Network for Single Image Super-resolution," in CVPR 2019 . 2. Dong, Chao, et al. "Image super-resolution using deep convolutional networks." IEEE transactions on pattern analysis and machine intelligence 38.2 (2015): 295-307. 3. Ledig, Christian, et al. "Photo-realistic single image super-resolution using a generative adversarial network." Proceedings of the IEEE conference on computer vision and pattern recognition. 2017. 4. Luong, Thang, Hieu Pham, and Christopher D. Manning. "Effective Approaches to Attention-based Neural Machine Translation." Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing. 2015. 5. Olah, Chris, and Shan Carter. "Attention and augmented recurrent neural networks." Distill 1.9 (2016): e1. 6. Xu, Kelvin, et al. "Show, Attend and Tell: Neural Image Caption Generation with Visual Attention." International Conference on Machine Learning. 2015. 7. Hu, Jie, Li Shen, and Gang Sun. "Squeeze-and-excitation networks." Proceedings of the IEEE conference on computer vision and pattern recognition. 2018. 8. Wang, Xiaolong, et al. "Non-local neural networks." Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2018. 9. Zhang, Yulun, et al. "Image super-resolution using very deep residual channel attention networks." Proceedings of the European Conference on Computer Vision (ECCV). 2018. 31
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
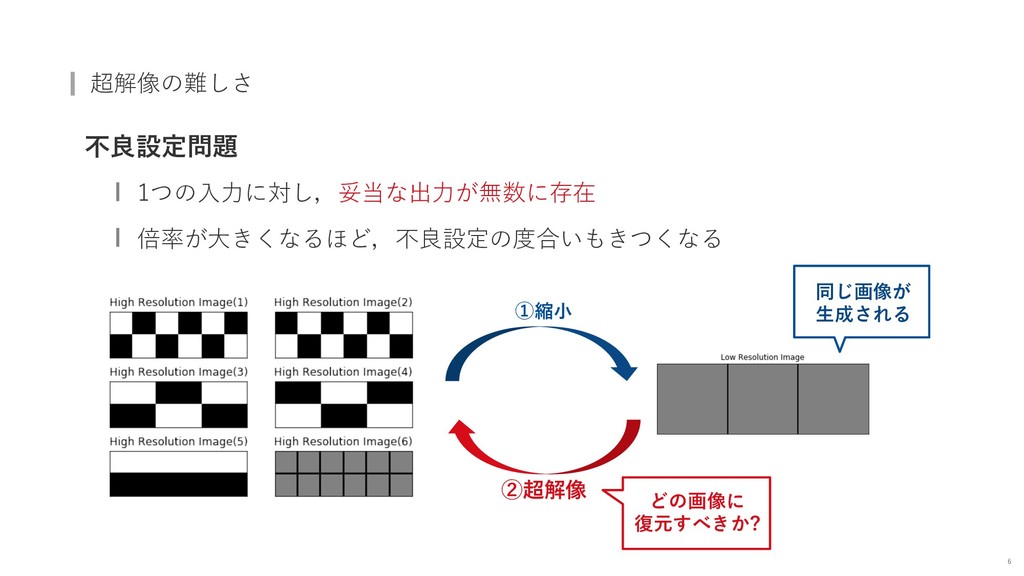{kind=link}
