Екатерина Полицына
Доцент, Московский авиационный институт
SECR 2019
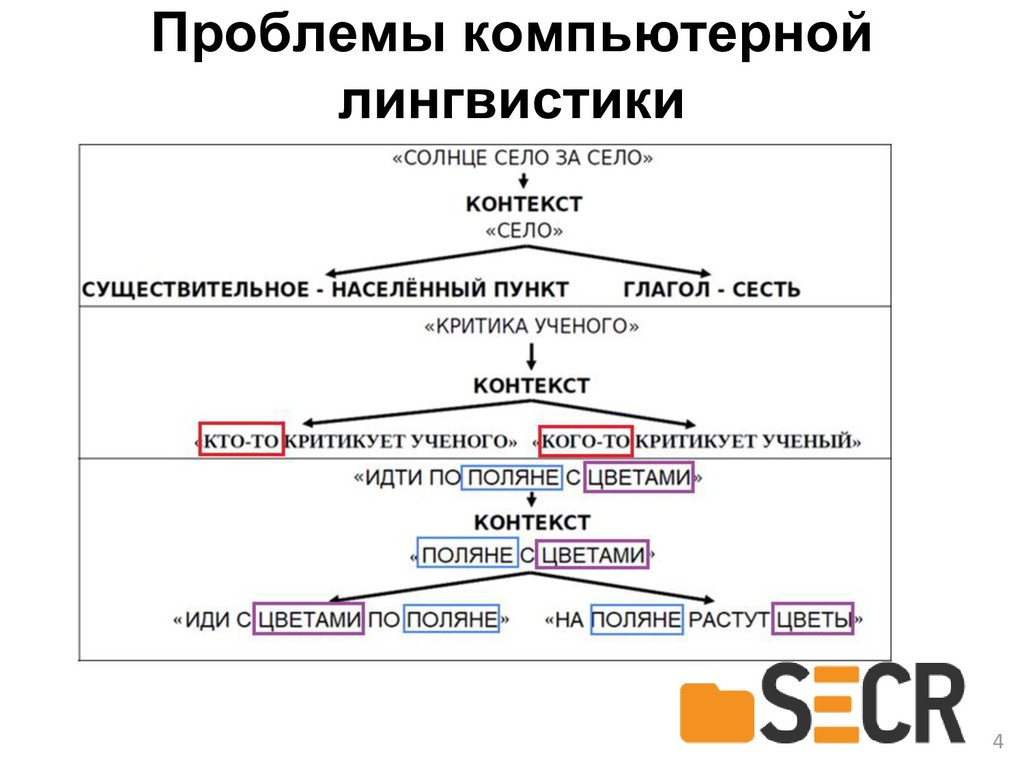
Применение лингвистического анализа, основанного на использовании накопленного опыта в области компьютерной лингвистики, позволяет упростить работу с огромными объемами текстовой информации и открывает новые возможности для автоматизации обработки текстовых документов.
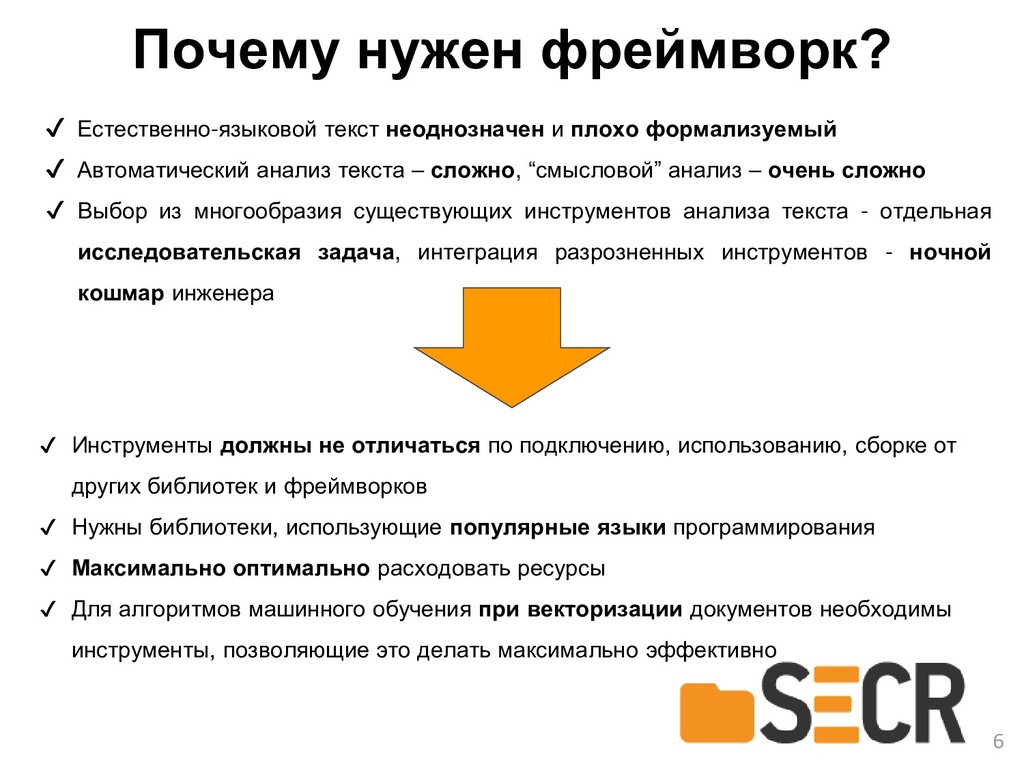
Проблема поиска подходящих инструментов, адаптация их для работы с текстами на русском языке и интеграция друг с другом затрудняет их применение в исследовательских целях и делает практически невозможным их использование в прикладных системах, поэтому в докладе предлагается новый разработанный Java-фреймворк с открытым исходным кодом TAWT, предоставляющий удобные готовые инструменты и структуры данных основных этапов анализа текста на русском языке и отвечающий современным требованиям к производительности, надежности, механизмам сборки проектов и т.д.
