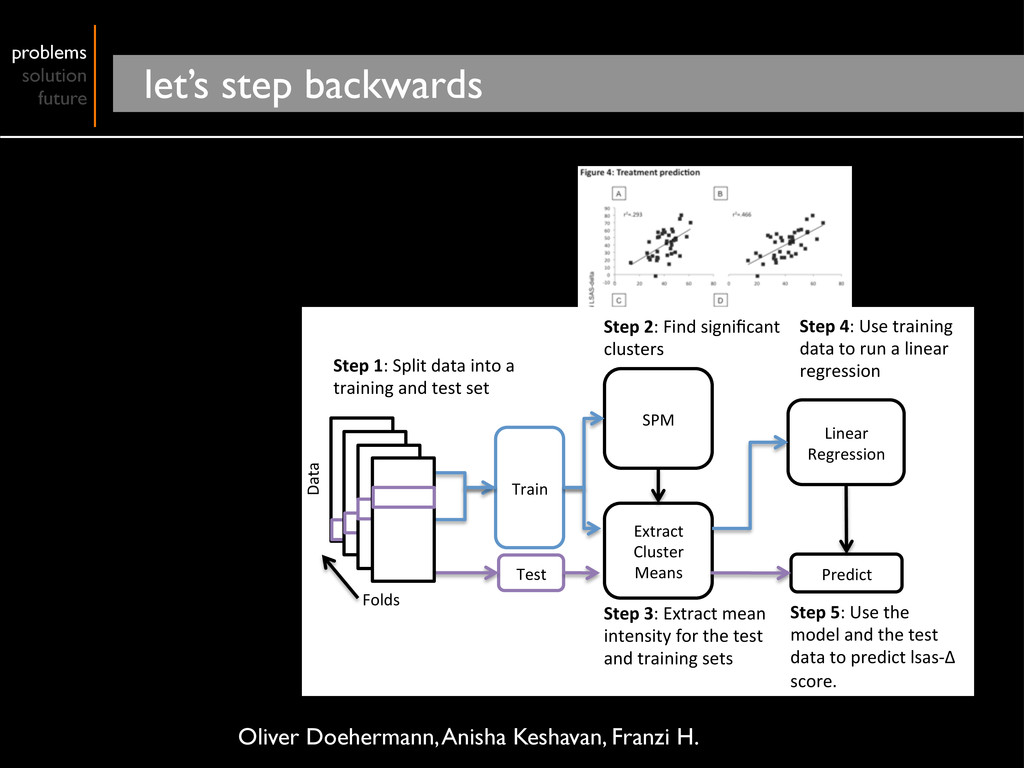
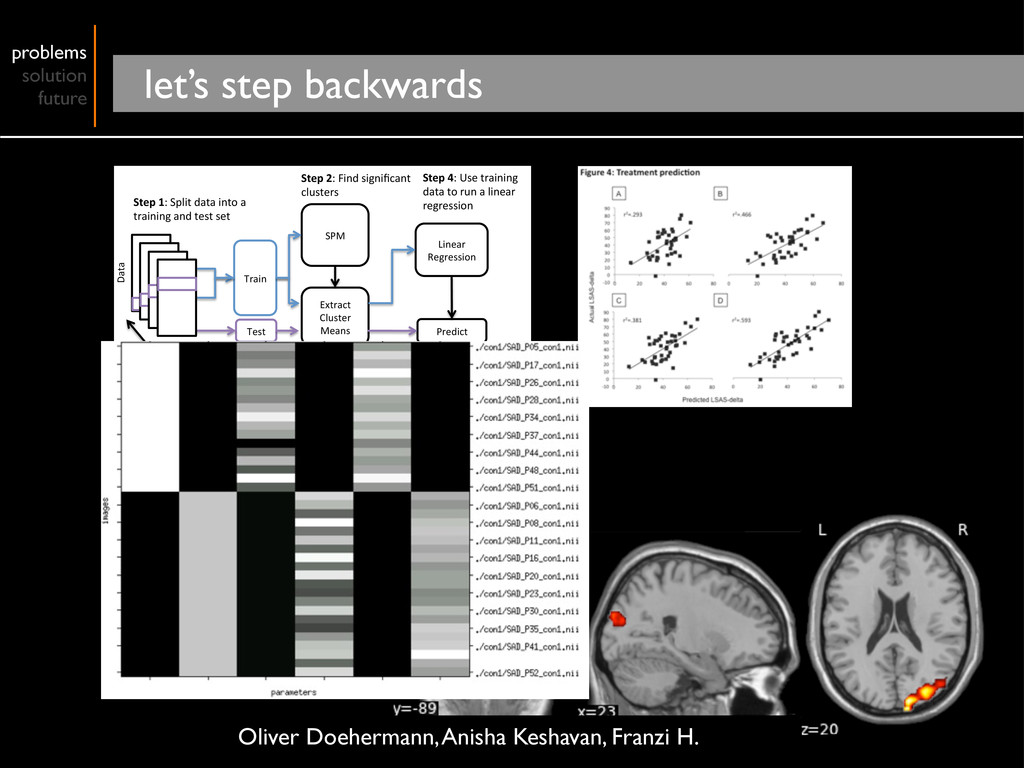
Cluster Means Linear Regression Predict Step 1: Split data into a training and test set Step 2: Find significant clusters Step 3: Extract mean intensity for the test and training sets Step 4: Use training data to run a linear regression Step 5: Use the model and the test data to predict lsas‐Δ score. Folds Data Oliver Doehermann, Anisha Keshavan, Franzi H.
