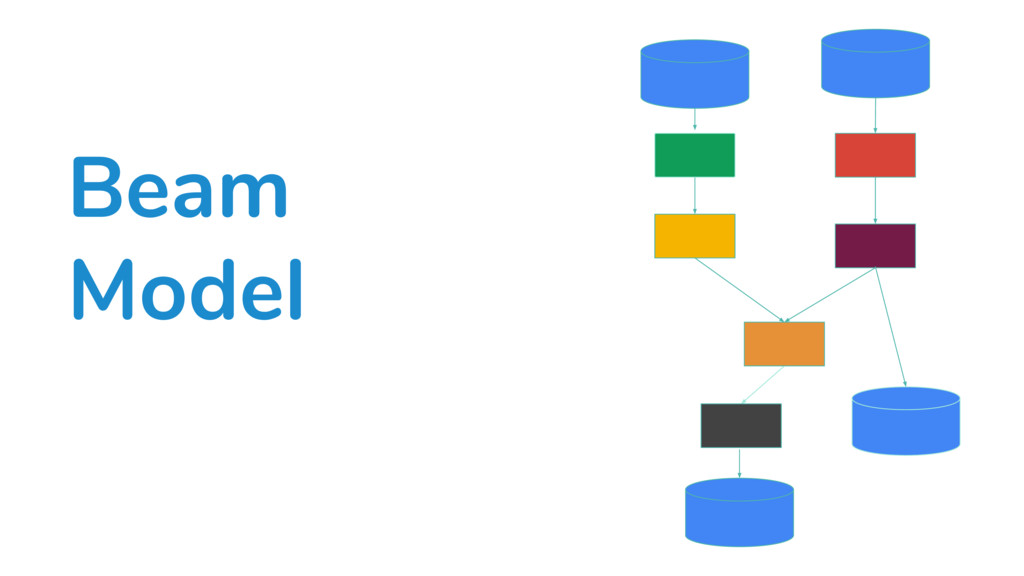
In this talk, we present the new Python SDK for Apache Beam - a parallel programming model that allows one to implement batch and streaming data processing jobs that can run on a variety of execution engines like Apache Spark and Google Cloud Dataflow. We will use examples to discuss some of the interesting challenges in providing a Pythonic API and execution environment for distributed processing.