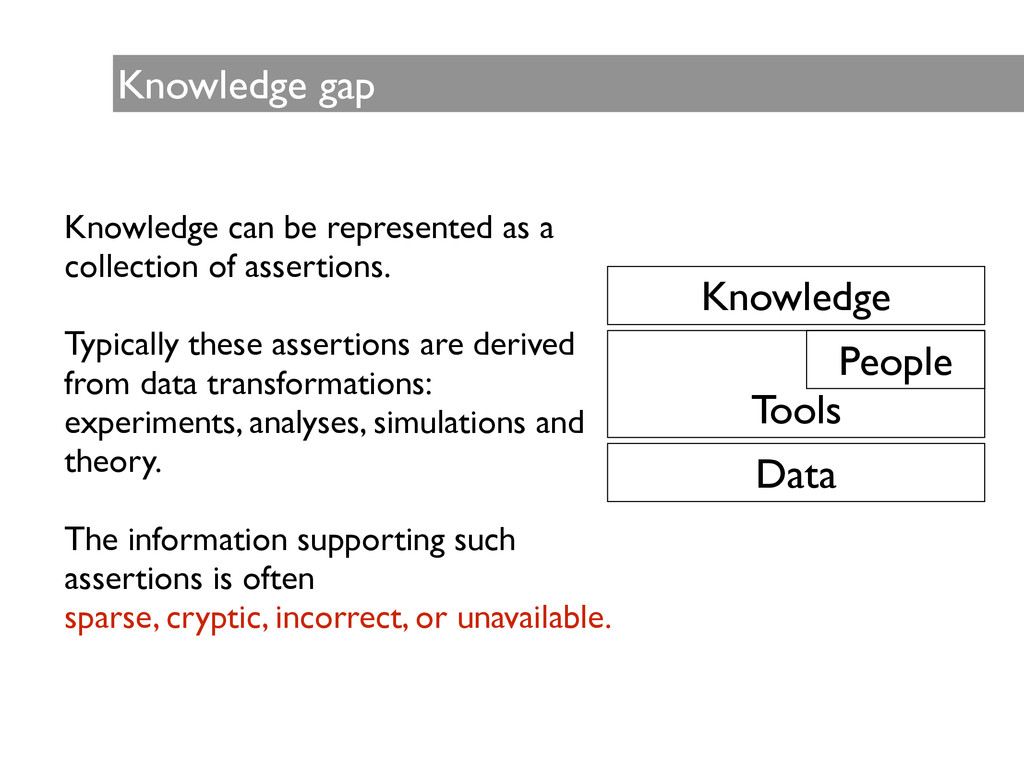
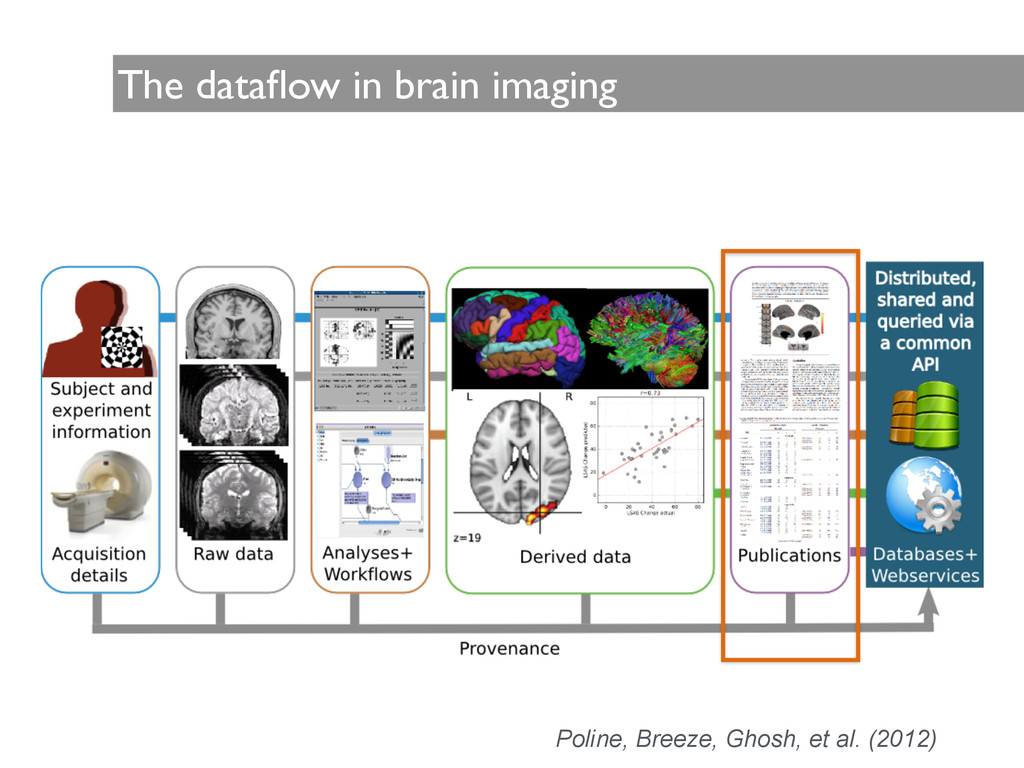
assertions. ! Typically these assertions are derived from data transformations: experiments, analyses, simulations and theory. ! The information supporting such assertions is often sparse, cryptic, incorrect, or unavailable. Data ! Tools Knowledge People
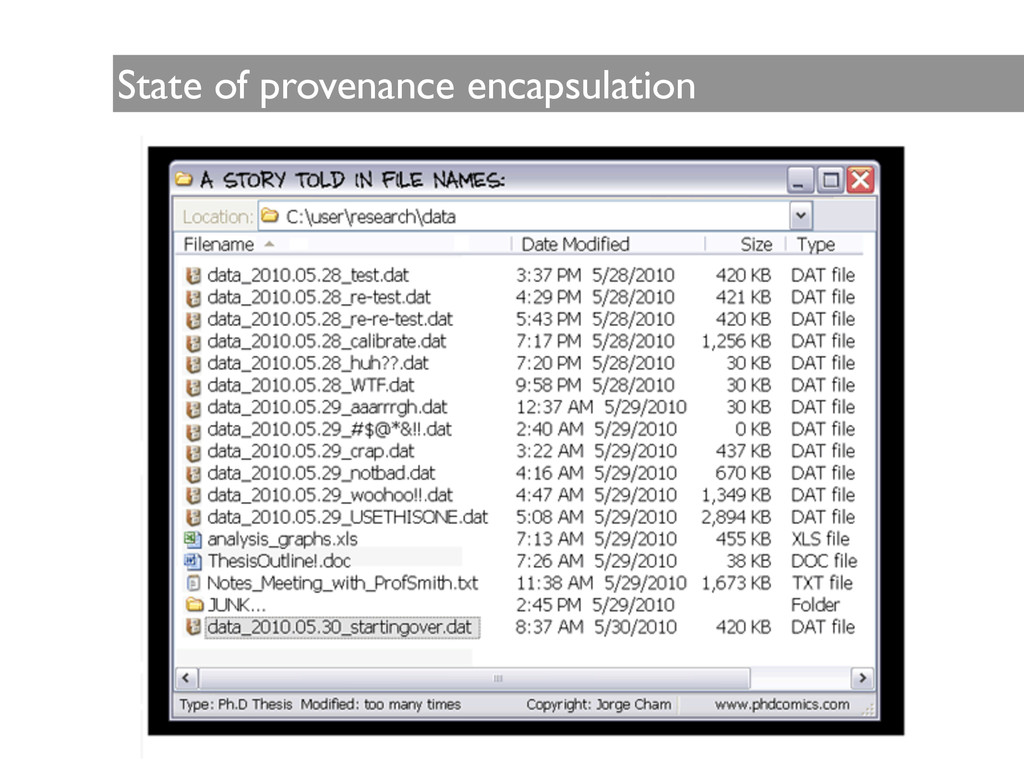
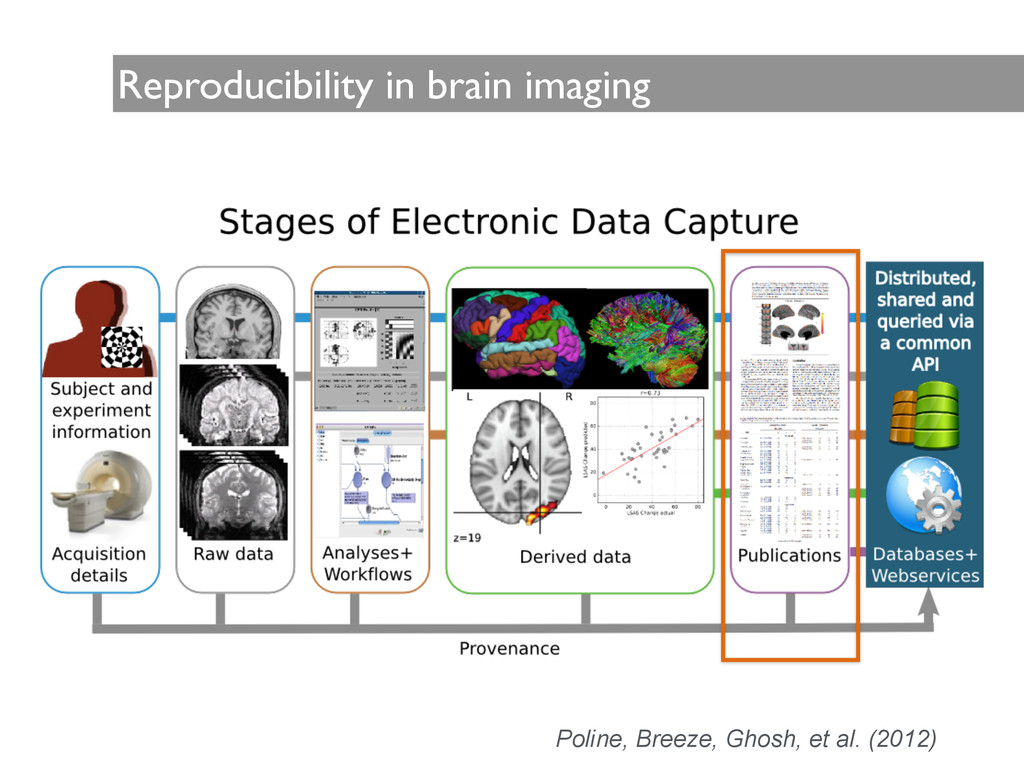
error is ubiquitous in scientific computing, and one needs to work very