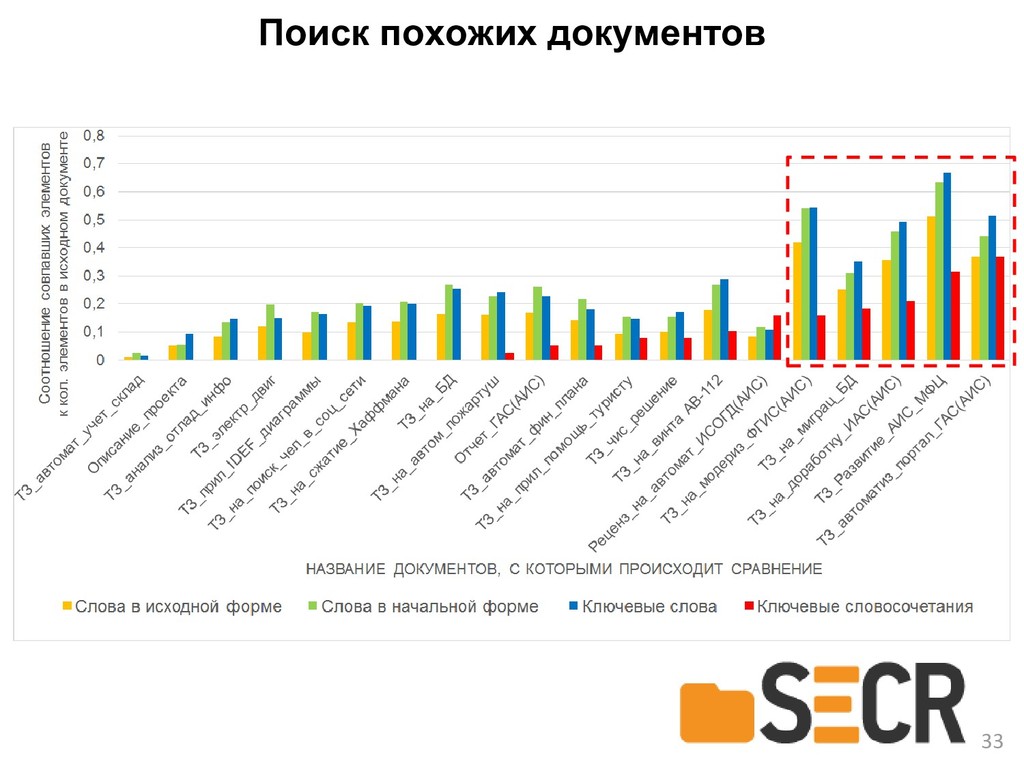
Демонстрируется применение фреймворка на примере автоматизации некоторых задач при подготовке технической документации, TAWT может быть полезен разработчикам