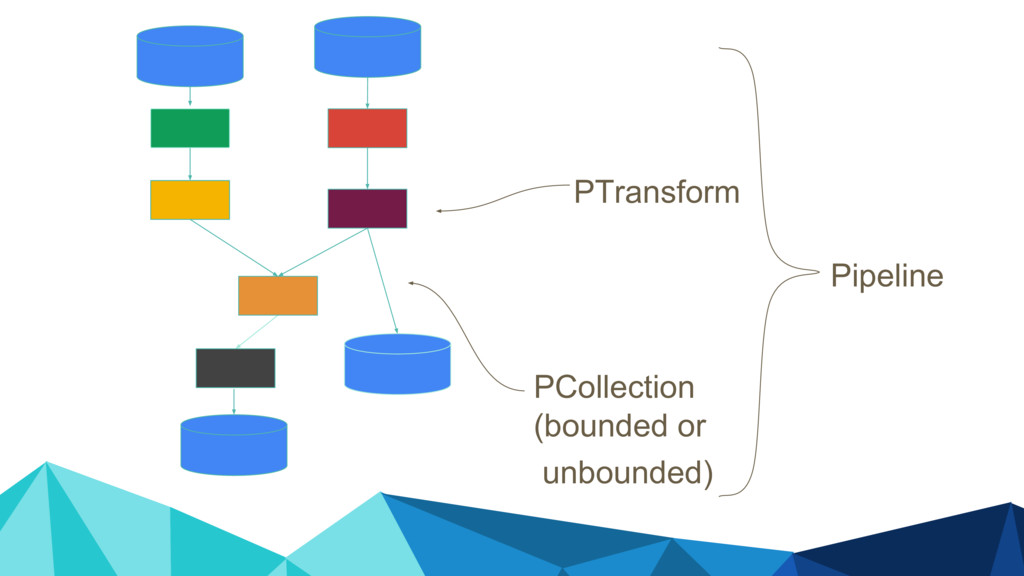
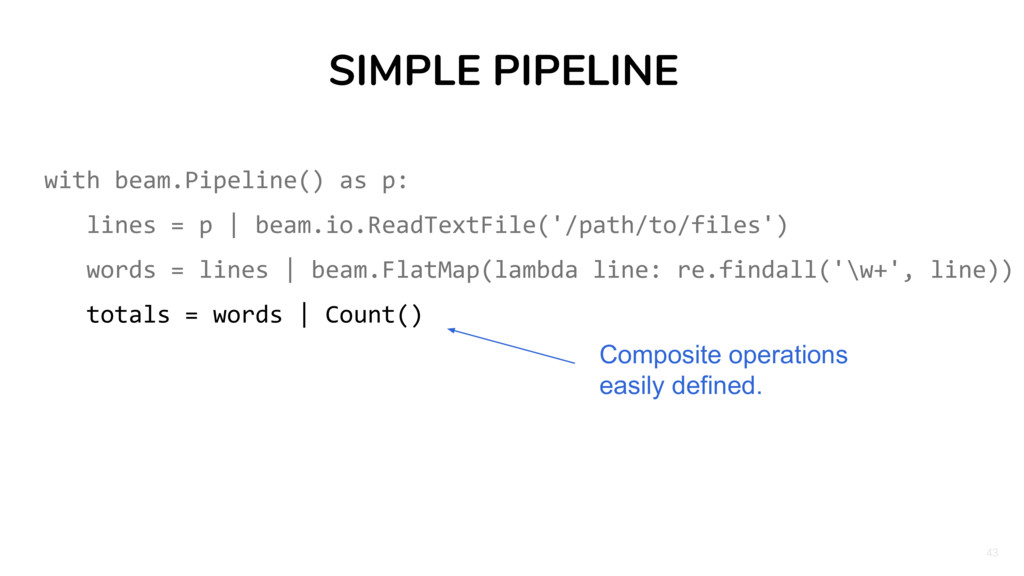
| beam.io.ReadTextFile('/path/to/files') words = lines | beam.FlatMap(lambda line: re.findall('\w+', line)) The "pipe" operator applies a transformation (on the right) to a PCollection, reminiscent of bash. This will be applied to each line, resulting in a PCollection of words.
