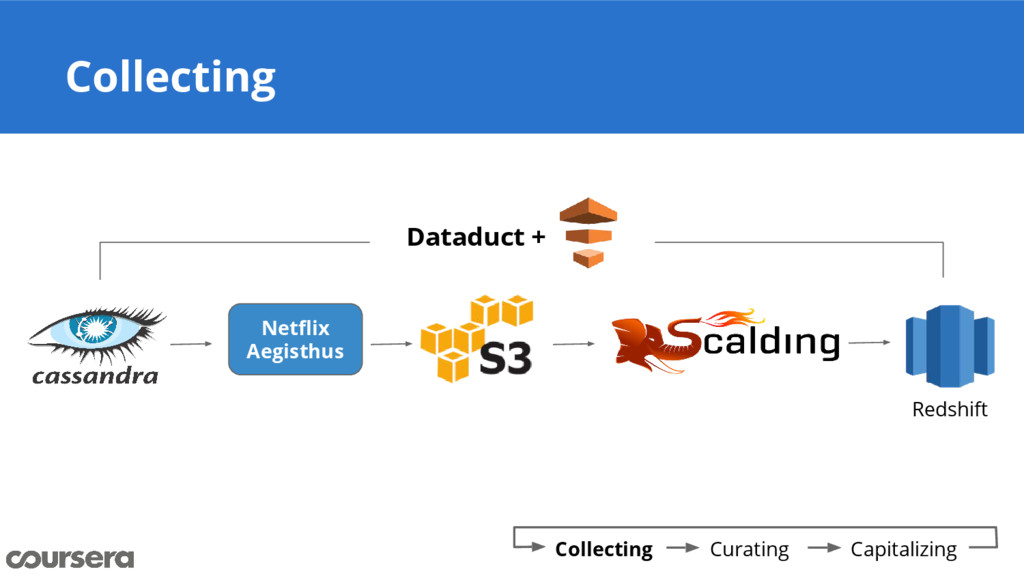
Coursera is an online educational startup with over 19 million learners across the globe. At Coursera we use Redshift as our primary data warehouse as it provides a standard SQL interface and has fast and reliable performance. We use our open-source framework Dataduct to move data to and fro from redshift. In this talk we’ll cover the workflow service at Coursera and how it is now