Reproducible research requires that information pertaining to all aspects of a research activity are captured and represented richly. However, most scientific domains, including neuroscience, only capture pieces of information that are deemed relevant. In this talk, we provide an overview of the components necessary to create this information-rich landscape and describe a prototype platform for knowledge exploration. In particular, we focus on a technology agnostic data provenance model as the core representation and Semantic Web technologies that leverage such a representation. While the data and analysis methods are related to brain imaging, the same principles and architecture are applicable to any scientific domain.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![A Prototype Platform NIDM platform Satrajit S. Ghosh - [email protected]](https://files.speakerdeck.com/presentations/8dfccc40f22301304d2956f02c133fac/slide_29.jpg){kind=link}
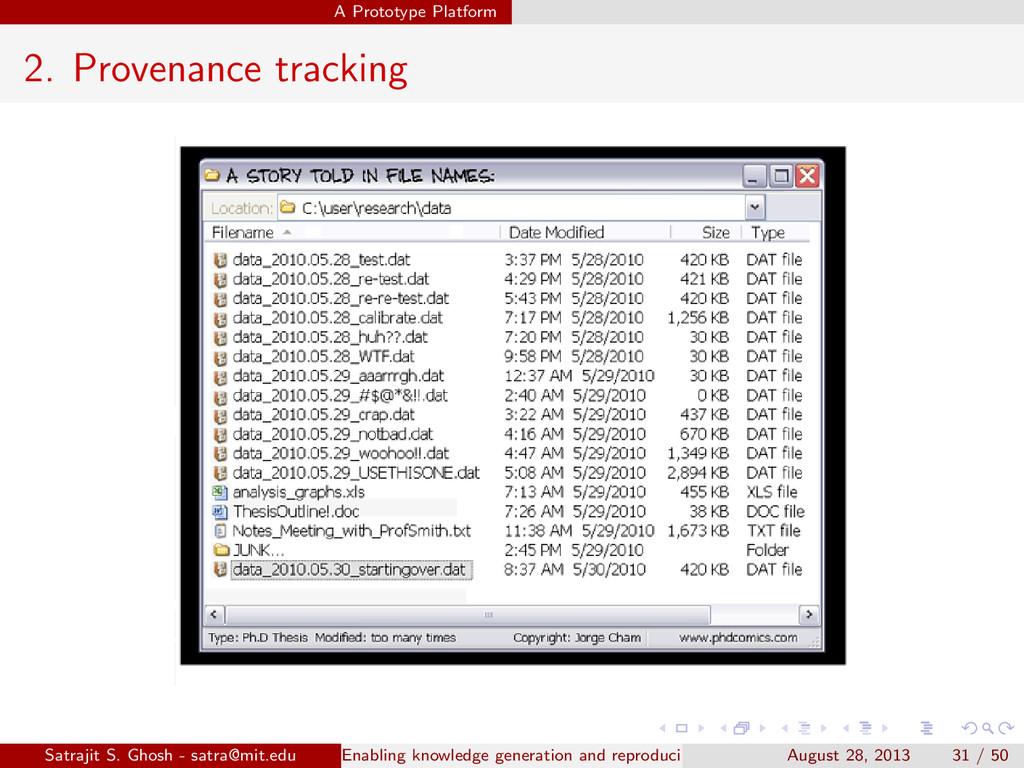{kind=link}
{kind=link}
{kind=link}
