Share
「夏のトップカンファレンス論文読み会」発表資料です。 https://www.slideshare.net/YosukeShinya/active-convolution-deformable-convolution-convolution より移行。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
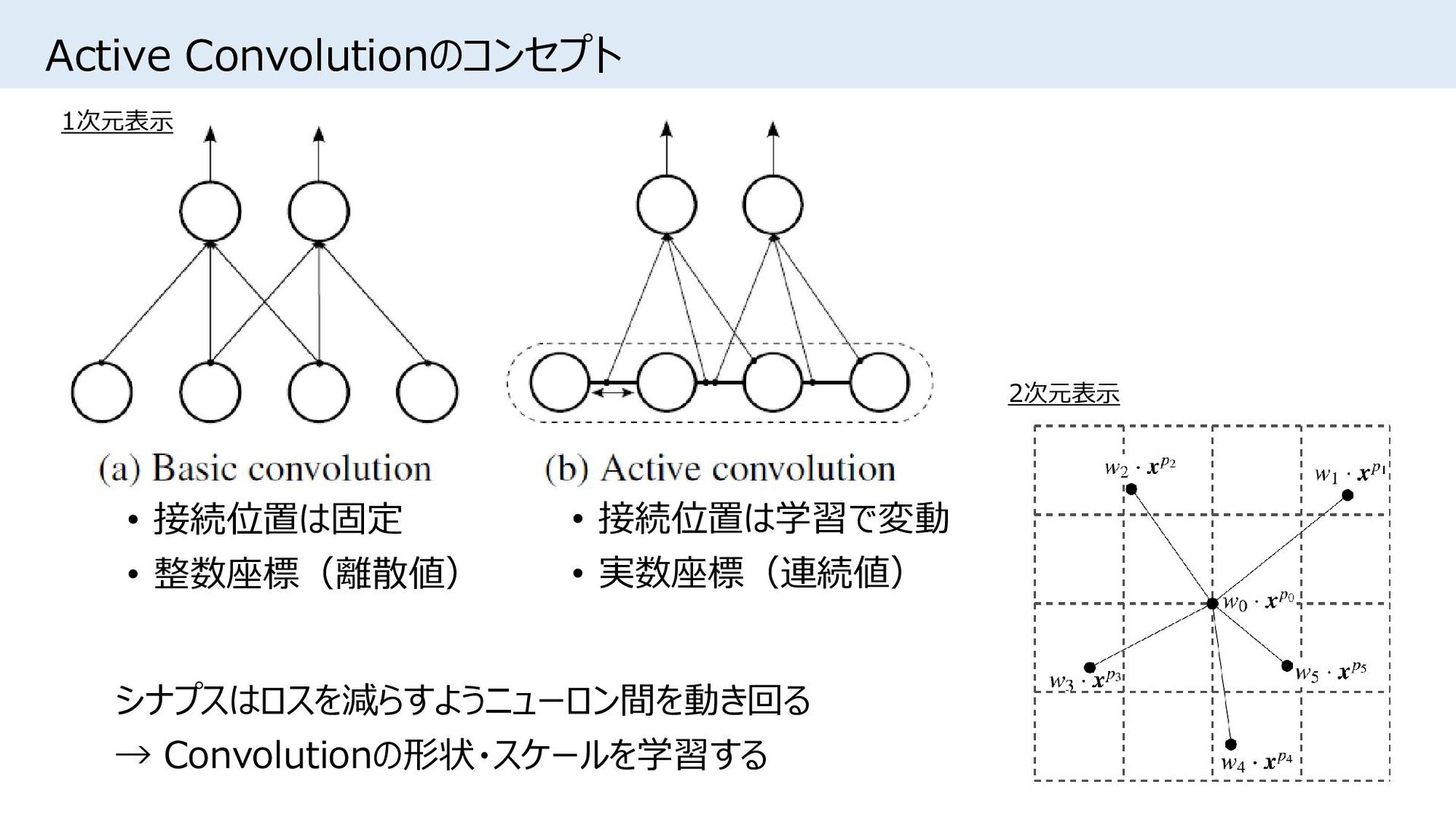{kind=link}
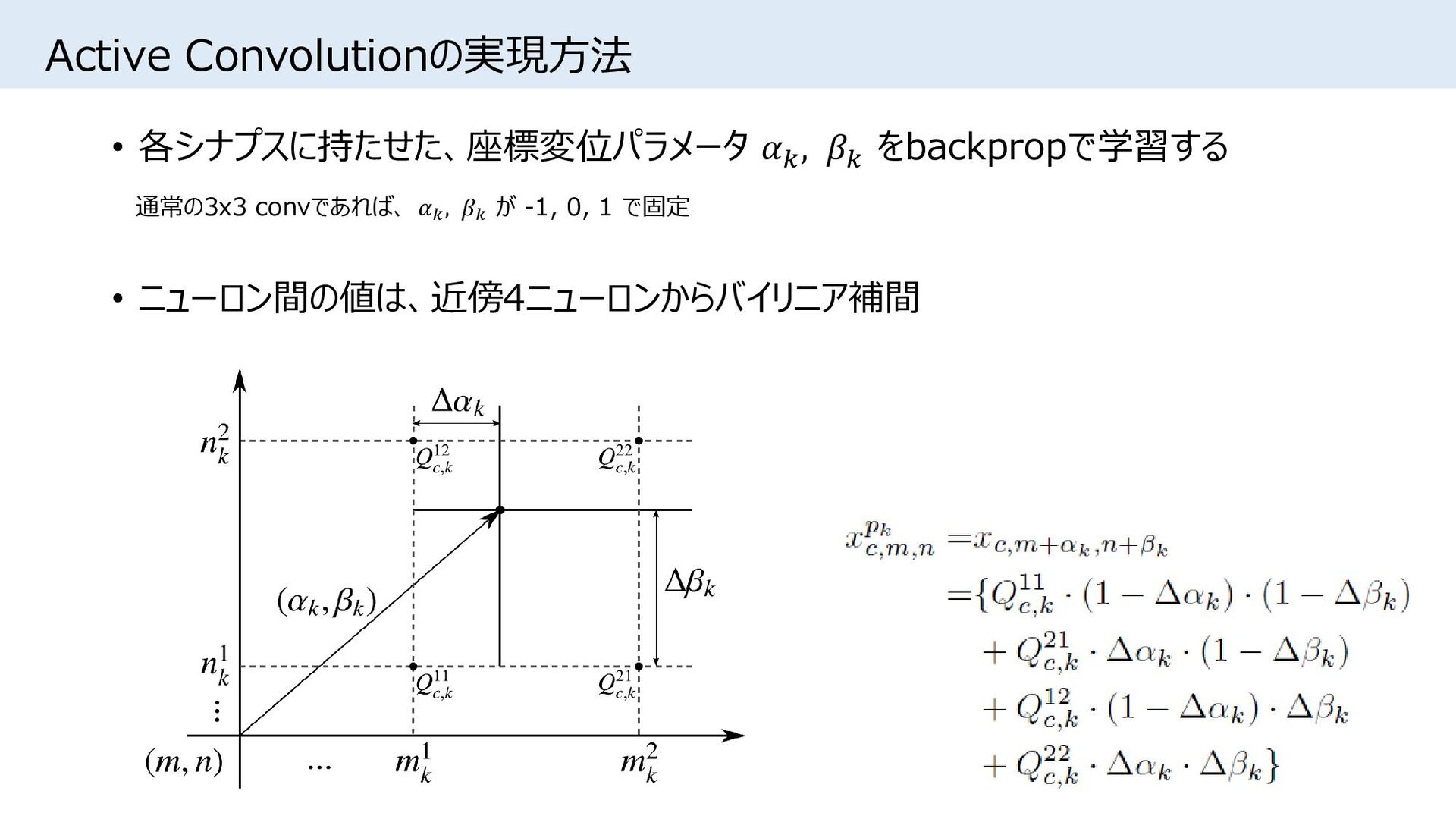{kind=link}
{kind=link}