being used for other use cases beyond just ETL such as machine learning, predictions and bulk loading into Cassandra.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Collecting Collecting Curating Capitalizing def processBranches(branchPipe: TypedPipe[BranchModel], outputPath: String): Unit](https://files.speakerdeck.com/presentations/5afb87acccdb40da976a0304f49270c6/slide_24.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
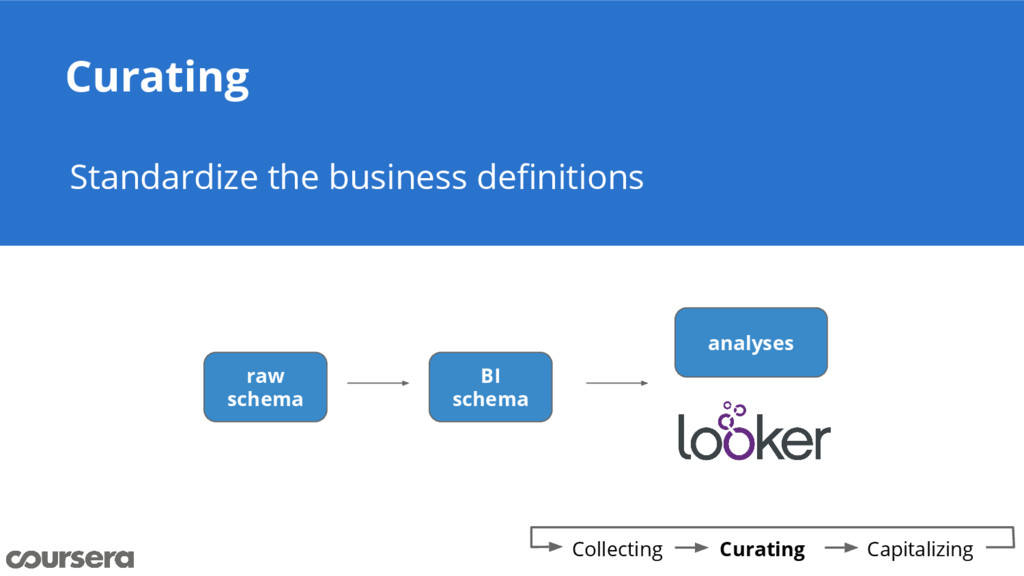{kind=link}
{kind=link}
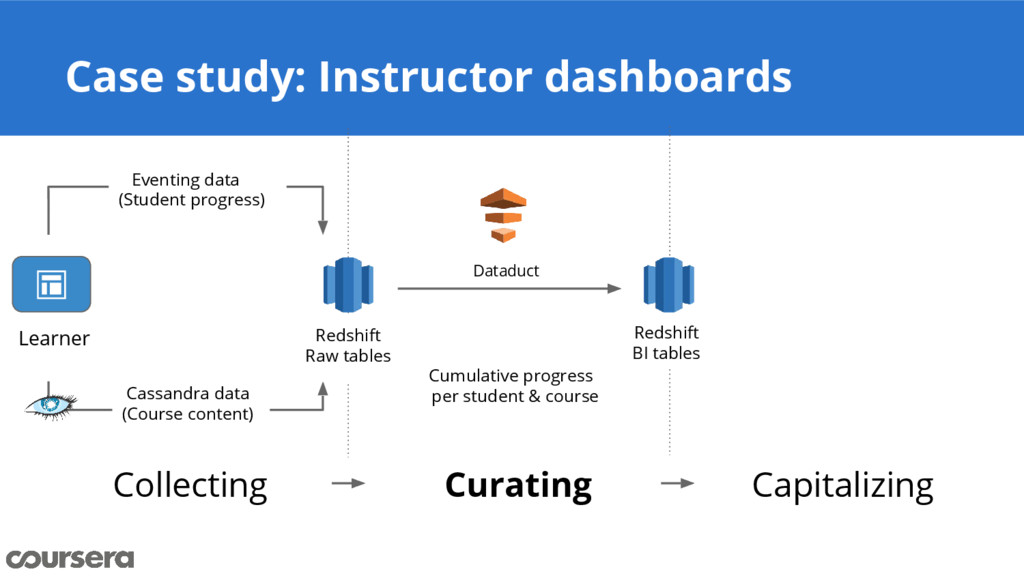{kind=link}
{kind=link}
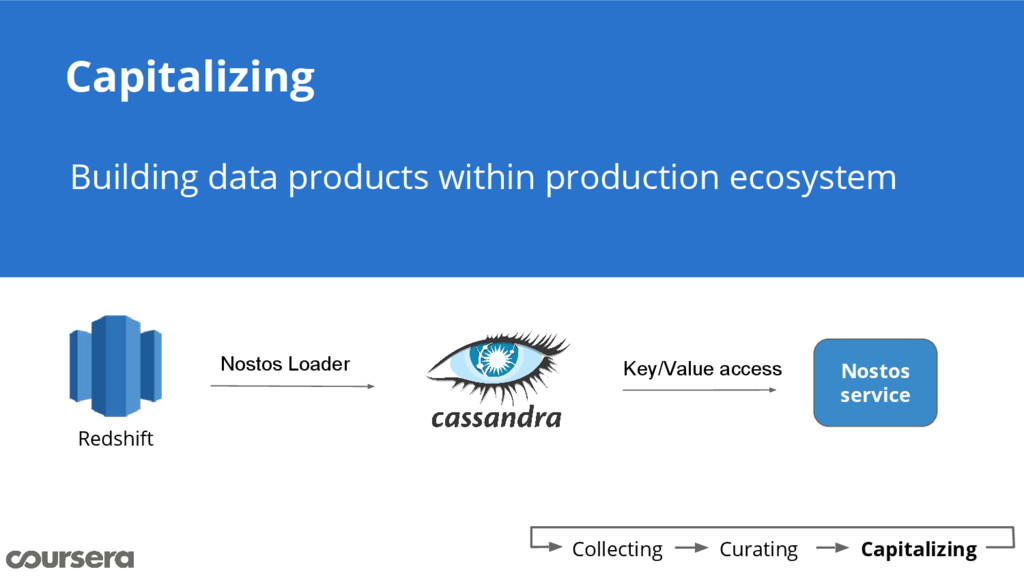{kind=link}
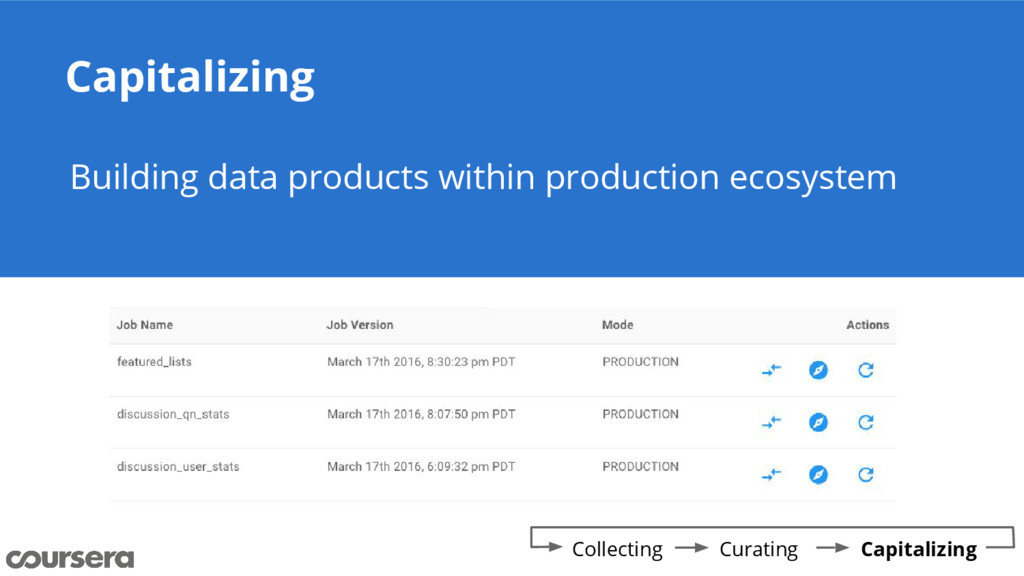{kind=link}
{kind=link}
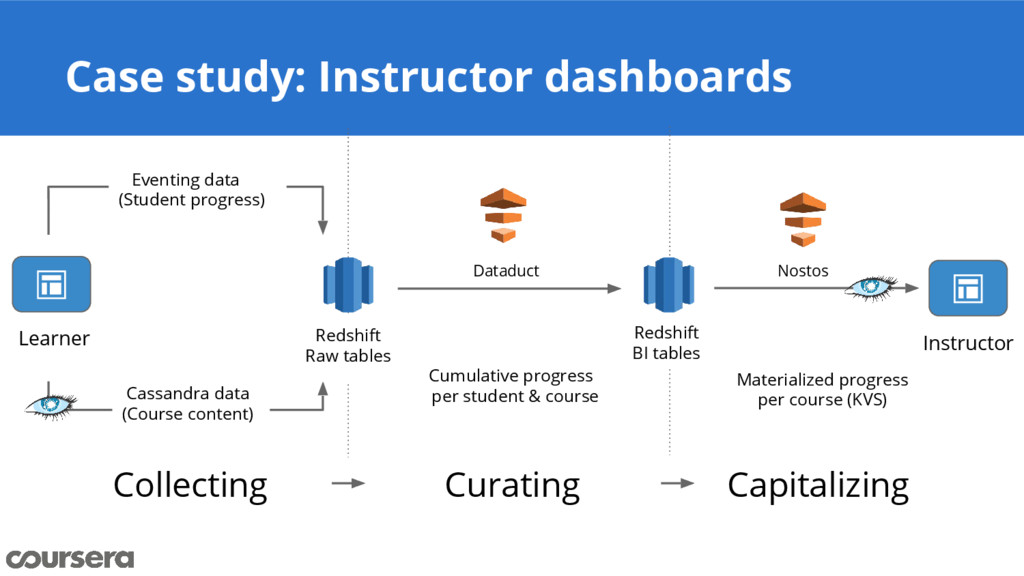{kind=link}
{kind=link}
{kind=link}
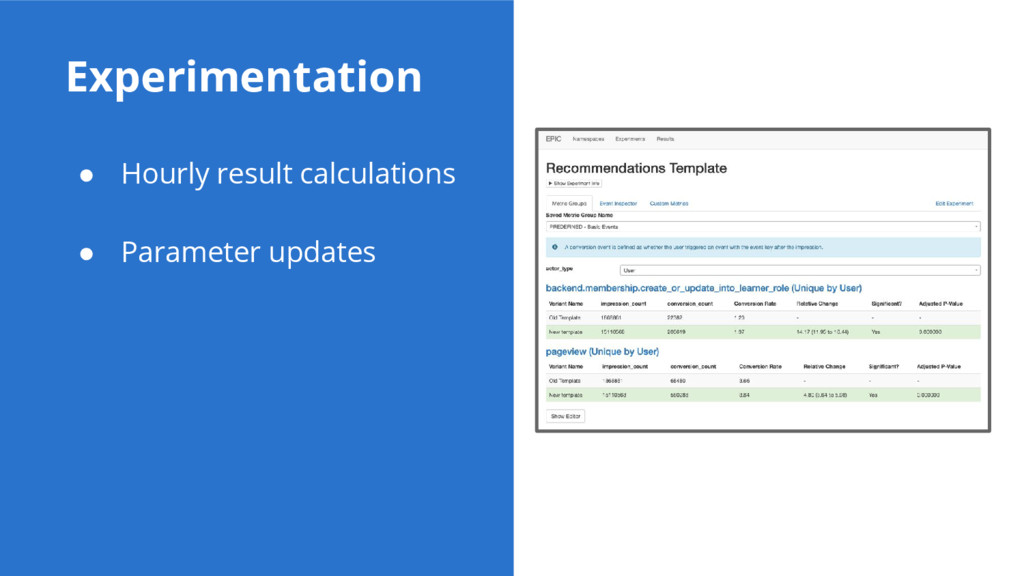{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}