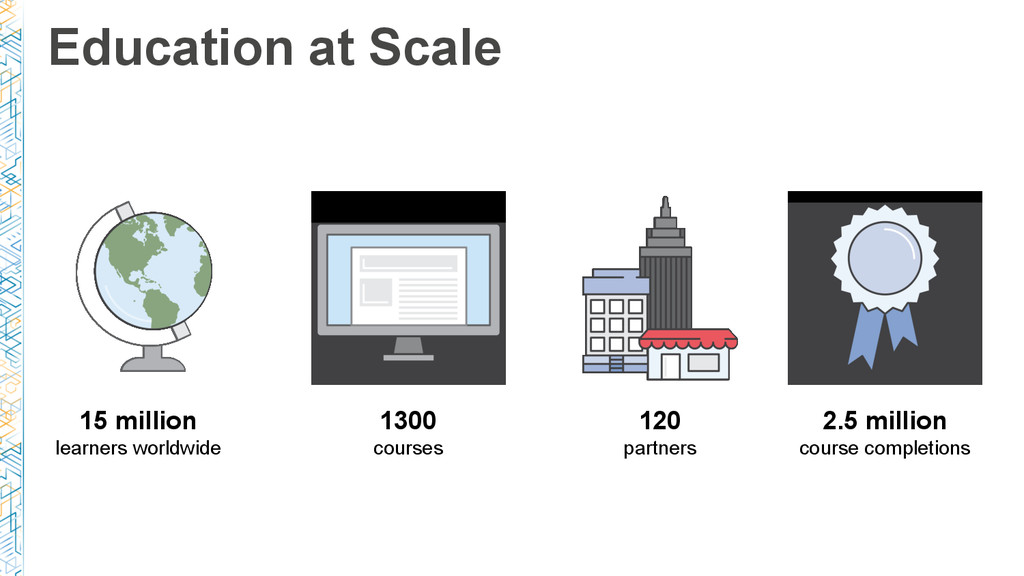
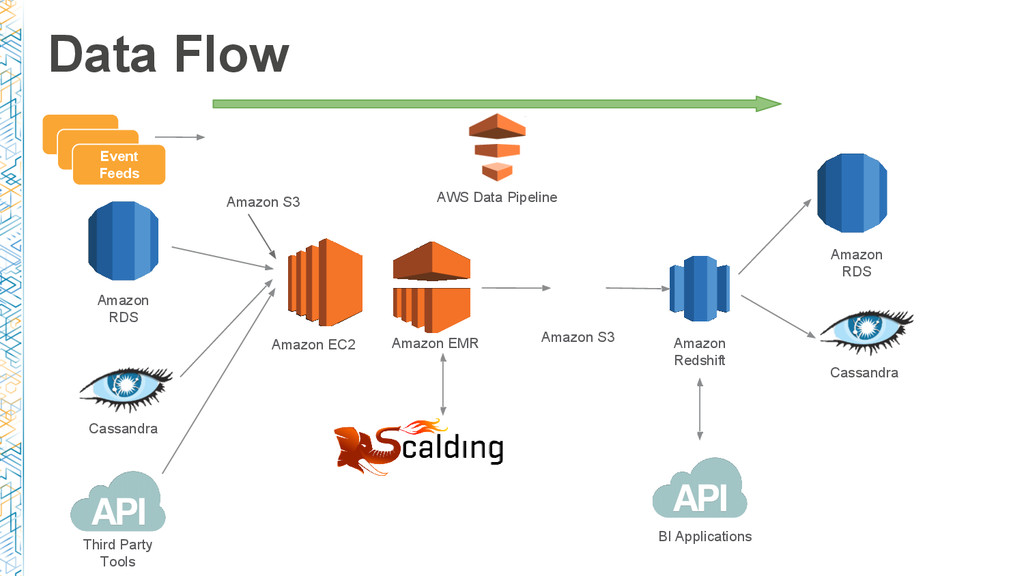
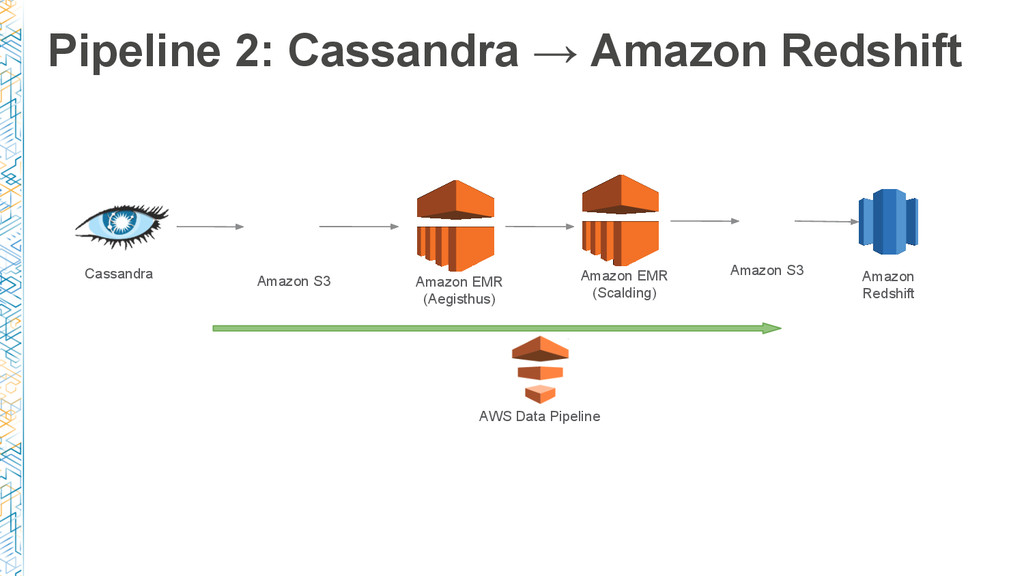
As data volumes grow, managing and scaling data pipelines for ETL and batch processing can be daunting. With more than 13.5 million learners worldwide, hundreds