![深層学習を⽤いた超解像 SRCNN [C. Dong et al. ECCV 2014] 超解像に深層学習を⽤いた初めての⼿法 3層のCNNで構成](https://files.speakerdeck.com/presentations/eef7362335c644c4b2f02ae245798773/slide_7.jpg){kind=link}
{kind=link}
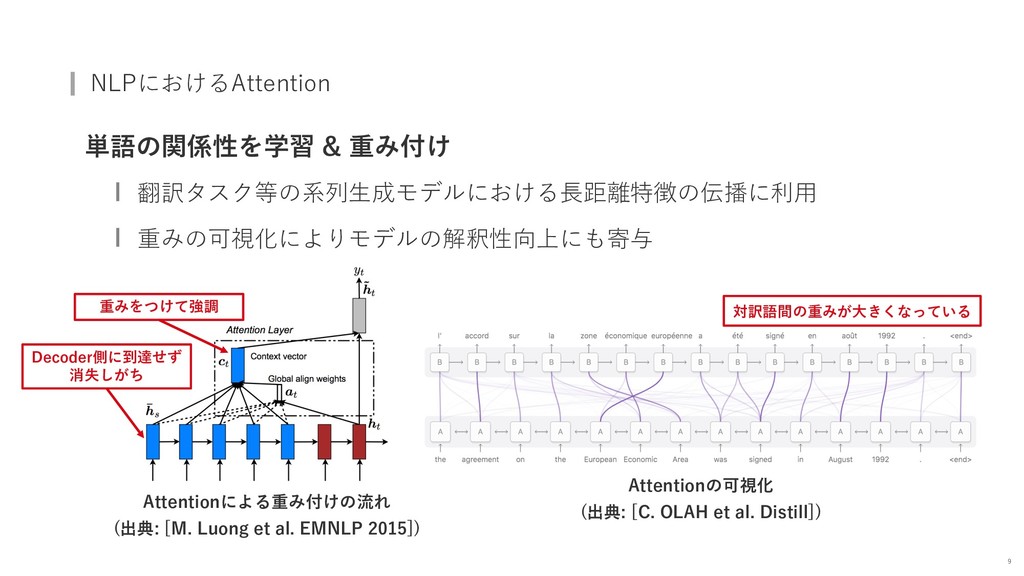{kind=link}
{kind=link}
![Show, Attend and Tell [K. Xu et al. ICML 2015]](https://files.speakerdeck.com/presentations/eef7362335c644c4b2f02ae245798773/slide_11.jpg){kind=link}
![Squeeze-and-Excitation Network [J. Hu et al. CVPR 2018] SEBlock: チャネル⽅向にAttentionを導⼊](https://files.speakerdeck.com/presentations/eef7362335c644c4b2f02ae245798773/slide_12.jpg){kind=link}
![Non-local Neural Network [X. Wang et al. CVPR 2018] CNNで⾮局所的な情報を扱えるようにする](https://files.speakerdeck.com/presentations/eef7362335c644c4b2f02ae245798773/slide_13.jpg){kind=link}