diligently and energetically to eliminate it. One needs a very clear idea of what has been done in order to know where to look for likely sources of error. ! I often cannot really be sure what a student or colleague has done from his/her own presentation, and in fact often his/her description does not agree with my own understanding of what has been done, once I look carefully at the scripts. ! Actually, I find that researchers quite generally forget what they have done and misrepresent their computations.” Donoho (2010)
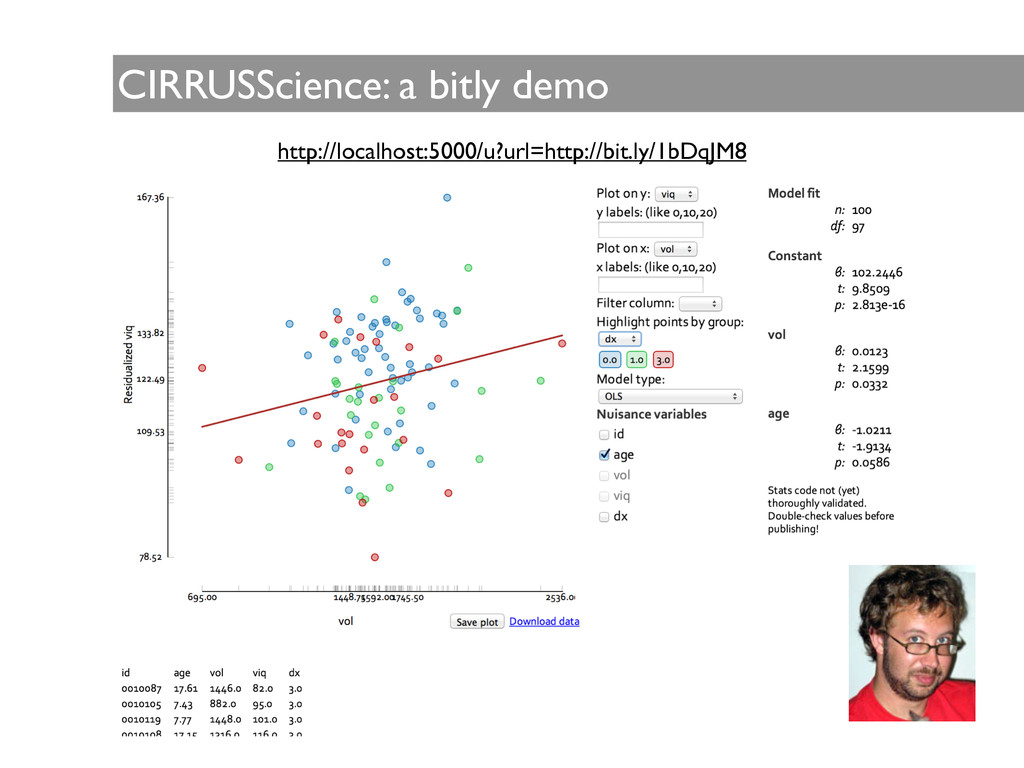
published between 2008 and 2010, retrieve all brain volumes and ADOS scores of persons with autism spectrum disorder who are right handed and under the age of 10. ! • Rerun the analysis used in publication X on my data. ! • Is the volume of the caudate nucleus smaller in persons with Obsessive Compulsive Disorder compared to controls? ! • Find data-use agreements for open-accessible datasets used in articles by author Y.