of courses, and thousands of instructors, Coursera manages over a hundred data pipelines for ETL, batch processing, and new product development.
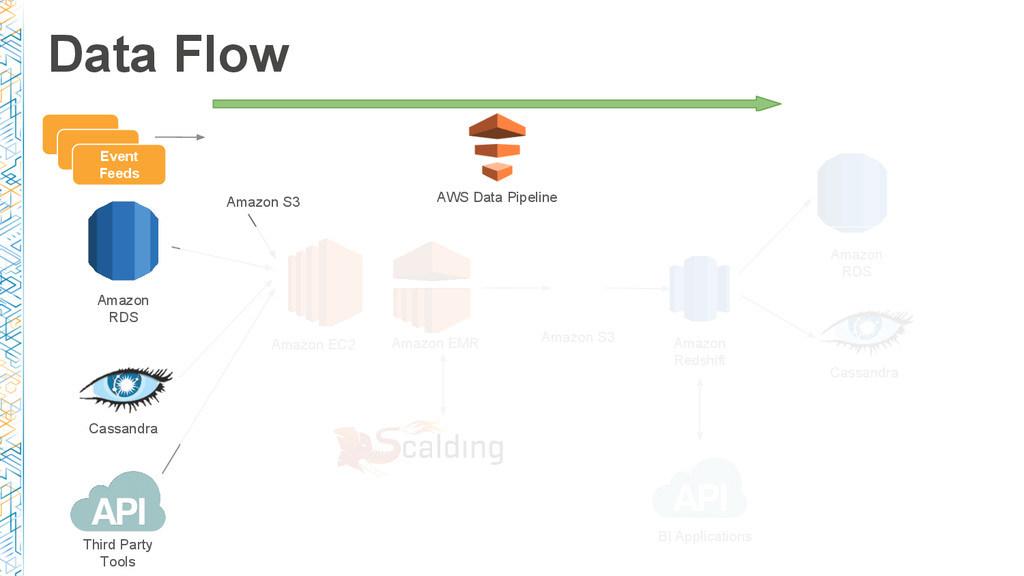
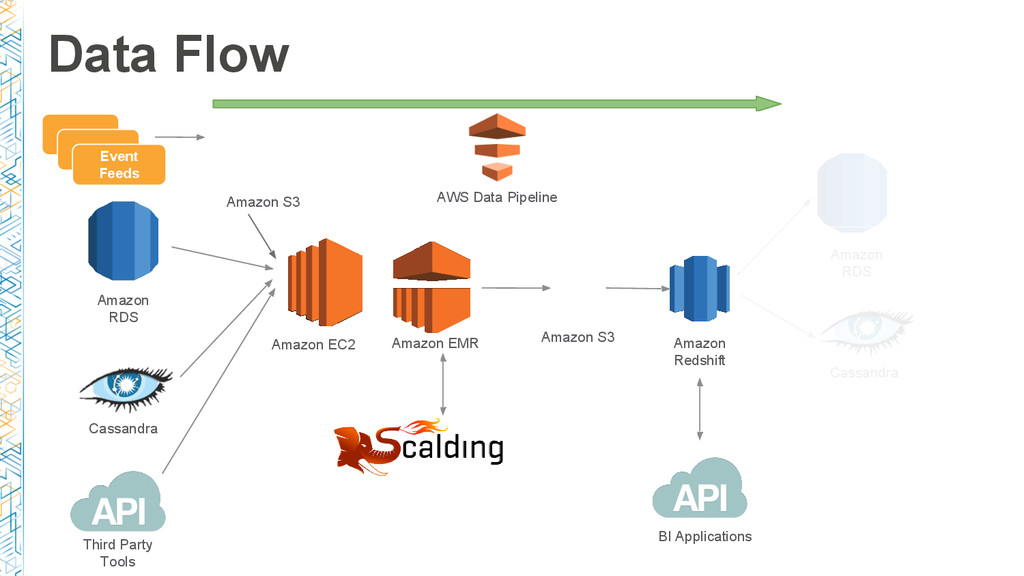
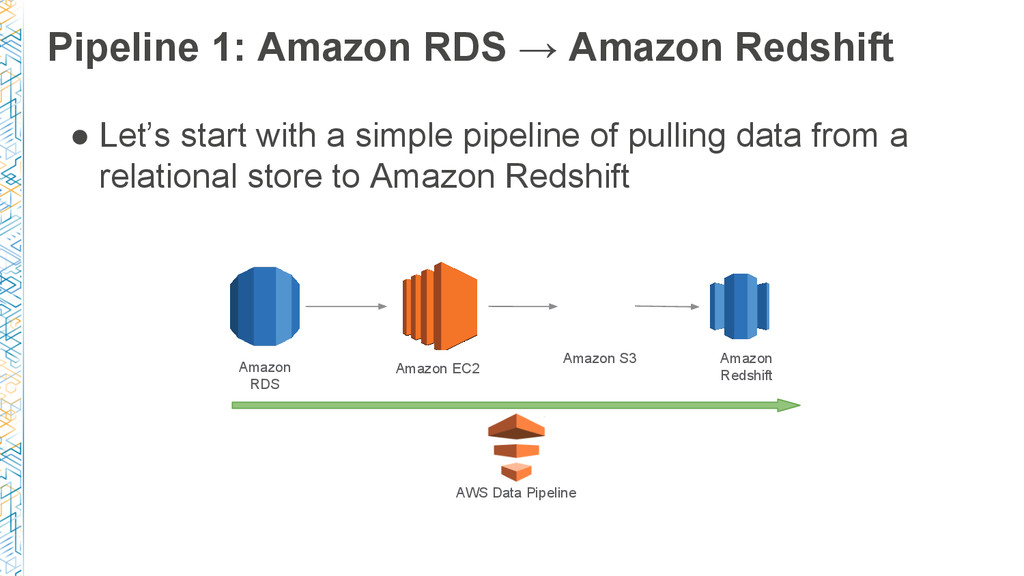
