Crowdsourcing [7]: 隠れた POI (Point of Interest) をうまく探すフレームワークを提案. • POI (Point of Interest): 誰かの役に⽴ったり興味を引いたりする場所のこと. • Hidden POI: • ビジネス上役に⽴つことが多いが, データが不⼗分であるために, あまりサービスに利⽤されない POI. • Hidden POI についてはもっとレビューなどが欲しい. Figure 1: H-POI Ranking Framework Overview Hidden POI と Popular POI のペアをワーカに投げて, 作業してもらうことで効率的に Hidden POI のランキング集計できる 2 段階のフレームワークを提案.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Data Strategy and Operation Center D&S model [4]: ワーカの能⼒を加味してEM Alg.](https://files.speakerdeck.com/presentations/6374552494a84c6787c93c9ae067c22c/slide_12.jpg){kind=link}
{kind=link}
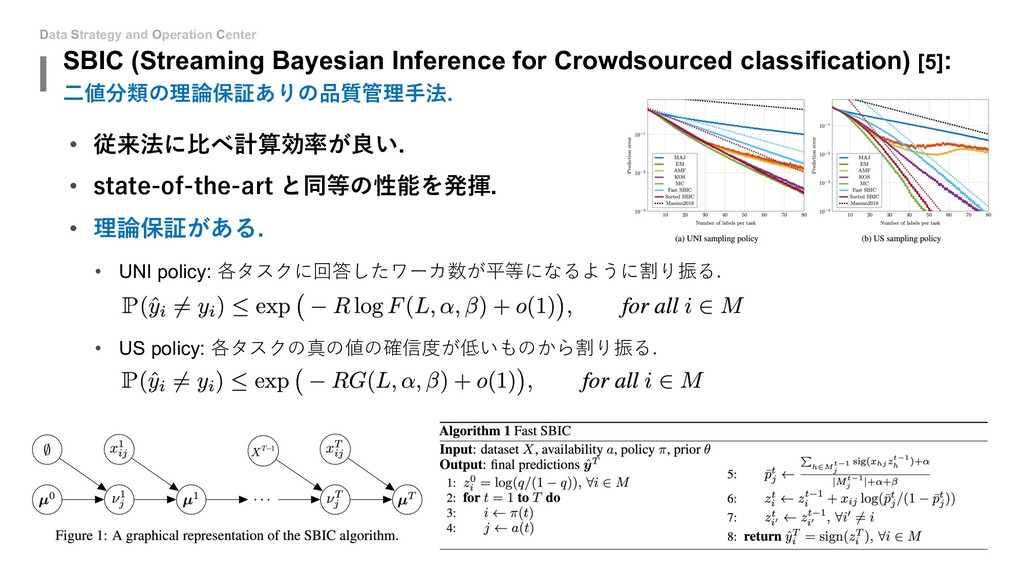
{kind=link}
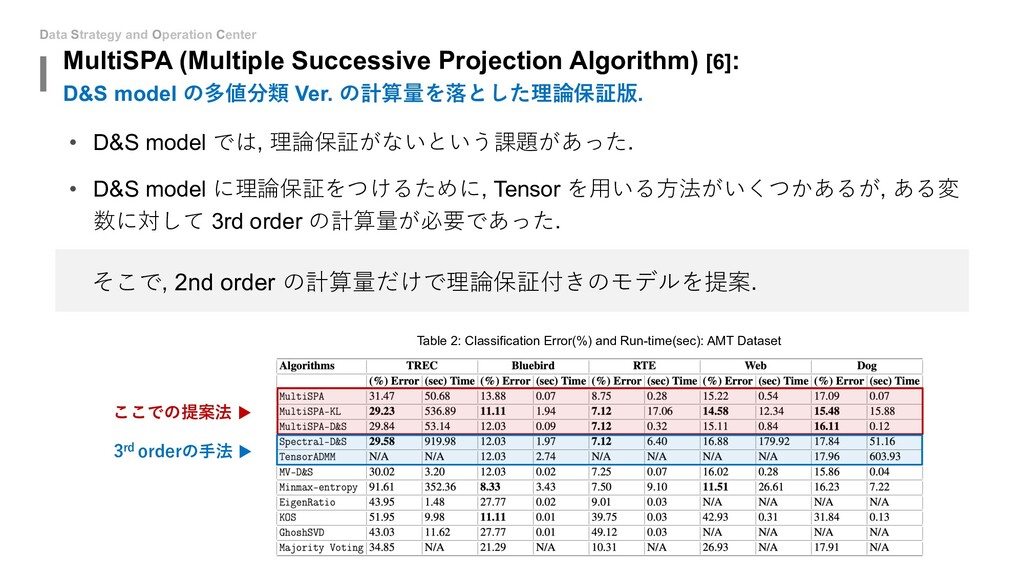
{kind=link}
{kind=link}
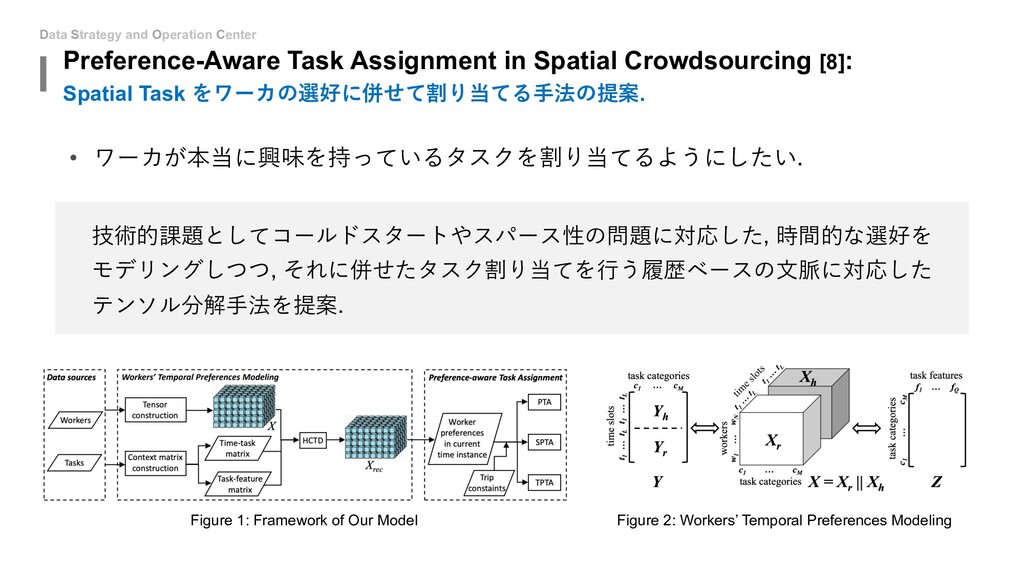{kind=link}
{kind=link}
![Data Strategy and Operation Center Human-in-the-loop interpretability prior [9]: ⼈間の](https://files.speakerdeck.com/presentations/6374552494a84c6787c93c9ae067c22c/slide_19.jpg){kind=link}
![Data Strategy and Operation Center Human-in-the-loop feature selection [10]: expert](https://files.speakerdeck.com/presentations/6374552494a84c6787c93c9ae067c22c/slide_20.jpg){kind=link}
{kind=link}
{kind=link}
![Data Strategy and Operation Center References [1] ヒューマンコンピュテーションとクラウドソーシング, JSAI 2018](https://files.speakerdeck.com/presentations/6374552494a84c6787c93c9ae067c22c/slide_23.jpg){kind=link}
{kind=link}