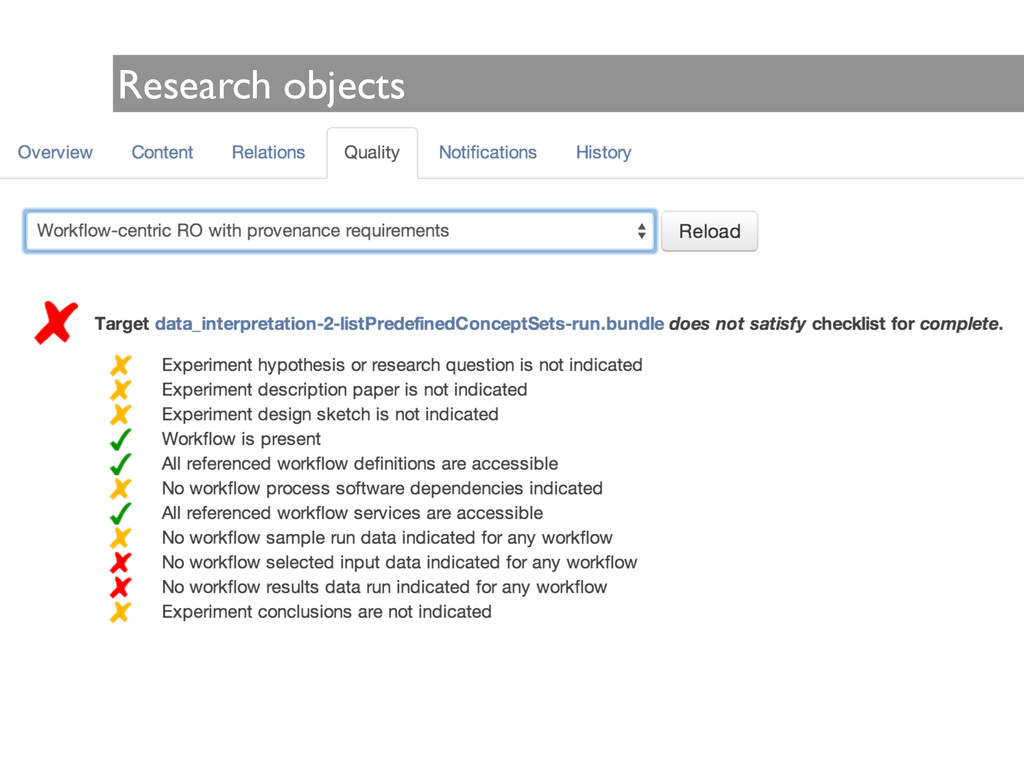
human effort to answer the previous queries, errors can happen from the lack of complete specification of data or methods, as well as from misinterpretation of methods
and are processed with methods specific to the sub-domain, limiting integration. • Provenance tracking tools are typically not integrated into scientific software, making the curation process time consuming, resource intensive, and error prone. • In many research laboratories much of the derived data are deleted, keeping only the bits essential for publication. • There are no standards for computational platforms. • Research involves proprietary tools and binary data formats that are harder to instrument. ! • There is no formal vocabulary to describe all entities, activities and agents in the domain, and vocabulary creation is a time-consuming process. • Information is behind barriers.