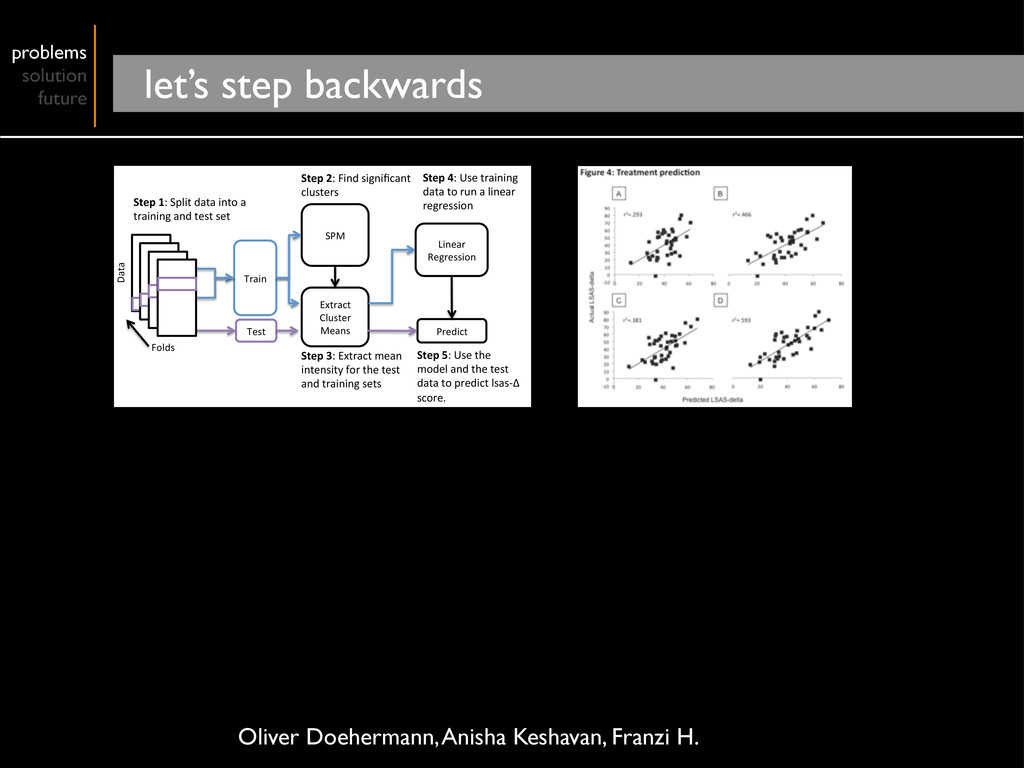
Cluster Means Linear Regression Predict Step 1: Split data into a training and test set Step 2: Find significant clusters Step 3: Extract mean intensity for the test and training sets Step 4: Use training data to run a linear regression Step 5: Use the model and the test data to predict lsas‐Δ score. Folds Data Oliver Doehermann, Anisha Keshavan, Franzi H.
