ICML2018読み会 (https://connpass.com/event/92705/) での発表資料です.
H. Cai, J. Yang, W. Zhang, S. Han, and Y. Yu, “Path-Level Network Transformation for Efficient Architecture Search,” in Proceedings of the 35th International Conference on Machine Learning, 2018, pp. 677–686.
http://proceedings.mlr.press/v80/cai18a.html
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
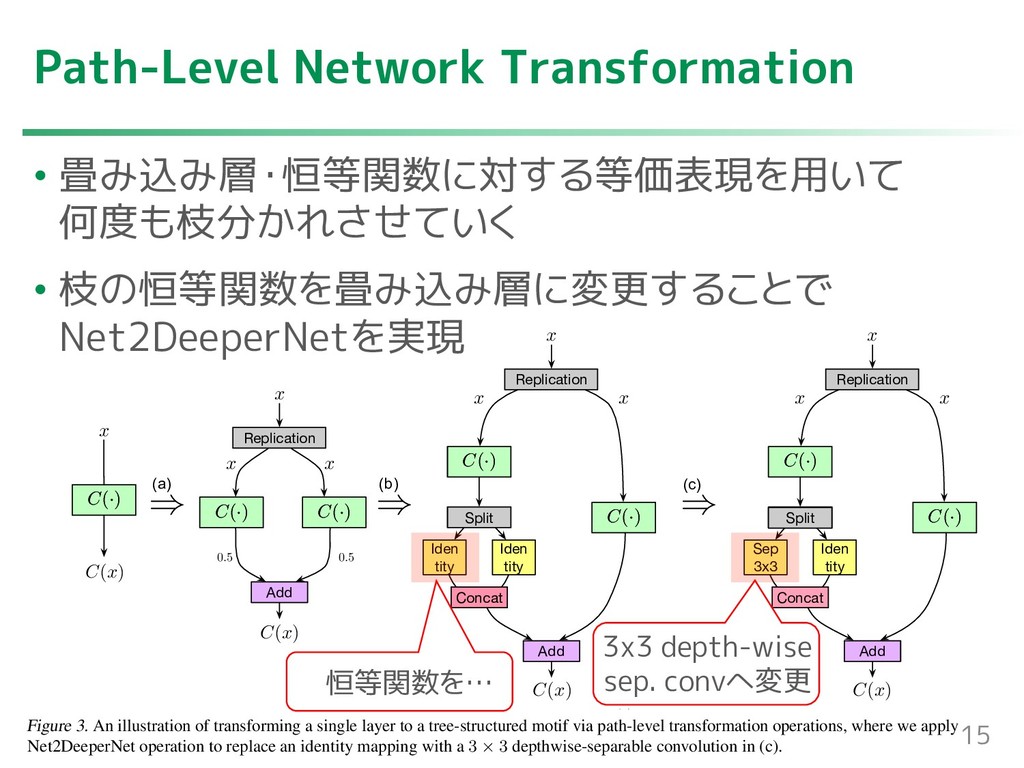{kind=link}
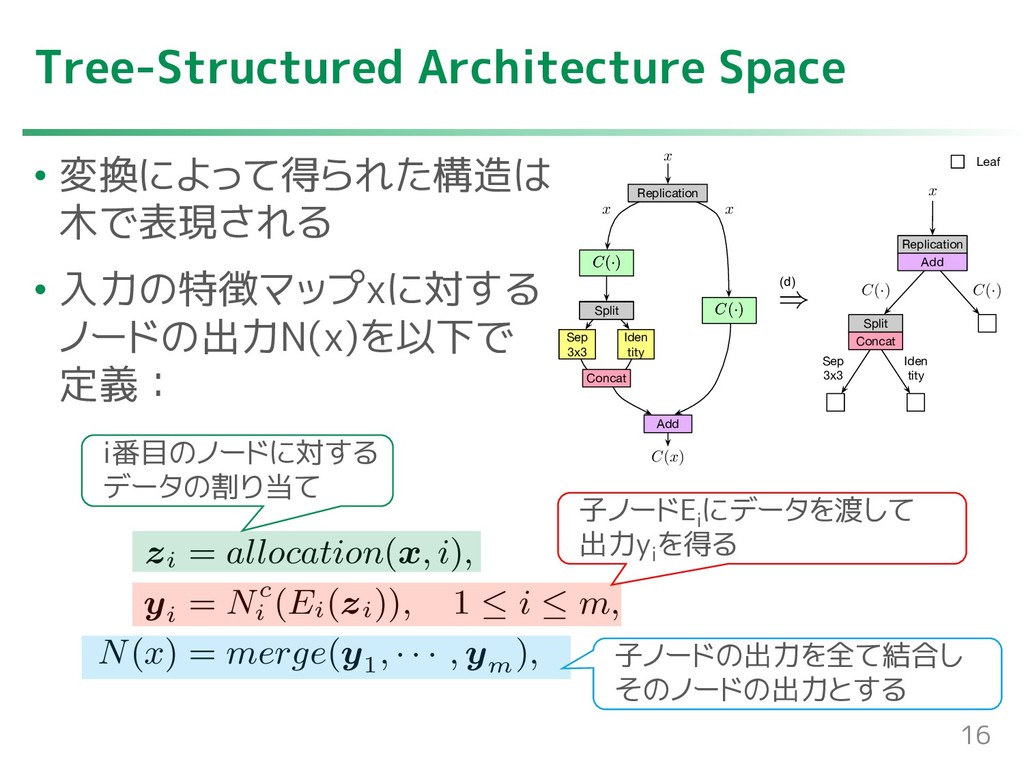{kind=link}
