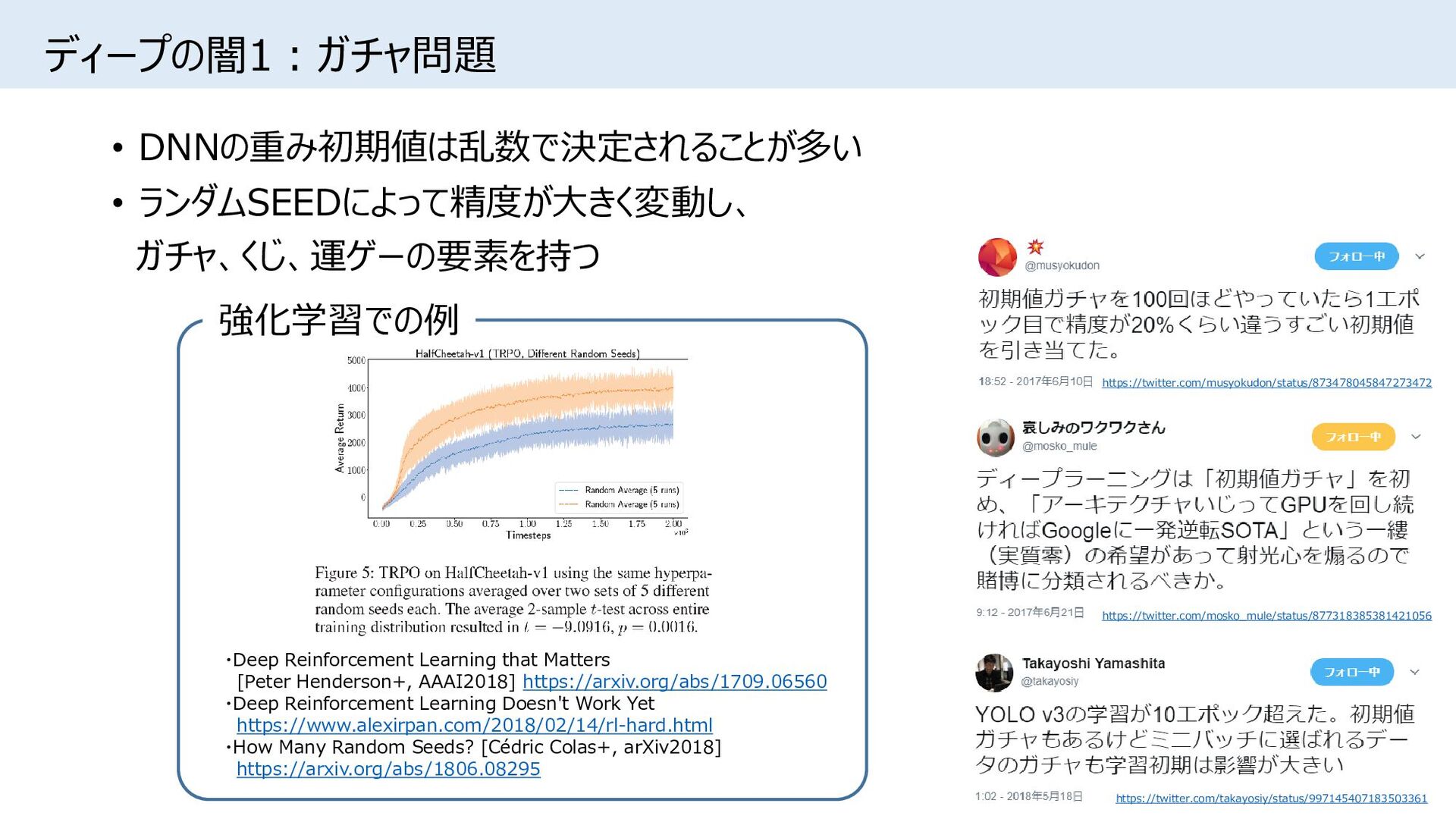
from Initialization [Vaishnavh Nagarajan+, NIPSW2017] http://www.cs.cmu.edu/~vaishnan/papers/nips17_dltp.pdf • Towards Understanding the Role of Over-Parametrization in Generalization of Neural Networks [Behnam Neyshabur+, arXiv2018] https://arxiv.org/abs/1805.12076 