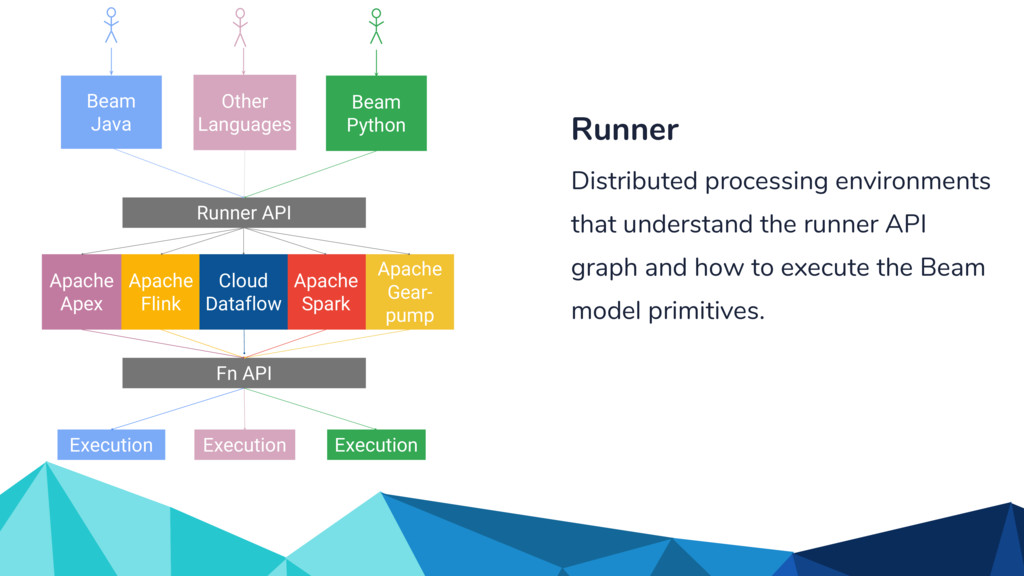
Backends The Beam Model: What / Where / When / How API (SDKs) for writing Beam pipelines Apache Apex Apache Flink InProcess / Local Apache Spark Google Cloud Dataflow Apache GearPump
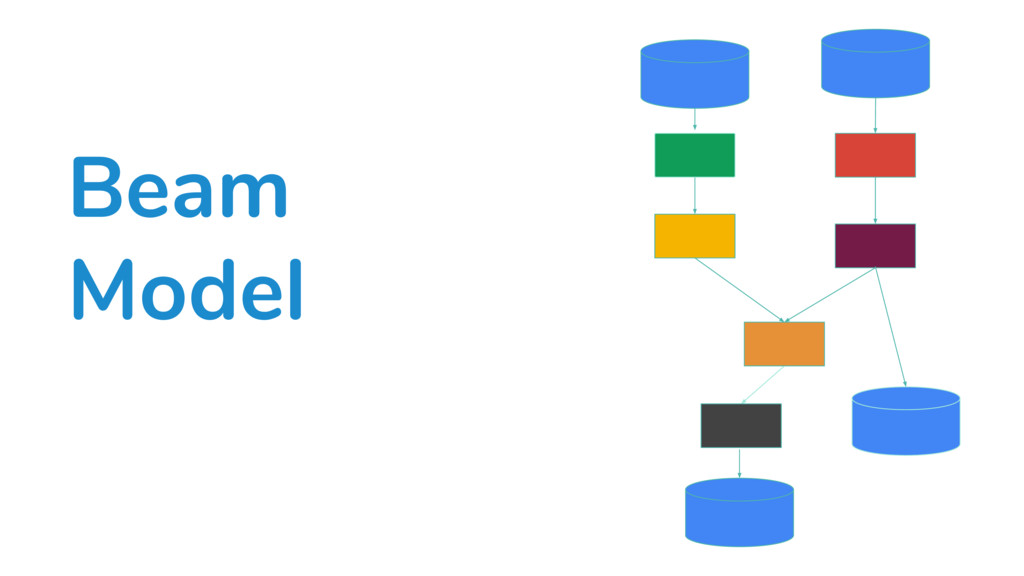
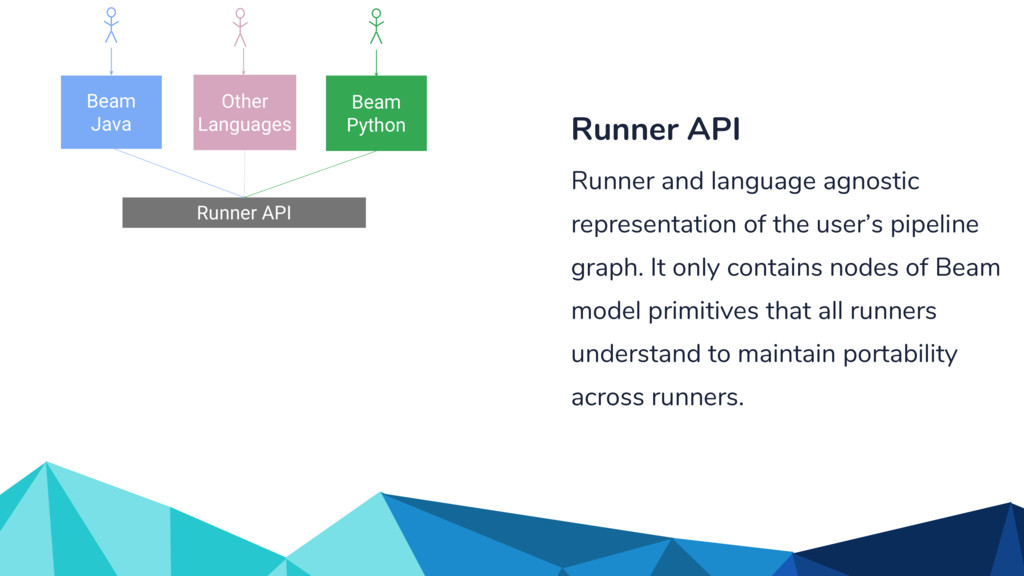
Runner and language agnostic representation of the user’s pipeline graph. It only contains nodes of Beam model primitives that all runners understand to maintain portability across runners.
