Share
第40回コンピュータビジョン勉強会@関東「AR/VRを支える技術」発表資料。 ディープラーニングによるDR (Diminished Reality)の実現について検討しています。 https://www.slideshare.net/YosukeShinya/ddr-deep-diminished-reality-76972258 より移行。
{kind=link}
{kind=link}
![前提知識:DR (Diminished Reality, 隠消現実感) 説明文・図引用元: [森ら, 日本バーチャルリアリティ学会論文誌2011] • 「視覚的に不要な物体を隠蔽・消去, もしくは障害となる物体を透過させる技術」](https://files.speakerdeck.com/presentations/8f85c881ab064ba29a4c11b548dca066/slide_2.jpg){kind=link}
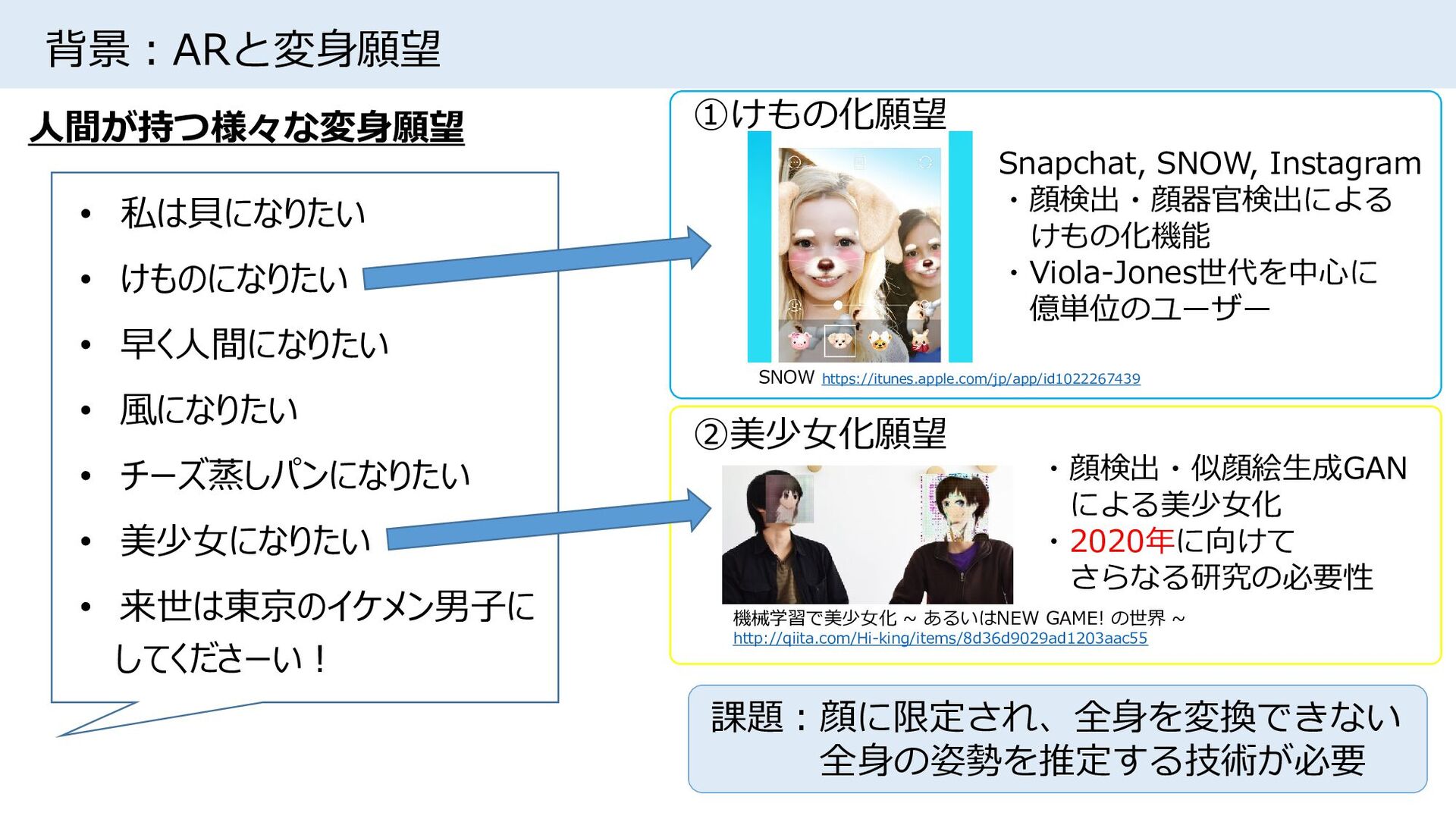{kind=link}
![人物姿勢推定 OpenPose https://github.com/CMU-Perceptual-Computing-Lab/openpose [Zhe Cao+, CVPR2017], [Tomas Simon+, CVPR2017] 多人数の2D姿勢を約10fpsで推定](https://files.speakerdeck.com/presentations/8f85c881ab064ba29a4c11b548dca066/slide_4.jpg){kind=link}
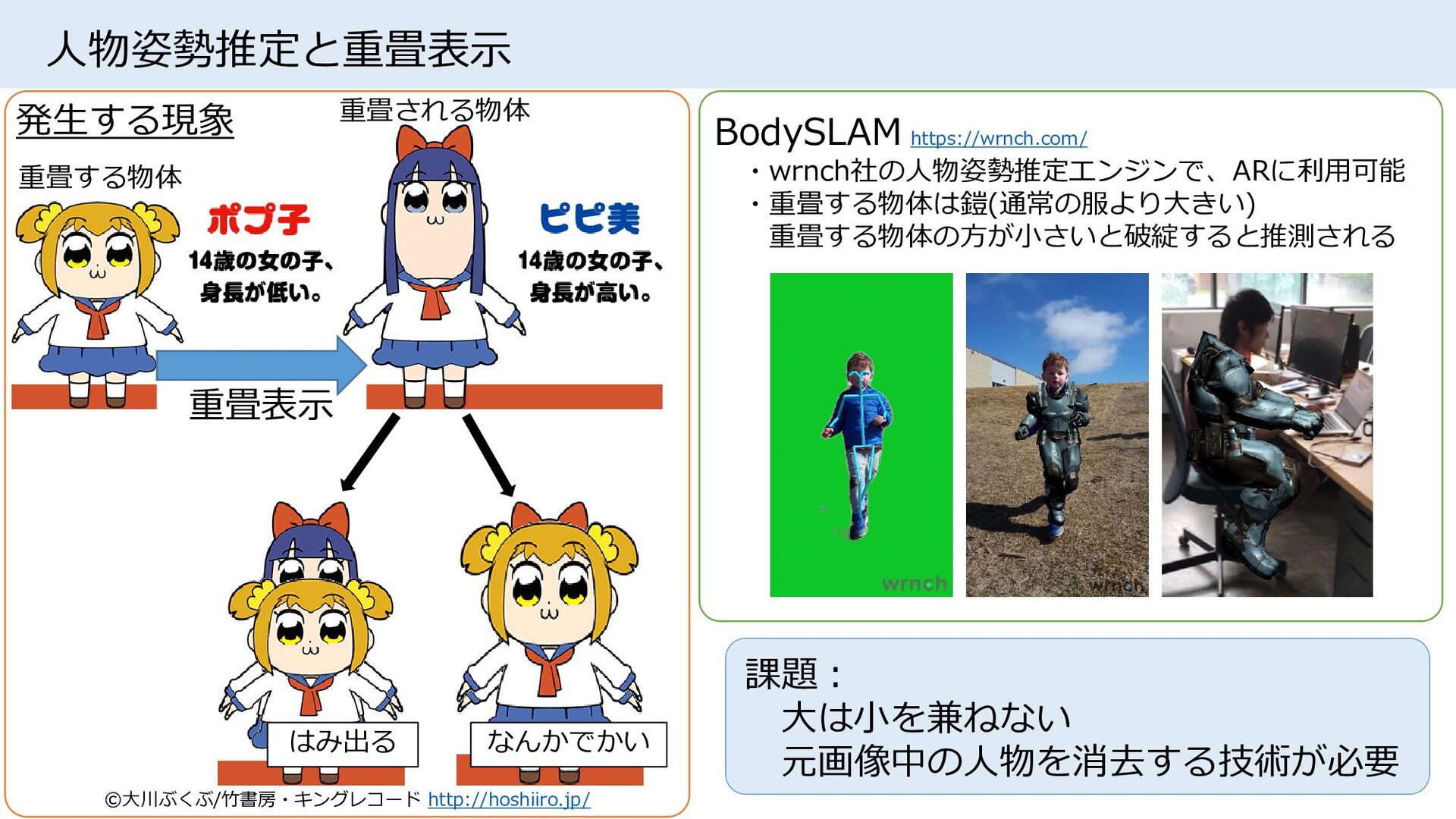{kind=link}