{kind=link}
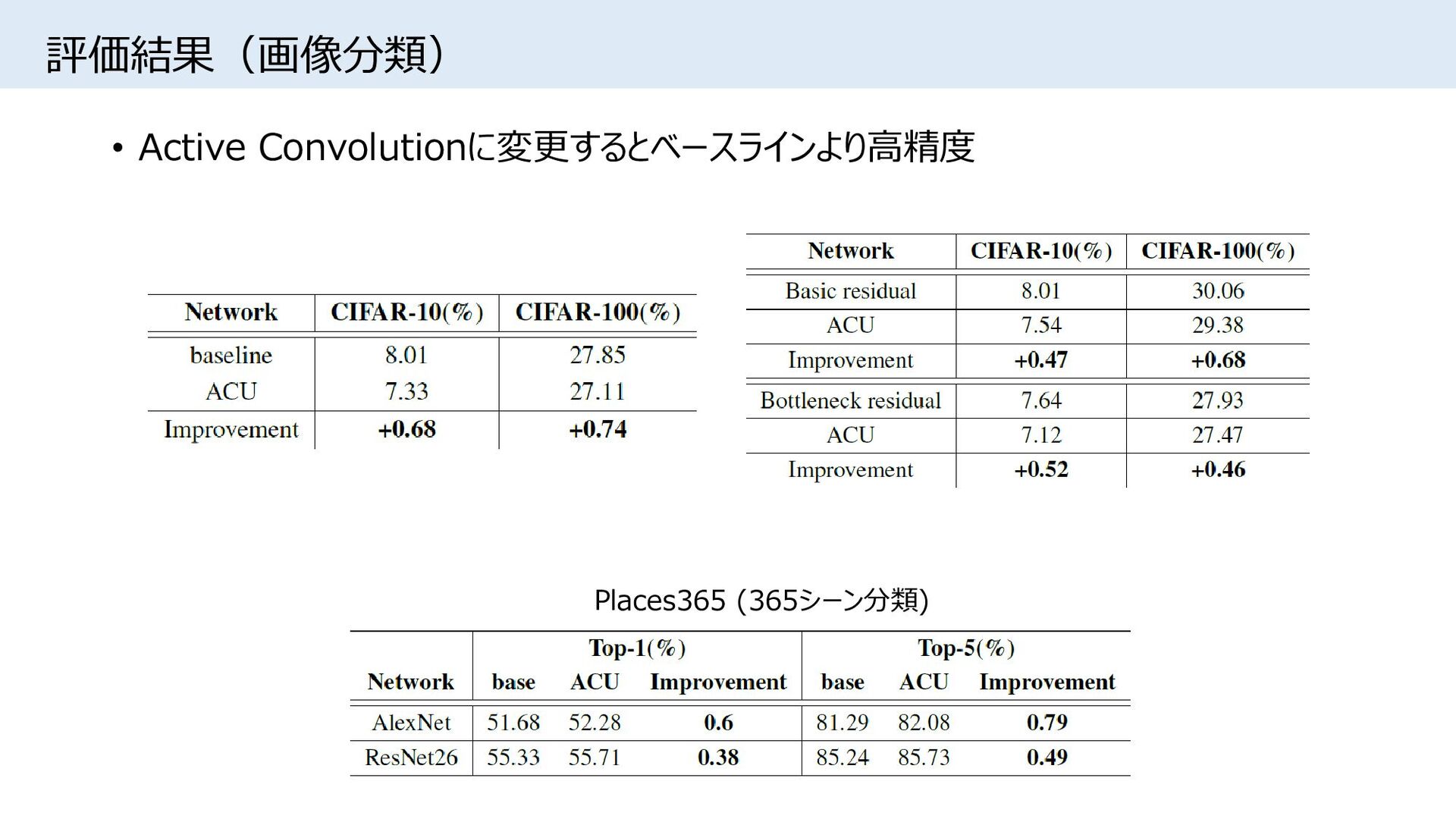{kind=link}
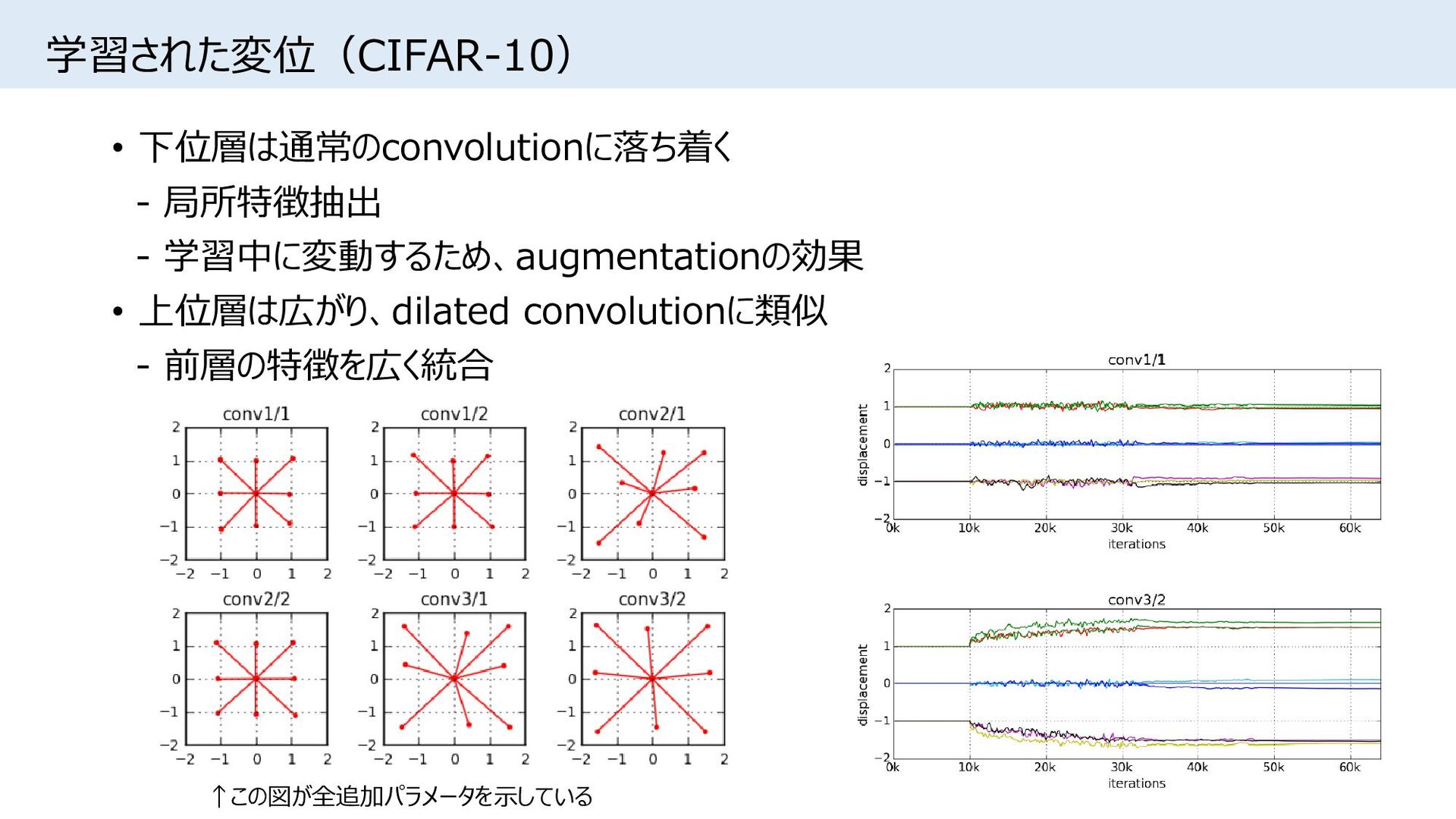{kind=link}
{kind=link}
{kind=link}