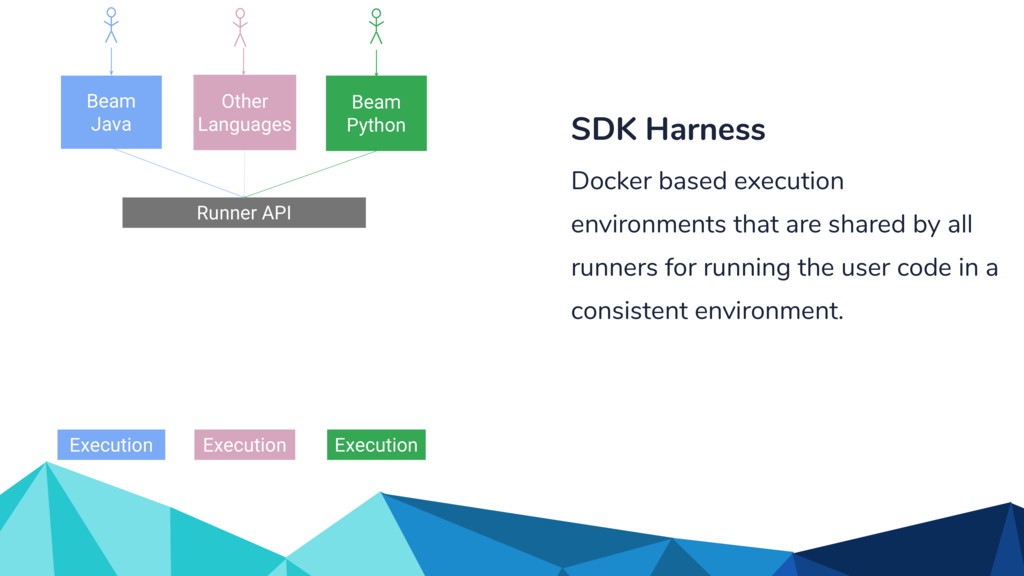
Execution Execution Execution Fn API API which the execution environments use to send and receive data, report metrics around execution of the user code with the Runner.
Beam Java Beam Python Execution Execution Cloud Dataflow Execution Apache Gear- pump Apache Apex Runner Distributed processing environments that understand the runner API graph and how to execute the Beam model primitives.