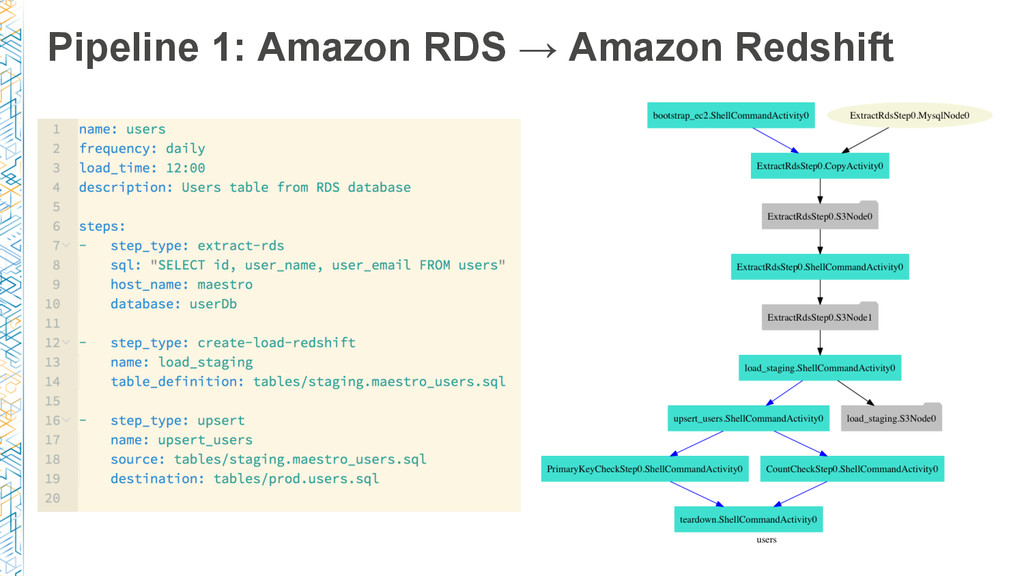
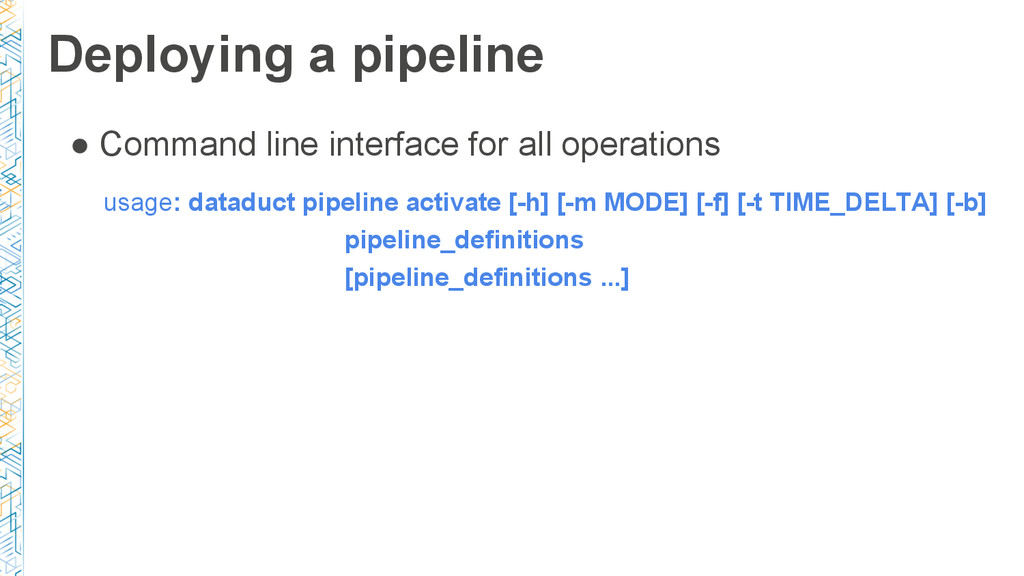
In this session, we dive deep into AWS Data Pipeline and Dataduct, an open source framework built at Coursera to manage pipelines and create reusable patterns to expedite developer productivity. We share the lessons learned during our journey: from basic ETL processes, such as loading data from Amazon RDS to Amazon Redshift, to more sophisticated pipelines to power recommendation engines and search services.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}