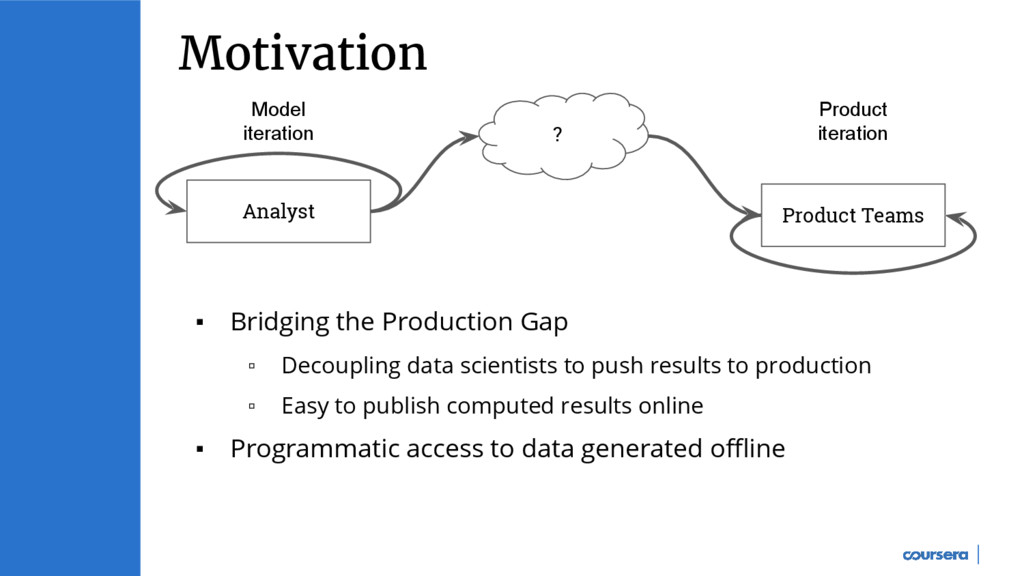
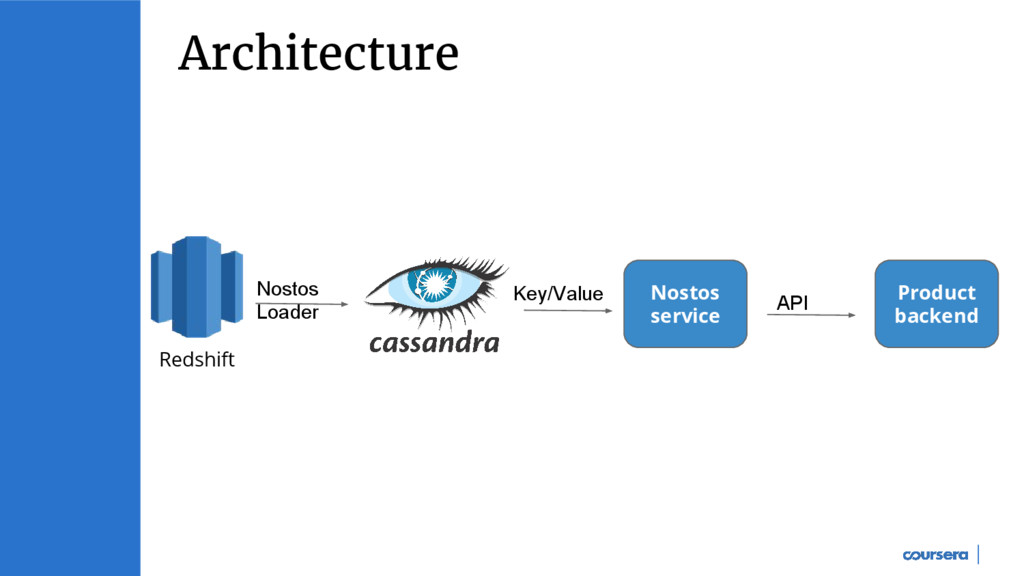
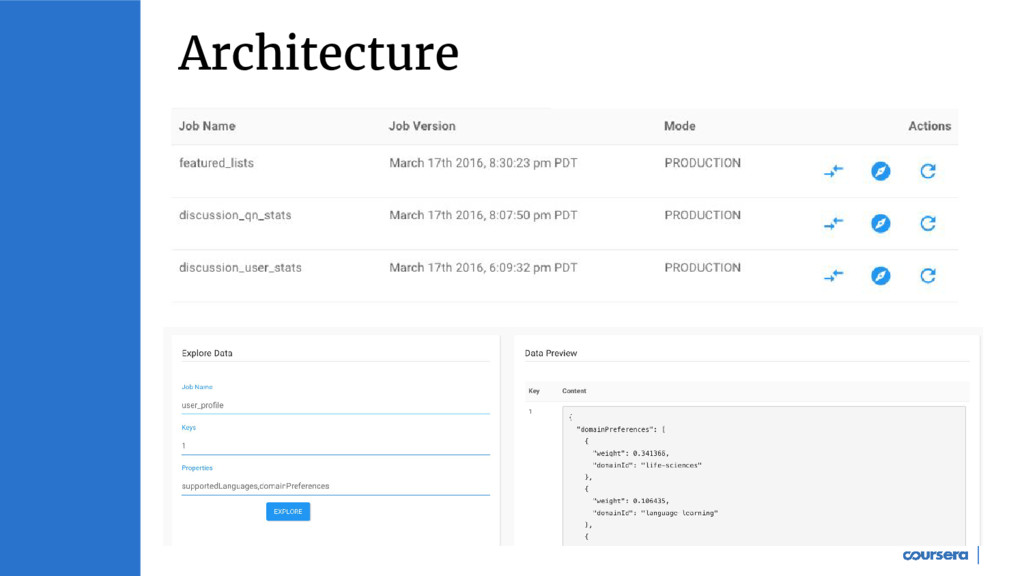
Batch loading in Cassandra can be used for cases such as data migrations between different systems etc. Sourabh (software engineer at Coursera) will talk about Nostos (batch loading service at Coursera) and some of its use cases in data products such as recommendations, search and prediction models. We will cover some of the design choice and tradeoffs made in building Nostos and see how the system has evolved over the past one year.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}