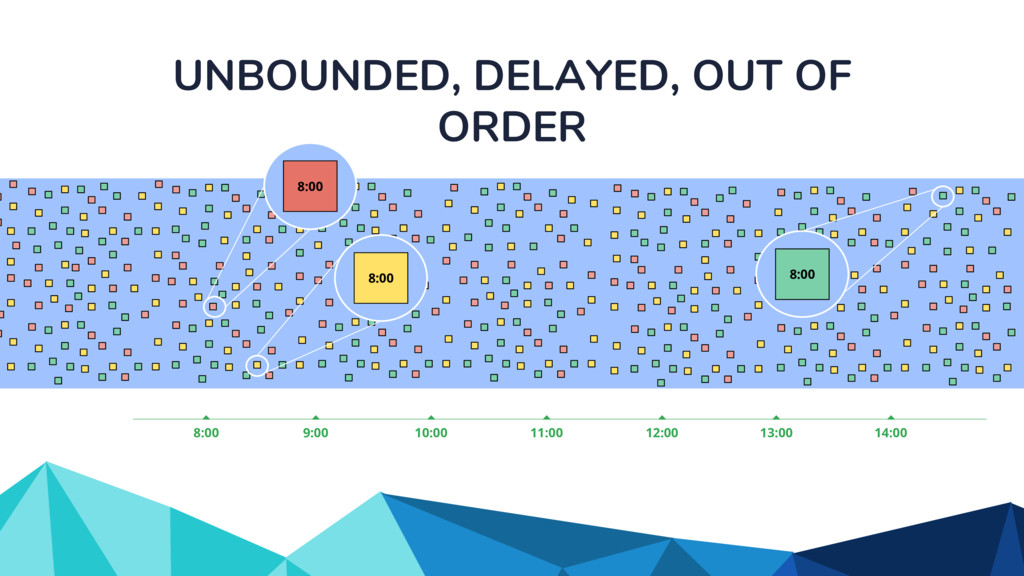
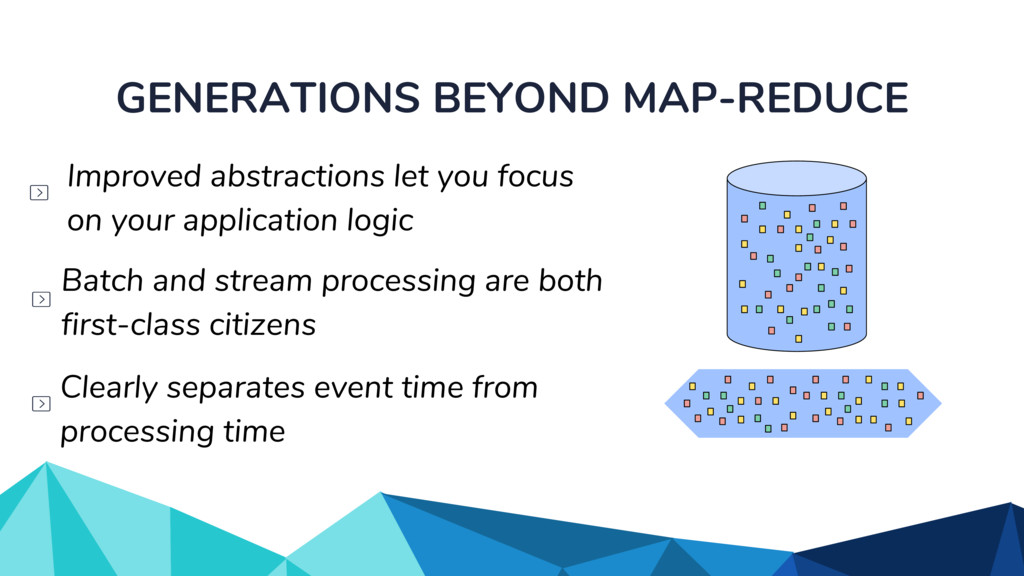
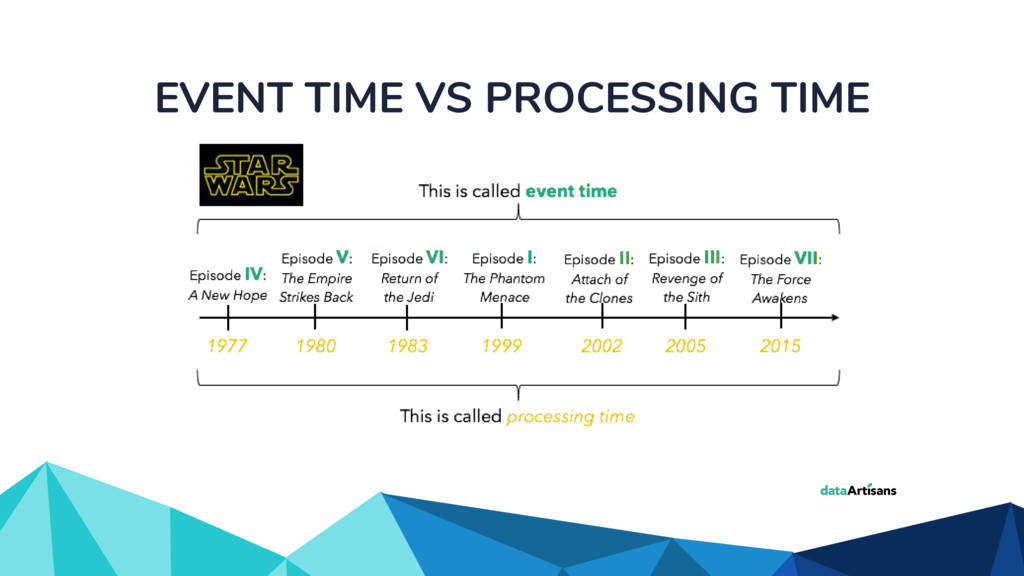
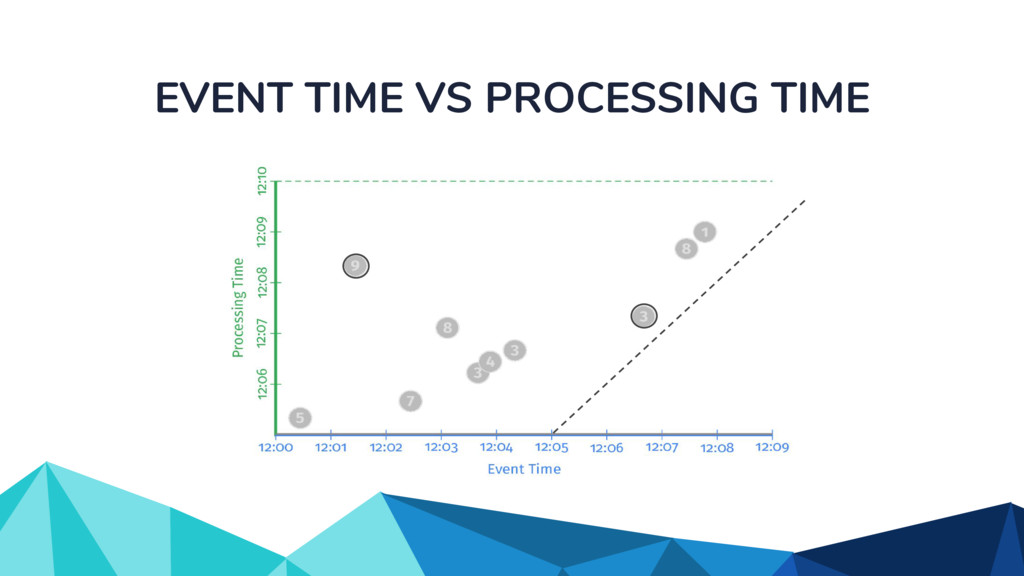