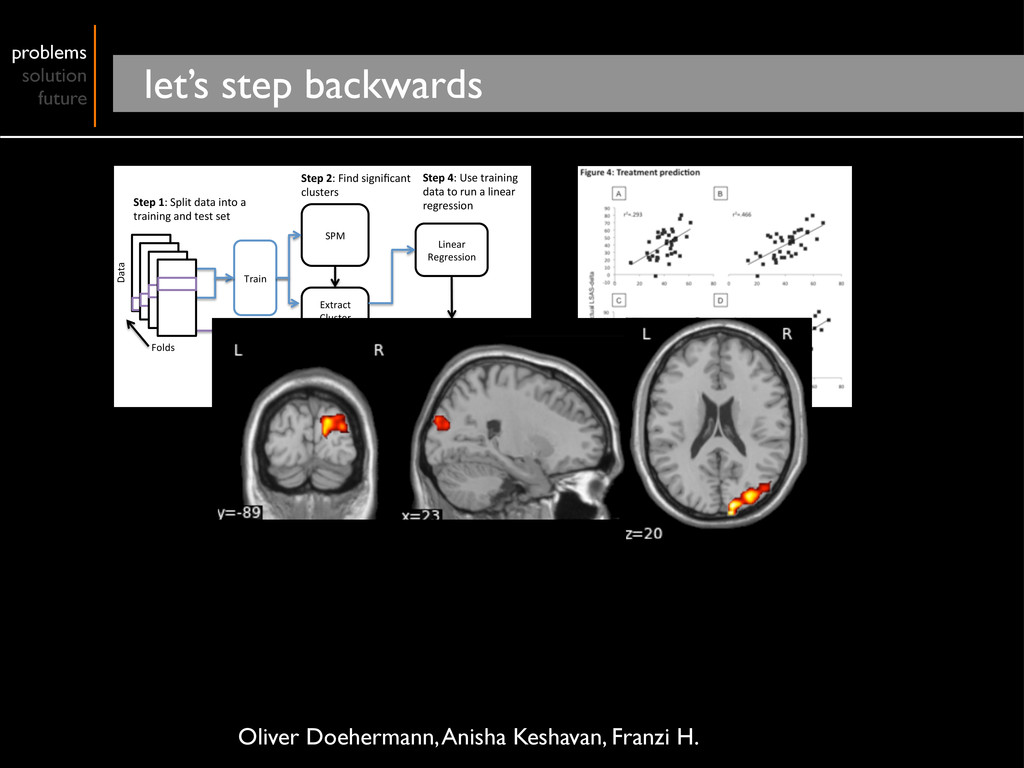
Cluster Means Linear Regression Predict Step 1: Split data into a training and test set Step 2: Find significant clusters Step 3: Extract mean intensity for the test and training sets Step 4: Use training data to run a linear regression Step 5: Use the model and the test data to predict lsas‐Δ score. Folds Data Oliver Doehermann, Anisha Keshavan, Franzi H.