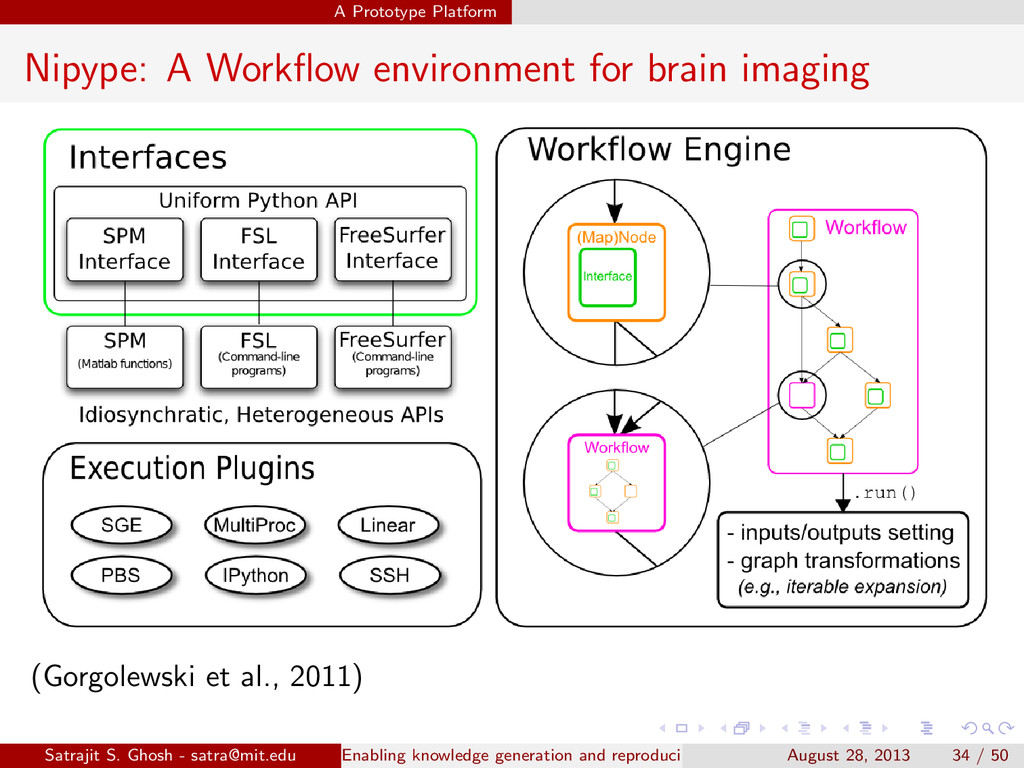{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
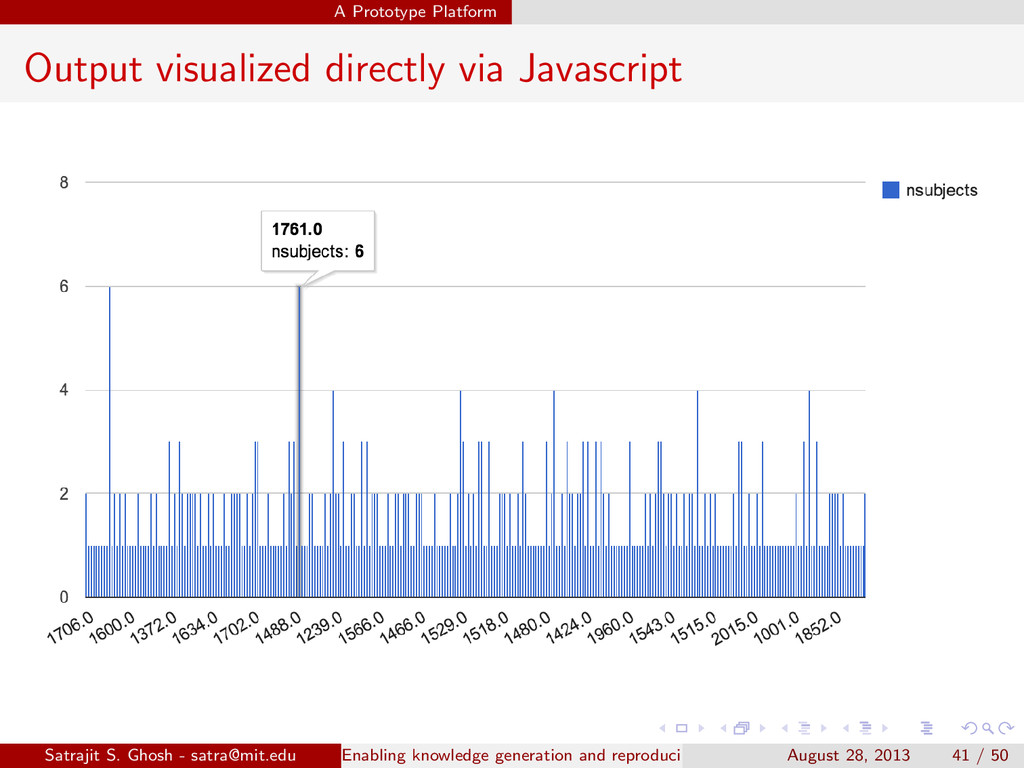{kind=link}
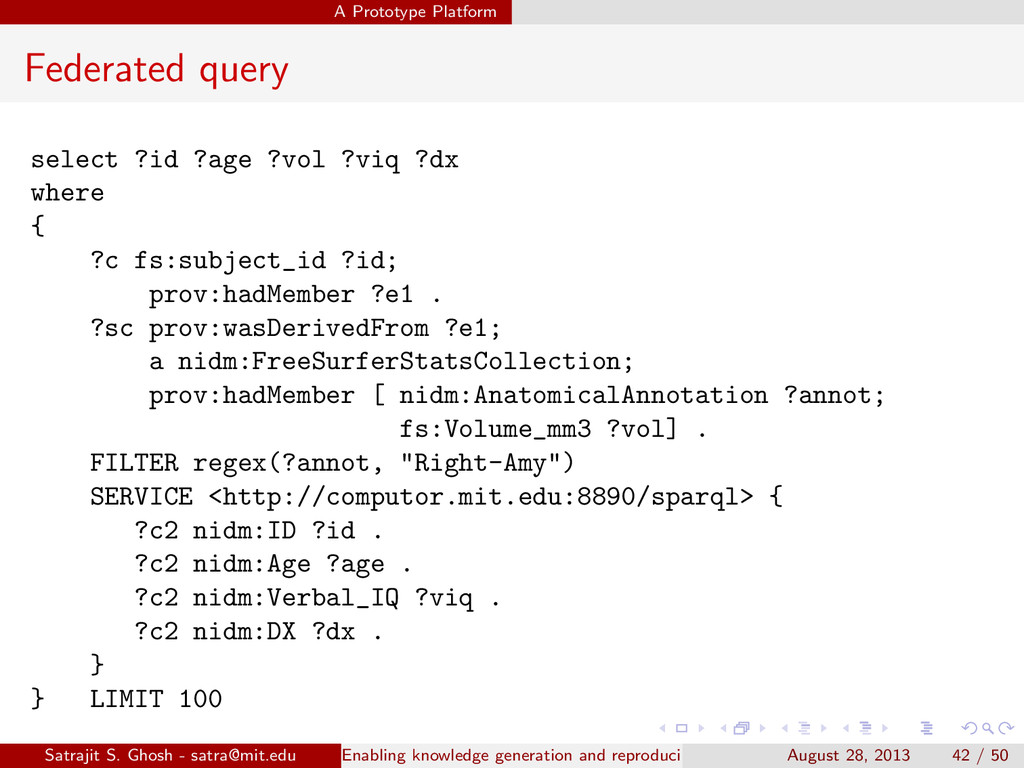{kind=link}
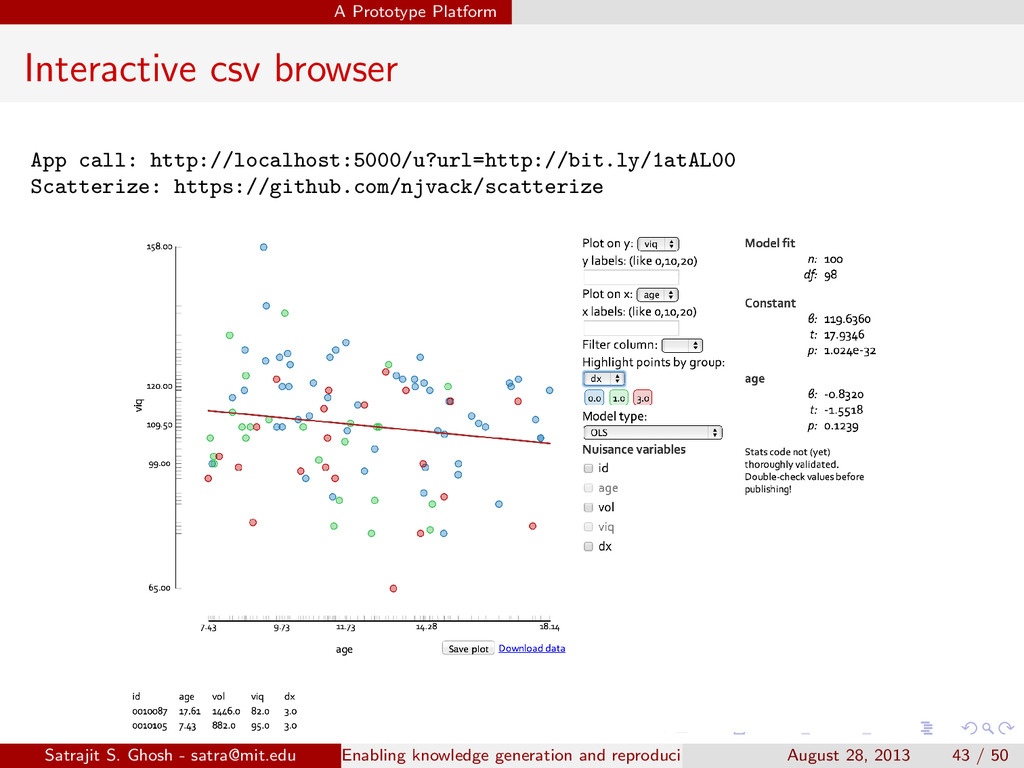{kind=link}
{kind=link}
{kind=link}
{kind=link}
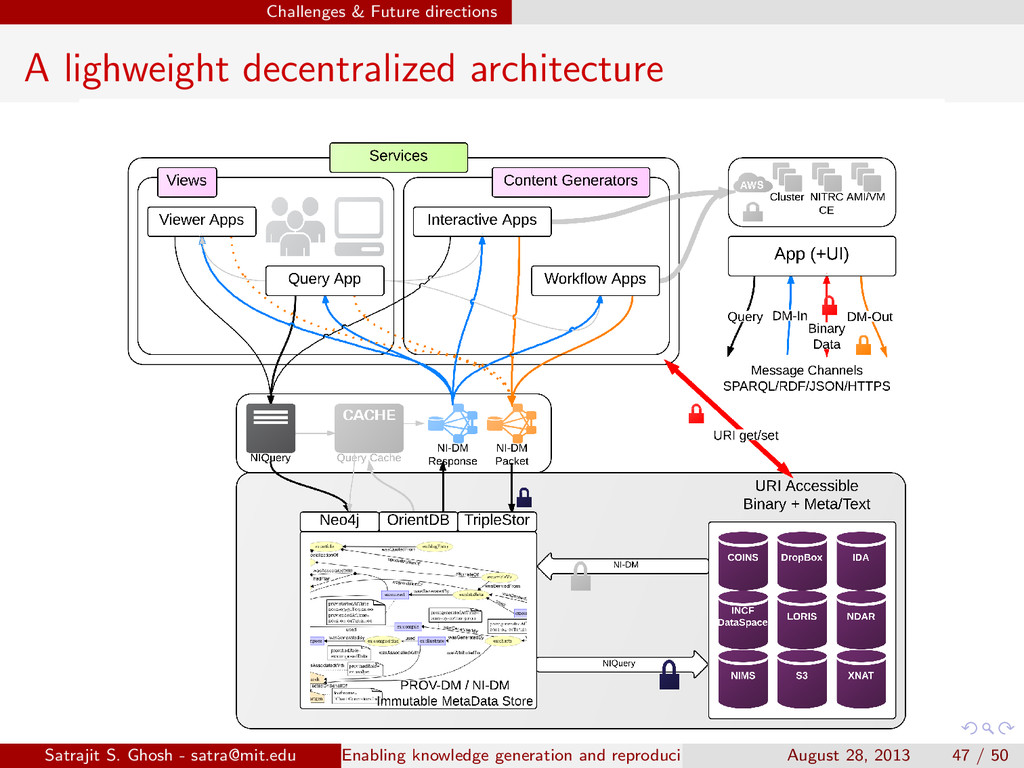{kind=link}
{kind=link}
{kind=link}
{kind=link}