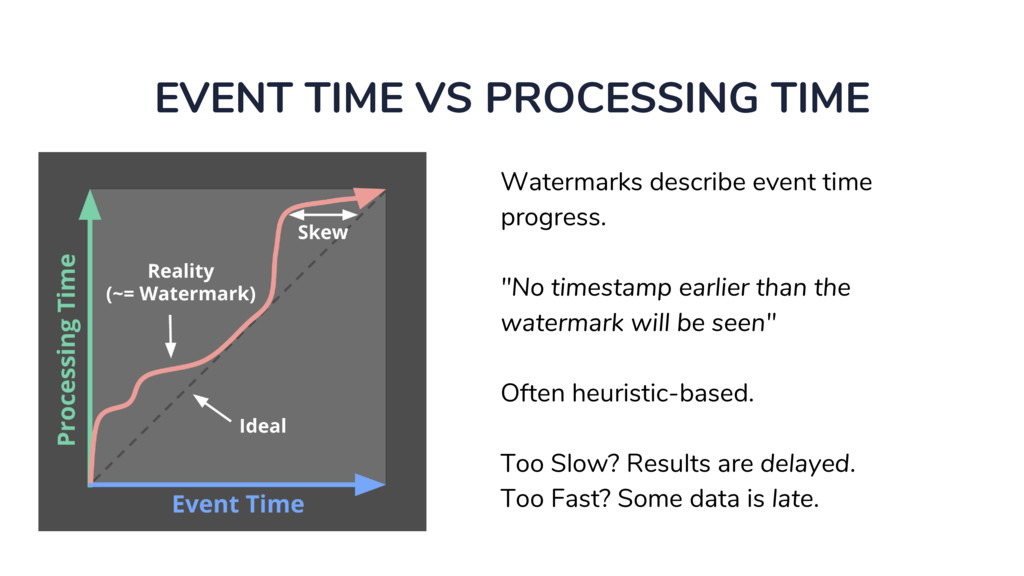
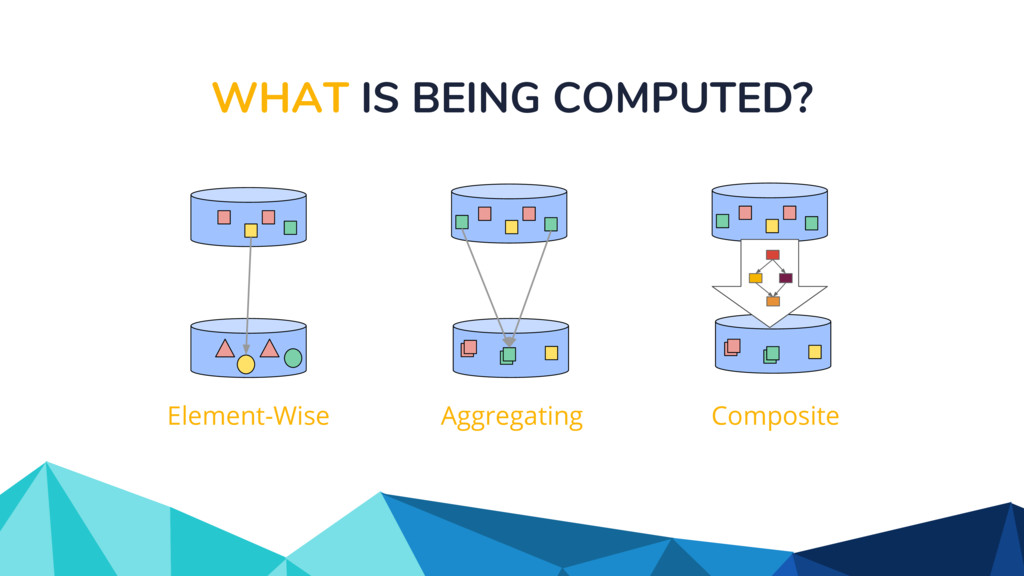
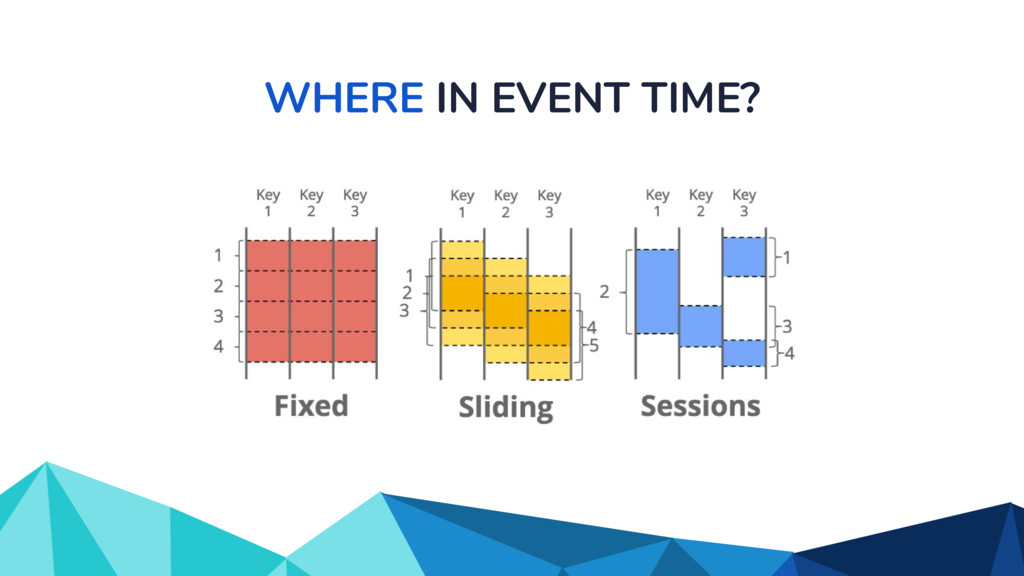
