MHSAの代わりにAveragePoolingを行ってベクトルを混ぜている • 単純なPoolingだが元モデルの精度を超えた • MetaFormerという構造がViTの鍵となっていることを主張 • 後半の層ではMHSAを使うことでより精度が向上 ⇢ 前半の層はスムージングだけだが後半の層にはそれ以外の役割も? MetaFormer Is Actually What You Need for Vision. Yu他. CVPR 2022. https://arxiv.org/abs/2111.11418
テクスチャを見ている • ViTでは猫と認識される! ⇢ 形を見ている Are Convolutional Neural Networks or Transformers more like human vision? Tuli他. CogSci 2021. https://arxiv.org/abs/2105.07197
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
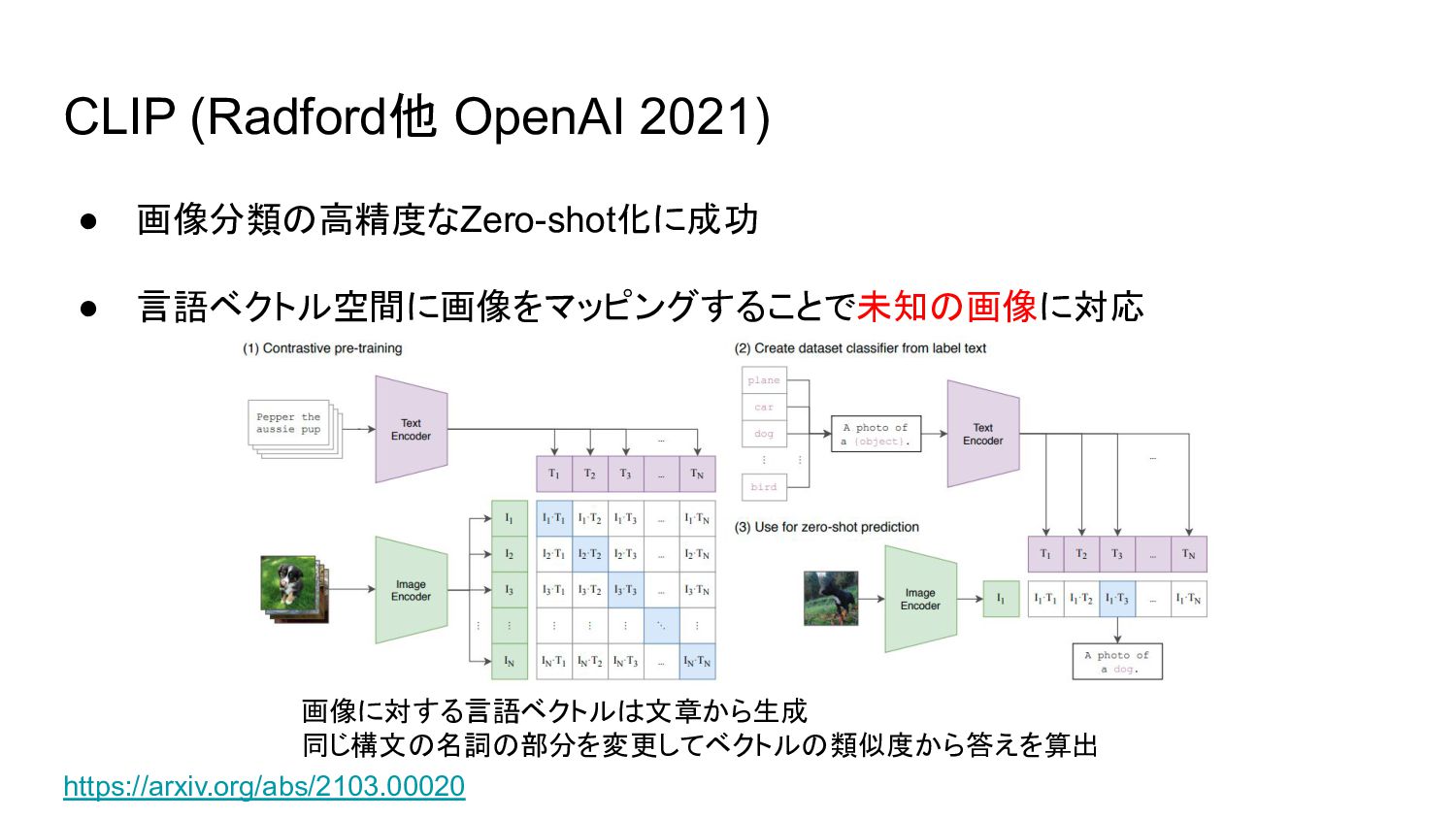{kind=link}
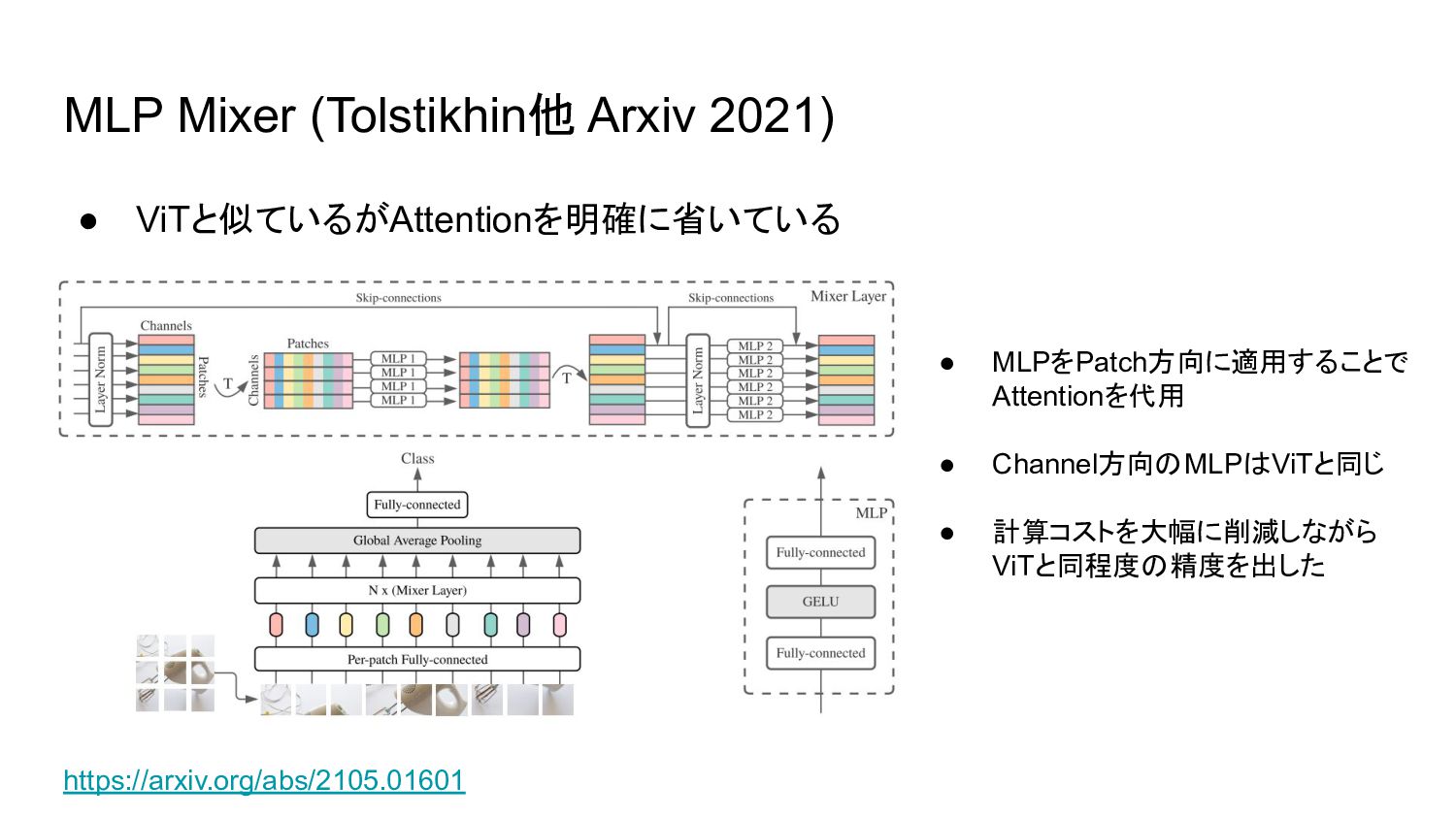{kind=link}
{kind=link}
{kind=link}
{kind=link}