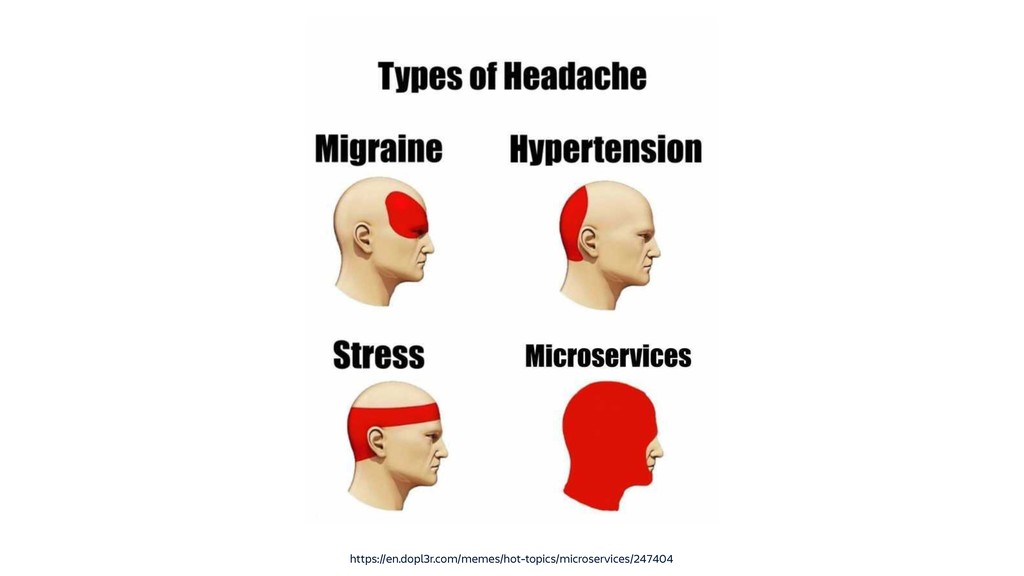
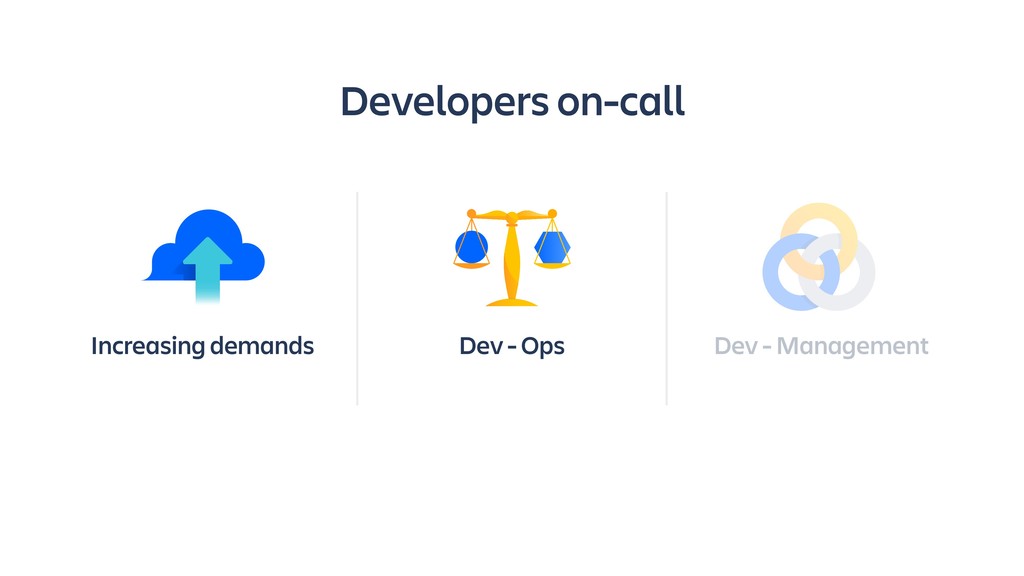
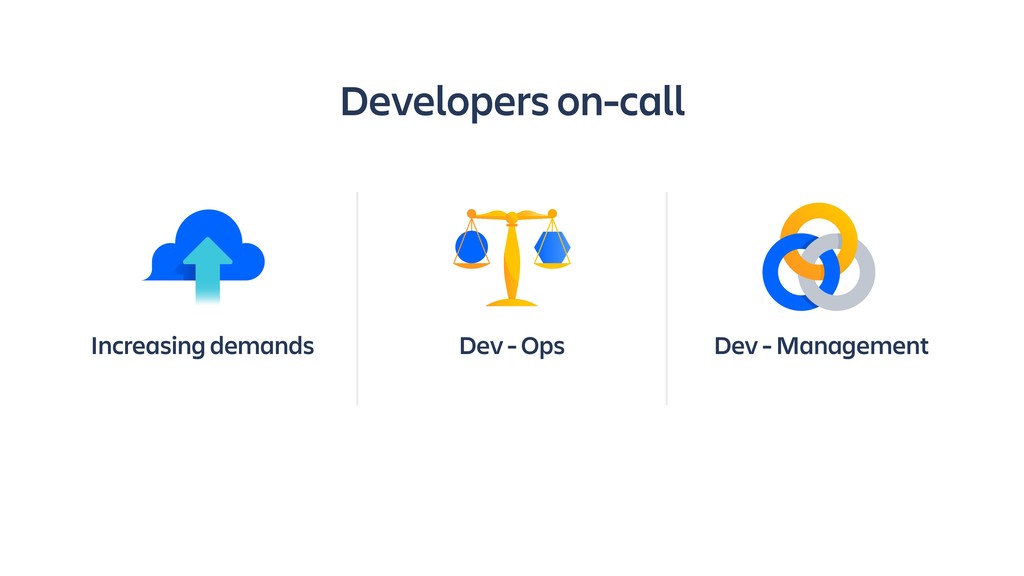
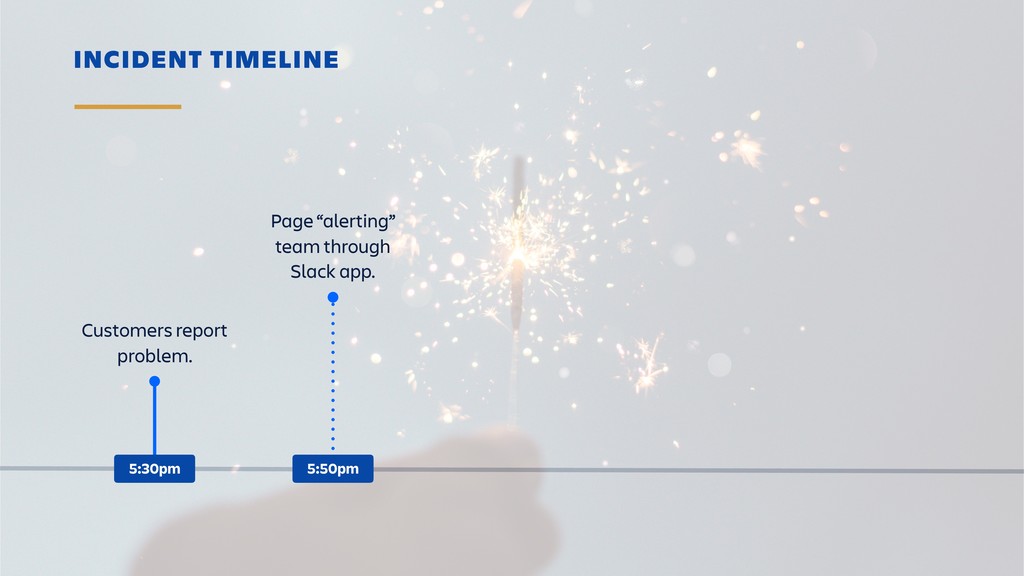
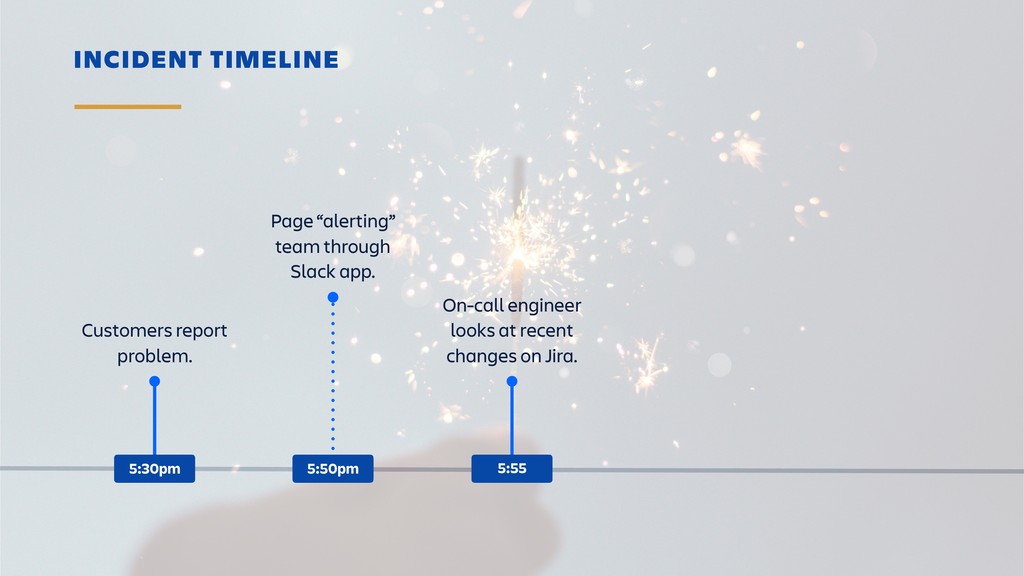
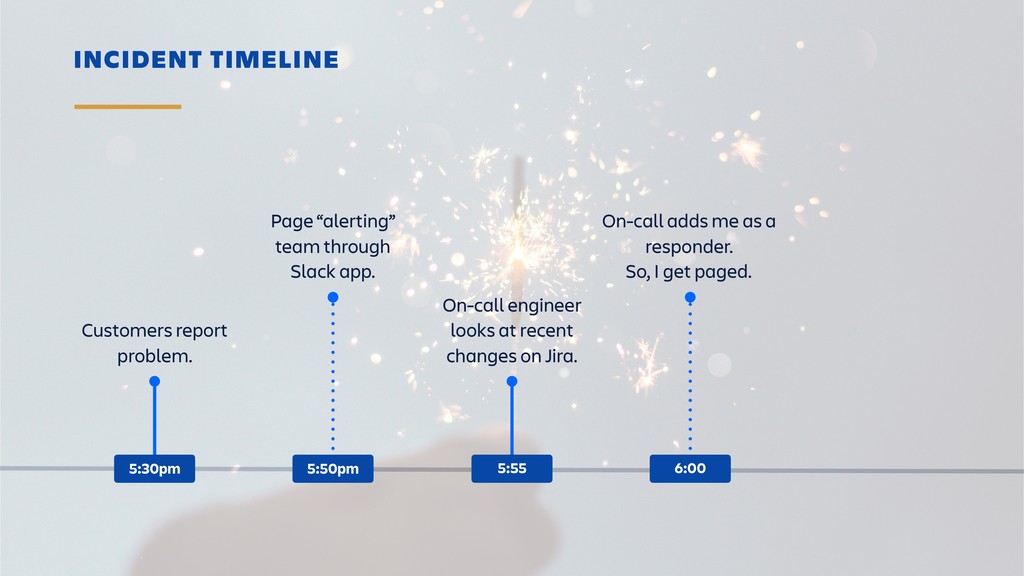
