Share
第53回 コンピュータビジョン勉強会@関東 CVPR2019読み会(前編) 発表資料。 https://www.slideshare.net/YosukeShinya/neural-rejuvenation-improving-deep-network-training-by-enhancing-computational-resource-utilization より移行。
{kind=link}
{kind=link}
{kind=link}
![LWC (Learning both Weights and Connections) [Song Han+, NIPS2015] •](https://files.speakerdeck.com/presentations/ad27f325b0e64f30b4e1b0c19527de00/slide_3.jpg){kind=link}
![Pruning Filters for Efficient ConvNets [Hao Li+, ICLR2017] ・pruningに対する各層のsensitivityを分析し、 pruning比率を決める必要がある](https://files.speakerdeck.com/presentations/ad27f325b0e64f30b4e1b0c19527de00/slide_4.jpg){kind=link}
![Network Slimming [Zhuang Liu+, ICCV2017] ・特定のリソースを狙って小さくできない ・小さくする方向だけ - リソースが不足している部分を大きくできない -](https://files.speakerdeck.com/presentations/ad27f325b0e64f30b4e1b0c19527de00/slide_5.jpg){kind=link}
![MorphNet FLOP/Size regularizer 誤ったら許さない というお気持ち [Ariel Gordon+, CVPR2018] FLOPs(演算回数)増やすんじゃねぇぞ というお気持ちを追加すると・・・](https://files.speakerdeck.com/presentations/ad27f325b0e64f30b4e1b0c19527de00/slide_6.jpg){kind=link}
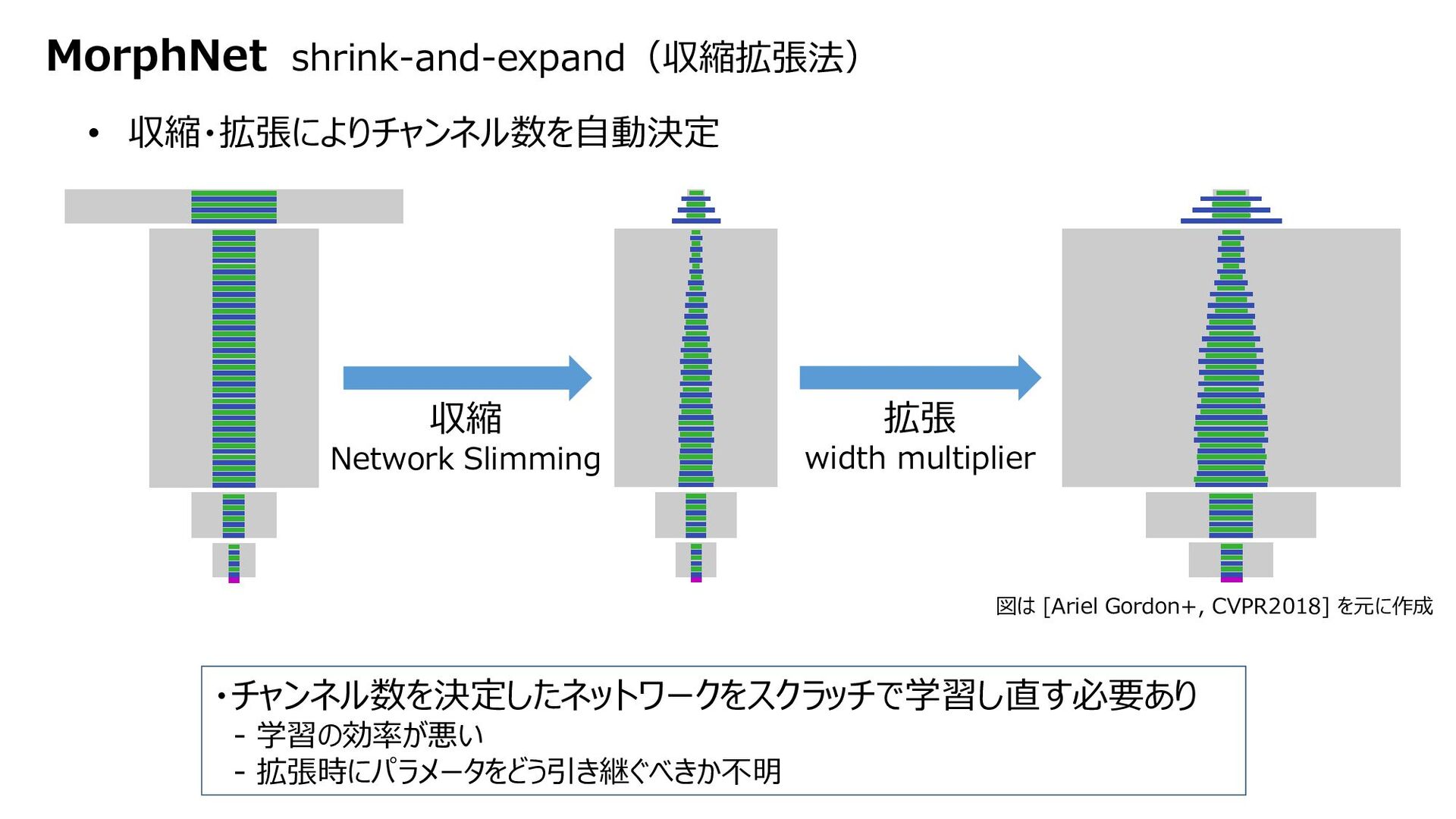{kind=link}
