Дмитрий Сошников
Senior Software Engineer, Microsoft
SECR 2019
Доклад будет интересен для Python-программистов, data scientists, специалистов по компьютерному зрению и обработке изображений.
Суть доклада: представление open-source библиотеки, которая облегчит обработку данных на Питоне, используя функциональный подход к программированию. Библиотека позволяет обрабатывать большие объемы данных за счет ленивых и отложенных вычислений. При наличии времени можно включить материал про распознавание событий на спортивном видео (формула E, футбол).
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![(mp.get_files('images') | take(5) | select(lambda x: (x,time.ctime(os.stat(x).st_ctime)[10:19])) | select(lambda x:](https://files.speakerdeck.com/presentations/a4df716766054caa9a3be1e355b02ea5/slide_9.jpg){kind=link}
{kind=link}
![(mp.get_files('images') | mp.as_field('fname') | mp.apply('fname','time',lambda x: time.ctime(os.stat(x).st_ctime)[10:19]) | mp.apply('fname','image',lambda x:](https://files.speakerdeck.com/presentations/a4df716766054caa9a3be1e355b02ea5/slide_11.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
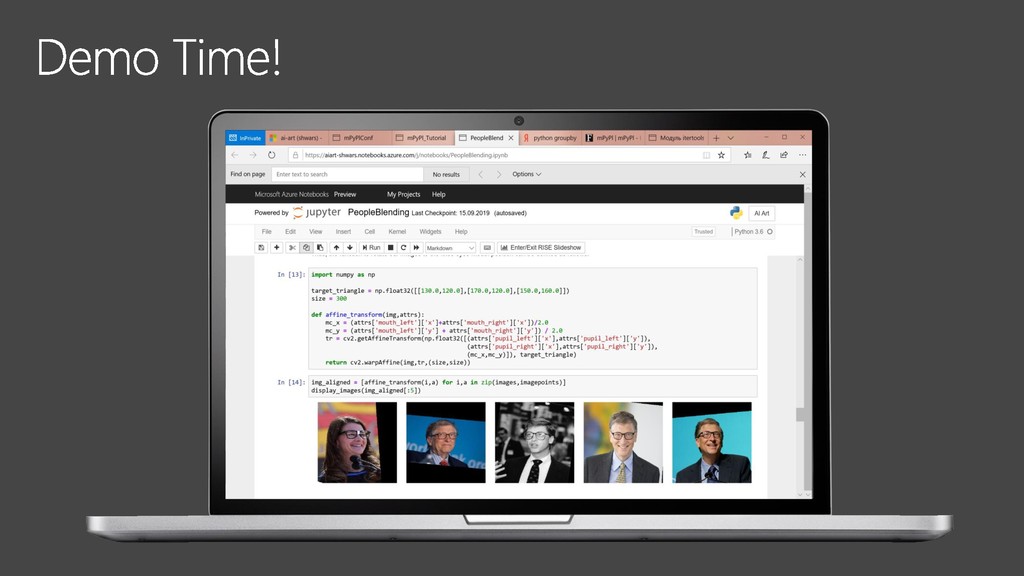{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
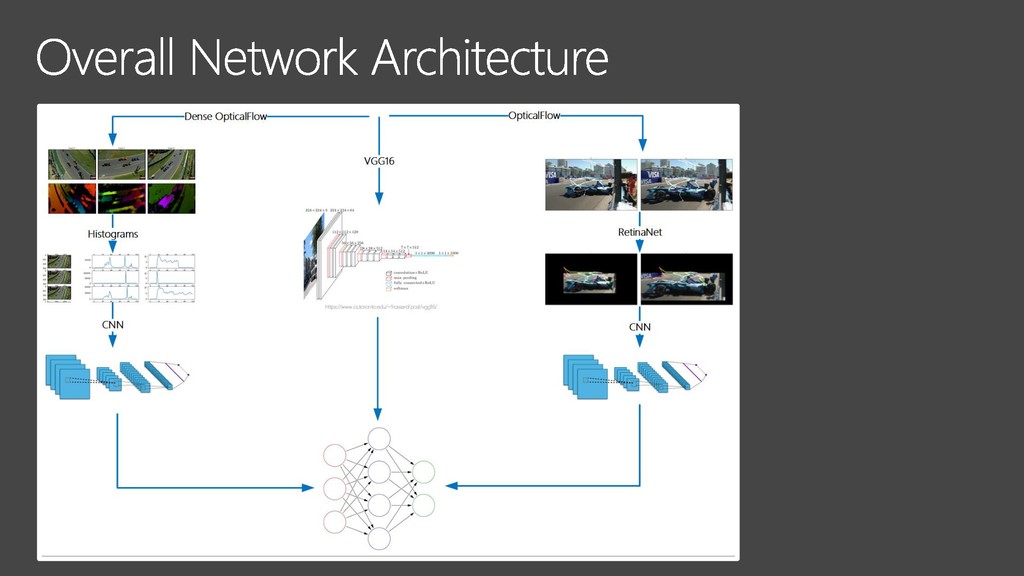{kind=link}
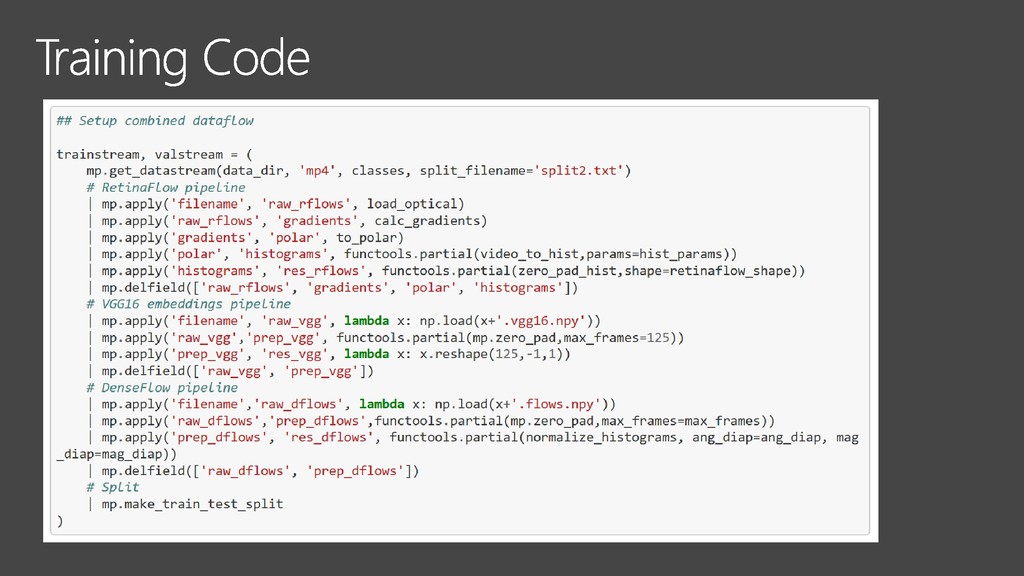{kind=link}
{kind=link}
![data = mp.get_xmlstream_from_dir( annotation_dir, list_fields=['object’], flatten_fields=['bndbox','size’], skip_fields=['pose','source','path']) data = mp.get_pascal_annotations(](https://files.speakerdeck.com/presentations/a4df716766054caa9a3be1e355b02ea5/slide_31.jpg){kind=link}
![def imprint(arg): # arg[0] is image, arg[1] is a list](https://files.speakerdeck.com/presentations/a4df716766054caa9a3be1e355b02ea5/slide_32.jpg){kind=link}
{kind=link}
{kind=link}