Subtransactions in PostgreSQL often go unnoticed—until they quietly erode performance under heavy workloads. This talk exposes how subtransactions impact transaction throughput, locking, and crash recovery, especially in large or highly concurrent systems. Attendees will learn how to detect hidden subtransaction bottlenecks, interpret system catalog behavior, and implement practical tuning strategies to prevent cascading latency and transaction bloat.
{kind=link}
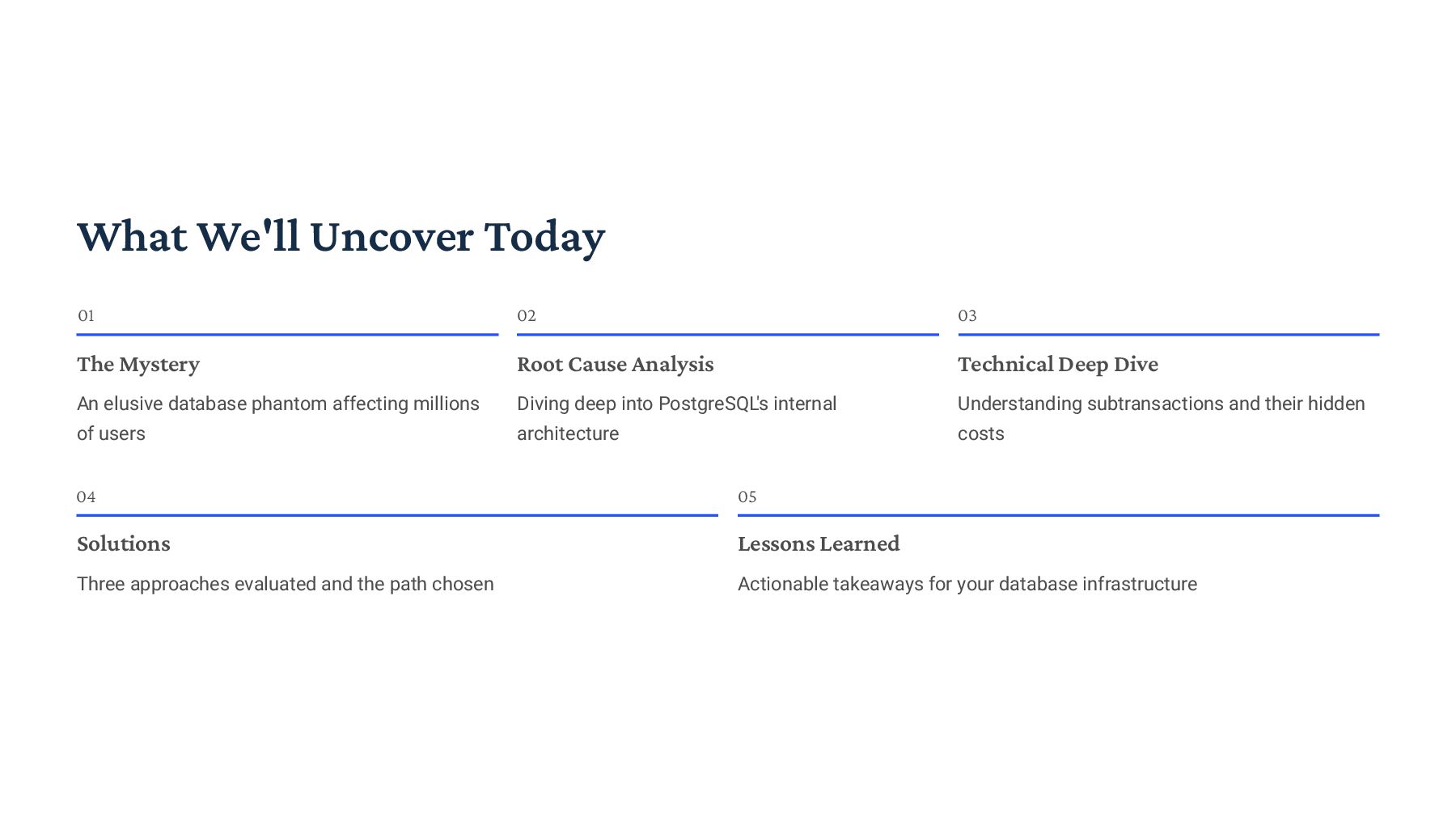{kind=link}
{kind=link}
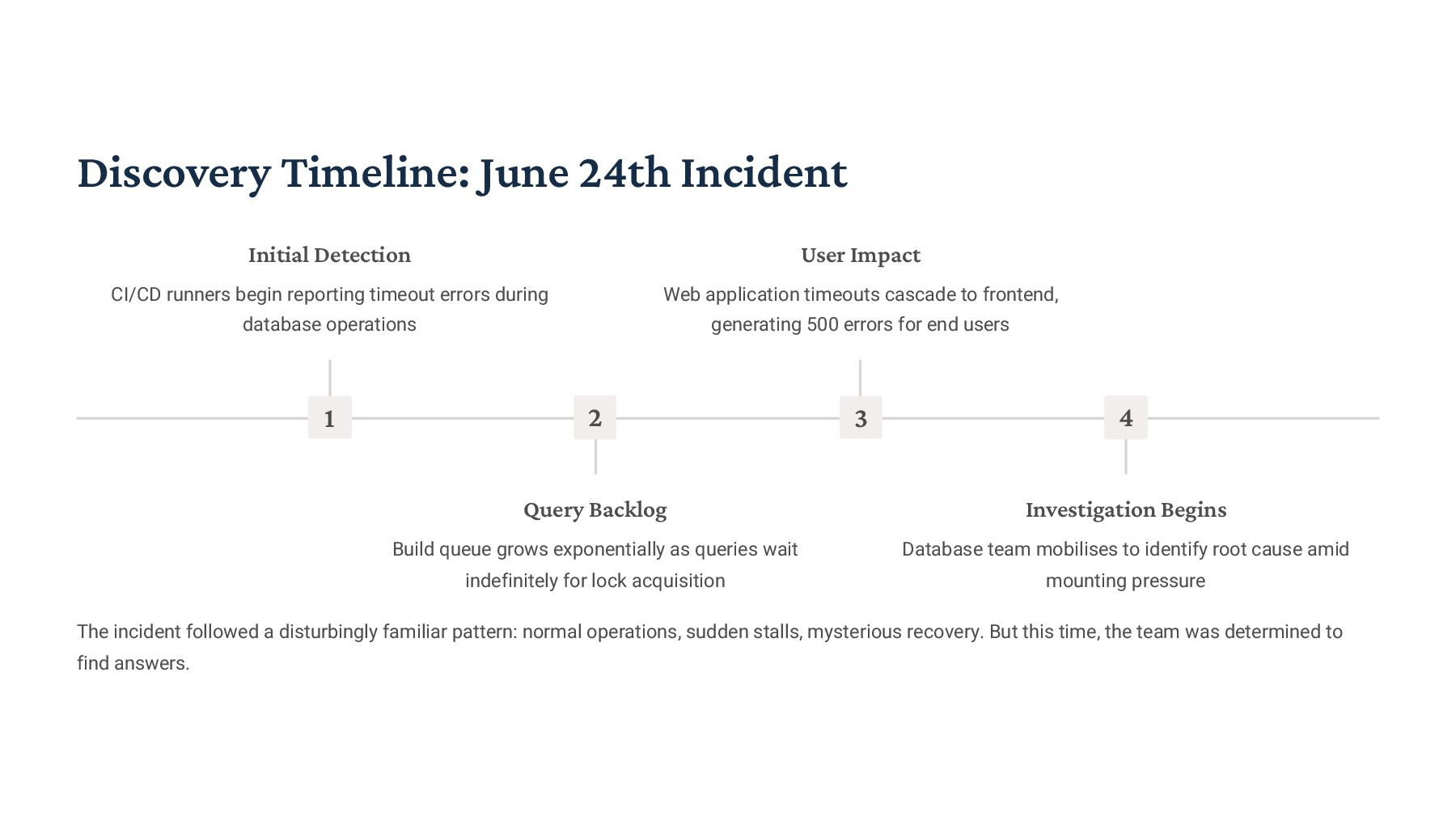{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