исследовательских инструментов для улучшения качества обработки текстов путем применения методов лингвистического анализа, командам разработки прикладного ПО для реализации новых функций в продуктах и разработчикам автоматизированных средств для сокращения рутинных действий при работе с разного вида документацией.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
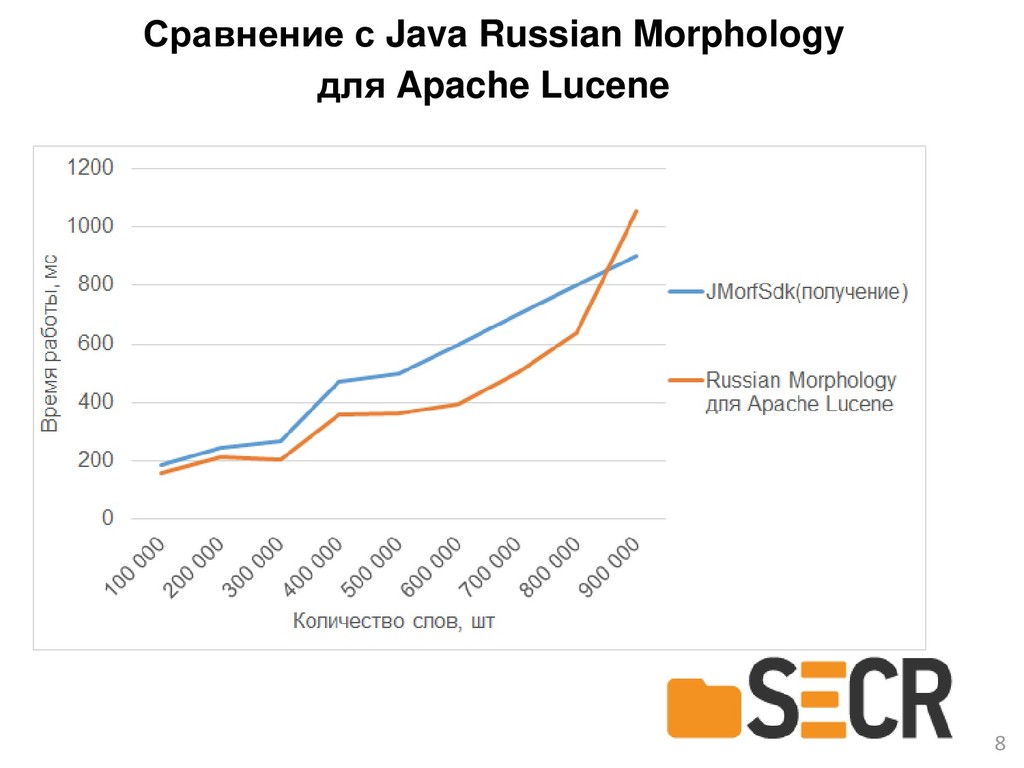{kind=link}
{kind=link}
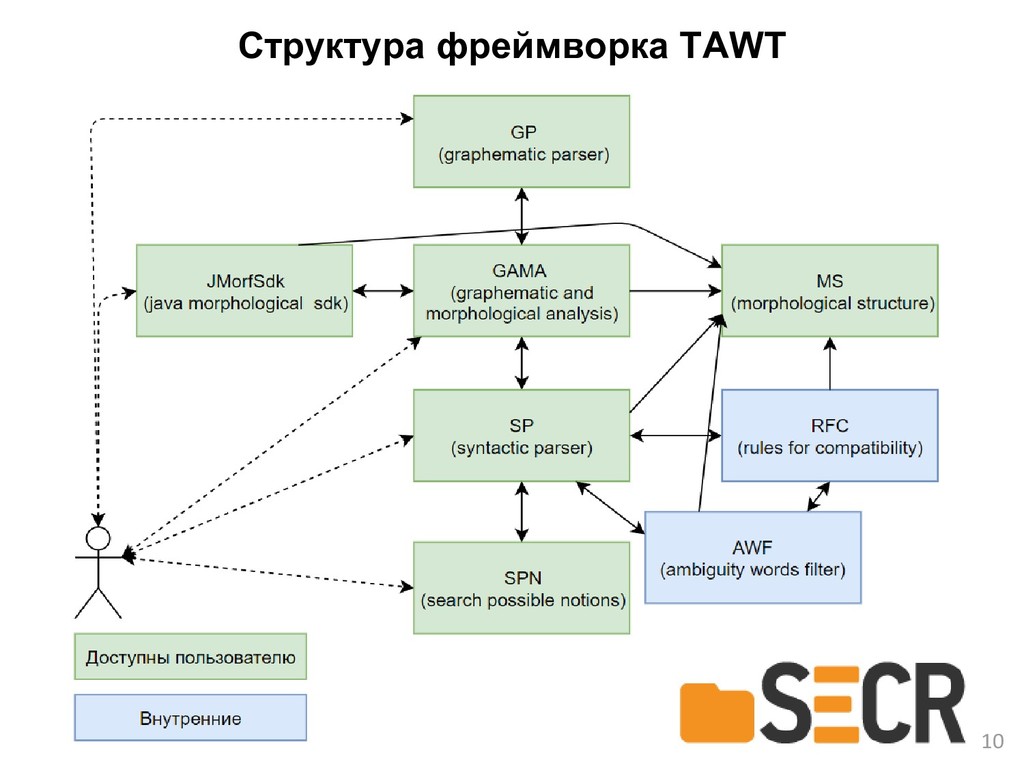{kind=link}
{kind=link}
{kind=link}
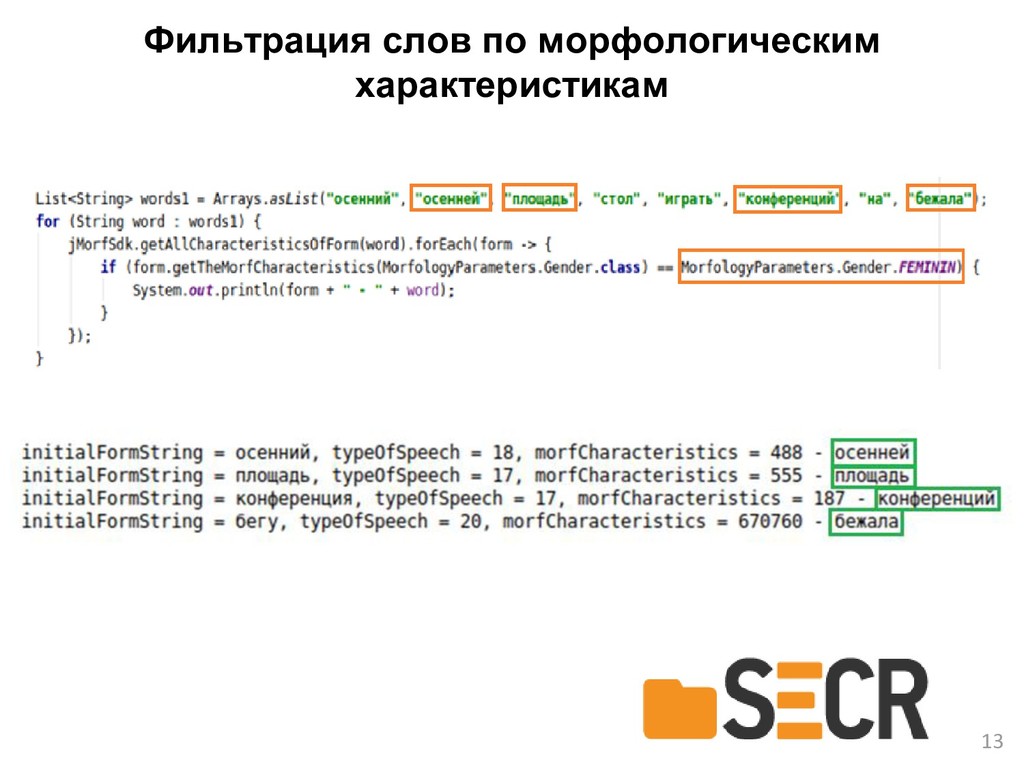{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
