on 01/30/2019). [2] 論文解説 attention is all you need (transformer) - ディープラーニングブログ. http://deeplearning.hatenablog.com/entry/transformer. (Accessed on 01/30/2019). [3] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. Attention is all you need. CoRR, abs/1706.03762, 2017. [4] 斎藤 康毅. 『ゼロから作る Deep Learning ②:自然言語処編』. オライリー・ジャパン, 2018. 16
{kind=link}
{kind=link}
{kind=link}
{kind=link}
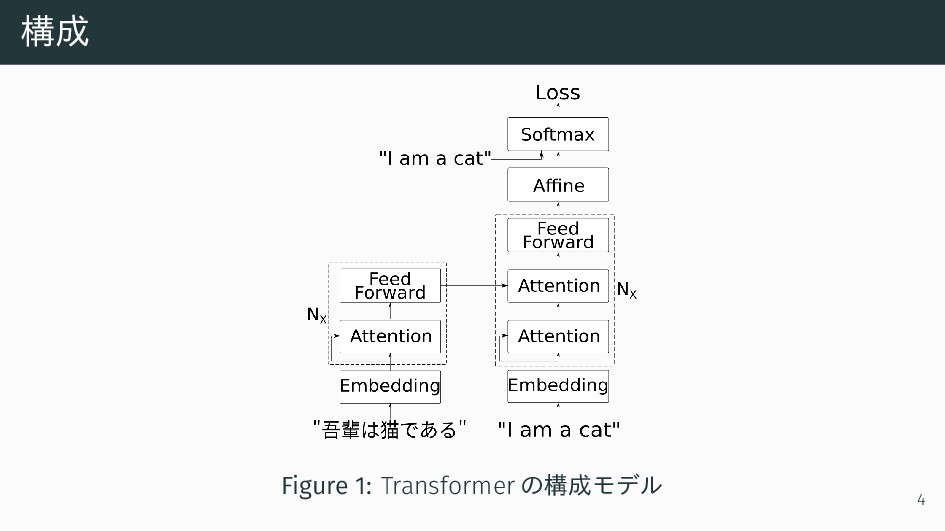{kind=link}
{kind=link}
{kind=link}
{kind=link}
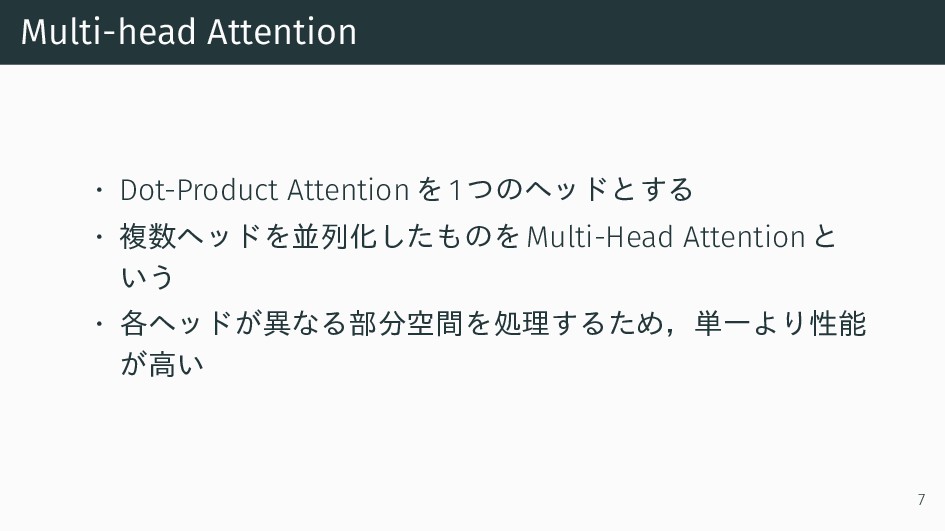{kind=link}
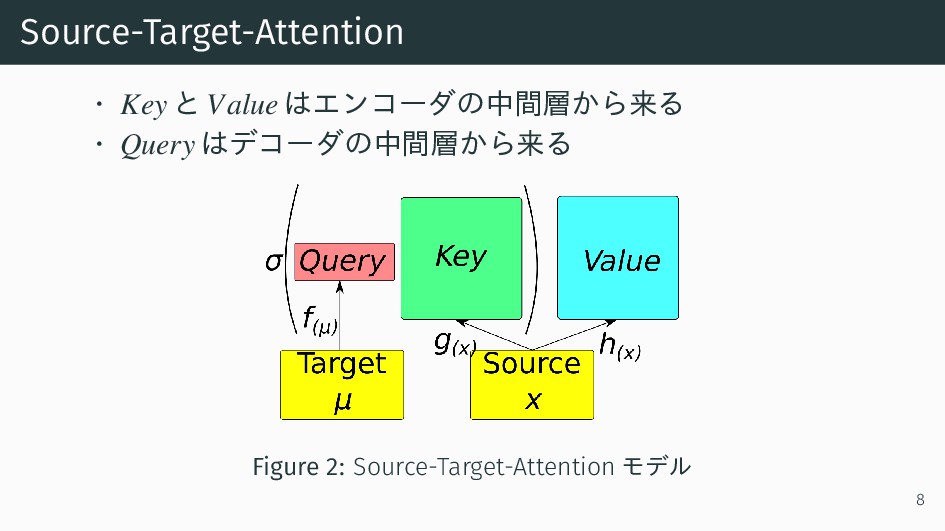{kind=link}
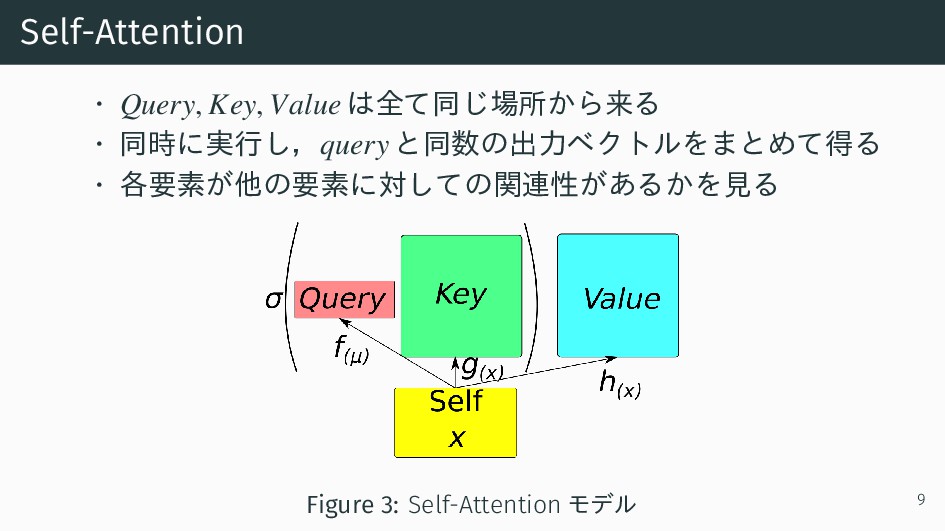{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![参考文献 [1] 作って理解する transformer / attention - qiita. https://qiita.com/halhorn/items/c91497522be27bde17ce#encoder. (Accessed](https://files.speakerdeck.com/presentations/8bc1a06f868b401eab97809e88dd606b/slide_20.jpg){kind=link}