![Non-local Neural Network [X. Wang et al. CVPR 2018] Non-local](https://files.speakerdeck.com/presentations/eef7362335c644c4b2f02ae245798773/slide_14.jpg){kind=link}
{kind=link}
{kind=link}
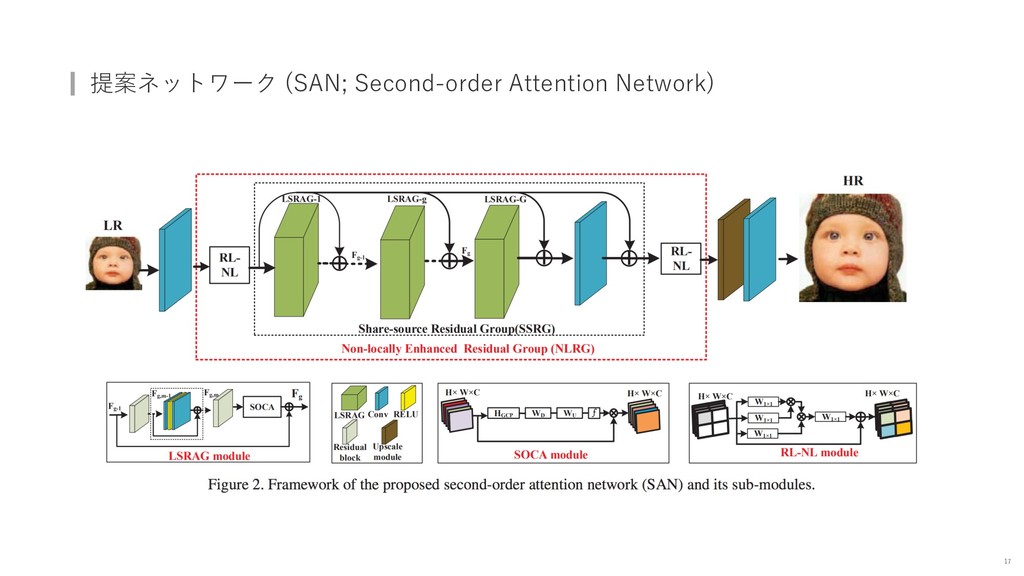{kind=link}
{kind=link}
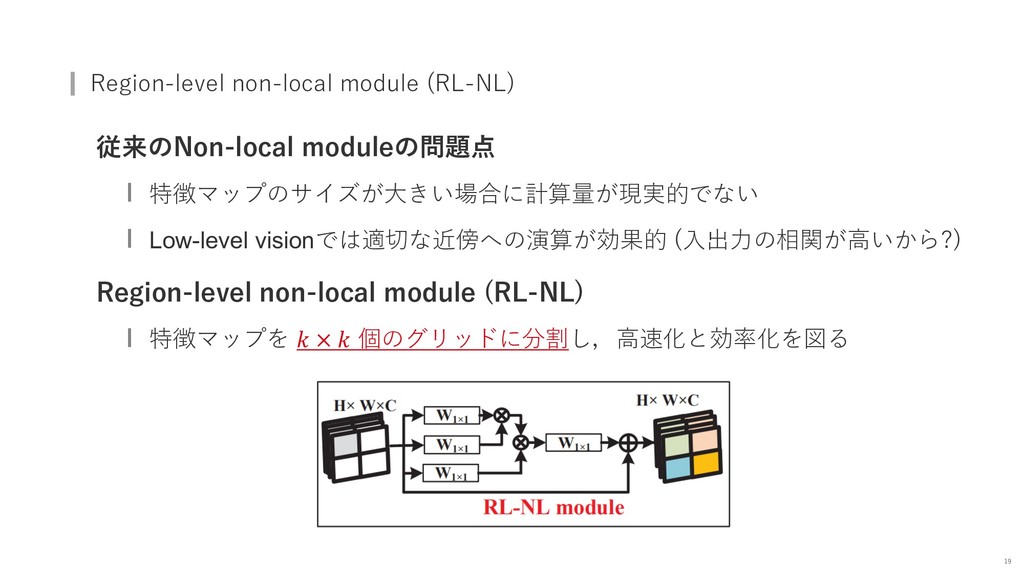{kind=link}
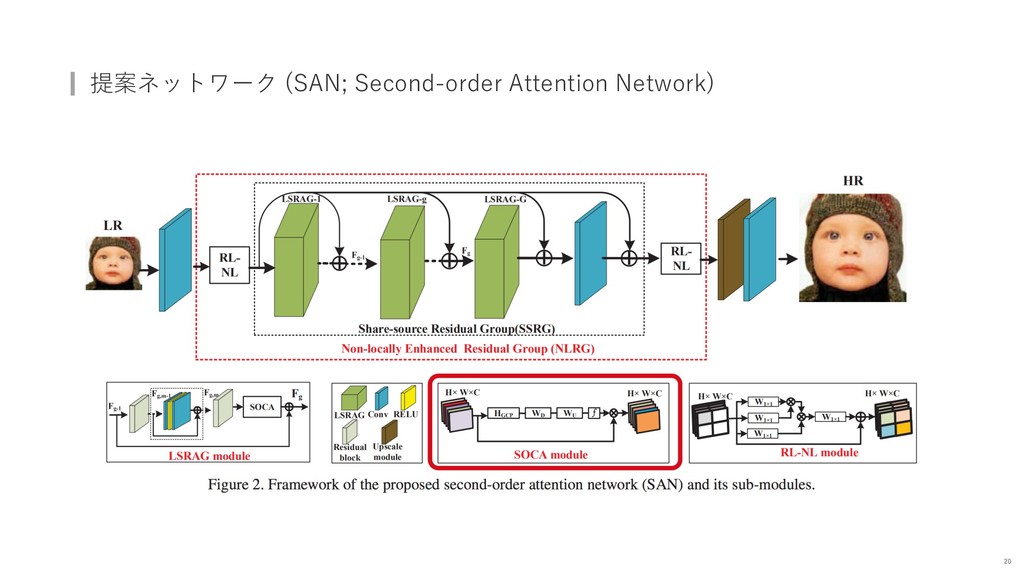{kind=link}
{kind=link}
{kind=link}
{kind=link}
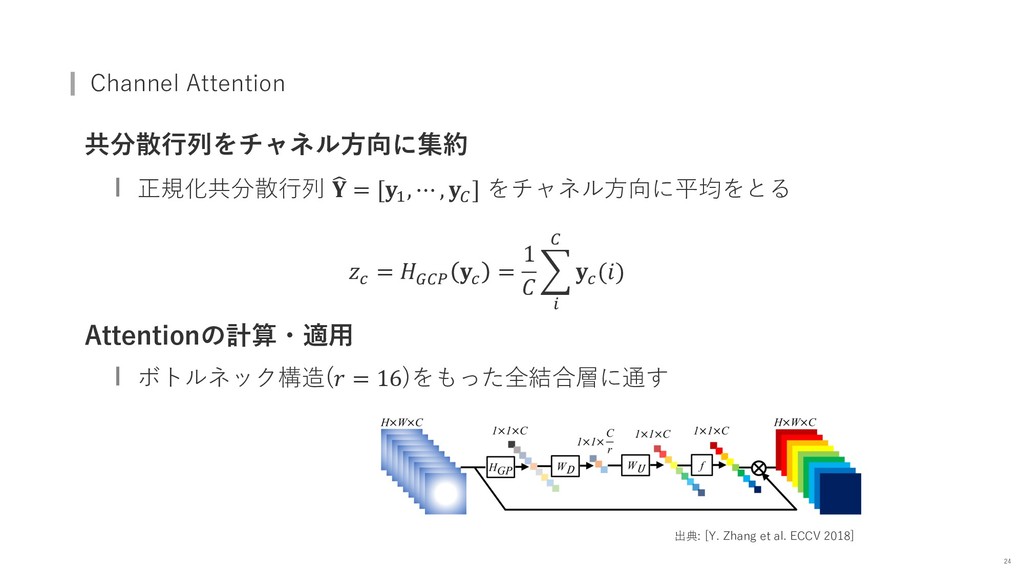{kind=link}
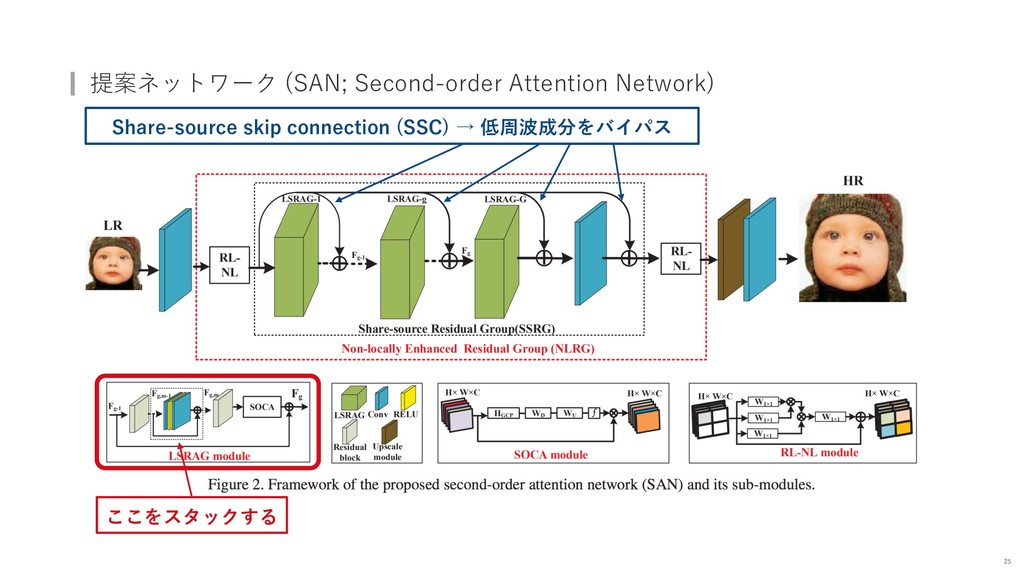{kind=link}
{kind=link}
{kind=link}
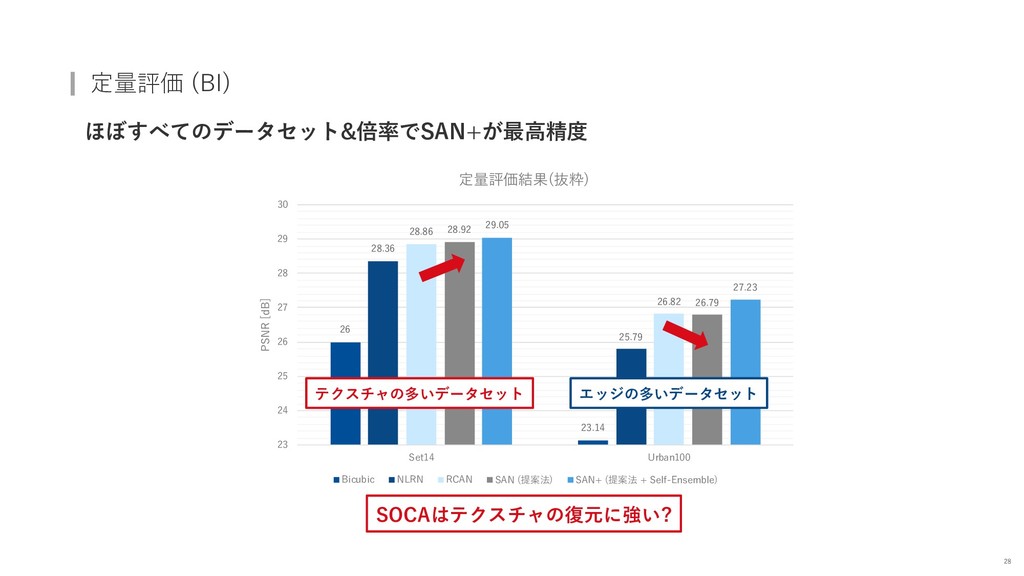{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}