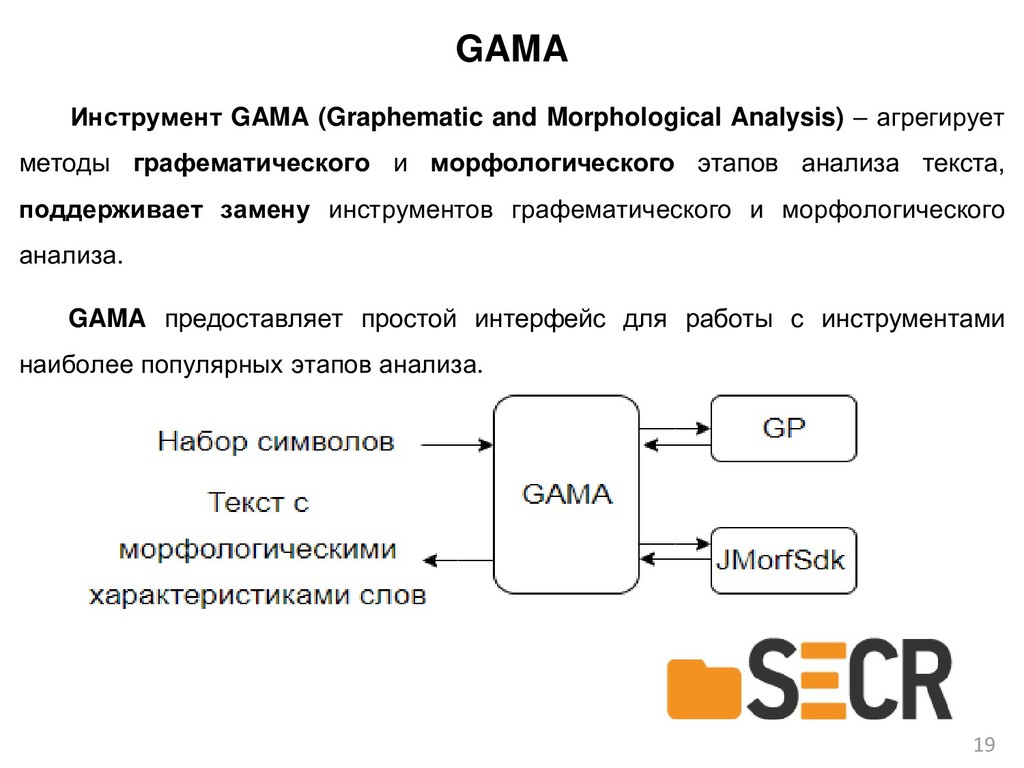{kind=link}
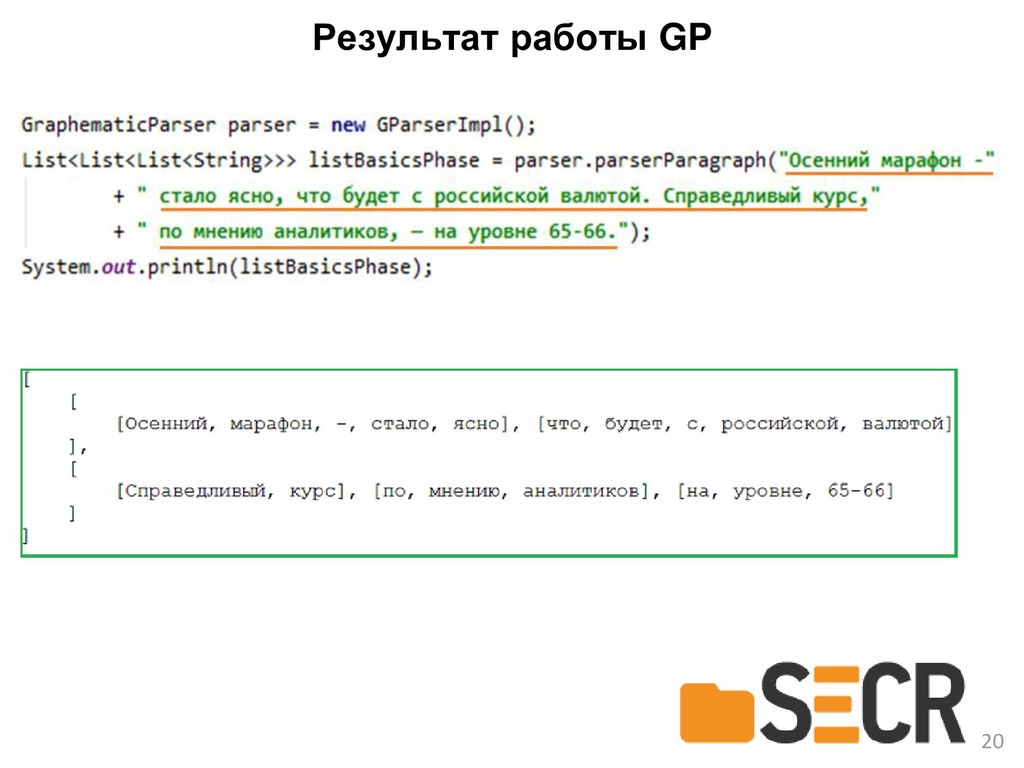{kind=link}
{kind=link}
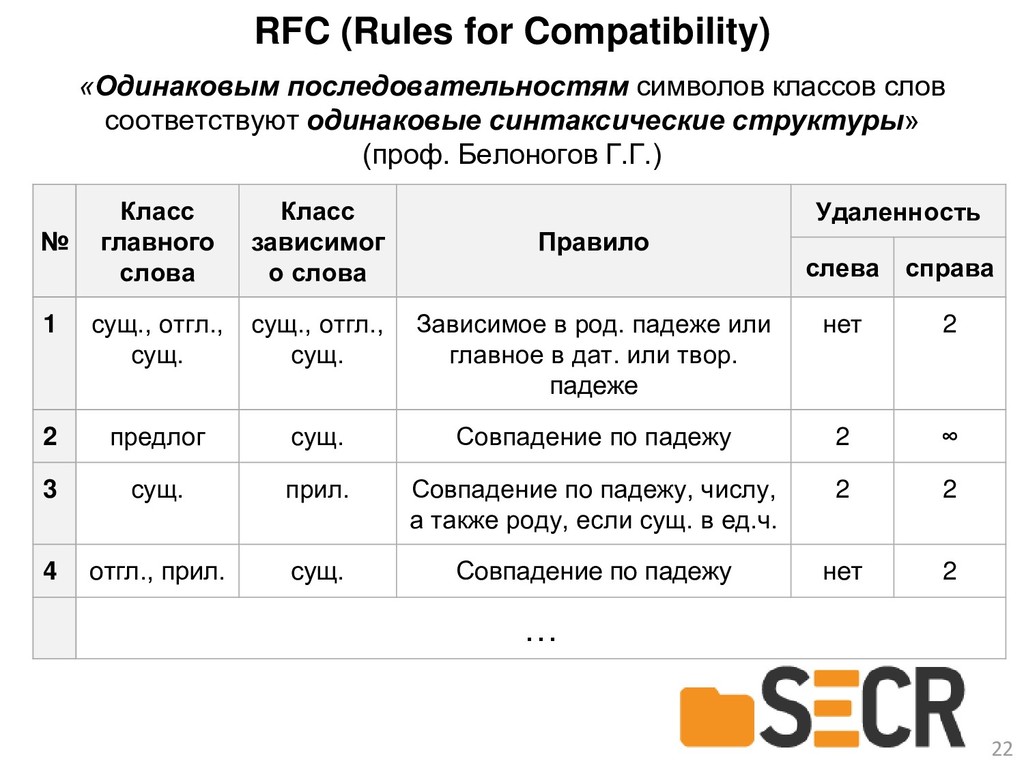{kind=link}