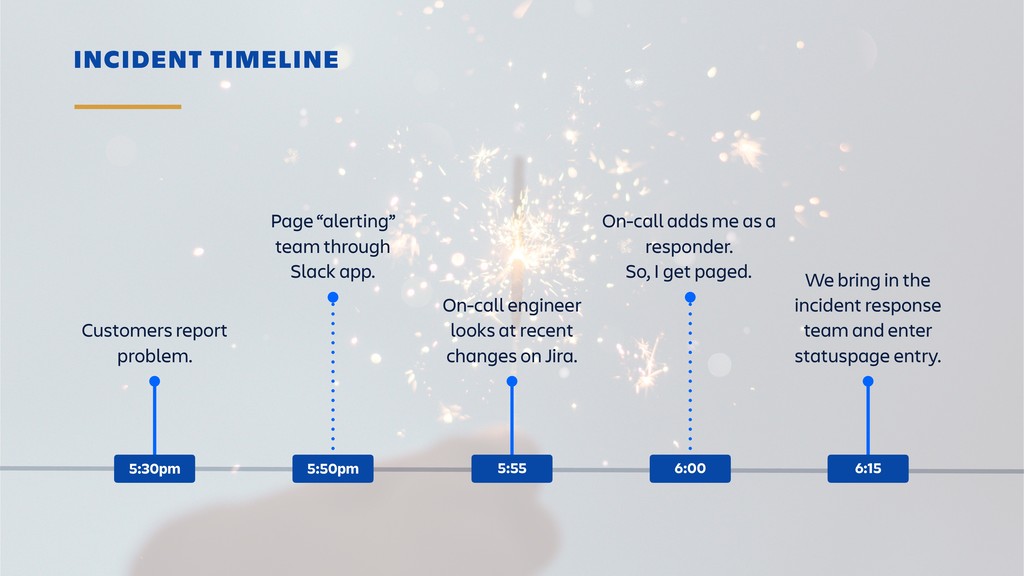
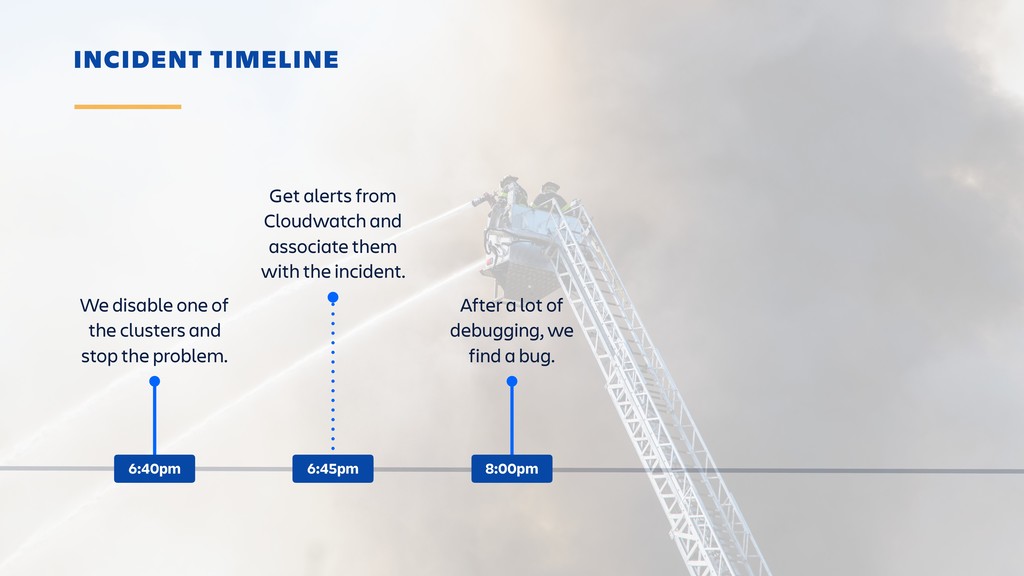
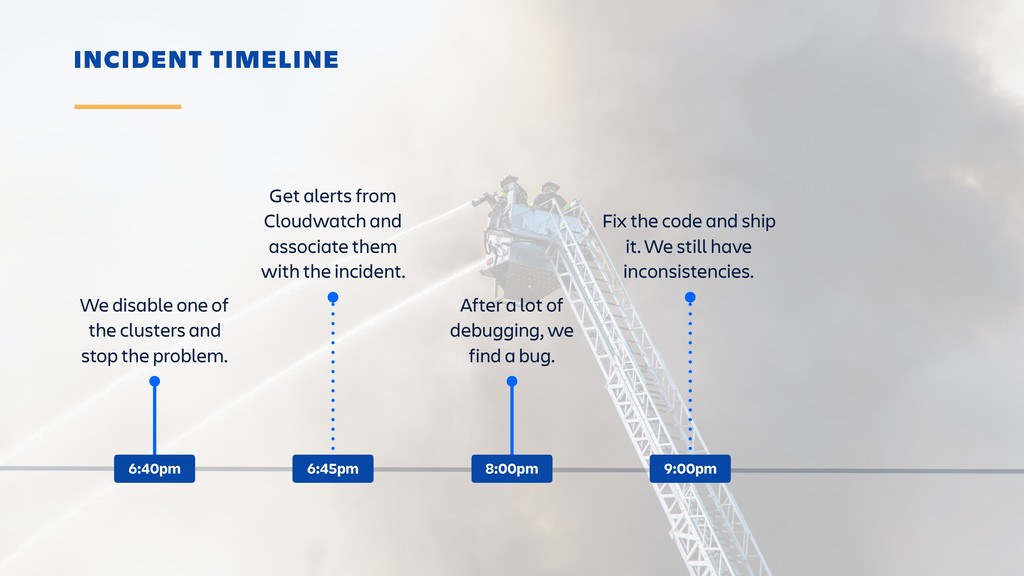
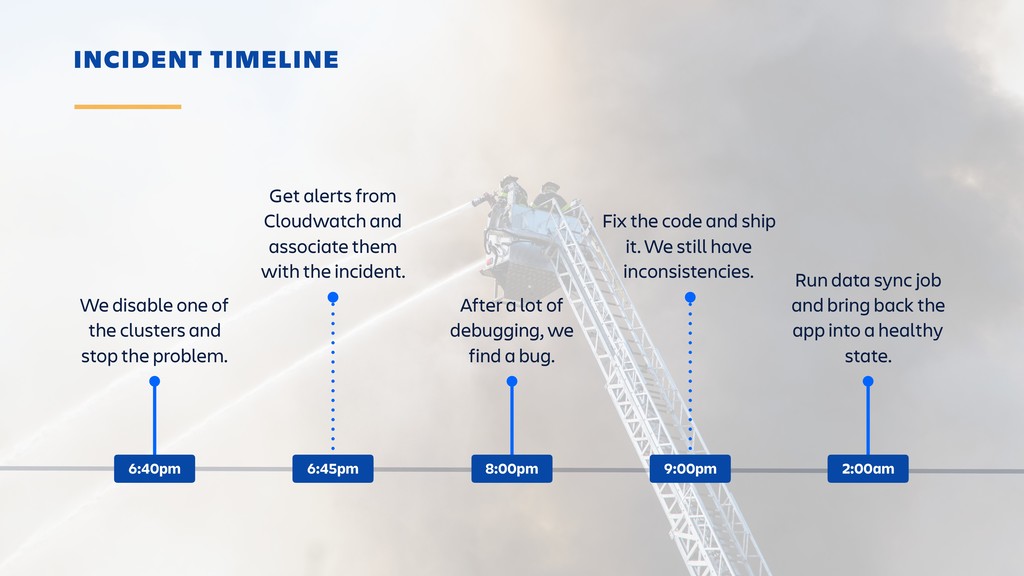
Raise your hand if you enjoy being buried in alerts or woken up at 2am? (Yeah... thought so.) Ever-rising customer expectations around high availability and performance put massive pressure on the teams who develop and support SaaS products. And teams are literally losing sleep over it.
Until outages and other incidents are a thing of the past, organizations need to invest in a way of dealing with them that won't lead to burn-out. In this session, you'll learn how to combine the latest tooling with DevOps practices in the pursuit of a sustainable incident response workflow. It's all about actionable alerts, training, transparency and learning from each incident.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}