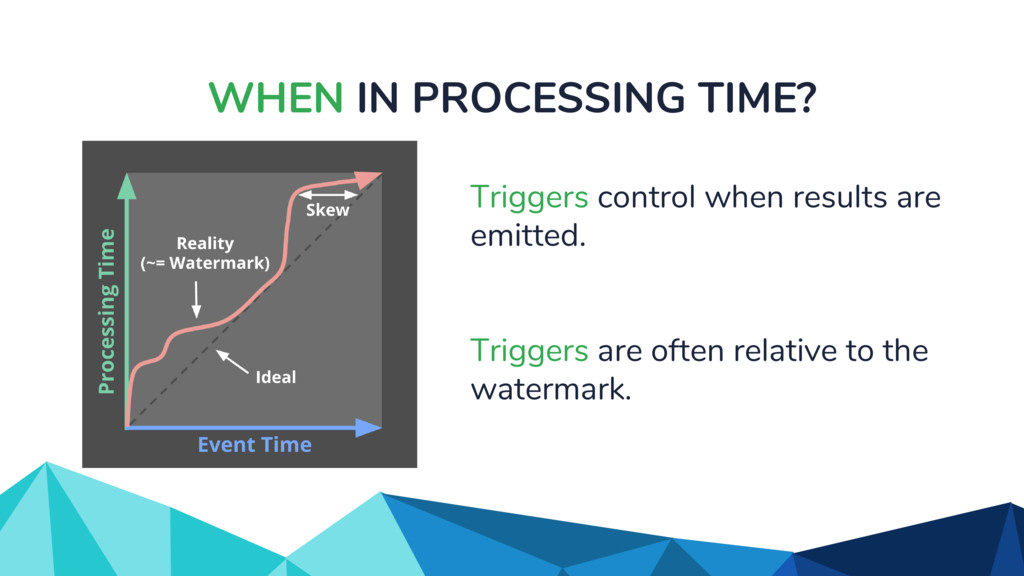
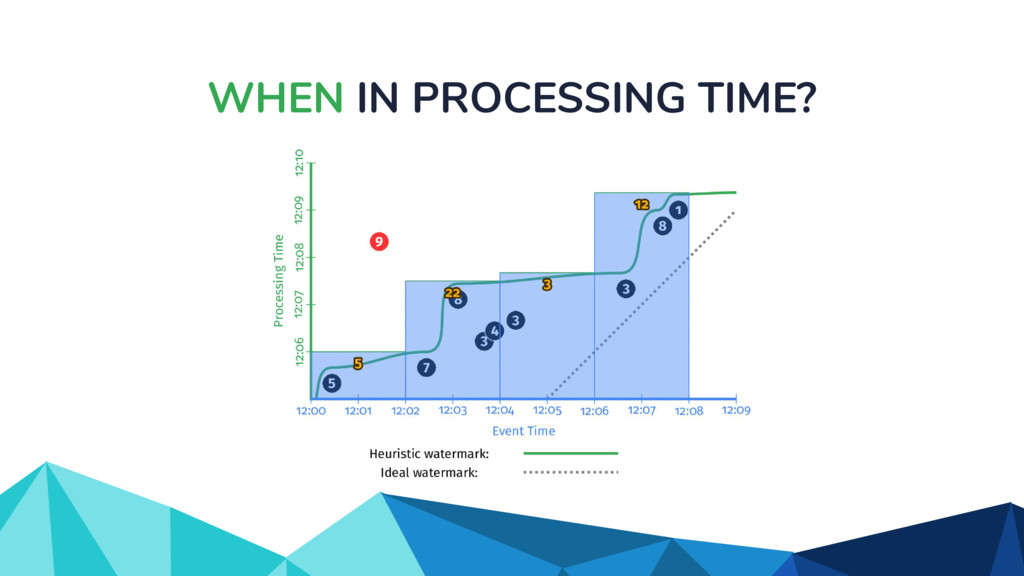
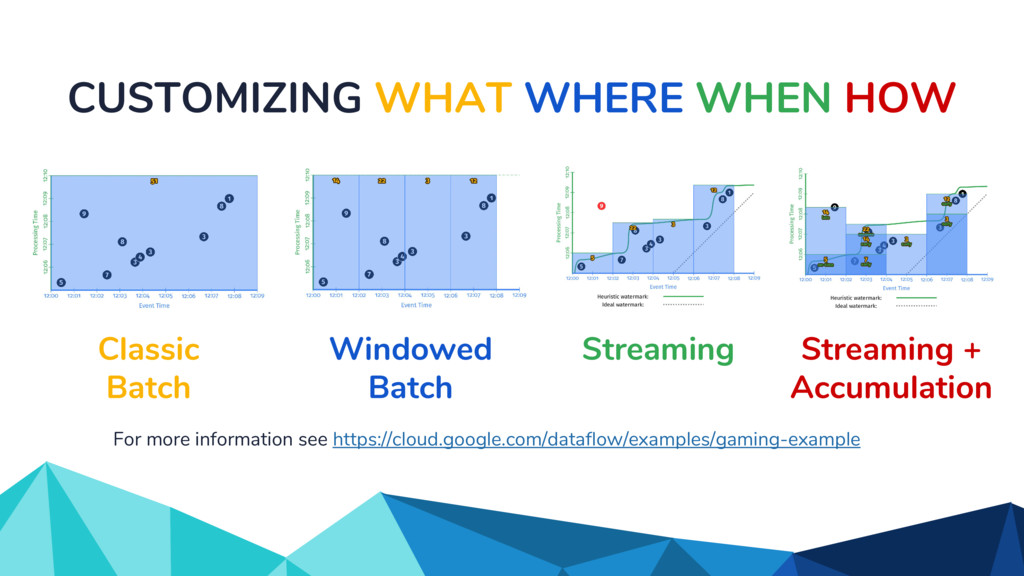
◦ Unbounded in volume ◦ Out of order ◦ Arbitrarily delayed • The Beam model separates concerns of: ◦ What is being computed? ◦ Where in event time? ◦ When in processing time? ◦ How do refinements happen?