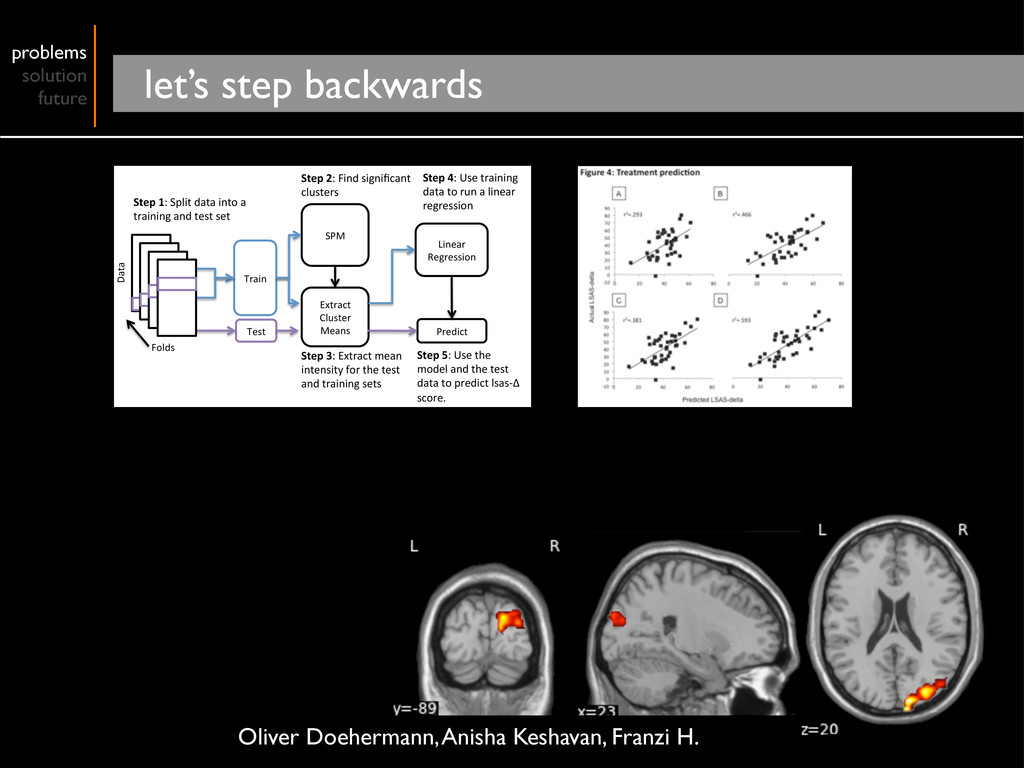
Cluster Means Linear Regression Predict Step 1: Split data into a training and test set Step 2: Find significant clusters Step 3: Extract mean intensity for the test and training sets Step 4: Use training data to run a linear regression Step 5: Use the model and the test data to predict lsas‐Δ score. Folds Data Oliver Doehermann, Anisha Keshavan, Franzi H.
Cluster Means Linear Regression Predict Step 1: Split data into a training and test set Step 2: Find significant clusters Step 3: Extract mean intensity for the test and training sets Step 4: Use training data to run a linear regression Step 5: Use the model and the test data to predict lsas‐Δ score. Folds Data Oliver Doehermann, Anisha Keshavan, Franzi H.
Cluster Means Linear Regression Predict Step 1: Split data into a training and test set Step 2: Find significant clusters Step 3: Extract mean intensity for the test and training sets Step 4: Use training data to run a linear regression Step 5: Use the model and the test data to predict lsas‐Δ score. Folds Data Oliver Doehermann, Anisha Keshavan, Franzi H.
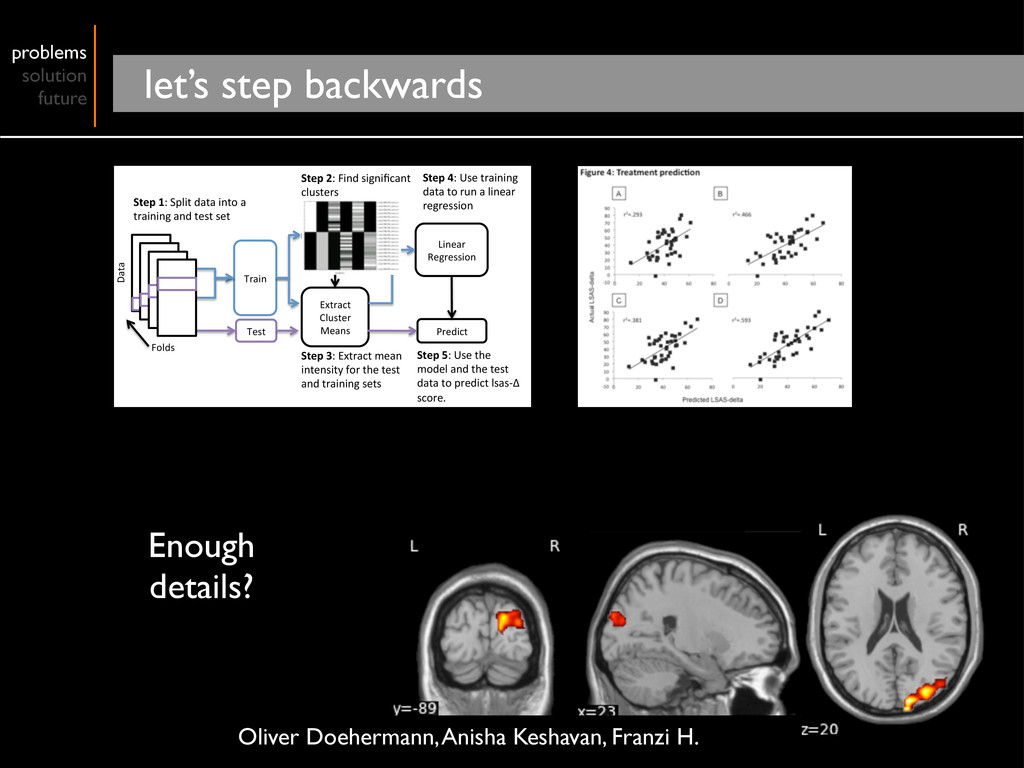