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
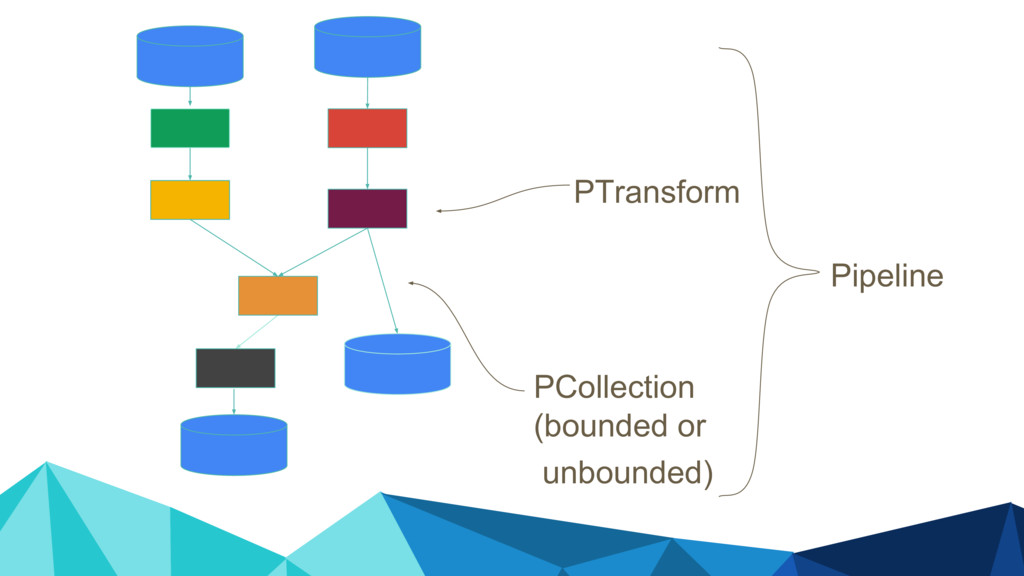{kind=link}
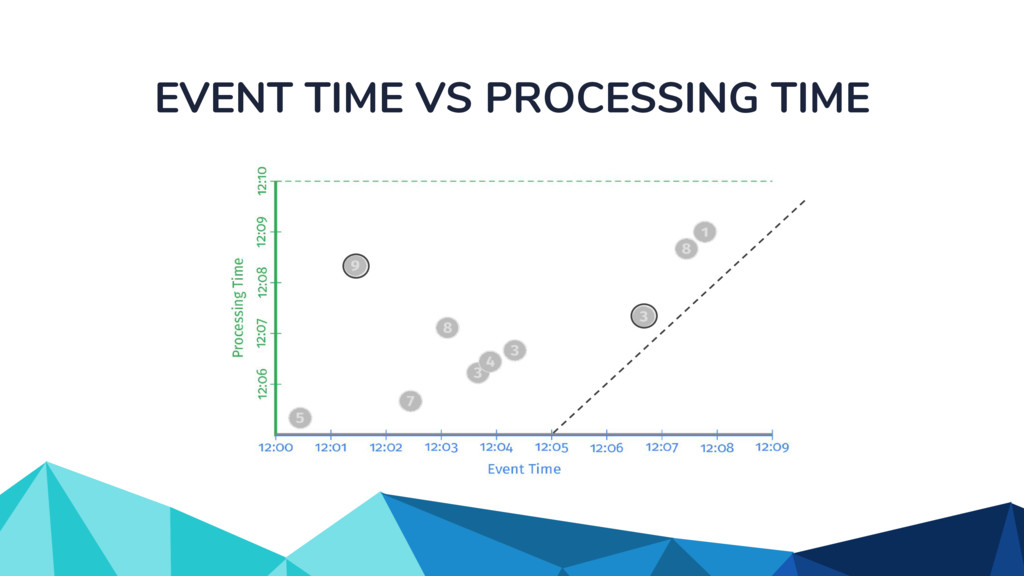{kind=link}
{kind=link}
![WHAT IS BEING COMPUTED? scores: PCollection[KV[str, int]] = (input |](https://files.speakerdeck.com/presentations/d6d4e08b0fcd40118ab79688d1d51fd5/slide_22.jpg){kind=link}
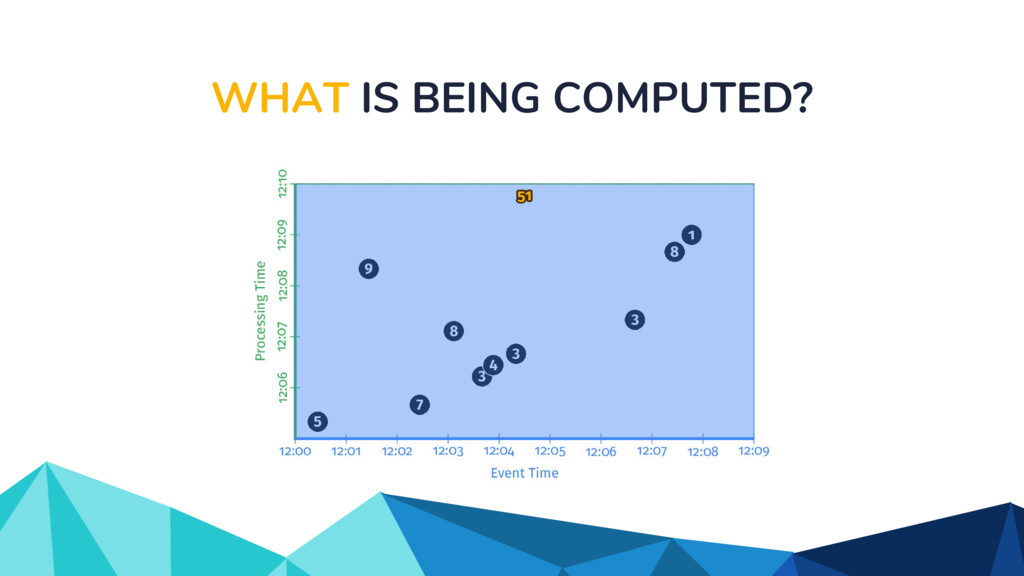{kind=link}