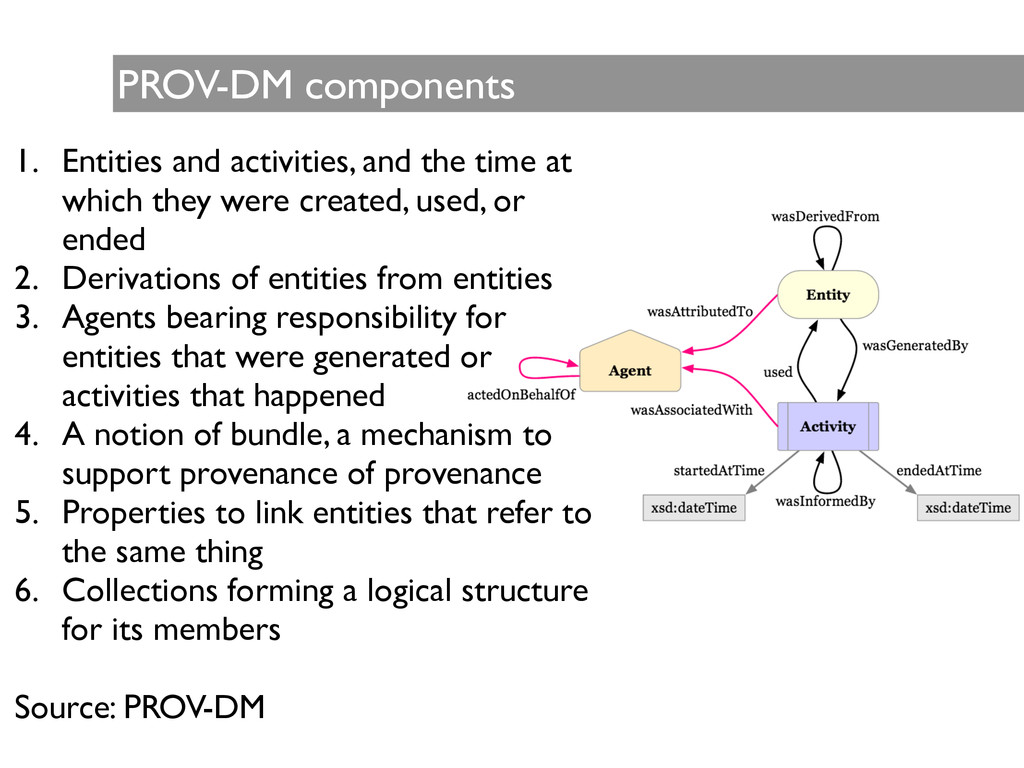
activities, and people involved in producing a piece of data or thing, which can be used to form assessments about its quality, reliability or trustworthiness. (source: w3c)
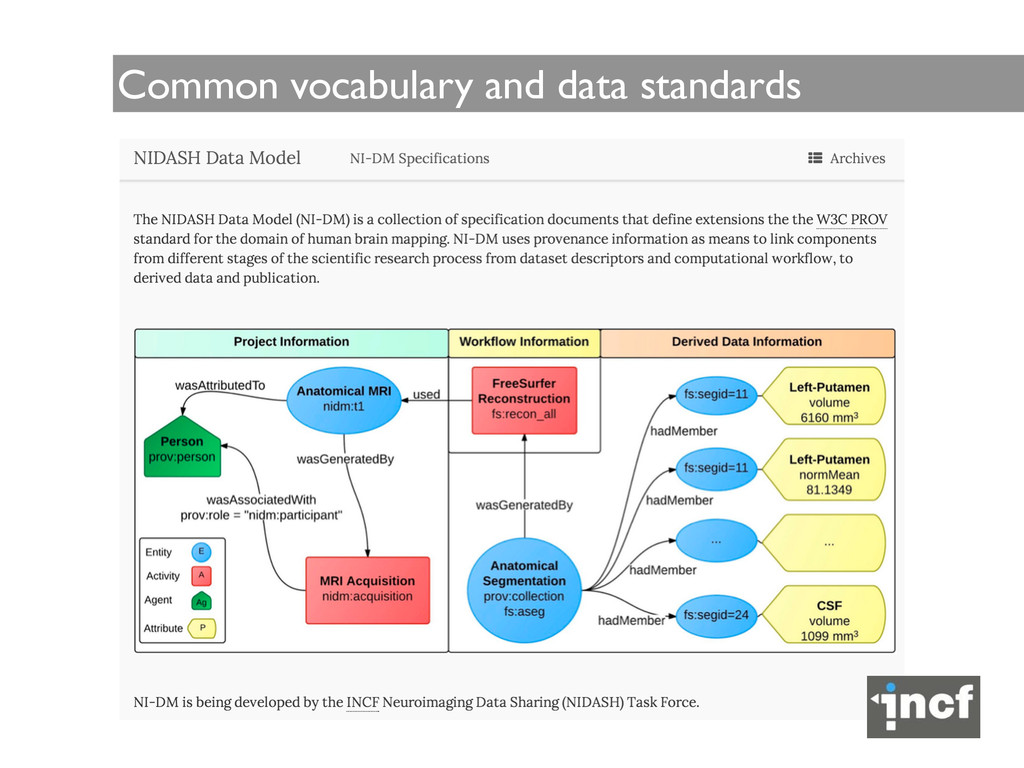
is an abstract conceptual formulation of information that explicitly determines the structure of data and allows software and people to communicate and interpret data precisely. (source: wikipedia) ! What is PROV-DM? PROV-DM is the conceptual data model that forms a basis for the W3C provenance (PROV) family of specifications. PROV- DM provides a generic basis that captures relationships associated with the creation and modification of entities by activities and agents.