Cluster Means Linear Regression Predict Step 1: Split data into a training and test set Step 2: Find significant clusters Step 3: Extract mean intensity for the test and training sets Step 4: Use training data to run a linear regression Step 5: Use the model and the test data to predict lsas‐Δ score. Folds Data Enough details? Oliver Doehermann, Anisha Keshavan, Franzi H.
Cluster Means Linear Regression Predict Step 1: Split data into a training and test set Step 2: Find significant clusters Step 3: Extract mean intensity for the test and training sets Step 4: Use training data to run a linear regression Step 5: Use the model and the test data to predict lsas‐Δ score. Folds Data Enough details? No Oliver Doehermann, Anisha Keshavan, Franzi H.
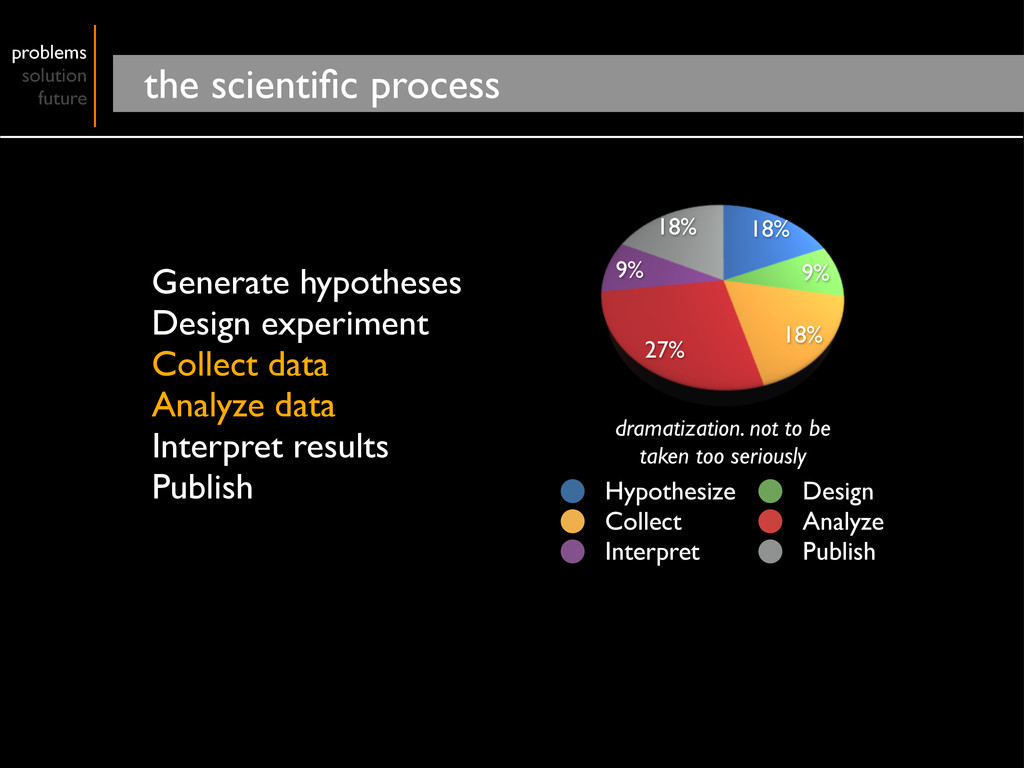
Collect data Analyze data Interpret results Publish 18% 9% 18% 27% 9% 18% Hypothesize Design Collect Analyze Interpret Publish dramatization. not to be taken too seriously
motivation is the ubiquity of error - the awareness that mistakes and self-delusion can creep in absolutely anywhere and that the scientist’s effort is primarily expended in recognizing and rooting out error.” Donoho et al. (2009) assumed veracity of publications dependence on peer review as a proxy for testing
Autism, ADHD, Schizophrenia) cross-discipline interaction : - provides data to test their algorithms problems solution future but why share data and code?