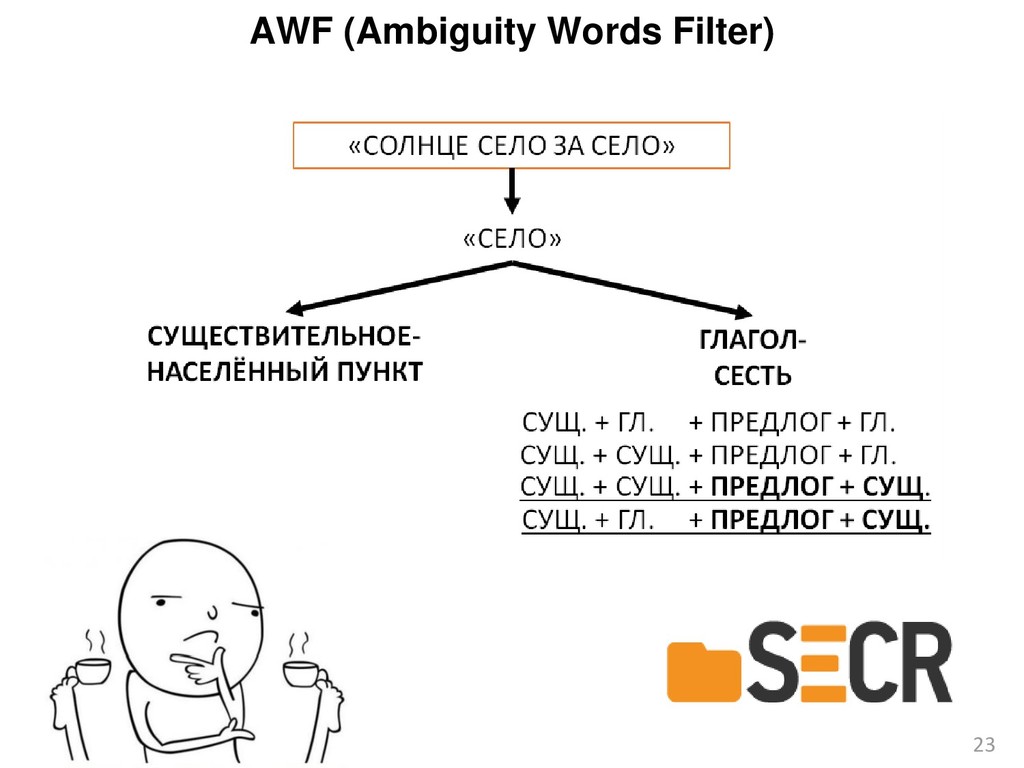{kind=link}
{kind=link}
{kind=link}
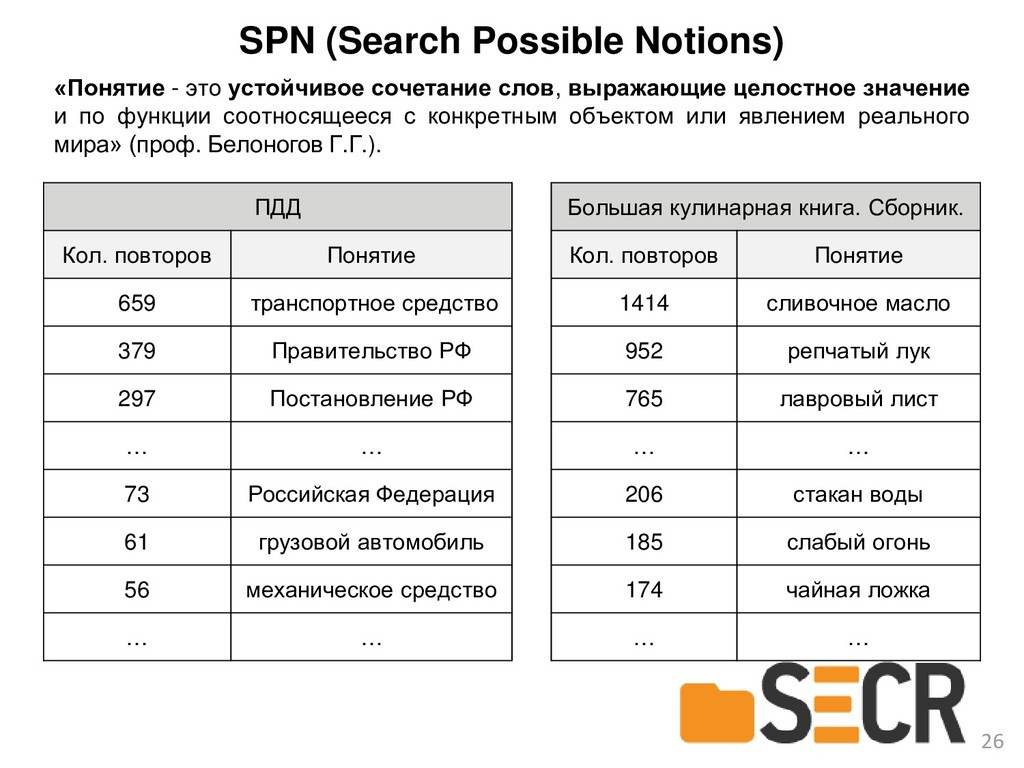{kind=link}
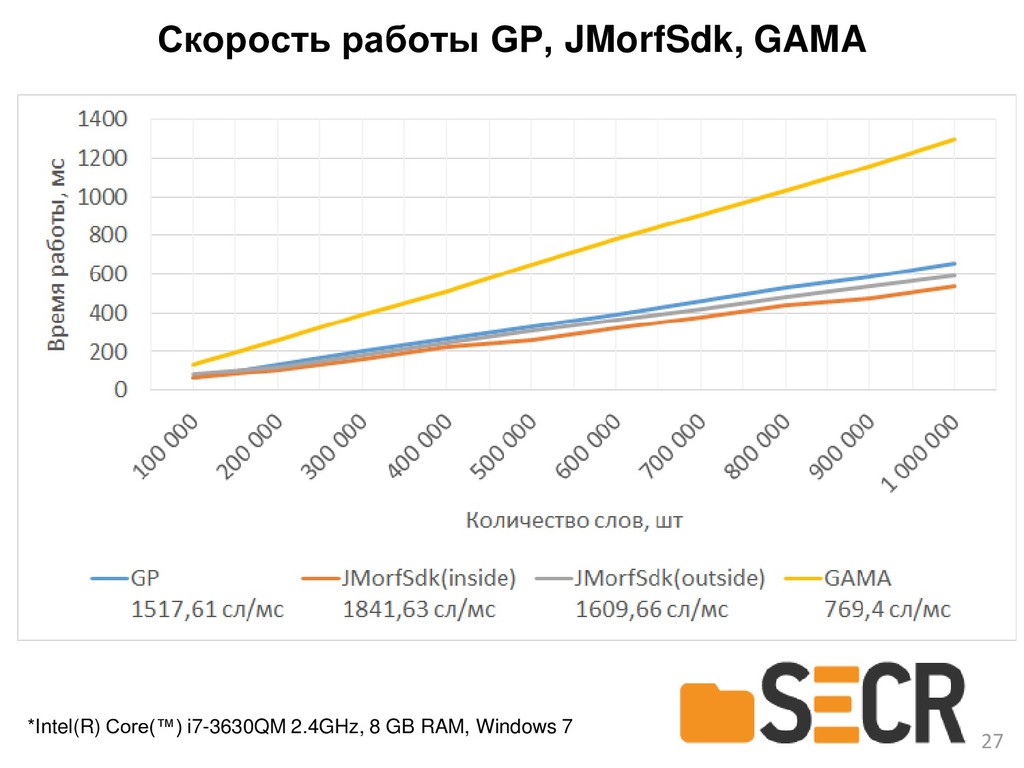{kind=link}
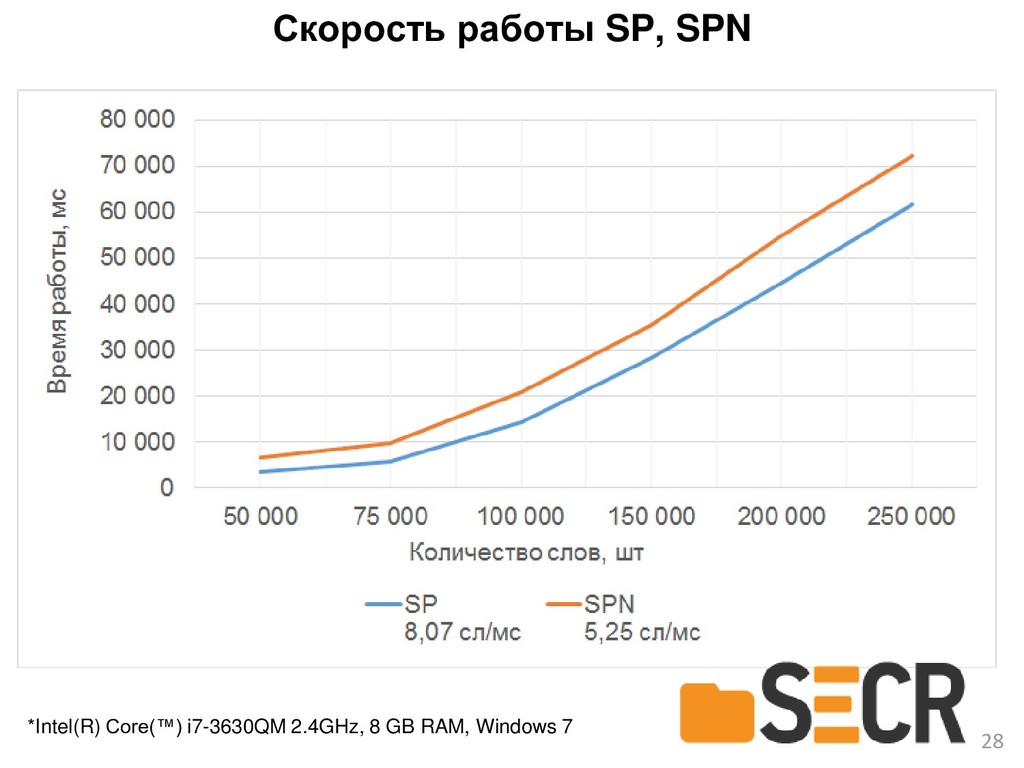{kind=link}