which they were created, used, or ended 2. Derivations of entities from entities 3. Agents bearing responsibility for entities that were generated or activities that happened 4. A notion of bundle, a mechanism to support provenance of provenance 5. Properties to link entities that refer to the same thing 6. Collections forming a logical structure for its members ! Source: PROV-DM
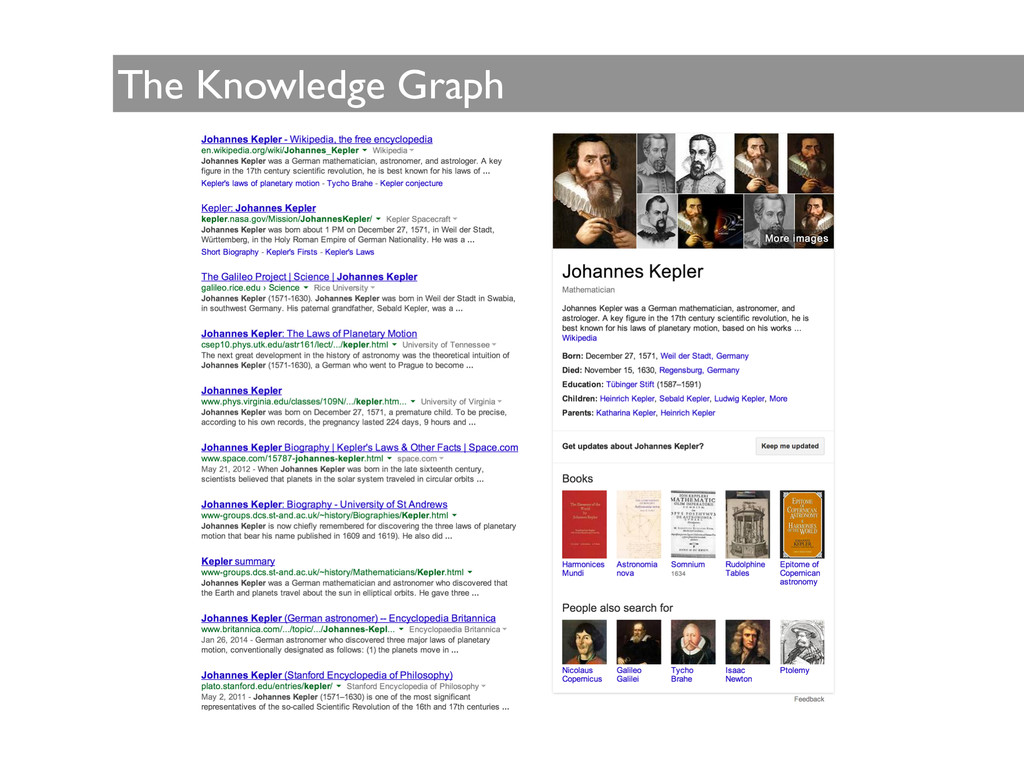
data and metadata (about entities, activities and agents) within the same context ! • A formal, technology-agnostic representation of machine-accessible structured information ! • Federated queries using SPARQL when represented as RDF ! • A W3C recommendation simplifies app development and allows integration with other future services
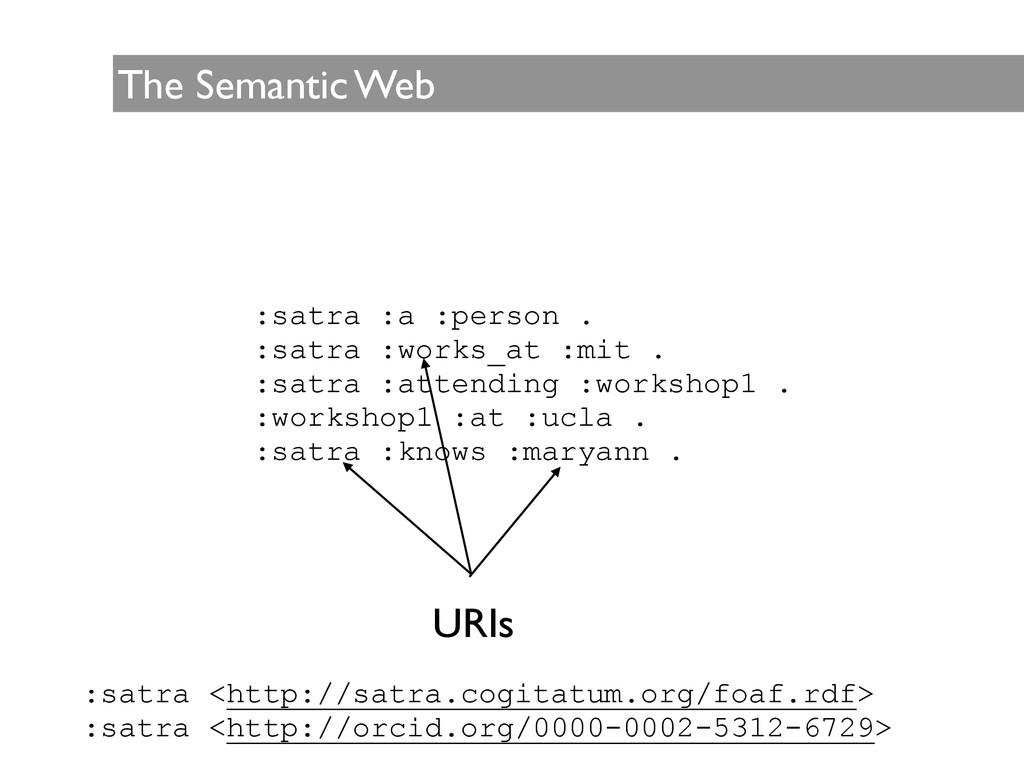
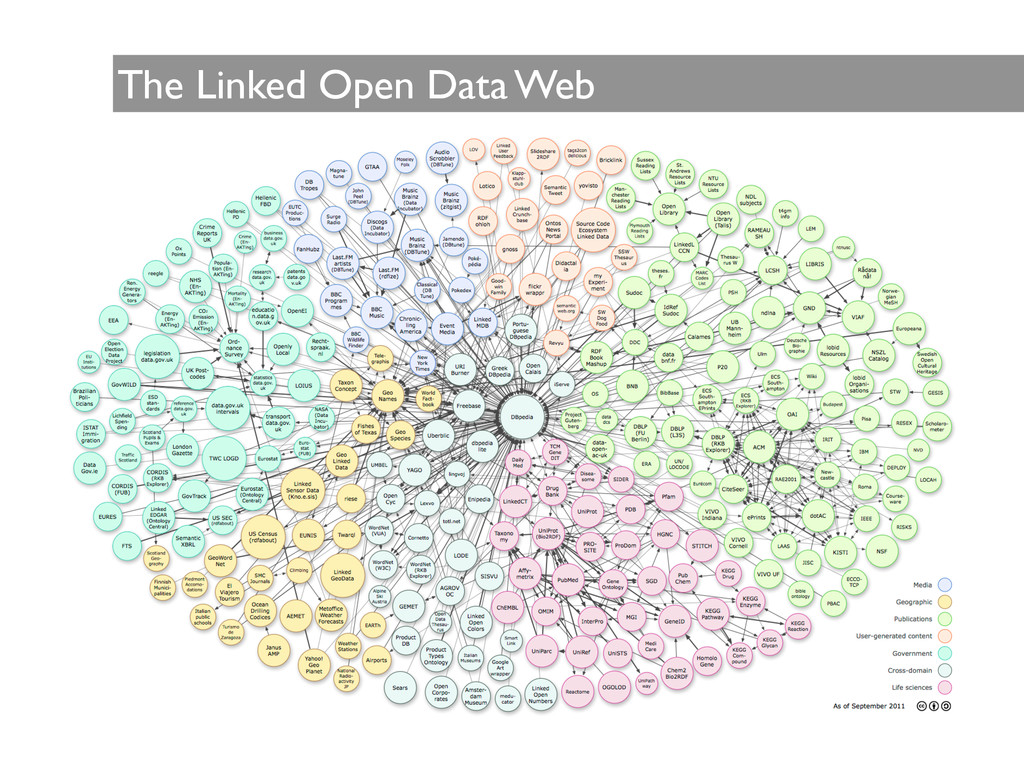
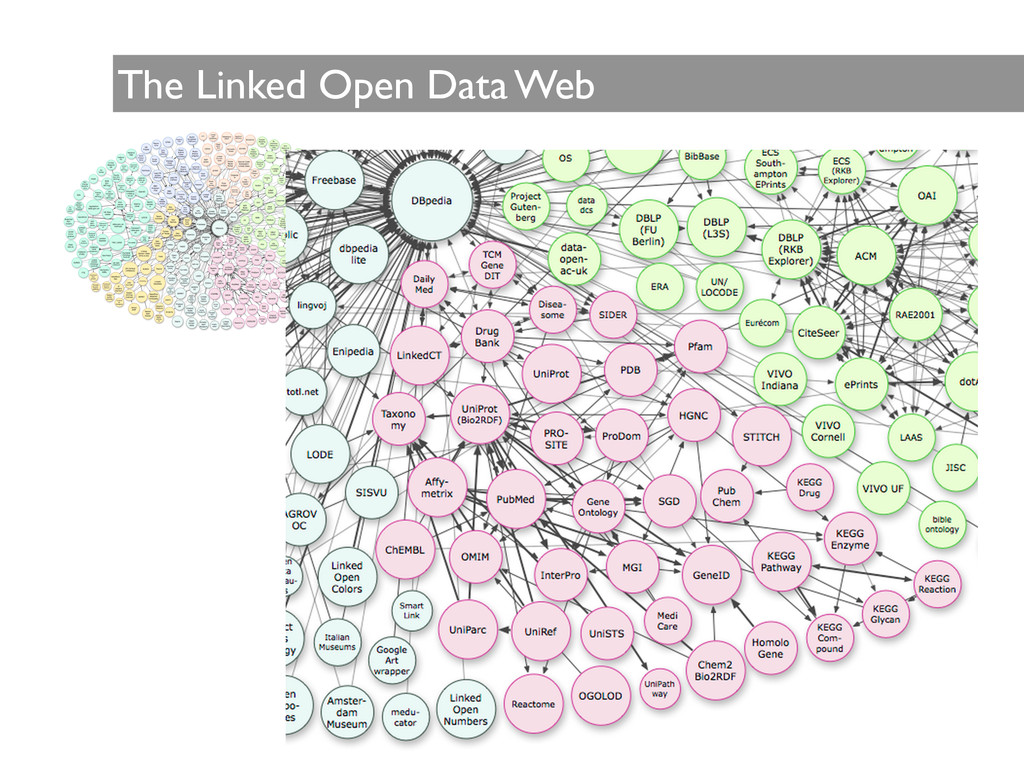
framework that allows data sharing and reuse, is based on the Resource Description Framework (RDF), and extends the principles of the Web from pages to machine useful data • Data and descriptors are accessed using uniform resource identifiers (URIs) • Unlike the traditional Web, the source and the target