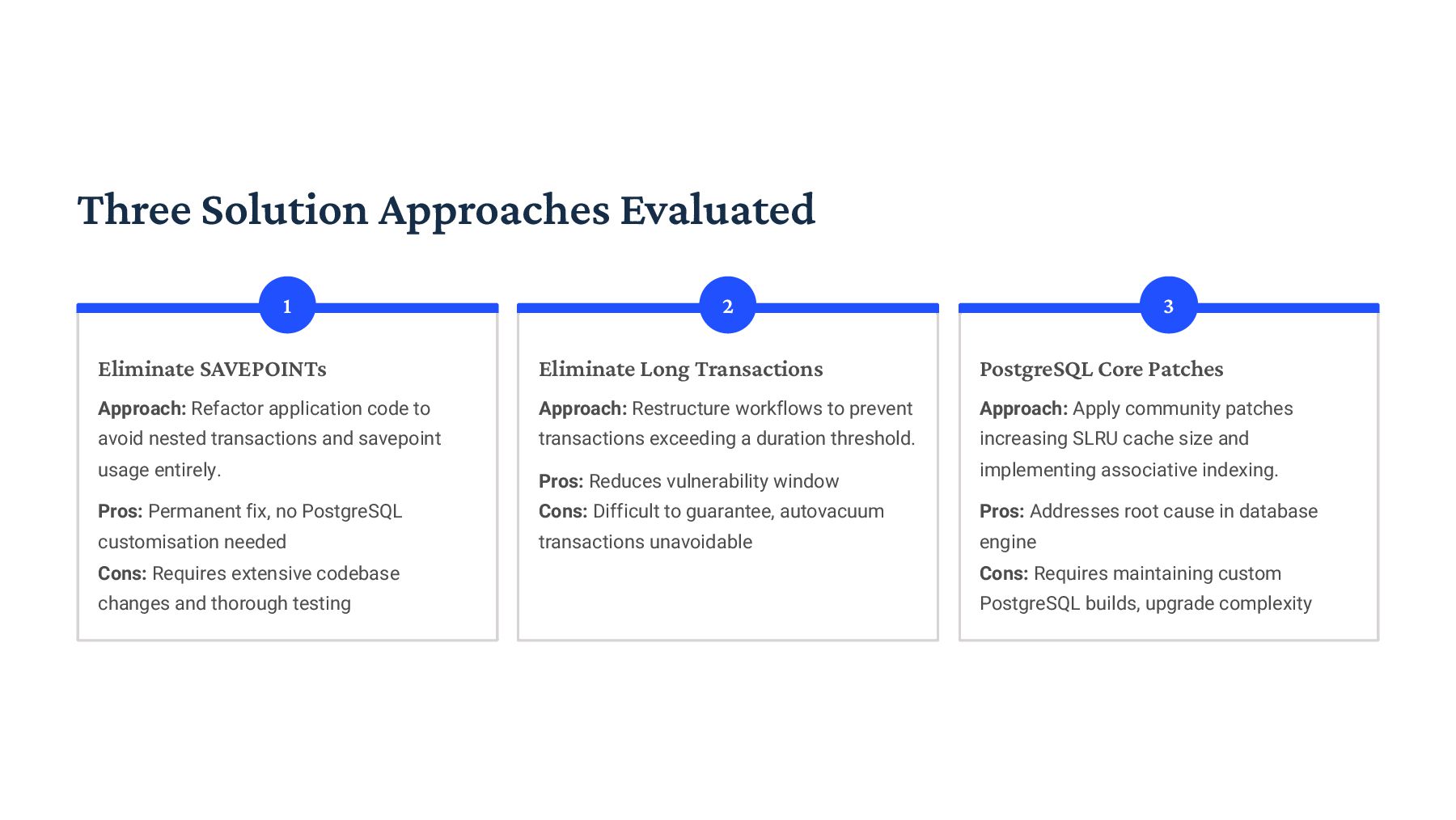{kind=link}
{kind=link}
{kind=link}
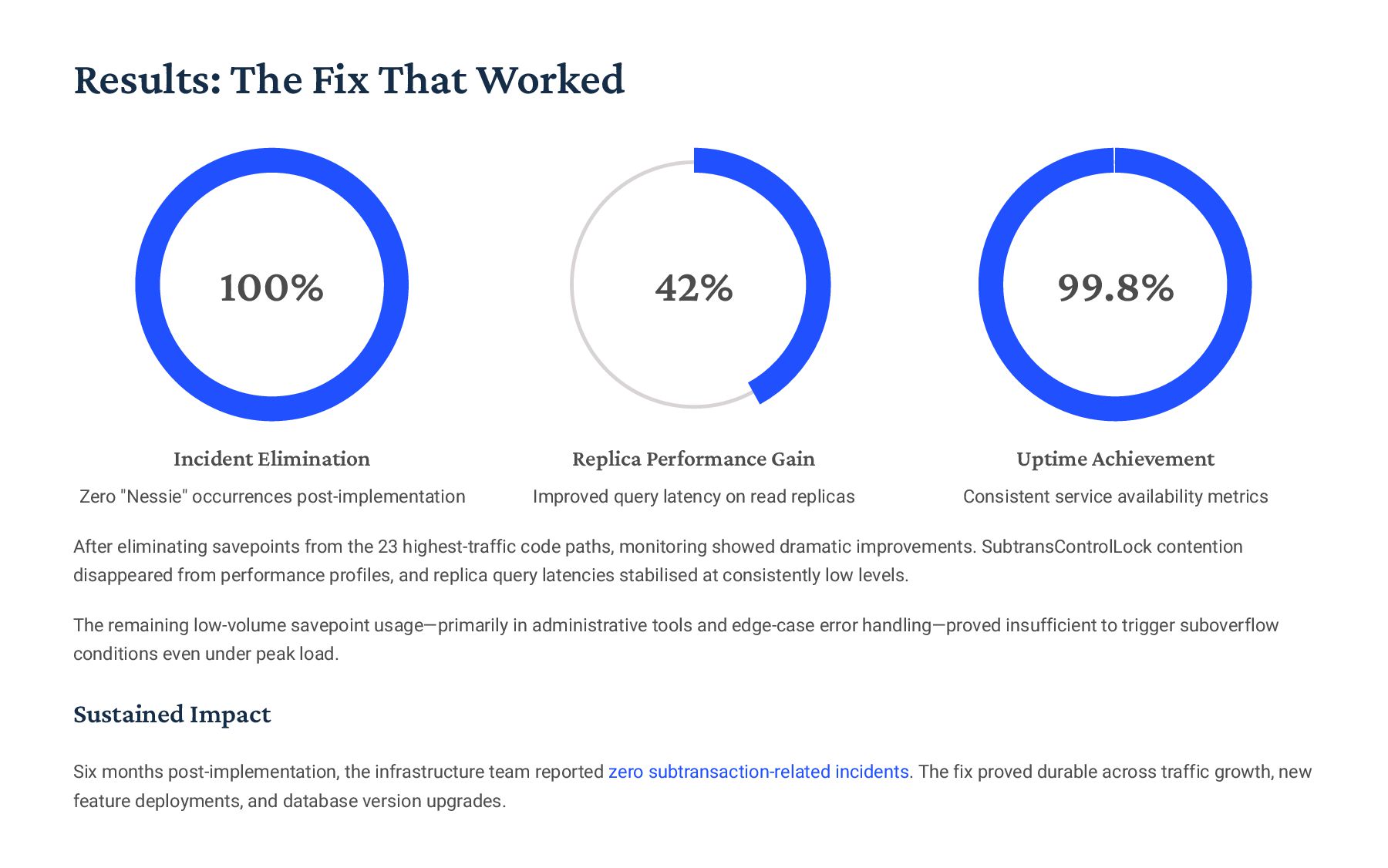{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}