![DSD: Dense-Sparse-Dense Training [Song Han+, ICLR2017] ・ガチャっぽくない ・ランダム性を活用したキャパシティ増加を行っていない • 一度pruningした重みを](https://files.speakerdeck.com/presentations/ad27f325b0e64f30b4e1b0c19527de00/slide_8.jpg){kind=link}
![RandomOut [Joseph Paul Cohen+, ICLRW2016] • 重要でないフィルタをランダム初期化し直し、訓練継続 探索するフィルタを増やし、ネットワークサイズを大きくすることなく精度を向上させる](https://files.speakerdeck.com/presentations/ad27f325b0e64f30b4e1b0c19527de00/slide_9.jpg){kind=link}
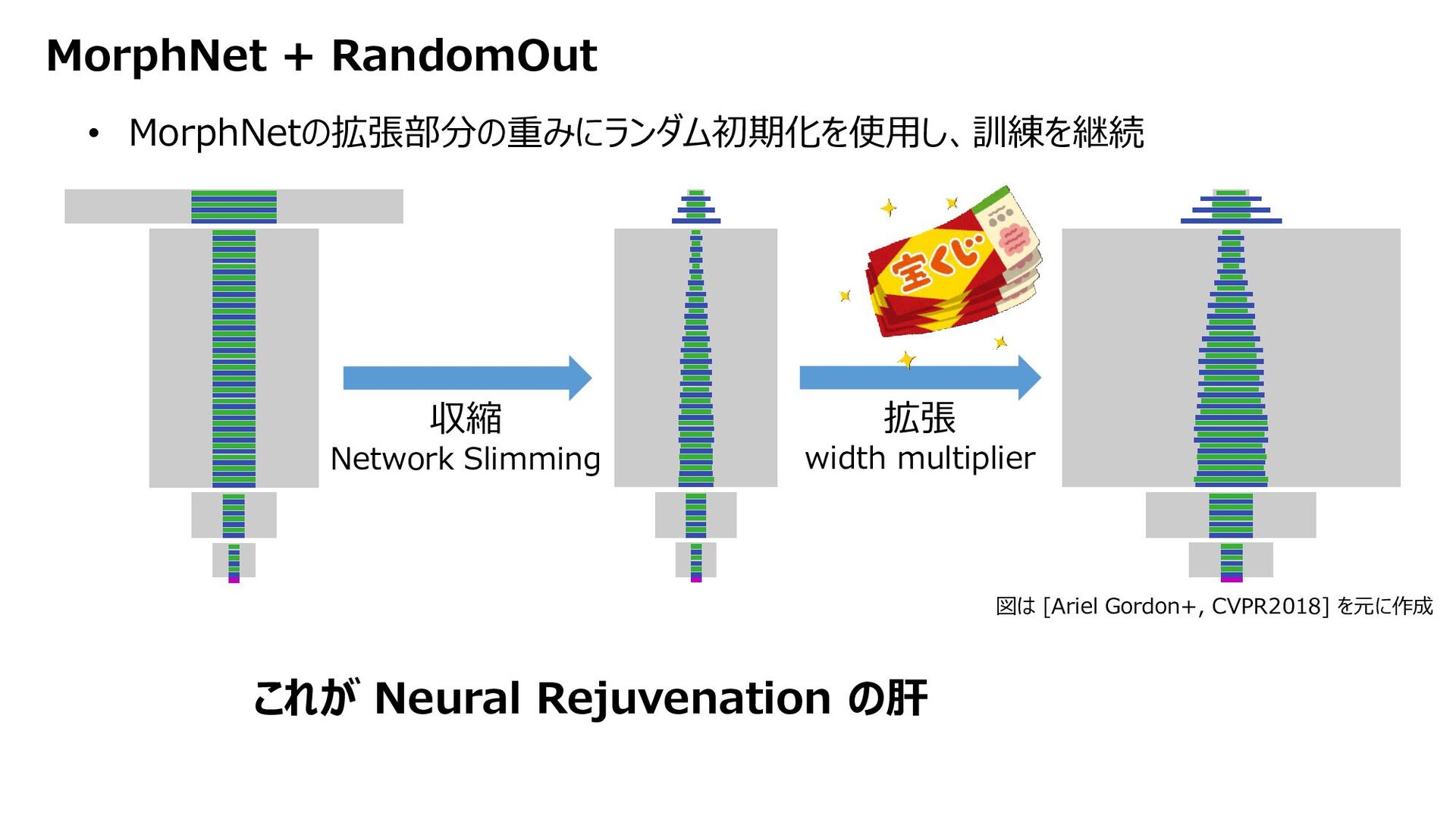{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