![WHERE IN EVENT TIME? scores: PCollection[KV[str, int]] = (input |](https://files.speakerdeck.com/presentations/d6d4e08b0fcd40118ab79688d1d51fd5/slide_24.jpg){kind=link}
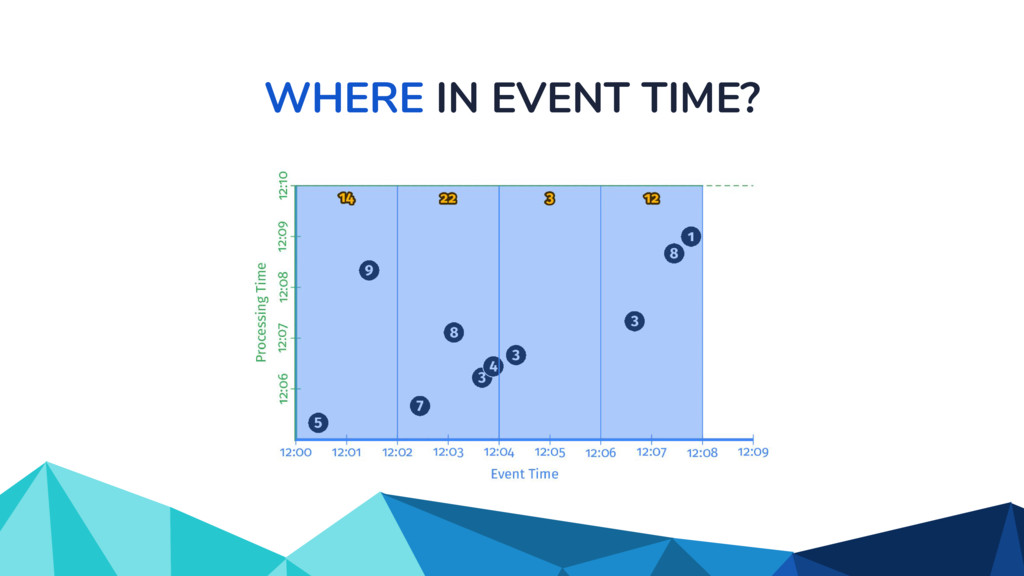{kind=link}
{kind=link}
![WHEN IN PROCESSING TIME? scores: PCollection[KV[str, int]] = (input |](https://files.speakerdeck.com/presentations/d6d4e08b0fcd40118ab79688d1d51fd5/slide_27.jpg){kind=link}
