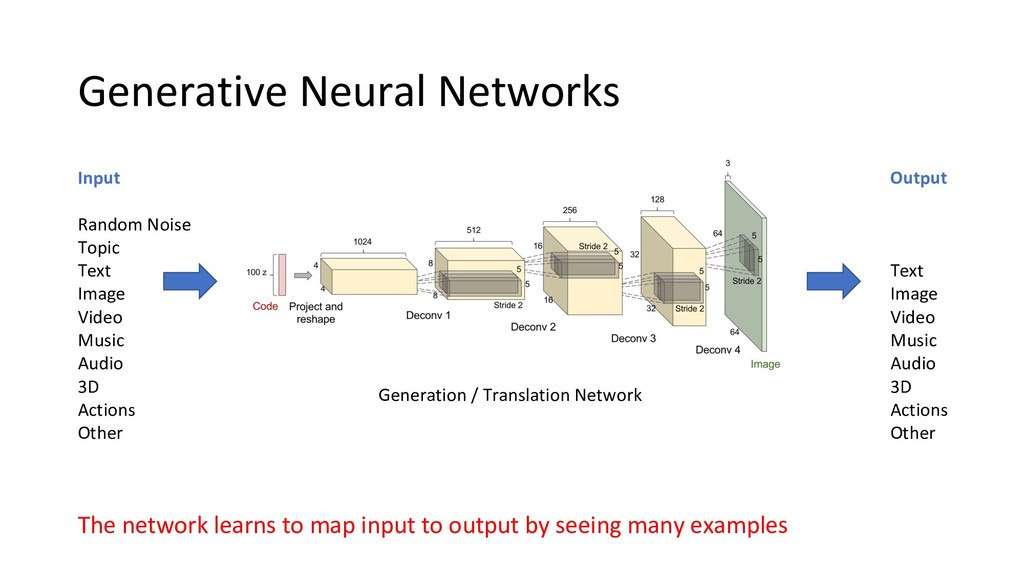
output by seeing many examples Output Text Image Video Music Audio 3D Actions Other Input Random Noise Topic Text Image Video Music Audio 3D Actions Other Generation / Translation Network
(StackGAN) Zhang et al., arxiv.org/abs/1612.03242 Code: github.com/hanzhanggit/StackGAN Cha et al., arxiv.org/abs/1708.09321 StackGAN++: Zhang et al., arxiv.org/abs/1710.10916 Code: github.com/hanzhanggit/StackGAN-v2
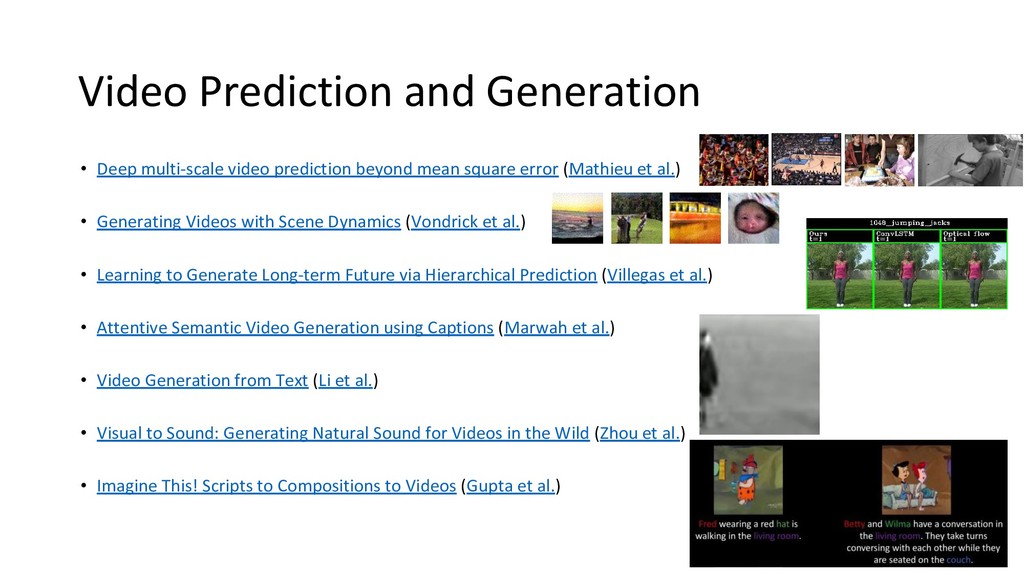
mean square error (Mathieu et al.) • Generating Videos with Scene Dynamics (Vondrick et al.) • Learning to Generate Long-term Future via Hierarchical Prediction (Villegas et al.) • Attentive Semantic Video Generation using Captions (Marwah et al.) • Video Generation from Text (Li et al.) • Visual to Sound: Generating Natural Sound for Videos in the Wild (Zhou et al.) • Imagine This! Scripts to Compositions to Videos (Gupta et al.)