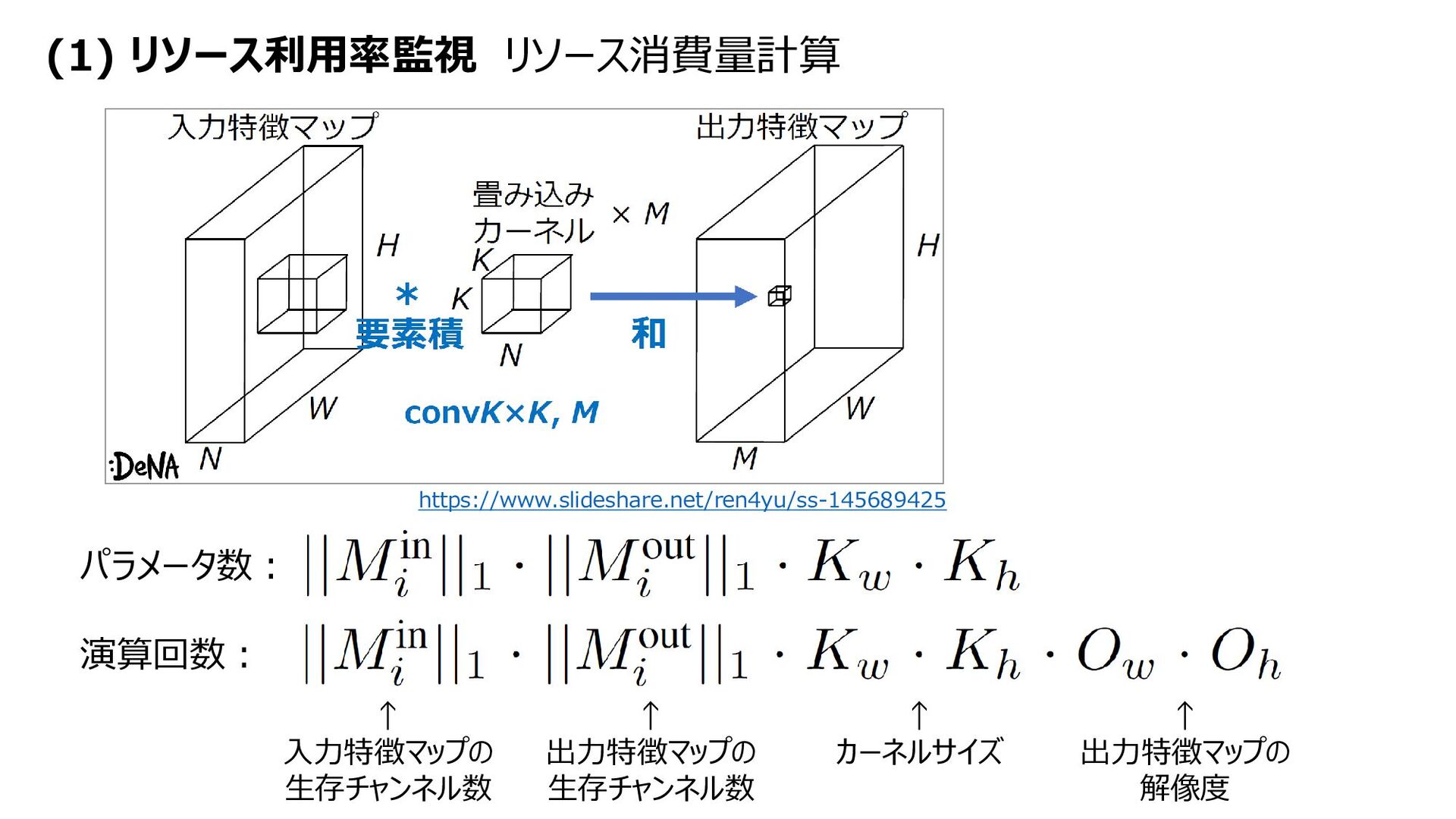{kind=link}
{kind=link}
{kind=link}
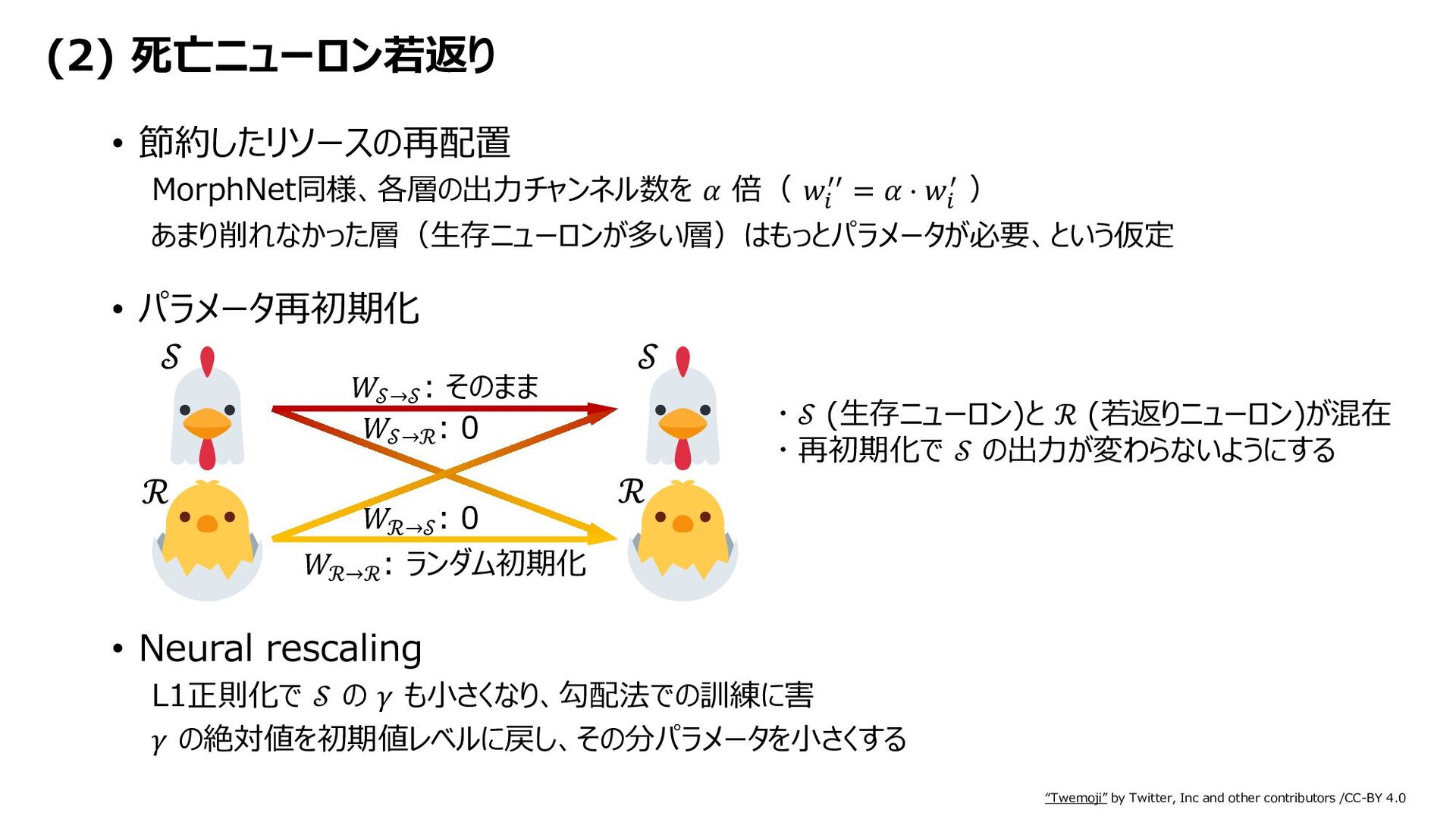{kind=link}
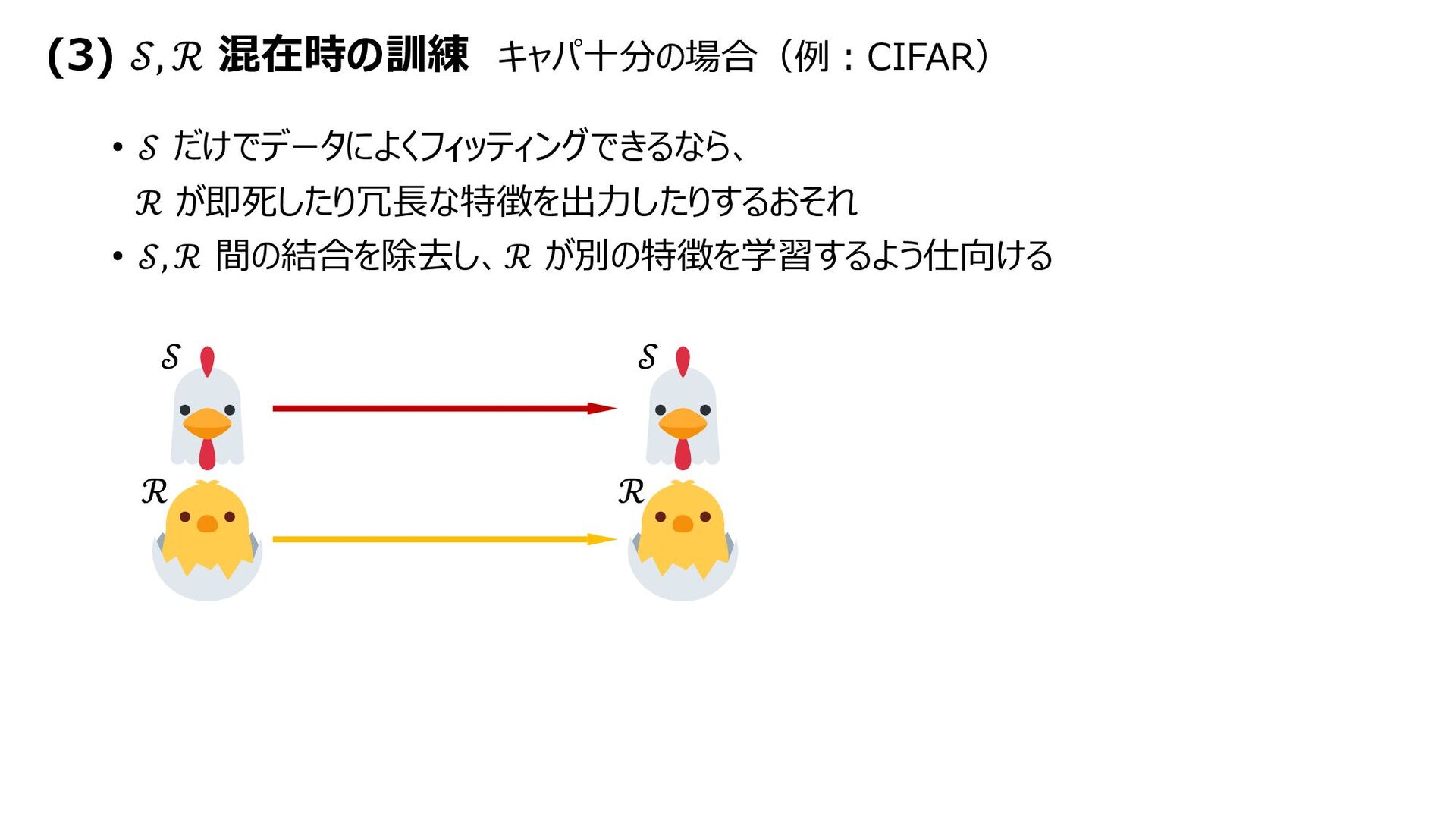{kind=link}
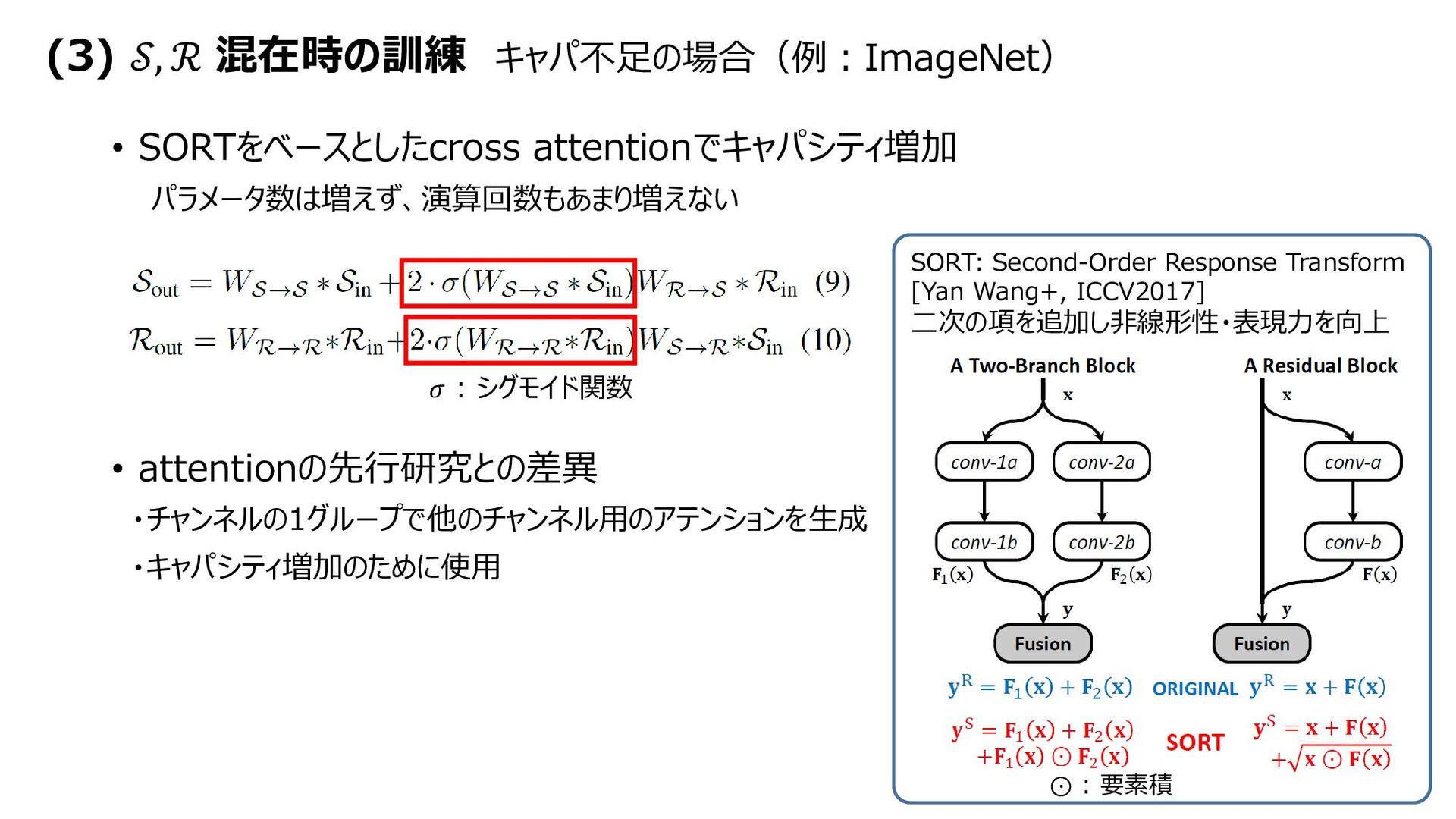{kind=link}
{kind=link}