ランダム初期化時と学習後の重みの値の距離に基づいて汎化誤差を分析 • DropBack: Continuous Pruning During Training [Maximilian Golub+, arXiv2018] https://arxiv.org/abs/1806.06949 • Intriguing Properties of Randomly Weighted Networks: Generalizing While Learning Next to Nothing [Amir Rosenfeld+,arXiv2018] https://arxiv.org/abs/1802.00844 重みの大半をランダム初期値で固定し、一部の重みのみを更新 • Insights on representational similarity in neural networks with canonical correlation [Ari S. Morcos+, arXiv2018] https://arxiv.org/abs/1806.05759 大きなネットワークほど似た解に収束する
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![標準的なpruning方法 図は [Song Han+, NIPS2015] を元に作成 (1) ランダム初期化 (2) 学習](https://files.speakerdeck.com/presentations/c60d7159cf7d4f83bad24759812e94fb/slide_6.jpg){kind=link}
![宝くじ券仮説の実験的な確かめ方(pruningによる当選券抽出) 図は [Song Han+, NIPS2015] を元に作成 (2) 学習 (3) pruning](https://files.speakerdeck.com/presentations/c60d7159cf7d4f83bad24759812e94fb/slide_7.jpg){kind=link}
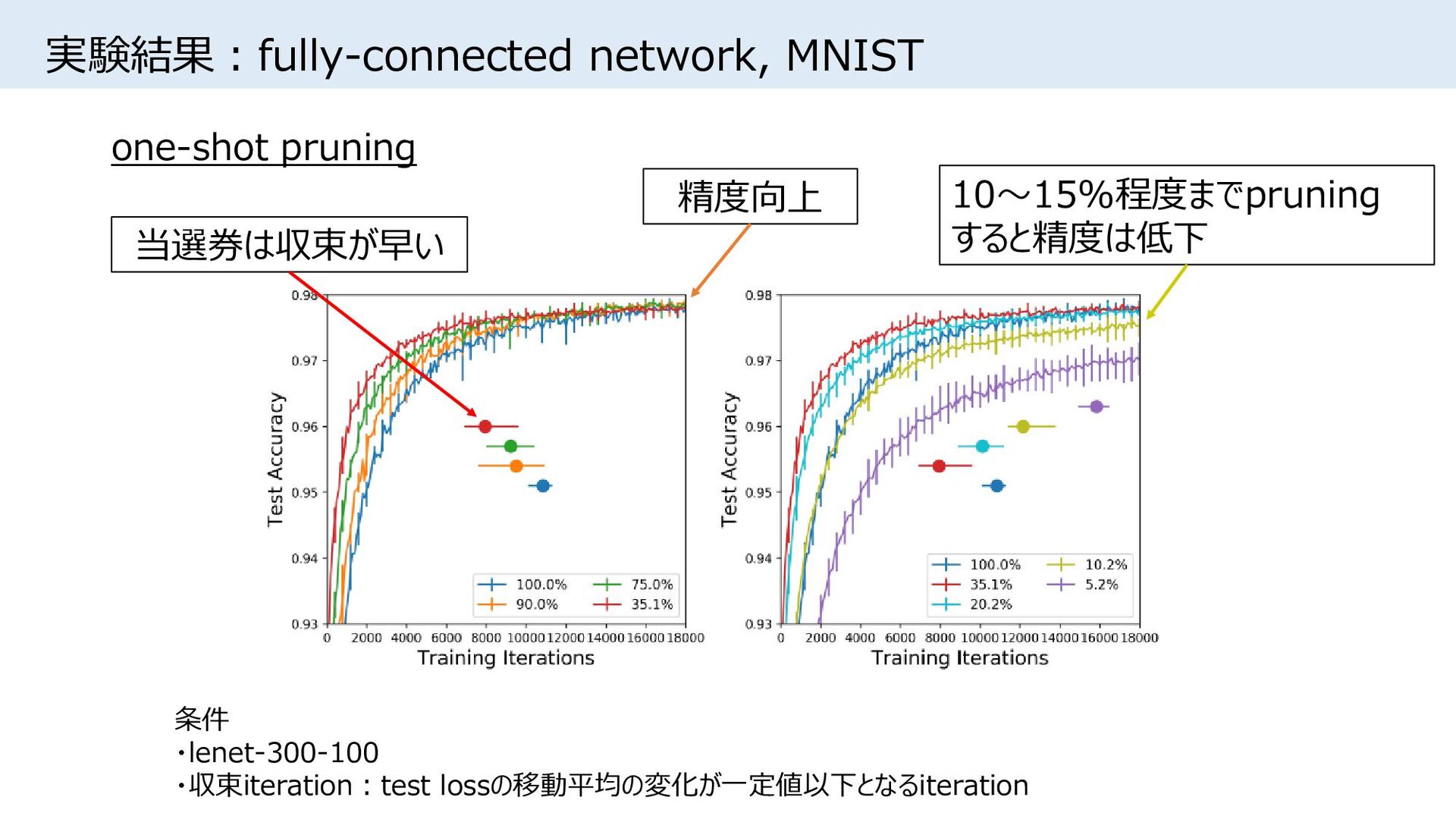
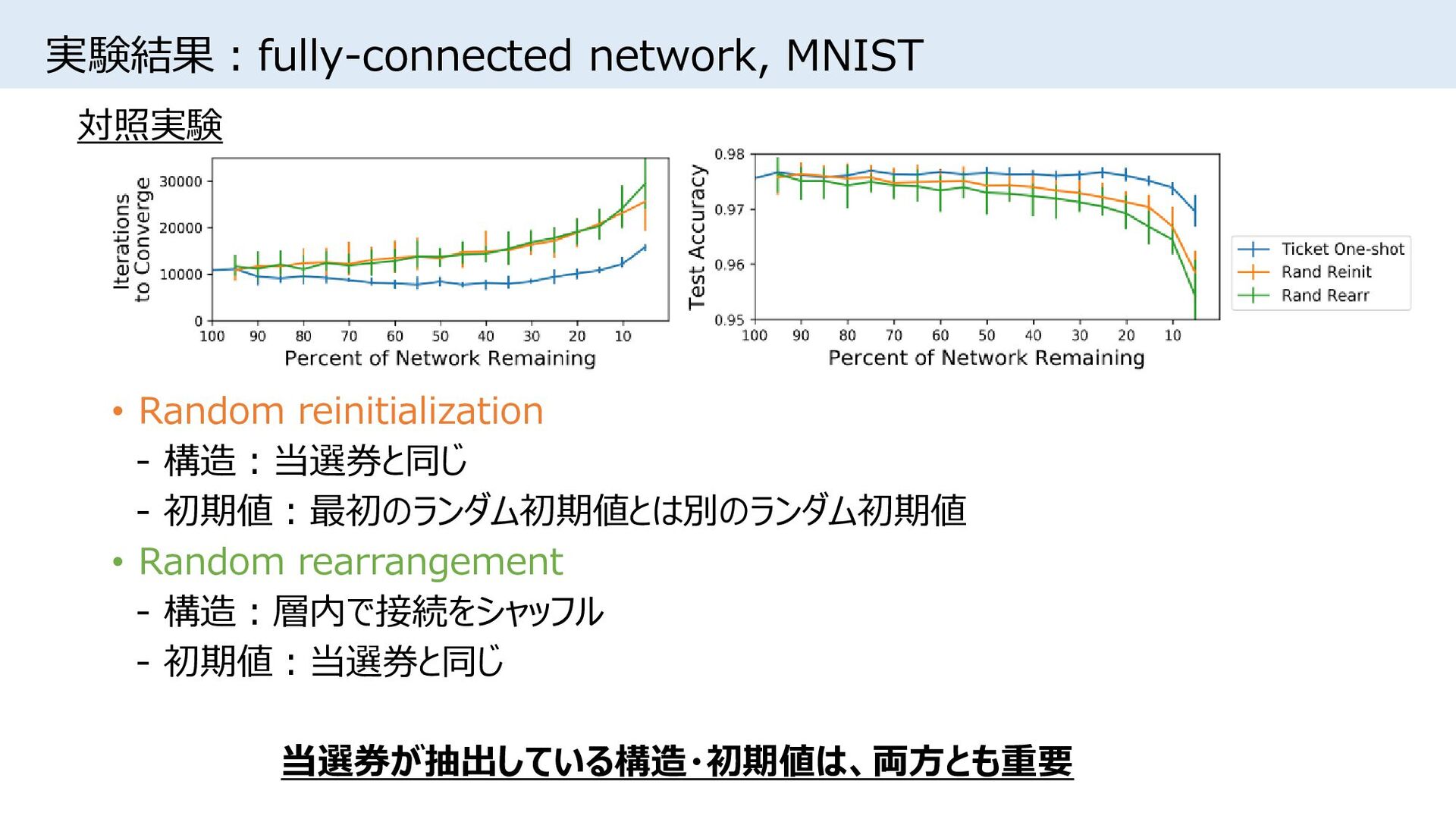
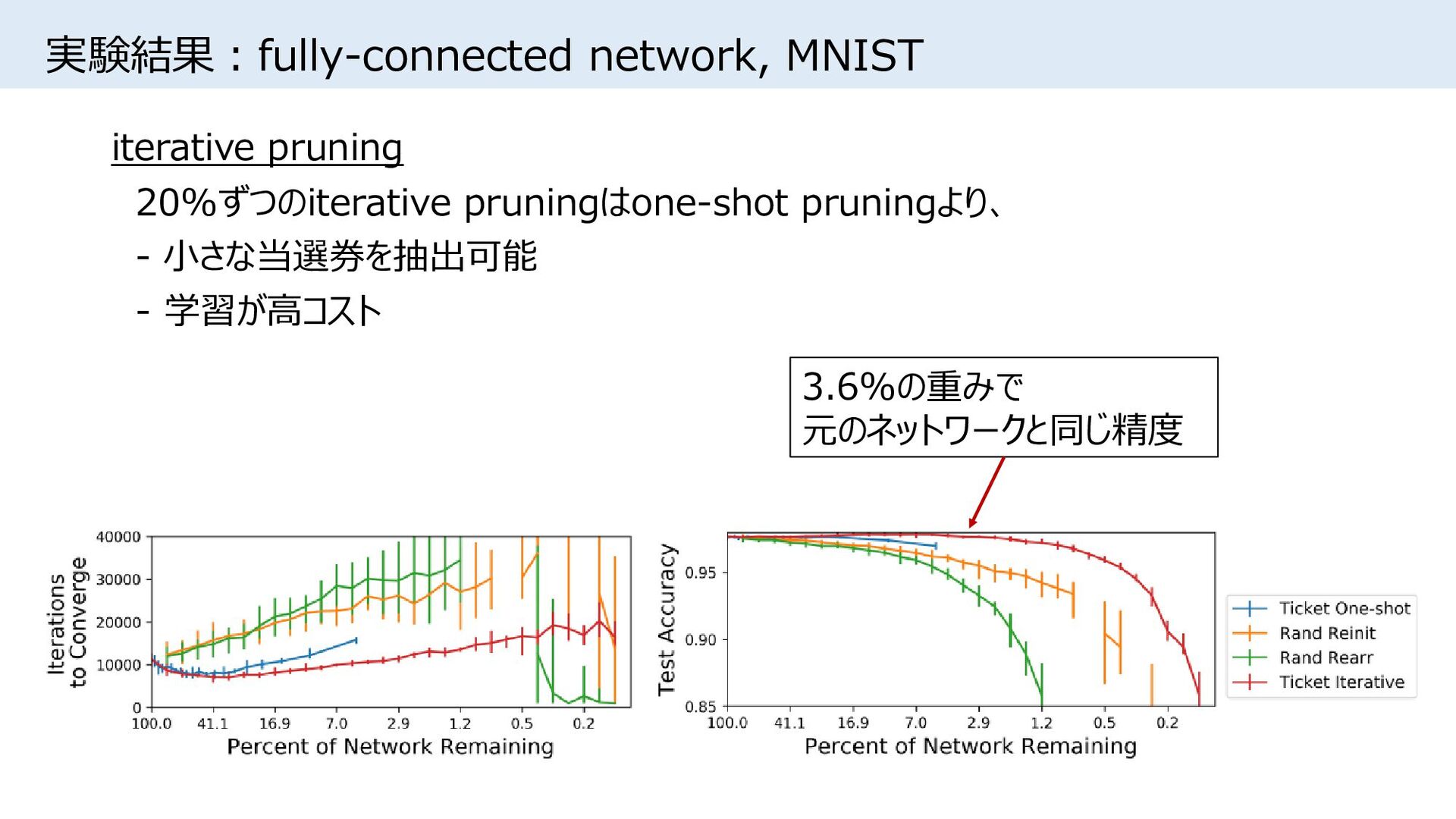
![実験条件 • [Song Han+, NIPS2015]同様、重みの絶対値が小さい接続をpruning • One-shot pruning:学習後、所望のサイズまで一気にpruning • Iterative](https://files.speakerdeck.com/presentations/c60d7159cf7d4f83bad24759812e94fb/slide_8.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
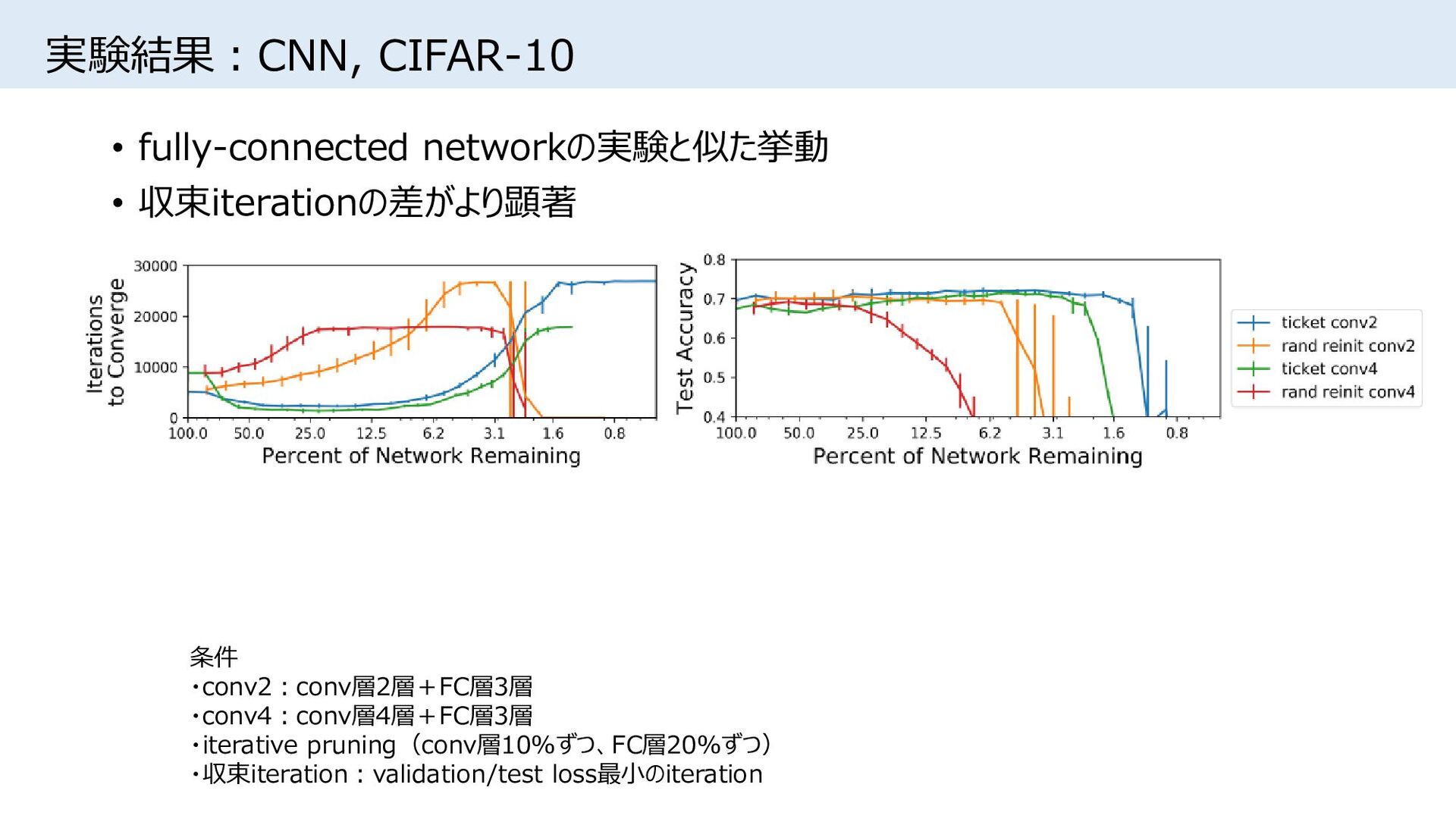{kind=link}
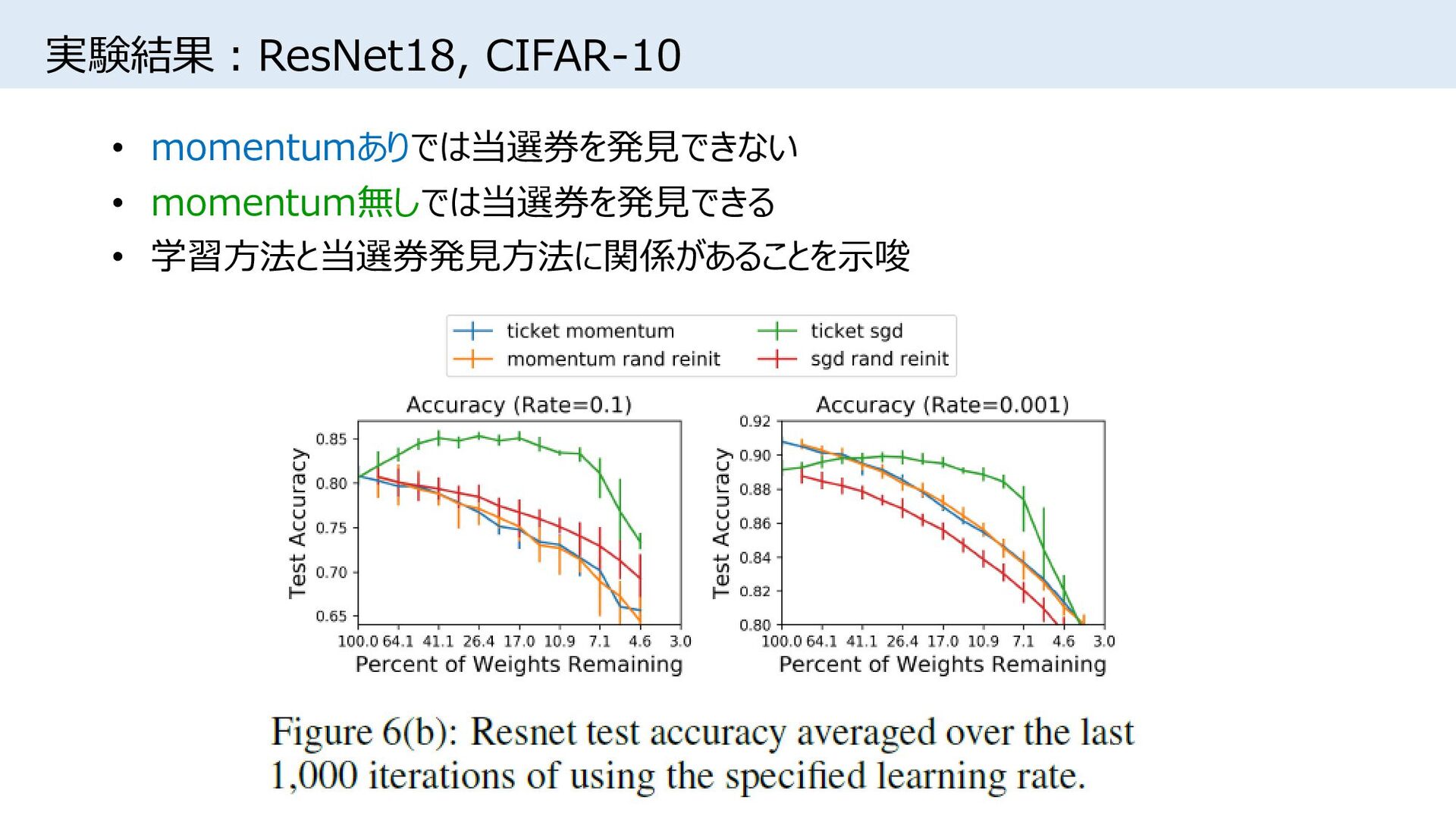{kind=link}
![実験結果:当選券の初期値分布 • 0付近の初期値を持つ重みは学習後も値が小さくpruningされやすい • [Song