Autism, ADHD, Schizophrenia) cross-discipline interaction : - provides data to test their algorithms - increases sample size for learning algorithms problems solution future but why share data and code?
Autism, ADHD, Schizophrenia) cross-discipline interaction : - provides data to test their algorithms - increases sample size for learning algorithms pedagogy : problems solution future but why share data and code?
Autism, ADHD, Schizophrenia) cross-discipline interaction : - provides data to test their algorithms - increases sample size for learning algorithms pedagogy : provides easy mechanism to train new personnel problems solution future but why share data and code?
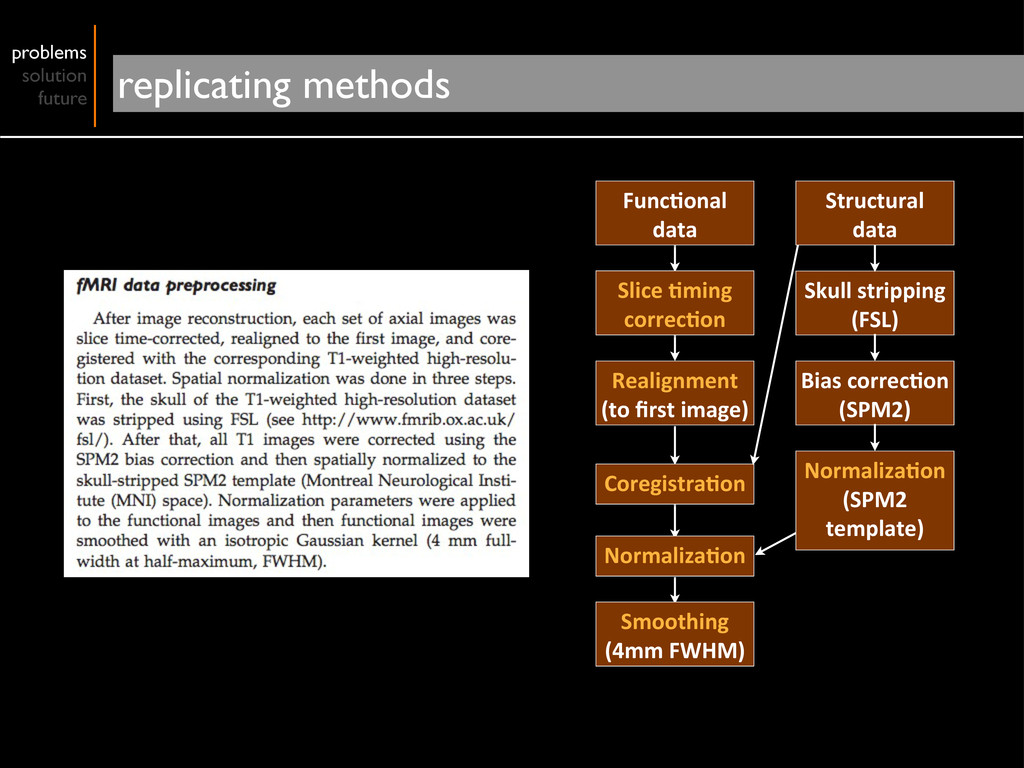
but provide no infrastructure for storage, distribution most scientists do not have the time to curate data no standard ontology for describing experiments, data, derived data, workflows problems solution future current barriers
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}