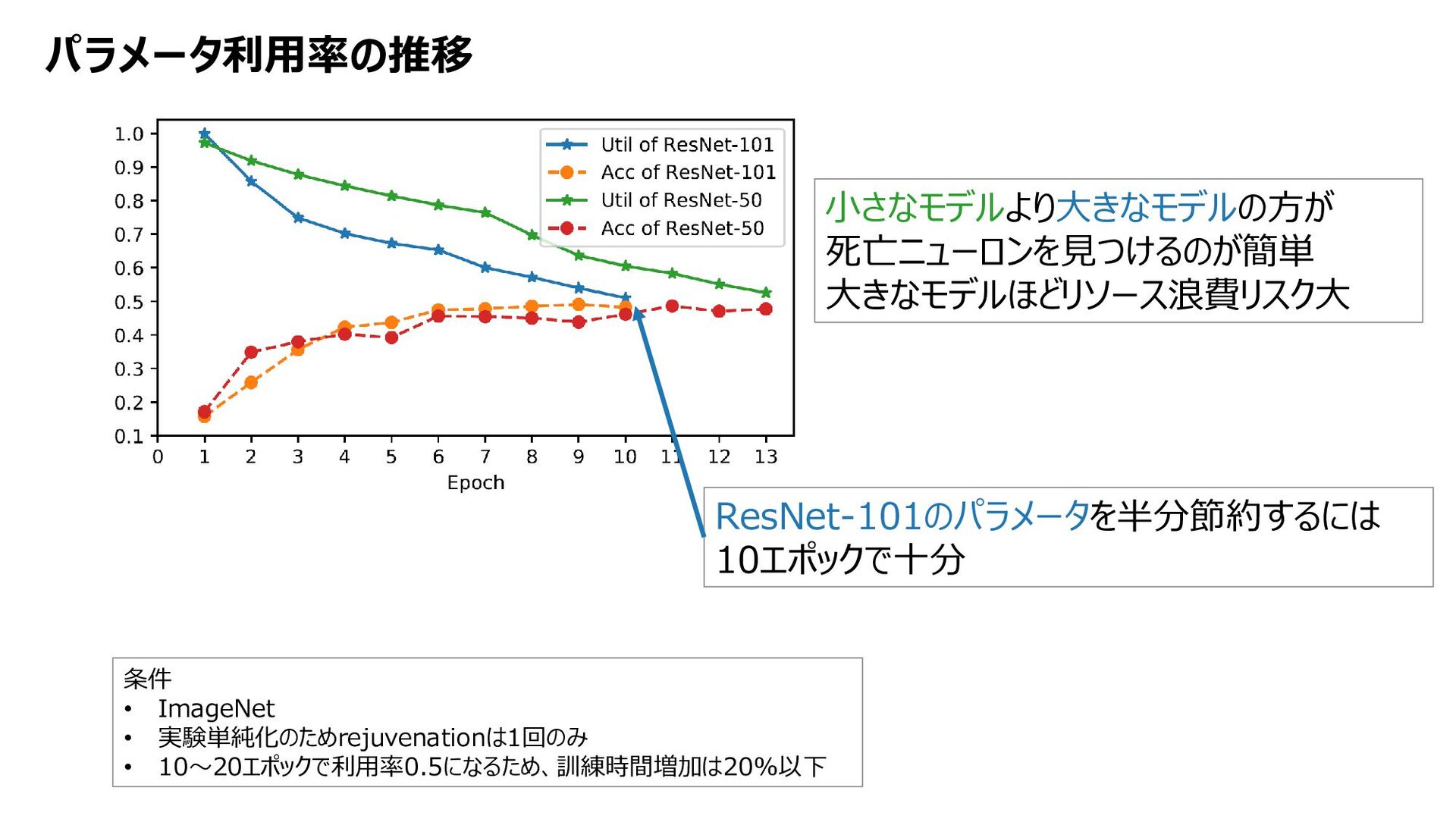{kind=link}
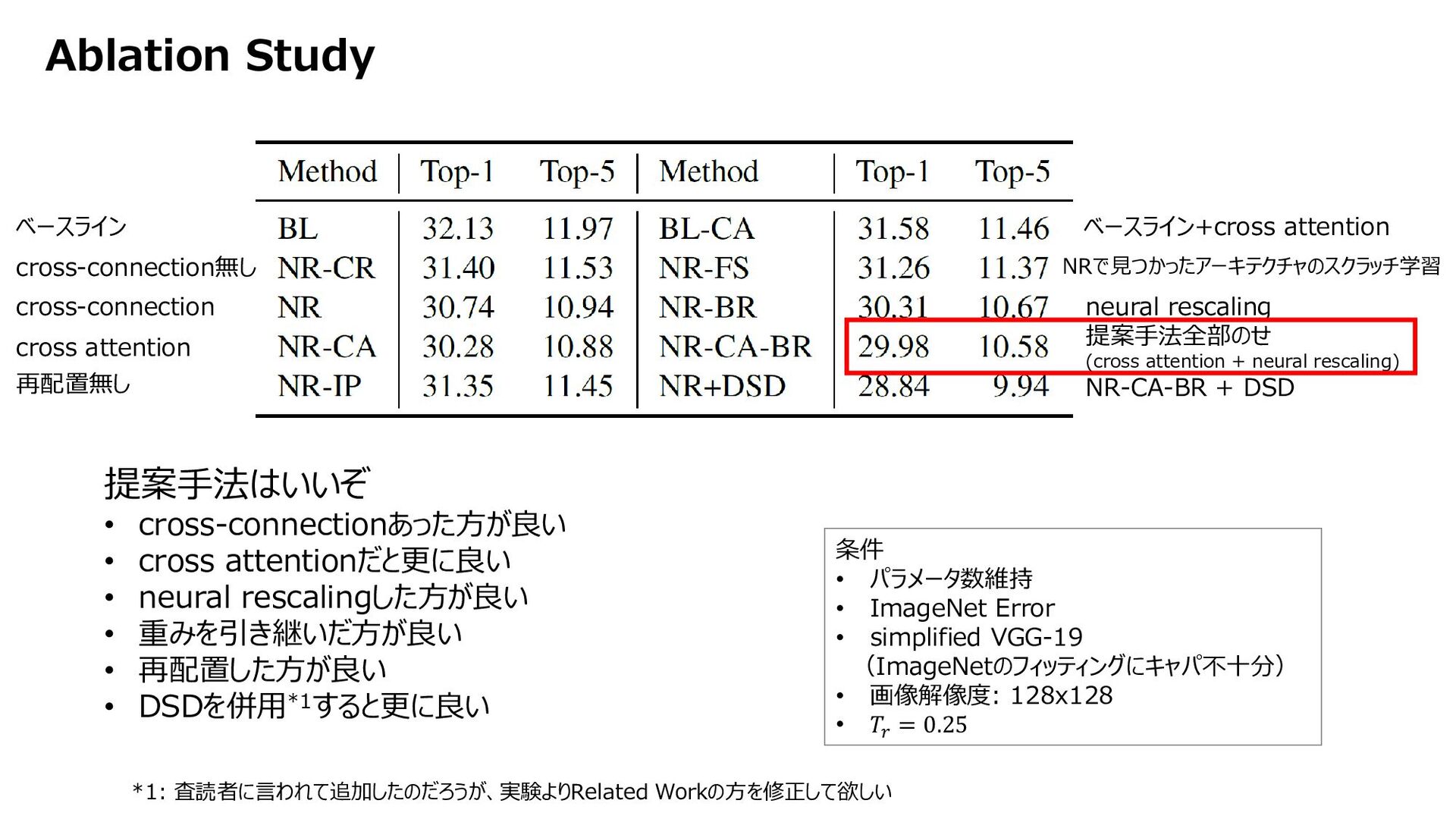{kind=link}
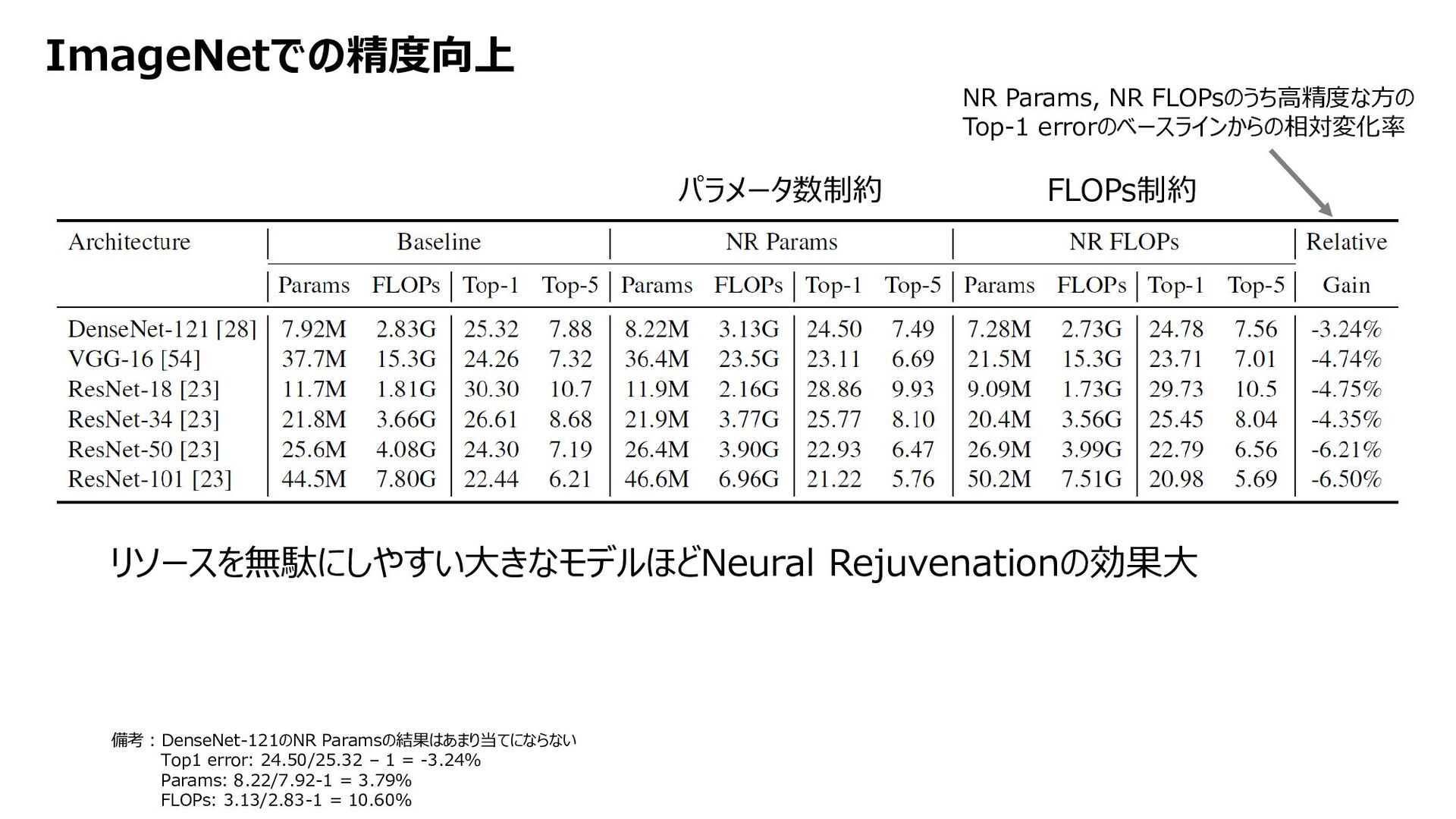{kind=link}
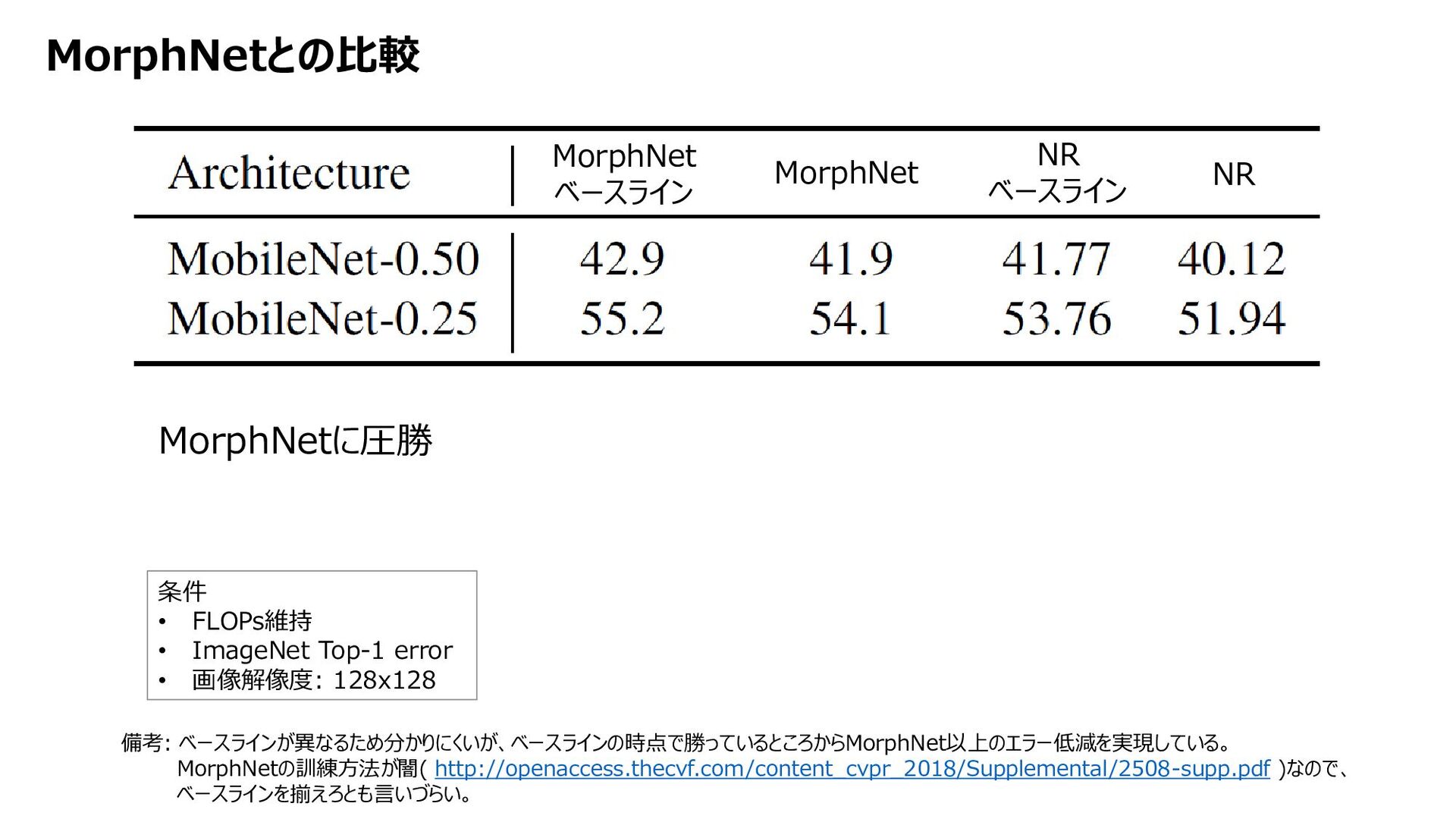{kind=link}
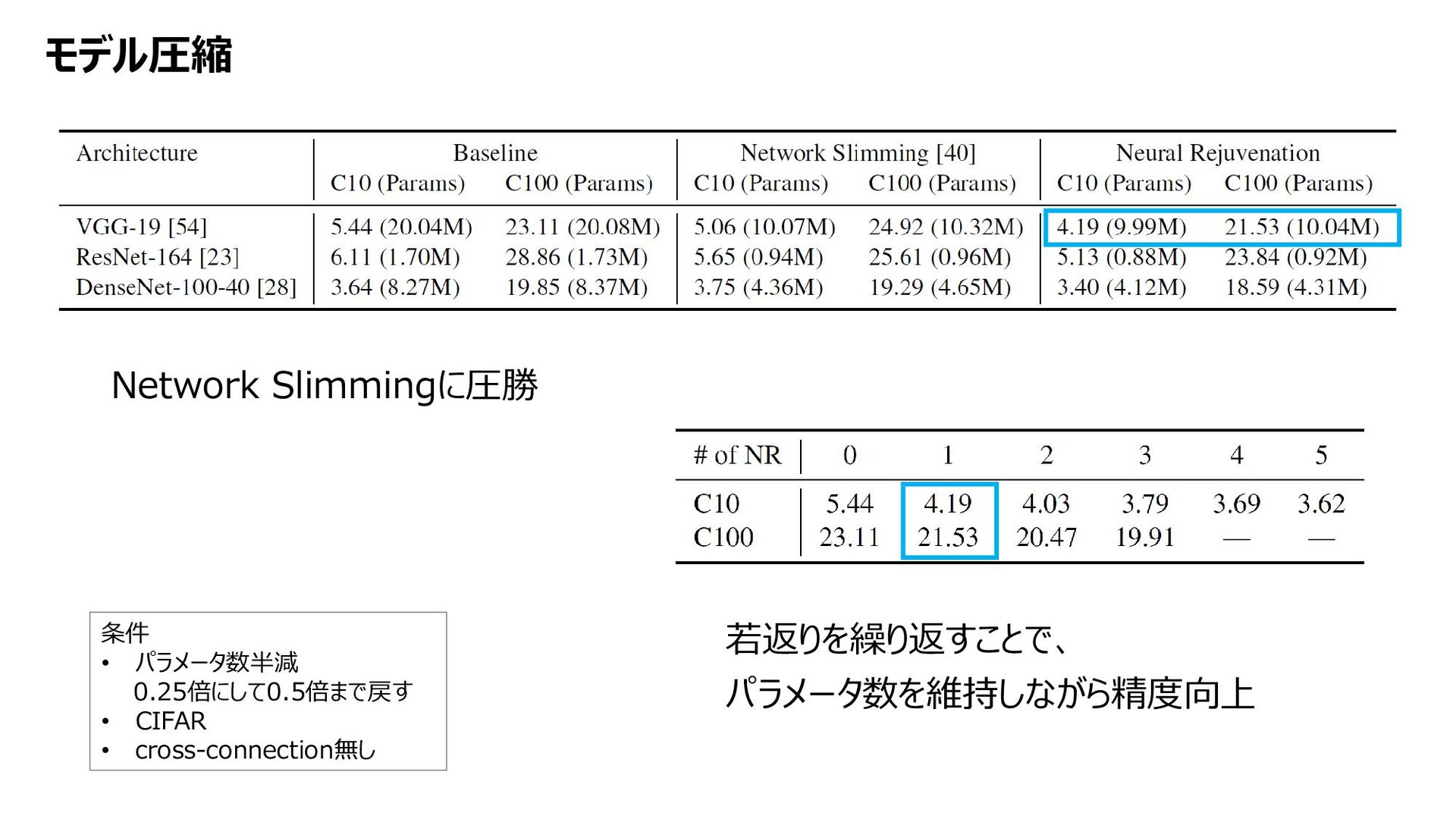{kind=link}
{kind=link}