{kind=link}
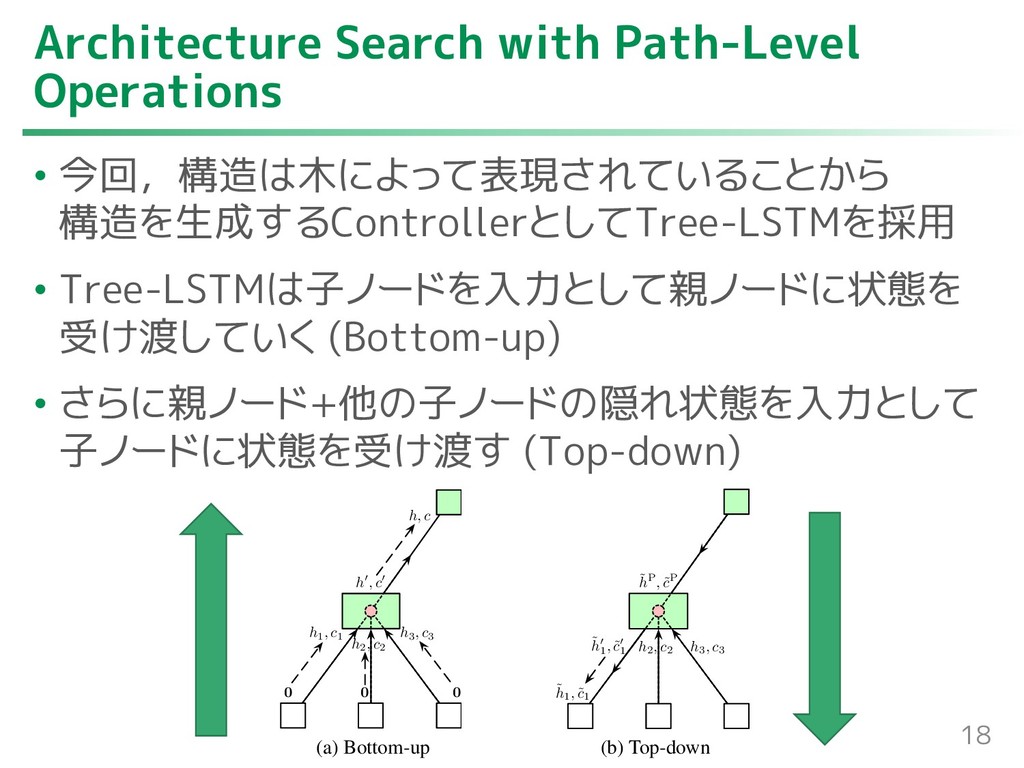{kind=link}
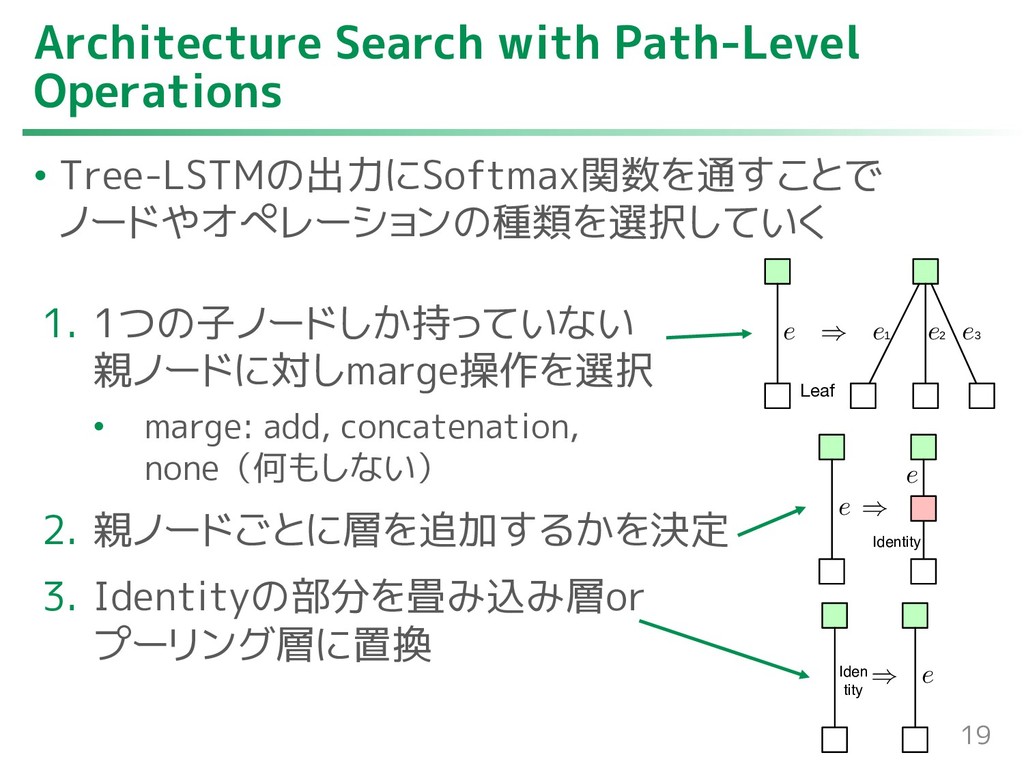{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![References 33 • [Pham et al., 2018] H. Pham, M.](https://files.speakerdeck.com/presentations/85f63cae79024215911a7cab11df0863/slide_32.jpg){kind=link}
![References 34 • [Huang et al., 2017] G. Huang, Z.](https://files.speakerdeck.com/presentations/85f63cae79024215911a7cab11df0863/slide_33.jpg){kind=link}