The following example assumes that you have – Watched “web scraping with nutch and solr” – The above movie identity is cAiYBD4BQeE – Set up Linux based Nutch/Solr environment – Run the web scrape in the above movie • Now we will – Clean up that environment – Web scrape a parameterised url – View the urls in the data
– Previously used apache-nutch-1.6/nutch_start.sh – This contained -dir crawl option – This created apache-nutch-1.6/crawl directory – Which contains our Nutch data • Clean this as – cd apache-nutch-1.6; rm -rf crawl • Only because it contained dummy data ! • Next run of script will create dir again
– Book mark this url – Only use it if you need to empty your data • Run the following ( with solr server running ) – http://localhost:8983/solr/update?commit=true -d '<delete><query>*:*</query></delete>'
complex • Web scrape a url that has parameters i.e. – http://<site>/<function>?var1=val1&var2=val2 • This web scrape will – Have extra url characters '?=&' – Need greater search depth – Need better url filtering • Remember that you need to get permission to scrape a third party web site
• In this instance I will use a url of the form – http://somesite.co.nz/Search?DateRange=7&industry=62 – ( this is not a real url – just an example ) • Change conf regex-urlfilter.txt entry i.e. – # skip URLs containing certain characters – -[*!@] – # accept anything else – +^http://([a-z0-9]*\.)*somesite.co.nz\/Search • This will only consider some site Search urls
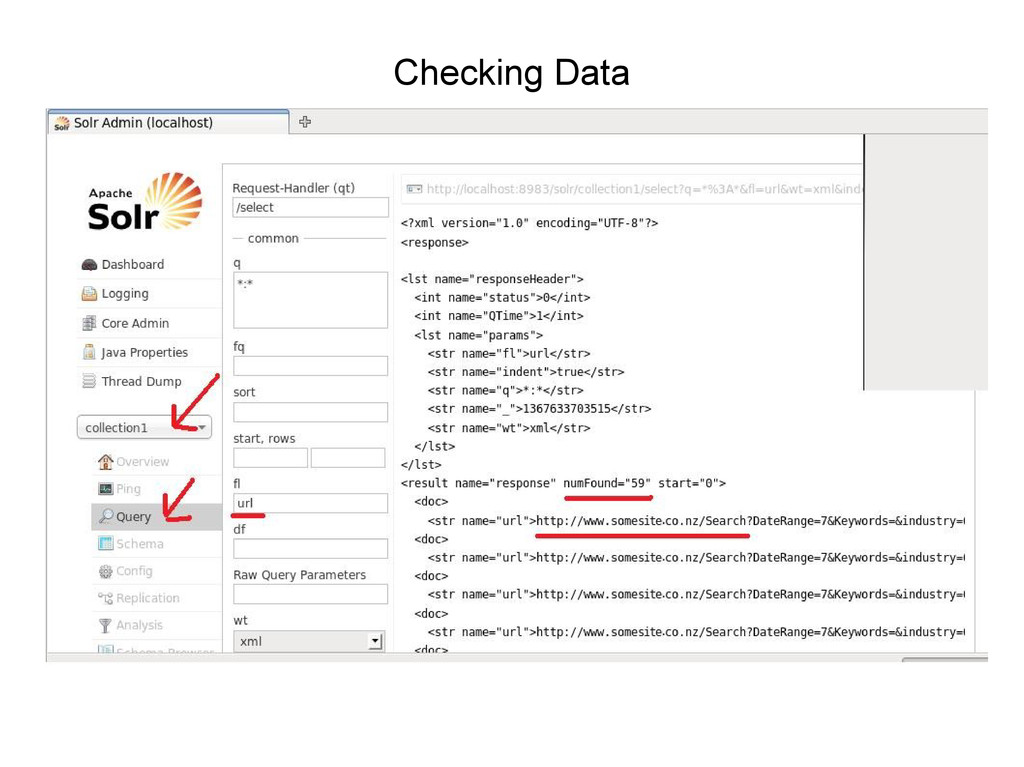
• In Solr Admin window – Set 'Core Selector' = collection1 – Click 'Query' – In Query window set fl field = url – Click Execute Query • The result ( next ) shows the filtered list of urls in Solr
www.semtech-solutions.co.nz – [email protected] • We offer IT project consultancy • We are happy to hear about your problems • You can just pay for those hours that you need • To solve your problems
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}