along with the relationship itself are unambiguously named with URIs and form a ‘triple’ of a subject, a relationship and an object nif:tbi rdf:type nif:mental_disorder . • This flexible approach allows data to be easily added and for the nature of the relations to evolve, resulting in an architecture that allows retrieving answers to more complex queries
(official W3C recommdation in March, 2013) • SPARQL allows users to write unambiguous queries ! • Supports federation: • a query can be distributed to multiple SPARQL endpoints, computed and results gathered • A SPARQL client library can query a static RDF document or a SPARQL endpoint
information in standardized and machine accessible form • View data from a provenance perspective • as products of activities or transformations carried out by people, software or machines • Allow any individual, laboratory, or institution to discover and share data and computational services • Immediately re-test an algorithm, re-validate results or test a new hypothesis on new data • Develop applications based on a consistent, federated query and update interface • Provide a decentralized linked data and computational network
genomics hypotheses about the yeast Saccharomyces cerevisiae and experimentally tested these hypotheses by using laboratory automation.” ! Abe Identify the full dynamical model from scratch without prior knowledge or structural assumptions. … The method performed well to high levels of noise for most states, could identify the correct model de novo, and make better predictions than ordinary parametric regression and neural network models. Adam - King et al. (2009); Abe - Schmidt et al. (2011)
for communication • Rich structured information including provenance • Domain specific object models that are embedded in the common structure • Data/Content can be repurposed differentially for applications • Execution duration could be used to instrument schedulers • Parametric failure modes can be tracked across large databases • Determine “amount” of existing data on a particular topic
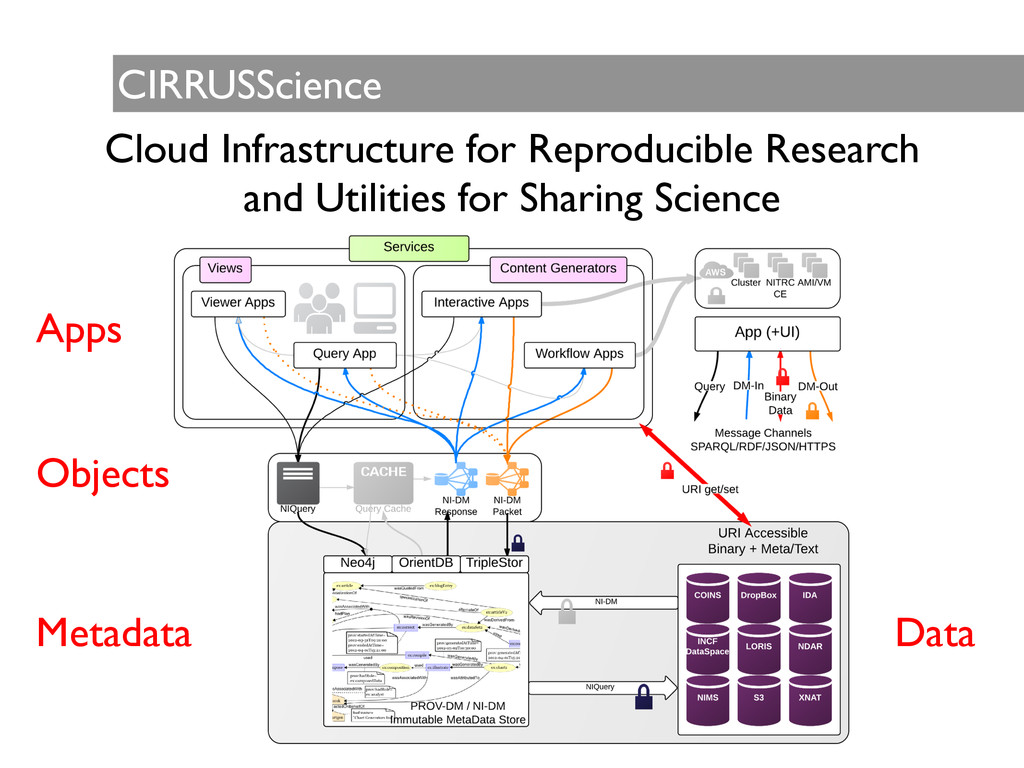
Provenance tracking can: - improve credibility (reduce loss) - aggregate information - extract knowledge ! CIRRUSScience aims to integrate computational resources and data using common object models. Summary
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}