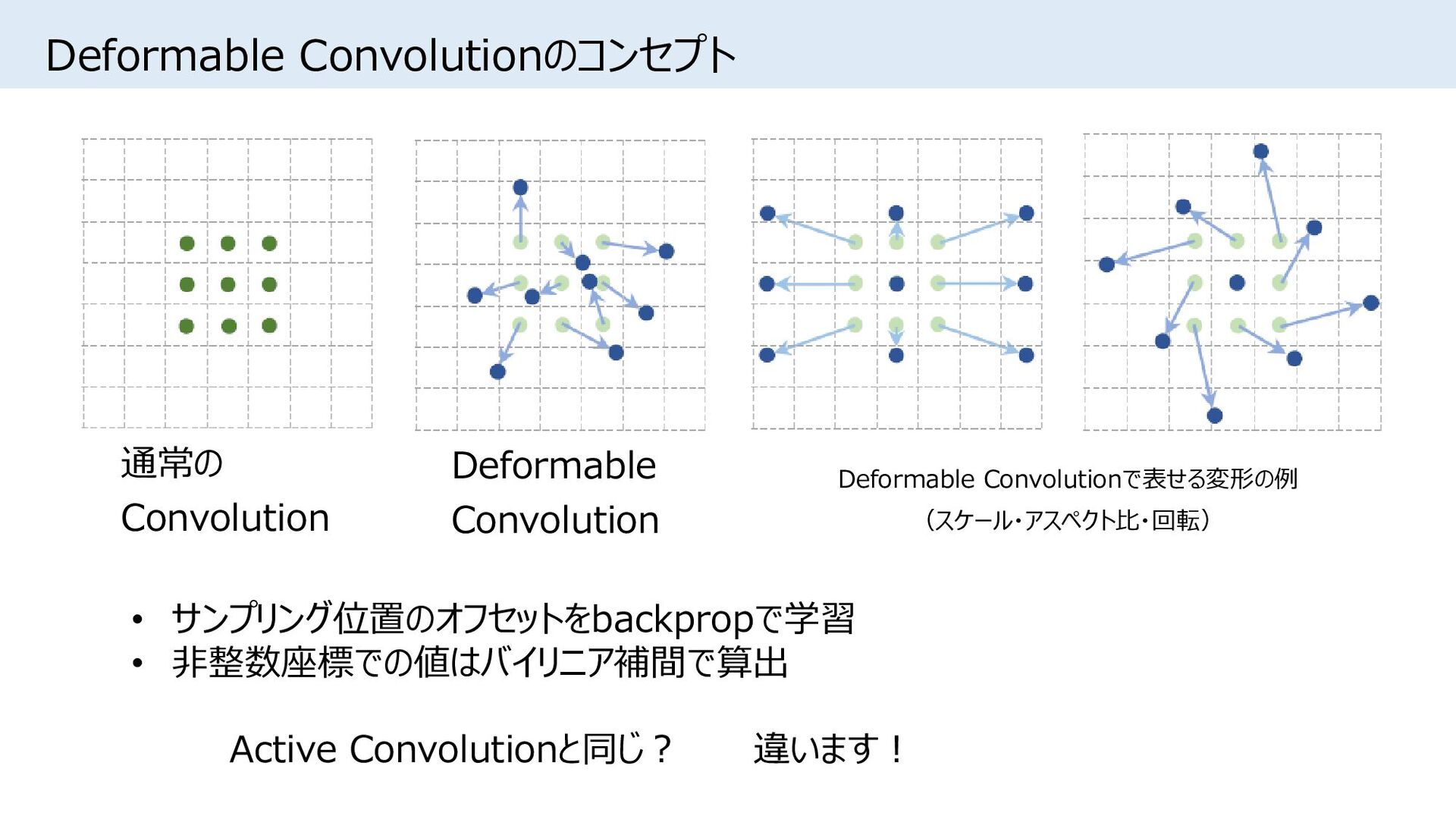{kind=link}
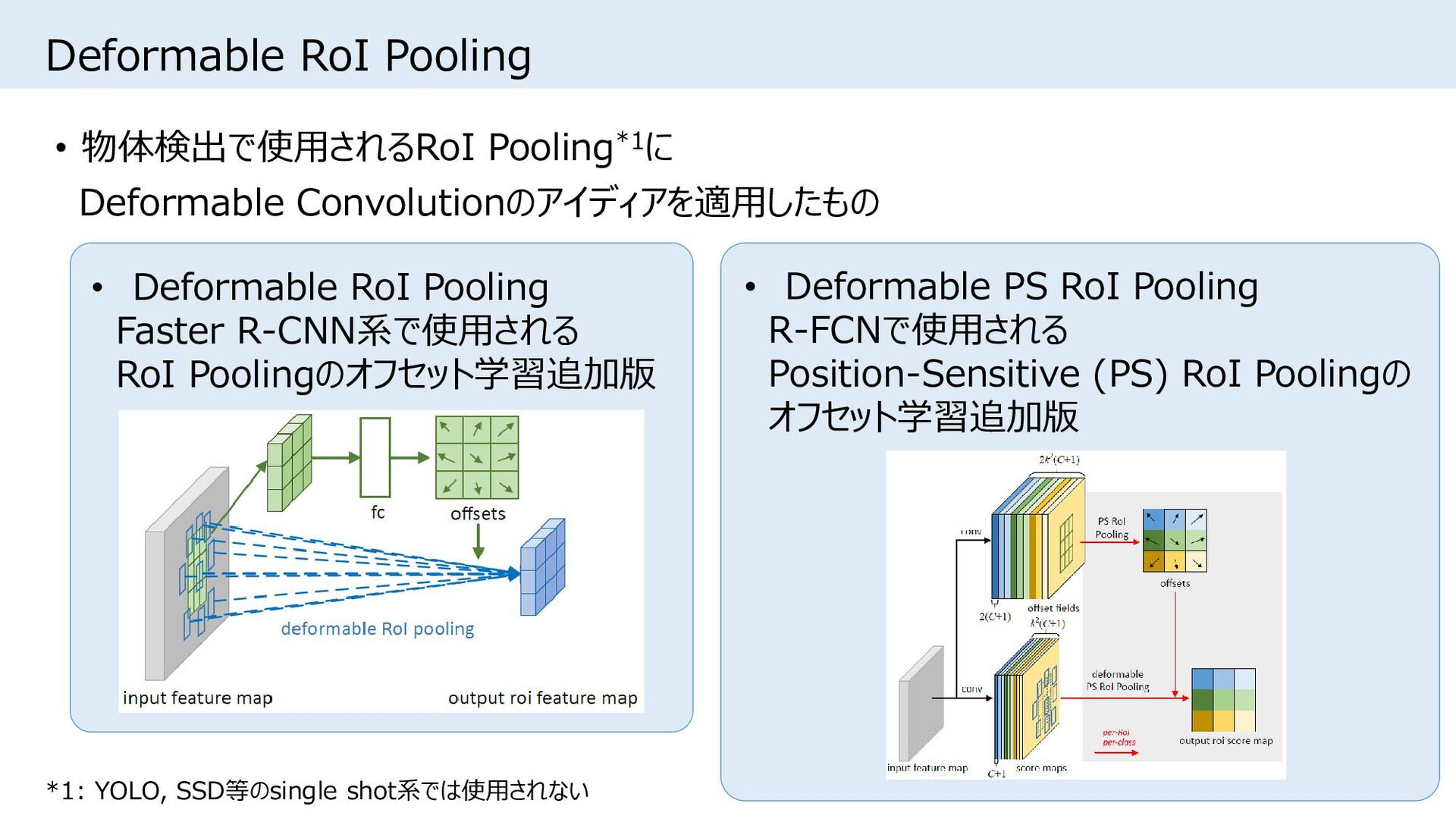
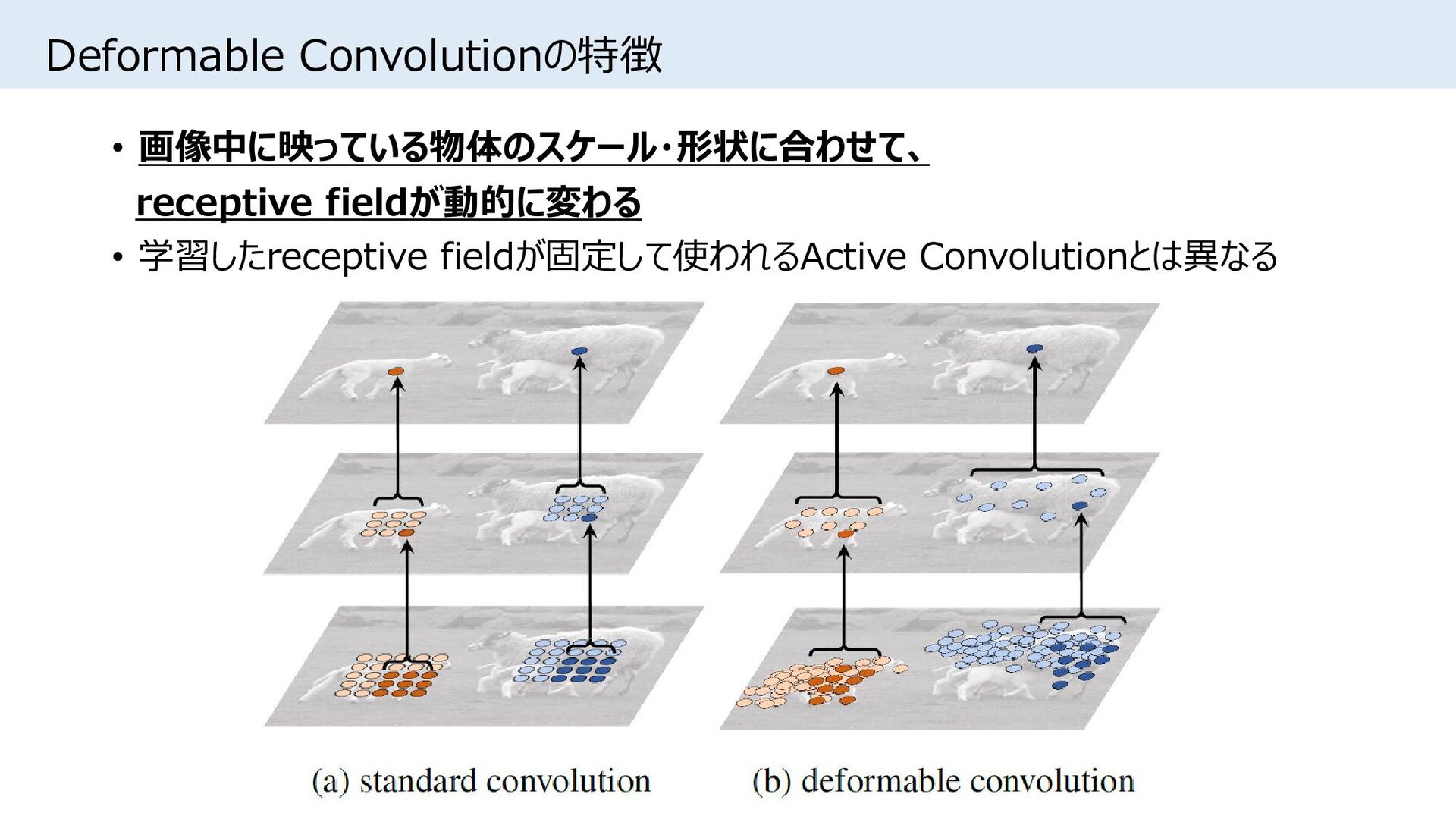{kind=link}