Han+, NIPS2015]でpruning・再学習後に見られる分布と似ているが、 上図は学習前の分布 • 正規分布からのランダム初期化は実質的に](https://files.speakerdeck.com/presentations/c60d7159cf7d4f83bad24759812e94fb/slide_14.jpg){kind=link}
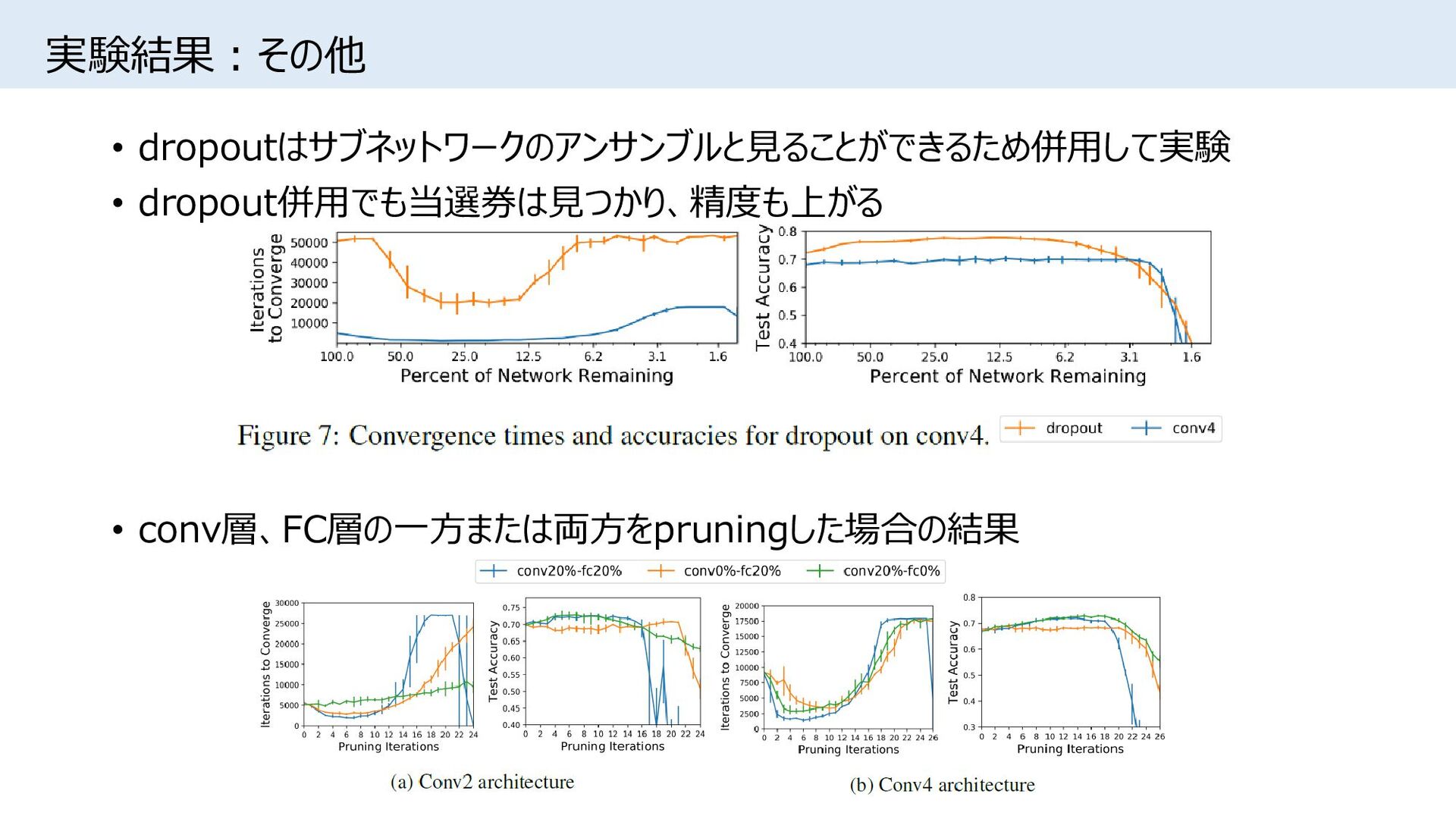{kind=link}
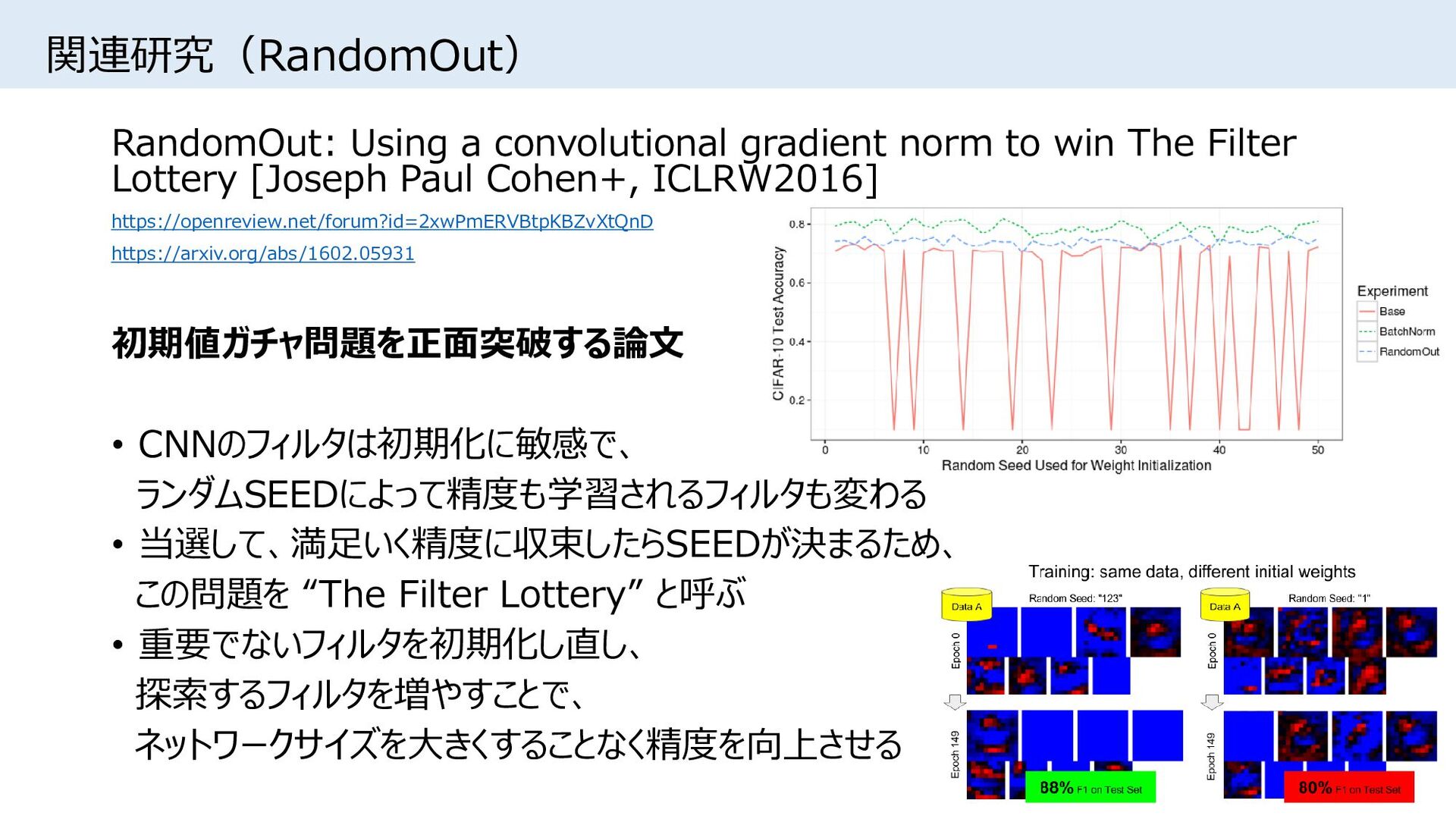{kind=link}