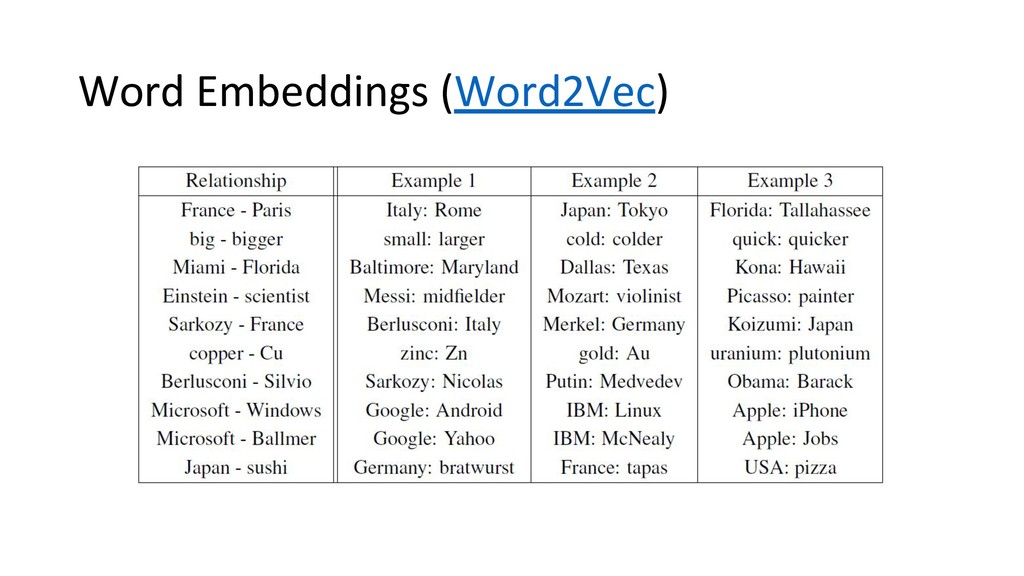
Woman King + ( Woman – Man ) = Queen King - Man + Woman = Queen Y X Web demos: • rare-technologies.com/ word2vec-tutorial • bionlp-www.utu.fi/wv_demo Semantically: Algebraically:
Sentences from a Continuous Space (1511.06349) •Semeniuta et al., A Hybrid Convolutional Variational Autoencoder for Text Generation (1702.02390) •Web demo: robinsloan.com/voyages-in-sentenc e-space
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![AttnGAN Xu et al., arxiv.org/abs/1711.10485 [supp]](https://files.speakerdeck.com/presentations/5125df66aa3341ebae1e05db64f977d3/slide_21.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
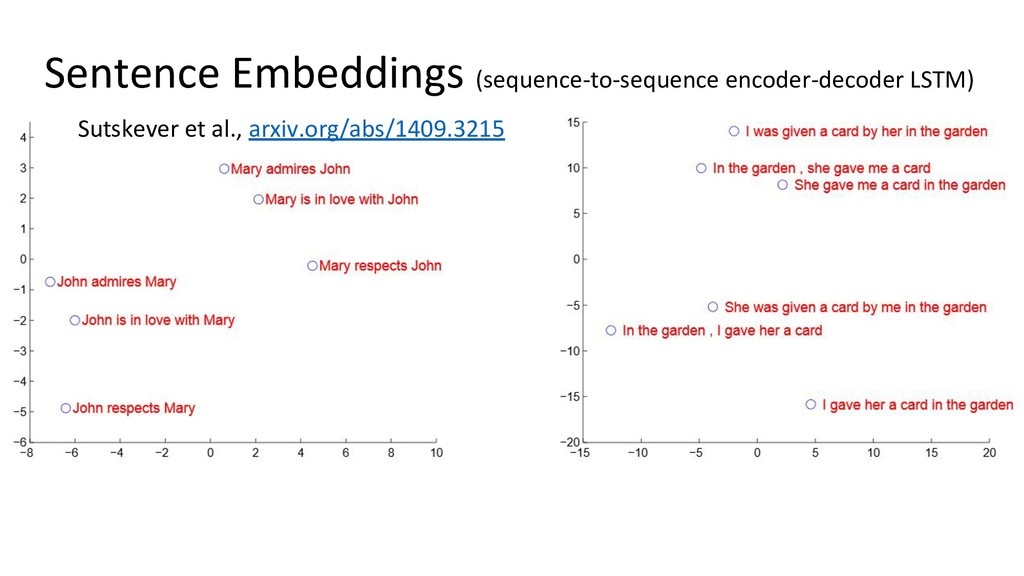{kind=link}
{kind=link}
{kind=link}