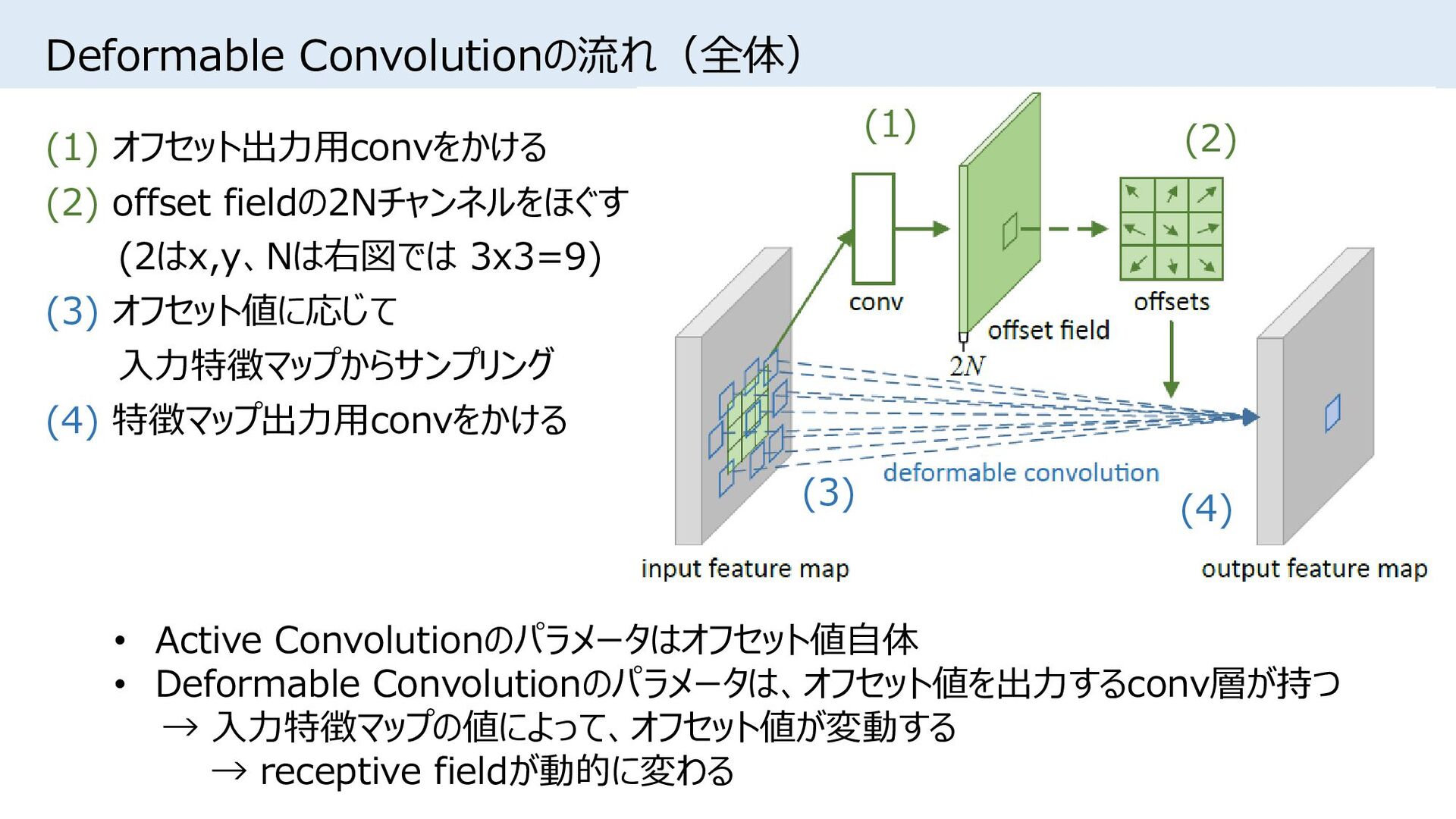{kind=link}
{kind=link}
{kind=link}
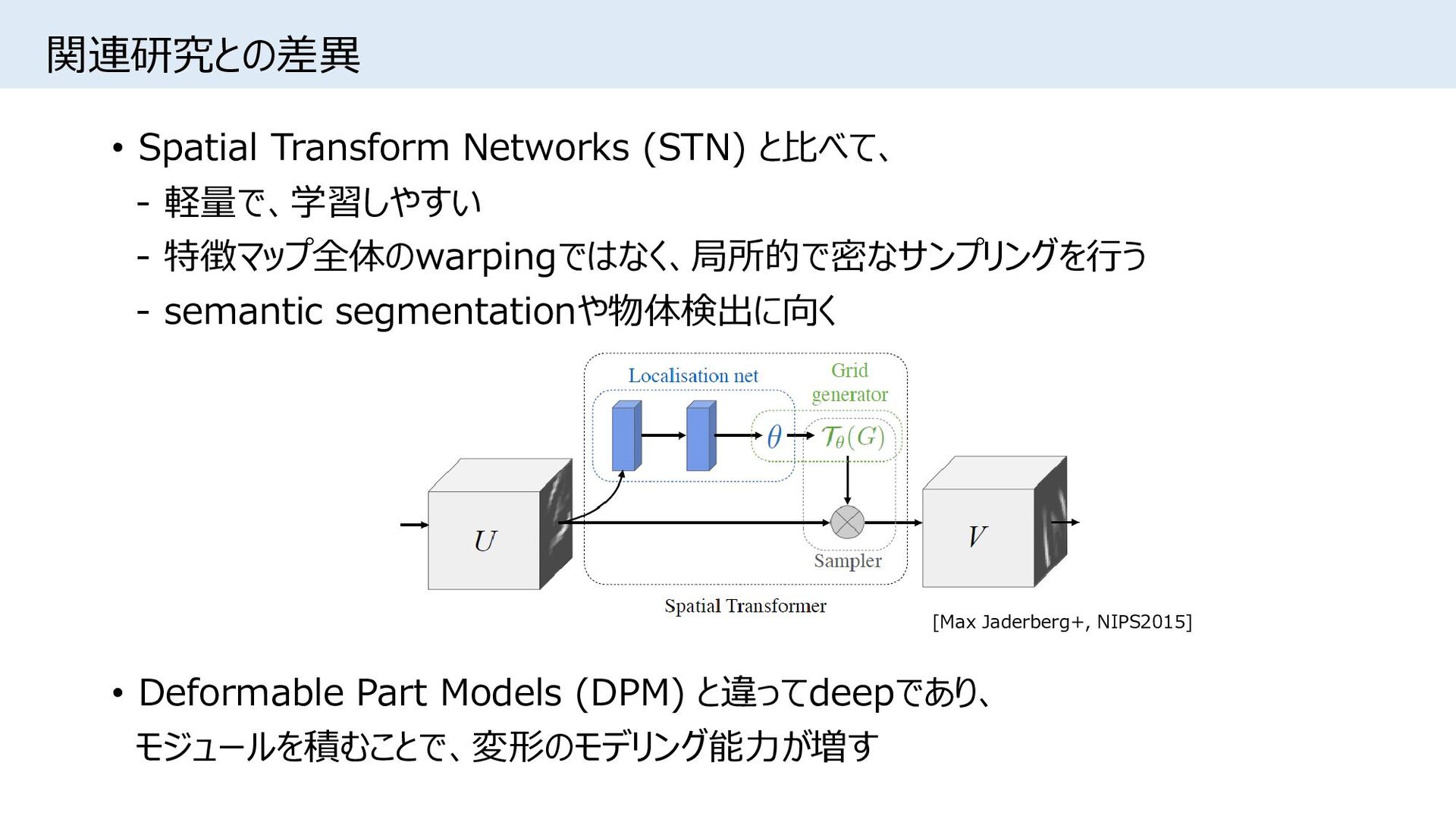{kind=link}
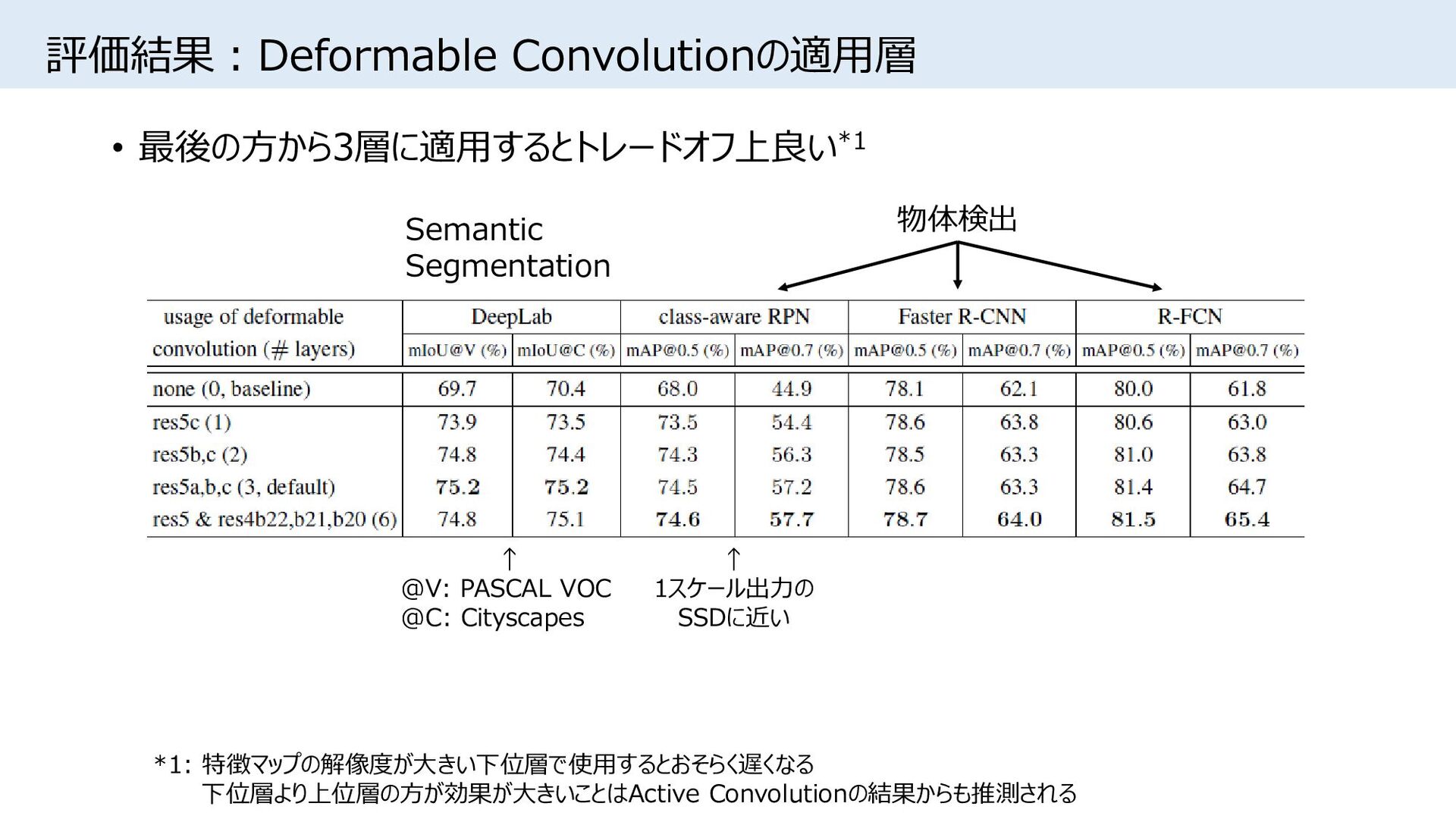