![画像補完 Globally and Locally Consistent Image Completion [Satoshi Iizuka+, SIGGRAPH2017]](https://files.speakerdeck.com/presentations/8f85c881ab064ba29a4c11b548dca066/slide_6.jpg){kind=link}
![Instance segmentation Mask R-CNN [Kaiming He+, arXiv2017] https://arxiv.org/abs/1703.06870](https://files.speakerdeck.com/presentations/8f85c881ab064ba29a4c11b548dca066/slide_7.jpg){kind=link}
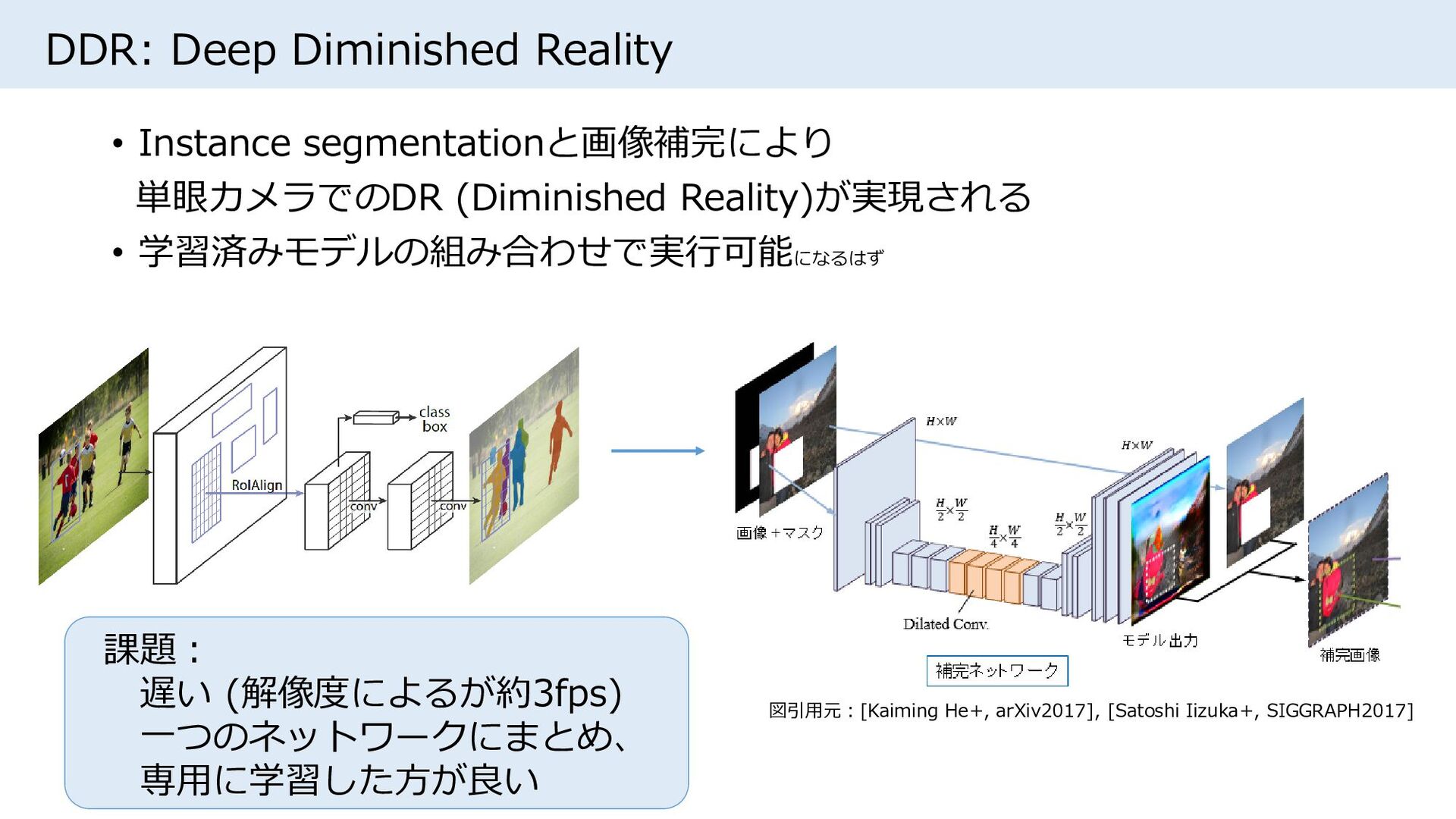{kind=link}
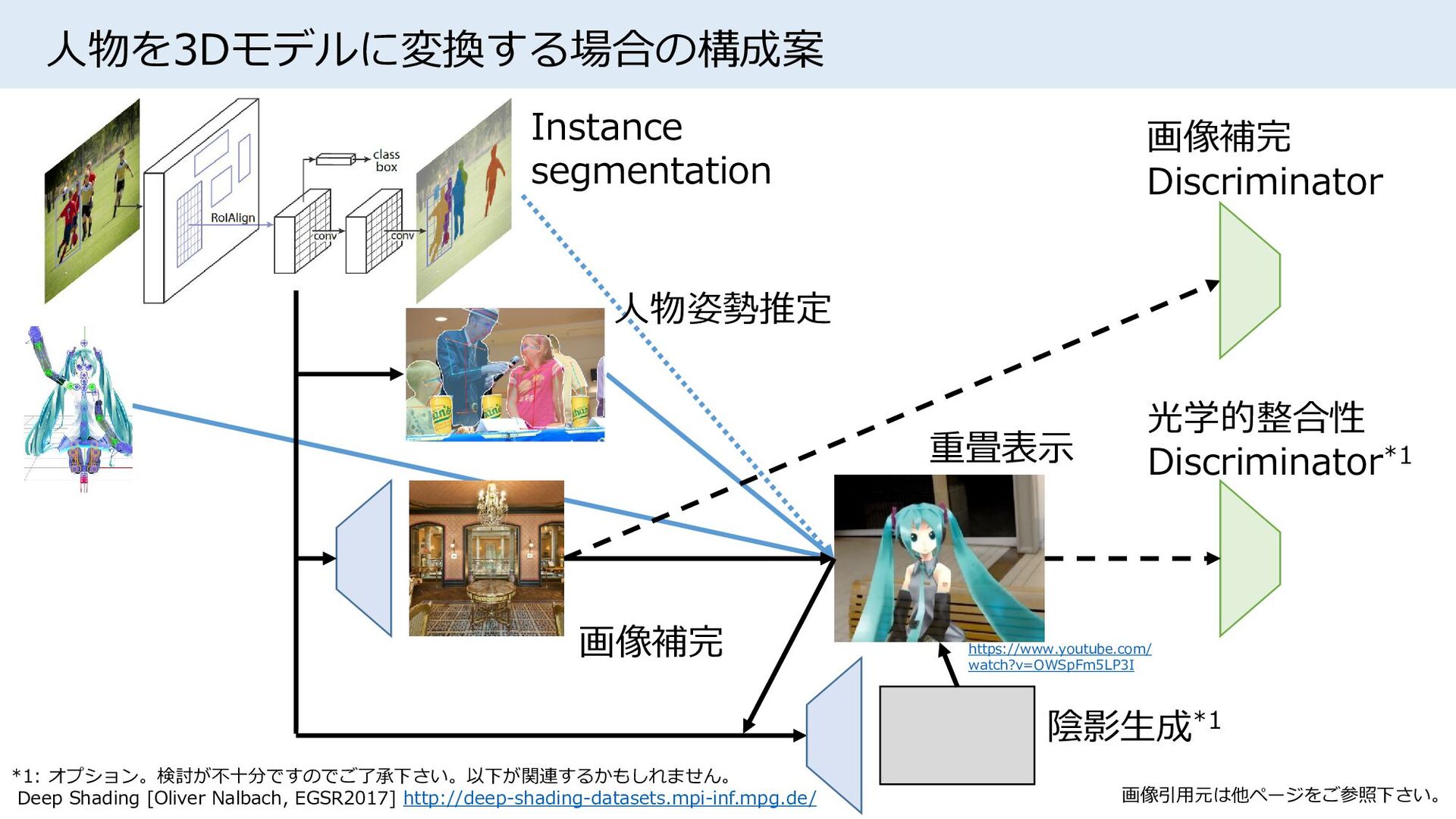{kind=link}
{kind=link}
![SURREAL Dataset Learning from Synthetic Humans [Gül Varol+, CVPR2017] http://www.di.ens.fr/willow/research/surreal/](https://files.speakerdeck.com/presentations/8f85c881ab064ba29a4c11b548dca066/slide_11.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}