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![WHAT IS BEING COMPUTED? scores: PCollection[KV[str, int]] = (input |](https://files.speakerdeck.com/presentations/917954db5be649ee929fdbe7fefedb50/slide_24.jpg){kind=link}
{kind=link}
{kind=link}
![WHERE IN EVENT TIME? scores: PCollection[KV[str, int]] = (input |](https://files.speakerdeck.com/presentations/917954db5be649ee929fdbe7fefedb50/slide_27.jpg){kind=link}
{kind=link}
{kind=link}
![WHERE IN EVENT TIME? scores: PCollection[KV[str, int]] = (input |](https://files.speakerdeck.com/presentations/917954db5be649ee929fdbe7fefedb50/slide_30.jpg){kind=link}
![WHEN IN PROCESSING TIME? scores: PCollection[KV[str, int]] = (input |](https://files.speakerdeck.com/presentations/917954db5be649ee929fdbe7fefedb50/slide_31.jpg){kind=link}
{kind=link}
{kind=link}
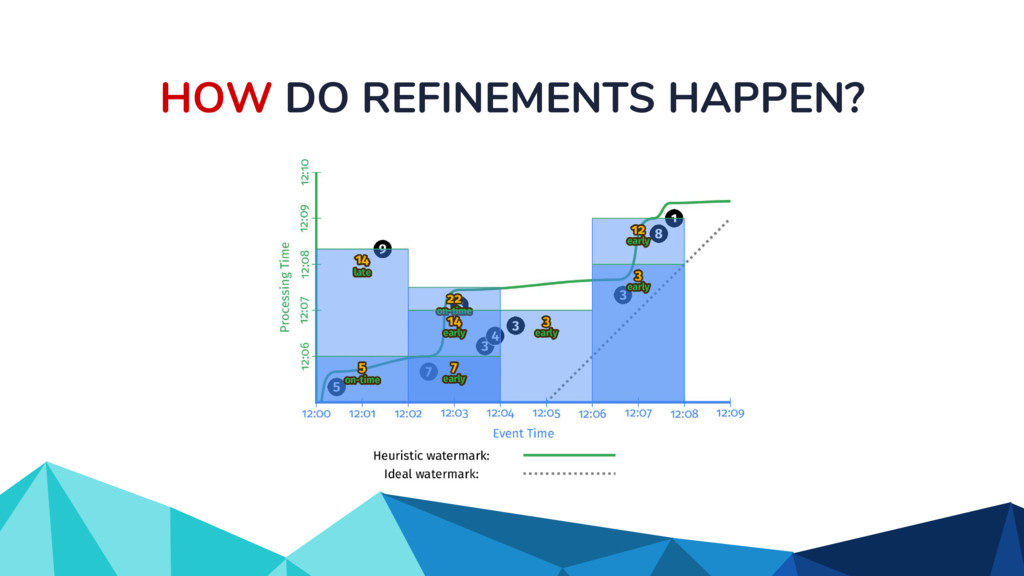
![HOW DO REFINEMENTS HAPPEN? scores: PCollection[KV[str, int]] = (input |](https://files.speakerdeck.com/presentations/917954db5be649ee929fdbe7fefedb50/slide_34.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}