{kind=link}
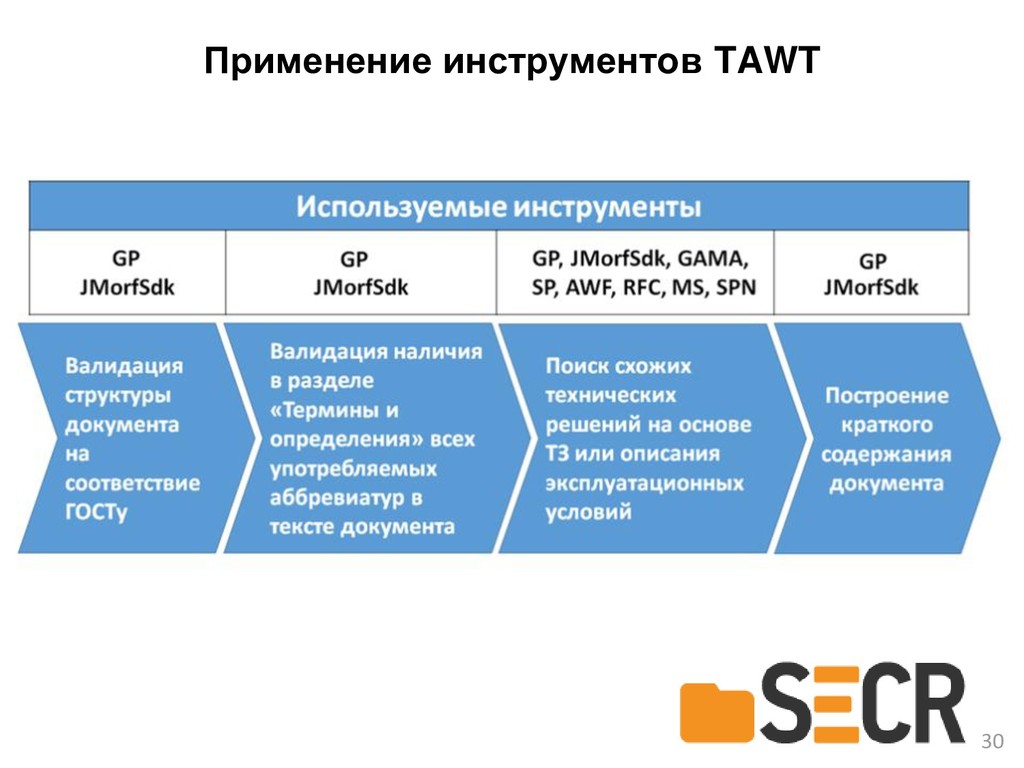{kind=link}
{kind=link}
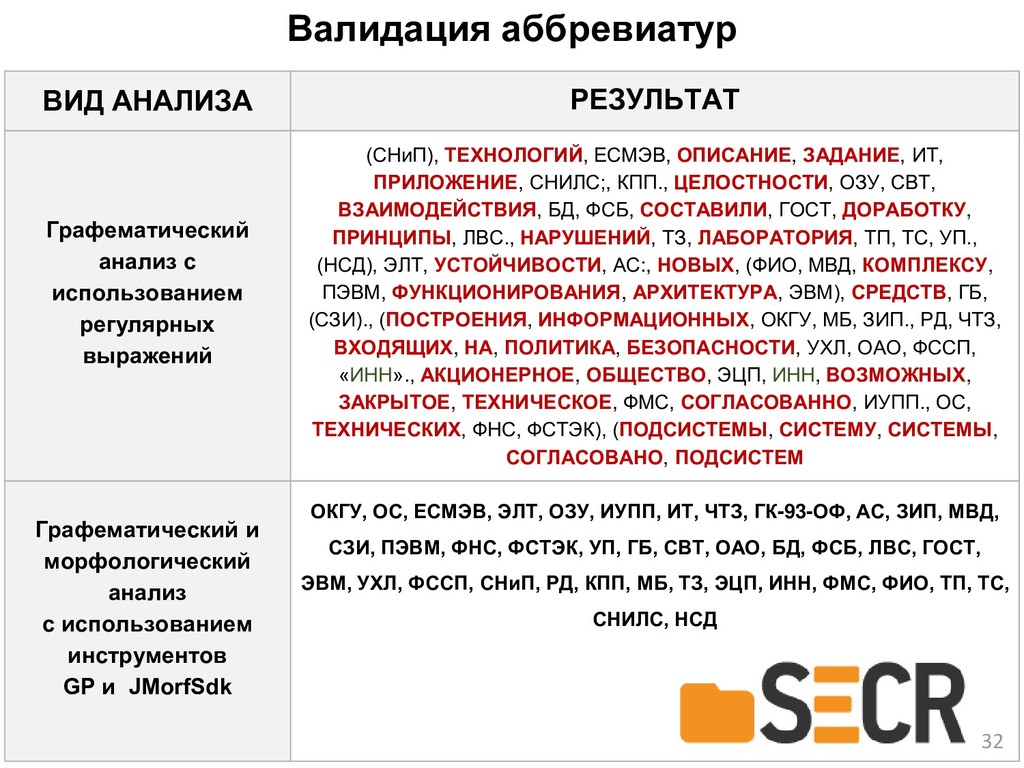{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}