{kind=link}
{kind=link}
{kind=link}
{kind=link}
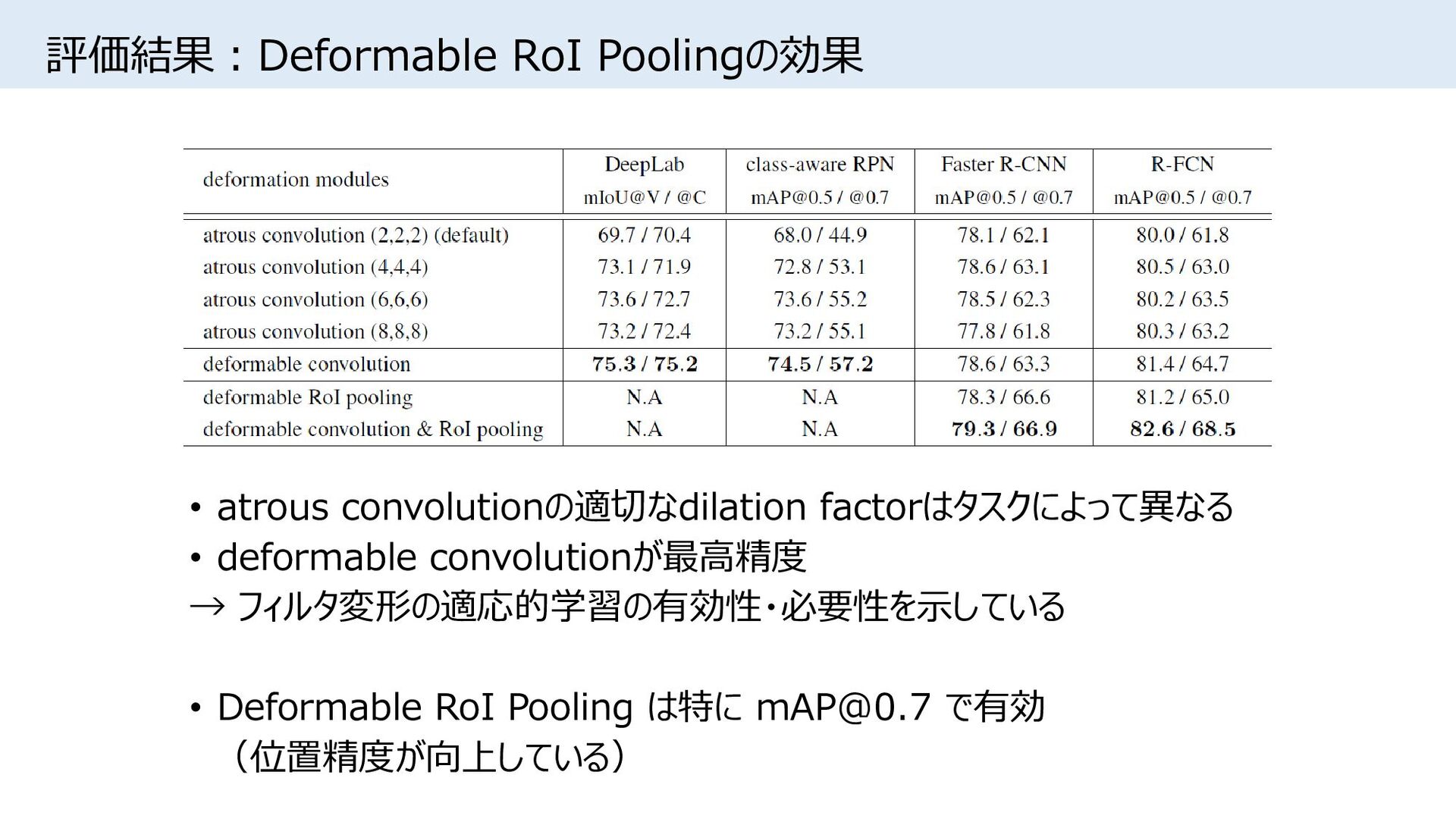{kind=link}
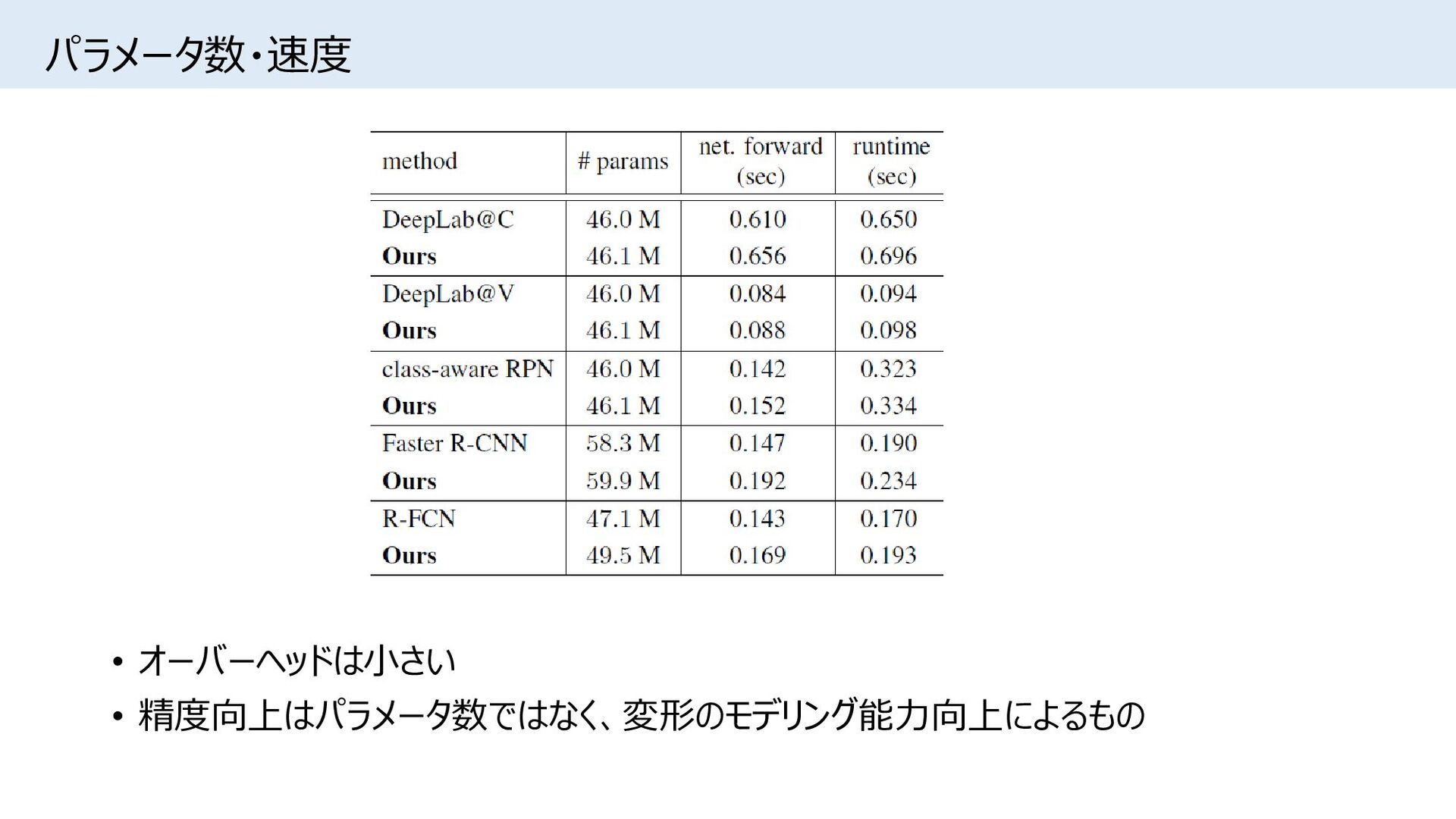{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![http://deeplearning.csail.mit.edu/instance_ross.pdf [Kaiming He+, ICCV2017] 補足:RoI Align (Mask R-CNN) でのバイリニア補間 4点使っているが別に4点でなくてもいい](https://files.speakerdeck.com/presentations/9cf24c739a5543bd84b15c3153faa7f2/slide_34.jpg){kind=link}