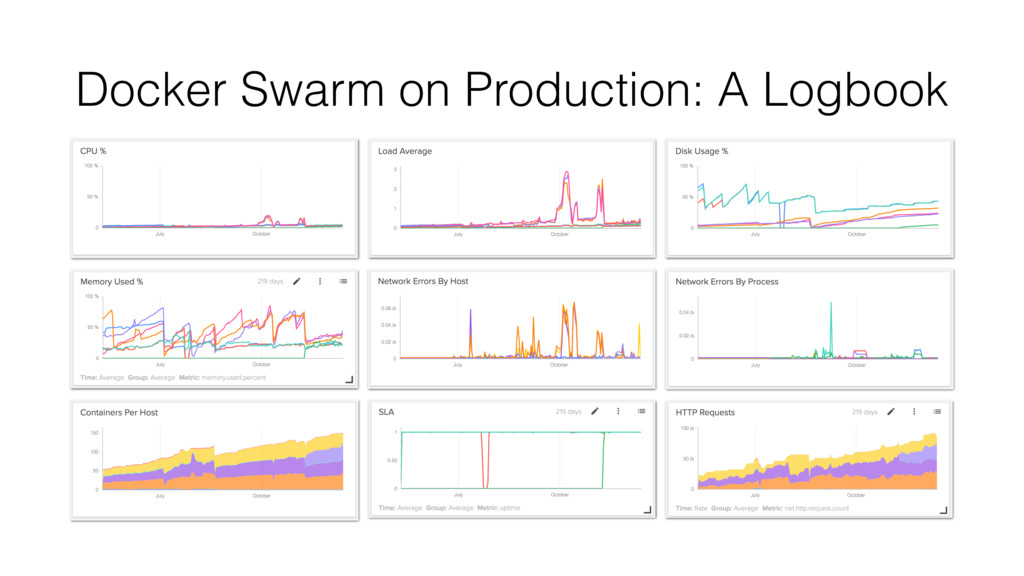
Spend time monitoring CPU / RAM / Load Average • Be aggressive configuring alerts to detect any strange behavior based on applications you run in Swarm (sudden CPU / Memory Used peaks) • Log Level configured to DEBUG on Swarm nodes
Rock solid. • November 7: some services fails to deploy into the cluster. After diving on Docker Swarm logs, found the reason: Docker internal IP allocation fails when a new service is deployed. Root causes: • Traefik Network Driver configured with subnet CIDR 10.0.0.0/24 -> 254 IPs - 1 allocated internally by Docker • 127 Stacks + 128 Services = 255 IPs on total • Docker Network can’t be updated on the fly, you need to recreate from scratch
Be careful when creating a Docker Network Overlay Driver, spend some time to properly configure a subnet based on your growth • Take special attention to Network Errors. A increased number tells a lot about Swarm inconsistencies • Same attention to CPU peaks, be more aggressive than you think you are • Create a swiss knife to recover Swarm cluster (Ansible, Bash, Python scripts, whatever)
reliable after all? • In my opinion, yes. Maybe not to you; for us fits well • Add new Docker Swarm servers is very, very easy • Operation is quite simple. Read the docs • 100~150 developers / QA engineers / PMs / customer stakeholders using it every day
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}