![関連研究(接続復活系) • DSD: Dense-Sparse-Dense Training [Song Han+, ICLR2017] https://arxiv.org/abs/1607.04381 •](https://files.speakerdeck.com/presentations/c60d7159cf7d4f83bad24759812e94fb/slide_17.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
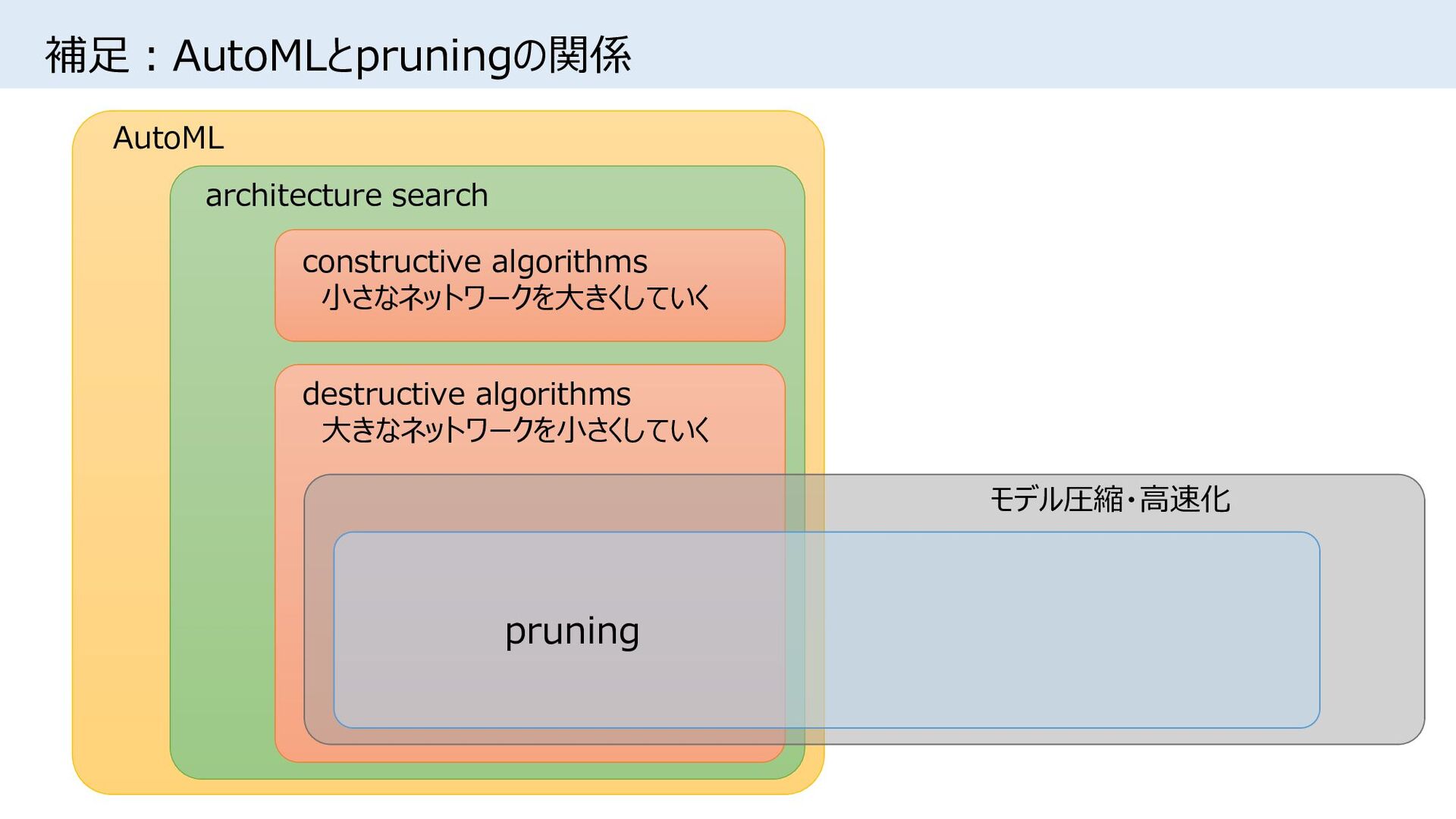{kind=link}
{kind=link}