{kind=link}
![HOW DO REFINEMENTS HAPPEN? scores: PCollection[KV[str, int]] = (input |](https://files.speakerdeck.com/presentations/d6d4e08b0fcd40118ab79688d1d51fd5/slide_29.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
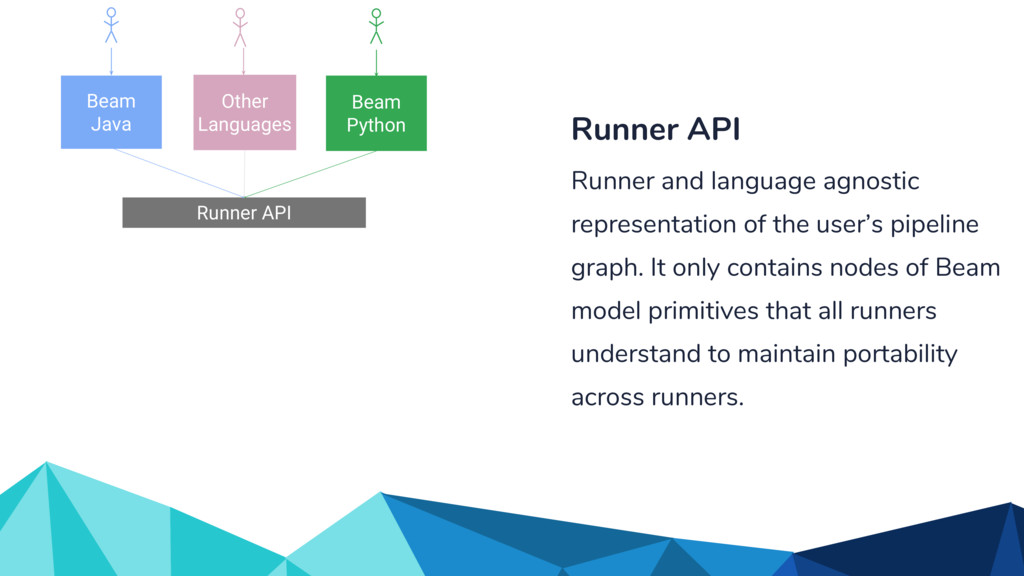{kind=link}
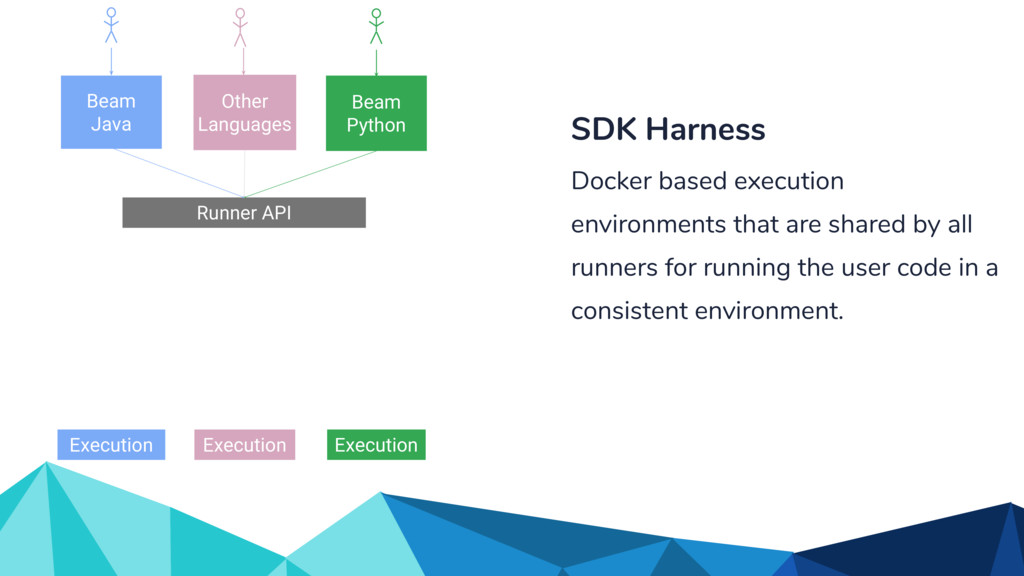{kind=link}
{kind=link}
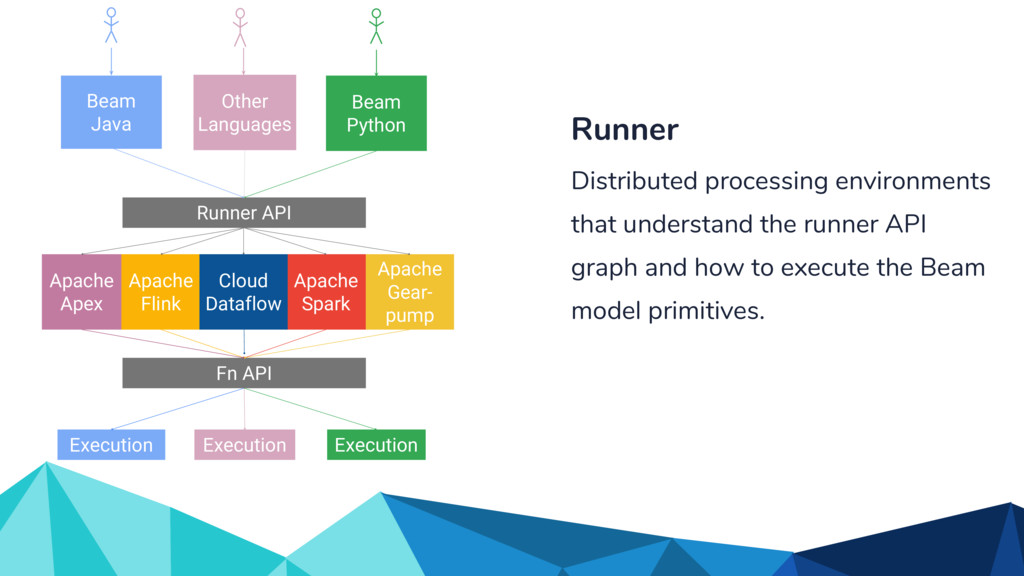{kind=link}
{kind=link}
{kind=link}